RioVista picks up where LRVM left off and aims for a performance conscience transaction. In other words, how can RioVista reduce the overhead of synchronous I/O, attracting system designers to use transactions
System Crash
Two types of failures: power failure and software failure
Key Words: power crash, software crash, UPS power supply
Super interesting concept that makes total sense (I’m guessing this is actually implemented in reality). Take a portion of the memory and battery back it up so that it survives crashes
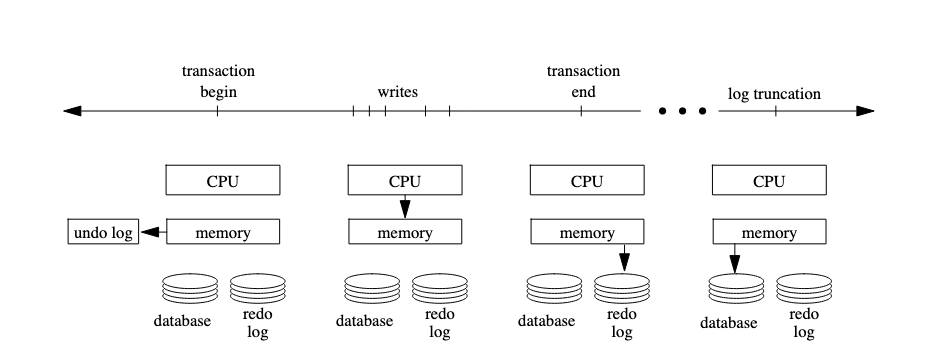
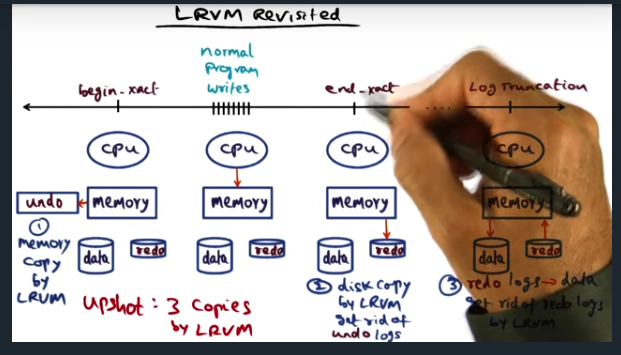
LRVM Revisited
Upshot: 3 copies by LRVM
Key Words: undo record, window of vulnerability
In short, LRVM can be broken down into begin transaction, end transaction. In the former, portion of memory segment is copied into a backup. At the end of the transaction, data persisted to disk (blocking operation, but can be bypassed with NO_FLUSH option). Basically, increasing vulnerability of system to power failures in favor of performance. So, how will a battery backed memory region help?
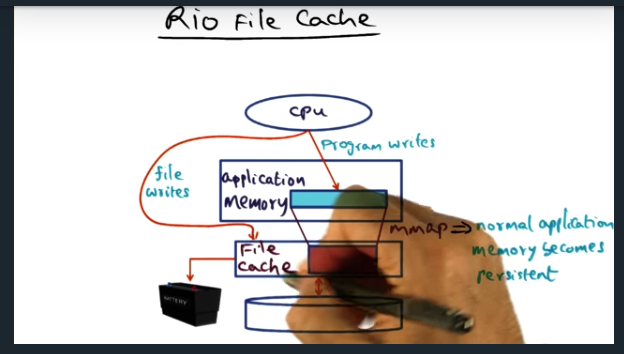
Rio File Cache
Creating a battery backed file cache to handle power failures
In a nutshell, we’ll use a battery backed file cache so that writes to disk can be arbitrarily delayed
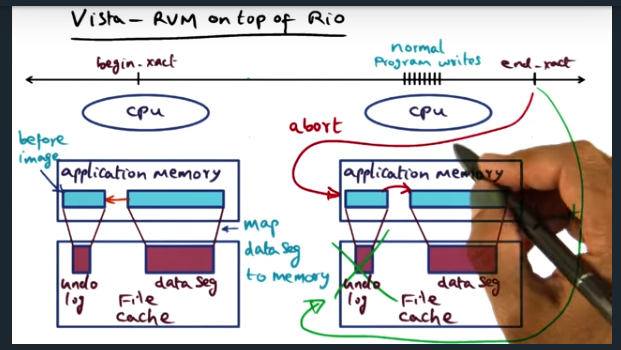
Vista RVM on Top of RIO
Vista – RMV on top of Rio
Key Words: undo log, file cache, end transaction, memory resisdent
Vista is a library that offers same semantics of LRVM. During commit, throw away the undo log; during abort, restore old image back to virtual memory. The application memory is now backed by file cache, which is backed by a power. So no more writes to disk
Crash Recovery
Key Words: idempotency
Brilliant to make the crash recovery mechanism the exact same scenario as an abort transaction: less code and less edge cases. And if the crash recovery fails: no problem. The instruction itself is idempontent
Vista Simplicity
Key Words: checkpoint
RioVista simplifies the code, reducing 10K of code down to 700. Vista has no redo logs, no truncation, all thanks to a single assumption: battery back DRAM for portion of memory
Conclusion
Key Words: assumption
By assuming there’s only software crashes (not power), we can come to an entirely different design
As system designers, we can make persistence into the virtual memory manager, offering persistence to application developers. However, it’s no easy feat: we need to ensure that the solution performs well. To this end, the virtual machine manager offers an API that allows developer to wrap their code in transactions; underneath the hood, the virtual machine manager uses redo logs that persists the user changes to disk which can defend against failures.
We can bake persistent into the virtual memory manager (VMM) but building an abstraction is not enough. Instead, we need to ensure that the solution is performant and instead of committing each VMM change to disk, we aggregate them into a log sequence (just like the previous approaches in distributed file system) so that 1) we write in a contiguous block
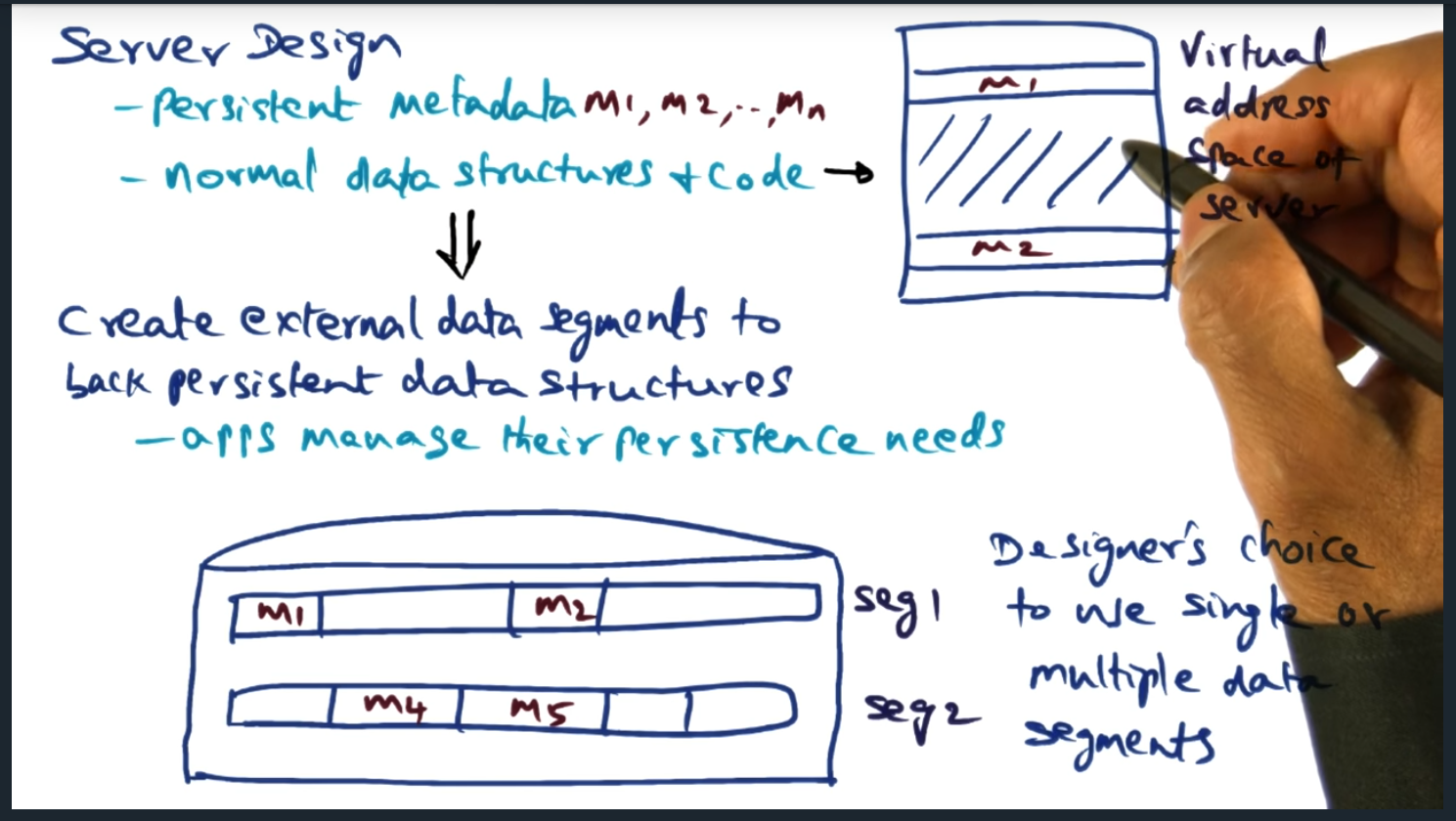
Server Design
Server Design – persist metadata, normal data structures
Key Words: inodes, external data segment
The designer of the application gets to decide which virtual addresses will be persisted to external data storage
Server Design (continued)
Key Words: inodes, external data segment
The virtual memory manager offers external data segments, allowing the underlying application to map portions of its virtual address space to segments backed by disk. The model is simple, flexible, and performant. In a nutshell, when the application boots up, the application selects which portions of memory must be persisted, giving the application developer full control
