Introduction
Summary
Main question is this: can we make a cluster look like a shared memory machine
Cluster as a parallel machine (sequential program)
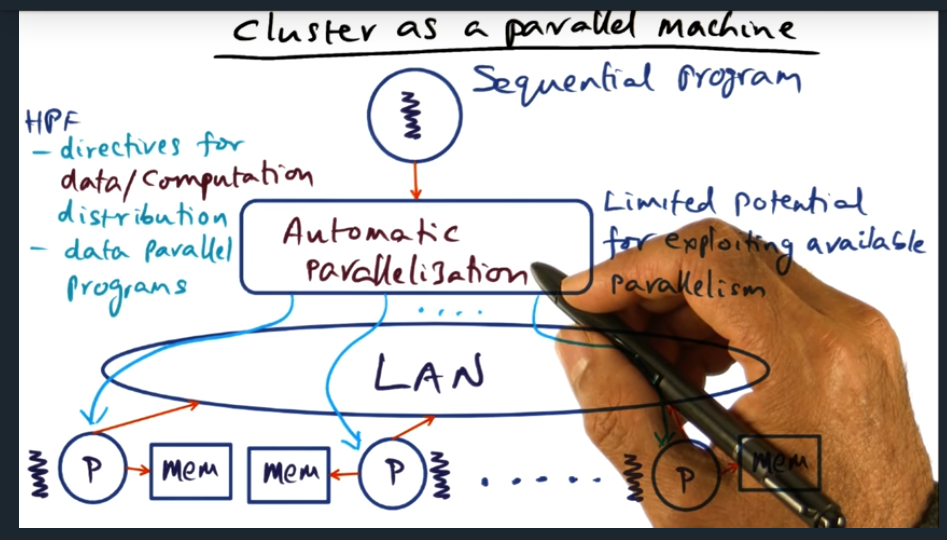
Summary
One strategy is to not write explicit parallel programs and instead use language assisted features (like pragma) that signal to the compiler that this section be optimized. But, there are limitations with this implicit approach
Cluster as a parallel machine (message passing)
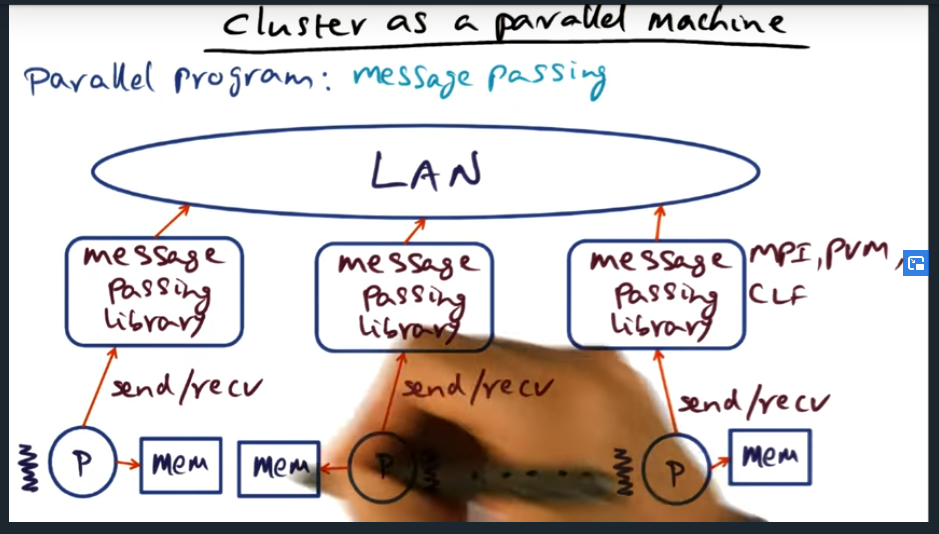
Summary
Key Words: message passing
One (of two) styles for explicitly writing parallel programs is by using message passing. Certain libraries (e.g. MPI, PVM, CLF) use this technique