Part 1 of barrier synchronization covers my notes on the first couple types of synchronization barriers including the naive centralized barrier and the slightly more advanced tree barrier. This post is a continuation and covers the three other barriers: MCS barrier, tournament barrier , dissemination barrier.
Summary
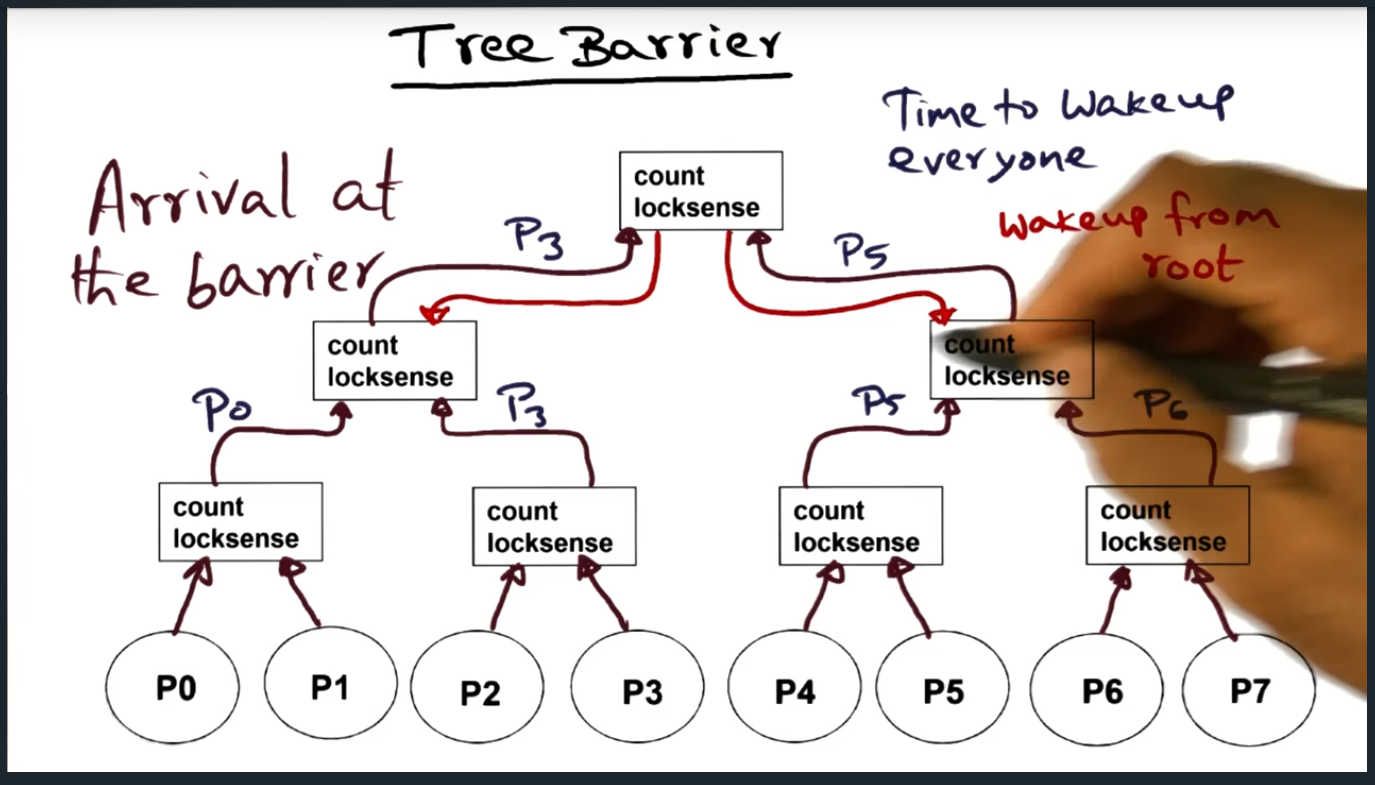
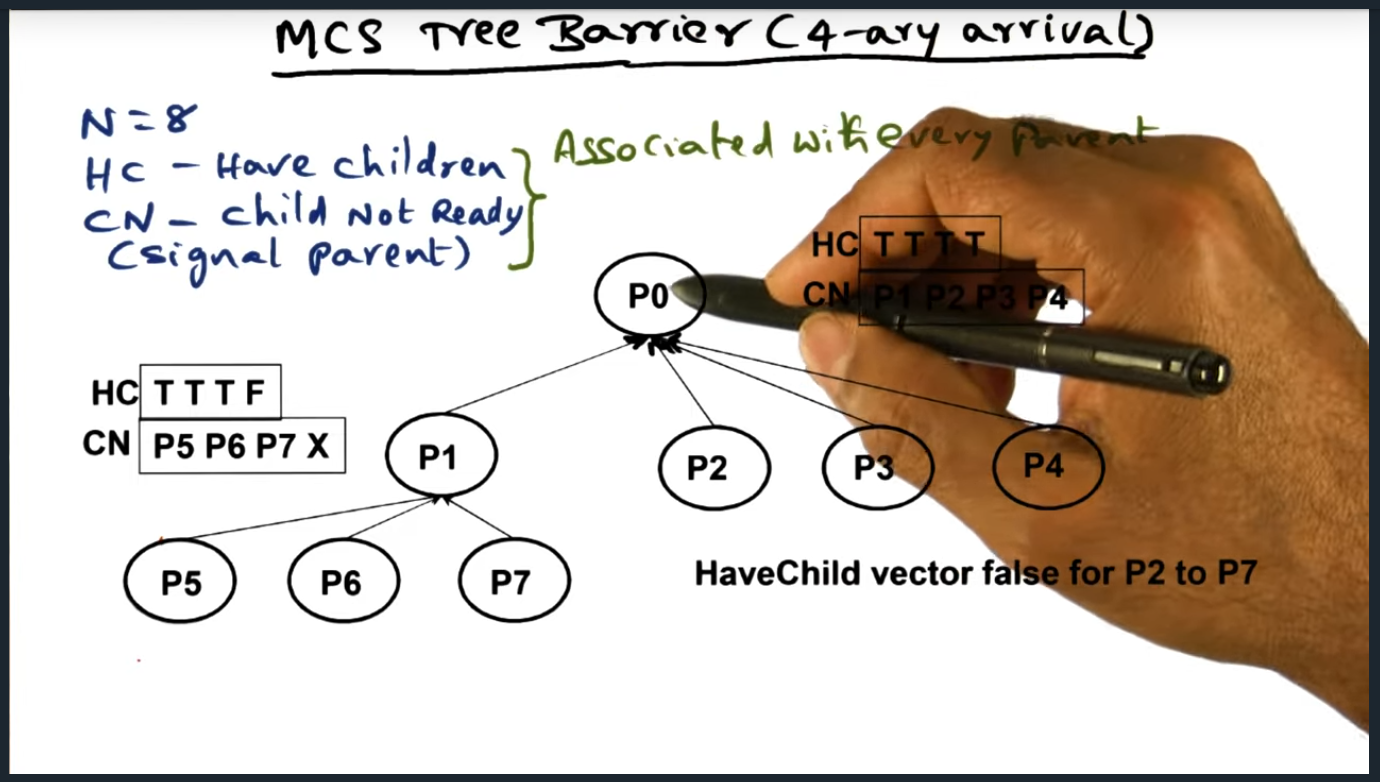
In the MCS tree barrier, there are two separate data structures that must be maintained. The first data structure (a 4-ary tree, each node containing a maximum of four children) handling the arrival of the processes and the second data structure handling the signaling and waking up of all other processes. In a nutshell, each parent node holds pointers to their children’s structure, allowing the parent process to wake up the children once all other children have arrived.