RVM Primitives
Key Words: transaction
RVM Primitives: initialization, body of server code
There are three main primitives: initialize, map, and unmap. And within the body of the application code, we use transactions: begin transaction, end transaction, abort transaction, and set range. The only non obvious statement is set_range: this tells the RVM runtime the specific range of addresses within a given transaction that will be touched. Meaning, when we perform a map (during initialization), there’s a larger memory range and then we create transactions within that memory range
RVM Primitives (continued)
RVM Primitives – transaction code and miscellaneous options
Key Words: truncation, flush, truncate
Although RVM automatically handles the writing of segments (flushing to disk and truncating log records), application developers can call those procedures explicitly
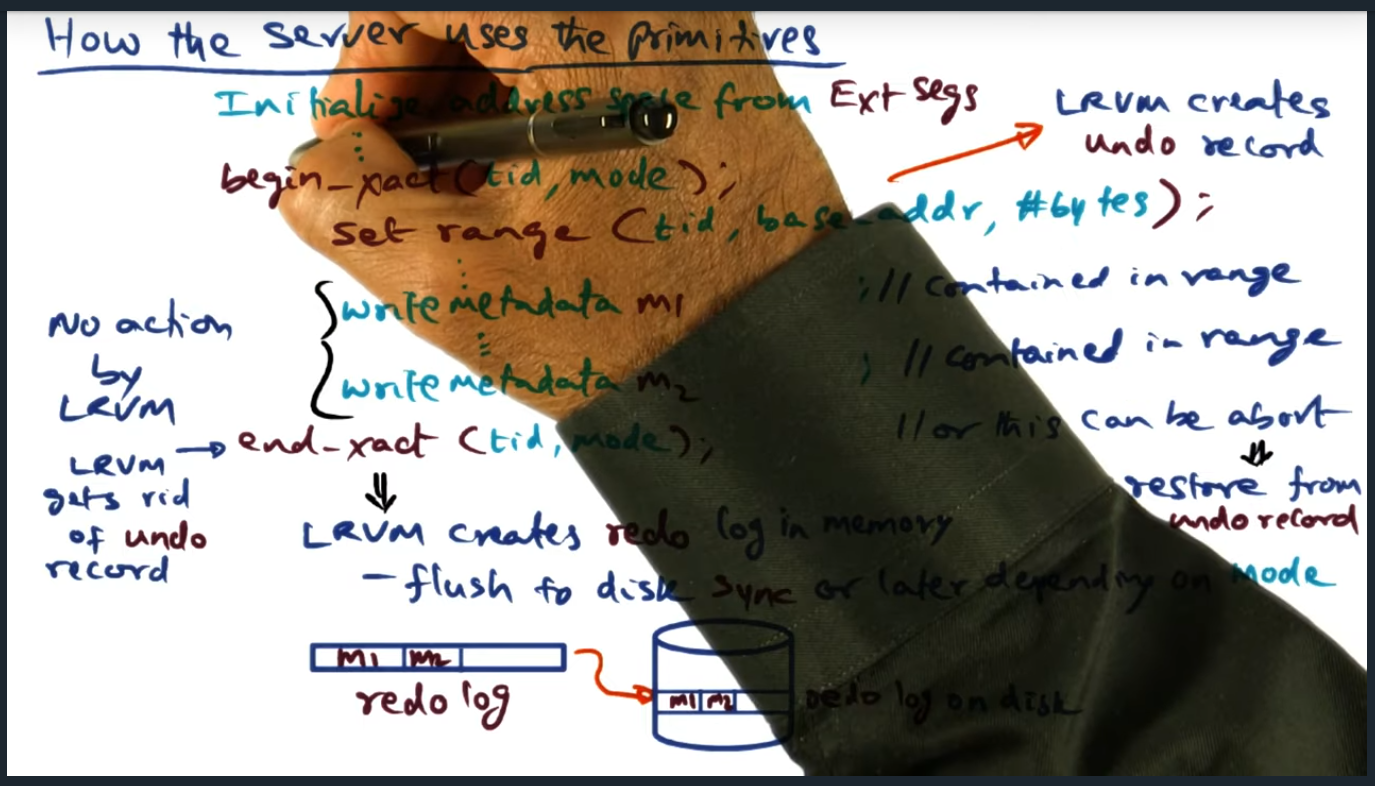
How the Server uses the primitives
How the server uses the primitives – begin and end transaction
Key Words: critical section, transaction, undo record
When transaction begins, the LRVM creates an undo record: a copy of the range specified, allowing a rollback in the event an abort occurs
How the Server uses the primitives (continued)
How the server uses the primitives – transaction details
Key Words: undo record, flush, persistence
During end transaction, the in memory redo log will get flushed to disk. However, by passing in a specific mode, developer can explicitly not call flush (i.e. not block) and flush the transaction themselves
Transaction Optimizations
Transaction Optimizations – ways to optimize the transaction
Key Words: window of vulnerability
With no_restore mode in begin transaction, there’s no need to create a in memory copy; similarly, no need to flush immediately with lazy persistence; the trade off here is that there’s an increase window of vulnerability
Redo log allows traversal in both directions (reverse for recovery) and only new values are written to the log: this implementation allows good performance
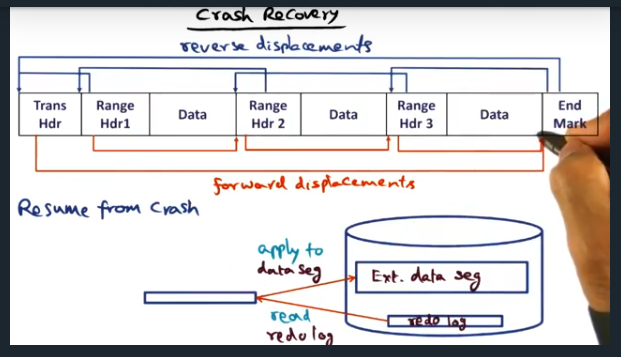
Crash Recovery
Crash Recovery – resuming from a crash
Key Words: crash recovery
In order to recover from a crash, the system traverses the redo log, using the reverse displacement.Then, each range of memory (along with the changes) are applied
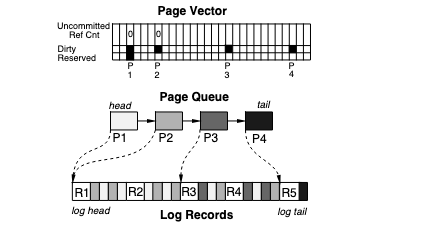
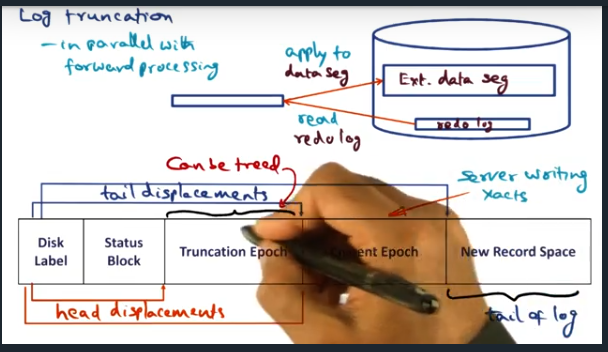
Log Truncation
Log truncation – runs in parallel with forward processing
Key Words: log truncation, epoch
Log truncation is probably the most complex part of LRVM. There’s a constant tug and pull between performance and crash recovery. Ensuring that we can recover is a main feature but it adds overhead and complexity since we want the system to make forward progress while recovering. This end, the algorithm breaks up data into epochs
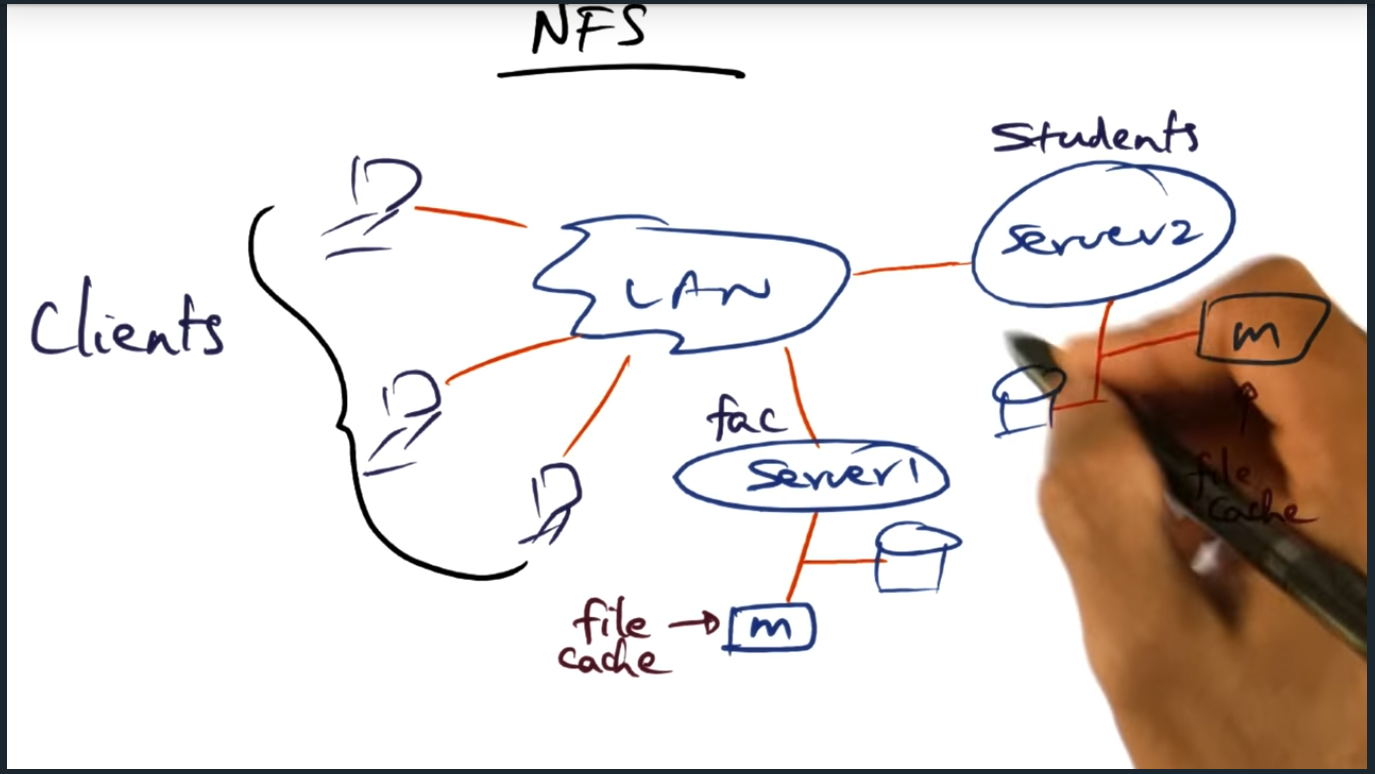
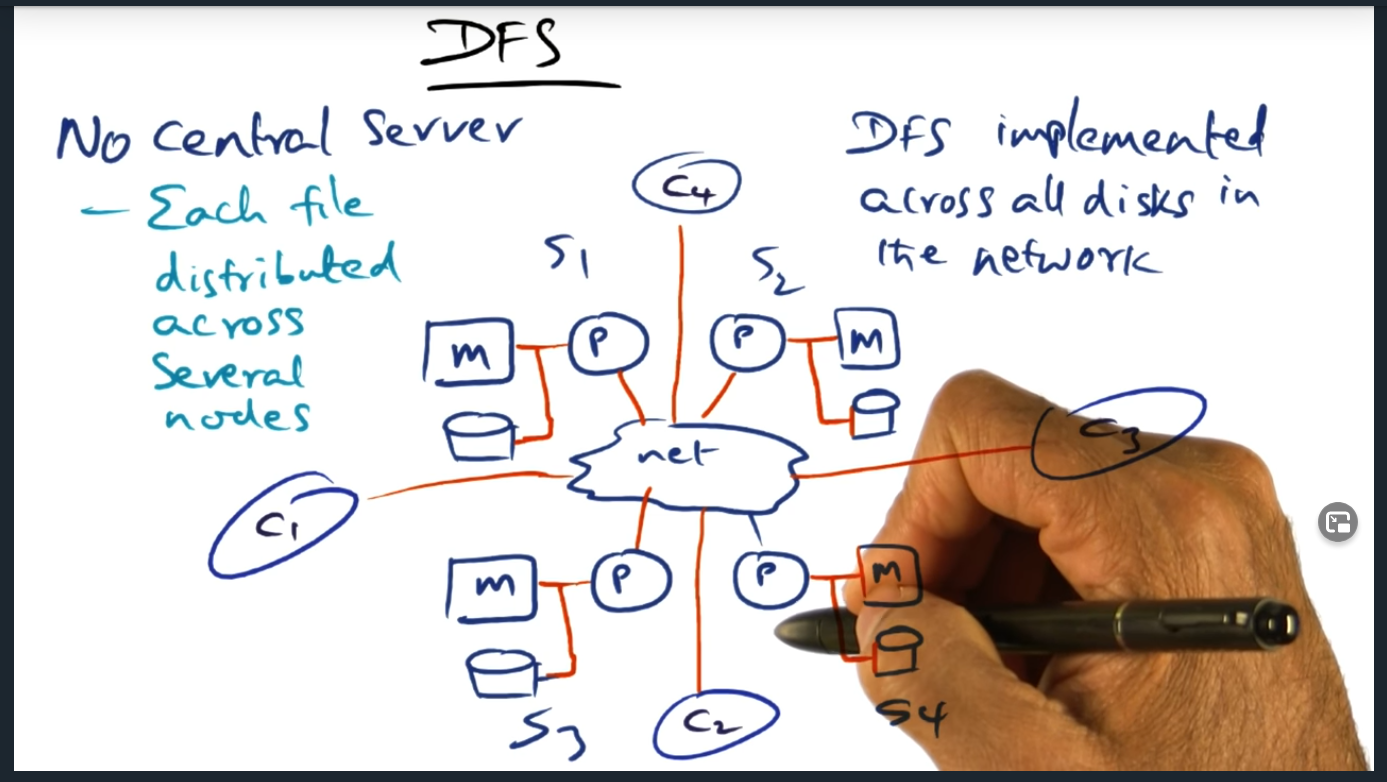
This lesson introduces network file system (NFS) and presents the problems with it, bottlenecks including limited cache and expensive input/output (I/O) operations. These problems motivate the need for a distributed file system, in which there is no longer a centralized server. Instead, there are multiple clients and servers that play various roles including serving data
Quiz
Key Words: computer science history
Sun built the first ever network file system back in 1985
NFS (network file system)
NFS – clients and server
Key Words: NFS, cache, metadata, distributed file system
A single server that stores entire network file system will bottle neck for several reasons, including limited cache (due to memory), expensive I/O operations (for retrieving file metadata). So the main question is this: can we somehow build a distributed file system?
