For the last couple days, I’ve been watching the distributed systems video lectures and reading the recommended papers that cover logical clocks. Even after making multiple passes on the material, the concepts just haven’t clicked: I cannot wrap my mind around why Lamport’s clocks satisfy only consistency — not strong consistency. But now I think I have a handle on it after sketching a few of my own process diagrams (below).
Before jumping into the examples, let’s first define strong consistency. We can categorize a system as strongly consistent if and only if, we can compare any two related event’s timestamps — and only the timestamps — and conclude that the two events are causally related. In other words, can we say “event A caused event B” just by inspecting their timestamps. In short, the timestamps must carry enough information to determine causality.
Example: Time Diagram of Distributed Execution
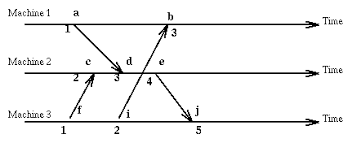
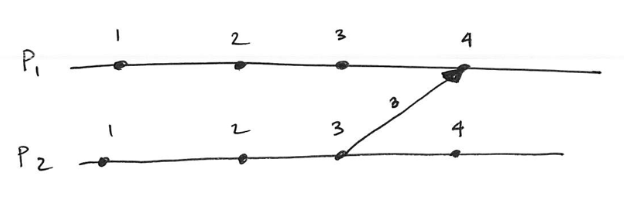
In my example below, I’ve limited the diagram to two process: P1 and P2.
P1 executes three of its own events (i.e. event 1, event 2, event 3) and receives an event (i.e. event 4) from P2. P2 executes 2 events (i.e. event 1, event 2), sends a message (i.e. event 3) to P1, then P4 executes a fourth and final event. To show the sending of a message, I’ve drawn an error connecting the two events, (P2, 3) to (P1, 4).
Logical clocks with an arrow from P2 to P1, showing causality between events (P2, 3) and (P1, 4)
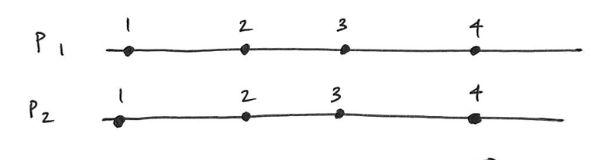
Cool. This diagram makes sense. It’s obvious from the arrow that (P2, 3) caused (P1, 4). But for the purposes of understanding why Lamport’s clocks are not strongly consistently, let’s remove the arrow from the diagram and see if we can reach the same conclusion of causality by inspecting only the timestamps.
Removing arrow that connects (P2, 3) to (P1, 4)
Next, let’s turn our attention to the timestamps themselves.
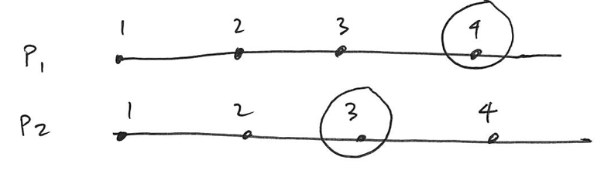
Can we in any way say that (P2, 3) caused (P4, 4)?
Just by comparing only the timestamps, what can we determine?
We can say that the event with the lower timestamp happened before the event with the higher timestamp. But that’s it: we cannot make any guarantees that event 3 caused event 4. So the timestamps in themselves do not carry sufficient information to determine causality.
If Lamport’s scalar clocks do not determine causality, what can we use instead? Vector clocks! I’ll cover these types of clocks in a separate, future blog post.
Cognitive biases (built-in patterns of thinking) and fallacies (errors in thoughts) creep into our every day lives, sometimes with us not even knowing it. For example, ever wonder why you work just a little harder, a little quicker, when you think someone is standing over your shoulder, watching you? This is known as the Hawthorne effect: people tend to change their behaviors when they know (or think) they are being watched.
Or how about situations when we are trying to solve a problem but reach for the same tool (i.e. using a hammer)? That might be the exposure effect, people preferring the same tools, processes — just because they are familiar.
Essentially, cognitive biases and fallacies trick us: they throw off our memory, perception, and rationality. So we must surface these blind spots to the forefront of our brains when designing and building distributed systems.
8 Fallacies
According to Schneider, there are 8 fallacies that bite distributed system designers. These fallacies stood the test of time. They were drafted over 25 years ago; designers have been building distributed systems for over 55 years. Despite advances in technology, these fallacies still remain true today.
1. The network is reliable
2. Latency is zero
3. Bandwidth is infinite
4. The network is secure
5. Topology doesn’t change
6. There is one administrator
7. Transport cost is zero
8. The network is homogeneous
Notice anything in common among these fallacies? They all tend to revolve around assumptions we make about the underlying communication, the network.
Network assumptions
I wouldn’t go as far and networks are fragile, but failures (e.g. hardware failure, power outages, faulty cable) happen on a daily basis. Sometimes, these failures are not observed by our users, their traffic being automatically routing towards an alternative — albeit sometimes a little slower — path; their dropped messages being resent thanks to the underlying (transport) communication protocol.
