The main take away with the introduction to distributed systems lectures is that as system designers, we need to carefully inspect our program and identify what events in our system can run concurrently (as well as what cannot run concurrency or must be serialized). To this end, we need to identify what events must happen before other events. And most importantly, we should only consider running distributed systems to increase performance when the time it takes to process an event exceeds the time it takes to send a message between nodes. Otherwise, just stick to local computation.
Lots of similarity between parallel systems and distributed systems. Symbiotic relationship between hardware and software (protocol stack)
Quiz: What is a distributed system?
Summary
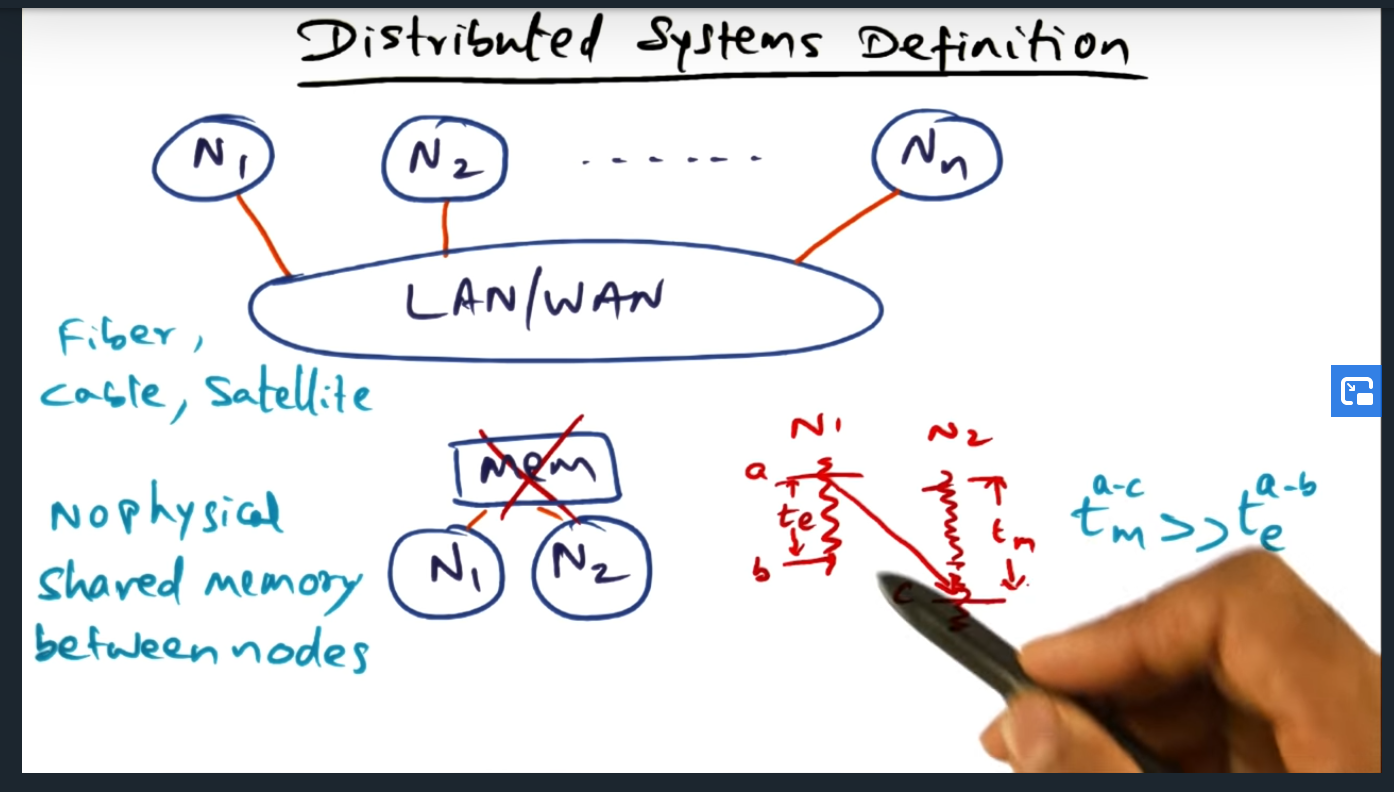
Distributed systems are connected via a LAN/WAN, communicate only via messages, and message time is greater than the event time (not sure what this means really)
Distributed Systems Definition
Summary
Key Words: event computation time, message transmission time; Third property is that message communication time is significantly larger than the event computation time (on a single node). Leslie’s definition is: A system is distributed if the message transmission time (TM) is not negligible to the time between events in a single process. The main take away is that the algorithms or applications run on distributed noes must take longer (in computation time) than the communication otherwise no benefit of parallelism.
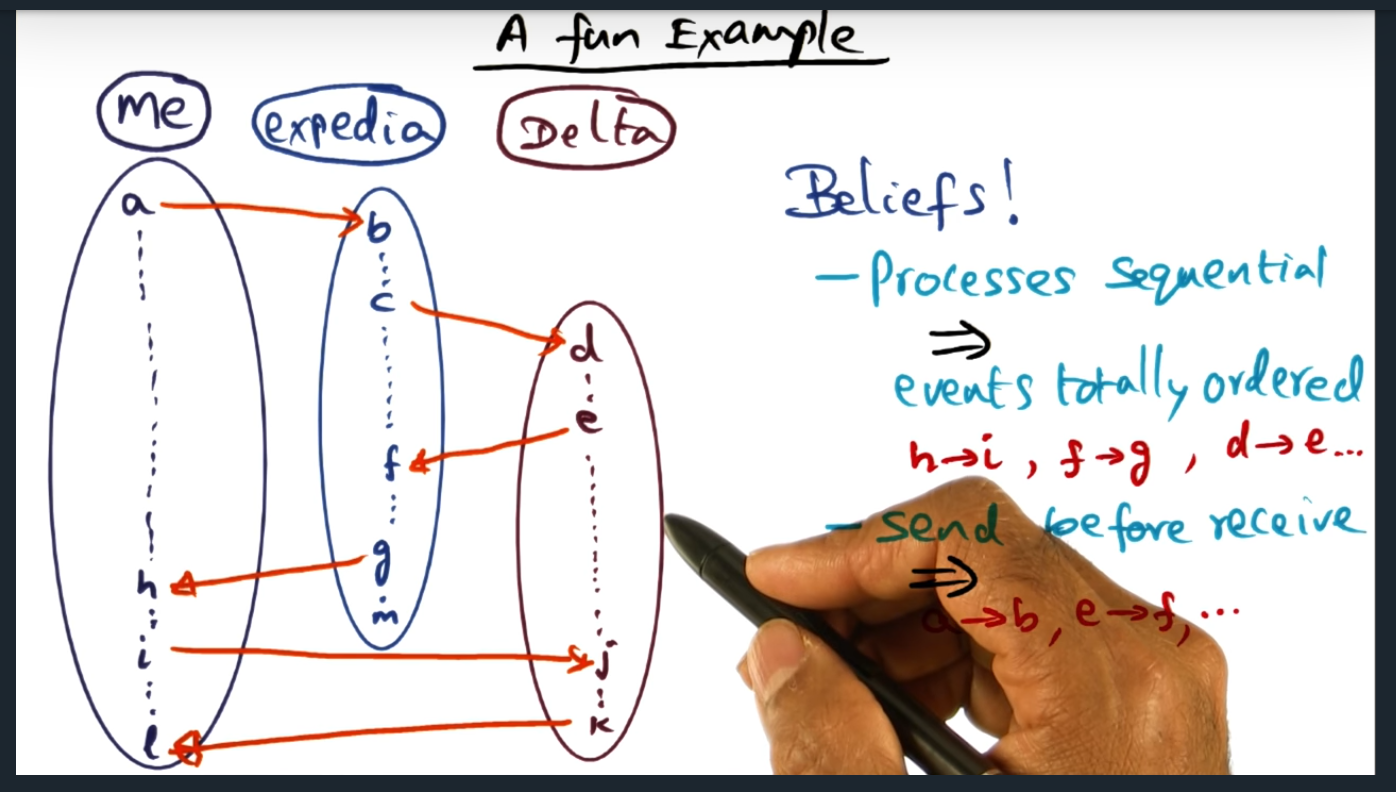
A fun example
Summary
Key Words: happened before relationship; Set of beliefs ingrained in a distributed system example. Within a single process, events are totally ordered. Second belief is that you cannot receive the receipt of a message until after the initial message is sent.
Happened Before Relationship
Happened Before Event description
Summary
The happened before relationship means one of two things. For events A and B, it means that 1) A and B are in the same process or 2) A is the sender of the message and B is the receiver of the message
Quiz Relation
Summary
You cannot assume or say anything about the order of A and B
Happy before relationship (continued)
Summary
When you cannot assume the ordering of events, they might be concurrent. One event might run before the other during one invocation. Then perhaps the order gets flipped. So, these types of events are not happened before, no apparent relationship between the two events. But my question is: what are some of the synchronization and communication and timing issues that he had mentioned?
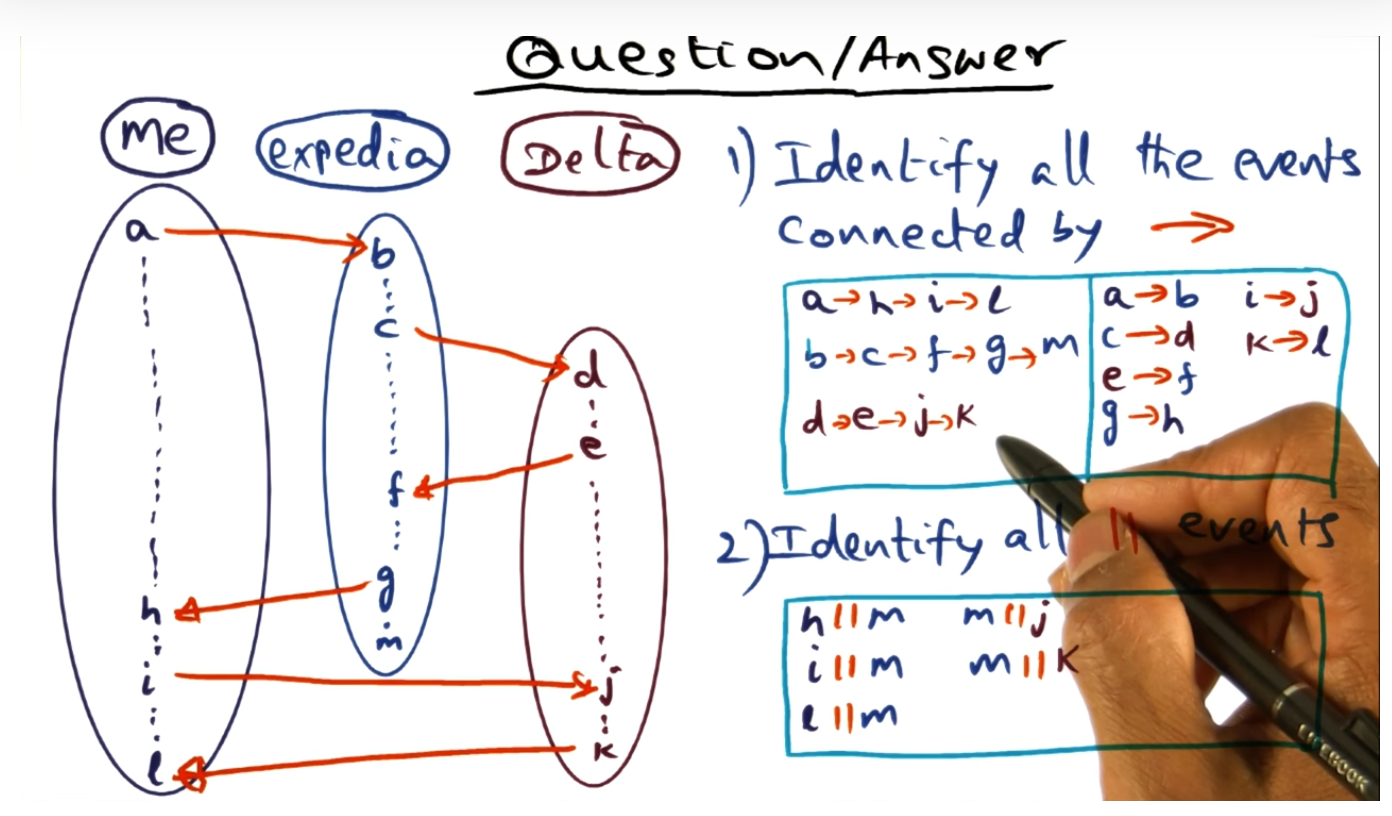
Identifying Events
Identifying concurrent and dependent and transitive events
Summary
Remember the events that “happened before” are not only between processes but within processes themselves. Also, two concurrent events are basically when we cannot guarantee whether or not an event in process A will run before an event in process B, again between processes
Example of Event Ordering
Summary
Basically the events between processes can be concurrent since there’s no guarantee in terms of wall clock time when they will execute, no ordering
I’m watching the YouTube learning series called “Introduction to OpenMP” in order to get a better understanding of how I can use the framework for my second project in advanced operating systems. You might find the below notes useful if you don’t want to sit through the entire video series.