DFS (distributed file system)
Distributed File Server – each file distributed across several nodes
Key Words: Distributed file server
The key idea here is that there is no longer a centralized server. Moreover, each client (and server) can play the role of serving data, caching data, and managing files
Lesson Outline
Key Words: cooperative caching, caching, cache
We want to cluster the memory of all the nodes for cooperative caching and avoid accessing disk (unless absolutely necessary)
Preliminaries (Striping a file to multiple disks)
Key Words: Raid, ECC, stripe
Key idea is to write files across multiple disks. By adding more disks, we increase the probability of failure (remember computing those failures from high performance computing architecture?) so we introduce a ECC (error correcting) disk to handle failures. The downside of striping is that it’s expensive, not just in cost (per disk) but expensive in terms of overhead for small files (since a small file needs to be striped across multiple disks)
Preliminaries
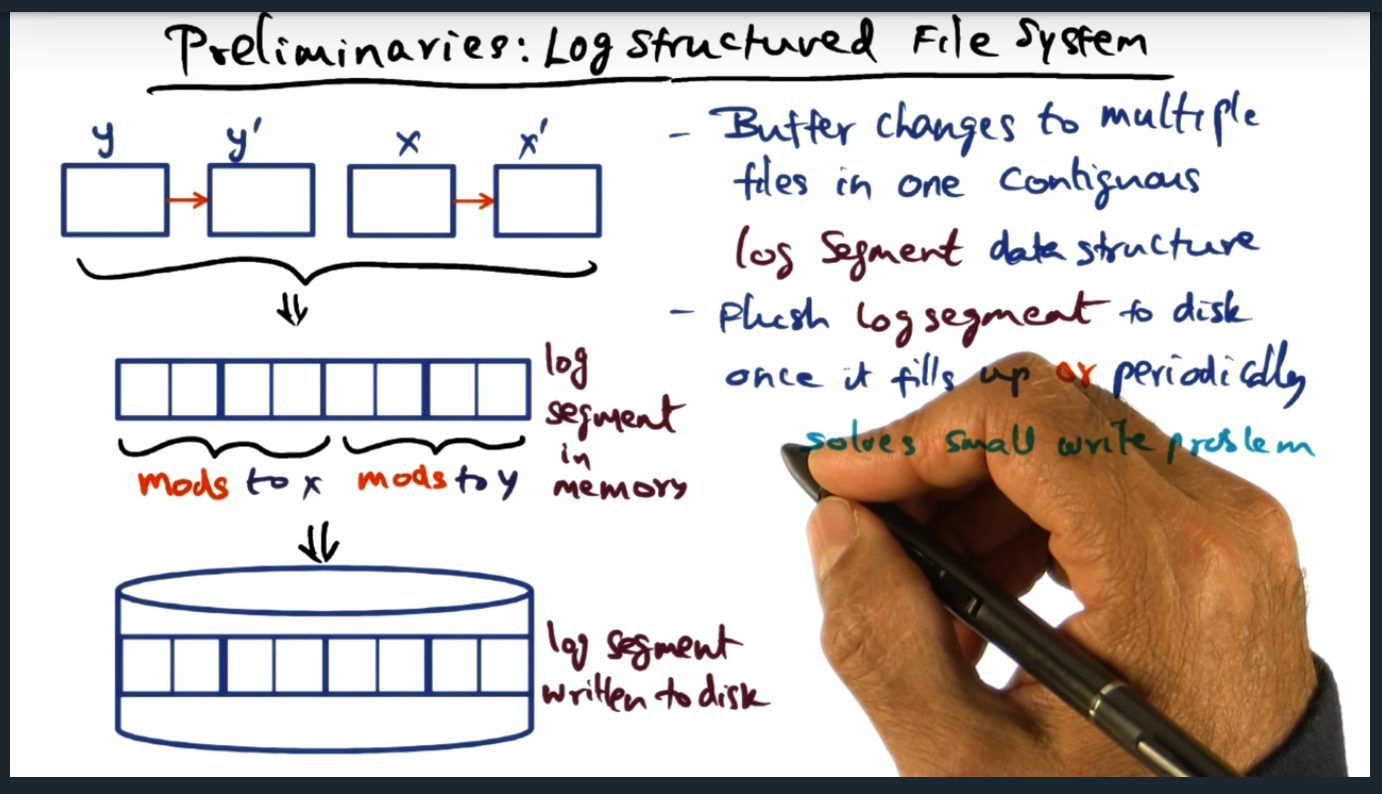
Preliminaries: Log structured file system
Key Words: Log structured file system, log segment data structure, journaling file system
In a log structured file system, the file system will store changes to a log segment data structure, the file system periodically flushing the changes to disk. Now, anytime a read happens, the file is constructed and computed based off of the delta (i.e. logs). The main problem this all solves is the small file problem (the issue with striping across multiple disks using raid). With log structure, we now can stripe the log segment, reducing the penalty of having small files
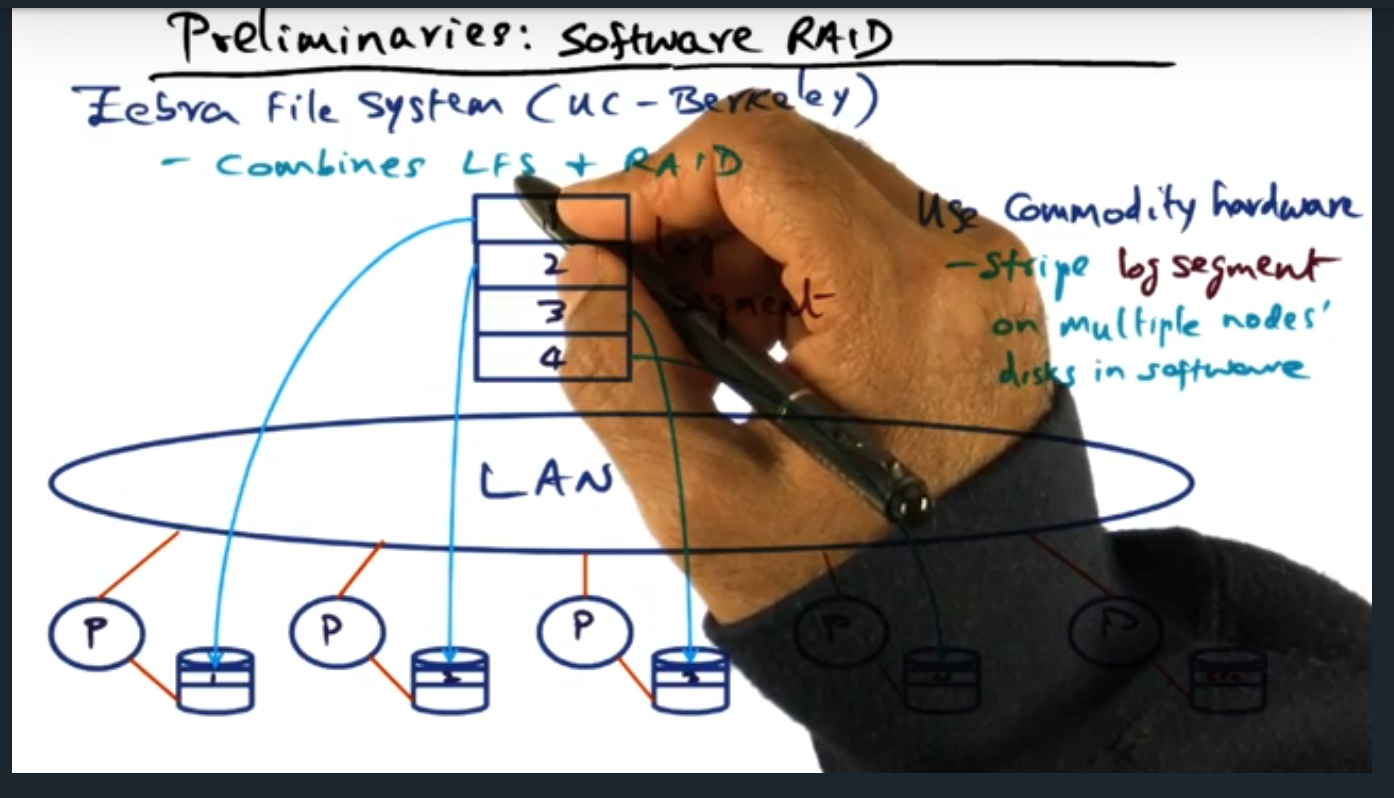
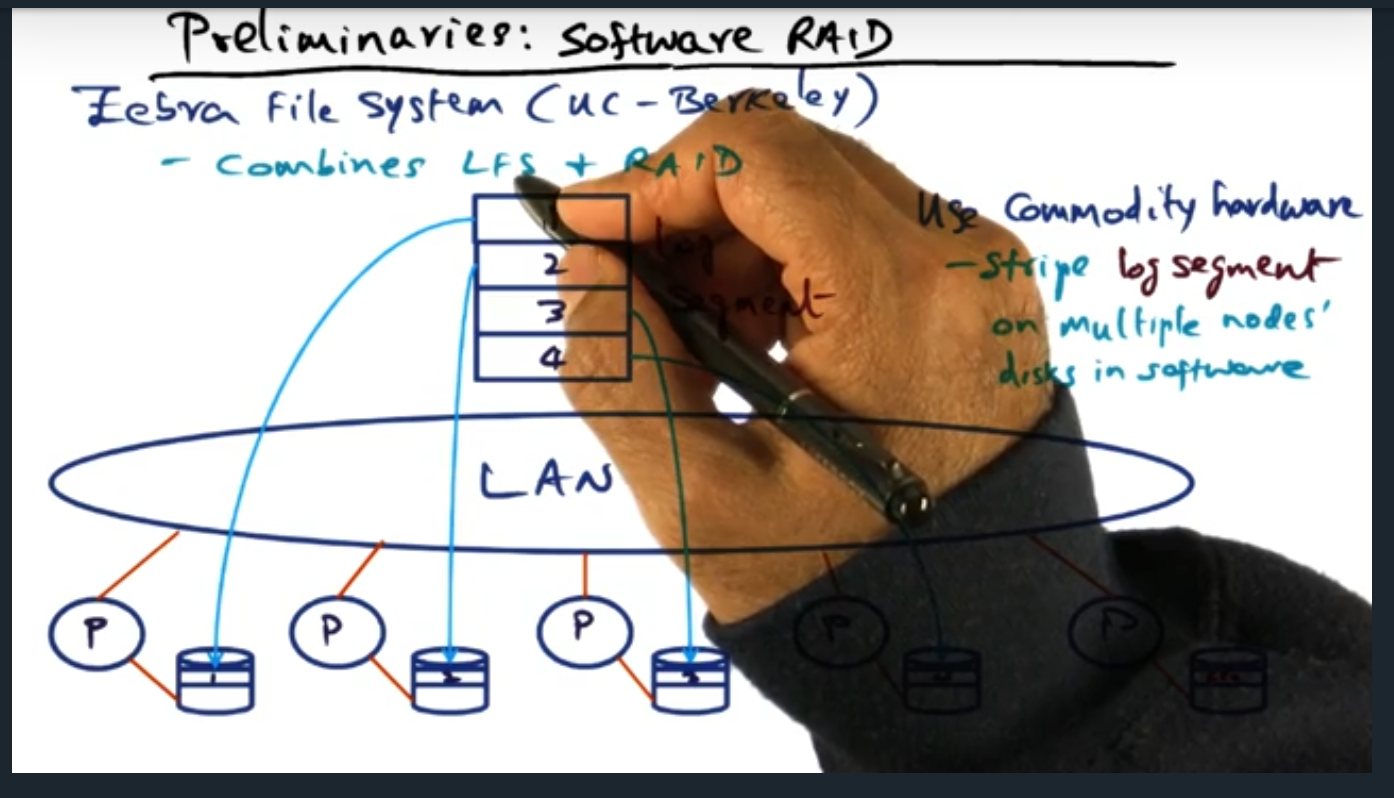
Preliminaries Software (RAID)
Preliminaries – Software Raid
Key Words: zebra file system, log file structure
The zebra file system combines two techniques for handling failures: log file structure (for solving the small file problem) and software raid. Essentially, error correction lives on a separate drive
Putting them all together plus more
Pputting them all together: log based, cooperative caching, dynamic management, subsetting, distributed
Key Words: distributed file system, zebra file system
The XFS file system puts all of this together, standing on top of the shoulders who built Zebra and built cooperating caching. XFS also adds new technology that will be discussed in later videos
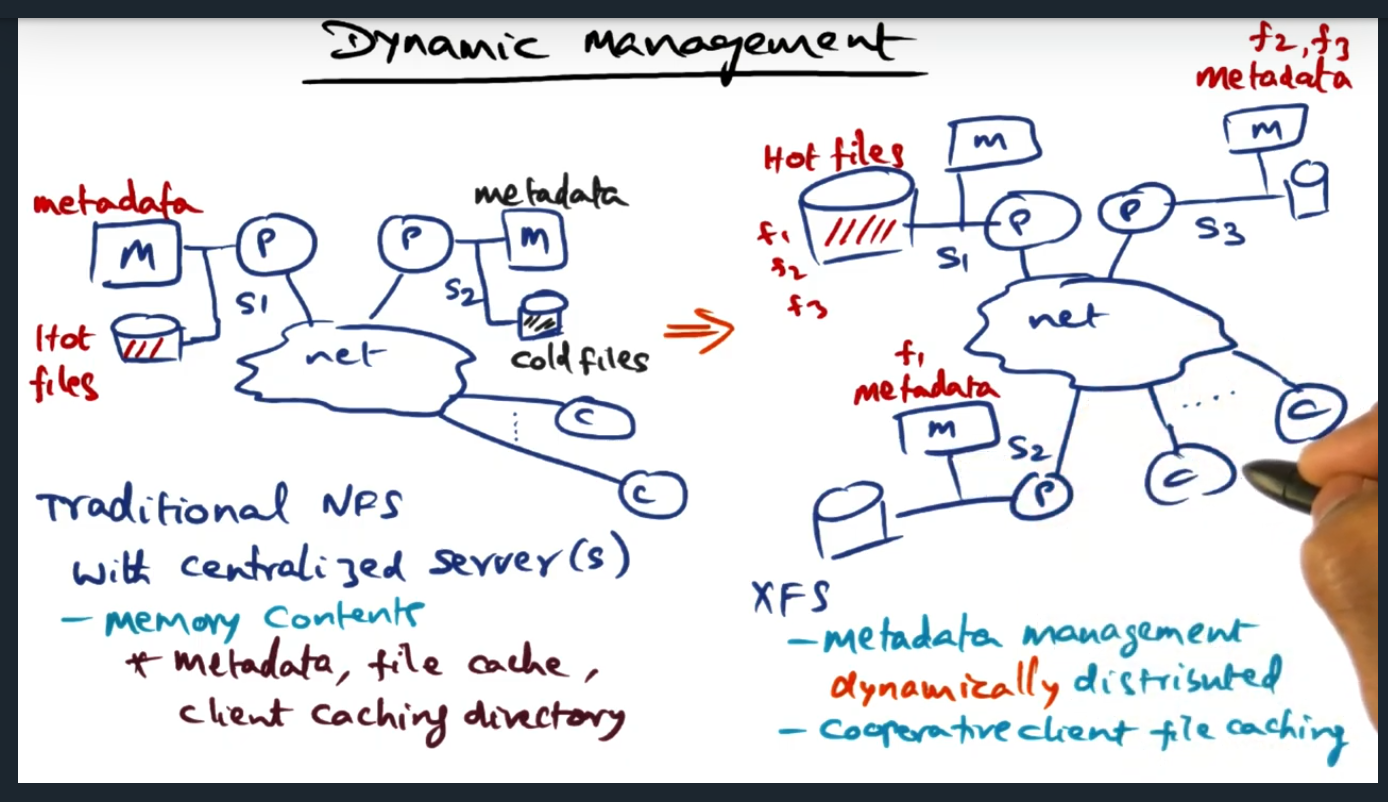
Dynamic Management
Dynamic Management
Key Words: Hot spot, metadata, metadata management
