This post is a continuation of virtualization. In the previous post, I talked about memory virtualization. This post instead discusses CPU and device virtualization.
Ultimately, as system designers, one of our chief aims is to provide an illusion to the underlying guest operating systems that they each individually won the underlying hardware, the CPU and IO devices. But how do will the guest OS transfer control back and forth to and from the hypervisor?
In a fully virtualized environment (i.e. guest OS has no awareness that it is virtualized), the guest operating communicates to the hypervisor via the standard way: sending traps. Unfortunately, this leaves little room for innovation, which is why in a para virtualized environment (i.e. guest OS contains specific code to communicate with the hypervisor) optimizes the communication by sharing a ring buffer (i.e. producer and consumer model)
Through this shared buffer, the guest VM and hypervisor send messages to one another, the messages containing pointers — not raw data — to buffer allocated by the either the guest operating or allocating by the hypervisor. This efficient method of communication prevents the need to copy buffers between the two entities.
Introduction
Summary
With CPU virtualization, there are two main focuses: giving the illusion to the guest that it owns the CPU and having the hypervisor field events (but what the hell is a discontinuity) ?
CPU Virtualization
Summary
Two techniques for CPU scheduling. Proportional share (commensurate with use) and fair share scheduler: everyone gets the same slice of the pie.
Device Virtualization Intro
Summary
Want to give guest illusion that they own the IO devices
Device Virtualization
Summary
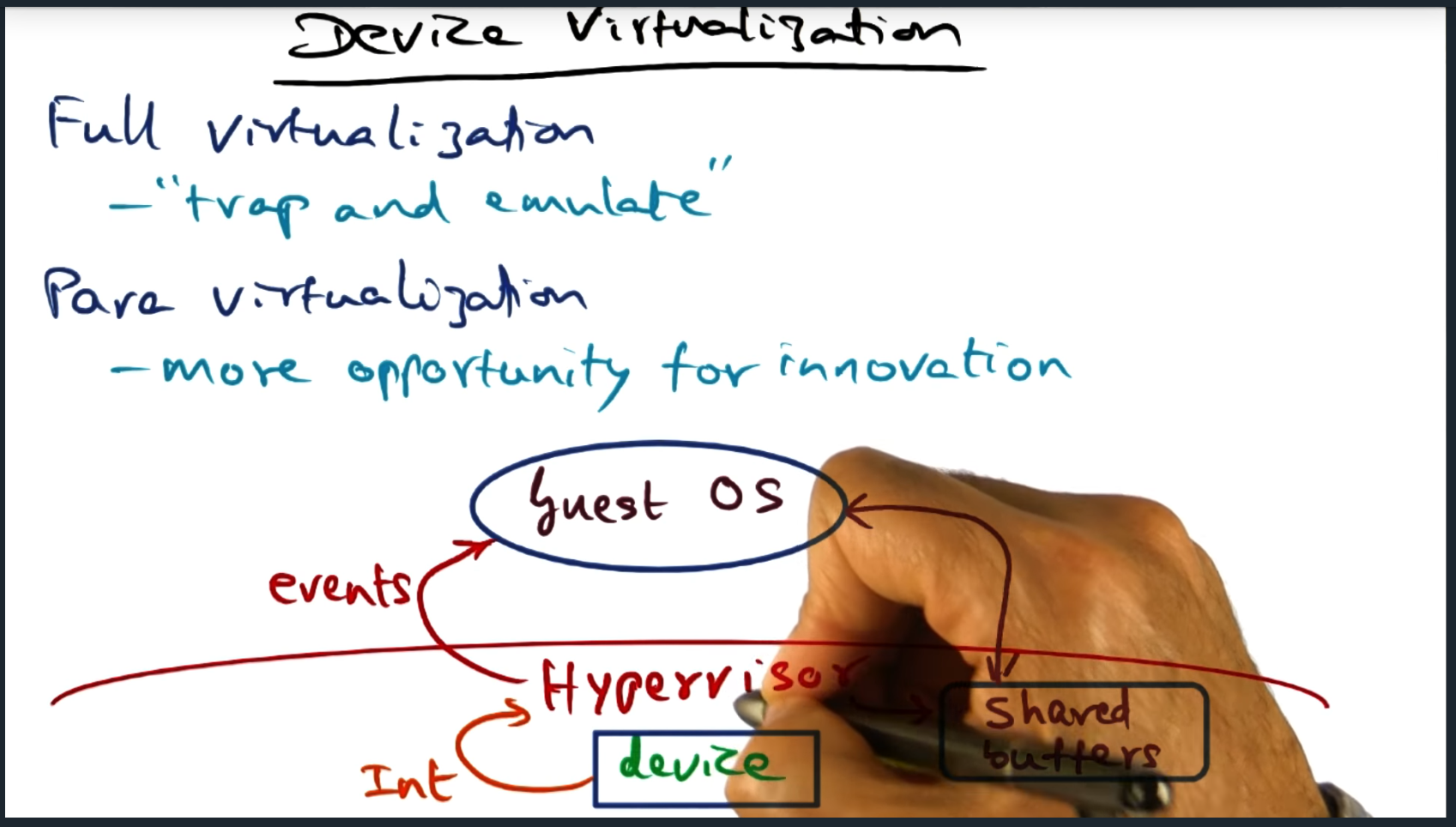
In a fully virtualized guest OS, there’s little room to innovate for device IO since the mechanism is really just a trap and emulate (by the hypervisor). In contrast, para virtualization offers lots of opportunities for optimization, including utilizing shared buffers. However, we need to figure out how to transfer control back and forth between the guest OS and the hypervisor
Control Transfer
Summary
