
An example

Summary
Key Words: Conditional variable, pthread_signal, pthread_wait
in the concrete example (screenshot below), P1 instructions that update memory (e.g. flag = 1) can be run in parallel with that of P2 because of release consistency model
Advantage of RC over SC
Summary
In a nutshell, we gain performance in a shared memory model using release consistency by overlapping computation with communication, because we no longer wait for coherence actions for every memory access
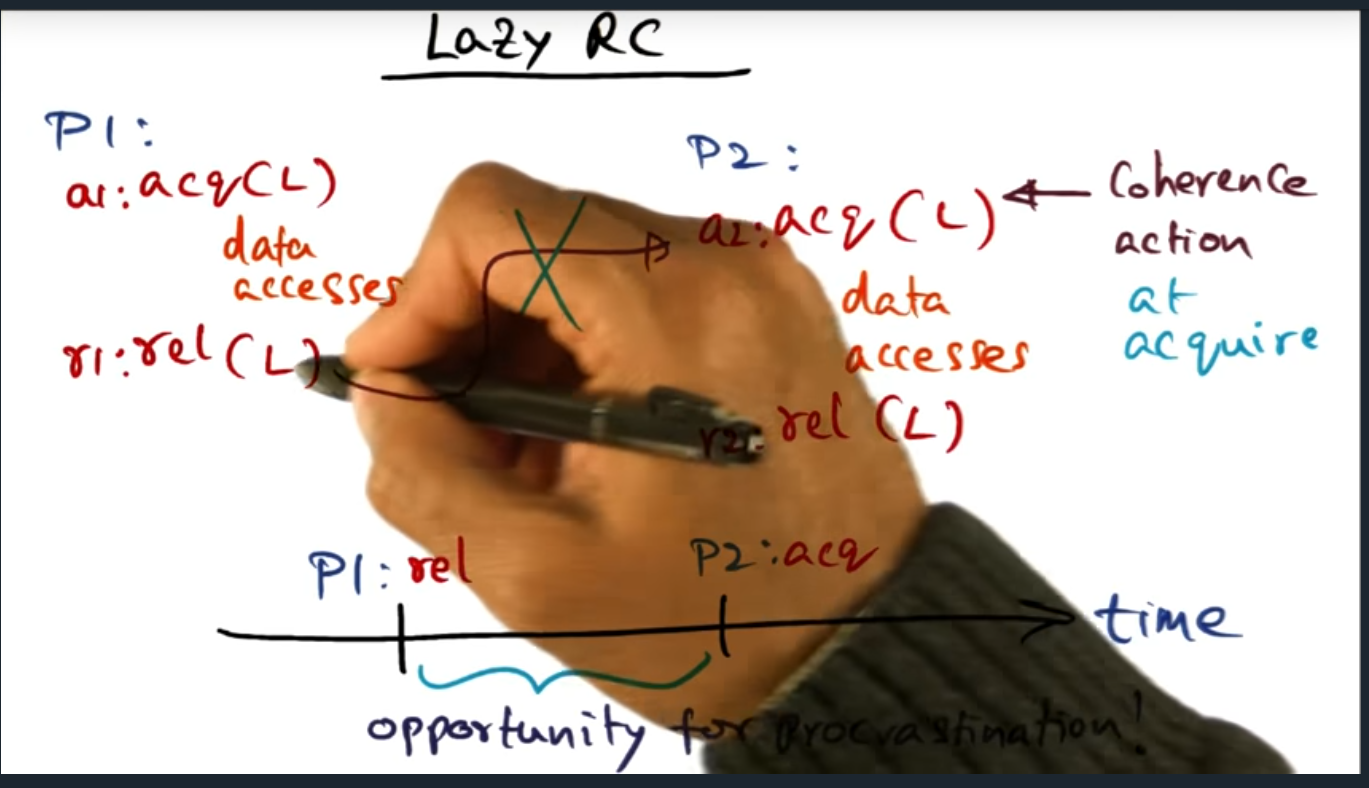
Lazy RC (release consistency)