Introduction to OpenMP: 02 part 1 Module 1
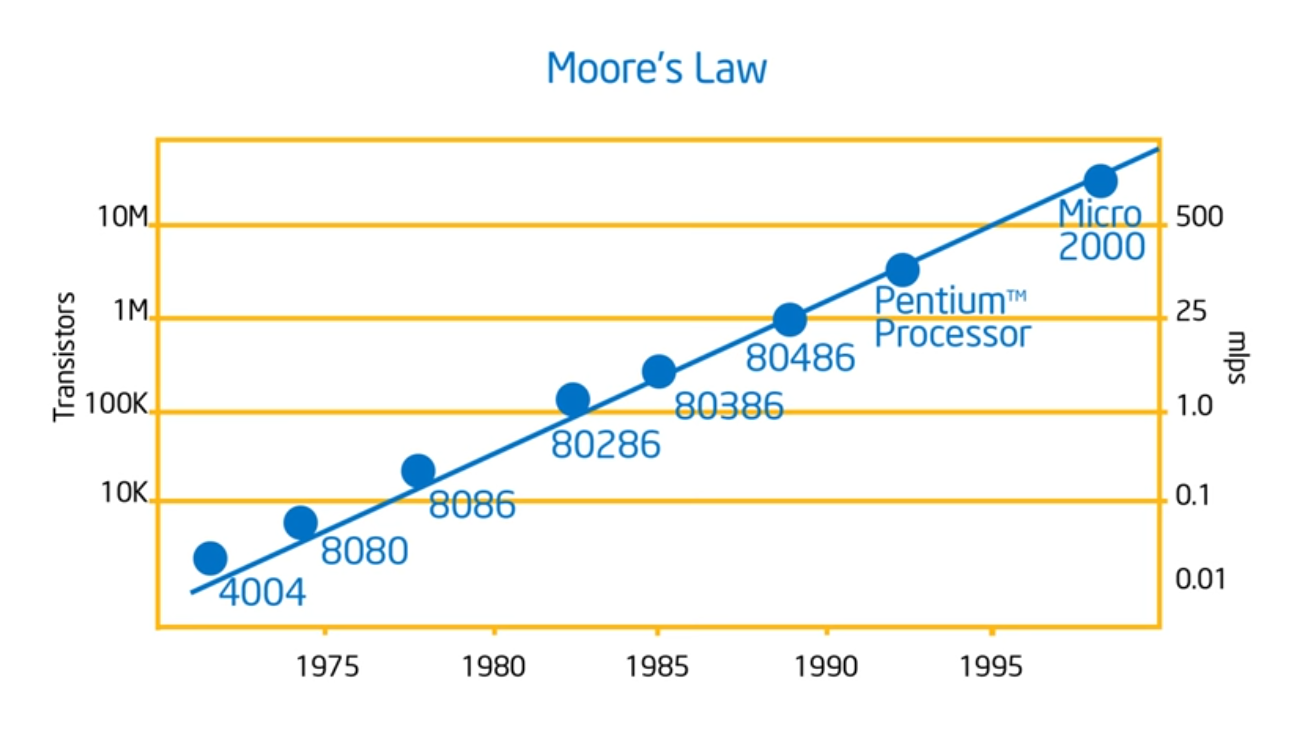
Moore’s Law
Summary
Neat that he’s going over the history, talking about Moore’s Law. The key take away now is that hardware designers are now going to optimize for power and software developers have to write parallel programs: there’s no free lunch. No magic compiler that will take sequential code and turn it into parallel code. Performance now c
Introduction to OpenMP – 02 Part 2 Module 1
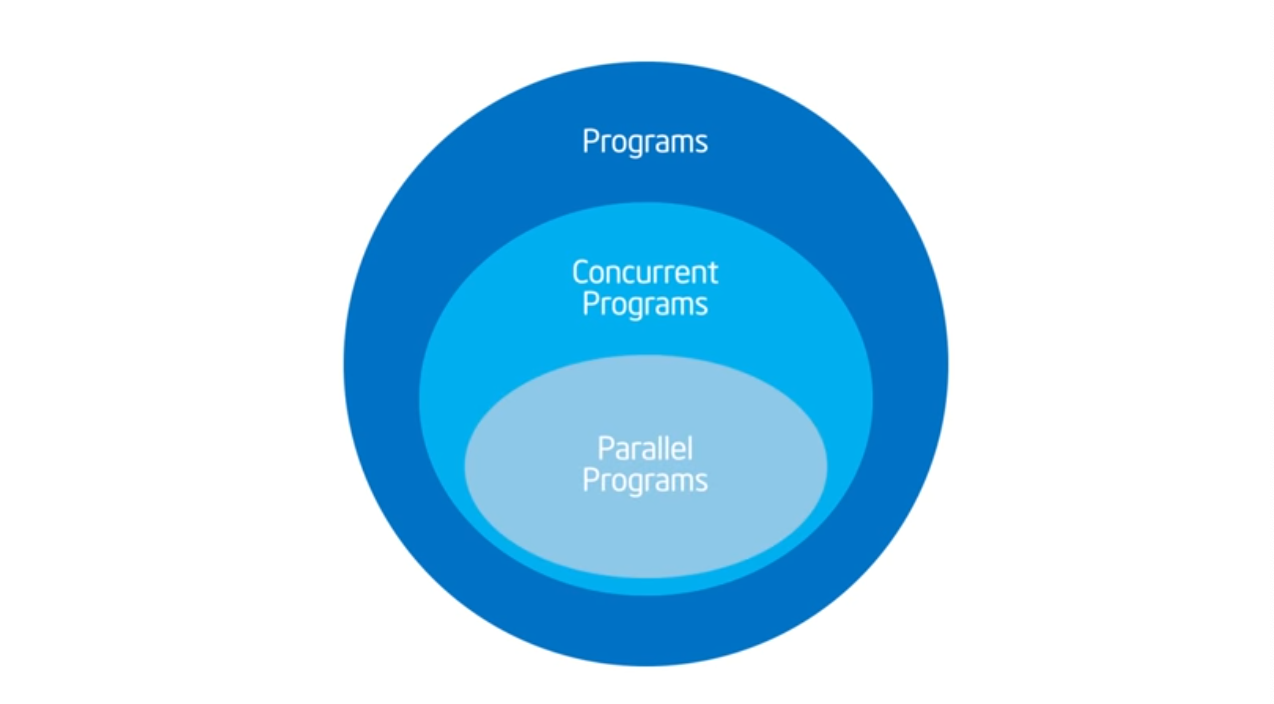
Concurrency vs Parallelism
Summary
The last step should be picking up the OpenMP Library (or any other parallel programming library). What should be done firs and foremost is breaking down your problem (the act of this has not been able to automated) into concurrent parts (this requires understanding of the problem space) and then figure out which can run in parallel. Once you figure that out, then you can use compiler syntactical magic (i.e. pragmas) to direct your compiler and then sprinkle some additional pragmas that will help the compiler tell where the code should enter and where it should exit.
Introduction to OpenMP – 03 Module 02
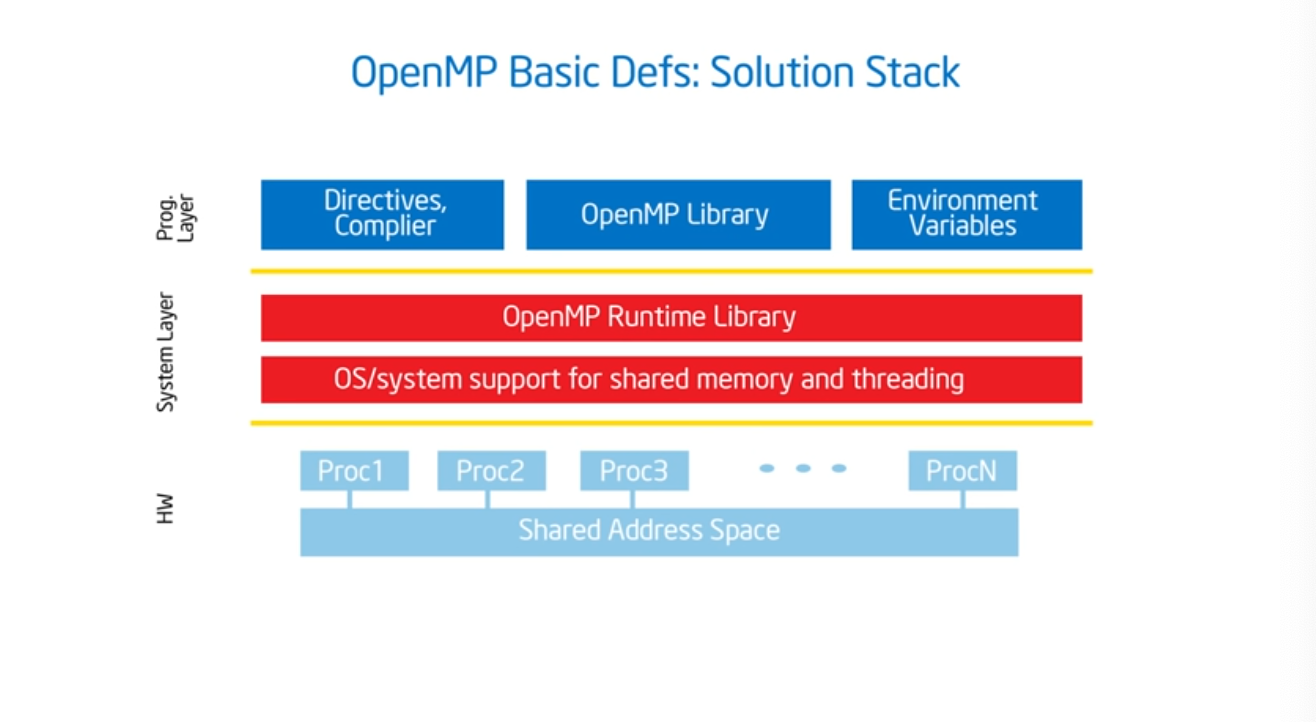
OpenMP Solution Stack
Summary
It’s highly likely that the compiler that you are using already supports OpenMP. For gcc, pass in -fopenmp. And then include the prototype, and add some syntactic sugar (i.e. #pragma amp parallel) which basically gives the program a bunch of threads.