and true to a process’s nature, the process does not share its memory and instead, if the process needs to communicate with another entity, it does so by message passing. The downside? More effort from the perspective of the application developer
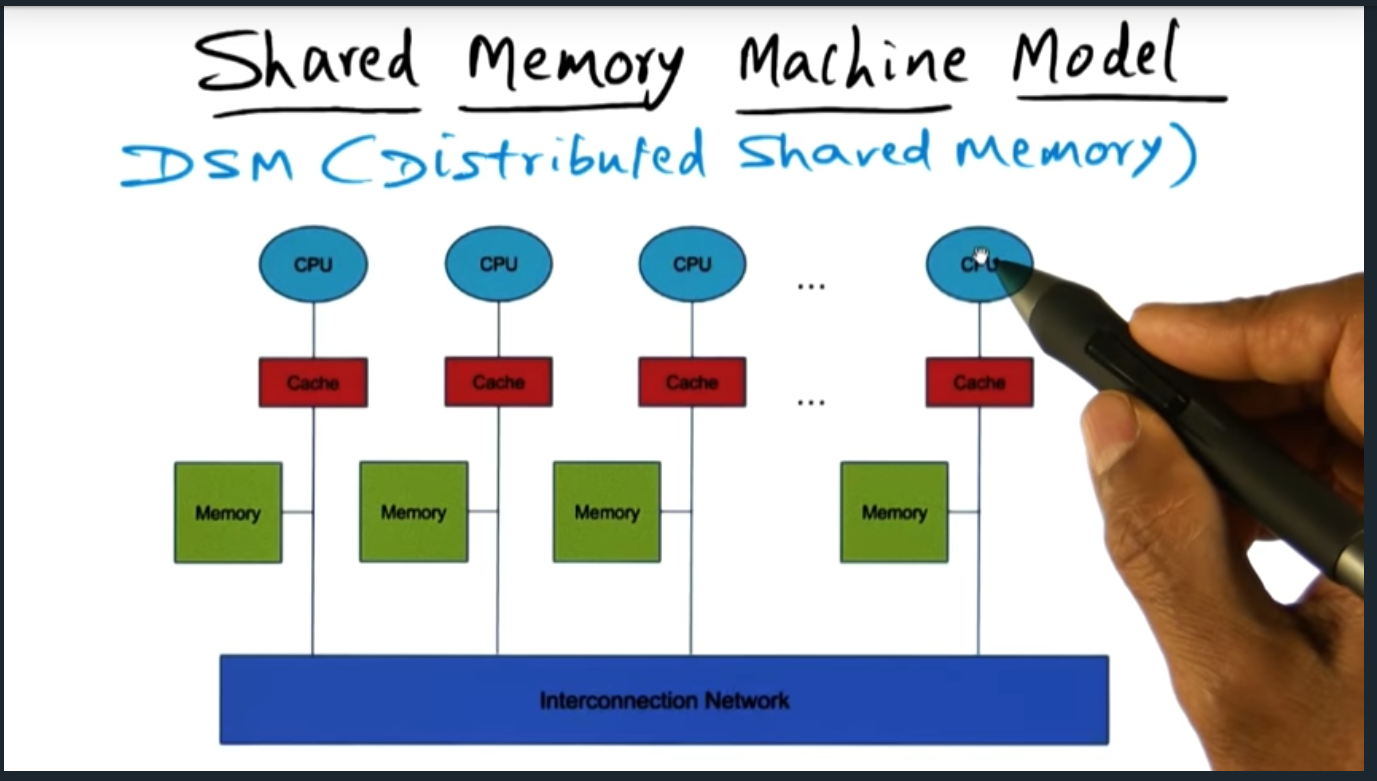
Cluster as a parallel machine (DSM)
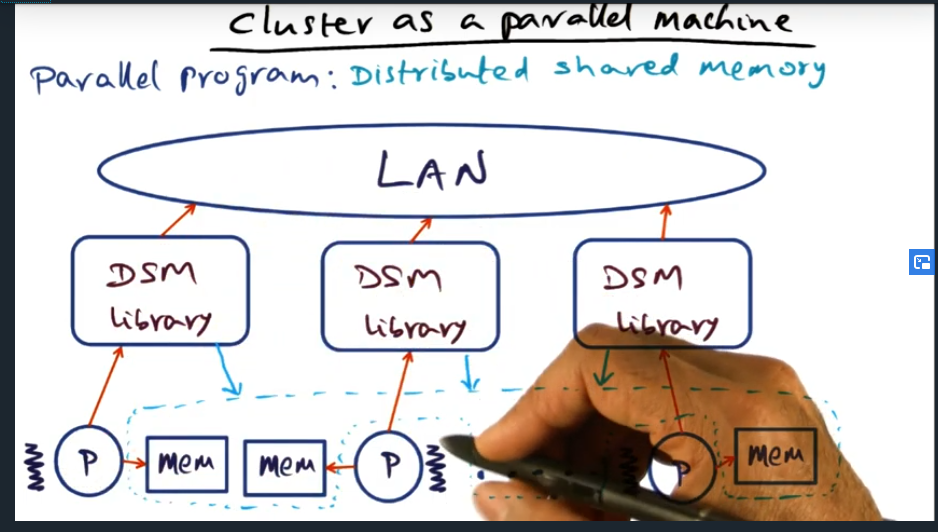
Summary
The advantage of a DSM (distributed shared memory) is that an application developer can ease their way in, their style of programming need not change: they can still use locks, barriers, and pthreads styles, just the way they always have. So the DSM library provides this illusion of a large shared memory address space.