Summary
Key Words: Eager
The main idea here is that the “release consistency” is eager, in the sense that cache coherence traffic is generated immediately after unlock occurs. But with lazy RC, we defer that cache coherence traffic until the acquisition
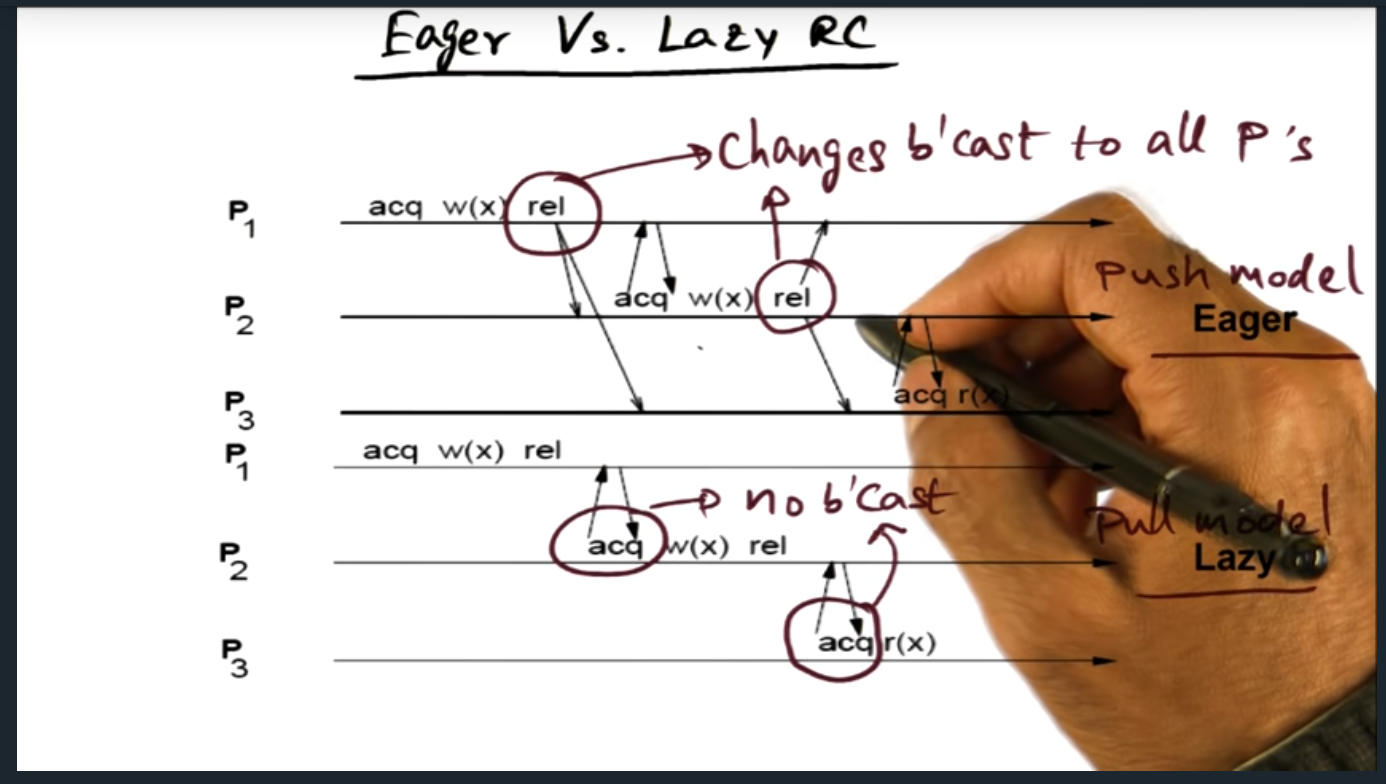
Eager vs Lazy RC
Summary
Key Words: Eager, Lazy
Basically, eager and lazy goes boils down to a push (i.e. eager) versus pull (i.e. lazy) model. In the former, every time the lock is released, coherence traffic broadcasts to all other processes
Pros and Cons of Lazy and Eager