Introduction to OpenMP: 04 Discussion 1
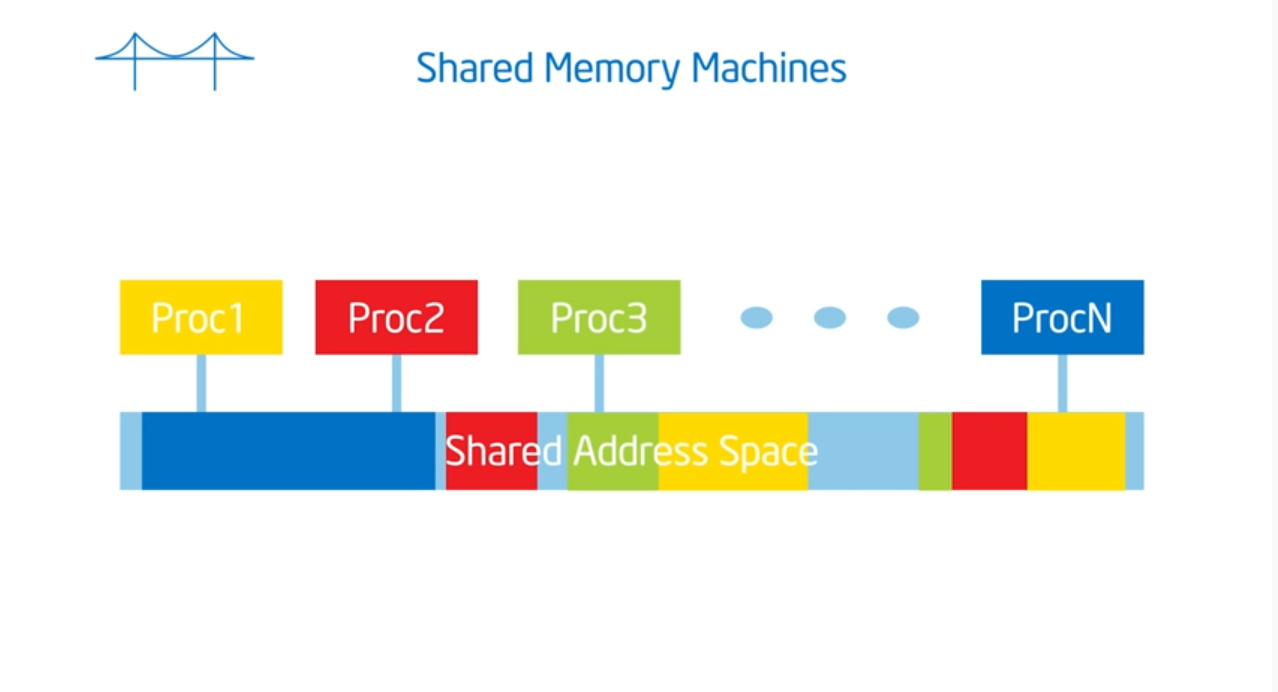
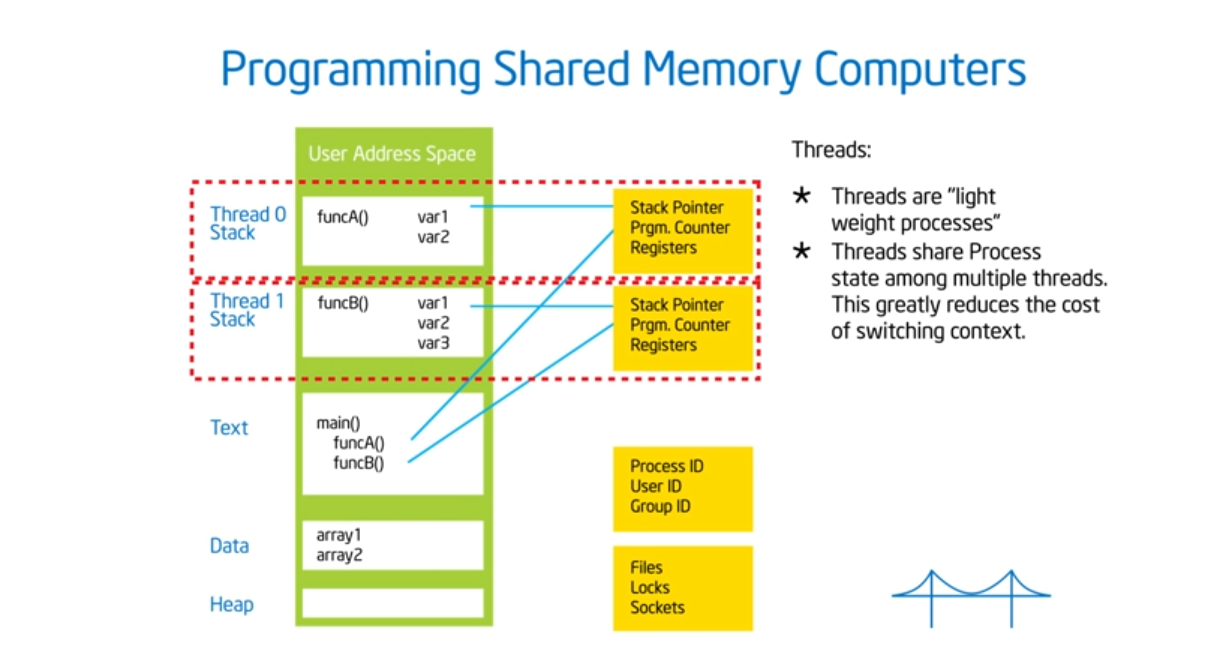
Shared address space
Summary
OpenMP assumes a shared memory address space architecture. The last true SMP (symmetric multi-processor) machine was in the late 1980s so most machines now run on NUMA (non uniformed multiple access) architectures. To exploit this architecture, we need to schedule our threads intelligently (which map to the same heap but contain different stacks) and place data in our cache’s as close as possible to their private caches. And, just like the professor said in advanced OS, we need to limit global data sharing and limit (as much as possible) the use of synchronization variables since they both slow down performance
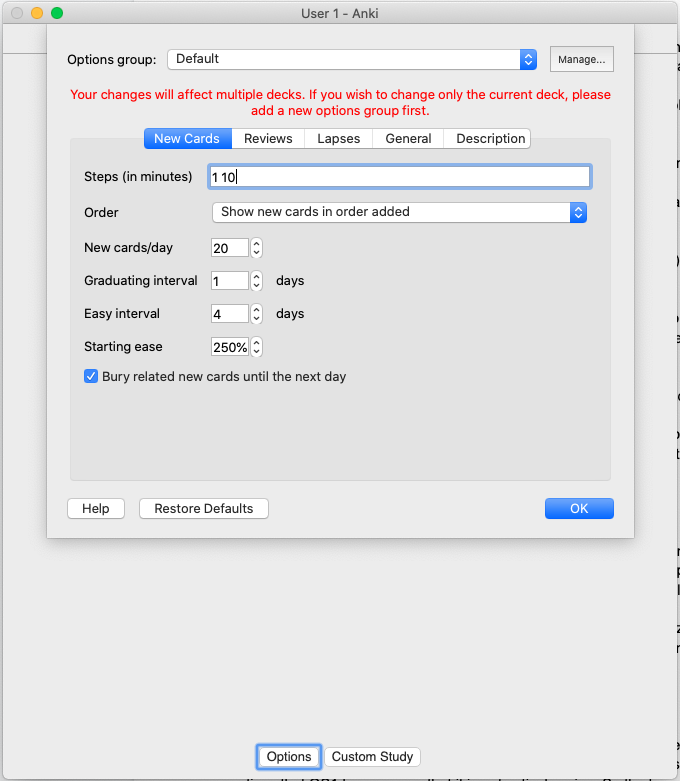
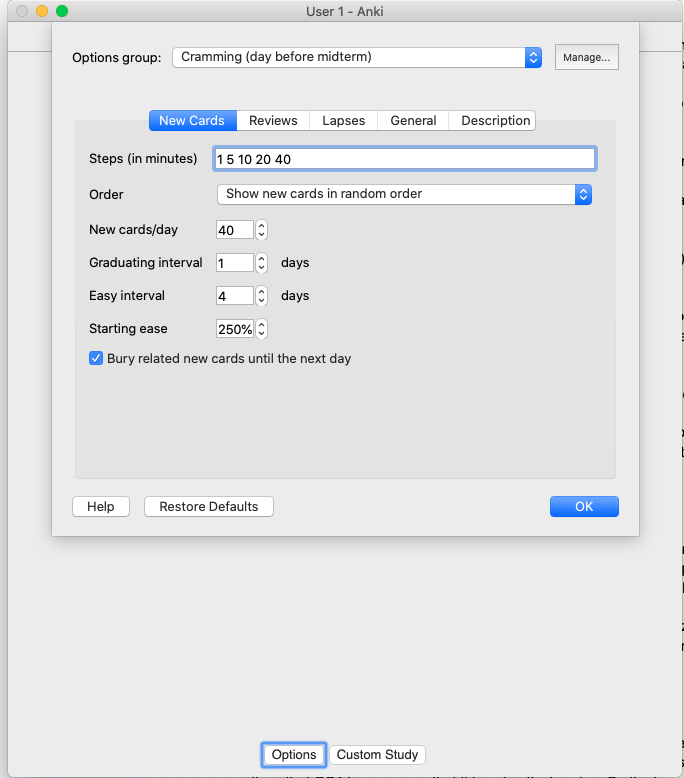
I spent a few minutes fiddling with my Anki settings yesterday, modifying the options for the advanced operating systems deck that I had created to help me prepare for the midterm. Although Anki’s default settings are great for committing knowledge and facts over a long period of time (thanks to its internal algorithm exploiting the forgetting curve), it’s also pretty good for cramming.
Although I don’t fully understand all the settings, here’s what I ended up tweaking some of the settings to. The top picture shows the default settings and the picture below it shows what I set them to (only for this particular deck).
I modified the order so that cards get displayed randomly (versus the default setting that presents the cards in the order that they were created), bumped up the number of cards per day to 35 (the total number of questions asked for the exam), and added additional steps so that the cards would recur more frequently before the system places the card in the review pile.
Because I don’t quite understand the easy interval and starting ease, I left those settings alone however I hope to understand them before the final exam so I can optimize the deck settings even more for the future final exam.
We’ll see how effective these settings were since I’ll report back once the grades get released for the exam, which I estimate will take about 2-3 weeks.
Default Anki Settings
Anki settings for advanced operating systems cramming
There are many challenges that the OS faces when building for parallel machines: size bloat (features OS just has to run), memory latency (1000:1 ratio) and numa effects (one process accessing another process’s memory across the network), false sharing (although I’m not entirely sure whether false sharing is a net positive, net negative, or just natural)
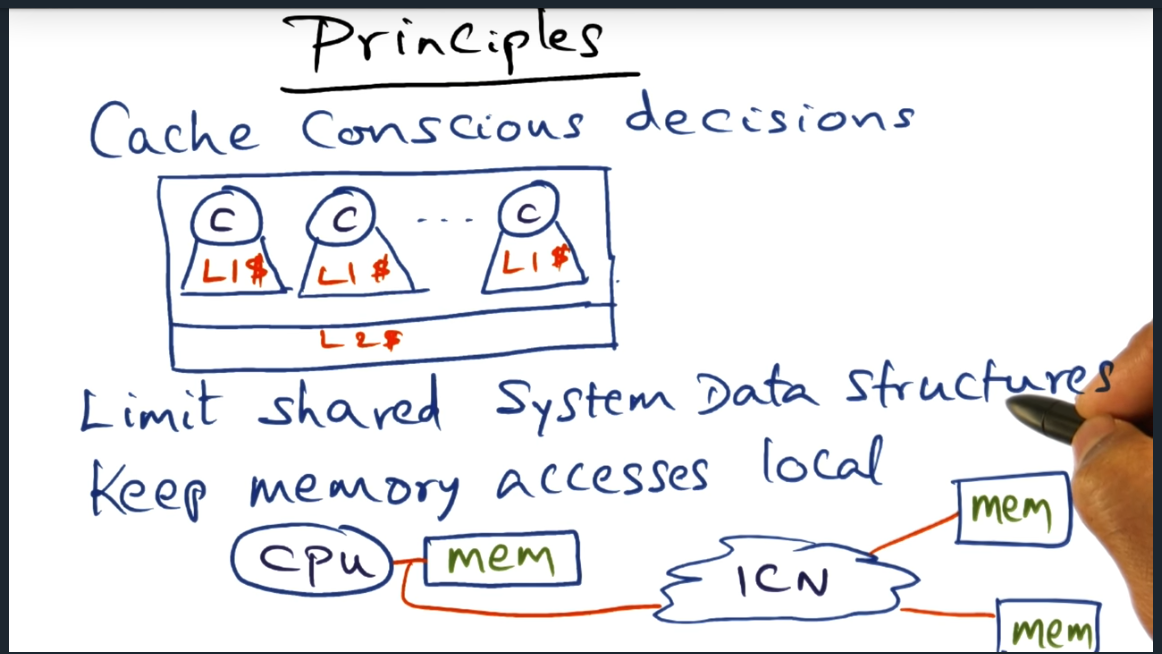
Principles
Summary
Two principles to keep in mind while designing operating systems for parallel systems. First it to make sure that we are making cache conscious decisions (i.e. pay attention to locality, exploit affinity during scheduling, reduce amount of sharing). Second, keep memory accesses local.
Refresher on Page Fault Service
Summary
Look up TLB. If no miss, great. But if there’s a miss and page not in memory, then OS must go to disk and retrieve the page, update the page table entry. This is all fine and dandy but the complication lies in the center part of the photo since accessing the file system and updating the page frame might need to be done serially since that’s a shared resource between threads. So … what we can do instead?
Parallel OS + Page Fault Service
Summary
There are two scenarios for parallel OS, one easy scenario and one hard. The easy scenario is multi-process (not multi-threaded) since threads are independent and page tables are distinct, requiring zero serialization. The second scenario is difficult because threads share the same virtual address space and have the same page table, shared data in the TLB. So how can we structure our data structures so that threads running on one process are not shared with other threads running on another physical processor?
Recipe for Scalable Structure in Parallel OS
Summary
Difficult dilemma for operating system designer. As designers, we want to ensure concurrency by minimizing sharing of data structures and when we need to share, we want to replicate or partition data to 1) avoid locking 2) increase concurrency
Tornado’s Secret Sauce
Summary
The OS creates a clustered object and the caller (i.e. developer) decides degree of clustering (e.g. singleton, one per core, one per physical CPU). The clustering (i.e. splitting of object into multiple representations underneath the hood) falls on to the responsibility of the OS itself, the OS bypassing the hardware cache coherence.
Traditional Structure
Summary
For virtual memory, we have shared/centralized data structures — but how do we avoid them?
Objectization of Memory
Summary
We break the centralized PCB (i.e. process control block) into regions, each region backed by a file cache manager. When thread needs to access address space, must access specific region.
Objectize Structure of VM Manager
Summary
Holy hell — what a long lecture video (10 minutes). Basically, we walk through workflow of a page fault in a objected structure. Here’s what happens. Page fault occurs with a miss. Process inspects virtual address and knows which region to consult with. Each region, backed by its file cache manager, will talk to the COR (cache object representation) which will perform translation of page, the page eventually fetched from DRAM. Different parts of system will have different representation. The process is shared and can be a singleton (same with COR), but region will be partitioned, same with FCM.