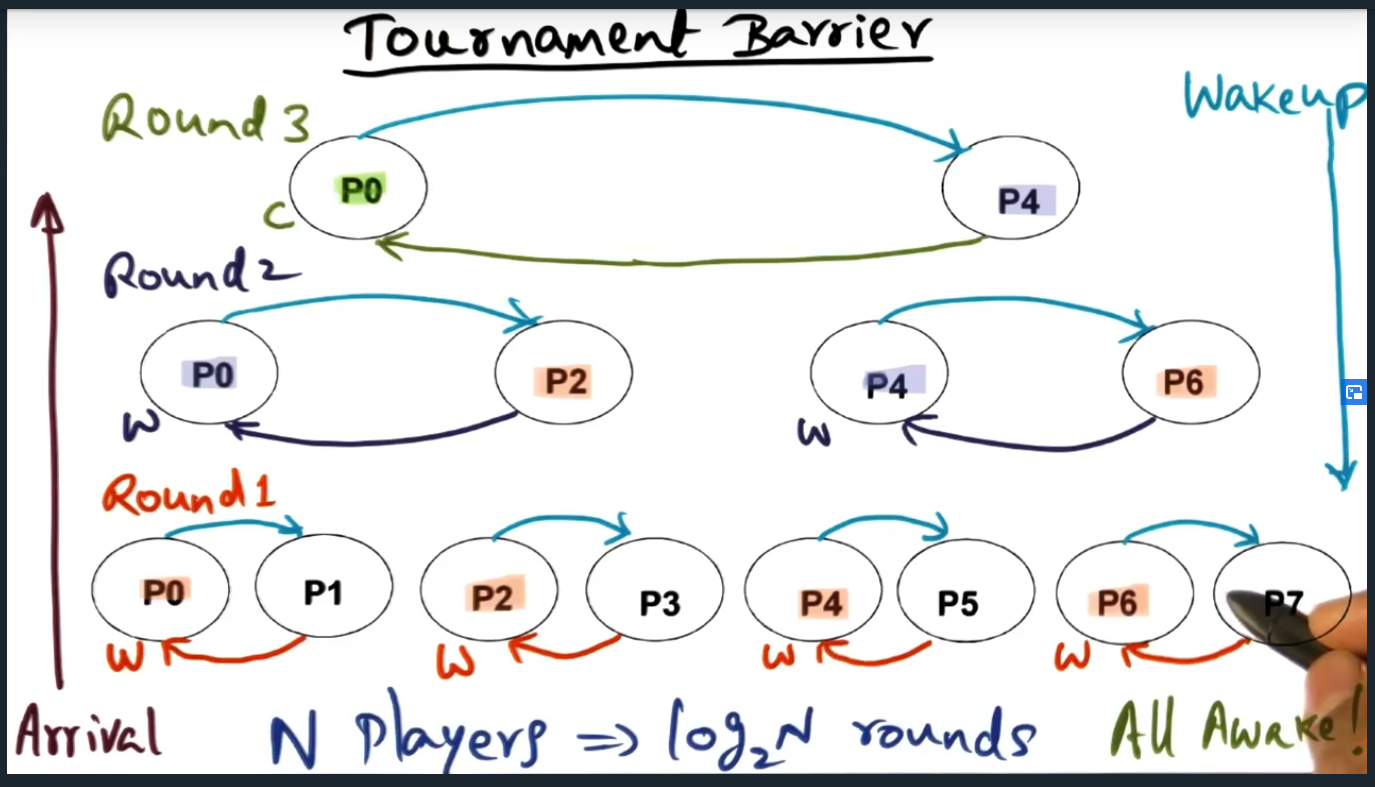
The tournament barrier constructs a tree too and at each level are two processes competing against one another. These competitions, however, are fixed: the algorithm predetermines which process will advanced to the next round. The winners percolate up the tree and at the top most level, the final winner signals and wakes up the loser. This waking up of the loser happens at each lower level until all nodes are woken up.
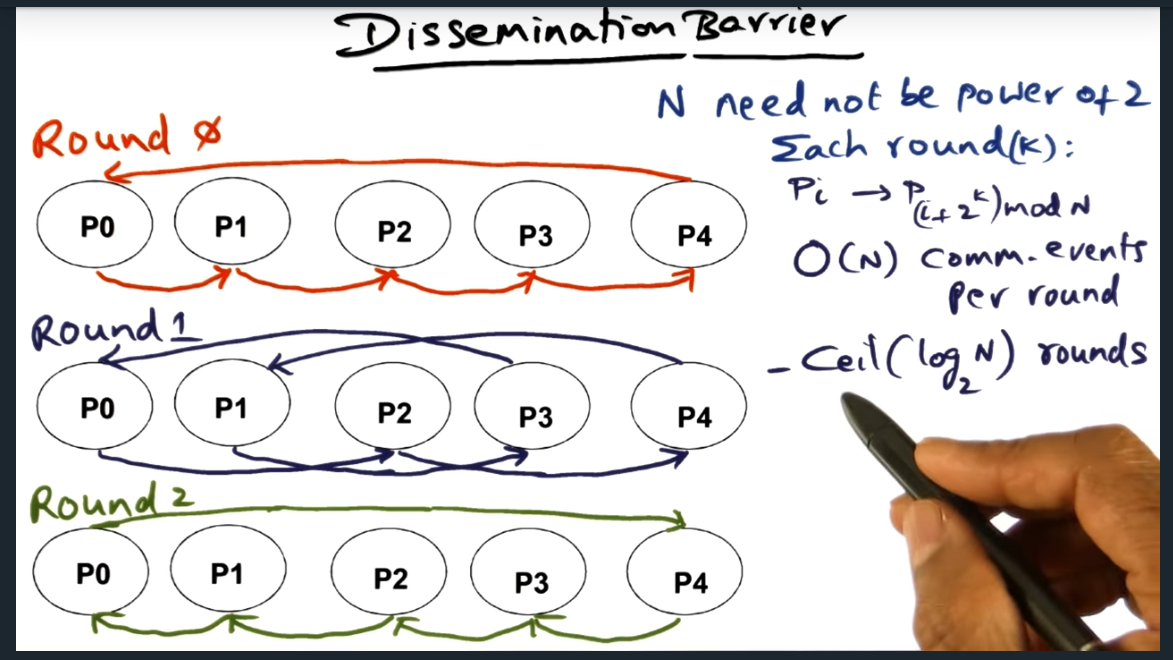
The dissemination protocol reminds me of a gossip protocol. With this algorithm, all nodes detect convergence (i.e. all processes arrived) once every