In a full virtualization environment, control from guest to hypervisor happens through a trap. Whereas in the para virtualization, the guest OS sends hyper calls. However, in both full and para virtualization, the hypervisor communicates to the guest OS via software interrupts.
Data Transfer
Summary
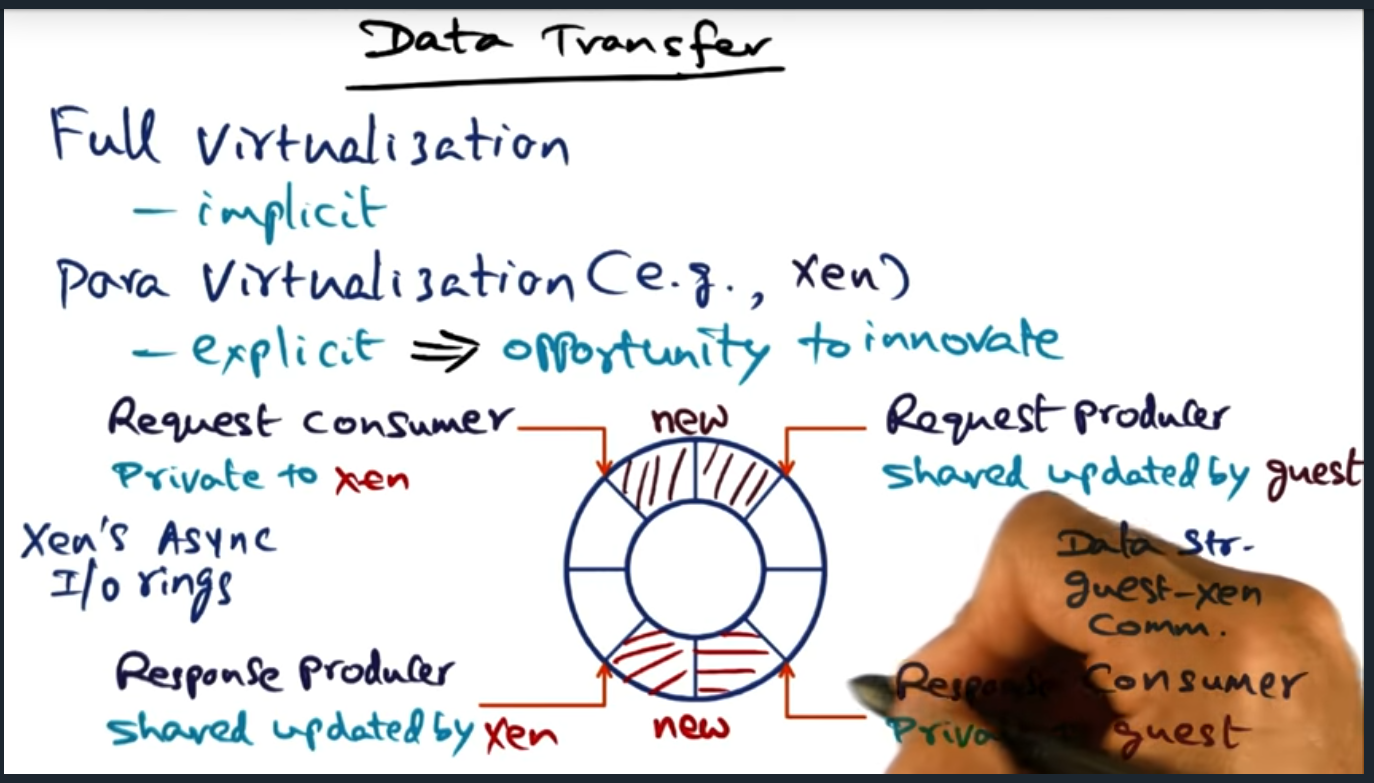
Data transfer in a para virtualization system is fascinating: the guest VM and the hypervisor share a IO circular buffer. The guest VM produces data and the hypervisor consumes it, the guest VM maintaining a pointer to the position of the data. And in the response path, the hypervisor maintains a pointer, on the same IO circular buffer, that tracks the responses (and where the guest VM tracks a private buffer)
Control and Data Transfer in Action
Summary
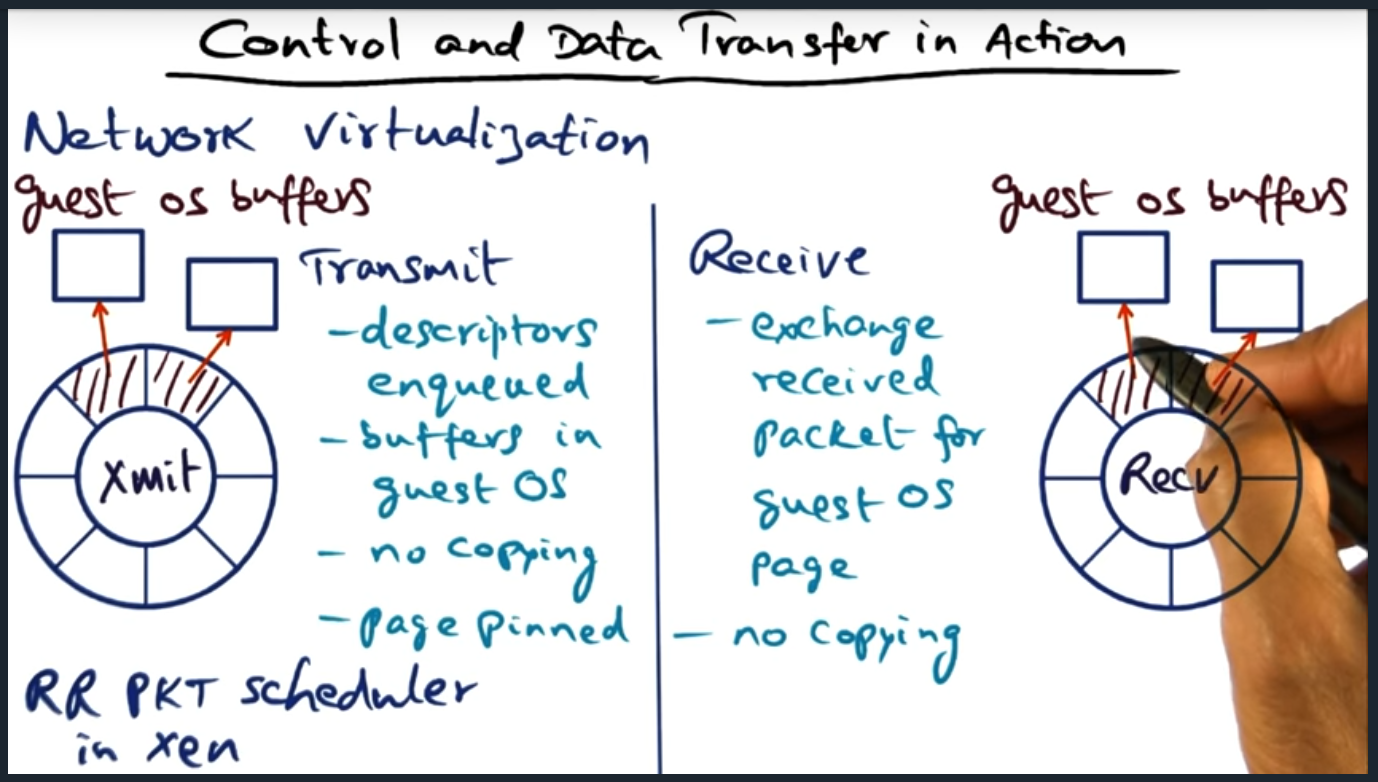
Pretty amazing how the hypervisor and guest VM work together to avoid copying data between address spaces. To this end, the guest VM will transmit data by maintaining a circular buffer and copy the pointers into the hypervisor, so no data is copied (just pointers). Same approach in the opposite direction, when hypervisor receives packet and then forwards it to the guest.