In a traditional NFS server, data blocks reside on disk and memory includes metadata. But in a distributed file system, we’ll extend caching to the client as well
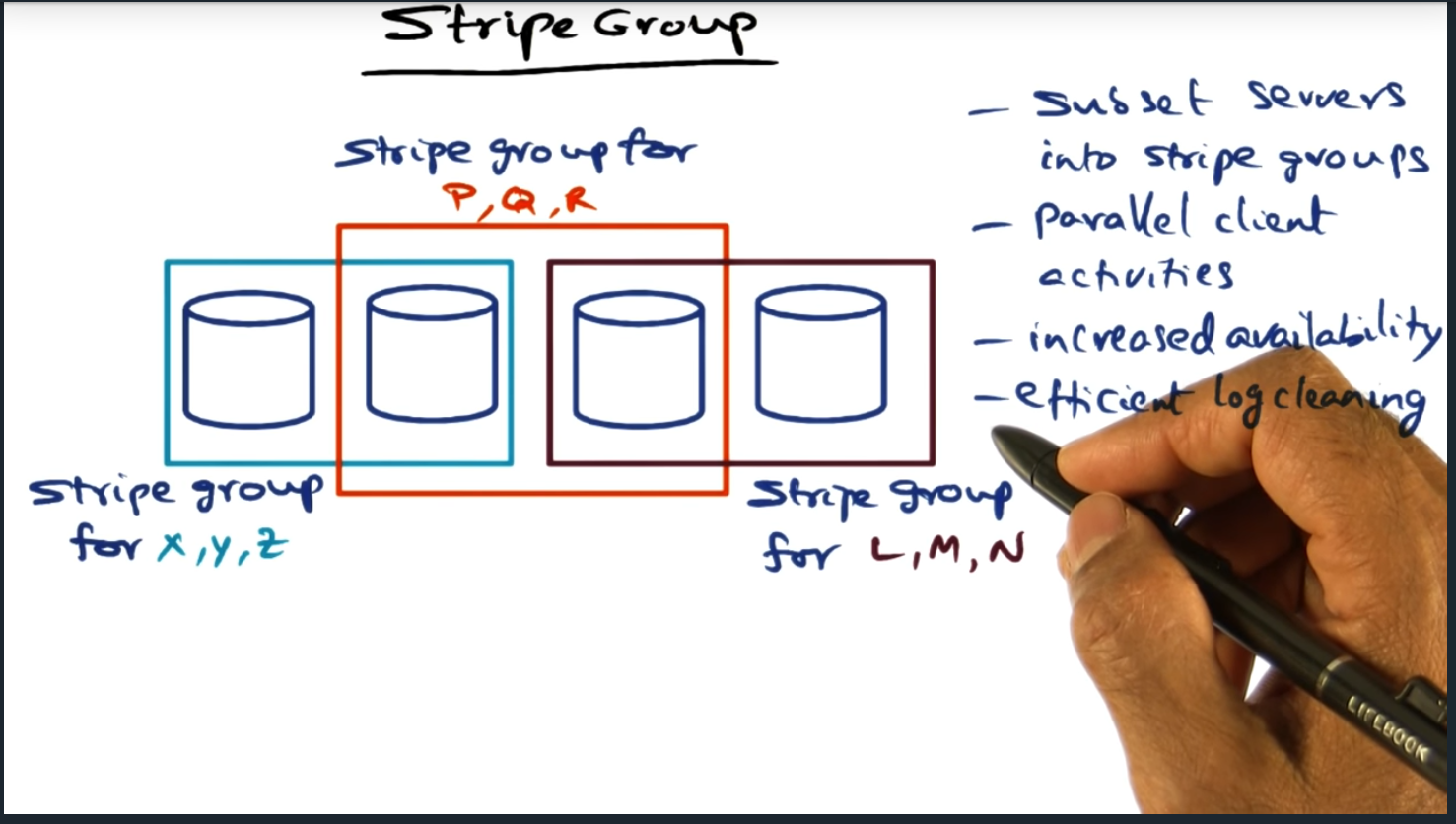
Log Based Striping and Stripe Groups
Log based striping and stripe groups
Key Words: append only data structure, stripe group
Each client maintains its own append only log data structure, the client periodically flushing the contents to the storage nodes. And to prevent reintroducing the small file problem, each log fragment will only be written to a subset of the storage nodes, those subset of nodes called the stripe group
Stripe Group
Stripe Group
Key Words: log cleaning
By dividing the disks into stripe groups, we promote parallel client activities and increases availability
Cooperating Caching
Cooperative Caching
Key Words: coherence, token, metadata, state
When a client requests to write (to a block), the manager (who maintains state, in the form of metadata, about each client) will cache invalidate the clients and grant the writer a token to write for a limited amount of time
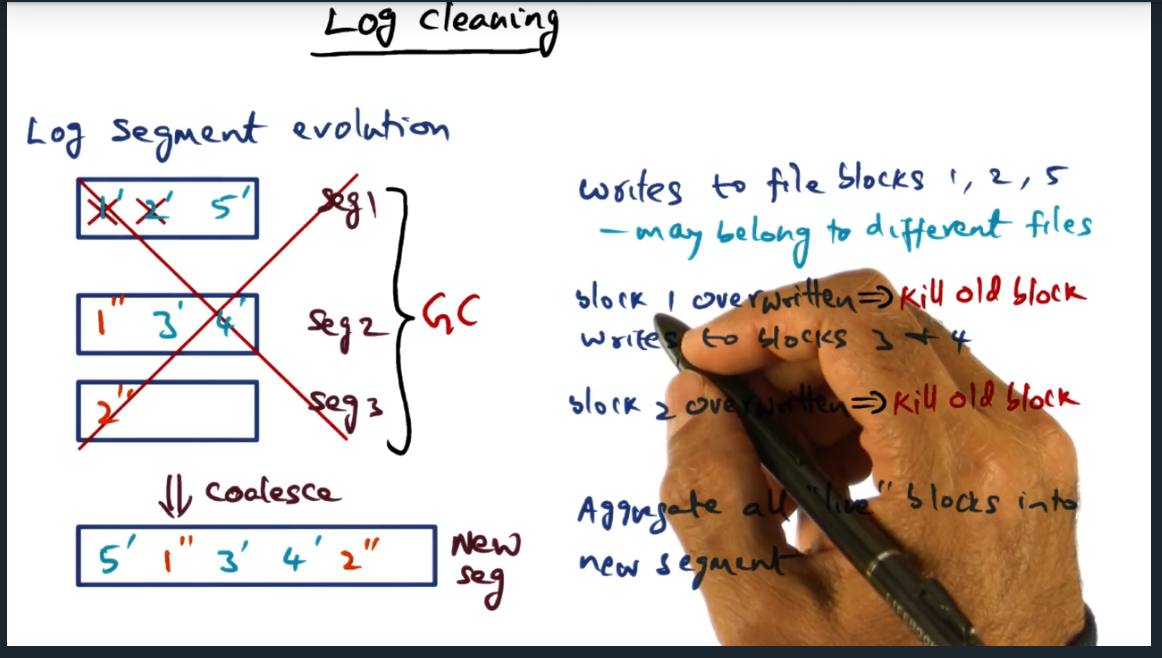
Log Cleaning
Log Cleaning
Key Words: prime, coalesce, log cleaning
Periodically, node will coalesce all the log segment differences into a single, new segment and then run a garbage collection to clean up old segments
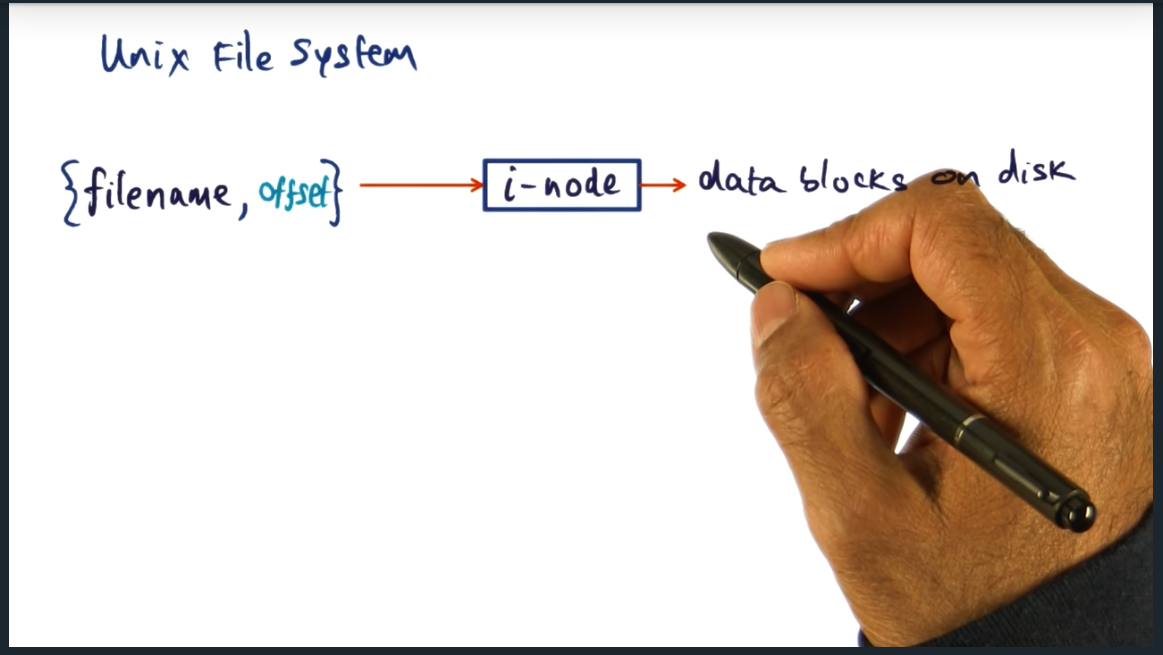
Unix File System
Unix File System
Key Words: inode, mapping
On any unix file system, there are inodes, which map filenames to data blocks on disk
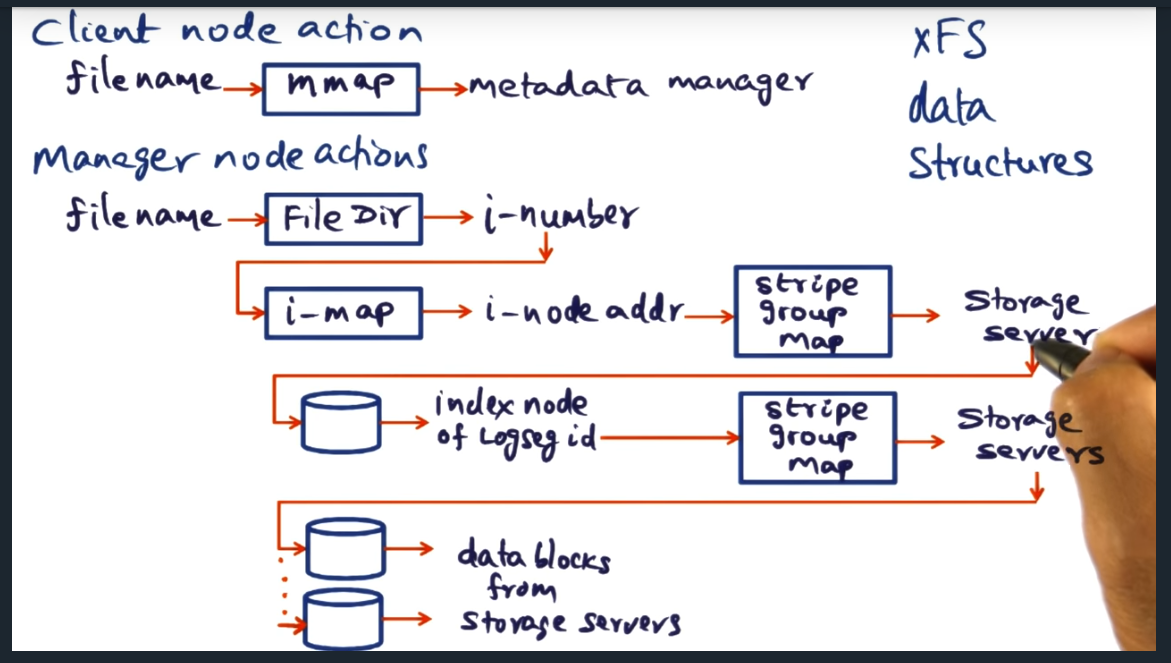
XFS Data Structures
XFS Data Structures
Key Words: directory, map
Manager node maintains data structures to map a filename to the actual data blocks from the storage servers. Some data structures include the file directory, and i_map, and stripe group map
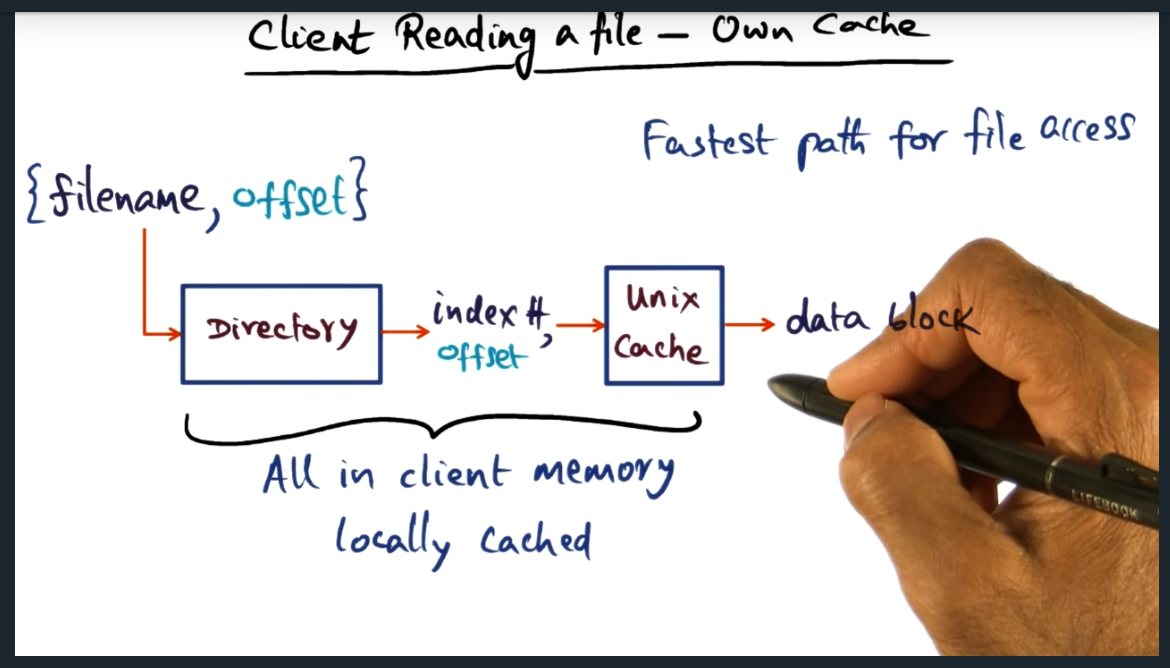
Client Reading a file own cache
Client Reading a file – own cache
Key Words: Pathological
There are three scenarios for client reading a file. The first (i.e. best case) is when the data blocks sit in the unix cache of the host itself. The second scenario is the client querying the manager, and the manager signals another peer to send its cache (instead of retrieving from disk). The worst case is the pathological case (i.e. see previous slide) where we have to go through the entire road map of talking to manager, then looking up metadata for the stripe group, and eventually pulling data from the disk
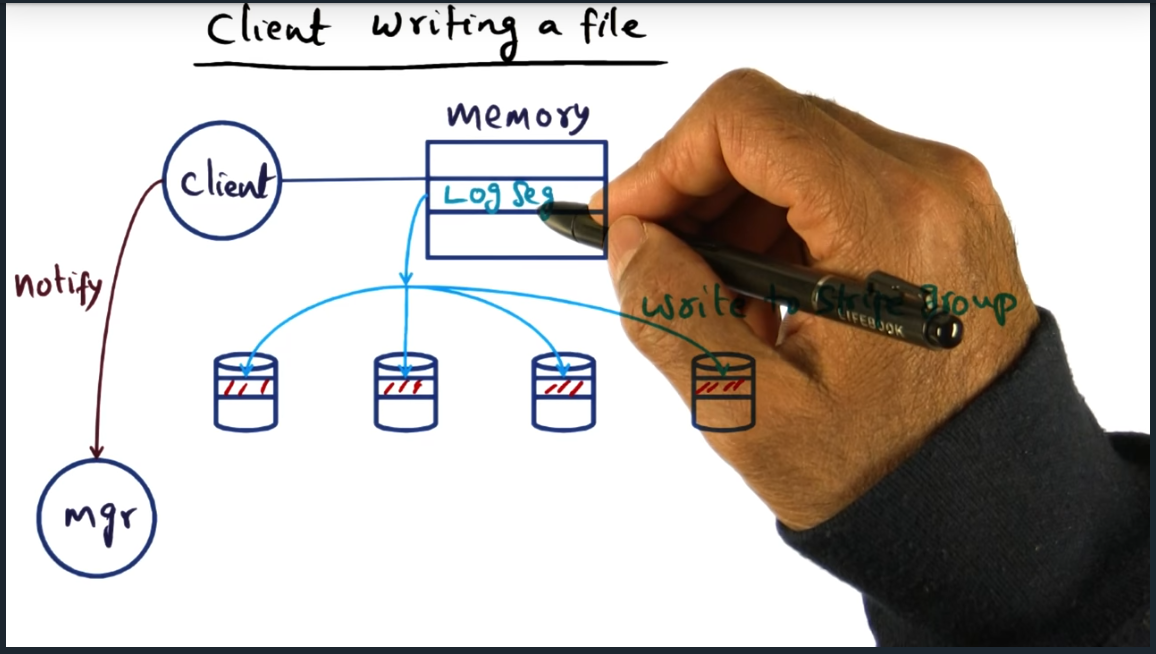
Client Writing a File
Client Writing a file
Key Words: distributed log cleaning
When writing, client will send updates to its log segments and then update the manager (so manager has up to date metadata)
