Today is going to be rough. I slept horribly, waking up multiple times throughout the night. Ultimately, I rolled out of my tri-folding foam mattress (a temporary bed while my daughter and wife sleep on the mattress in a separate room as to not wake me up: that parent life) at 03:45 AM this morning. Perhaps the gods above are giving me what I deserve since I had complained yesterday that I had “slept in” and as a result didn’t get a chance to put in any meaningful work before work. So now they are punishing me. Touché. Touché.
Yesterday
Fell into a black hole of intense focus while hunting down a bug that was crashing my program (for project 1 of advanced operating systems). Sometimes I make the right call and distance myself from a problem before falling into a viscous mental loop and sometimes (like this scenario) I make the right call and keep at a problem and ultimately solve it.
Writing
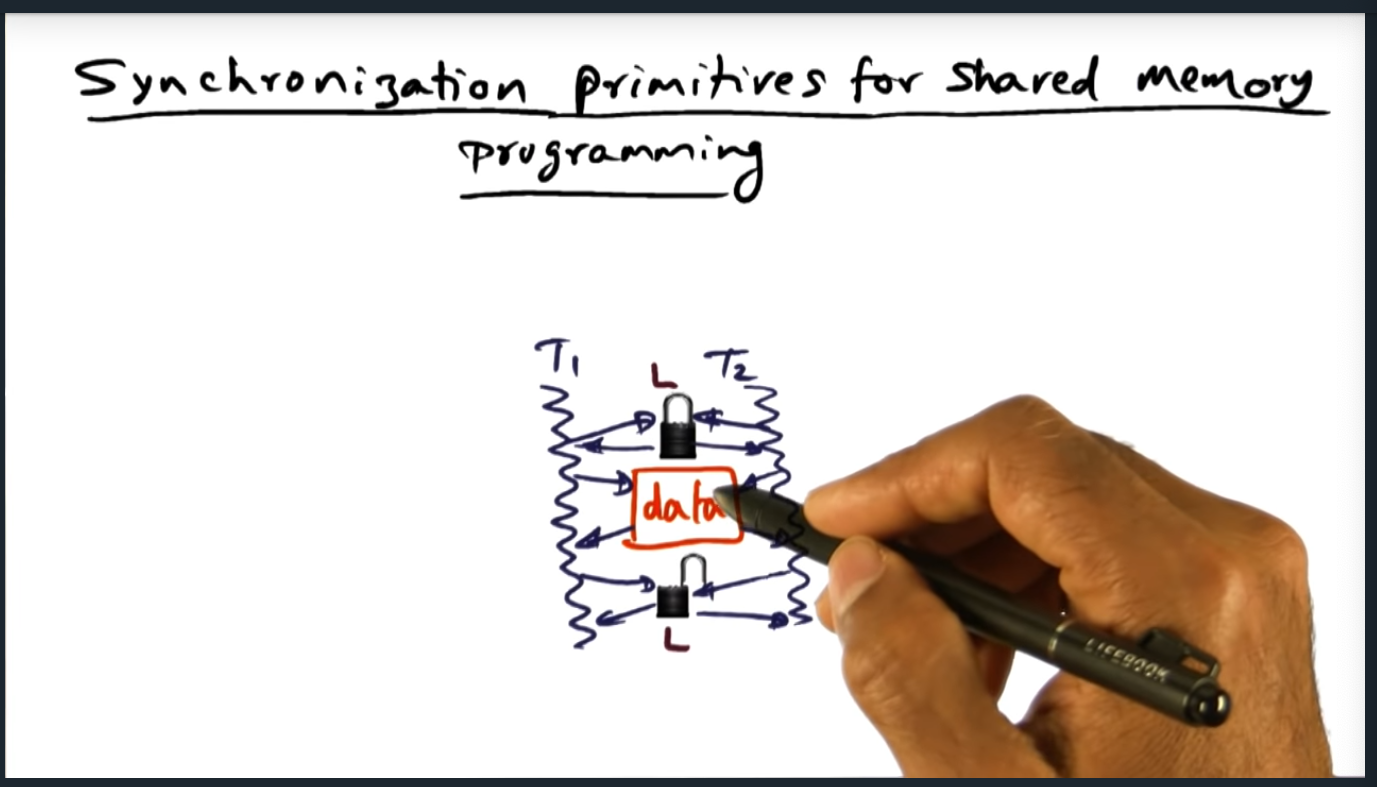
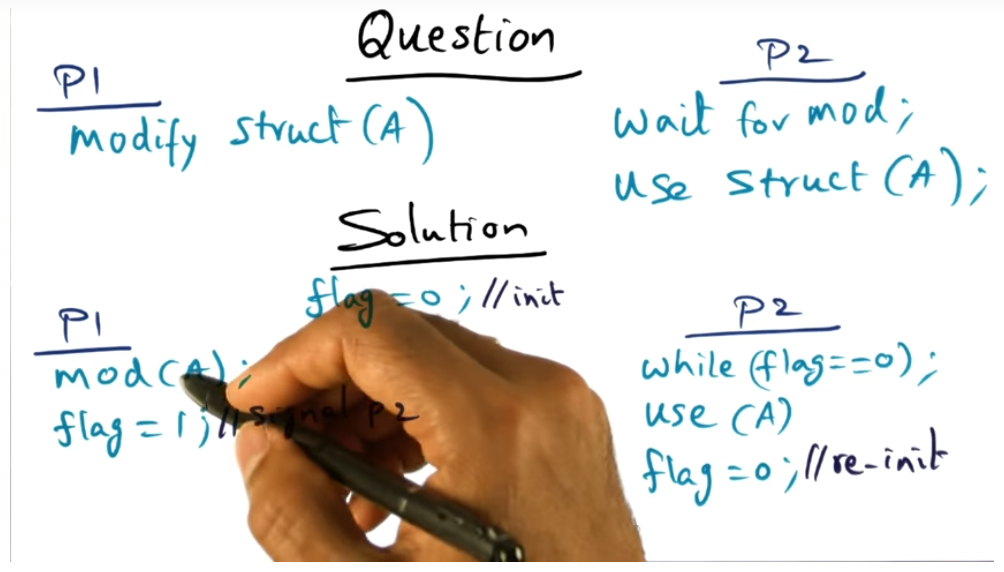
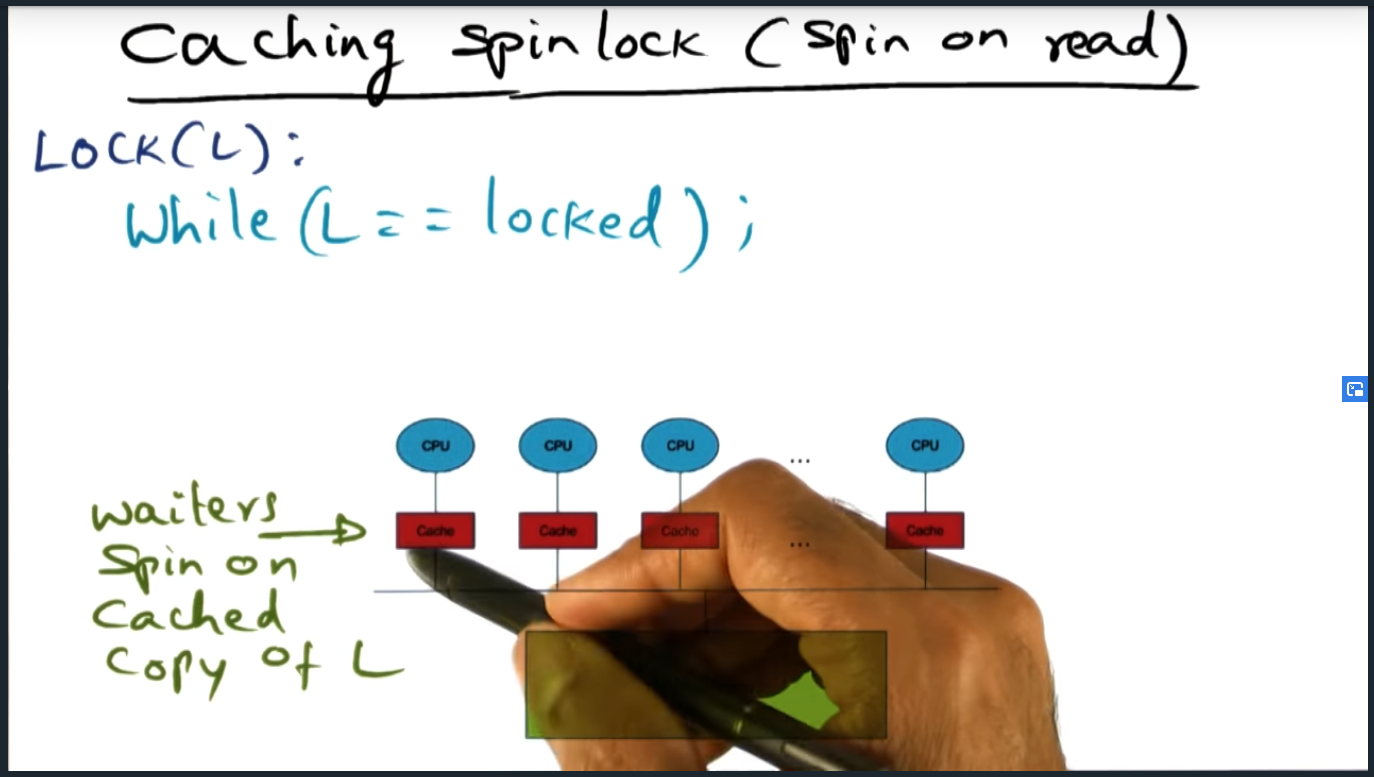
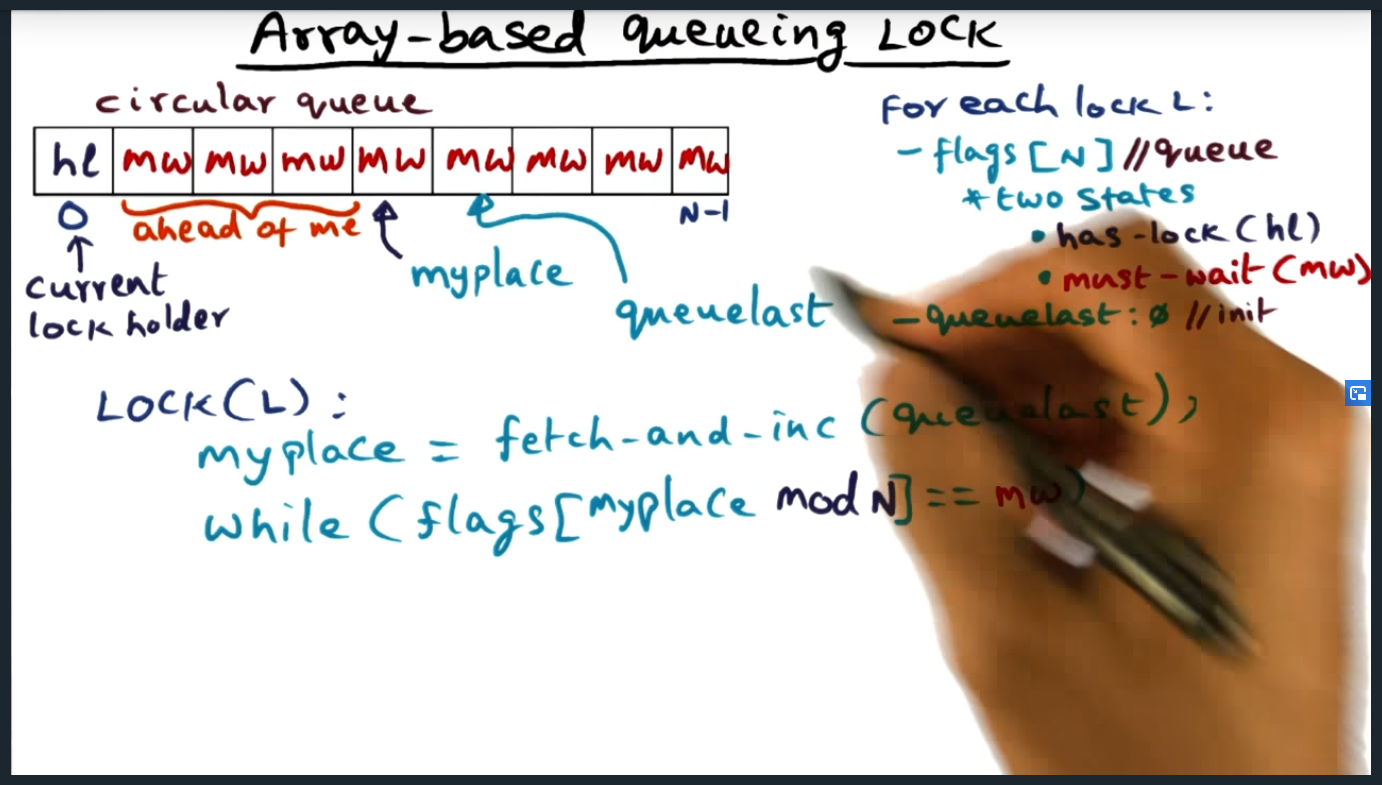
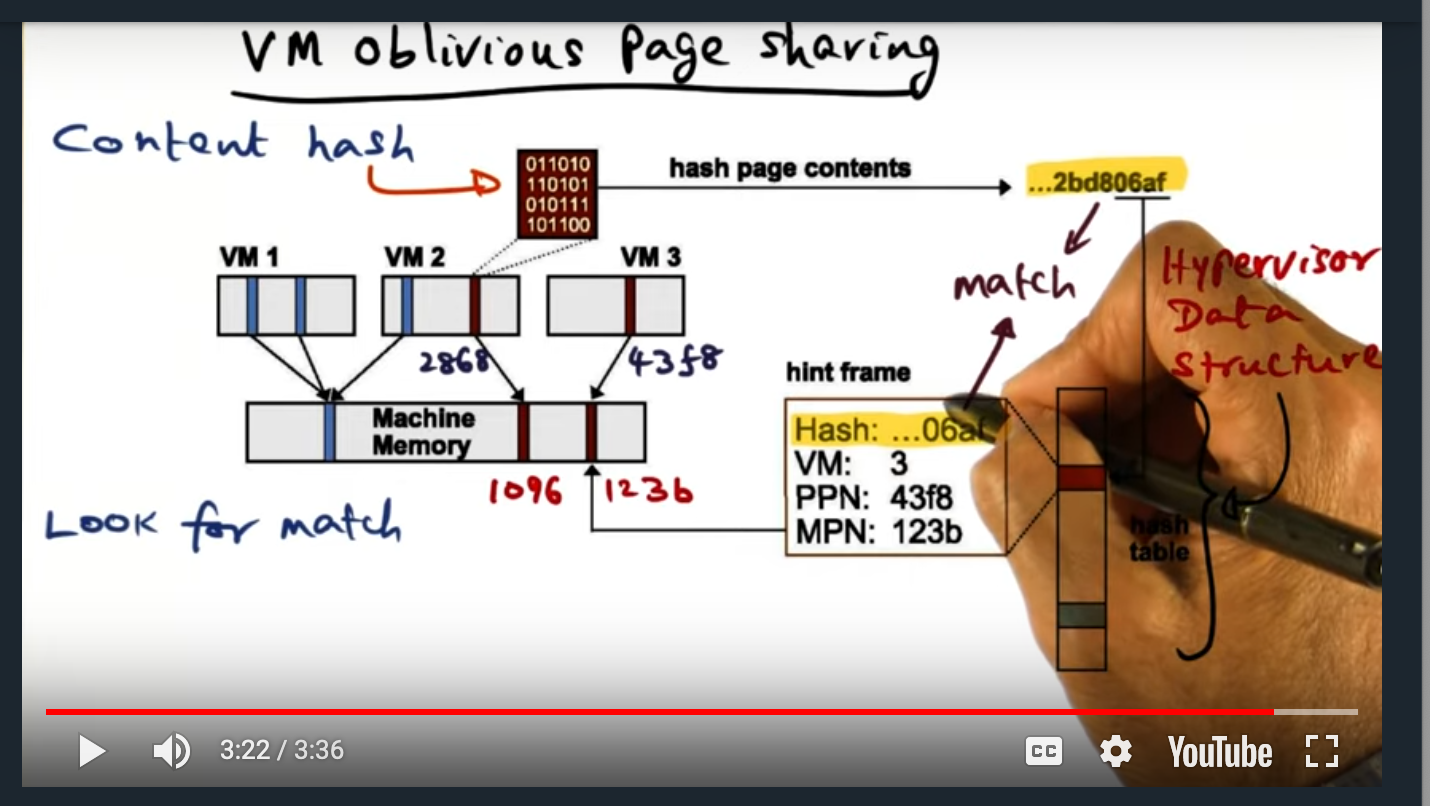
- Published part 1 notes on synchronization (up until array based queuing lock)
Best parts of my day

- Teaching Elliott how to shake her head and signal “no”. For the past few months, I’ve tried to teach her during our daily bathes but when I had tried to previously teach her, her body and head were not cooperating with her. When she had tried say no, she was unable to interdependently control her head movement, her entire body would turn left and right along with her. But yesterday, she got it and now, she loves saying “no” even though she really means yes. She’s so adorable.