Advantages of Clustered Object
Summary
A single object make underneath the hood have multiple representations. This same object references enables less locking of data structures, opening up opportunities for scaling services like page fault handling
Implementation of Clustered Object
Summary
Tornado incrementally optimizes system. To this end, tornado creates a translation table that maps object references (a common object) to the processor specific representation. But if obj reference does not reside in t translation table, then OS must refer to the miss handling table. Since this miss handling table is partitioned and not global, we also need a global translation table that handles global misses and has knowledge of location of partition data.
Non Hierarchical Locking
Summary
Hierarchical locking kills concurrency (imagine two threads sharing process object). What can we do instead? How about referencing counting (so cool to see code from work bridge the theoretically and practical gap), eliminating need for hierarchical locking. With a reference count, we achieve existence guarantee!
Non Hierarchical Locking + Existence Guarantee (continued)
Summary
The reference count (i.e. existence guarantee) provides same facility of hierarchical locking but promote concurrency
Dynamic Memory Allocation
Summary
We need dynamic memory allocation to be scalable. So how about breaking the heap up into segments and threads requesting additional memory can do so from specific partition. This helps avoid false sharing (so this answers my question I had a few days ago: false sharing on NUMA nodes is a bad thing, well bad for performance)
IPC
Summary
With objects at the center of the system, we need an efficient IPC (inter process communication) to avoid context switches. Also, should point out that objects that are replicated must be kept consistent (during writes) by the software (i.e. the operating system) since hardware can only manage coherence at the physical memory level. One more thing, the professor mentioned LRPC but I don’t remember studying this topic at all and don’t recall how we can avoid a context switch if two threads calling one another are living on the same physical CPU.
Tornado Summary
Summary
Key points is that we use an object oriented design to promote scalability and utilize reference counting for implementing a non hierarchical locking, promoting concurrency. Moreover, OS should optimize the common case (like page fault handling service or dynamic memory allocation)
Summary of Ideas in Corey System
Summary
Similar to Tornado, but 3 take aways: address ranges provided directly to application, file descriptor can be private (and note shared), dedicated cores for kernel activity (helps locality).
Virtualization to the Rescue
Summary
Cellular disco is a VMM that runs as a very thin layer, intercepting requests (like I/O) and rewriting them, providing very low overhead and showing by construction the feasibility of a thin virtual machine management.
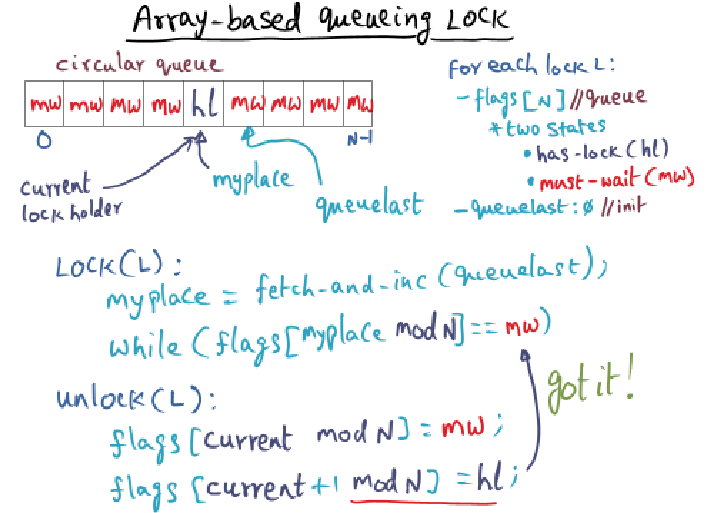
The algorithm is implemented on a cache coherent architecture with an invalidation-based shared-memory bus.
The circular queue is implemented as an array of consecutive bytes in memory such that each waiting thread has a distinct memory location to spin on. Let’s assume there are N threads (each running on distinct processors) waiting behind the current lock holder.
If I have N threads, and each one waits its turn to grab the lock once (for a total of N lock operations), I may see far more than N messages on the shared memory bus. Why is that?
My Guess
Wow .. I’m not entirely sure why you would see far more than N messages because I had thought each thread spins on its own private variable. And when the current lock holder bumps the subsequent array’s flag to has lock … wait. Okay, mid typing I think I get it. Even though each thread spins on its own variable, the bus will update all the other processor’s private cache, regardless of whether they are spinning on that variable.
Solution
This is due to false-sharing.
The cache-line is the unit of coherence maintenance and may contain
multiple contiguous bytes.
Each thread spin-waits for its flag (which is cached) to be set to hl.
In a cache-coherent architecture, any write performed on a shared
memory location invalidates the cache-line that contains the location
in peer caches.
All the threads that have their distinct spin locations in that same
cache line will receive cache invalidations.
This cascades into those threads having to refresh their caches by
contending on the shared memory bus.
Reflection
Right: the array belongs in the same cache line and the cache line may contain multiple contiguous bytes. We just talked about all of this during the last war room session.
Question 3e
Give the rationale for choosing to use a spinlock algorithm as opposed to blocking (i.e., de-scheduling) a thread that fails to get a lock.
My Guess
Reduced complexity for a spin lock algorithm
May be simpler to deal with when there’s no cache coherence offered by the hardware itself
Solution
Critical sections (governed by a lock) are small for well-structured parallel programs. Thus, cost of spinning on the lock is expected to be far lesser than the cost of context switching if the thread is de- scheduled.
Reflection
Key take away here is a reduced critical section and cheaper than a context switch
Question 3f
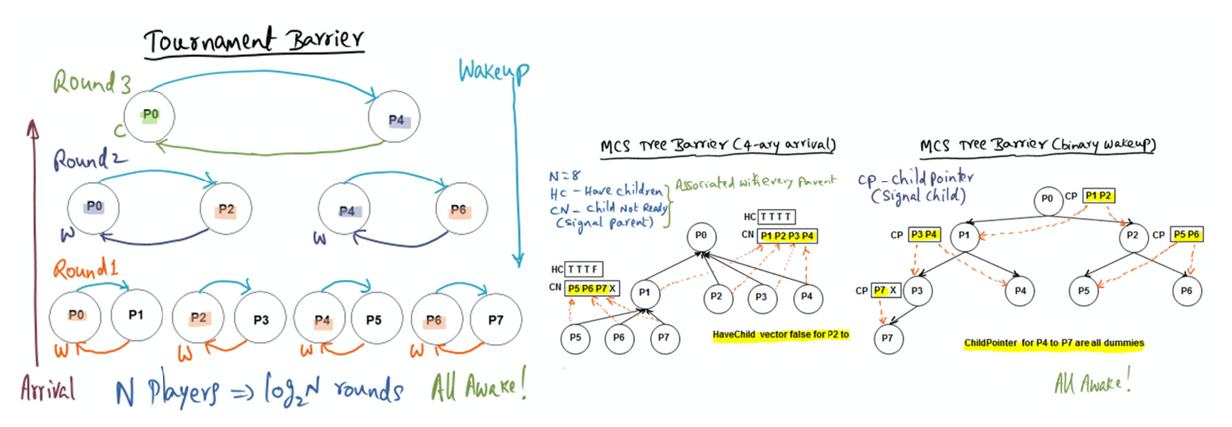
Tournament Barrier vs MCS Tree Barrier
(Answer True/False with justification)(No credit without justification)
In a large-scale CC-NUMA machine, which has a rich inter-connection network (as opposed to a single shared bus as in an SMP), MCS barrier is expected to perform better than tournament barrier.
Guess
The answer is not obvious to me. What does having a CC (cache coherence) numa machine — with a rich interconnection network instead of a single shared bus — offer that would make us choose an MCS barrier over a tournament barrier …
The fact that there’s not a single shared bus makes me think that this becomes less of a bottle neck for cache invalidation (or cache update).
Solution
False. Tournament barrier can exploit the multiple paths available in the interconnect for parallel communication among the pair-wise contestants in each round. On the other hand, MCS due to its structure requires the children to communicate to the designated parent which may end up sequentializing the communication and not exploiting the available hardware parallelism in the interconnect.
Reflection
Sounds line the strict 1:N relationship between the parent and the children may cause a bottle neck (i.e. sequential communication).
3g Question
In a centralized counting barrier, the global variable “sense” informs a processor which barrier (0 or 1) it is currently in. For the tournament and dissemination barriers, how does a processor know which barrier (0 or 1) it is in?
Guess
I thought that regardless of which barrier (including tournament and dissemination), they all require sense reversal. But maybe …. not?
Maybe they don’t require a sense since the threads cannot proceed until they reach convergence. In the case of tournament, they are in the same barrier until the “winner” percolates and the signal to wake up trickles down. Same concept applies for dissemination.
Solution
Both these algorithms do not rely on globally shared data structures. Each processor knows “locally” when it is done with a barrier and is in the next phase of the computation. Thus, each processor can locally flip its sense flag, and use this local information in its communication with the other processors.
Reflection
Key take away here is that neither tournament nor sense barrier share global data structures. Therefore, each processor can flip its own sense flag.
3h
Tornado uses the concept of a “clustered” object which has the nice property that the object reference is the same regardless of where the reference originates. But a given object reference may get de-referenced to a specific representation of that object. Answer the following questions with respect to the concept of a clustered object.
The choice of representation for the clustered object is dictated by the application running on top of Tornado.
Guess
No. The choice of representation is determined by the operating system. So unless the OS itself is considered an application, I would disagree.
Solution
The applications see only the standard Unix interface. Clustered object is an implementation vehicle for Tornado for efficient implementation of system
services to increase concurrency and avoid serial bottlenecks. Thus choice of representation for a given clustered object is an implementation/optimization choice internal to Tornado for which the application program has no visibility.
Reflection
Key point here is that the applications see a standard Uni interface. And that the clustered object is an implementation detail for Tornado to 1) increase concurrency and 2) avoid serial bottlenecks (that’s why there are regions and file memory caches and so on).
Question 3h
Corey has the concept of “shares” that an application thread can use to give a “hint” to the kernel its intent to share or not share some resource it has been allocated by the kernel. How is this “hint” used by the kernel
Guess
The hint is used by the kernel to co-locate threads on the same process or in the case of “not sharing” ensure that there’s no shared memory data structure.
Answer
In a multicore processor, threads of the same application could be executing on different cores of the processor. If a resource allocated by the kernel to a particular thread (e.g., a file descriptor or a network handle) is NOT SHARED by that thread with other threads, it gives an opportunity for the kernel to optimize the representation of the associated kernel data structure in such a way as to avoid hardware coherence maintenance traffic among the cores.
Reflection
Similar theme to all the other questions: need to be very specific. Mainly, “allow kernel to optimize representation of data structure to avoid hardware coherence maintenance traffic among the cores.
Question 3j
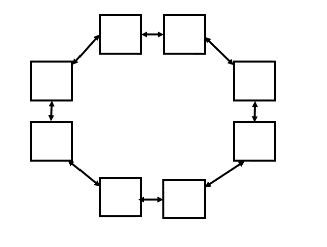
Imagine you have a shared-memory NUMA architecture with 8 cores whose caches are structured in a ring (as shown below). Each core’s cache can only communicate directly with the one next to it (communication with far cores has to propagate among all the caches between the cores). Overhead to contact a far memory is high (proportional to the distance in number of hops from the far memory) relative to computation that accesses only its local NUMA piece of the memory.
Rich architecture of shared-memory NUMA architecture
Would you expect the Tournament or Dissemination barrier to have the shortest worst-case latency in this scenario? Justify your answer. (assume nodes are laid out optimally to minimize communication commensurate with the two algorithms). Here we define latency as the time between when the last node enters the barrier, and the last node leaves the barrier.
Guess
In a dissemenation barrier, the algorithm is to hear back from (i+2^k) mod n. As a result, each process needs to talk to another distant processor.
Now what about Tournament barrier, where the rounds are pre determined?
I think with tournament barrier, we can fix the rounds such that the processors speak to its closest node?
Solution
Dissemination barrier would have the shortest worst-case latency in this scenario.
In the Tournament barrier, there are three rounds and since the caches can communicate with only the adjacent nodes directly, the latency differs in each round as follows:
First round: Tournament happens between adjacent nodes and as that can happen parallelly, the latency is 1.
Second round: Tournament happens between 2 pairs of nodes won from previous round which are at a distance 2 from their oppoent node. So, the latency is 2 (parallel execution between the 2 pairs).
Third round: Tournament happens between last pair of nodes which are at distance 4 from each other, making the latency 4.
The latency is therefore 7 for arrival. Similar communication happens while the nodes are woken up and the latency is 7 again. Hence, the latency caused by the tournament barrier after the last node arrives at the barrier is 7+7 = 14.
In the dissemination barrier, there are 3 rounds as well.
First round: Every node communicates with its adjacent node
(parallelly) and the latency is 1. (Here, the last node communicates
with the first node which are also connected directly).
Second round: Every node communicates with the node at a distance 2
from itself and the latency is 2.
