In part 1 of synchronization, I talked about the more naive spin locks and other naive approaches that offer only marginally better performance by adding delays or reading cached caches (i.e. avoiding bus traffic) and so on. Of all the locks discussed thus far, the array based queuing lock offers low latency, low contention and low waiting time. And best of all, the this lock offers fairness. However, there’s no free lunch and what we trade off performance for memory: each lock contains an array with N entries where N is the number of physical CPUs. That high number of CPUs may be wasteful (i.e. when not all processors contend for a lock).
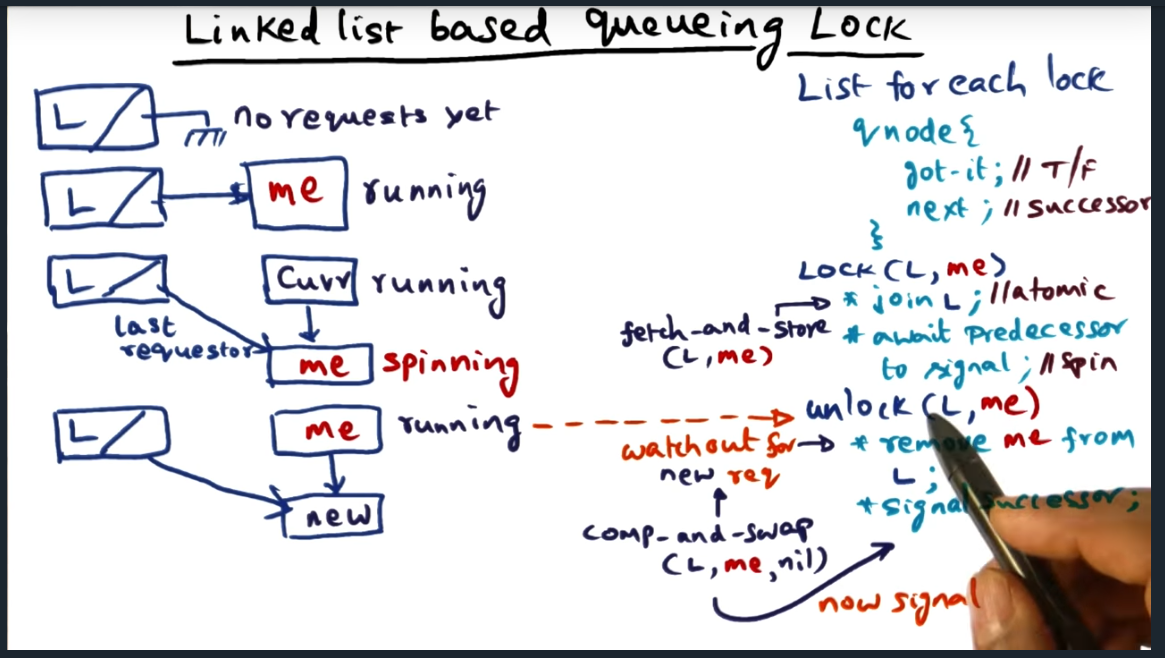
That’s where linked based queuing locks come in. Instead of upfront allocating a contiguous block of memory reserved for each CPU competing for lock, the linked based queuing lock will dynamically allocate a node on the heap and maintain a linked list. That way, we’ll only allocate the structure as requests trickle in. Of course, we’ll need to be extremely careful with maintaining the linked list structure and ensure that we are atomically updating the list using instructions such as fetch_and_store during the lock operation.
Most importantly, we (as the OS designer that implement this lock) need to carefully handle the edge cases, especially while removing the “latest” node (i.e. setting it’s next to NULL) while another node gets allocated. To overcome this classic race condition, we need to atomically rely on a new (to me at least) atomic operation: compare_and_swap. This instruction will be called like this: compare_and_swap(latest_node, me, nil). If the latest node’s next pointer matches me, then set the next pointer to NIL. Otherwise, we know that there’s a new node in flight and will have to handle the edge case.