So, what does this mean for you, the system designer?
To overcome network hiccups, we should either “use a communication medium that supplies full reliable message” or employ the following messaging techniques: retry, acknowledge important messages, identify/ignore duplicates, reorder messages (or do not depend on message order), and very message integrity.
In addition to hardening our software, be prepared to thoroughly stress test your system. You’ll want to hamper network performance: drop messages, increase latency, congest the pipes. How well can your system tolerate these conditions? Can your system sustain these performance degradations? Or does your system fail in unexpected ways?
Main takeaway
In short, we should assume that the failure is unreliable and in response we should both employ techniques (e.g. retry messages) that harden our system as well as thoroughly test our systems/software under non-ideal conditions including device failures, congestion, increased latency.
References
1. Hunt Pragmatic Thinking and Learning: Refactor your wetware
2. https://fallacyinlogic.com/fallacy-vs-bias/
Schneider, F. B. (1993). What good are models and what models are good. Distributed Systems, 2, 17–26.
Paper Summary
In his seminal paper on models (as they apply to distributed systems), Schnedier describes the two conventional ways — experimental observation; modeling and analysis — we normally develop an intuition when studying a new domain. And for the remainder of the paper, he focuses on modeling and analysis, directing our attention towards two main attributes of distributed systems: process execution speeds; and message deliver delays. With these two attributes at the forefront of our minds we can build more fault-tolerant distributed systems.
Main Takeaways
The biggest “ah hah” moment for me was while reading “fault tolerance and distributed systems”. In this section, Schneider suggest that system architects should, from day one, focus their attention on fault-tolerance system architectures and fault-tolerant protocols, with an eye towards both feasibility and cost. To build fault tolerant systems, we should physically separate and isolate process, connect process by a communication network: doing so ensures component fails independently. That’s some seriously good intuition; I hope to incorporate those words of wisdom as I continue to learn about distributed and as I design my own distributed systems.
Great Quotes
In a distributed system, the physical separation and isolation of processors linked by a communications network ensures that components fail independently.”
One way to regard a model is as an interface definition—a set of assumptions that programmers can make about the behavior of system components. Programs are written to work correctly assuming the actual system behaves as prescribed bythe model. And, when system behavior is not consistent with the model, then no guarantees can be made
Notes
Defining Intuition
Distributed systems are hard to design and understand because we lack intuition for them
When unfamiliar with a domain, we can develop an intuition for it in one of two ways:
Experimental observation – build prototype and observe behavior. Although the behavior in various settings might not be fully understood, we can use the experience to build similar systems within similar settings
Modeling and analysis – we formulate a model and then analyze model using either mathematics or logic. If this model reflects reality, we now have a powerful tool (a model should also be both accurate and tractable)
Good Models
What is a model?
Schneider’s definition of a model is as follows: collection of attributes and a set of rules that govern how these attributes interact. Perhaps as important (if not important) is that there’s no single correct model for an object: there can be many. Choosing the right model depends on the questions we ask. But regardless of which specific model we choose, we should should choose a “good model”, one that is both accurate and tractable. Accurate in the sense it yields truth about the object; tractable in the sense that an analysis is possible.
What questions should we ask ourselves as we build distributed systems?
While modeling distribution systems, we should constantly ask ourselves two questions: what’s the feasibility (i.e. what types of problems does this solve); and cost (i.e. how expensive can the system be). The reason we ask ourselves this question is three-fold. First, we don’t want to try to solve an unsolvable problem “lurking beneath a system’s requirements”, wasting our time with design, implementation, and testing. Second, by taking the cost into consideration up front, we can skip choosing protocols that are too slow or too expensive. Finally, with these two attributes in mind, we can evaluate our solution, providing a “yardstick with which we can evaluate any solution that we devise.”
Why is studying algorithms and computational complexity insufficient for understanding distributed systems?
Although studying algorithms and computational complexity address two above questions (feasibility and cost), it ignores the subtle nuances of distributed systems. Algorithms and computational complexity assumes a single process, one that is sequential in nature. But distributed systems are different: multiple process communicating over channels. Thus, we need to extend our model to address the new concerns.
Coordination problem
I’m hoping I can update this blog post’s section because even after reading this section twice, I’m still a bit confused. First, I don’t understand the problem; second I don’t understand why said problem cannot be solved with a protocol.
Synchronous vs. Asynchronous
Why should we distinguish synchronous systems from asynchronous ones?
It’s useful to distinguish a synchronous system versus a asynchronous system. In the former, we make assumptions: speed of system is bounded. In the latter, we assume nothing — no assumptions about neither process execution nor message delivery delays.
Author makes a super strong argument in this section, saying that ALL systems are asynchronous, and that a protocol designed for a asynchronous system can be used in ANY distributed system. Big arguments. But is this true? He backs his claim up by saying that even processes that run in lockstep and message delivery is instantaneous still falls under the definition of a asynchronous system (as well as synchronous system).