Third round: Every node communicates with the node at a distance 4
from itself and the latency is 4. The latency is therefore 7.
Hence, we can see that dissemination barrier has shorter latency than the tournament barrier. Though the dissemination barrier involves a greater number of communication than the tournament barrier, since all the communication at each round can be done in parallel, the latency is lesser for it.
Reflection
Right, I forgot completely that with a tournament barrier, there needs to be back propagation to signal the wake up as well, unlike the dissementation barrier, which converges hearing from ceil(log2n) neighbors due to its parallel nature.
This is a continuation of me attempting to answer the midterm questions without peeking at the answers. Part 1 covered questions from OS Structures and this post (part 2) covers virtualization and includes questions revolving around memory management in hypervisors and how to test-and-set atomic operations work.
A few useful links I found while trying to answer my own questions:
VM1 is experiencing memory pressure. VM2 has excess memory it is not using. There are balloon drivers installed in both VM1 and VM2. Give the sequence through which the memory ownership moves from VM2 to VM1.
My Guess
Hypervisor (via a private communication channel) signals VM2’s balloon driver to expand
VM2 will page out (i.e. from memory to swap if necessary)
Hypervisor (again, via a private communication channel) signals VM1’s balloon driver to deflate
VM1 will page in (i.e. from swap to memory if necessary)
Essentially, balloon driver mechanisms shifts the memory pressure burden from the hypervisor to the guest operating system
Solution
Hypervisor (Host) contacts balloon driver in VM2 via private channel that exists between itself and the driver and instructs balloon device driver to inflate, which causes balloon driver to request memory from Guest OS running in VM2
If balloon driver’s memory allocation request exceeds that of Guest OS’s available physical memory, Guest OS swaps to disk unwanted pages from the current memory footprint of all its running processes
Balloon driver returns the physical memory thus obtained from the guest to the Hypervisor (through the channel available for its communication with the hypervisor), providing more free memory to the Host
Hypervisor contacts VM1 balloon driver via private channel, passes the freed up physical memory, and instructs balloon driver to deflate which results in the guest VM1 acquiring more physical memory.
This completes the transfer of ownership for the memory released by VM2 to VM1
Reflection
I was correct about the private communication channel (hooray)
No mention of swapping in the solution though (interesting)
No mention of memory pressure responsibility moving from hypervisor to guest OS
I forgot to mention that the guest OS’s response includes the pages freed up by the balloon driver during inflation
Question 2e
VM1 has a page fault on vpn2. From the disk, the page is brought into a machine page mpn2. As the page is being brought in from the disk, the hypervisor computes a hash of the page contents. If the hash matches the hash of an already existing machine page mpn1 (belonging to another virtual machine VM2), can the hypervisor free up mpn2 and set up the mapping for vpn2 to mpn1? (Justify your answer)
My Guess
I think that the hypervisor can map VPN2 to MPN1. However, it’s much more nuanced than that. The question refers to the memory sharing technique. The hypervisor actually needs to set the flag on a copy-on-write metadata attribute on the page table entry so that if there are any writes (to VPN1 or VPN2) then the hypervisor will then create a copy of the memory addresses.
Solution
Even though the hash of mpn2 matches the hash of mpn1, this initial match can only be considered a hint since the content of mpn1 could have changed since its hash was originally computed
This means we must do a full comparison between mpn1 and mpn2 to ensure they still have the same content
If the content hashes are still the same, then we modify the mapping for vpn2 to point to mpn1, mark the entry as CoW, and free up mpn2 since it is no longer needed
Reflection
Need to mention that hypervisor must perform an another hash computation just in case VPN1 had change (if I recall correctly, this hash is computed only once when the page is allocated)
Call out that mpn2 will be freed up (with the caveat that the MPN1 entry will be marked as copy on write, as I had mentioned)
Question 2f
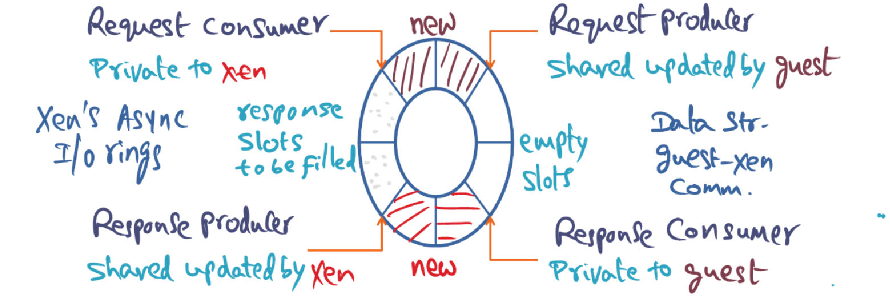
Hypervisor producer consumer ring
Above pictures shows the I/O ring data structure used in Xen to facilitate communication between the guest OS and Xen. Guest-OS places a request in a free descriptor in the I/O ring using the “Request Producer” pointer.
Why is this pointer a shared pointer with Xen?
Why is it not necessary for the guest-OS to get mutual exclusion lock to update this shared pointer?
Xen is the “Response Producer”. Is it possible for Xen to be in a situation where there are no slots available to put in a response? Justify your answer.
My Guess
1. Why is the pointer a shared pointer with Xen
Shared pointer because we do not want to copy buffer from user into privileged space.
By having a shared pointer, the xen hypervisor can simply access the actual buffer (without copying)
2. Why is it not necessary for the guest-OS to get mutual exclusion lock to update this shared pointer?
Isn’t the guest OS the only writer to this shared pointer?
The guest OS is responsible for freeing the page once (and only once) the request is fulfilled (this positive confirmation is detected when the hypervisor places a response on the shared ring buffer)
3. Xen is the “Response Producer”. Is it possible for Xen to be in a situation where there are no slots available to put in a response? Justify your answer.
My intuition is no (but let me think and try to justify my answer)
I’m staying no with the assumption that the private response consumer’s pointer position is initialized at the half way park in the buffer. That way, if the guest OS’s producer pointer catches up and meets with the response consumer pointer, the guest OS will stop producing.
Solution
This shared pointer informs Xen of the pending requests in the ring. Xen’s request consumer pointer will consume up until the request producer pointer.
The guest-OS is the only writer i.e. it is solely responsible for updating this shared pointer by advancing it, while Xen only reads from it. There is no possibility of a race condition which precludes the need of a mutual execution lock.
Two answers
This is not possible. Xen puts in the response in the same slot from where it originally consumed the request.It consumes the request by advancing the consumer pointer which frees up a slot. Once the response is available, it puts it in the freed-up slot by advancing the response producer pointer.
This is possible. Xen often uses these “requests” as ways for the OS to
specify where to put incoming data (e.g. network traffic). Consequently, if Xen receives too much network traffic and runs out of requests, the “response producer” may want to create a “response,” but have no requests to respond into.
Reflection
Got the first two answers correct (just need to a be a little more specific around the consumer pointer consuming up until the request producer pointer)
Not entirely sure how both answers (i.e. not possible and possible) are acceptable.
Parallel Systems
Question
Parallel Systems Question (did not want to wrestle with formatting the question)
Show the execution sequence for the instructions executed by P1 and P2 that would yield the above results.
Is the output: c is 0 and d is 1 possible? Why or why not?
My Guesses
c and d both 0 means that thread T2 ran to completion and was scheduled before Thread T1 executed
c and d both 1 means that thread T1 ran to completion and then Thread T2 ran
c is 1 and d is 0 means that Thread T1 Instruction 1 ran, followed by both Thread T2’s instructions
The situation in which c is 0 and d is 1 is not possible assuming sequential consistency. However, that situation is possible if that consistency is not guaranteed by the compiler.
This is possible because even though the processor P1 presents the memory updates in program order to the interconnect, there is no guarantee that the order will be preserved by the interconnect, and could result in messages getting re-ordered (e.g., if there are multiple communication paths from P1 to P2 in the interconnect).
Reflection
I got the ordering of the threads correctly however apparently got the answer wrong about the program order. I would argue that my answer is a bit more specific since I call out the assumption of the consistency model effecting whether or not the messages will be sent/received in order.
Question 3b
Consider a Non-Cache-Coherent (NCC)NUMA architecture. Processors P1 and P2 have memory location X resident in their respective caches.
Initially X = 0;
P1 writes 42 into X
Subsequently P2 reads X
What value is P2 expected to get? Why?
Guess
Since there’s no cache coherence guarantee, P2 will read in 0. However, I am curious, how the value will get propagated to P2’s cache. In a normal cache coherent system there will be a cache invalidate or write update … but how does it all work in a non cache coherent architecture? Who’s responsibility is it then to update the cache. Would it be the OS? That doesn’t sound right to me.
Solution
0. In NUMA, each processor would have a local cache storing X value. When P1 writes 42 to X, P2 would not invalidate the copy of X in its cache due to non-cache-coherence. Rather, it would read the local value which is still set to zero.
Reflection
How would the new value ever get propagated to P2? I’m assuming in software somehow, not hardware.
Question 3c
Test-and-Set (T&S) is by definition an atomic instruction for a single processor. In a cache-coherent shared memory multiprocessor, multiple processors could be executing T&S simultaneously on the same memory location. Thus T&S should be globally atomic. How is this achieved (Note there may be multiple correct implementations, giving any one is sufficient)?
My Guess
My guess would be that the requests will enter some sort of FIFO queue
But how would the hardware actually care this out ….
Solution
There are multiple ways this could be enforced:
Bypassing the cache entirely and ensuring that the memory controller
for the said memory location executes the T&S semantics atomically.
Locking the memory bus to stop other operations on the shared address
Exclusive ownership within the caching protocol (and atomic RMW of your exclusively owned cache line)
A multi-part but speculative operation within your cache (failing and retrying if another processor reads/writes the memory location between the beginning and end)
Reflection
Okay I was way off the mark here. But the answers do actually make sense. Thinking back at the lectures, T+S would cause lots of bus traffic so a more optimized version would be read followed by a T+S, T+S bypassing cache every time. The other answers make sense too, especially locking the memory bus.
Protection domains allow providing independence, integrity, and isolation for the memory space occupied by a specific subsystem of the operating system, e.g., a CPU scheduler. As opposed to procedure calls in a program, going from one protection domain to another results in overhead. Succinctly define (one bullet for each) the implicit cost and explicit cost of going from one protection domain to another.
My first guess
Implicit Cost
Cache pollution
Flushing of the TLB (unless we are using virtually indexed physically tagged)
Explicit Cost
Context Switch
Hardware address space change
Solution
Explicit cost
latency incurred in switching address spaces from one domain to another and copy of data structures with the cross-domain call
Implicit Cost
latency incurred due to change of locality, including TLB and cache misses
Reflection
I sort of got the answer right but I could be more specific with the implicit costs. Instead of cache pollution, let’s just say: latency due to change of locality due to TLB and cache misses. Same specificity required for explicit costs as well: instead of saying context switch and hardware address space change, let’s go with latency incurred in switching address spaces due to copying of data structures required for a cross-domain call.
Question 1b
A and B are protection domains. Consider two implementation alternatives: (1) A and B are given distinct architecture-supported hardware address spaces. (2) A and B are packed into the same hardware address space but each is given a portion of the available virtual address space enforced through architecture-supported segment registers.
(i) Alternative 1 gives more memory isolation than alternative 2 for the two protection domains. (ii) Alternative 2 is expected to perform better than alternative 1 for cross-domain calls
My First Guess
I would say i (i.e. more memory isolation) is false (although my intuition initially said that it is true) because the hardware itself check the bounds (lower and upper) of the virtual addresses that the process tries to access. However, on some level, I feel hardware separation equates to true separation.
I would also say that (ii) is false as well. During cross domain calls, doesn’t the OS need to copy user space buffers into the kernel? Why would using a virtual address have any positive impact? If anything, there’s additional overhead required of virtual address memory although the performance degredation is a good trade off for security.
Solution
False. In both implementations, the hardware enforces the memory isolation for the two domains. In option (1) the hardware associates a distinct page table with each domain; and in (2) the hardware ensures that each memory access is confined to the allocated virtual address space for the domain via the segment registers (lower and upper bounds).
True. Alternative 2 in this scenario would not require a page table swap/TLB flush as there is not virtual address space switch (only a very cheap segment switch) when calling between domains in the same address space, reducing the cost of the operation.
Reflection
Again, need to be more specific here and use specific keywords. In particular, I should mention page tables — distinct page tables — and how the hardware associates each process with a unique page table. Otherwise, I nailed it by calling out the lower and upper bounds stored in the hardware registers.
Apparently having a virtual address space does improve performance because no page table/TLB flush is required (I don’t agree with this since the answer assumes a virtually indexed physically tagged cache. Otherwise how would you ensure virtual address spaces do not overlap).
Question 1c
Consider a user program running on a vanilla operating system such as Unix. It makes a call “open” to the file system (which is part of the operating system). Open can be viewed as a cross-domain call between the user-space and the kernel. We are not interested in the details of what “open” does for the user program. Please succinctly specify the steps that transfer control from the user-space to the kernel’s implementation of open.