Anyways, check out the last paragraph on this page if you want a nice matrix that compares all the locks discussed so far.
Linked Based Queuing Lock
Summary
Similar approach to Anderson’s array based queueing lock, but using a linked list (authors are MCS: mellor-crummey J.M. Scott). Basically, each lock has a qnode associated with it, the structure containing a got_it and next. When I obtain the lock, I point the qnode towards me and can proceed into the critical section
Link Based Queuing Lock (continued)
Summary
The lock operation (i.e. Lock(L, me)) requires a double atomic operation, and to achieve this, we’ll use a fetch_and_store operation, an instruction that retrieves the previous address and then stores mine
Linked Based Queuing Lock
Summary
When calling unlock, code will remove current node from list and signal successor, achieving similar behavior as array based queue lock. But still an edge case remains: new request is forming while current thread is setting head to NIL
Linked Based Queuing Lock (continued)
Summary
Learned about a new primitive atomic operation called compare and swap, a useful instruction for handling the edge of updating the dummy node’s next pointer when a new request is forming
Linked Based Queuing Lock (continued)
Summary
Hell yea. Correctly anticipated the answer when professor asked: what will the thread spin on if compare_and_swap fails?
Linked Based Queuing Lock (continued)
Summary
Take a look at the papers to clarify the synchronization algorithm on a multi-processor. Lots of primitive required like fetch and store, compare and swap. If these hardware primitives are not available, we’ll have to implement them
Linked Based Queuing Lock (continued)
Summary
Pros and Cons with linked based approach. Space complexity is bound by the number of dynamic requests but downside is maintenance overhead of linked list. Also another downside potentially is if no underlying primitives for compare_and_swap etc.
Algorithm grading Quiz
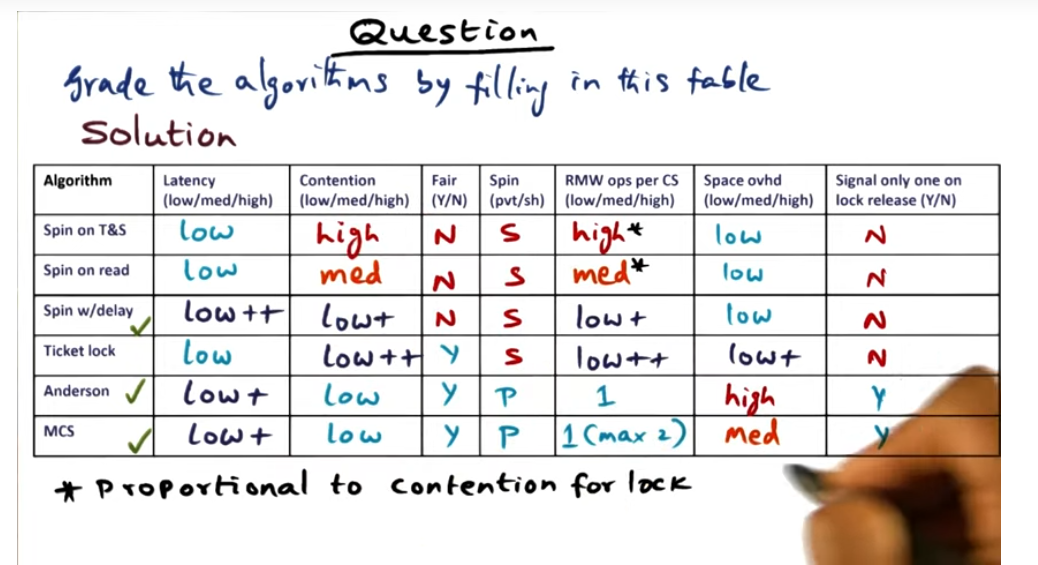
Summary
Amount of contention is low, then use spin w delay plus exponential backoff. If it’s highly contended, then use statically assigned.