Blog
-
There are no shortcuts to becoming a great writer. As Stephen King says, great writers need to read a lot and write a lot. But that’s not enough. Nope. I’d argue you need to take writing one step further: imitate good writing. Imitating great tennis players When I was a young boy, about 8 or…

-
One silver lining of COVID-19 is that I’m working remotely from home and despite the constant interruptions, I’ve grown to appreciate situation. I’m afforded experiences not normally available to me when working physically in the office. Among which is seeing my daughter grow up, right before my eyes. Every day, I catch these fleeting moments,…

-
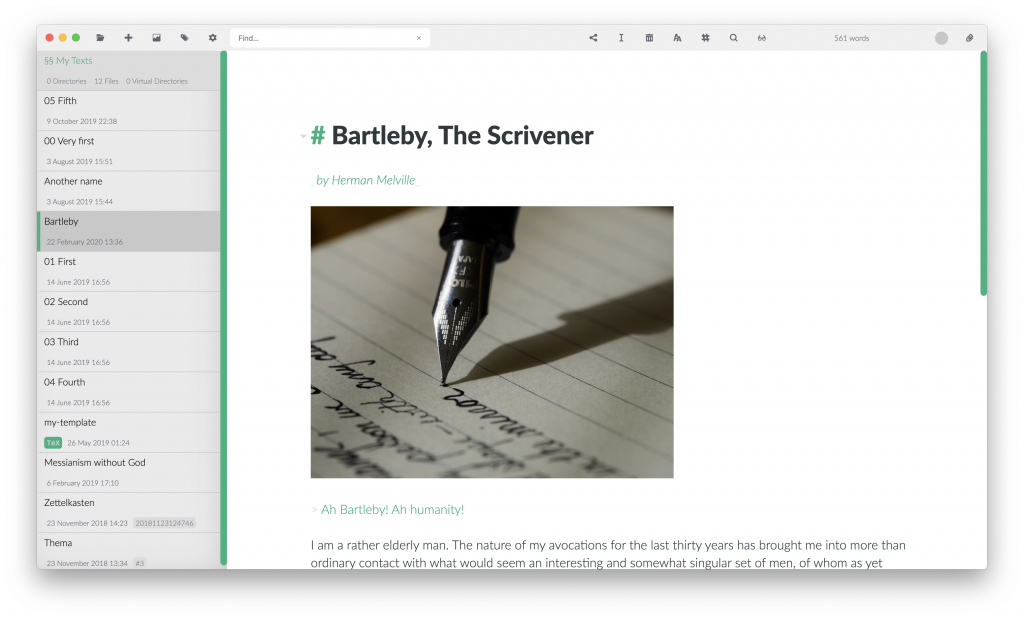
I serendipitously stumbled on another Zettelkasten desktop application called Zettlr. Perusing the online forum over at Zettelkasten.de, I had noticed that at least three of four members repping the app in their signatures. Naturally, I was curious so I followed the scent on the trail and loaded up the Zettlr website in my browser. After…
-
I’m obsessed with personal information management (PIM) and as I learn more about the discipline, one concept continues to repeatedly crop up: Zettelkasten. I first learned about Zettelkasten after reading one of my favorite books “How to take smart notes”, and since then, I’m sold on the idea and continue to tweak my digital workflow…