Election Protocol
What can we achieve by viewing a system as asynchronous?
By no longer viewing a system as synchronous sand asynchronous instead, we can employ simpler or cheaper protocols. The author presents a new problem: N processes, each process Pi with a unique identifier uid(i). Create protocol so all processes learn leader.
According to the author, although we can solve the problem easily, the cost is steep: each node broadcasts its own uid.
So how can we solve the election protocol assuming a synchronous system?
We can define a τ to be both 1) greater than largest message delivery delay; and 2) largest difference observed at any instant by reading clocks. Basically, we use a constant and each process will wait until τ * uid(i) before broadcasting. In other words, the first process will broadcast and the messages will arrive at all other nodes before the second node attempts to sends a second broadcast.
Failure Models
When trying to understand failure models, we assign faulty behavior not by counting the occurrences, but by counting the number of components: processors and communication channels. With this component counting approach, we can say a system is t-fault tolerant, a system continuing to satisfy its specifications (i.e. keeps working) as long as no more than t of its components fault. This component driven concept is novel to me and forces me to think
Why is it important to correctly attribute failure?
The author states that we need to properly attribute failure. He provides an example on message loss. A message can be loss due to electrical issues on the channel (i.e. blame the channel) or maybe due to a buffer overflow on the receiver (i.e. blame the receiver). And since replication is the only way to tolerate faulty components (I’d like to learn more about this particular claim), we need to correctly attribute fault to the components because “incorrect attribution leads to an inaccurate disattributed system model; erroneous conclusions about system architecture are sure to follow”.
What are some of the various models?
He then talks about the various failure models including failstop, crash, crash+link, and so on. Among these failures, the lease disruptive is “failstop” since no erroneous actions are ever taken place.
Although it may not be possible to distinguish between a process that has crashed versus a process that’s running very very slowly, the implications and distinctions are important. When a process has crashed, other processes can assume the role and responsibility, moving forward. But, if the system respond slowly and if the other processes assume the slow process’s responsibilities, we are screwed: the state of the world loses its consistency.
When building failure models, how deep in the stack should we go? Should we go as far as handling failures in the ALU of a processor!? Why or why not?
We don’t want to consider a CPU’s ALU failing: it’s too expensive for us to solve (which relates ot the two attributes above, feasibility and cost); in addition, it’s a matter of abstractions:
A good model encourages suppression of irrelevant details”.
Fault Tolerance and distributed systems
As the size of a distributed system increases, so does the number of its components and, therefore, so does the probability that some component will fail. Thus, designers of distributed systems must be concerned from the outset with implementing fault tolerance. Protocols and system architectures that are not fault tolerant simply are not very useful in this setting
From day one, should think about fault tolerance system architectures and fault tolerant protocols.But he goes on to make another very strong claim (probably backed up too), that the only way to achieve fault tolerance is by building distributed systems (really, is it?!).
In a distributed system, the physical separation and isolation of processors linked by a communications net-work ensures that components fail independently.
This makes me think about systems that I design. How do I model and design systems such that I encourage process and communication boundaries, so I clearly understand the failure models. This is why it is so important for control plane and dataplane separation. It’s another way to wrap our minds around failure scenarios and how system will react to those failures.
Which model when?
Although we should study all the models, each model “idealizes some dimension of real systems” and it’s prudent of us to understand how each system attribute impacts the feasibility or cost — the two important benchmarks described earlier.
Distributed systems are everywhere: social media, internet of things, single server systems — all part of larger, distributed systems. But how do you define a distributed system? A distributed system is, according to Leslie Lamport (father of distributed computing), a system in which failure of some component (or node) impacts the larger system, rendering the whole system either unstable or unusable.
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable – Leslie Lamport
To better understand distributed systems, we can model their behaviors using nodes and messages. Nodes send messages to one another, over unreliable communication links in a 1:1 or 1:N fashion. Because of the assumed flaky communication, messages may never arrive due to node failure. This simple model of nodes and messages, however, does not take the nodes capturing events into consideration; for this, our model must be extended into a slightly more complex one, introducing the concept of “state” being stored at each node.
When evaluating distributed system, we can and should leverage models. Without them, we’d have to rely on building prototypes and running experiments to prove our system; this approach is untenable due to issues such as lack of resources or due to the scale of the system, which may require hundreds of thousands of nodes. When selecting a model, we want ensure that it can accurately represent the problem and be used to analyze the solution. In other words, the model should hold two qualities: accurate and tractable.