- Jess yelling out for me to rush over to the bathroom to help her … pick up Elliott’s poop that rolled out of her diaper, two nuggets falling out, one landing on the tile floor while the other smashing on the floor mat
- Catching up over the phone with my friend Brian Frankel. He’s launched a new start up called Cocoon, his company aiming to solve the problem of slimy mushrooms and slimy strawberries in the refrigerator. I had bought one of his new inventions mainly to support his vision (it’s always nice to support friends) but also I’m a huge fan of refrigerator organization and cleanliness. Unfortunately, the box arrived broken (looks like something heavy in the delivery truck landed on the box, crushing it into pieces)
Mental and Physical Health
- At the top of the hour (not every hour, unfortunately) I hit the imaginary pause button, pulling my hands off the keyboard and stepping back from my standing desk to stretch my hamstrings and strengthen my hips with Asians squats
Graduate School
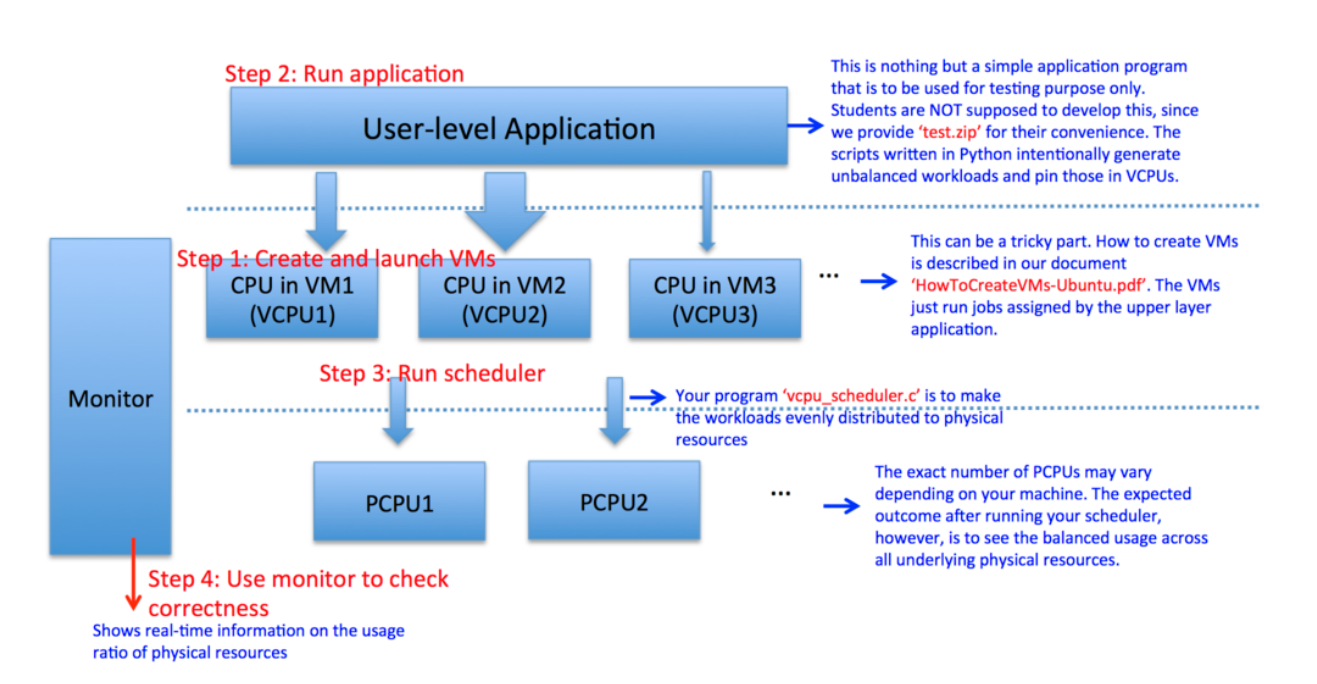
- Watched no lectures yesterday, all the time (about 2 hours) dumped into polishing up the virtual CPU scheduler, adding a new “convergence” feature that skips the section of code that (re)pins the virtual CPUs to physical CPUs, skipping when the standard deviation falls 5.0% (an arbitrary number that I chose)
- Wrestled with my program crashing. The crashes’s backtrace was unhelpful since the location of the code that had nothing to do with the code that I had just added.
Work
- Attended a meeting lead by my manager, the meeting reviewing the results of the “Tech Survey”. The survey is released by the company every year, asking engineers to answer candidly to questions such as “Is your work sustainable?” or “Is your laptop’s hardware sufficient for your work?”. Basically, it allows the company to keep a pulse of how the developer experience is and is good starting point for igniting necessary changes.
- Stepped through code written by a principle engineer, C code that promised to bound a binary search by trading off 2 bytes to serve as an index.
Family and Friends
- Fed Elliott during my lunch. Was extremely tiring (but at the same time, enjoyable) chasing her around the kitchen floor, requiring me constantly squat and constantly crawl. She’s mobile now, working her way up to taking one to two steps.
