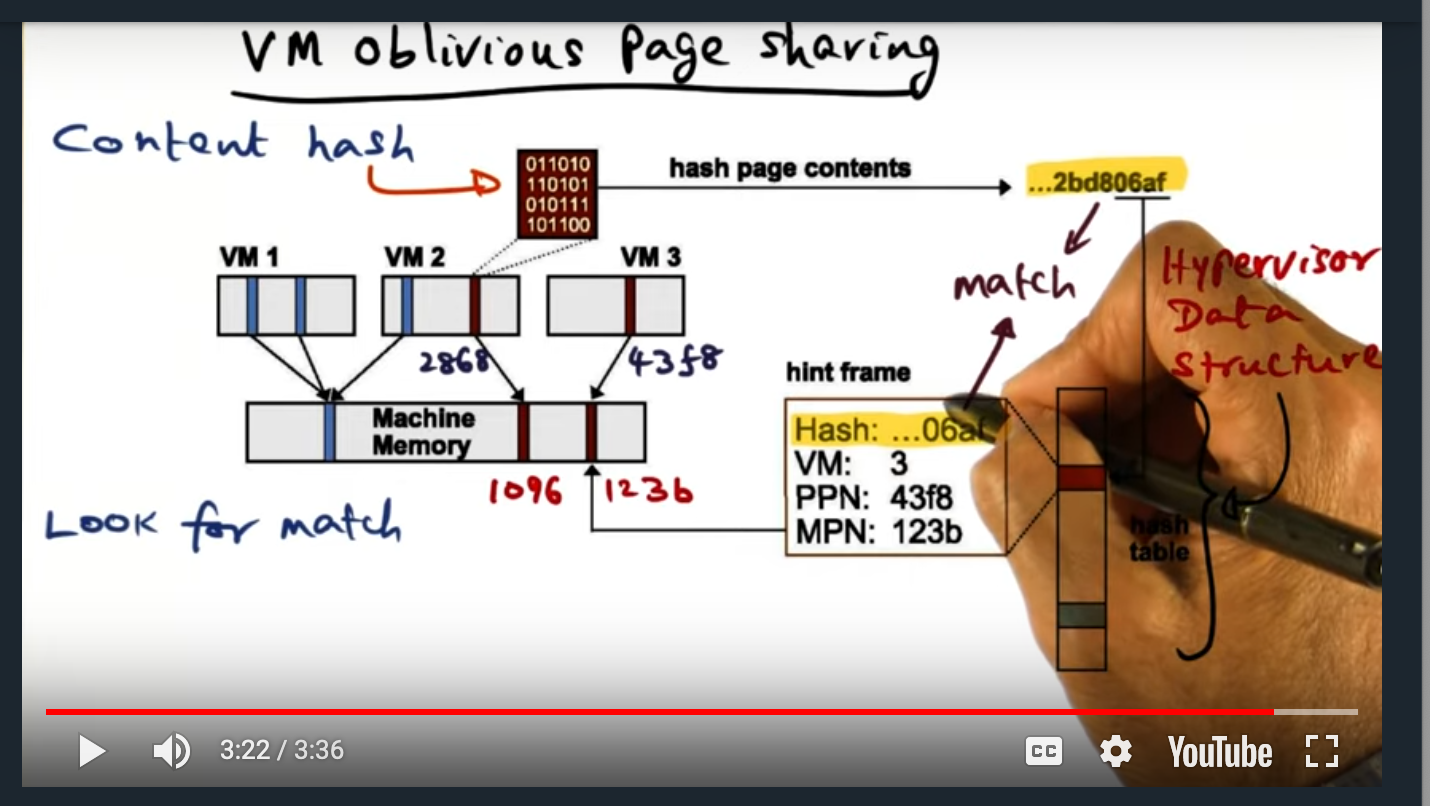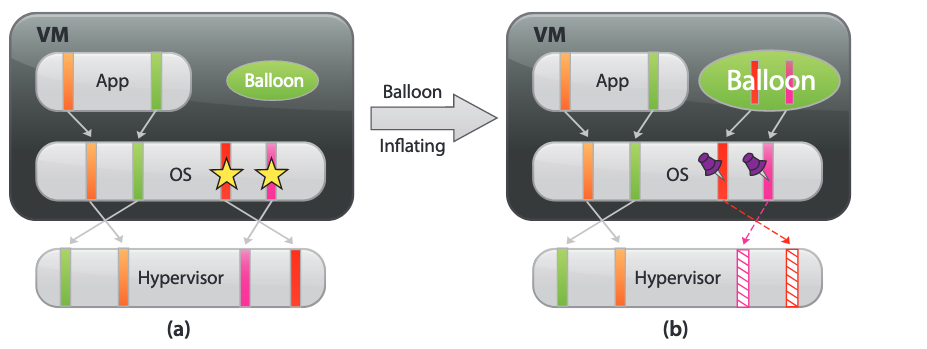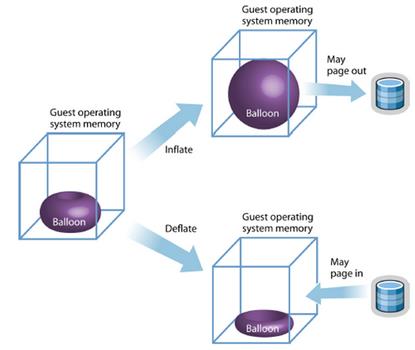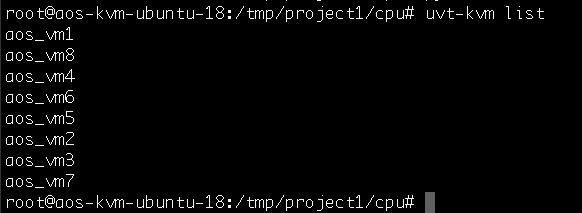
I’m getting ready to begin developing a memory coordinator for project 1 but before I write a single line of (C) code, I want to run the provided test cases and read the output of the tests so that a get a better grip of the memory coordinator’s actual objective. I’ll refer back to these test cases throughout the development process to gauge whether or not I’m off trail or whether I’m heading in the right direction.
Based off of the below test cases, their output, and their expected outcome, I think I should target balancing the unused memory amount. That being said, I now have a new set of questions beyond the ones I first jotted down prior to starting the project:
- What specific function calls do I need to make to increase/decrease memory?
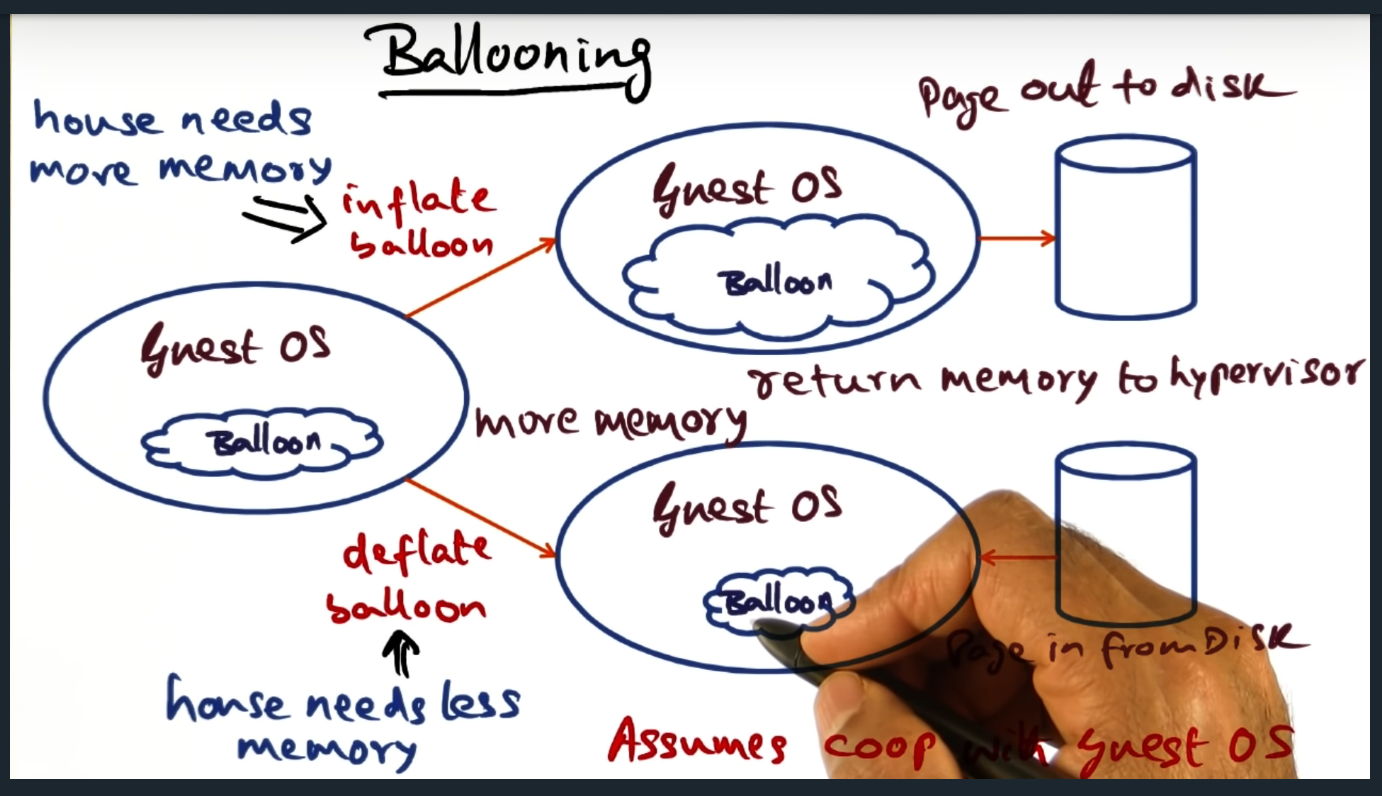
- Will I need to directly inflate/deflate the balloon driver?
- Does the coordinator need to inflate/deflate the balloon driver across every guest operating system (i.e. domain) or just ones that are underutilized?
Test 1
The first stage
1. The first virtual machine consumes memory gradually, while others stay inactive.
2. All virtual machines start from 512MB.
3. Expected outcome: The first virtual machine gains more and more memory, and others give out some.The second stage
1. The first virtual machine start to free the memory gradually, while others stay inactive.
2. Expected outcome: The first virtual machine gives out memory resource to host, and up to policy others may or may not gain memory.