Using Models. Source: Georgia Tech
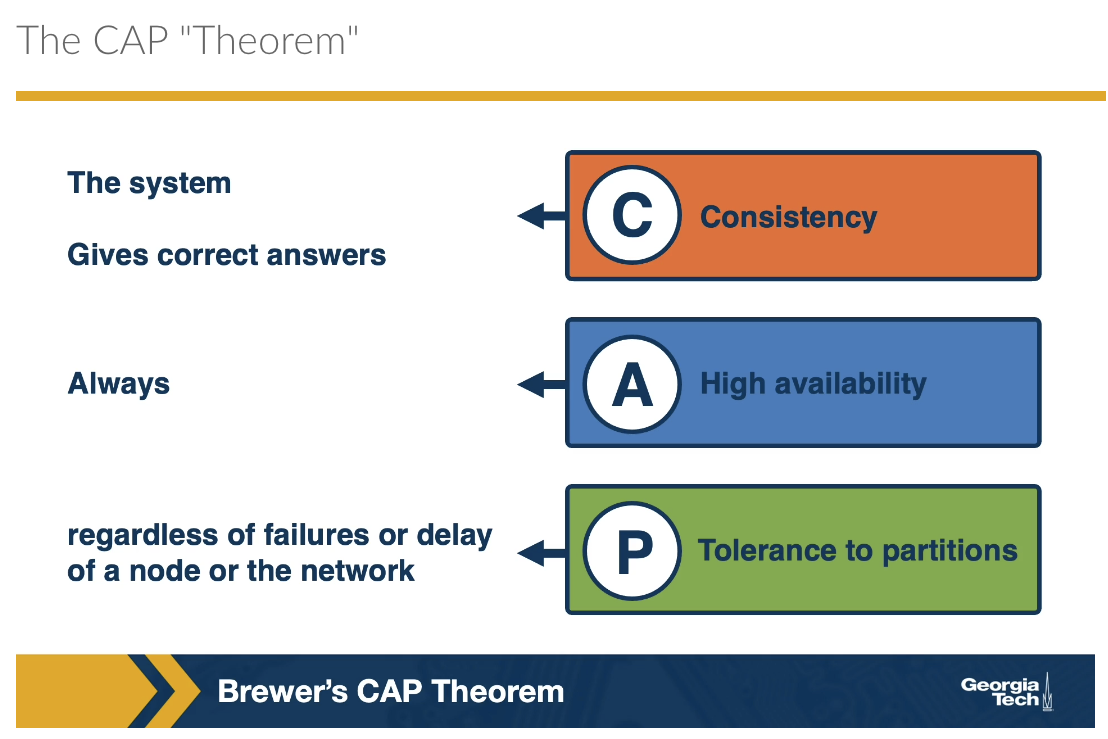
Building distributed systems can be difficult for three reasons: asynchrony, failures, consistency. Will a system assume messages are sent immediately within a fixed amount of time? Or will it be asynchronous, potentially losing messages? How will the system handle the different types of failures: total, grey, byzantine (cannot tell, misbehaving) ? How will the system remain consistent if we introduce caching or replication? All of these things are part of the larger 8 fallacies of distributed computing systems.
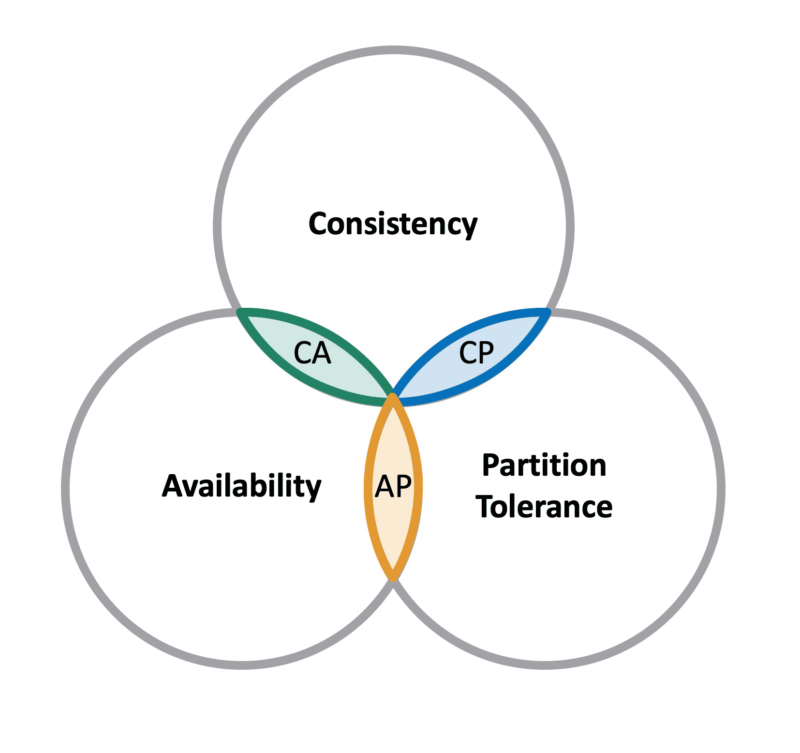
CAP Theorem. Source: Georgia Tech
Ultimately, when it comes to building reliable and robust systems, we cannot have our cake and eat it too. Choose 2 out of the 3 properties: consistency, availability, partitioning. This tradeoff is known as CAP theorem (which has not been proven and is only a theorey). If you want availability and partitioning (e.g. cassandra, dynamodb), then you sacrifice consistency; similarly, if you want consistency and partitioning (e.g. MySQL, Megastore), you sacrifice availability.