Summary
Advantage of lazy (over eager) is that there are less messages however there will be more latency during acquisition
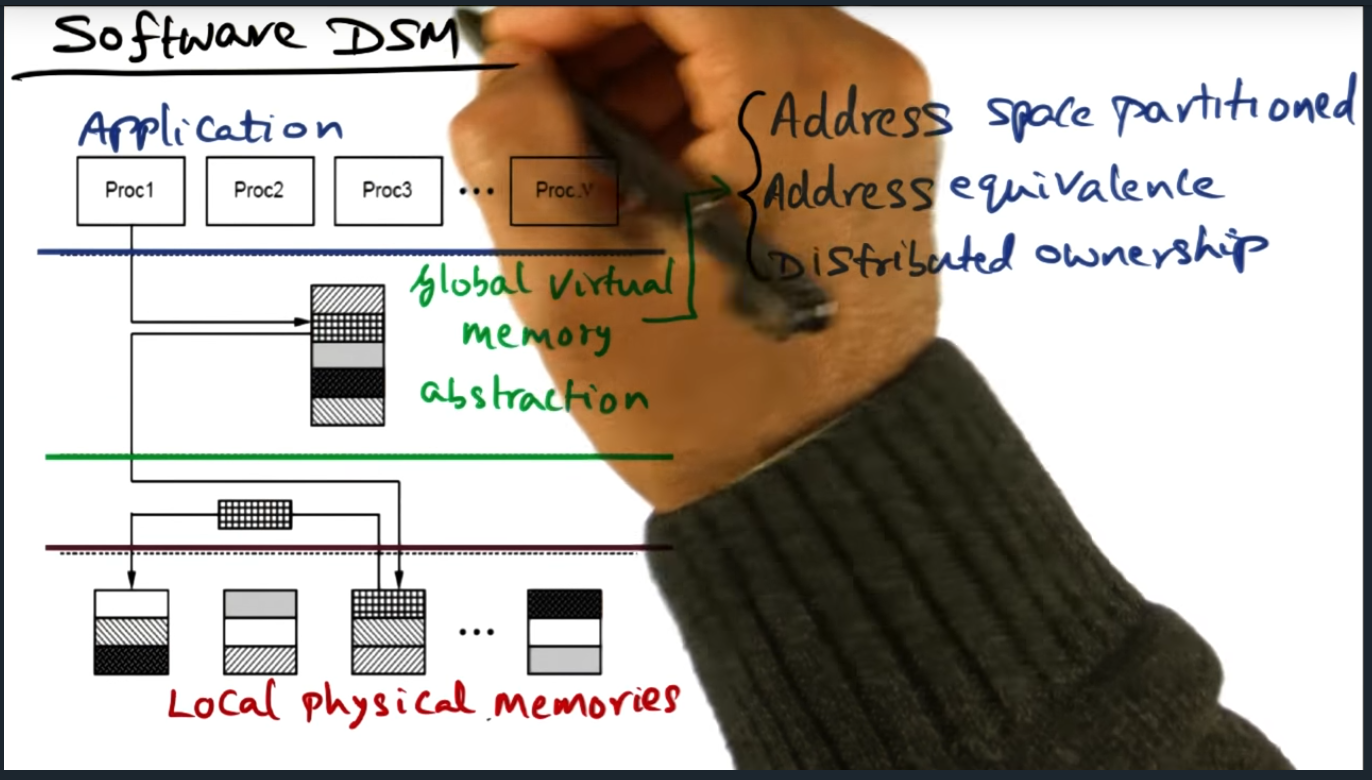
Software DSM
Summary
Address space is partitioned, meaning each processor is responsible for a certain set of pages. This model of ownership is a distributed, and each node holds metadata about the page and is responsible for sending coherence traffic (at the software level)
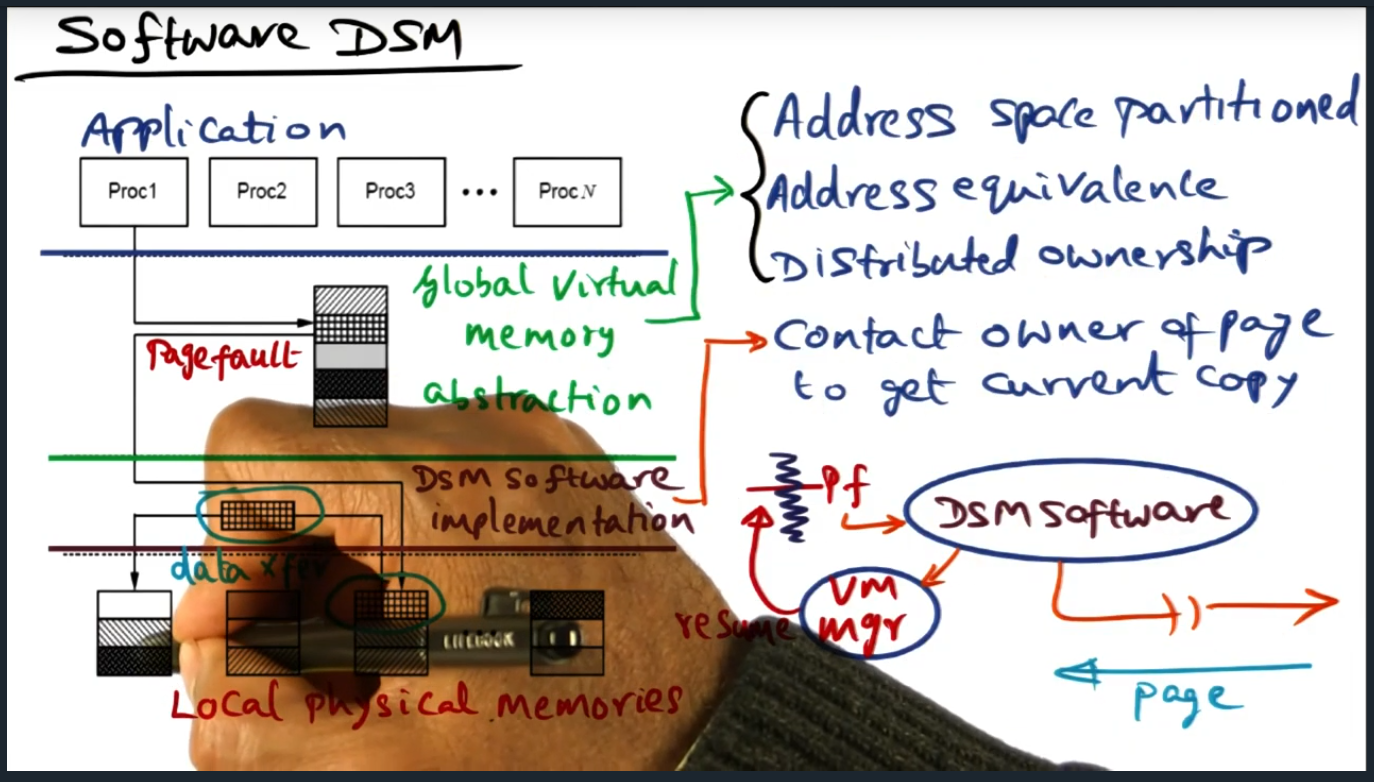
Software DSM (Continued)
Summary
Key Words: false sharing