-
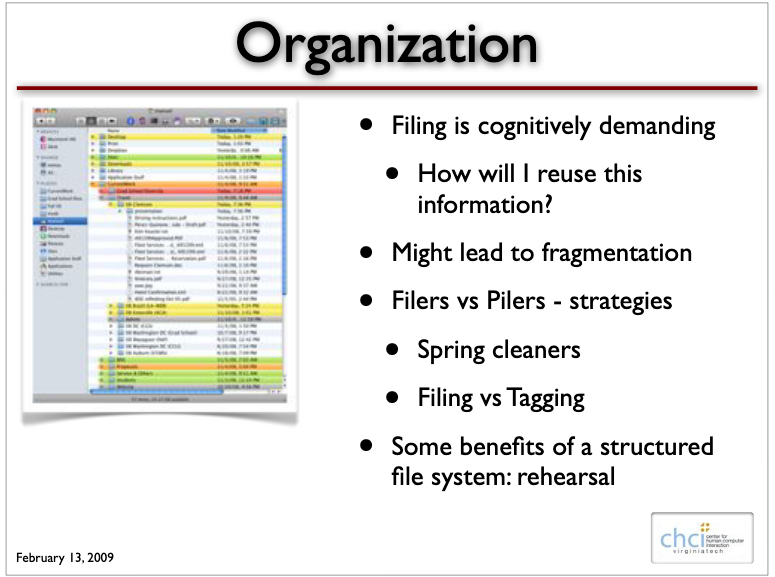
Generally speaking, there two ways people store their digital assets. Some file their digital assets— PDF documents, images, videos, bookmarks and so on — into neat, hierarchical structures. In the other camp are people who leverage tagging, assigning one or more key words to their files. When retrieving assets, these people tend to leverage their…
-
Why publish my studying techniques? This semester, I manage to pull off an A not only for the midterm and final exams, but for the class as a whole. My intention of revealing my grade is not to boast (that’s poor taste), but to give some credibility to the techniques and strategies below, techniques and…
-
Three passes World class writers sit down and pour out beautiful prose in a single sitting, right? That’s the image I image I held in mind for many years and this belief is not only far from the truth but this belief crippled me as a writer. I would sit down to type and proceed…

-
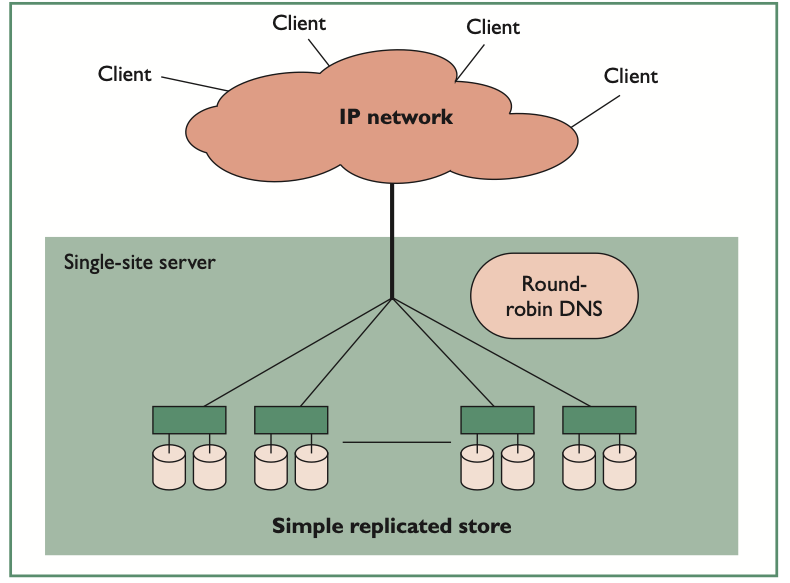
Introduction We’ll address some questions like “how to program big data systems” and how to “store and disseminate content on the web in scalable manners” Quiz: Giant Scale Services Basically almost every service is backed by “Giant Scale” services Tablet Introduction This lesson covers three issues: system issues in giant scale services, programming models for…
-
Click here to download “Advanced OS refresher course – summary and study guide” I compiled my various blog posts from the advanced operating systems refresher course and bundled them together into a nicely packed e-book. So, if you are about to enroll in Georgia Tech’s advanced operating system course (AOS) and want to step through…

-
Students in the Georgia Tech program collaborate with one another — and collaborate with professors and teacher assistants — through a platform called Piazza. But at the end of the semester, this forum shuts off to read only mode, meaning we all lose connection with one another. Because of this, I recently created an e-mail…