History of shared memory systems

Summary
In a nutshell, software DSM has its roots in the 80s, when Ivy league academics wanted to scale the SMP. And now, (in the 2000s), we are looking at clusters of symmetric memory processors.
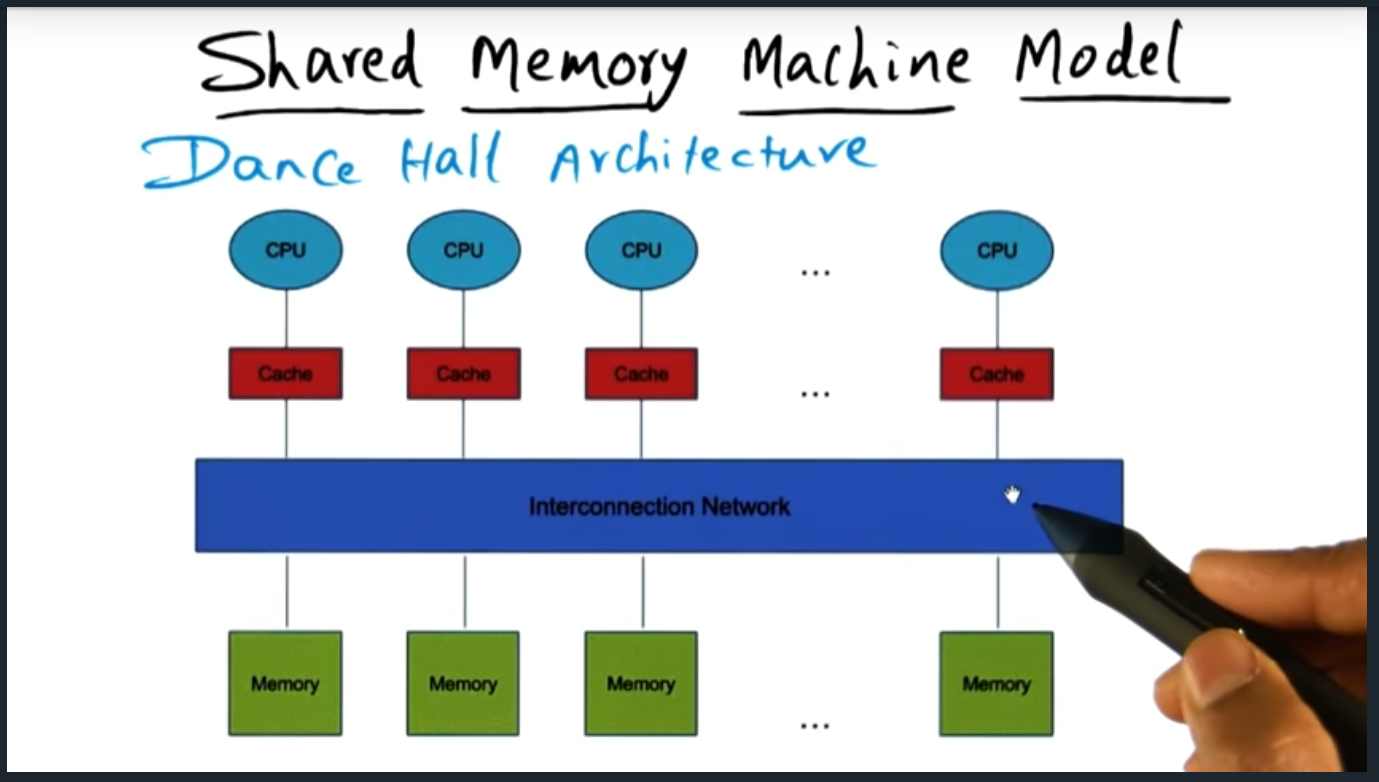
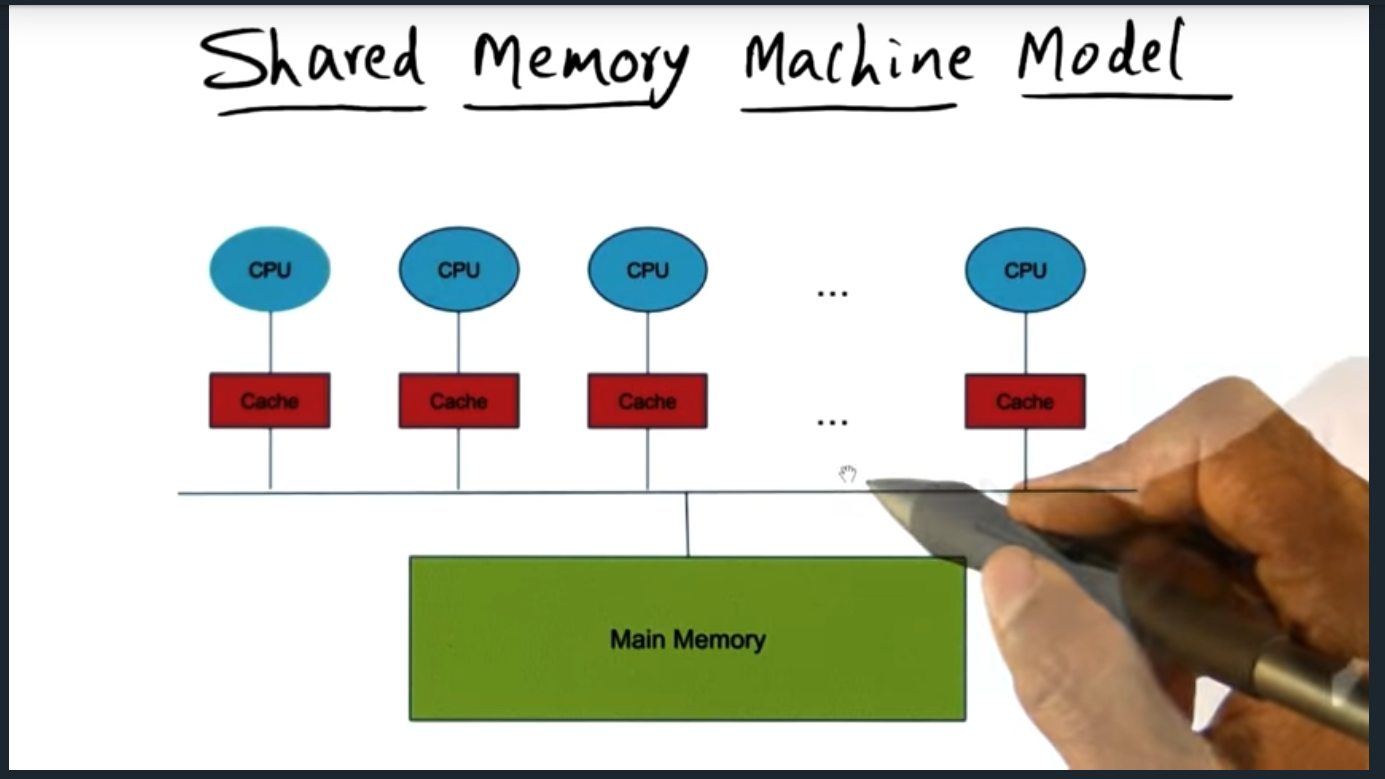
Shared Memory Programming
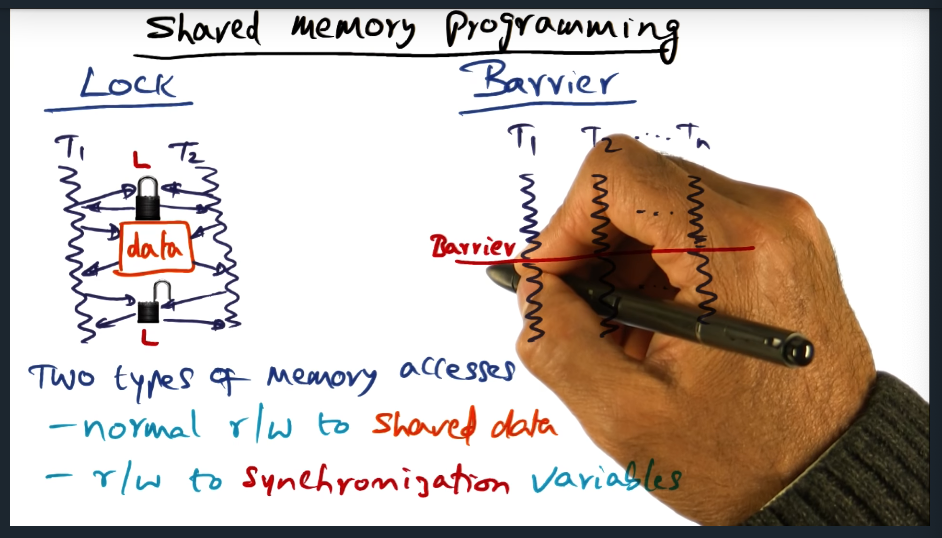
Summary
There are two types of synchronization: mutual exclusion and barrier. And two types of memory accesses: normal read/writes to shared data, and read/write to synchronization variables