DSM software runs on each processor (cool idea) in a single writer multiple reader model. This model can be problematic because, coupled with false sharing, will cause significant bus traffic that ping pongs updates when multiple data structures live within the same cache line (or page)
LRC with Mutli-Writer Coherence Protocol

Summary
With lazy release consistency, a process will (during the critical section) generate a diff of the pages that have been modified, the diff later applied when another process performs updates to those same pages
LRC with Multi-Writer Coherence Protocol (Continued)
Summary
Need to be able to apply multiple diffs in a row, say Xd and Xd’ (i.e. prime)
LRC with Multi Writer Coherence Protocol (Continued)
Summary
Key Words: Multi-writer
The same page can be modified at the same time by multiple threads, just so as long as a separate lock is used
Implementation
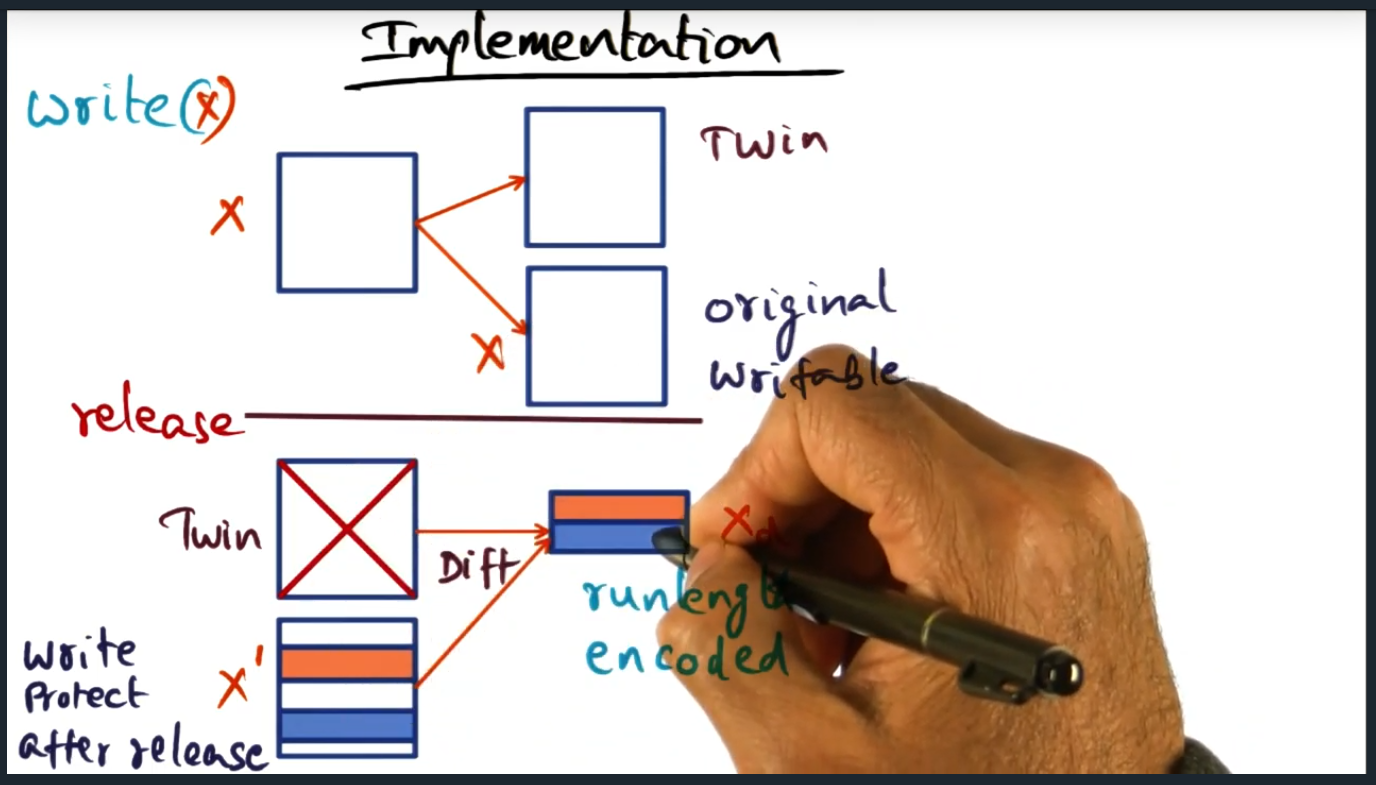
Summary
Key Words: Run-length encoded
During a write operation (inside of a lock), a twin page will get created, essentially a copy of the original page. Then, during release, a run-length