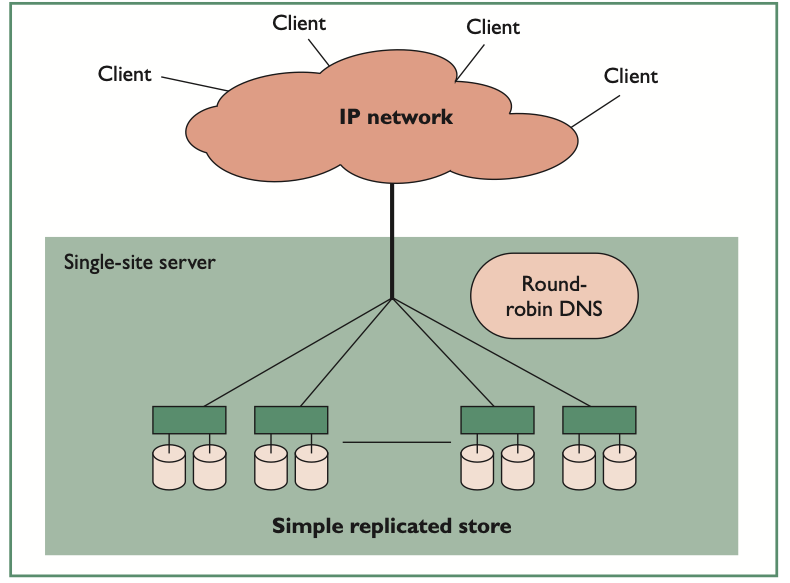
Introduction
We’ll address some questions like “how to program big data systems” and how to “store and disseminate content on the web in scalable manners”
Quiz: Giant Scale Services
Basically almost every service is backed by “Giant Scale” services
Tablet Introduction
This lesson covers three issues: system issues in giant scale services, programming models for applications working on big data and content distribution networks
Generic Service Model of Giant Scale Services
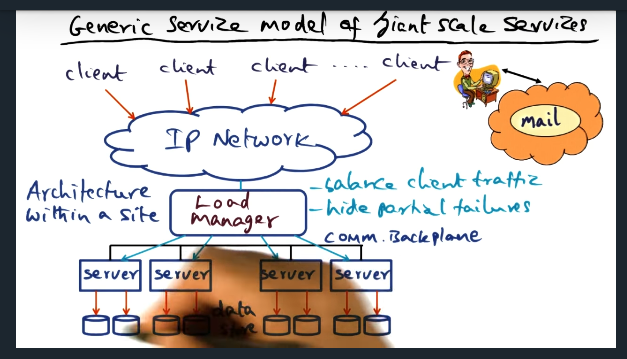
Key Words: partial failures, state
A load manager sits between clients and the back end services and is responsible for hiding partial failures by observing state of the servers
Clusters as workhorses

Key Words: SMP, backplane, computational clusters
Treat each node in the cluster as the same, connecting the nodes via a high performance backplane. This strategy offers advantages, allowing easy horizontal scaling, making it easy for a systems administrator manage the load and system
Load Management Choices
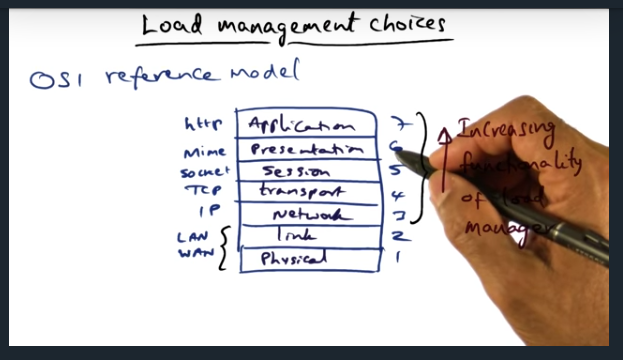
Key Words: OSI, application layer
The higher the layer in which you construct the load manager, the more functionality you can have
Load management at the network level
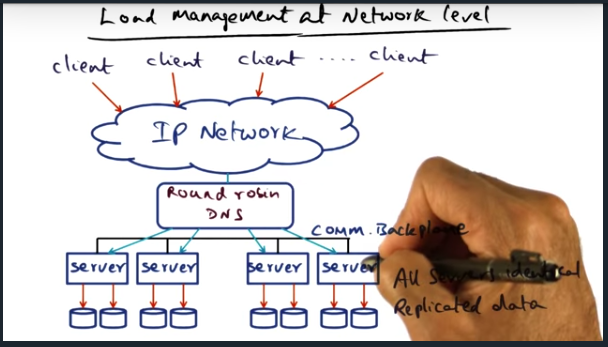
Key Words: DNS, semantics, partition