My Guess
Open makes a system call
System makes a trap into the OS
OS verifies process (and user) can perform system call
OS verifies user permissions to location on file system
OS sends instruction to disk (via memory mapped IO), sending the block number
Once device fetches block data is returned to CPU via bus (or in DMA data copied to memory)
Devices sends interrupt to OS, signaling that data is now available
User can now access data stored via virtual address
Solution
The call results in a trap (vai the TRAP instruction in the processor) into the kernel
into the kernel. (-1 if trap not mentioned)
The processor mode changes to “kernel” (i.e., privileged mode) as a result of the trap. (-1 if mode change not mentioned)
Trap instruction (which is a program discontinuity) will automatically transfer control to the entry point of the Trap handler (code for open call in the kernel) via the interrupt vector table. (+2 for any reasonable description that captures this sense)
Reflection
I got points 1 and 2 right but my answer appears to be a little too comprehensive. Basically there’s a trap instruction and need to explictly call out processor changing from user to kernel mode and calling out transfer of control to the trap handler via interrupt vector table.
Question 1d
Consider a process P1 executing on top of SPIN operating system. P1 makes a system call. Servicing this system call results in 3 cross domain calls within SPIN. How many hardware address spaces are involved in this system call (including the user-process’s address space)? (Justify your answer)
My Guess
Only two hardware address spaces are involved, including the user-process’s address space because SPIN, in order to achieve performance, groups all the OS services into the same hardware address space, enforcing security using Modula-3 programming language
Solution
There will be 2 hardware address space switches.
The first switch is from the user space to the protection domain of
SPIN kernel which requires hardware address switch.
The second switch is from this protection domain to the user domain to
return the results back to the user process P1
4. The 3 cross domain calls will happen in same hardware address space
because of the way SPIN is constructed.
If you are an online masters of computer science student (OMSCS) at Georgia Tech and enrolled in advanced operating systems (AOS) course, you might want to check out the notes I’ve taken for the lectures by clicking on the advanced operating systems category on my blog. For each video lecture, I’ve written down a summary and the key take away. These notes may help you out by giving you a quick overview of the topics or help you decide what sections to revisit or skip.
At the time of this writing, the write ups start from the refresher course (e.g. memory systems) all the way up until the end of parallel systems (i.e. last lectures included as part of the midterm).
The key take away for scheduling is that as OS designers you want to follow this mantra: “keep the caches warm“. Following this principle will ensure that the scheduler performs well.
There are many different scheduling algorithms including first come first serve (FCFS), fixed processor (focus on fairness), fixed processor (thread runs on the same process every time), last processor scheduling (processor will select thread that last ran on it, defaulting to choosing any thread), and minimum intervening (checks what other threads ran between, focusing on cache affinity). One modification to minimum intervening is a minimum intervening with a queue (since threads sitting in the queue may pollute the cache as well, so we’ll want to choose the minimum between the two).
One major point of the different scheduling algorithms is that there’s no correct answer: we need to look at trends and look at the overhead. The latter option (i.e. minimum intervening thread with queues) seems like the best solution but really what about the hidden costs like keeping track of the internal data structures?
Regardless of which of the above policies are chosen, the OS designer must exercise caution during implementation. Although designing the policy with a single global queue may work for a small system with a handful of processors or threads, imagine a system with dozens of processors and hundreds of threads: what then? Perhaps build affinity-based local queues instead, each queue policy specific (nice for flexibility too).
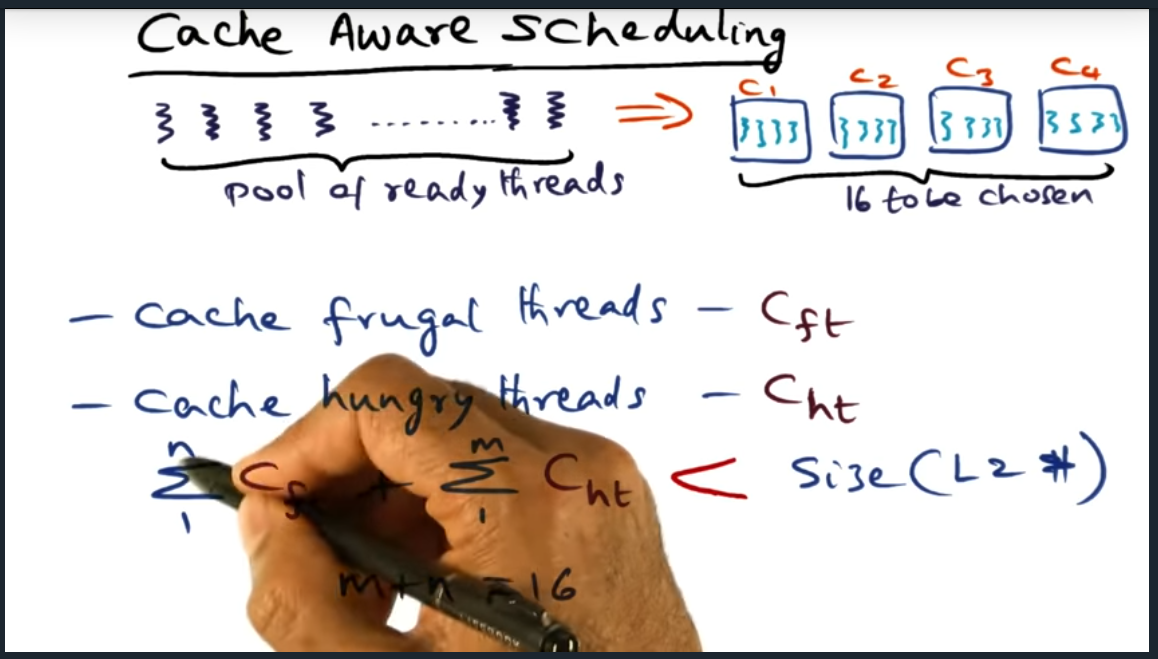
Finally, for performance, think about how to avoid polluting the cache. Ensure that the memory footprint of the threads (either frugal or hungry threads, combination of the two) footprint do not exceed the L2 cache. Determining what threads are frugal or hungry requires the operating system to profile the processes, additional overhead to the OS. So we’ll want to minimize profiling.
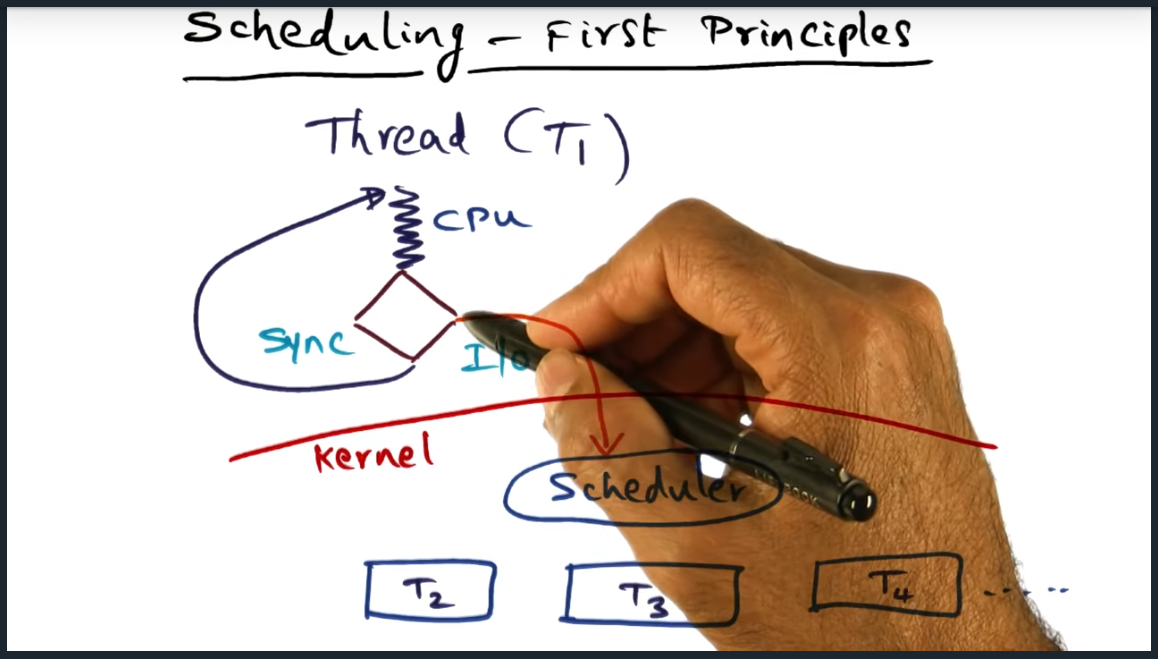
Scheduling First Principles
Summary
Mantra is always the same: “keep the caches warm”. That being said, how do we (as OS designers), when designing our schedulers, choose which thread or process that should run next?
Quiz: Scheduler
Summary
How should scheduler choose the next thread – all of the answers are suitable. Remainder of lecture will focus on “thread whose memory contents are in the cpu cache”. So … what sort of algorithm will we come up with determine whether another processor’s have its contents in the cache. I can imagine a few naive solutions
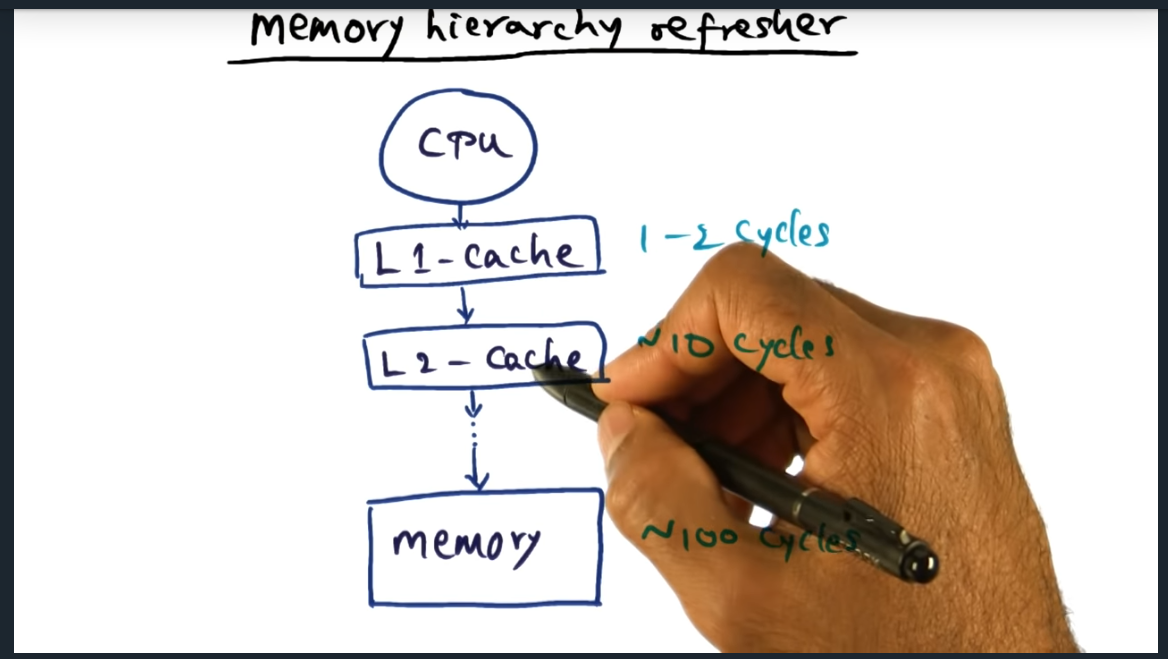
Memory Hierarchy Refresher
Memory Hierarchy Refresher – L1 cache costs 1-2 cyces, L2 caches about 10 days, and memory about 100 cycles
Summary
Going from cache to memory is a heavy price to pay, more than two orders of magnitude. L1 cache takes 1-2 cycles, L2 around 10 cycles, and memory around 100 cycles
Cache affinity scheduling
Summary
Ideally a thread gets rescheduled on the same processor as it ran on before. However, this might not be possible due to intervening threads, the cache being polluted.
Scheduling Policies
Summary
Different types of scheduling policies including first come first serve (focuses on fairness, not affinity), fixed processor scheduling (every thread runs on the same processor every time), last processor scheduling (processor will pick thread that it previously ran, falling through to picking any thread), and minimum intervening (most sophisticated but requires state tracking).