encoded diff is computed. Following this step, the memory access is then write protected
Implementation (continued)
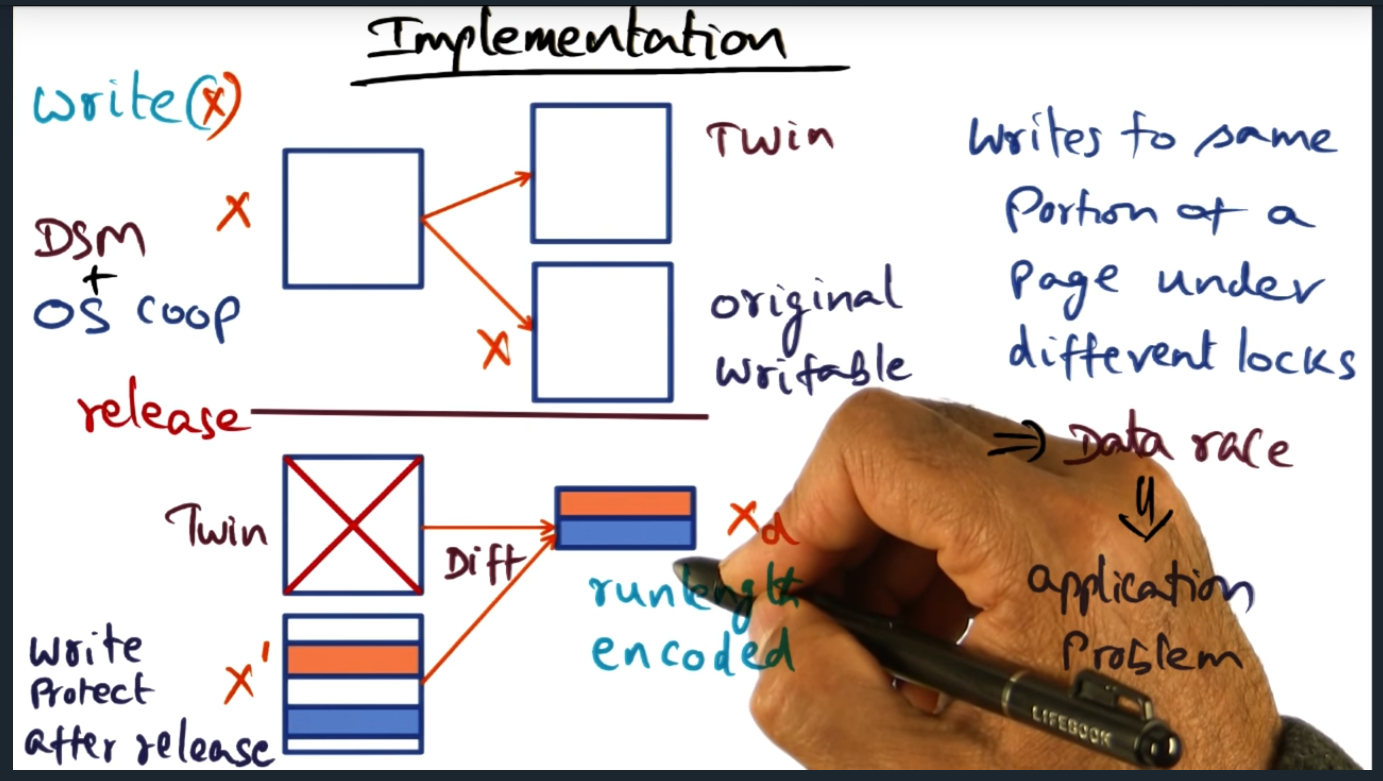
Summary
Key Words: Data Race, watermark, garbage collection
A daemon process (in every node) wakes up periodically and if the number of diffs exceed the watermark threshold, then daemon will apply diffs to original page. All in all, keep in mind that there’s overhead involved with this solution: overhead with space (for the twin page) and overhead in runtime (due to computing the run-length encoded diff)
