My plan on completing Data Structures and Algorithms in Java by December 31st, 2016, requires changing my reading strategy. Reading technical books cover to cover, like a novel, is rewarding but inefficient and impractical. How about a different approach ?
I’m applying active reading principles from How to read a book[1] and A mind for numbers: active reading by questioning author’s intention, indentifying questions author is attempting to answer.
I skimmed the 15 chapters (although I had already read the chapters on maps) and below are my notes.
The skeleton
Before I skimmed each chapter, I paused and flipped to the page that maps each chapter/section to the ACM[2]. I bookedmarked this page because it helps frame the entire study session — constant questioning of what, and why, I am reading the material.
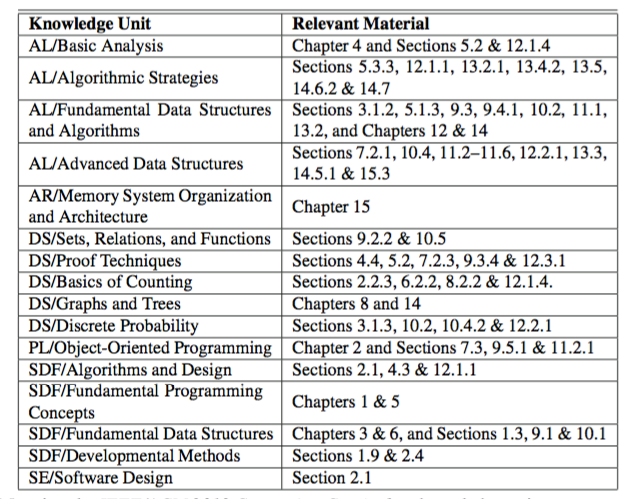
Chapter 1
Introduction to java and basic programming principles. Conditionals, loops — basic stuff.
Chapter 2
Object oriented design. Introduction to design patterns such as the adapter pattern. The three criteria for good software: robustness (handling unexpected inputs), adaptiblity (adapting to changes and requirements), reusability (reusing code somewhere else).
Chapter 3
Fundamental data structures including arrays and linked lists — singlely, doubley and circular linked lists. Covers the advantage of implementing linked lists over arrays, and vice versa. Compares shallow and deep copies: shallow method copies pointers but deep instantiates another copy of the reference.
Chapter 4
Establishing nomenclature for comparing performacne: big-o. The question of what and why big-o notation, and its history. The three levels of performance: best, worst, and avergae. The 7 mathematical functions, described in ascending order, from best to worst:
- Constant time
- Logaritmic
- Linear
- N(Logarithmic)
- Quadratic
- Cubed
- Exponential
Chapter 5
Recursion. Impleneting a recursive search algorithm: binary search. When is recursion a bad idea? What a tail recursion is and how to eliminate it.
Chapter 6
Additional data structures. Introducing additional abstract data types (ADT): stacks and queues. Two primary methods of implementing a stack: array and linked list. Leveraging modulus technique to maintain a circular queue. Dequeue, pronounced as “deck”, implements properties of both stack and queue: add to head or tail, and remove from head or tail.
Chapter 7
High level concept of object oriented programming. Instead of relying on the client to initially size the array, a more client-friendly solution is offered: dynamic arrays. The iterator interface is introduced, as well as positional lists.
Chapter 8
Generic trees and ordered trees – including binary and binary search trees, and techniques to traverse: preorder, postorder. Peek at breathe depth first — I thought this concept was reserved for graphs. The chapter ends use cases and trees can model and solve real problems.
Chapter 9
Additional ADT: priority queue, which can be implementing with a positional list or a sorted list. The positional list offers O(1) to insert, but is O(N) for retrieving the minimum. The sorted list can, instead, offer O(1) for minimum but O(N) for inserting. Is there a data structure that offers the best of both worlds, something in between? Yes. The Heap. The heap offers log(N) for both insert and retrieving the minimum value. Additional features, such as removing an entry (not minimum) from a priority queue, require adapting the ADT.
Chapter 10
The map ADT is introduced. A primitive data structure to implement a map, via an array, is introduced, by followed the hashtable. The chapter ends with sorted maps, skip lists and sets.
Chapter 11
Binary search trees, a special type of tree. To combat the worst case scenario (inserting sorted items produces, effectively, a linked list) another ADT is introduced: AVL trees. Two other balancing trees are introduced: splay and (2,4) trees. Chapter ends with Red-Black trees.
Chapter 12
Up until Chapter 12, only two elementary sorting algorithms have been introduced: insertion sort and select sort. Divide and conquer, an algorithm design pattern, is introduced with two concrete implementations: merge and quick sort — both with a runtime complexity of O(nlogn). Radix and bucket is an improvement in runtime complexity — O(N). The concept of stable sorting algorithms are introduced, and we face another type of issue: selecting the correct items.
Chapter 13
Pretty neat topic on tackling “string matching.” Discusses a primitive method for string matching — I think we can I guess how this brute force method works — followed by advanced techniques: The Boyer-Moore algorithm and Knute-Morris-Prath Algorithms. Covers compression algorithms, including the huffman code. Covers dynamic programming, a method for matching a sequence of strings but reduces the runtime complexity, from exponential, by implementing “a few loops”.
Chapter 14
Introduces another ADT – graphs and respective terms: edges, vertices, directed, undirected. Presents two different strategies for keeping track of neighbors: adjaceny matrix and adjancey list. Discusses (2) methods for searching for nodes: depth search first or breathe search first. Covers several methods for constructing a minimum spanning tree. Like OSPF, introduces Dijastreka’s algorithms for determining shortest paths.
Chapter 15
Dives into characteristics of JVM: garbage collection. Introduces the PC — not personal computer — to keep track of function/procedure calls. Compares the types of memory and the hiearchy in terms of performance. How data is stored on external disks, such as B-Tree.
Footnotes
[1] – How to read a book – http://pne.people.si.umich.edu/PDF/howtoread.pdf and a similar article: https://www.farnamstreetblog.com/how-to-read-a-book/
[2] – ACM – https://www.acm.org/education/CS2013-final-report.pdf
Leave a Reply