Disk IO Virtualization
Summary
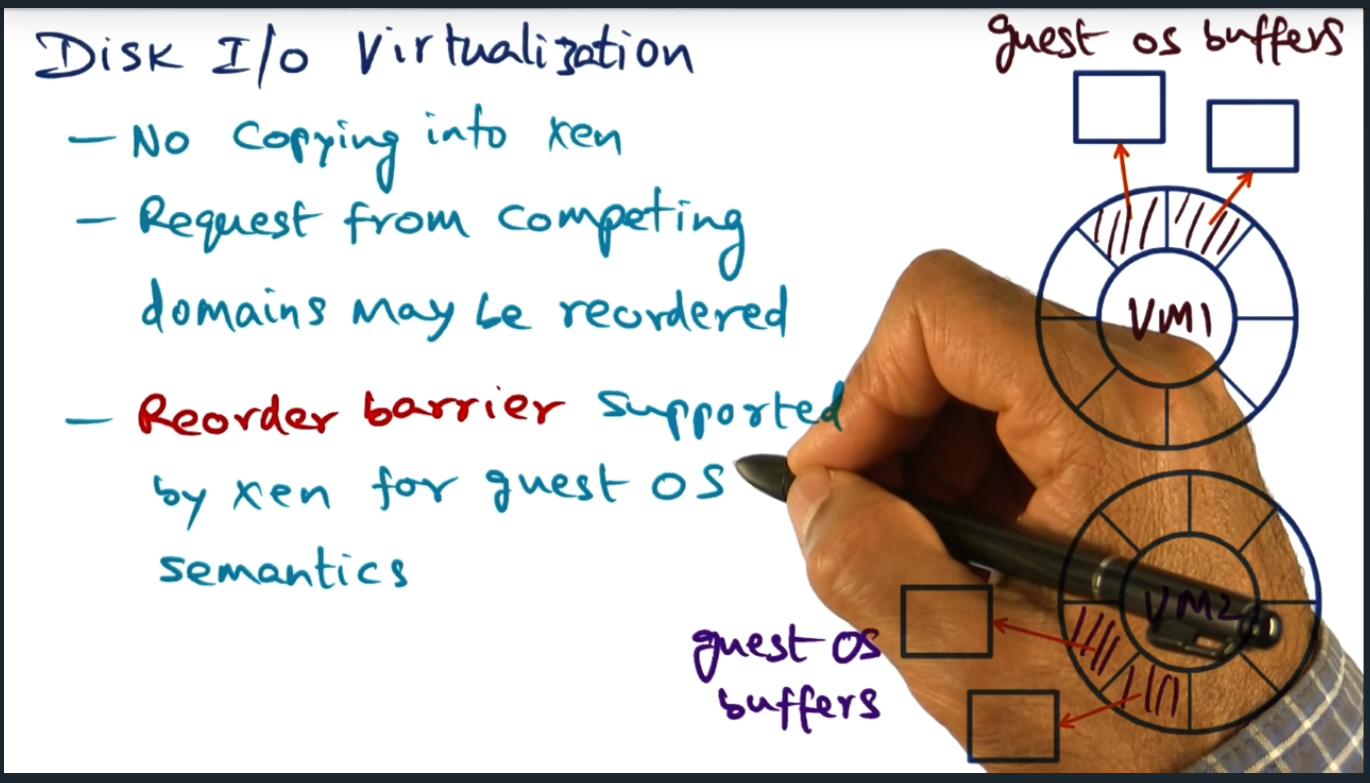
Pretty much identical to data transfer in network IO virtualization. Except that Xen offers a reorder barrier to support higher level semantics like write ahead logging (a topic that seems really interesting to me: I’d be curious how to build a database from the ground up)