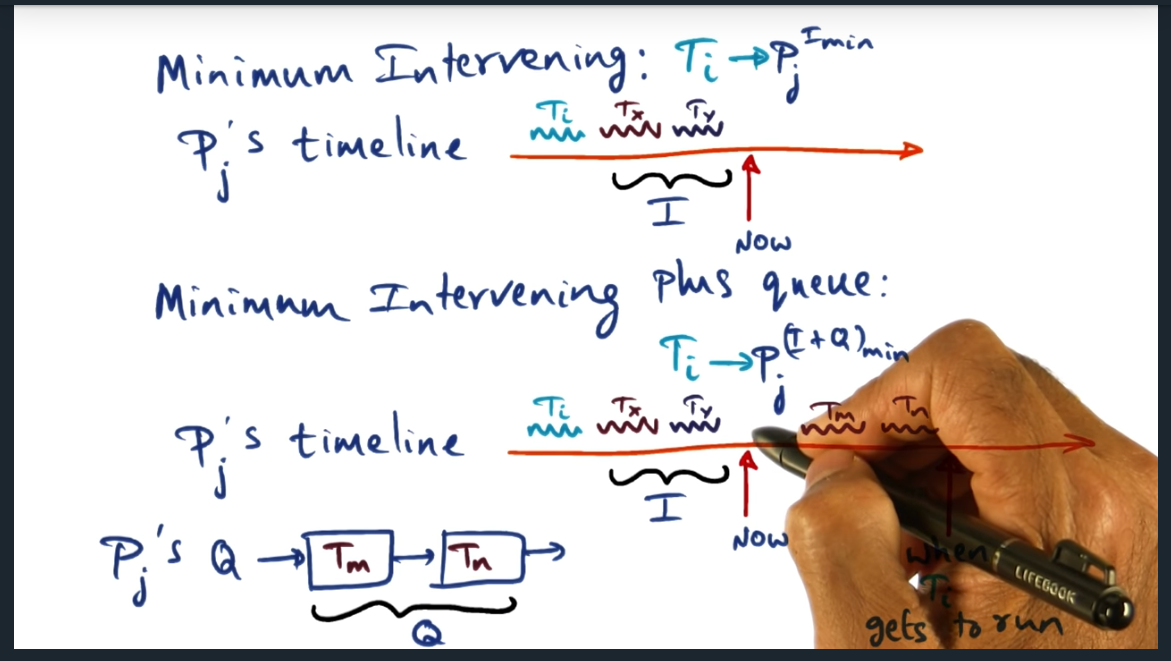
Minimum Intervening Policy
Summary
For a given thread (say Ti), the affinity is the number of threads that ran in between Ti’s execution
Minimum Intervening Plus Queue Policy
Summary
Minimum Intervening with queue – choose minimum between intervening number and queue size
Attributes of OS is to quickly make a decision and get out of the way, hence why we might want to employ minimum intervening scheduler (with limits). Separately, we want our scheduler to take into account of the queued threads, not just the affinity, since it’s entirely possible for affinity to be low for a CPU but for the queue to contain other threads, polluting the cache. So the minimum intervening plus queue takes both the affinity and the queued threads into account
Summarizing Scheduling Policies
Summary
Scheduling policies can be categorized into processor centric (what thread should a particular processor should choose to maximize chance of cache amount of cache content will be relevant) and thread centric (what is the best decision for a particular thread with respects to its execution). Thread centric: fixed and last processor scheduling policies. Processor centric is minimum intervening and intervening plus queue.
Quiz: Scheduling Policy
Summary
With the Minimum interleaving with queues, we select the processor that has the minimum value between number of intervening threads and minimum number of items in the queue.
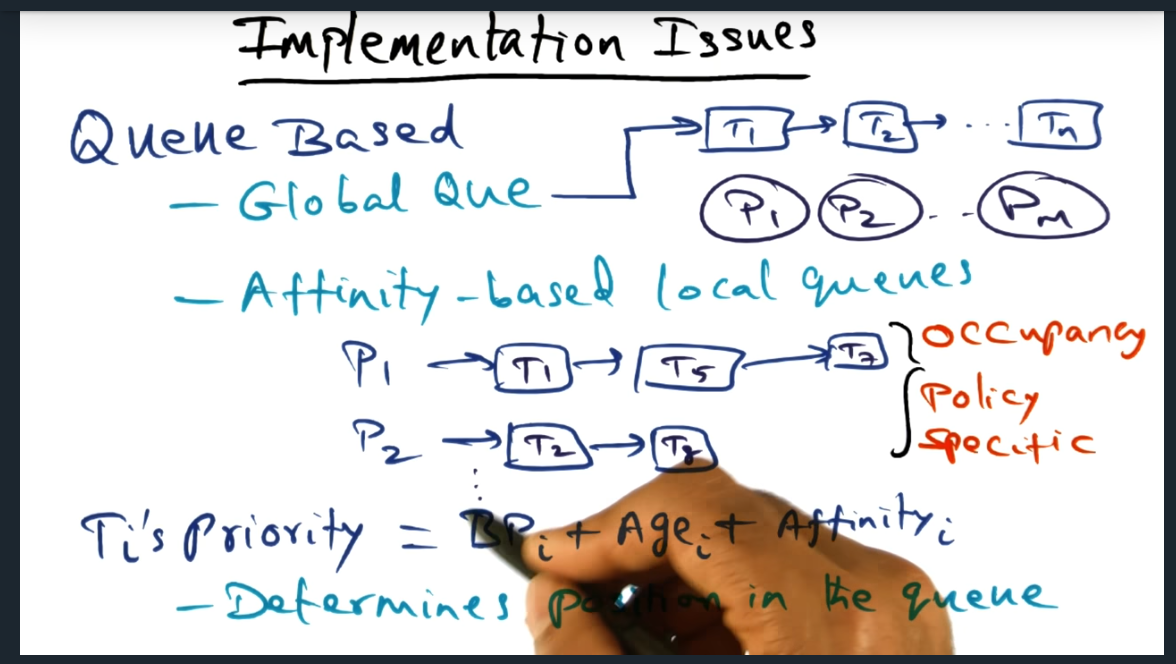
Implementation Issues
Implementation Issues – instead of having a single global queue, one queue per CPU
Summary
One way to implement the scheduling is to use a global queue. But this may be problematic for systems with lots of processors. Another approach is to have one queue per processor, and each queue can have its own policy (e.g. first come first served, fixed processor, minimum intervening). And within the queue itself, the threads position’s is determined by: base priority (when thread first launched), age (how long thread has been around) and affinity
Performance
Summary
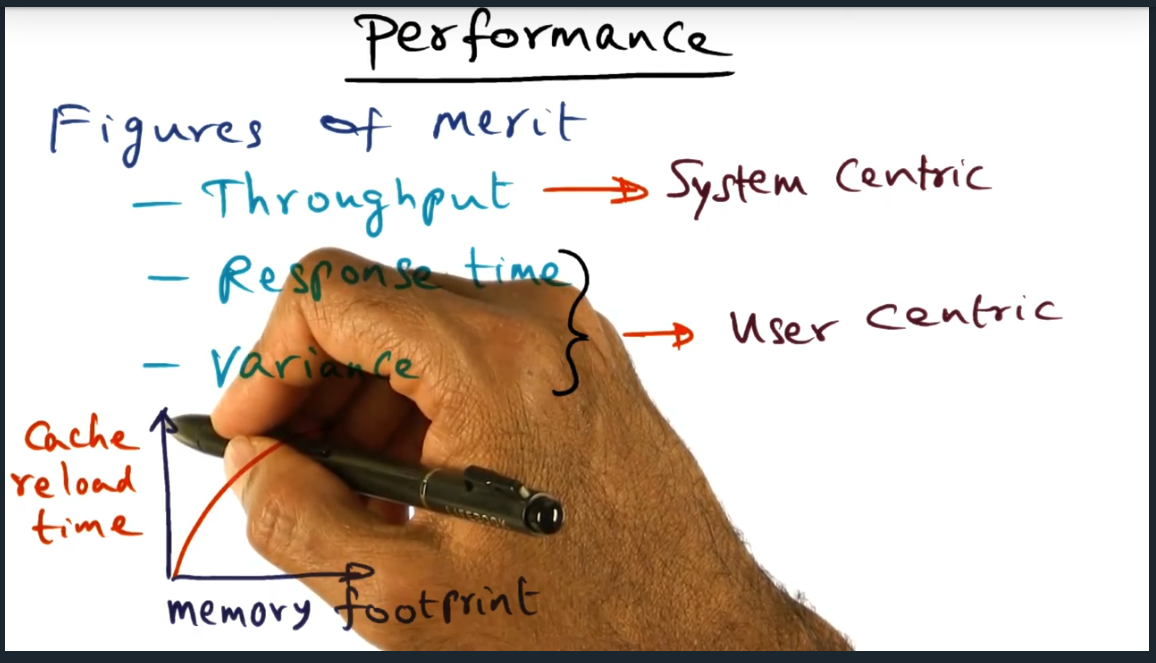
How do we evaluate the scheduling policies? We can look at it from the system’s point of view: throughput. That is, what are the number of threads that get executed per unit of time. From another viewpoint: user centric, which consists of response time (end to end time) and variance (i.e. deviation of end to end times). With that in mind, the first come first serve would perform poorly due to high variance, given that policy does not distinguish one thread from another thread
Performance continued
Performance of scheduler – throughput (system centric) vs response time + variance (user centric)
Summary
A minimum intervening policy may not suitable for all work loads. Although the policy may work well for small to light to medium work loads, may not perform very well when system under stress because caches will get polluted. In this case, a fixed processing scheduling may be more performant. So no one size fits all. Also, may want to introduce delays in scheduling, a technique that works in both synchronization and in file systems (which I will learn later on in the course, apparently)
Cache Affinity and Multicore
Summary
Hardware can switch out threads seamlessly without the operating system’s knowledge. But there’s a partnership between hardware and the OS. The OS tries to ensure that the working set lives in either L1 or at L2 cache; missing in these caches and going to main memory is expensive: again, can be twice order of magnitude.
Cache Aware Scheduling
Cache aware scheduling – categorize threads into frugal vs hungry threads. Make sure sum of address space between two do not exceed size of L2 cache
Summary
For cache aware scheduling, we categorize threads into two: cache hungry and cache frugal. Say we have 16 hardware threads, we want to make sure that during profiling, we group them and make sure that cache size of hungry and cache size of frugal have a working set size less than cache (L2). But OS must be careful to profiling and monitoring — should not heavily interfere. In short, overhead needs to be minimal.
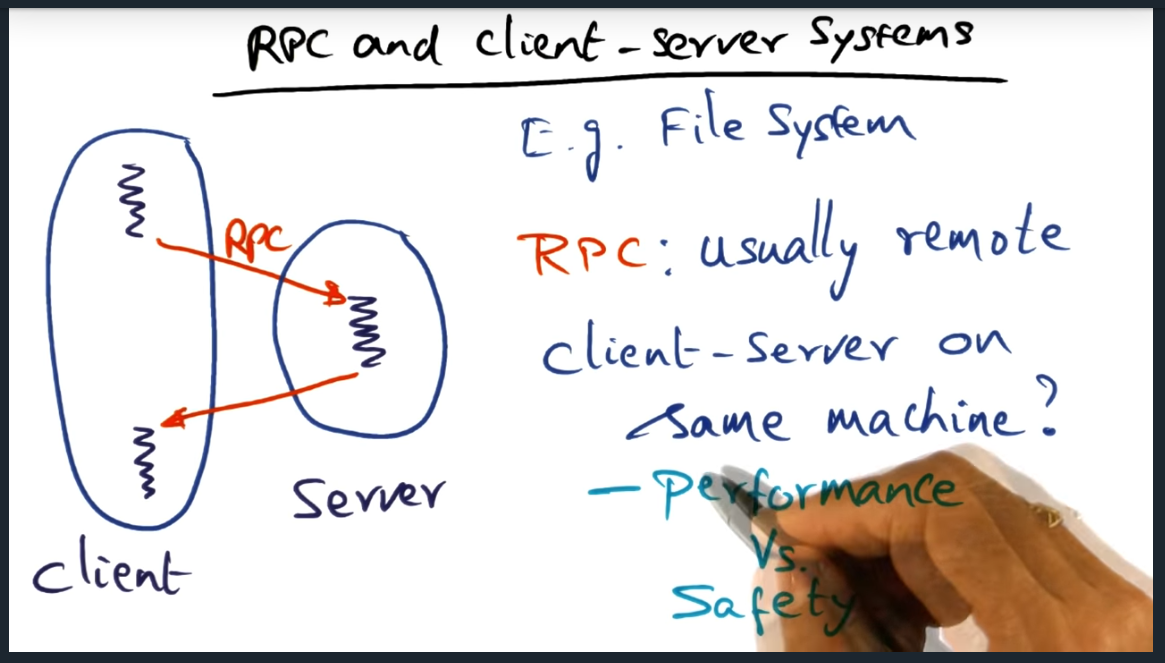
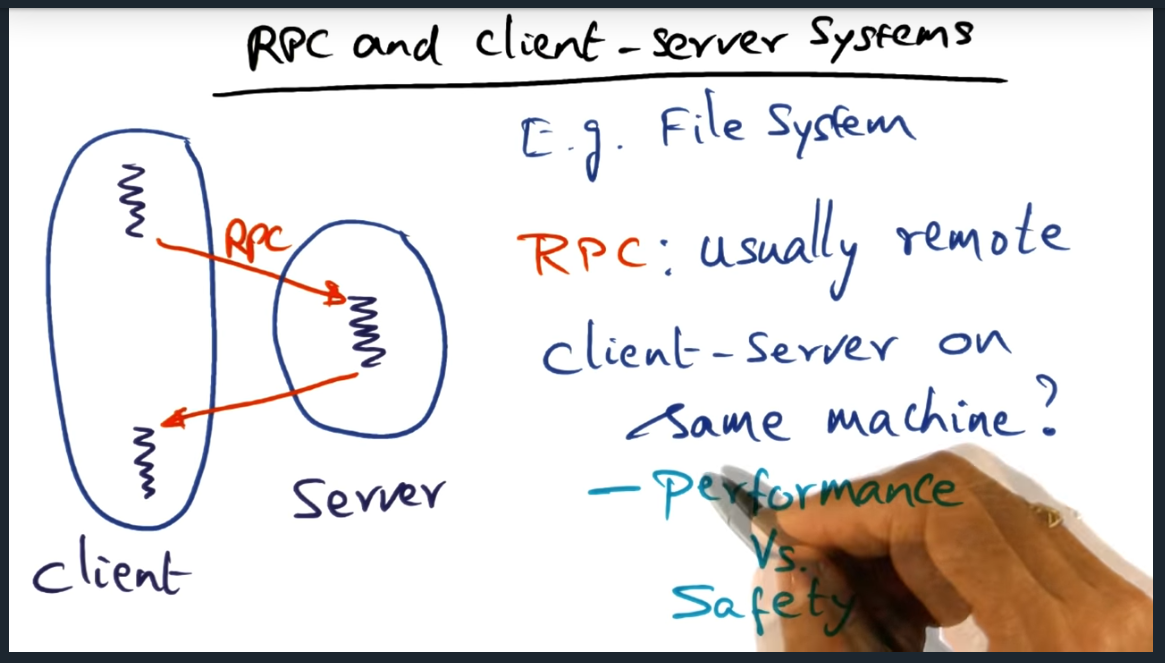
Remote procedure call (RPC) is a framework offered within operating systems (OS) to develop client/server systems and they promote good software engineering practices and promote logical protection domains . But without careful consideration, RPC calls (unlike simple procedure calls) can be cost prohibitive in terms over overhead incurred when marshaling data from client to server (and back).