Yes! I’m finally registered for the distributed computing course. This course is hot off the press! It’s spanking brand new to the OMSCS program and offered for the first time this (Spring 2021) term. I’ve been eagerly waiting over two years for a course centering around distributed systems, combining both theory and practice.
The course is taught by professor Ada, who also teaches Graduate Introduction to Operating Systems, which received the highest accolades from previous students who wrote reviews over at OMSCentral review. I bet this class will raise the bar, intellectually challenging and stimulating our minds. According to the course’s syllabus, we’ll bridge both theory and practice by delivering 5 programming projects, the assignments based on University of Washington’s Distributed Systems Labs that are published in this repository: https://github.com/emichael/dslabs . The projects will require us students to:
Build a simple ping/pong protocol
Implement an exactly-once RPC protocol (parts of lab 1 reused)
Design and implement a primary-backup protocol to teach fault-tolerance
Implement the famous Paxos
Implement a key value stored using Paxos and implement a two-phased commit protocol
I’m particularly interested in the last two projects: paxos and two-phased commit protocol. I had first read the original Paxos paper about four years ago, when I first joined Amazon, but never implemented Paxos myself; and I only recently learned about two-phased commit protocols a month or two ago when taking advanced operating systems last semester and it’s a topic I want to understand more deeply.
I’m hoping that during (and after I take this class) I’ll be able to apply the principles of distributed computing to effectively analyze the reliability of existing and new services powering Amazon Web Services. Moreover, I’ll incorporate the lessons learned into my mental model and refer to them as I both design and build new systems
First things first: I’m grateful for surviving this difficult, weird and straight-up dystopian year. 2020 was the absolute worst; although the year will permanently leave its mark in our memories, we’re all ready to leave it behind, ready to move on. Who could have, apart from maybe Bill Gates during during 2014 Ted Talk, predicted a global pandemic forcing all of humanity into stay-at-home lockdowns? To add fuel to the fire, forest fires broke out in the Pacific Northwest, smoke blanketing the sky, rendering the air unbreathable, tightening the lockdown’s grip and exacerbating the already untenable cabin fever.
The lockdowns and the constant bombardment of never-up-lifting coronavirus news ate away my health: physically, emotionally, mentally. I miss playing tennis with friends; I miss striking up conversations with both friends and strangers — I miss pre-pandemic life. But above all else, I miss not fearing that the person breathing next to me will sneeze and spread the virus. That’s the thing with COVID-19: even when it’s not on your mind, it’s on your mind. It’s always just beneath the surface, swimming around in your subconscious. Is it normal to dream nightmares where you are sitting on a public bus and the only one wearing a masks?
Notwithstanding the global pandemic, 2020 blessed me in many ways. Below, I’ll share some life updates — the good and the bad — that tend to revolve around two north stars (who says you can’t more than one north star): family; and personal development. Then, I’ll close the post out with what’s lined up for 2021.
Looking Back
Family
On Parenting
“(Parenting) is a young person’s game – Mom”
After becoming a parent, I stopped snapping harsh judgements of other parents for their shortcomings. Because surprise surprise: parenting is HARD. These days, whenever I witness some toddler throwing a tantrum because their cup happens to be colored blue, my heart goes out to their parents. Parenting has taught me to hold more sympathy, more understanding, more patience, towards all parents, including my own. Because the old adage rings true: “We never know the love of a parent till we become parents ourselves”.
Jess and Elliott smiling for the camera
The way Jess raises Elliott motivates me to become a better father. Watching Jess mother is like watching Picasso show up every day and paint his canvas — it’s an honor. And really beautiful. Jess speaks so softly to Elliott, never losing her patience, her tone always somehow miraculously combined with light-hardheartedness, seriousness, curiosity, warmth, humanity, and above all else: love. Without skipping a beat, Jess will dive face first into a ball pit, crawl around on all fours, and proceed to chase Elliott. She’ll neatly decorate Elliott’s plate of food every day — every meal. She’ll fly up the stairs as soon as Elliott makes a peep in the middle of the night. All these moments … it’s all art unfolding in front of my very eyes. With Jess leading the way, I’m confident that Elliott will grow into a well adjusted human being.
I’m still the same person
Yes — I’m a dad now. My life looks radically different. But fundamentally I remain the same person (apart from the new salt and pepper hairstyle). Before fatherhood, I used to think that once I stepped into my new role, the very core of who I was would somehow shift, that all my previous dreams and desires and aspirations would somehow get tossed the window. Because you hear that sort of story all the time, right? From books, from friends, from everyone. Maybe the cessation of one’s desires does really happen for some parents: but not me. Don’t get me wrong, being a dad is one of the proudest titles I hold. There’s just still so much I want to accomplish in my life. And I’m lucky that I’m in good company; they get to join my journey and I get to join theirs.