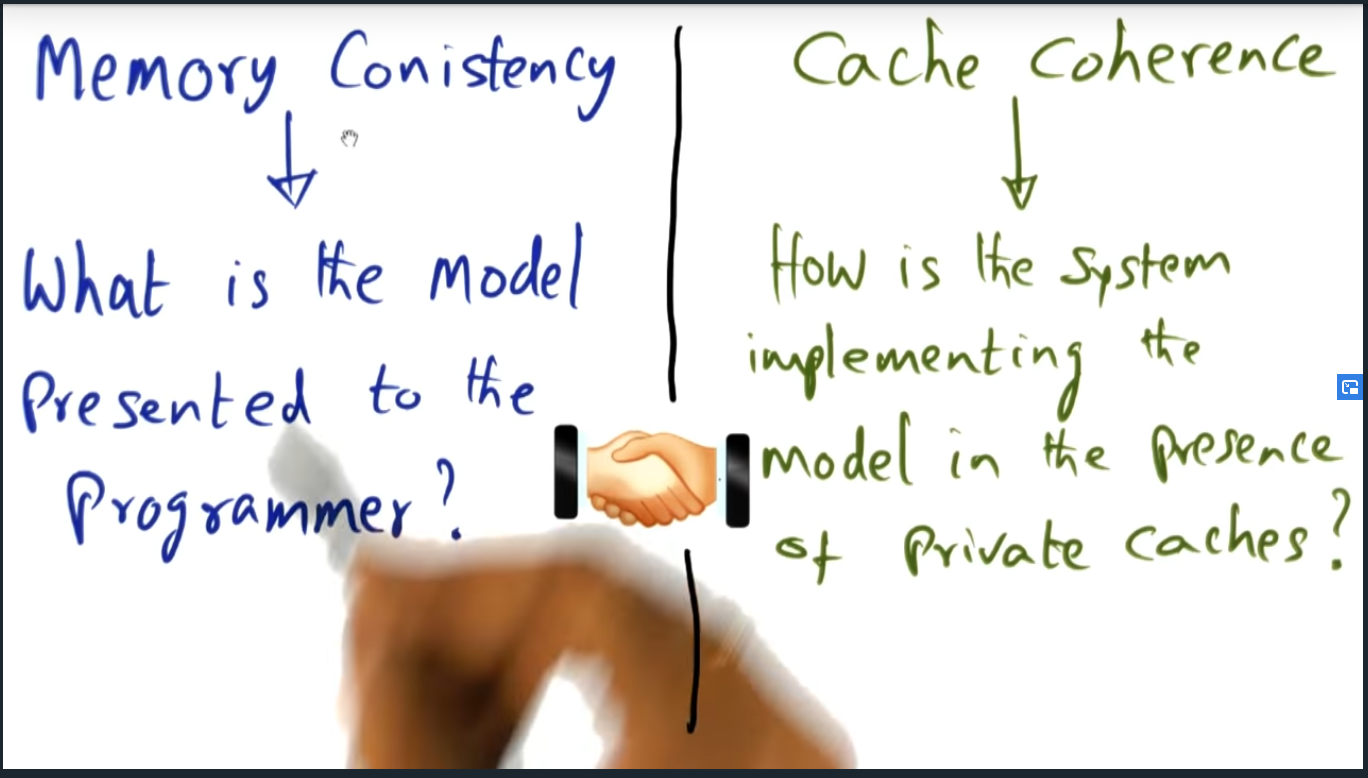
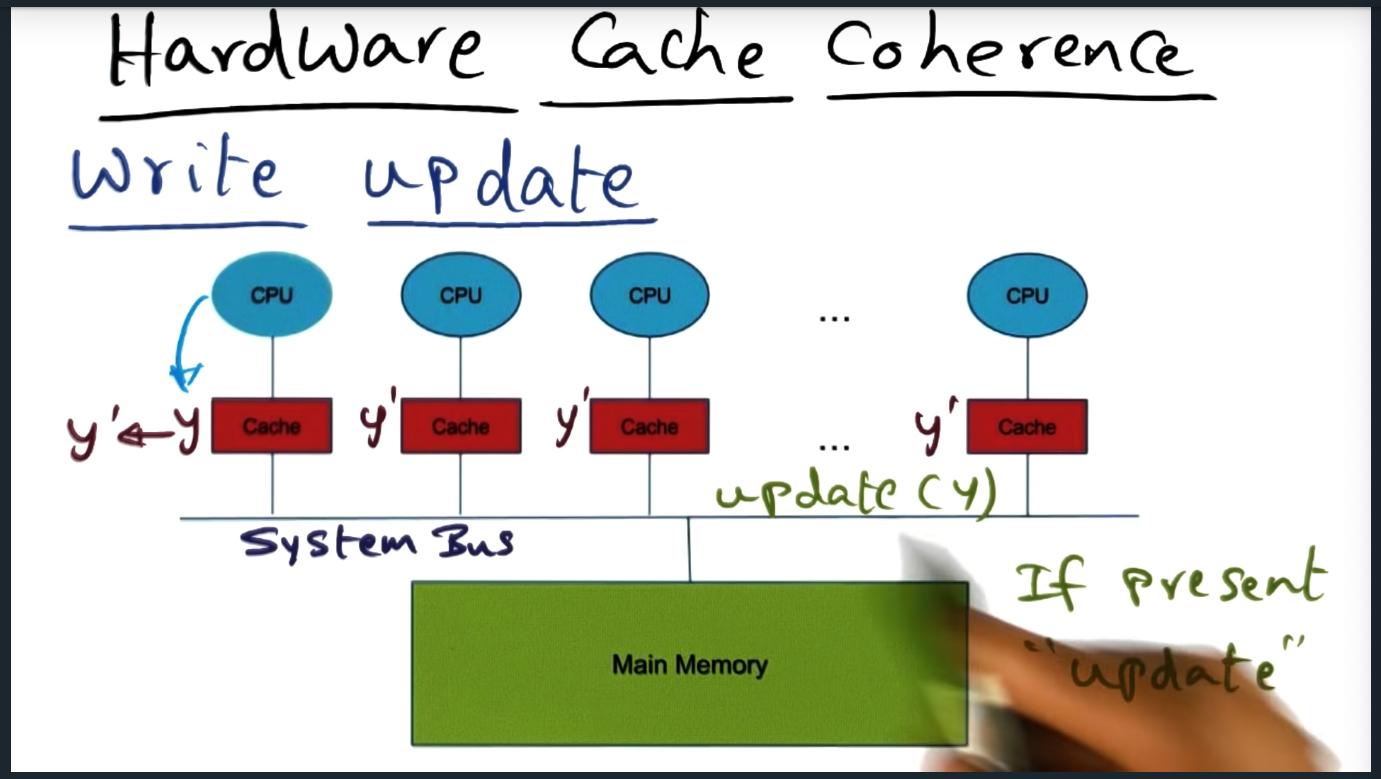
Memory consistency and cache coherence
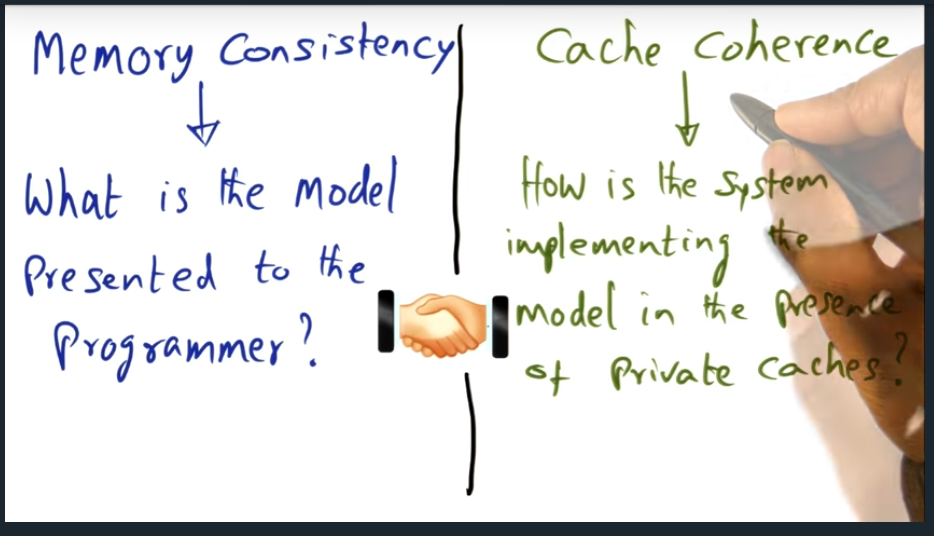
Summary
Key Words: Cache Coherence, Memory consistency
Memory consistency is the contract between programmer and the system and answers the question “when”: when will a change to the shared memory address space reflect in the other process’s private cache. And cache coherence answers the “how”, what mechanism will be used (cache invalidate or write update)
Sequential Consistency

Summary