Out of the box and with no optimization, an RPC costs four memory copy operations: client to kernel, kernel to server, server to kernel, kernel to client. On the second copy operation, the kernel makes an upcall into the server stub, unmarshaling the marshalled data from the client. To reduce these overhead, us OS designers need a way to reduce the cost.
To this end, we will reduce the number of copies by using a shard buffer space that gets set up by the kernel during binding, when the client initializes a connection to the server.
RPC and Client Server Systems
The difference between remote procedure calls (RPC) and simple procedure calls
Summary
We want the protection and want the performance: how do we achieve that?
RPC vs Simple Procedure Call
Summary
An RPC call, happens at run time (not compile time) and there’s a ton of overhead. Two traps involved. First is call trap from client; return trap (from server). Two context switches: switch from client to server and then server (when its done) back to client.
Kernel Copies Quiz
Summary
For every RPC call, there are four copies: from client address space, into kernel space, from kernel buffer to server, from server to kernel, finally from kernel back to client (for the response)
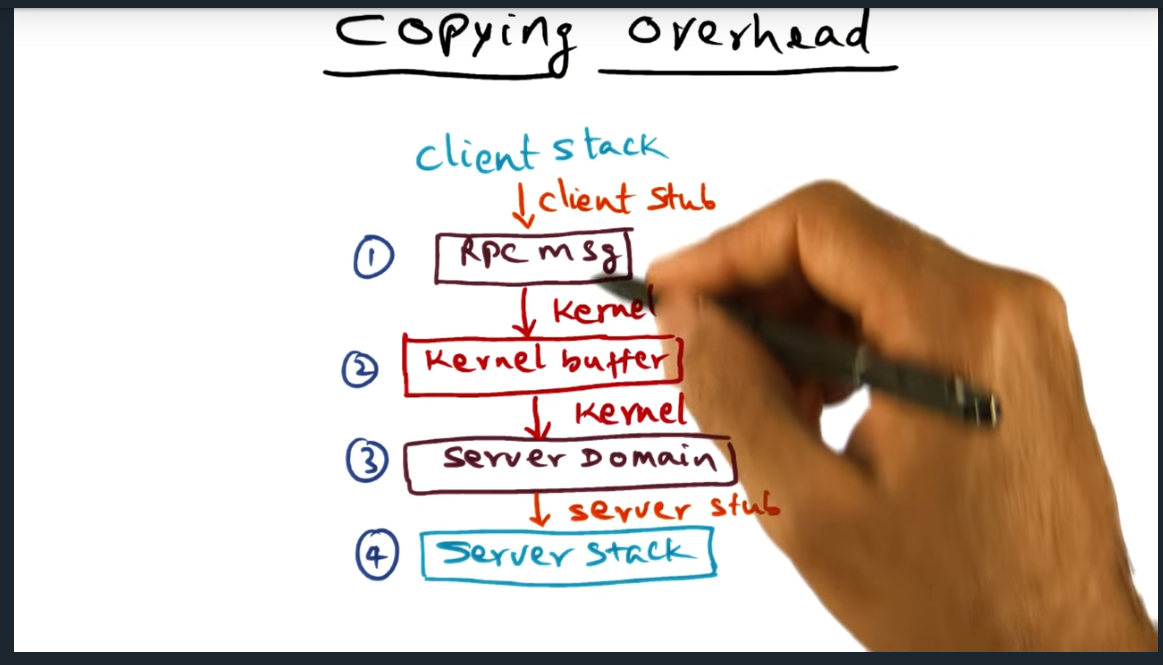
Copying Overhead
The (out of the box) overhead of RPC
Summary
Client Server RPC calls require the kernel to perform four copies, each way. Need to emulate the stack with the RPC framework. Client Stack (rpc message) -> Kernel -> Server -> Server Stack. Same thing backwards
Making RPC Cheap
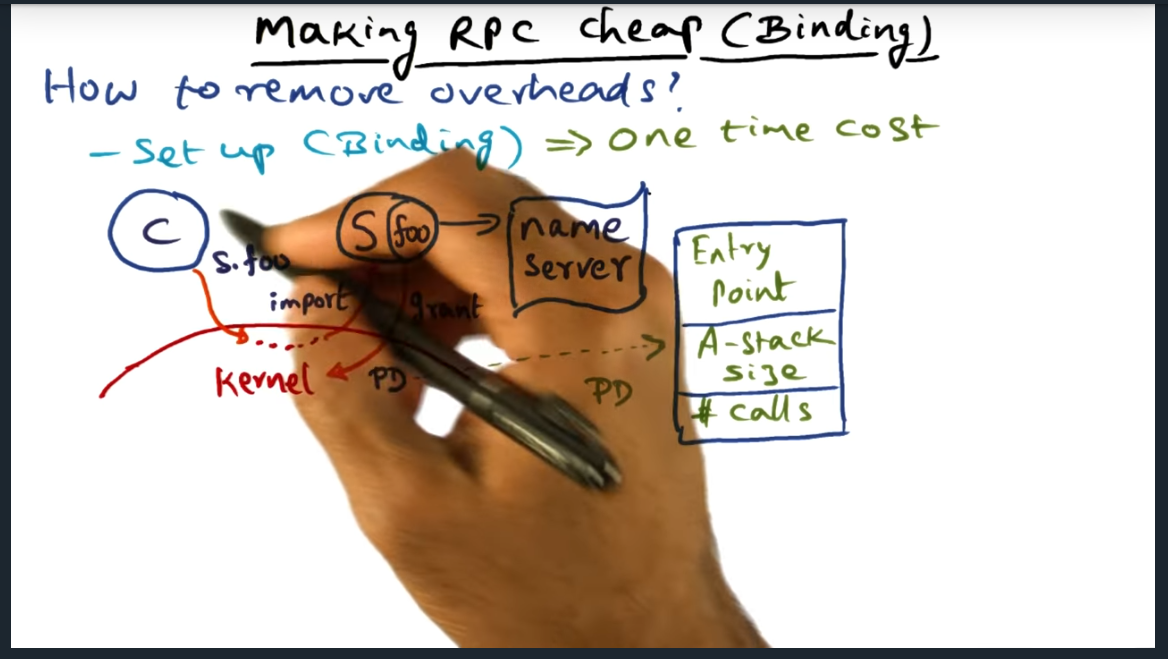
Making RPC cheap (binding)
Summary
Kernel is involved in setting up communication between client and server. Kernel makes an up call into the server, checking if the client is bonafide. If validation passes, kernel creates a PD (a procedure descriptor) that contains the three following: entry point (probably a pointer, I think), stack size, and number of calls (that the server can support simultaneously).
Making RPC Cheap (Binding)
Summary
Key Take away here is that the kernel performs the one-time set up operation of setting up the binding, the kernel allocating shared buffers (as I had correctly guessed) and authenticating the client. The shared buffers basically contain the arguments in the stack (and presumably I’ll find out soon how data flows back). Separately, I learned a new term called “up calls”.
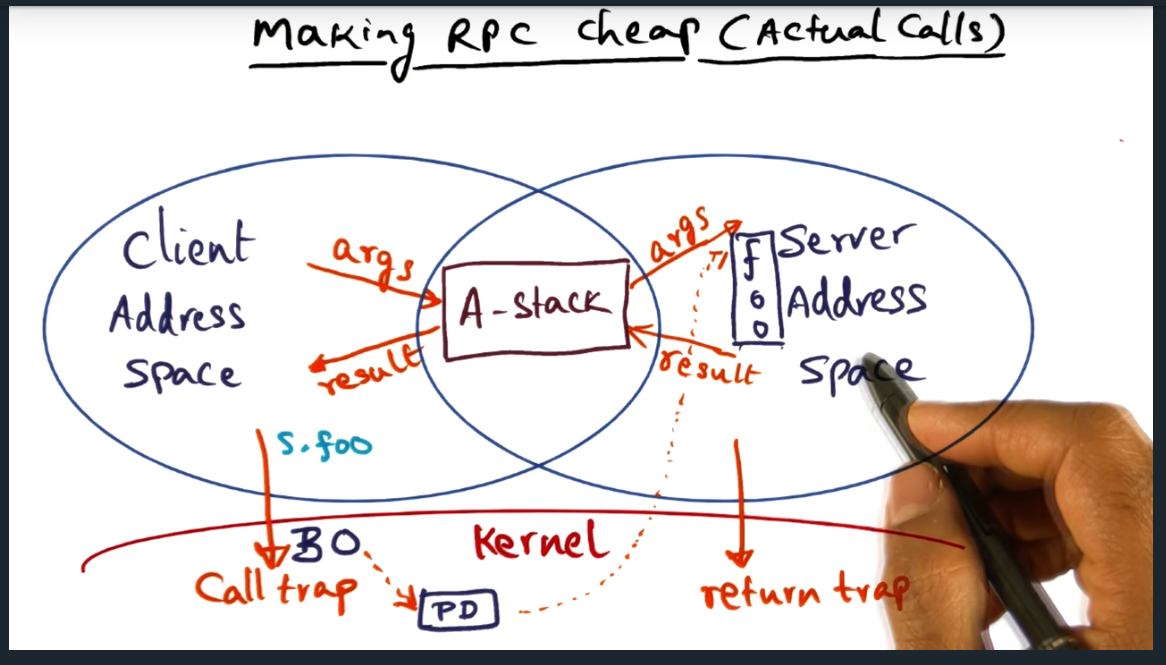
Making RPC Cheap (actual calls)
Summary
A (argument) shared buffer can only contain values passed by value, not reference, since the client and server cannot access each other’s address spaces. The professor also mentioned something about the client thread executing in the address space of the server, an optimization technique, but I’m not really following.
Making RPC Cheap (Actual Calls) continued
Summary
Stack arguments are copied from “A stack” (i.e. shared buffer) to “E” stack (execution). Still don’t understand the entire concept of “doctoring” and “redoctoring”: will need to read the research paper or at least skim it
Making RPC Cheap (Actual Calls) Continued
Summary
Okay the concept is starting to make sense. Instead of the kernel copying data, the new approach is that the kernel steps back and allows the client (in user space) copy data (no serialization, since semantics are well understood between client and server) into shared memory. So now, no more kernel copying, just two copies: marshal and unmarshal. Marshal copies from client to server. And from server to client.
Making RPC Cheap Summary
Making RPC calls cheap (summary)
Summary
Explicit costs with new approach: 1) client trap and validating BO (binding operation) 2) Switching protection domain from client to server 3) Return trap to go back into client address space. But there are also implicit costs like loss of locality
RPC on SMP
Summary
Can exploit multiple CPUs by keeping cache warm by dedicating processors to servers
RPC on SMP Summary
Summary
The entire gist is this: make RPC cheap so that we can promote good software engineering practices and leverage the protection domains that RPC offers.