Unexpected moments of happiness
Elliott breathes joy into my life and constantly puts a much needed smile on my face: every time she smiles; every time she lays a wet one on either Metric or Mushroom. Sometimes, she acts cute on purpose: she’ll slowly tilt her her head to the side and send you a smirk. She knows how to tug at my heart. But most of the times, she’s just doing nothing, just being herself, and I catch love feelings washing over me.
Elliott kissing her “deer” (it’s a llama, but she loves deer…so its a deer)
Fur daughters
Before becoming a human father, I was first a fur father to Metric and Mushroom. I continue to appreciate them, for guarding Elliott at night, for licking up all of Elliott’s food that she splatters on the floor, and for teaching me more about humanity than any human.
Two silly dogs occupying the front and passenger seats in the car
House move
We packed up all of our belongings and moved out of our rental house located in North Seattle, relocating to the suburbs of Renton. Even though Jess and I will always miss North Seattle — Cloud City Cafe, Maple Leaf Park, Magnuson Park, Grateful Bread — moving to Renton, in retrospect, was the right decision. We simply had outgrew the previous house; Elliott was constantly crawling back and forth, from one corner of the living room to the next, not much square footage for a baby locked inside in the midst of a pandemic. And for that reason alone, we traded our city lives for a home that offers some more breathing room.
U-haul filled to the brim
Personal Development
Graduate School
I completed the second year of graduate school and it continues to serve its purpose: deepening my understanding of computer science. Interestingly though, my acquisition of new knowledge does not always reflect in the grades that I receive. For example, I bled sweat and tears while taking “Compilers: Theory and Practice” course, burning the midnight oil, pouring roughly 30 additional hours per week (on top of work) when I normally clock 10-15 hours for every other course. Despite all the additional time I threw into the course, I received the lowest grade I ever received in graduate school. But receiving a lower no longer irks me. Because graduate school is not about earning high marks. It’s about changing the way you think.
Collaborating with other students
Earning a masters can feel lonely. So last semester, Fall 2020, I stayed active on the course forum, replying to other student’s questions as well posting new threads to spark conversation. I would share links to relevant blog posts. Also, I started something called “war room” study sessions, where a handful of us students would hop on a Zoom call together and study together for the exams; I’d share my screen and together, we would tease out the right answers. This student collaboration was the highlight of the course: connecting with other students wards off loneliness. Wanting to stay connected with other students once the course ended, I started a private mailing list for other graduate students who are also specializing in computing systems at Georgia Tech. To date, over 50 students subscribed and the list continues growing.
Career as a software engineer
I love my job as a software engineer. Every day, I make magic happen behind the scenes, continuing to breathe life into the Amazon (Web Services) Cloud. But this past year, work sucked the soul out of me. First, several on call rotations melted my brain into mashed potatoes. I turned into a drooling zombie after being alarmed out of bed at 3:00 AM and after staring at the computer screens until 10:00pm — three nights in a row. Second, workplace politics threw a wrench into the game and for the first time in my career, I was viewed as someone who no longer wanted to advance their career: all because I turned down a senior engineer’s offer to lead a particular project; to make matters worst, I used to consider that senior engineer as someone in my corner, someone who advocated for my career. The entire experience left a poor taste in my mouth and I still haven’t fully recovered from the sense of betrayal.
Getting in touch with my feelings
Separating self-worth from work
“But there was a chance to chart your own course”
– Dolores from Westworld. Season 3
For most of my career, I’d measure my self-worth by the quality of the code or prose that I write. I often would only publish my work once I considered it to be “perfect”. Not anymore. I no longer buy into perfectionism because perfect does not exist. Perfection is subjective. I now focus on “shipping it”, delivering work at an accelerated rate. Ironically, my work quality has not degraded; in fact, I would say has improved in some aspects since I’m now producing, practicing and flexing my skills more than before.
Getting lost in one’s work (aka “blackholes”)
“I see your brain”
– Jess Boyd
I cannot count the number of times when I’m stuck solving a difficult problem, gluing myself to the keyboard, spinning my wheels, never breaking focus for hours and hours: Jess calls these my “blackholes”. Sometimes, intense focus pays off. Sometimes I arrive at the answer, all the self-induced tension resolving. But most of the times I fail to move forward, fail to make even an inch of progress, stuck in the same spot. Only after stepping back from these difficulty problems do I realize that I should’ve distanced myself earlier, allowing some time — even 5 minutes — to pass in order to see the problem with fresh eyes.