Key Words: Sequential Consistency
With sequential consistency, program order is respected, but there’s arbitrary interleaving. Meaning, each individual read/write operations are atomic on any processor
SC Memory Model
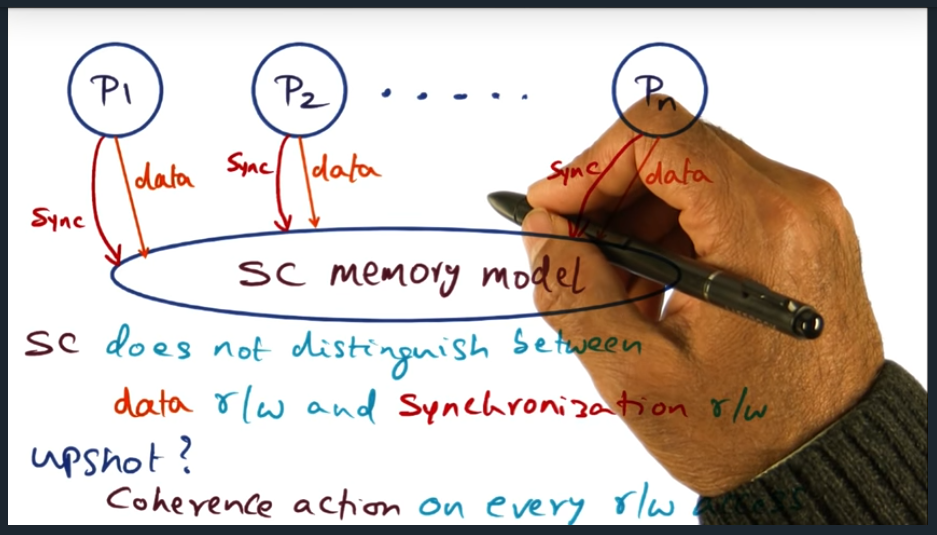
Summary
With sequential consistency, the memory model does not distinguish a read/write access to a synchronization read/write access. Why is this important? Well, we always get the coherence action, regardless of memory access type
Typical Parallel Program

Summary
Okay, I think I get the main gist and what the author is trying to convey. Basically, since we cannot distinguish the reads and writes for memory accesses — from normal read/write versus synchronization read/write — then that means (although we called it out as a benefit earlier) cache coherence will continue to take place all throughout the critical section. But, the downside here is that that coherence traffic, is absolutely unnecessary. And really, what we probably want is that only after we unlock the critical section should the data within that critical section, be updated across all other processor cache
Release Consistency

Summary
Key Words: release consistency
Release consistency is an alternative memory consistency model to sequential consistency. Unlike sequential consistency, which will block a process until coherence has been achieved for an instruction, release consistency will not block but will guarantee coherence when the lock has been released: this is a huge (in my opinion) performance improvement. Open question remains for me: does this coherence guarantee impact processes that are spinning on a variable, like a consumer