Conclusion
Techniques for building file systems can be reused for other distributed systems
Before starting project 2 (for my advanced operating systems course), I took a snapshot of my understanding of synchronization barriers. In retrospect, I’m glad I took 10 minutes out of my day to jot down what I did (and did not) know because now, I get a clearer pictur eof what I learned. Overall, I feel the project was worthwhile and I gained not only some theoretical knowledge of computer science but I was also able to flex my C development skills, writing about 500 lines of code.
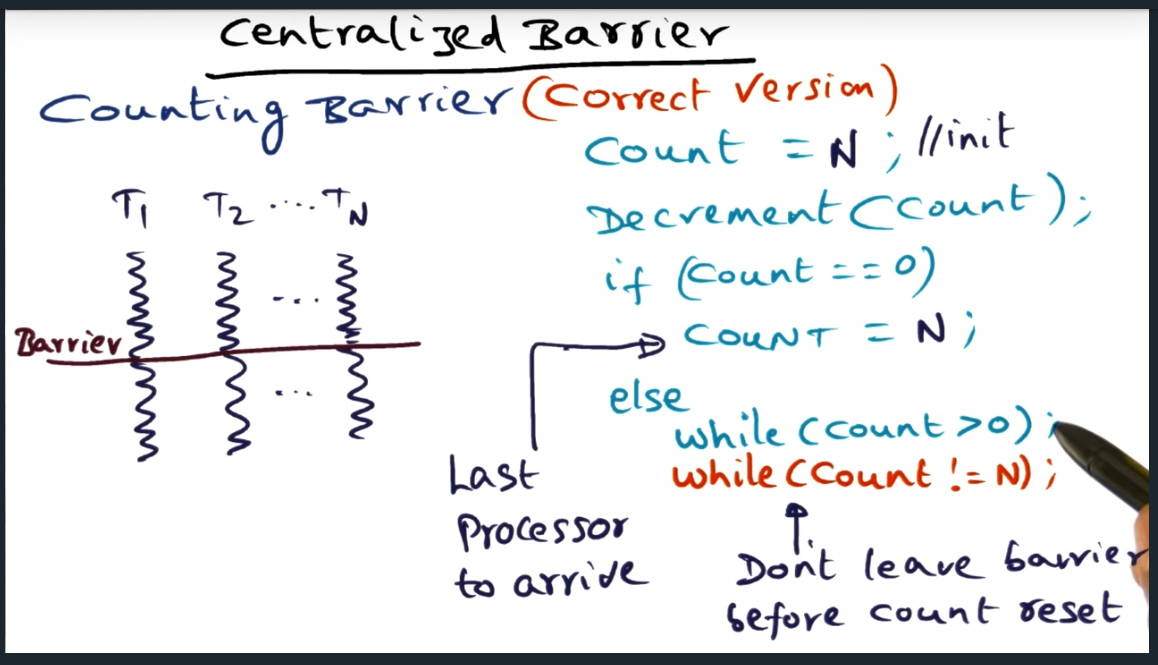
Discovered a subtle race condition with lecture’s pseudo code
Just by looking at the diagram below, it’s not obvious that there’s a subtle race condition hidden. I only was able to identify it after whipping up some code (below) and analyzing the concurrent flows. I elaborate a little more on the race condition — which results in a deadlock — in this blog post.
Centralized Barrier
[code lang=”C”]
/*
* Race condition possible here. Say 2 threads enter, thread A and
* thread B. Thread A scheduled first and is about to enter the while
* (count > 0) loop. But just before then, thread B enters (count == 0)
* and sets count = 2. At which point, we have a deadlock, thread A
* cannot break free out of the barrier
*
*/
if (count == 0) {
count = NUM_THREADS;
} else {
while (count > 0) {
printf("Spinning …. count = %d\n", count);
}
while (count != NUM_THREADS){
printf("Spinning on count\n");
}
}
[/code]
Data Structures and Algorithms
How to represent a tree based algorithm using multi-dimensional arrays in C
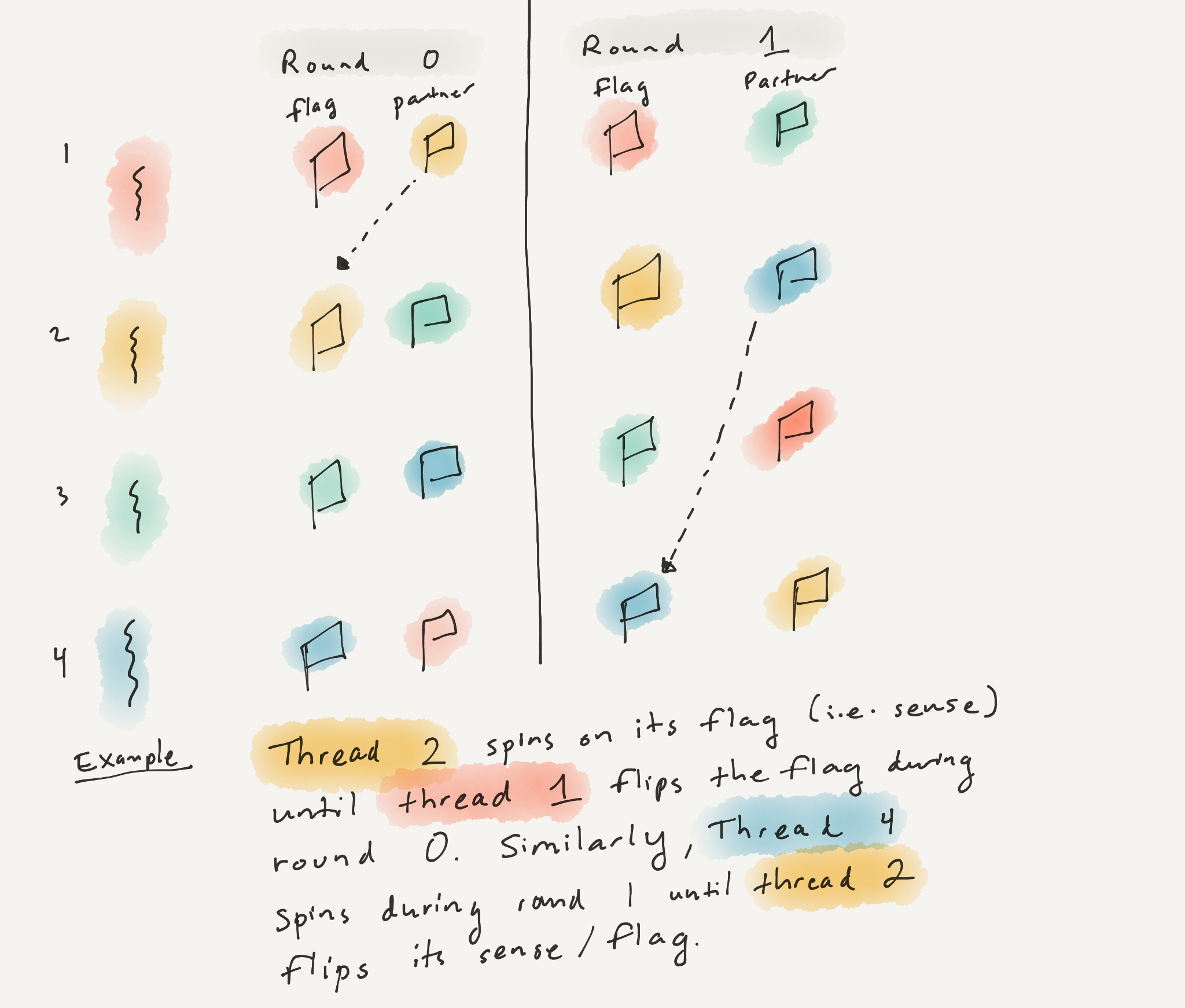
For both the dissemination and tournament barrier, I had to build multi-dimensional arrays in C. I initially had a difficult time envisioning the data structure described in the research papers, asking myself questions such as “what do I use to index into the first index?”. Initially, my intuition thought that for the tournament barrier, I’d index into the first array using the round ID but in fact you index into the array using the rank (or thread id) and that array stores the role for each round.
void flags_init(flags_t flags[MAX_ROUNDS])
{
int i,j,k;
for (i = 0; i < MAX_NUM_THREADS; i++) {
for (j = 0; j < PARITY_BIT; j++) {
for (k = 0; k < MAX_NUM_THREADS; k++) {
flags[i].myflags[j][k] = false;
}
}
}
}
[/code]
OpenMP and OpenMPI
Prior to starting I never heard of neither OpenMP nor OpenMPI. Overall, they are two impressive pieces of software that makes multi-threading (and message passing) way easier, much better than dealing with the Linux pthreads library.