Identifying as an introvert
In December, I had picked up a book while walking the aisles at Barnes and Noble, the book titled “Networking for people who hate networking”. The book ships with a friendly, short 10-question quiz that helps you assess where you land on the spectrum of introversion. After answering the quiz and tallying up the points, I discovered that I’m highly introverted! Learning about introverted tendencies has helped me explain — not only to others, but to myself — some of my quirks, including the never-ending craving for alone time. Being introverted helps explain both why large social events drain my energy dry and why I wake up at 04:00 AM: no wife, no kids, no dogs — just me time. So I’m thankful for stumbling on the book and now I feel less guilty about my own introverted tendencies.
Marketing oneself
On a daily basis, I fear coming off as someone who excessively boasts, someone who reeks of arrogance. Not wanting to be perceived this way, I usually stop myself from sharing my original content (e.g. writing, music, videos); up until recently, I’d cringe when hearing the words “marketing oneself”. But my adverse reaction to marketing has been replaced with a shift in perspective: I now define marketing as solving other people’s problems and adding value to their lives. This new mind-set, combined with separating my work from myself, enables me to more freely share my thoughts.
Saying goodbye to Trump
I burst into tears of joy while listening to the radio, when NPR broke the good news that Trump lost the 2020 presidential election. Trump being out of the picture restores some of my faith in humanity (despite the fact that an overwhelming number of Americans voted for him). Of course, Trump will somehow continue stealing the spotlight; like cancer, he’ll reappear and crawl his way back into politics over the next few years. Nonetheless, he’s out of the presidential picture for at least the next four years.
Leaning forward
Good bye New Year’s resolution. Say hello to habits
New years resolutions can be useful, but more often than not, most people abandon them within a few weeks or months. I’m no exception. So instead of penciling in some lofty goals for the year, I’m directing my energy towards cultivating healthy habits: existing habits I want to retain; new habits I want to develop. Because I believe that how we live everyday is how we live for the rest of our lives.
Masters in computer science
In fall 2021, I’ll graduate with a masters in computer science. Between now and then, I’ll need to complete three more courses: high performance computing; distributed computing; graduate algorithms. The main motivation for graduate school has been — and will continue to be — stretching my brain and forcing myself to see problems through a different lens. Because when all you have is a hammer, everything looks like a nail.
Communication skills
Every morning I sit down and write. And I write. And I write. I’ve committed myself to the craft for three reasons. First, writing helps me untangle the web of thoughts constantly buzzing around in my head; it’s easy to trick ourselves into believing we fully grasp a topic … that is until our incomprehensible prose exposes our lack of understanding. Second, writing, I think, is the key ingredient that distinguishes good engineers from great engineers. Some of the best engineers I worked with don’t just “know more”; they leverage their writing skills to influence the roadmap. Third, most simply, I enjoy the never ending pursuit of becoming a great writer. And someday soon, I’ll have the chops necessary to write my own memoir.
Human Connections
Cultivate marriage
Before having children, I never understood how children coming into the picture would cause parents to drift apart. I get it now. Unless you carve out time for one another, unless you deliberately nurture your relationship, raising children fills up the entire day. So Jess and I are tossing ideas out in the air, looking for creative ways to turn into each other. Some ideas we toyed with so far include: starting a book club, writing together, recording song covers together. Really, I don’t think the activity itself matters — it’s just spending some quality time together.
Stay connected with friends and family
Family zoom call
Earlier this year in the midst of the pandemic, I text messaged some old friends and after some back and forth chit-chat, I realized that I both miss and crave human connection. Because a warm, fuzzy feeling warmed my body after they shared updates around their family, their work, their world; me staying off of social media — Facebook and Instagram — for close to 5 years doesn’t help either. I essentially miss their moments, big and small. Wanting to stay more connected to friends and family, I often question should rejoin social networking. Probably not. From my perspective, the positive benefits are outweighed by the negative ones; the mindless thumb scrolling and lack of privacy are both the primary reasons I severed myself from these closed-in platforms. So, instead of plugging back in into social media, Ill continue with my own method for keeping tabs on people’s lives: a simple excel sheet.
Closing
Elon Musk offered some brilliant career advice that can be summed up into a single sentence: “If you’re not progressing, you’re regressing; so, keep moving forward.” But for 2021, I’d be completely content with regressing back to the way society looked prior to the pandemic. So, come on 2021, let’s do this. I hope — I pray — that the pandemic ends this year and that we all return back to some sense of normalcy.
Ira was not born an amazing story teller. Early on in his career (in his early 20s), he realized a gap existed between his current and future skills. And when asked what kept him moving forward, Ira Glass responded:
Just over the horizon
I feel like I could … imagine a thing … which didn’t exist, that was so much better than what I was doing. And … and it’s like it was just over the horizon. And … I didn’t have any other goals. Like, I really thought like I can’t do this now, and I’m not sure how you get to the point where you can do it. Um…and I think, I’m stubborn. And I act on faith.
The above quote deeply resonates with me, especially when it comes to my current writing abilities. I know — I feel — that I can produce good writing: cohesive; coherent; and beautiful. And like Ira, my writing skill gap lives just over the horizon: I just need to continue practicing, continue learning, and ultimately, continue producing large volumes of work. All that hard work, plus the two most essential ingredients: faith and luck.