We can use DNS to load balancer traffic, but this approach does not hide server failures well. By moving up the stack, and performing balancing at the transport layer, we can balance traffic based off of service
DQ Principle
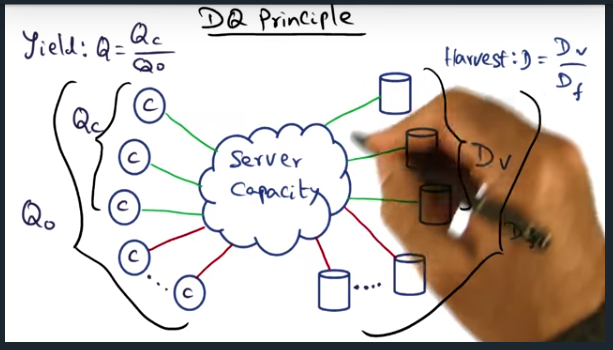
Key Words: DF (full data set), corpus of data, harvest (D), yield
We’re getting a bit more formal here. Basically, there are two ratios: Q (yield) and D (harvest). Q’s formula is Qc (completed requests)/ Q0 (offered load). Ideally want this ratio to be 1, which means all client requests were serviced. For D (harvest), formula is Dv (available data) / DF (full data). Again, want this ratio to be 1 meaning all data available to service client request
DQ Principle (continued)
Key Words: IOPS, metrics, uptime, assumptions, MTTR, MTBF, corpus of data, DQ
DQ principle very powerful, helps architect the system. We can increase harvest (data), but keep the yield the same. Increase the yield, but keeping D constant. Also, we can track several metrics including uptime, which is a ration between MTBF (mean time between failures) and MTTR (mean time to repair). Ideally, this ratio is 1 (but probably improbable). Finally, these knobs that a systems administrator can tweak assumes that the system is network bound, not IO bound
Replication vs Partitioning
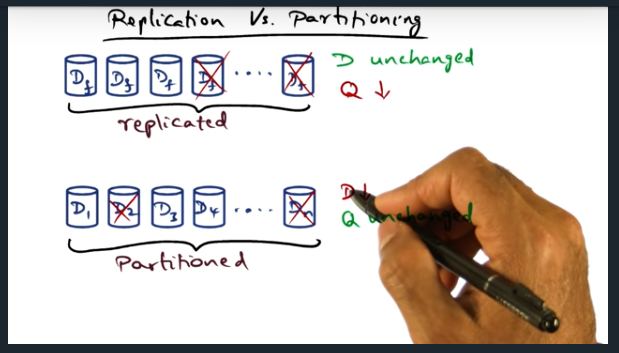
Key Words: replication, corpus of data, fidelity, strategy, saturation policy