Summary
Overall, the project was rewarding and my understanding of synchronization barriers (and the various flavors) were strengthen by hands on development. And if I ever need to write concurrent software for a professional project, I’ll definitely consider using OpenMP and OpenMPI instead of low level libraries like PThread.
I’m implementating the dissemination barrier (above) in C for my advanced OS course and I’m not quite sure I understand the pseudo code itself. In particular, I don’t get the point of the parity flag …. what’s the point of it? What problem does it solve? Isn’t the localsense variable sufficient to detect whether or not the threads (or processes) synchronized? I’m guessing that the parity flag helps with multiple invocations of the barrier but that’s just a hunch.
I’m watching the YouTube learning series called “Introduction to OpenMP” in order to get a better understanding of how I can use the framework for my second project in advanced operating systems. You might find the below notes useful if you don’t want to sit through the entire video series.
Introduction to OpenMP: 02 part 1 Module 1
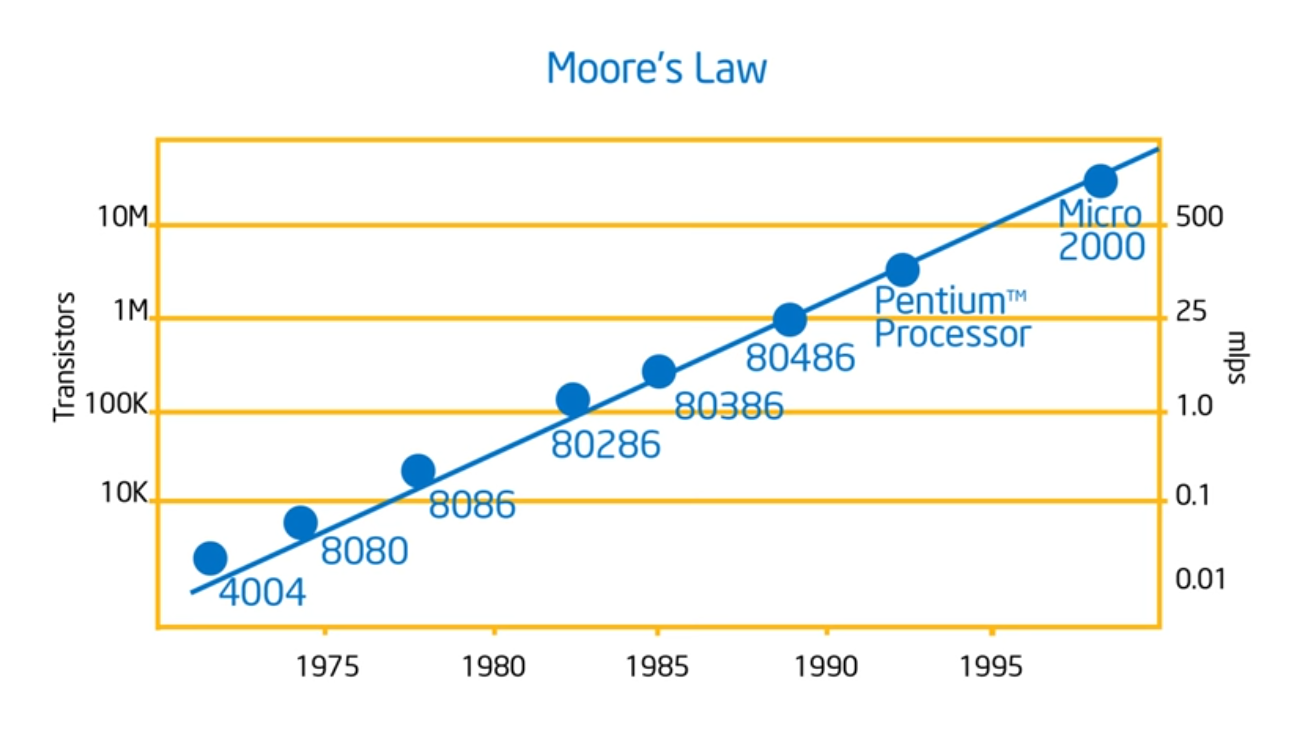
Moore’s Law
Summary
Neat that he’s going over the history, talking about Moore’s Law. The key take away now is that hardware designers are now going to optimize for power and software developers have to write parallel programs: there’s no free lunch. No magic compiler that will take sequential code and turn it into parallel code. Performance now c
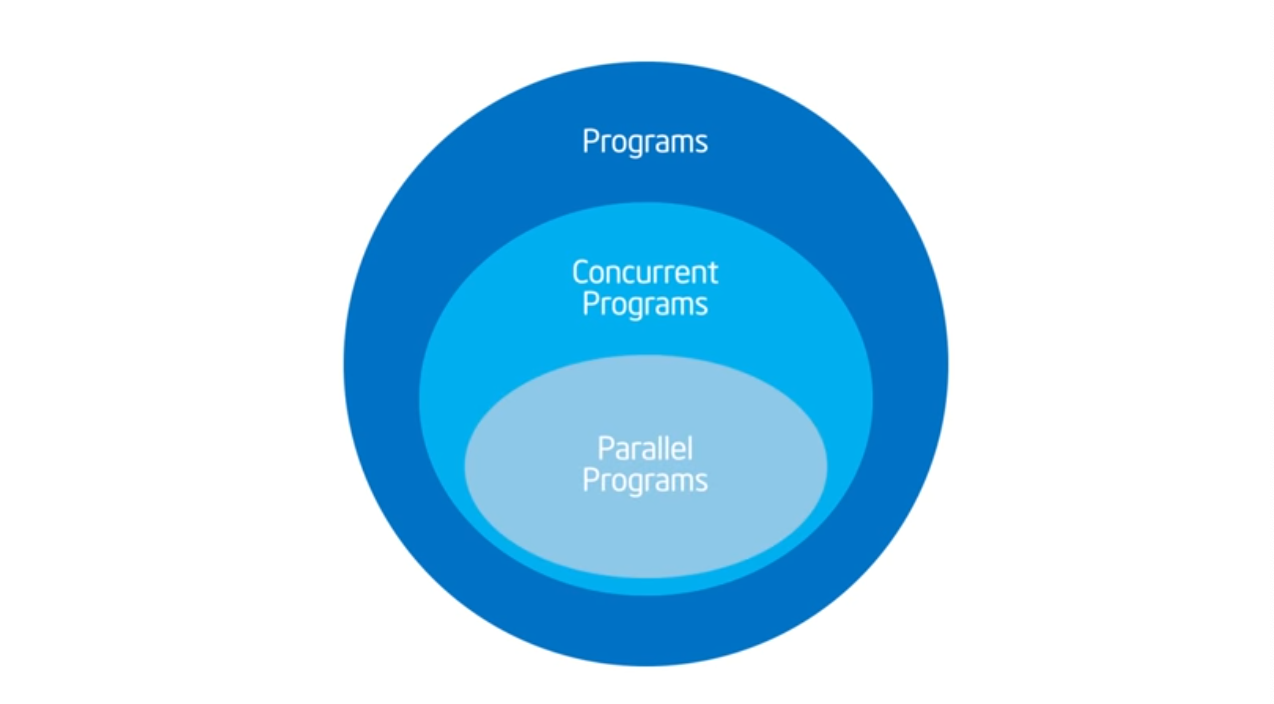
Introduction to OpenMP – 02 Part 2 Module 1
Concurrency vs Parallelism
Summary
The last step should be picking up the OpenMP Library (or any other parallel programming library). What should be done firs and foremost is breaking down your problem (the act of this has not been able to automated) into concurrent parts (this requires understanding of the problem space) and then figure out which can run in parallel. Once you figure that out, then you can use compiler syntactical magic (i.e. pragmas) to direct your compiler and then sprinkle some additional pragmas that will help the compiler tell where the code should enter and where it should exit.
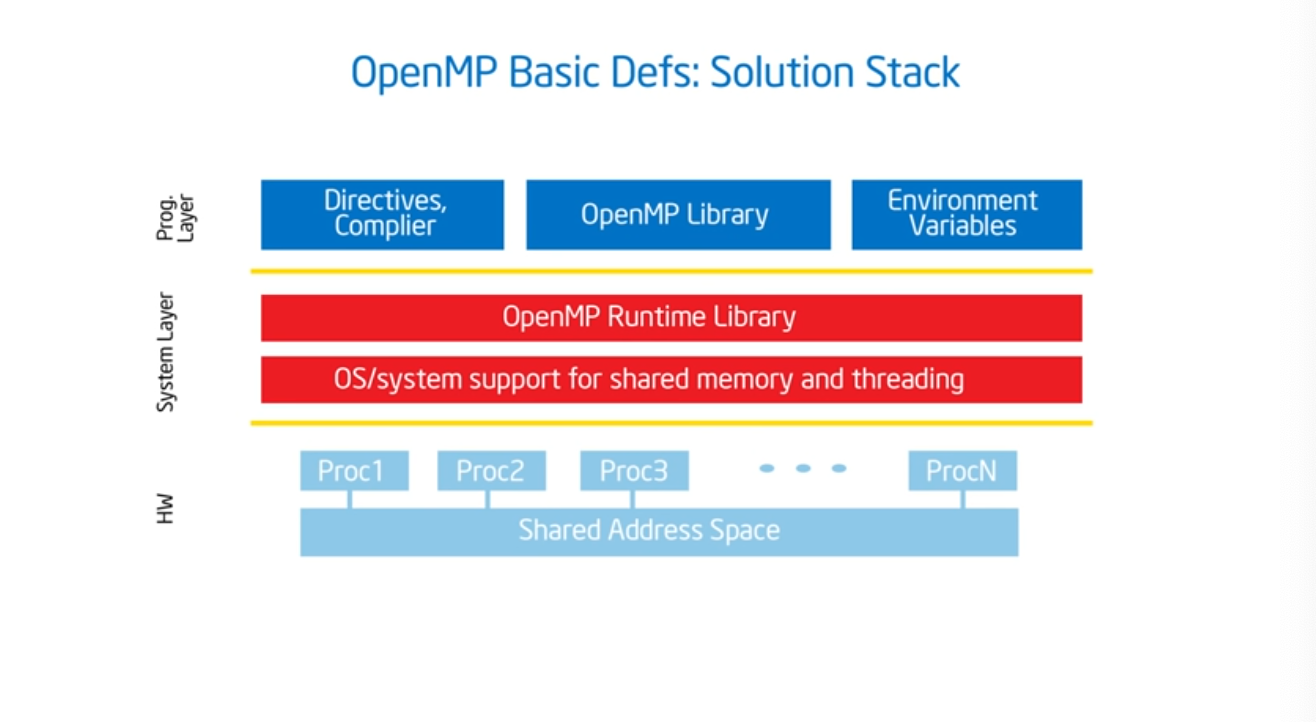
Introduction to OpenMP – 03 Module 02
OpenMP Solution Stack
Summary
It’s highly likely that the compiler that you are using already supports OpenMP. For gcc, pass in -fopenmp. And then include the prototype, and add some syntactic sugar (i.e. #pragma amp parallel) which basically gives the program a bunch of threads.
