Schneider, F. B. (1993). What good are models and what models are good. Distributed Systems, 2, 17–26.
Paper Summary
In his seminal paper on models (as they apply to distributed systems), Schnedier describes the two conventional ways — experimental observation; modeling and analysis — we normally develop an intuition when studying a new domain. And for the remainder of the paper, he focuses on modeling and analysis, directing our attention towards two main attributes of distributed systems: process execution speeds; and message deliver delays. With these two attributes at the forefront of our minds we can build more fault-tolerant distributed systems.
Main Takeaways
The biggest “ah hah” moment for me was while reading “fault tolerance and distributed systems”. In this section, Schneider suggest that system architects should, from day one, focus their attention on fault-tolerance system architectures and fault-tolerant protocols, with an eye towards both feasibility and cost. To build fault tolerant systems, we should physically separate and isolate process, connect process by a communication network: doing so ensures component fails independently. That’s some seriously good intuition; I hope to incorporate those words of wisdom as I continue to learn about distributed and as I design my own distributed systems.
Great Quotes
In a distributed system, the physical separation and isolation of processors linked by a communications network ensures that components fail independently.”
One way to regard a model is as an interface definition—a set of assumptions that programmers can make about the behavior of system components. Programs are written to work correctly assuming the actual system behaves as prescribed bythe model. And, when system behavior is not consistent with the model, then no guarantees can be made
Notes
Defining Intuition
Distributed systems are hard to design and understand because we lack intuition for them
When unfamiliar with a domain, we can develop an intuition for it in one of two ways:
- Experimental observation – build prototype and observe behavior. Although the behavior in various settings might not be fully understood, we can use the experience to build similar systems within similar settings
- Modeling and analysis – we formulate a model and then analyze model using either mathematics or logic. If this model reflects reality, we now have a powerful tool (a model should also be both accurate and tractable)
Good Models
What is a model?
Schneider’s definition of a model is as follows: collection of attributes and a set of rules that govern how these attributes interact. Perhaps as important (if not important) is that there’s no single correct model for an object: there can be many. Choosing the right model depends on the questions we ask. But regardless of which specific model we choose, we should should choose a “good model”, one that is both accurate and tractable. Accurate in the sense it yields truth about the object; tractable in the sense that an analysis is possible.
What questions should we ask ourselves as we build distributed systems?
While modeling distribution systems, we should constantly ask ourselves two questions: what’s the feasibility (i.e. what types of problems does this solve); and cost (i.e. how expensive can the system be). The reason we ask ourselves this question is three-fold. First, we don’t want to try to solve an unsolvable problem “lurking beneath a system’s requirements”, wasting our time with design, implementation, and testing. Second, by taking the cost into consideration up front, we can skip choosing protocols that are too slow or too expensive. Finally, with these two attributes in mind, we can evaluate our solution, providing a “yardstick with which we can evaluate any solution that we devise.”
Why is studying algorithms and computational complexity insufficient for understanding distributed systems?
Although studying algorithms and computational complexity address two above questions (feasibility and cost), it ignores the subtle nuances of distributed systems. Algorithms and computational complexity assumes a single process, one that is sequential in nature. But distributed systems are different: multiple process communicating over channels. Thus, we need to extend our model to address the new concerns.
Coordination problem
I’m hoping I can update this blog post’s section because even after reading this section twice, I’m still a bit confused. First, I don’t understand the problem; second I don’t understand why said problem cannot be solved with a protocol.
Synchronous vs. Asynchronous
Why should we distinguish synchronous systems from asynchronous ones?
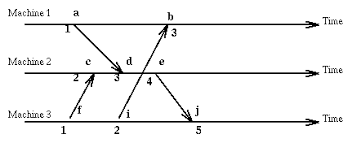
It’s useful to distinguish a synchronous system versus a asynchronous system. In the former, we make assumptions: speed of system is bounded. In the latter, we assume nothing — no assumptions about neither process execution nor message delivery delays.
Author makes a super strong argument in this section, saying that ALL systems are asynchronous, and that a protocol designed for a asynchronous system can be used in ANY distributed system. Big arguments. But is this true? He backs his claim up by saying that even processes that run in lockstep and message delivery is instantaneous still falls under the definition of a asynchronous system (as well as synchronous system).
Election Protocol
What can we achieve by viewing a system as asynchronous?
By no longer viewing a system as synchronous sand asynchronous instead, we can employ simpler or cheaper protocols. The author presents a new problem: N processes, each process Pi with a unique identifier uid(i). Create protocol so all processes learn leader.
According to the author, although we can solve the problem easily, the cost is steep: each node broadcasts its own uid.
So how can we solve the election protocol assuming a synchronous system?
We can define a τ to be both 1) greater than largest message delivery delay; and 2) largest difference observed at any instant by reading clocks. Basically, we use a constant and each process will wait until τ * uid(i) before broadcasting. In other words, the first process will broadcast and the messages will arrive at all other nodes before the second node attempts to sends a second broadcast.
Failure Models
When trying to understand failure models, we assign faulty behavior not by counting the occurrences, but by counting the number of components: processors and communication channels. With this component counting approach, we can say a system is t-fault tolerant, a system continuing to satisfy its specifications (i.e. keeps working) as long as no more than t of its components fault. This component driven concept is novel to me and forces me to think
Why is it important to correctly attribute failure?
The author states that we need to properly attribute failure. He provides an example on message loss. A message can be loss due to electrical issues on the channel (i.e. blame the channel) or maybe due to a buffer overflow on the receiver (i.e. blame the receiver). And since replication is the only way to tolerate faulty components (I’d like to learn more about this particular claim), we need to correctly attribute fault to the components because “incorrect attribution leads to an inaccurate disattributed system model; erroneous conclusions about system architecture are sure to follow”.
What are some of the various models?
He then talks about the various failure models including failstop, crash, crash+link, and so on. Among these failures, the lease disruptive is “failstop” since no erroneous actions are ever taken place.
Although it may not be possible to distinguish between a process that has crashed versus a process that’s running very very slowly, the implications and distinctions are important. When a process has crashed, other processes can assume the role and responsibility, moving forward. But, if the system respond slowly and if the other processes assume the slow process’s responsibilities, we are screwed: the state of the world loses its consistency.
When building failure models, how deep in the stack should we go? Should we go as far as handling failures in the ALU of a processor!? Why or why not?
We don’t want to consider a CPU’s ALU failing: it’s too expensive for us to solve (which relates ot the two attributes above, feasibility and cost); in addition, it’s a matter of abstractions:
A good model encourages suppression of irrelevant details”.
Fault Tolerance and distributed systems
As the size of a distributed system increases, so does the number of its components and, therefore, so does the probability that some component will fail. Thus, designers of distributed systems must be concerned from the outset with implementing fault tolerance. Protocols and system architectures that are not fault tolerant simply are not very useful in this setting
From day one, should think about fault tolerance system architectures and fault tolerant protocols.But he goes on to make another very strong claim (probably backed up too), that the only way to achieve fault tolerance is by building distributed systems (really, is it?!).
In a distributed system, the physical separation and isolation of processors linked by a communications net-work ensures that components fail independently.
This makes me think about systems that I design. How do I model and design systems such that I encourage process and communication boundaries, so I clearly understand the failure models. This is why it is so important for control plane and dataplane separation. It’s another way to wrap our minds around failure scenarios and how system will react to those failures.
Which model when?
Although we should study all the models, each model “idealizes some dimension of real systems” and it’s prudent of us to understand how each system attribute impacts the feasibility or cost — the two important benchmarks described earlier.