Non Page Based DSM
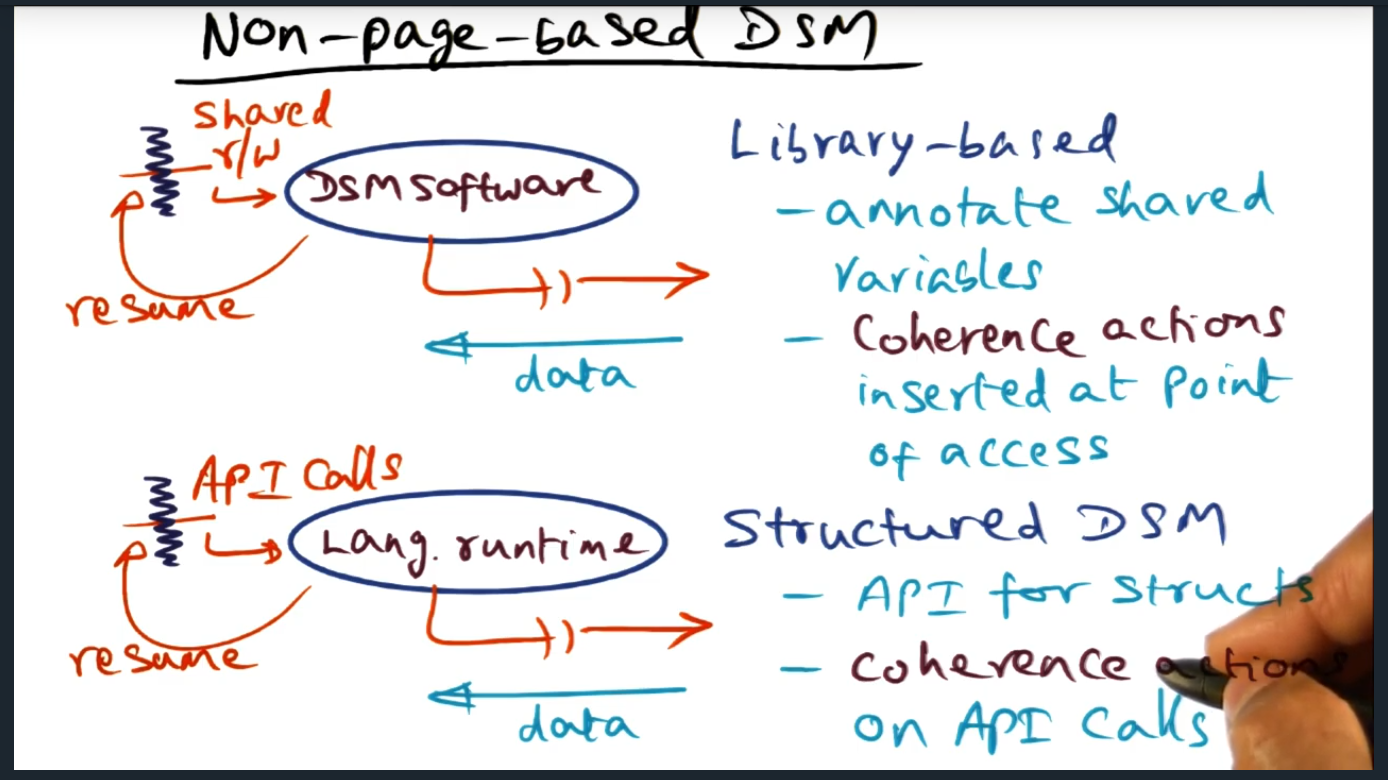
Summary
Two types of library based that offer alternatives, both that do not require OS support. The two approaches are library-based (variable granularity) and structured DSM (API for structures that triggers coherence actions)
Scalability

Summary
Do our (i.e. programmer’s) expectations get met as the number of processors increase: does performance increase accordingly as well? Yes, but there’s substantial overhead. To be fair, the same is true with true shared memory multiple processor