-------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [257.21484375] Memory (VM: aos_vm4) Actual [512.0], Unused: [343.125] Memory (VM: aos_vm2) Actual [512.0], Unused: [328.36328125] Memory (VM: aos_vm3) Actual [512.0], Unused: [324.55859375] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [246.1953125] Memory (VM: aos_vm4) Actual [512.0], Unused: [343.12890625] Memory (VM: aos_vm2) Actual [512.0], Unused: [328.2421875] Memory (VM: aos_vm3) Actual [512.0], Unused: [325.12109375] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [235.17578125] Memory (VM: aos_vm4) Actual [512.0], Unused: [343.12890625] Memory (VM: aos_vm2) Actual [512.0], Unused: [328.2421875] Memory (VM: aos_vm3) Actual [512.0], Unused: [325.15234375] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [224.15625] Memory (VM: aos_vm4) Actual [512.0], Unused: [343.12890625] Memory (VM: aos_vm2) Actual [512.0], Unused: [328.2421875] Memory (VM: aos_vm3) Actual [512.0], Unused: [325.15234375] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [212.7734375] Memory (VM: aos_vm4) Actual [512.0], Unused: [343.12109375] Memory (VM: aos_vm2) Actual [512.0], Unused: [328.2421875] Memory (VM: aos_vm3) Actual [512.0], Unused: [325.15234375] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [201.75390625] Memory (VM: aos_vm4) Actual [512.0], Unused: [343.12109375] Memory (VM: aos_vm2) Actual [512.0], Unused: [328.2421875] Memory (VM: aos_vm3) Actual [512.0], Unused: [325.15234375] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [190.61328125] Memory (VM: aos_vm4) Actual [512.0], Unused: [343.12109375] Memory (VM: aos_vm2) Actual [512.0], Unused: [328.2421875] Memory (VM: aos_vm3) Actual [512.0], Unused: [325.15234375] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [179.3515625] Memory (VM: aos_vm4) Actual [512.0], Unused: [343.12109375] Memory (VM: aos_vm2) Actual [512.0], Unused: [328.2421875] Memory (VM: aos_vm3) Actual [512.0], Unused: [325.15234375] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [168.33203125] Memory (VM: aos_vm4) Actual [512.0], Unused: [343.12109375] Memory (VM: aos_vm2) Actual [512.0], Unused: [328.2421875] Memory (VM: aos_vm3) Actual [512.0], Unused: [325.15234375] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [157.3125] Memory (VM: aos_vm4) Actual [512.0], Unused: [343.12109375] Memory (VM: aos_vm2) Actual [512.0], Unused: [328.2421875] Memory (VM: aos_vm3) Actual [512.0], Unused: [325.15234375]
Test 2
The first stage
1. All virtual machines consume memory gradually.
2. All virtual machines start from 512MB
3. Expected outcome: all virtual machines gain more and more memory. At the end each virtual machine should have similar memory balloon size.The second stage
1. All virtual machines free memory gradually.
2. Expected outcome: all virtual machines give memory resources to host.
-------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [71.7578125] Memory (VM: aos_vm4) Actual [512.0], Unused: [76.765625] Memory (VM: aos_vm2) Actual [512.0], Unused: [73.5625] Memory (VM: aos_vm3) Actual [512.0], Unused: [74.09765625] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [76.50390625] Memory (VM: aos_vm4) Actual [512.0], Unused: [65.98828125] Memory (VM: aos_vm2) Actual [512.0], Unused: [62.69921875] Memory (VM: aos_vm3) Actual [512.0], Unused: [63.078125] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [65.484375] Memory (VM: aos_vm4) Actual [512.0], Unused: [66.4453125] Memory (VM: aos_vm2) Actual [512.0], Unused: [69.015625] Memory (VM: aos_vm3) Actual [512.0], Unused: [66.5390625] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [65.3984375] Memory (VM: aos_vm4) Actual [512.0], Unused: [63.19921875] Memory (VM: aos_vm2) Actual [512.0], Unused: [68.2109375] Memory (VM: aos_vm3) Actual [512.0], Unused: [66.71875] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [347.85546875] Memory (VM: aos_vm4) Actual [512.0], Unused: [345.90234375] Memory (VM: aos_vm2) Actual [512.0], Unused: [347.515625] Memory (VM: aos_vm3) Actual [512.0], Unused: [347.25390625] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [347.85546875] Memory (VM: aos_vm4) Actual [512.0], Unused: [345.90234375] Memory (VM: aos_vm2) Actual [512.0], Unused: [347.515625] Memory (VM: aos_vm3) Actual [512.0], Unused: [347.25390625]
Test 3
A comprehensive test
1. All virtual machines start from 512MB.
2. All consumes memory.
3. A, B start freeing memory, while at the same time (C, D) continue consuming memory.
4. Expected outcome: memory resource moves from A, B to C, D.
Memory (VM: aos_vm1) Actual [512.0], Unused: [72.13671875] Memory (VM: aos_vm4) Actual [512.0], Unused: [78.59375] Memory (VM: aos_vm2) Actual [512.0], Unused: [72.21484375] Memory (VM: aos_vm3) Actual [512.0], Unused: [74.3125] -------------------------------------------------- Memory (VM: aos_vm1) Actual [512.0], Unused: [77.609375] Memory (VM: aos_vm4) Actual [512.0], Unused: [67.6953125] Memory (VM: aos_vm2) Actual [512.0], Unused: [78.4140625] Memory (VM: aos_vm3) Actual [512.0], Unused: [63.29296875]