Introduction to OpenMP: 04 Discussion 1
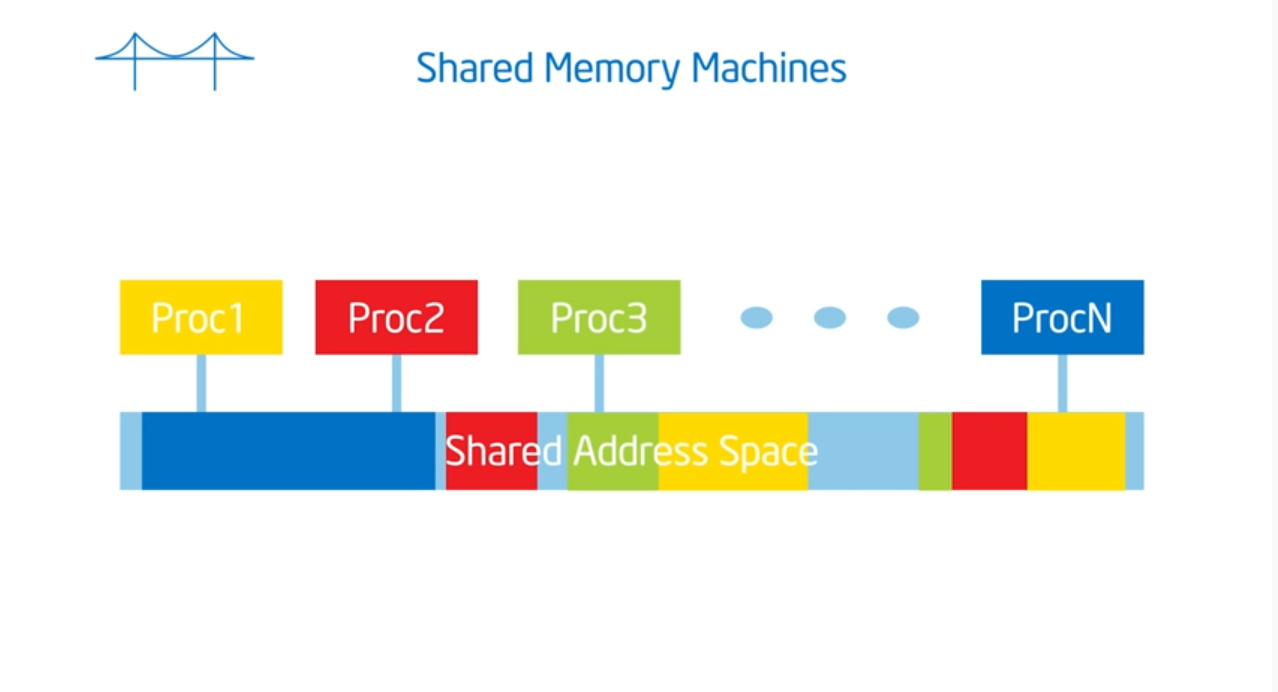
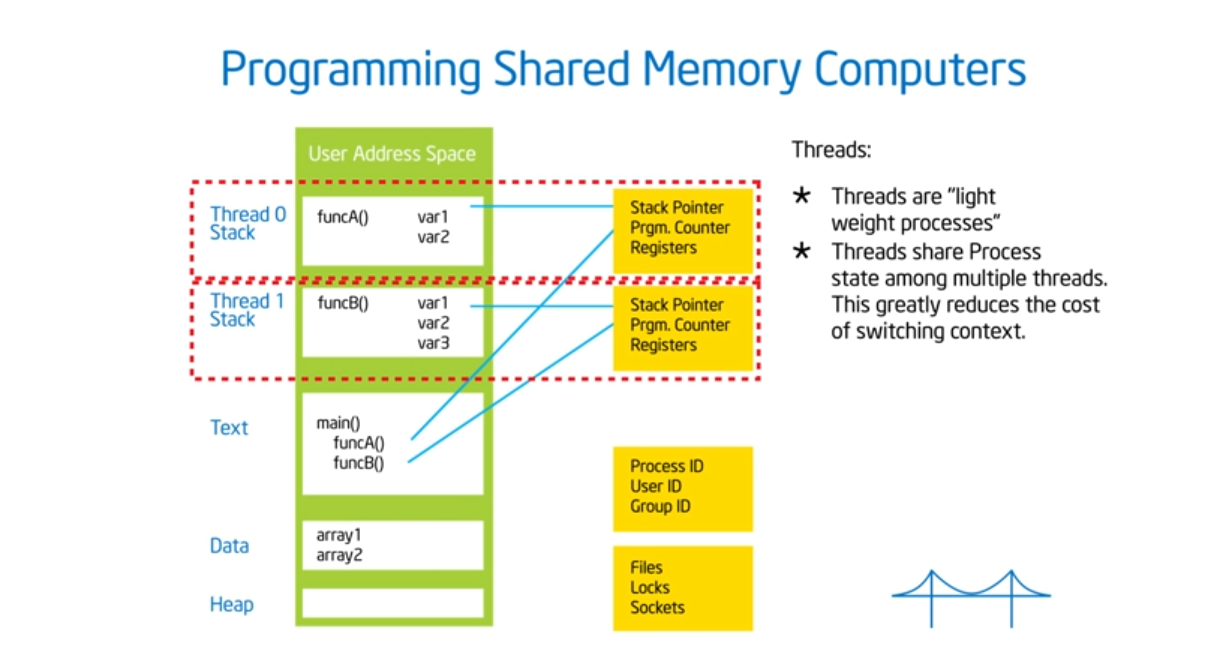
Shared address space
Summary
OpenMP assumes a shared memory address space architecture. The last true SMP (symmetric multi-processor) machine was in the late 1980s so most machines now run on NUMA (non uniformed multiple access) architectures. To exploit this architecture, we need to schedule our threads intelligently (which map to the same heap but contain different stacks) and place data in our cache’s as close as possible to their private caches. And, just like the professor said in advanced OS, we need to limit global data sharing and limit (as much as possible) the use of synchronization variables since they both slow down performance
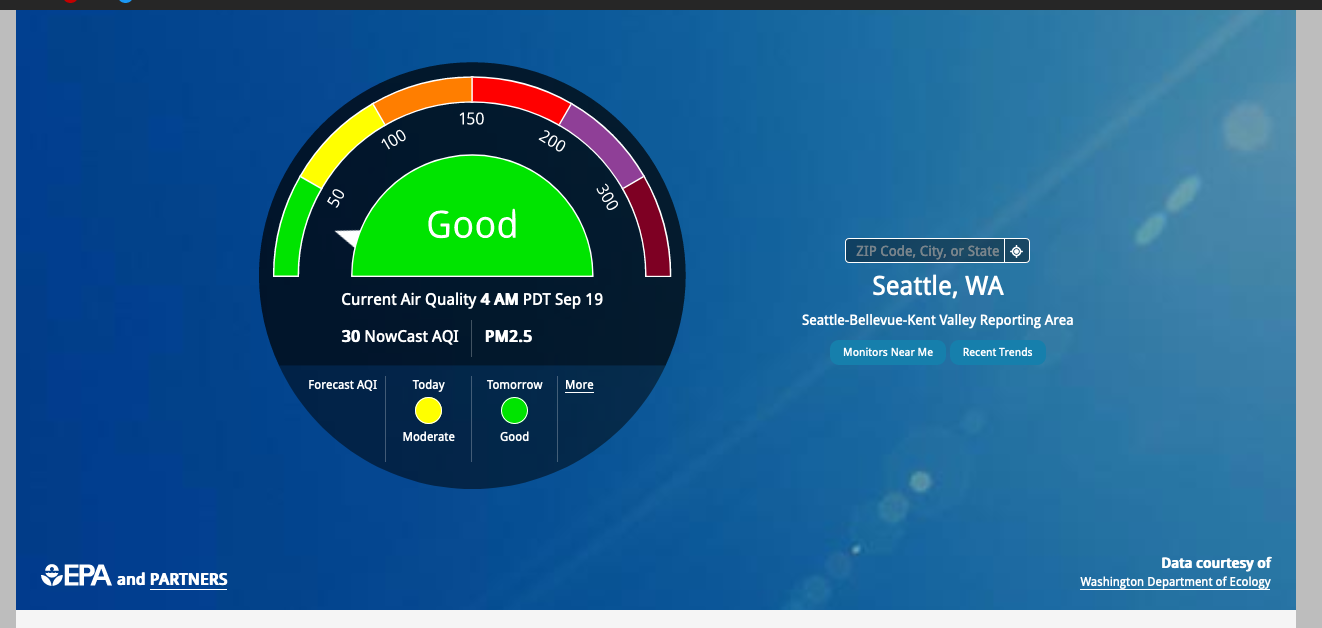
Hooray! Today is the first day in a couple weeks that air quality is considered good, at least according to the EPA. I’m so pleased and so grateful for clean air because my wife and daughter have not left the house since the wild fires started a week ago (or was it two weeks — I’ve lost concept of time since COVID hit) and today marks the first day we can as an entire family can go for a walk at a local park (it’s the little things in life) and breathe in that fresh, crisp pacific northwest air. Of course, we’ll still be wearing masks but hey, better than staying cooped up inside.
Yesterday
What I learned yesterday
Static assertion on C structures. This type of assertion fires off not at at run-time but at compile time. By asserting on the size of a structure, we can ensure that they are sized correctly. This sanity check can be useful in situations such as ensuring that your data structure will fit within your cache lines.
Writing
Published my daily review that I had to recover in WordPress since I had accidentally deleted the revision
Best parts of my day
Video chatting at the end of the work day with my colleague who I used to work with in Route 53, the organization I had left almost two years ago. It’s nice to speak to a familiar face and just shoot the shit.
Graduate School
Finished lectures on barrier synchronization (super long and but intellectually stimulating material)
Started watching lectures on lightweight RPC (remote procedure calls)
Submitted my project assignment
Met with a classmate of mine from advanced operating systems, the two of us video chatting over Zoom and describing our approaches to project 1 assignment
Work
Finished adding a simple performance optimization feature that takes advantage of the 64 byte cache lines, packing some cached structs with additional metadata squeezed into the third cache line.
Miscellaneous
Got my teeth cleaned at the dentist. What an unusual experience. Being in the midst of the pandemic for almost 8 months now I’ve forgotten what it feels like to talk to someone up close while not wearing a mask (of course the dentist and dental hygienist were wearing masks) so at first I felt a bit anxious. These days, any sort of appointments (medical or not) are calculated risks that we must all decide for ourselves.
Today
Writing
Publish Part 1 of Barrier Synchronization notes
Publish this post (my daily review)
Review my writing pipeline
Mental and Physical Health
Slip on my Freebird shoes and jog around the neighborhood for 10 minutes. Need to take advantage of the non polluted air that cleared up (thank you rain)
Swing by the local Cloud City coffee house and pick up a bottle of their in house Chai so that I can blend it in with oat milk at home.
Review my tasks and project and breakdown the house move into little milestones
Family
Take Mushroom to her grooming appointment. Although I put a stop gap measure in place so that she stops itching and wounding herself, the underlying issue is that she needs a haircut since her hair tends to develop knots.
Walk the dogs at either Magnuson or Marymoore Park. Because of the wild fires, everyone (dogs included) have been pretty much stuck inside the house.
Pack pack pack. 2 weeks until we move into our new home in Renton. At first, we were very anxious and uncertain about the move. Now, my wife and I are completely ready and completely committed to the idea.
With working remote and establishing a (somewhat) daily routine (that has become pretty monotonous), it’s sometimes easy to forget that we’re in the midst of a global pandemic. But that reality is amplified because of the recent wild fires, forcing those of us living in the pacific north west (PNW) — and those living in Northern California — to remain indoors. This additional layer of lock down definitely impacts the mental health for both my wife and I. I’m almost certain that not breathing in fresh air from outside negatively affects my 11 month year old daughter, who has not stepped (or carried) outside this past week — not even for a few minutes. I really want her to join me for the daily walks with the dogs, even if it is for a few minutes, but my wife and I agreed that’s its best for the long term if she doesn’t inhale any of the ashes trickling down from the sky.
Unrelated to the above comment about the pandemic, I was reading Write it down make it happen on my Kindle while sitting on the can (you’d be surprised how much reading you can get done during your trips to the bathroom) and there’s a section in the book that suggests sometimes the way to make things happen is to simply let go of the reins and relegate all control.
On some level, I agree that sometimes you’ll find the very thing you’ve been looking for when you stop searching. This concept rings true to me because during my mid twenties, I stopped searching for “the one” and instead, began looking inward and healing myself (my life was spiraling out of control due to my compulsive and addictive behavior) and on the path to recovery, I ended up meeting the one, my now wife, the two of us bumping into each other while volunteering at a children’s orphanage (she often jokes and tells people that I adopted her … not everyone gets the joke).
Yesterday
What I learned yesterday
Learned a new data structure called n-ary tree (i.e. each node can have up to N children). Picked up this new graph theory inspired data structure from watching the video lectures for advanced operating systems
Funny moments
Professor made me laugh while I was watching his recorded lecture videos, the professor describing the tournament barrier and how the algorithm “rigs” the competition and how the algorithm seems applicable to real life given professional sports rig competitions all the time (e.g. baseball and world series) Okay, reading this out to myself now doesn’t sound that funny but I guess its something you have to hear first hand.
Writing
Published my daily review describing how I crashed and burned during the afternoon
Eating dinner with Jess while grubbing on some delicious Vietnamese take out food from our favorite (for now) local restaurant called Moonlight. They sell the best Vegan Vietnamese food, dishes including Ca Co (clay pot fish) and Canh Chua (Vietnamese Sweet and Sour Soup) and Pho. All this wonderful food while the two of us planted in front of the cinema sized television playing “Fresh Off The Boat”.
Bridging the gap between theory (computer science) and practice (life as a software engineer at Amazon). While walking through code with a principle engineer, he described the data structure he came up with that (classically) traded space for lookup performance, describing an index that bounds the binary search. To clarify the data structure, he “whiteboarded” with me, using (an internally hosted) draw.io, and the figures made me realize that the data structure resembles how page tables in operating systems are designed.
Mental and Physical Health
Remembered to stretch my hamstrings a couple days throughout the day. Not really enough exercise but the best I could do given that the weather outside still is labeled “very unhealthy” due to the wildfire smokes.