- Bathed Elliott last night and taught her how to touch her shoulders, a body part she’s been completely unaware of. Since she loves playing with my wedding right, I let her play with during our night time routine and last night I would take the ring, and place the ring on her infant sized shoulder, pointing to it and guiding her opposite hand to reach out to grab the ring.
- Caught up with one of our friends over Facetime. Always nice to see a familiar face during COVID-19, a very isolating experience that all of society will look back on in a few years, all of us wondering if it just all a bad dream because that’s what it feels like
Miscellaneous
- Got my second hair cut this year (damn you COVID-19) at nearby hair salon. I love the hair salon for a multiple reasons. First, the entire trip — from the moment I leave my house, to the moment I return back — takes 30 minutes, a huge time saver. Second, the stylist actually listens to what I want (you’d be surprised how many other stylists get offended when I tell them what I want and what I don’t want) and gives me a no non-sense hair cut. And third, the hair cut runs cheap: $20.00. What a steal! I don’t mind paying more for hair cuts (I was previously paying triple that price at Steele Barber).
Today
Mainly will just try to survive the day and not collapse from over exhaustion. If I can somehow afford the time, I’d like to nap this afternoon for half an hour. Will gladly trade off 30 minutes of lunch if that means not being zapped of all my energy for the remainder of the day.
Writing
- Publish “Synchronization” notes (part 2)
- Publish daily review (this one that I’m writing right here)
Mental and Physical Health
- Attending my weekly therapy session today at 09:00 AM. Will be an interesting session given how entangled we got last week.
Graduate School
- Write up the README for the two parts of my project
- Change the directory structure of project 1 so that the submission validator passes
- Submit the project to Canvas
- Watch 30 minutes worth of lectures (if my tired brain can handle it today)
Work
- Interview a candidate “on-site” later this afternoon
- Continue troubleshooting unreproducible fuzzing failure (will try to tweak our fuzzer for a potential out of memory issue)
Family
- Pack a couple more boxes with Jess. Only a couple more weeks and we move our family unit into a new home in Renton.