process receives a message from all other processes (this is the key take away); a process receives one (and only one) message per round. The runtime complexity of this algorithm is nlogn (coefficient of n because during each round n messages, one message sent from one node to its ordained neighbor).
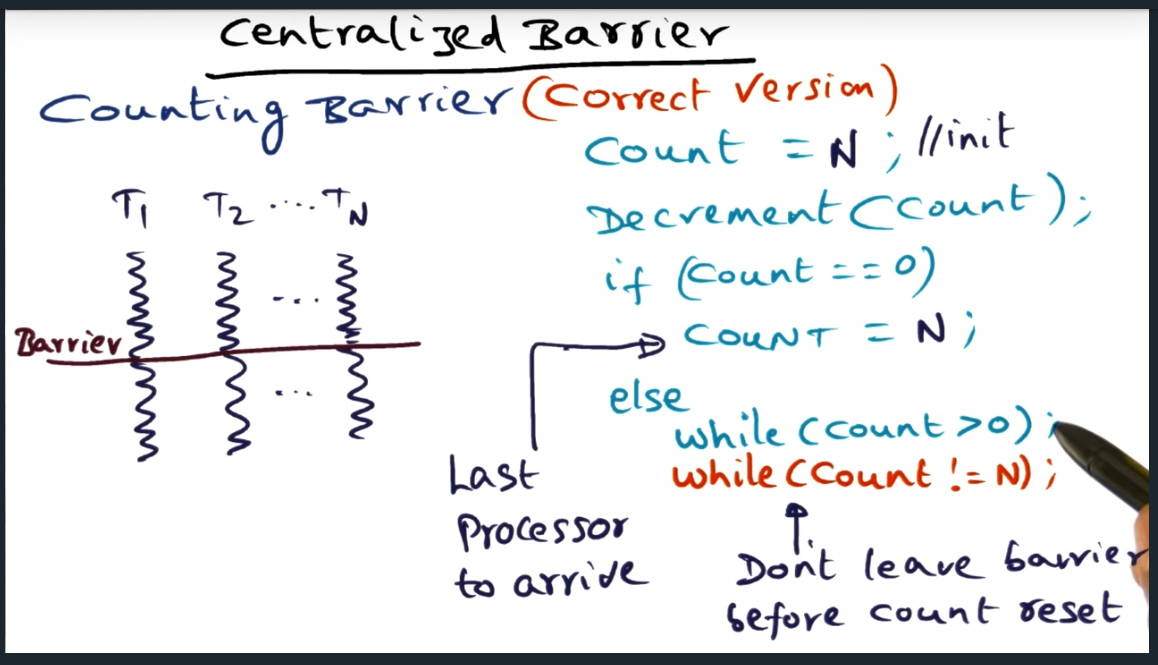
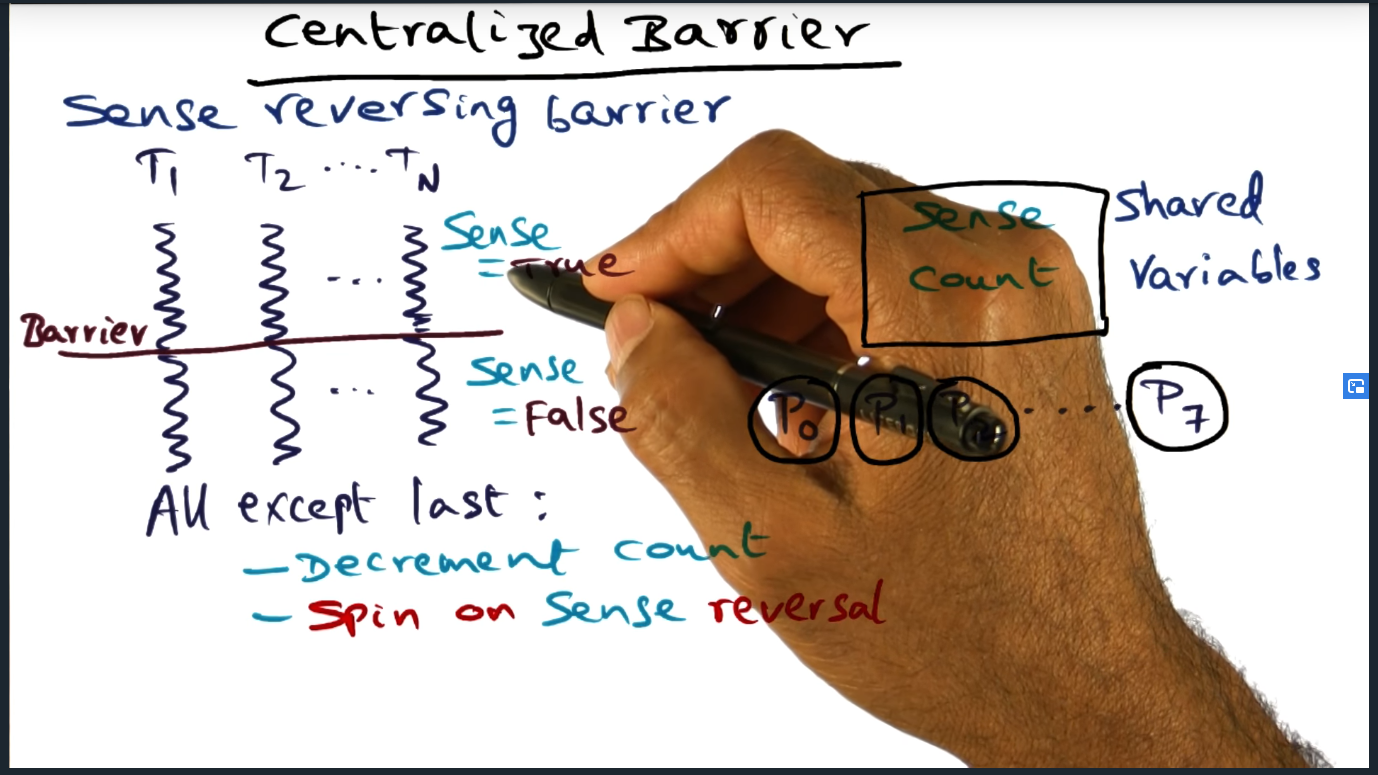
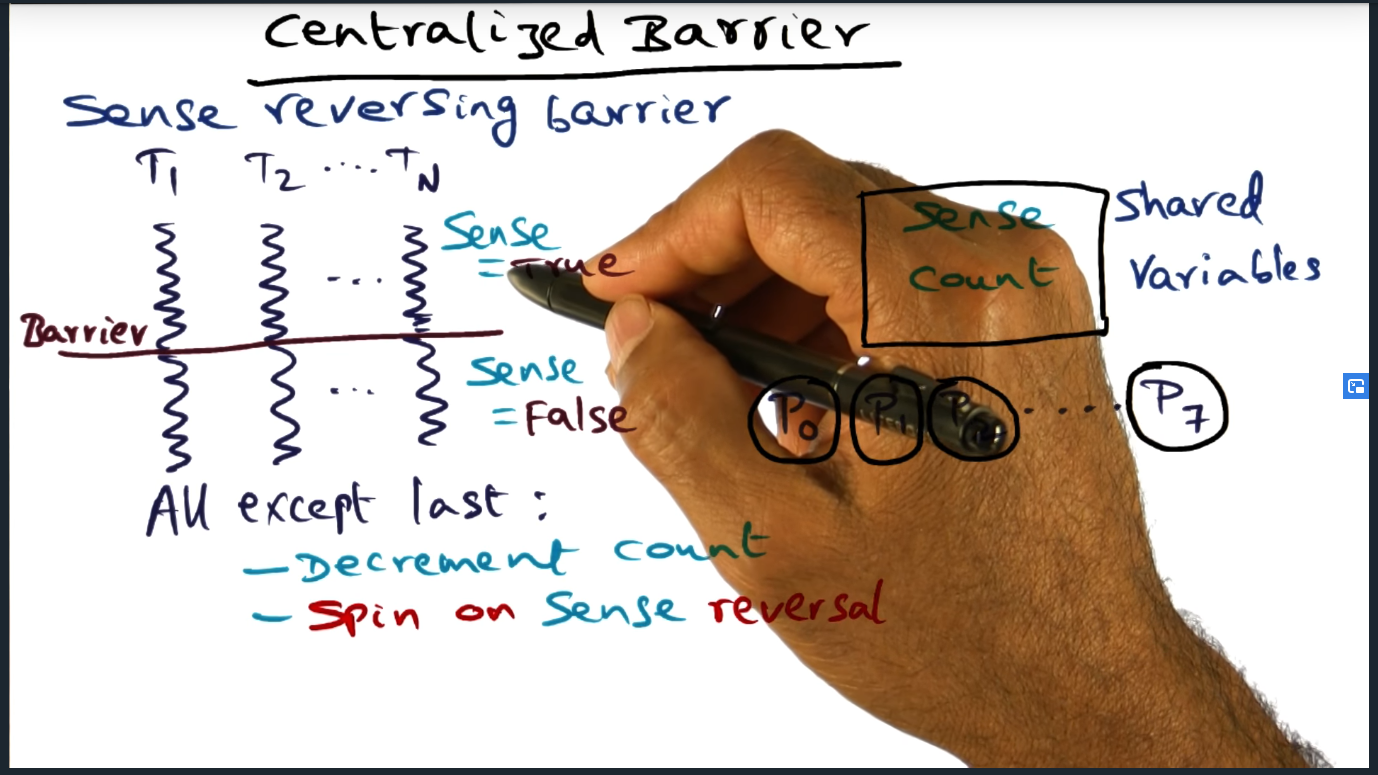
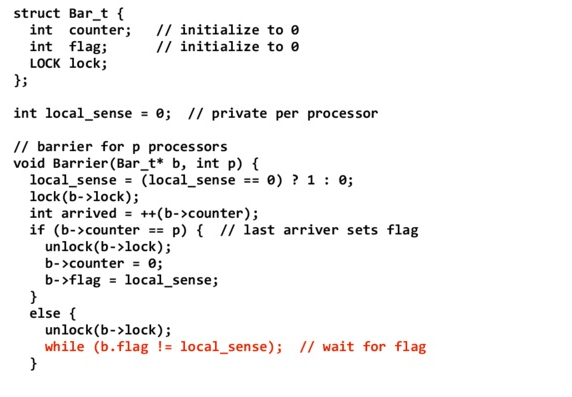
The algorithms described thus far share a common requirement: they all require sense reversal.
MCS Tree Barrier (Binary Wakeup)
Summary
Okay, I think I understand what’s going on. There are two separate data structures that need to be maintained for the MCS tree barrier. The first data structure handles the arrival (this is the 4-ary tree) and the second (binary tree) handles the signaling and waking up of all the other processes. The reason why the latter works so well is that by design, we know the position of each of the nodes and each parent contains a pointer to their children, allowing them to easily signal the wake up.
Tournament Barrier
Summary
Construct a tree and at the lowest level are all the nodes (i.e. processors) and each processor competes with one another, although the round is fixed, fixed in the sense that the winner is predetermined. Spin location is statically determined at every level
Tournament Barrier (Continued)
Summary
Two important aspects: arrival moves up the tree with match fixing. Then each winner is responsible for waking up the “losers”, traversing back down. Curious, what sort of data structure? I can see an array or a tree …
Tournament Barrier (Continued)
Summary
Lots of similarity with sense reversing tree algorithm
Dissemination Barrier
Summary
Ordered communication: like a well orchestrated gossip like protocol. Each process will send a message to ordained peer during that “round”. But I’m curious, do we need multiple rounds?