Graduate School
Watched a few more lectures from the “Barrier Synchronization” series, learning more about the tree barrier and the tournament barriers, two slightly more advanced data structures than the simplistic centralized barrier
Finished putting together my submission, a .zip file containing: source code, Makefile, log files (from running my program against the test cases).
Work
Met with a Vietnamese senior principle engineer yesterday who I reached out to for two reasons: asking him to participate in a future event that I’ll host on behalf of Asians@ and asking him for some tips given he’s excelled (at least on paper) in his career while bringing his full self to work (i.e. being a father).
Walked through some C data structures with a principle engineer and successfully imported the code (with a few minor tweaks) into my team’s package
During my 1:1 with my manager, he straight up asked me if I was leaving the team. I realized that I may have given him that impression because during a team meeting, I spoke up about how if the operations on the team continues to disturb me and wake me up consistently in the middle of the night then I would reconsider switching teams, which is true. Although I love my position and love what I’m doing at work, I do value other things such as a good nights sleep because poor sleep means poor mental health which leads me down a very dark path.
Family and Friends
Watched after my daughter yesterday morning from 06:00 to 06:45, allowing my wife to catch up on some sleep due to a difficult night with Elliott, who we think is teething, given that she’s been waking up in the middle of the night, waking up more than usual.
Left a couple voice notes in WhatsApp for my brother-in-law, who is getting into writing and who asked me for some suggestions on writing platforms to host his blogging content. In short, I say it doesn’t really matter all that much but what does matter is that he owns his content and syndicates it out
Miscellaneous
Downloaded 30 days of Wells Fargo and Morgan Stanley transaction history, proving that my wife and I have the funds needed to complete the transaction on September 30th, the day we close on our house located in Renton
Today
Writing
Publish Part 1 of Barrier Synchronization notes
Publish this post (my daily review)
Mental and Physical Health
Stretch stretch stretch! Add a 5 minute event that notifies you on your phone so that step back from your desk and reach for your toes. Squat a couple times. Drop to the ground for a couple push ups. Get that heart pumping!
Submit code review for small feature the optimizations look up time on the packet path
Administrative
Attend my dentist appointment at 02:30 in the afternoon. How the hell is that going to work with the pandemic? Obviously I won’t be able to wear a mask with the pandemic … I should probably give them a ring this afternoon, before stepping into the appointment
Family
Pack pack pack! There’s only a couple weeks left until we are out of this house. It’s difficult to pack at the end of the day because both Jess and I are both exhausting, her from watching Elliott and me from working. But maybe we can pack while eating dinner instead of sprawling out on the couch and watching “Fresh off the boat” (one of my favorite TV series, I think)
I had mentioned yesterday that I slept horribly, waking up early and starting day off at around 03:45 AM. That wake up time was brutal and as a result, I crashed and burned in the afternoon, leveraging those precious 30 minutes of my lunch to nap in my wife’s / daughter’s bedroom (a room with an actual mattress, unlike my office, where I’m sleeping on the floor on top of a tri-folding piece of foam).
I slept so well during that afternoon nap that I didn’t hear the ear piercing alarm that I set on my TIMER YS-390 ; luckily I warned my wife before hand and had asked her to wake me up just in case I overslept. Thankfully she did.
Yesterday, I had suspected that I woke up so early and slept so poorly due to the loud air conditioner shaking on and off throughout the night, but I’m 100% confident of what woke me up this morning at 03:00: my daughter belting out a loud scream (and then immediately fell back asleep).
Yesterday
I’m in great company while working from home. Here’s metric sleeping by my foot
Writing
Published my daily review
Best parts of my day
The afternoon 30 minute nap. Seriously. The nap makes me wonder how I would’ve taken that sort of break if I were not working remote and if I were working back in the office?
Mental and Physical Health
Attended my weekly therapy session with good old Roy. As anticipated, we followed up on our tension filled conversation that occurred last week. What was comforting and brought me solace was that he opened up (just a little) and shared that he was similar to me in the sense that he often will take on additional work that just needs to be done, a person who sees a hole and fills it. That conversation made me think of the term transference: “a phenomenon in which an individual redirects emotions and feelings, often unconsciously, from one person to another.”
Graduate School
Watched no lectures yesterday (as mentioned, I was like a zombie) and instead ran my programs (i.e. virtual CPU scheduler and memory coordinator) across the various use cases, collecting all the terminal output that I’ll need to include as part of the submission
Work
Conducted an “on site” interview. I say onsite but because of COVID-19, all interviews are held over (Amazon) Chime.
Debugged an unexpected drop in free memory and realized that it pays off to be able to distinguish memory allocations happening on the stack versus memory allocations happening else where (like shared memory in the kernel).
Family and Friends
Miscellaneous
Got my second hair cut this year (damn you COVID-19) at nearby hair salon. I love the hair salon for a multiple reasons. First, the entire trip — from the moment I leave my house, to the moment I return back — takes 30 minutes, a huge time saver. Second, the stylist actually listens to what I want (you’d be surprised how many other stylists get offended when I tell them what I want and what I don’t want) and gives me a no non-sense hair cut. And third, the hair cut runs cheap: $20.00. What a steal! I don’t mind paying more for hair cuts (I was previously paying triple that price at Steele Barber).
Today
Mainly will just try to survive the day and not collapse from over exhaustion. If I can somehow afford the time, I’d like to nap this afternoon for half an hour. Will gladly trade off 30 minutes of lunch if that means not being zapped of all my energy for the remainder of the day.
Writing
Publish “Synchronization” notes (part 2)
Publish daily review (this one that I’m writing right here)
Mental and Physical Health
Attending my weekly therapy session today at 09:00 AM. Will be an interesting session given how entangled we got last week.
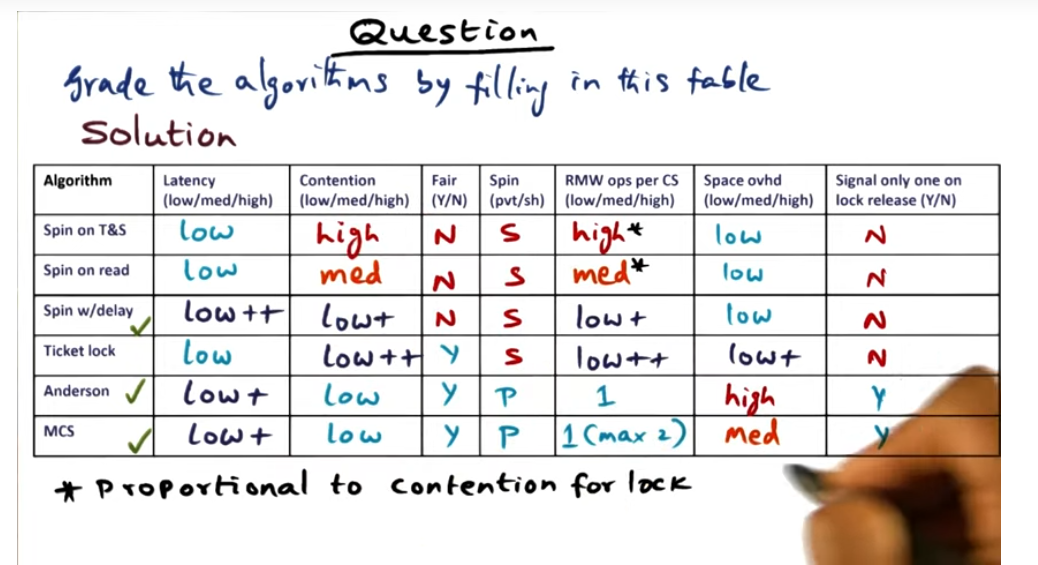
In part 1 of synchronization, I talked about the more naive spin locks and other naive approaches that offer only marginally better performance by adding delays or reading cached caches (i.e. avoiding bus traffic) and so on. Of all the locks discussed thus far, the array based queuing lock offers low latency, low contention and low waiting time. And best of all, the this lock offers fairness. However, there’s no free lunch and what we trade off performance for memory: each lock contains an array with N entries where N is the number of physical CPUs. That high number of CPUs may be wasteful (i.e. when not all processors contend for a lock).
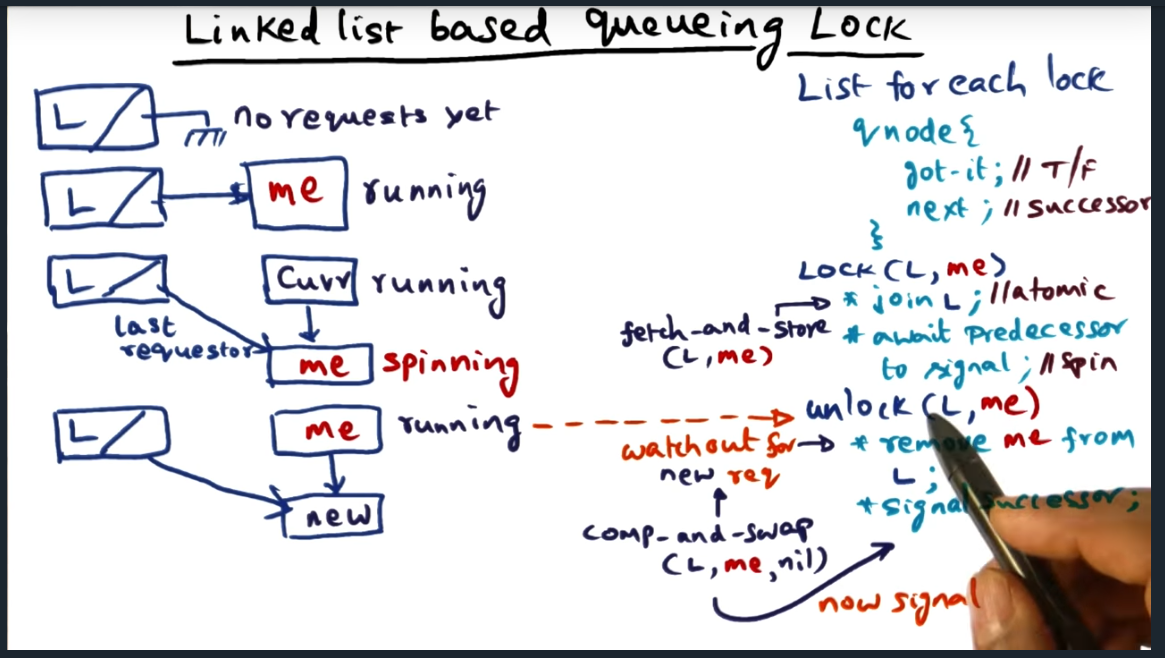
That’s where linked based queuing locks come in. Instead of upfront allocating a contiguous block of memory reserved for each CPU competing for lock, the linked based queuing lock will dynamically allocate a node on the heap and maintain a linked list. That way, we’ll only allocate the structure as requests trickle in. Of course, we’ll need to be extremely careful with maintaining the linked list structure and ensure that we are atomically updating the list using instructions such as fetch_and_store during the lock operation.
Most importantly, we (as the OS designer that implement this lock) need to carefully handle the edge cases, especially while removing the “latest” node (i.e. setting it’s next to NULL) while another node gets allocated. To overcome this classic race condition, we need to atomically rely on a new (to me at least) atomic operation: compare_and_swap. This instruction will be called like this: compare_and_swap(latest_node, me, nil). If the latest node’s next pointer matches me, then set the next pointer to NIL. Otherwise, we know that there’s a new node in flight and will have to handle the edge case.
Anyways, check out the last paragraph on this page if you want a nice matrix that compares all the locks discussed so far.
Linked Based Queuing Lock
Summary
Similar approach to Anderson’s array based queueing lock, but using a linked list (authors are MCS: mellor-crummey J.M. Scott). Basically, each lock has a qnode associated with it, the structure containing a got_it and next. When I obtain the lock, I point the qnode towards me and can proceed into the critical section
Link Based Queuing Lock (continued)
Summary
The lock operation (i.e. Lock(L, me)) requires a double atomic operation, and to achieve this, we’ll use a fetch_and_store operation, an instruction that retrieves the previous address and then stores mine
Linked Based Queuing Lock
Summary
When calling unlock, code will remove current node from list and signal successor, achieving similar behavior as array based queue lock. But still an edge case remains: new request is forming while current thread is setting head to NIL
Linked Based Queuing Lock (continued)
Summary
Learned about a new primitive atomic operation called compare and swap, a useful instruction for handling the edge of updating the dummy node’s next pointer when a new request is forming
Linked Based Queuing Lock (continued)
Summary
Hell yea. Correctly anticipated the answer when professor asked: what will the thread spin on if compare_and_swap fails?
Linked Based Queuing Lock (continued)
Summary
Take a look at the papers to clarify the synchronization algorithm on a multi-processor. Lots of primitive required like fetch and store, compare and swap. If these hardware primitives are not available, we’ll have to implement them
Linked Based Queuing Lock (continued)
Summary
Pros and Cons with linked based approach. Space complexity is bound by the number of dynamic requests but downside is maintenance overhead of linked list. Also another downside potentially is if no underlying primitives for compare_and_swap etc.
Algorithm grading Quiz
Comparison between various spin locks
Summary
Amount of contention is low, then use spin w delay plus exponential backoff. If it’s highly contended, then use statically assigned.