DQ is independent of replication or partioning. And beyond a certain point, replication is preferred (from user’s perspective). During replication, harvest data is unaffected but yield decreases. Meaning, some users fail for some amount of time
Graceful Degradation

Key Words: harvest, fidelity, saturation, DQ, cost based admission control, value based admission control, reduce data freshness
DQ provides an explicit strategy for handling saturation. The technique allows the systems administrator to tweak the fidelity, or the yield. Do we want to continue servicing all customers, with degraded performance … or do we want to, once DQ limit is reached, service existing clients with 100% fidelity
Online Evolution and Growth
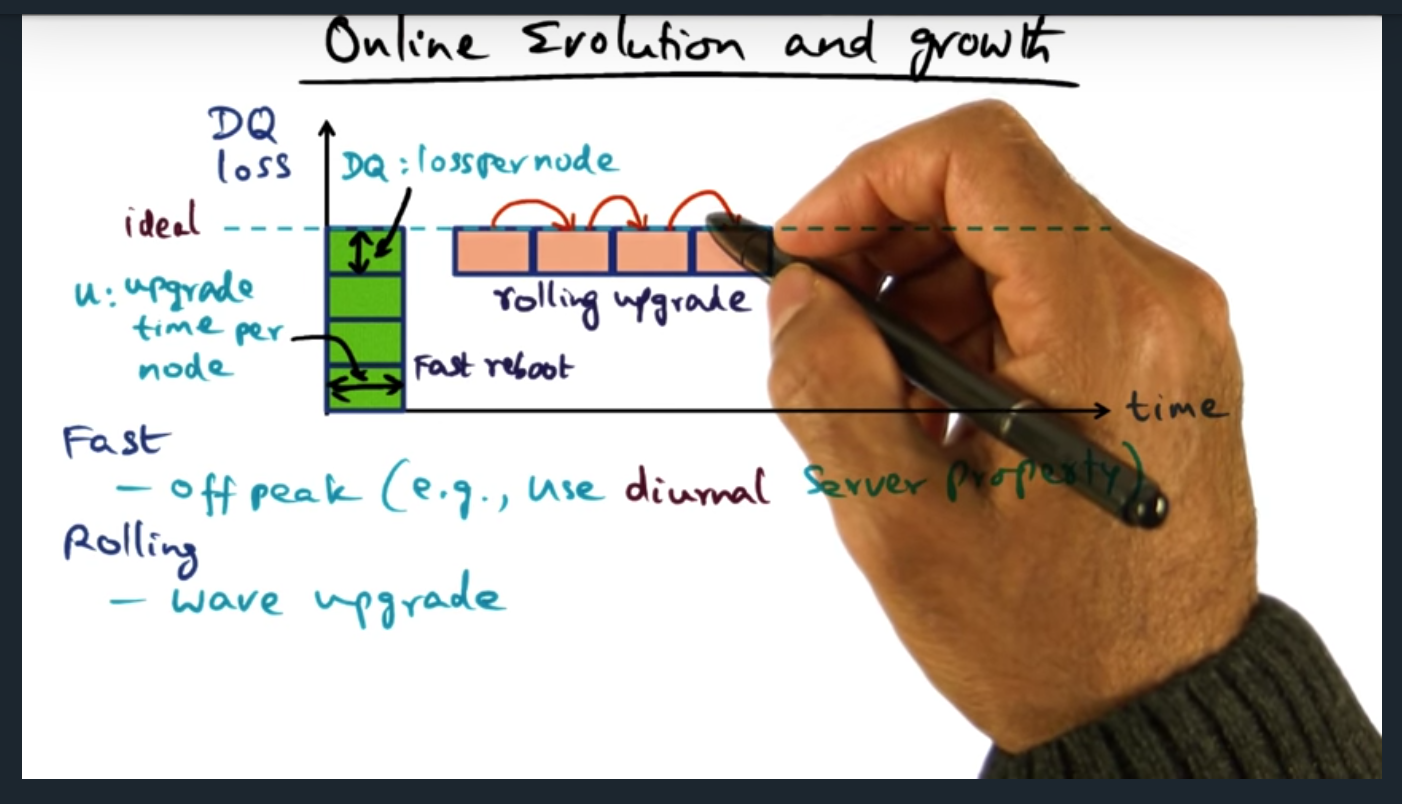
Key Words: diurmal server property
Two approaches for deploying software on large scale systems: fast and rolling. With fast deployment, services are upgraded off peak, all nodes down at once. Then there’s a rolling upgrade, in which the duration is longer than a fast deployment, but keeps the service available
Online evolution and growth (continued)
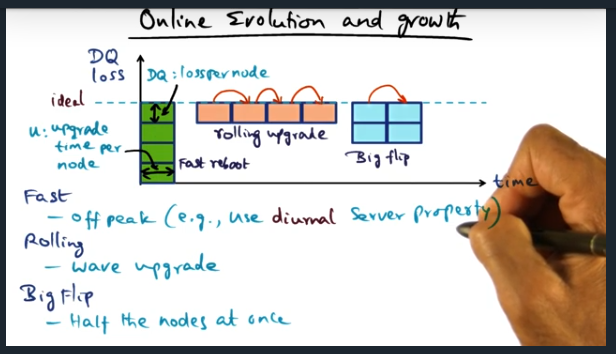
Key Words: DQ, big flip, rolling, fast
With a big flip, half the nodes are down, the total DQ down by half for U units of time
Conclusion
DQ is a tool for system designers to optimize for yield or for harvest. Also helps designer deal with load saturation, failed, or upgrades are planned