Dissemination Barrier (continued)
Summary
Gossip in each round differs in the sense the ordained neighbor changes based off of Pi -> P(I + 2^k) mod n. Will probably need to read up on the paper to get a better understanding of the point of the rounds ..
Quiz: Barrier Completion
Summary
Key point here that I just figured out is this: every processor needs to hear from every other processor. So, it’s log2N with a ceiling since N rounds must not be a power of 2 (still not sure what that means exactly)
Dissemination Barrier (continued)
Summary
All barriers need sense reversal. Dissemination barrier is no exception. This barrier technique works for NCC and clusters.Every round has N messages. Communication complexity is nlogn (where N is number of messages) and log(n). Total communication nlogn because N messages must be sent every round, no exception
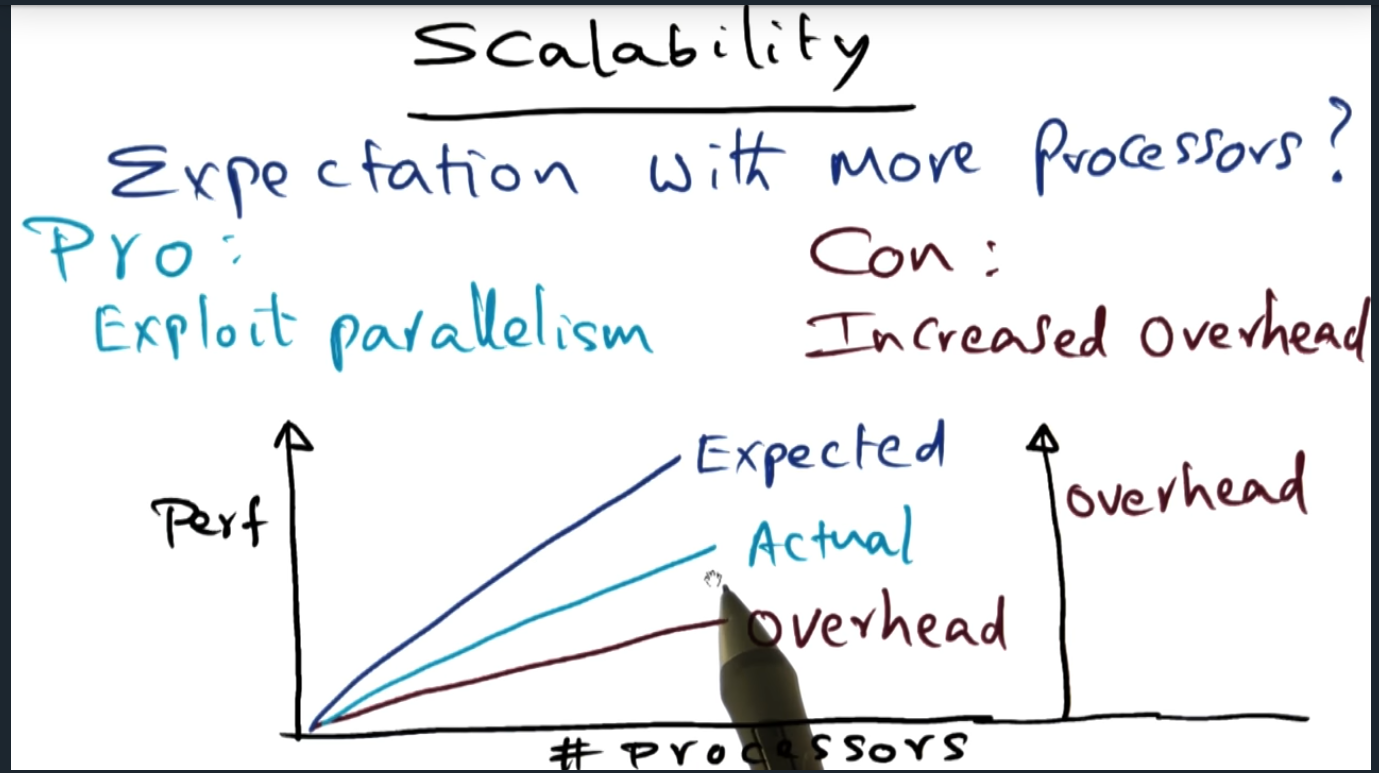
Performance Evaluation
Summary
Most important question to ask when choosing and evaluating performance is: what is the trend? Not exact numbers, but trends.