No sign for talent
And when I hear what I was doing, I can see why. It wasn’t good. Years ago, one of our producers dug up one of those pieces. Because I said, “Oh, I did a piece on that, when I was 26”. And she just dug it up and she said “This is amazing. There was no sign that you have any talent for radio. There was no sign that you will ever turn into something good. At all.” And when I hear it, I hear the same thing: You can’t tell.
So just keep dancing with your craft and have a little faith. Not just in yourself, but in the universe. Because the time will come when luck will pay you a visit.
Like almost everyone else working remotely due to the COVID-19 global pandemic, I struggled with adjusting to the work from home situation, more than I could’ve possibly anticipated. I found difficulty in my daily routines suddenly disappearing; my deeply ingrained habits vanished out of thin air: no more commuting to the office; no more breathing in the fresh, cold air during my walks to the bus; no more swinging by the local gym for a short 30 minute mental and emotional exercise; and no more leaving the house. On top of wrestling with the change in routines, the constant at home interruptions kicked me in the butt:
No way to shut people out; no way shut myself in.
I cannot begin to count the number of moments where I reached a deep state of focus, only to be interrupted, either by my adorable daughter or by one of my two dogs or by my beautiful wife. Although these interruptions knocked me off my balance, I’ve adapted to them and, on some level, grown to appreciate them. Without my family unit, I would be just another lone wolf. And I’ll take interruptions all day long over being lonely.
Look at the above example, the four sentences. Now, take each of those sentences and imagine you poll an audience of 100 people, asking them the following question: “Does the author want you [the reader] to give Fred either a thumbs up or thumbs up?” How do you think the audience answer? More than likely, the audience answers as follows:
a) mostly thumbs down for Fred
b) mostly thumbs down up for Fred
c) slightly more thumbs down for Fred
d) slightly more thumbs up for Fred
What the heck is going on here?
Why? Why when we present the audience with semantically equivalent sentences — but with the order of the words re-positioned — do their perceptions of Fred swing in completely opposite directions?
Three dimensions
The answer lies within how the author structures the sentences, how the author arranges (and rearranges) the words to leverage the reader’s expectations, using the following three dimensions: stress position, main clause, length (because each of the above example sentences run the same length, we won’t discuss this dimension, but just bear in mind that the longer a clause, the more the readers emphasize it). With these dimensions in mind, let’s deconstruct the first two examples. But first, let’s define the stress position.
Analysis of example (a) and example (b)
The stress position (which emphasizes certain words) sits immediately to the left of any of the three punctuation marks that denote the end of a semantic closure: a period, a semicolon; a colon. Because our examples only house a period, so let’s focus our attention there, starting with the first example: “Although Fred’s a nice guy, he beats his dog.” In this example, “he beats his dog” is the main clause and occupies the stress position. For these two reasons, the audience will generally (not always) emphasize Fred beating his dog and as a result, they give him a thumbs down. Next, moving on to the second example: “Although Fred beats his dog, he is a nice guy.” With this sentence, the author subordinated “Fred beats his dog”, reducing the sentence’s importance; “he is a nice guy” now holds the stress position and lives as the main clause. Therefore, Fred gets a thumbs up.
Leverage reader’s expectations
You can emphasize certain words within your sentences by leveraging reader’s expectations. Take advantage of the inherent structure within the English language, by applying the three simple techniques: place important (what you consider important) words in the stress position; make them the main clause; and lengthen the clause for additional for additional emphasis.
Like many other aspiring authors, I’m always sharpening my writing skills, dozens of writing books (including one of my favorites: On Writing by Stephen King) lined up on my bookshelf. Almost all these books share the same stance when comparing the active and passive voices. They strongly prefer the active voice over the passive voice. Always. Black and white. No grey area. Their justification? The books claim the passive voice sound weak when compared to the (strong) active voice.
Sorry — that’s baloney.
Some situations call for passive voice. What I’m saying is this: sometimes passive voice outperforms the active voice. Voice selection depends on whose story you want to tell. Here’s a simple example: Jack loves Jill. In this example, Jack (the subject) loves (the action) Jill (the object); as readers, we expect that the following sentences revolve around the subject, Jack. But, what if the author really wanted to focus the story on Jill, instead? Simple: change the voice from active to passive. Switch the subject from Jack to Jill and change the tense: Jill is loved by Jack. Jill (subject) is loved (the action) by Jack (agent).
How about taking a look at an example of changing the voice (from passive to active) adds confusion to the mix. In the two examples below, the top is written in passive, the bottom its active voice equivalent.
Passive voice. Source: Gopen (2020) video companion PDF
Active voice. Source: Gopen (2020) video companion PDF
Does the conversion improve the movement, improve the quality, improvement the passage as a whole? No! If anything, the new passage confuses us readers! We are now distracted, our attention pointing towards the scientists, when we should be focusing on the science.