Measuring Time
Summary
Fundamental tenet is utility computing so we need a way to accurately bill users
Xen and guests
Summary
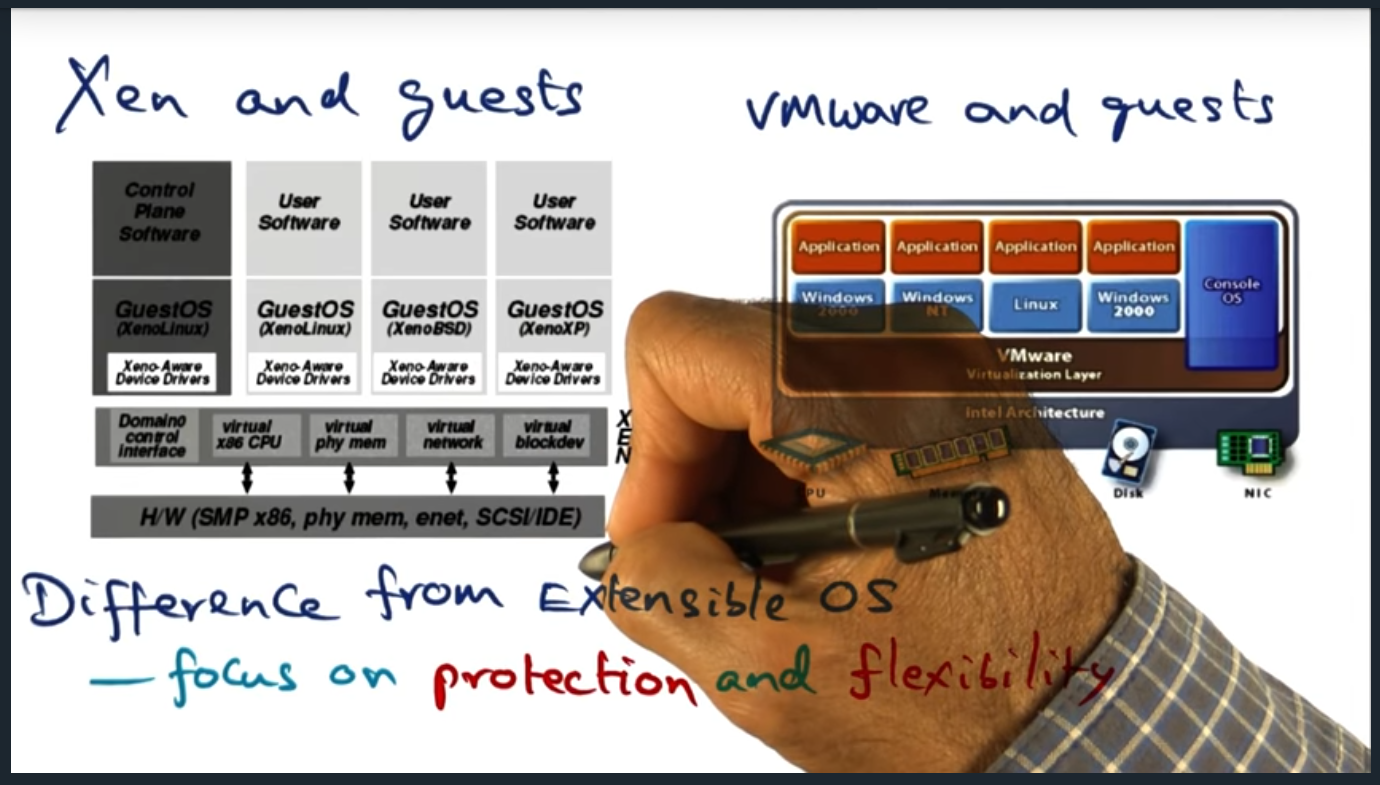
Xen offers para virtualization and VMWare offers fully virtualization (i.e. guest VM has no clue). Regardless, virtualization focuses on protection and flexibility, trading off performance