Introduction
Summary
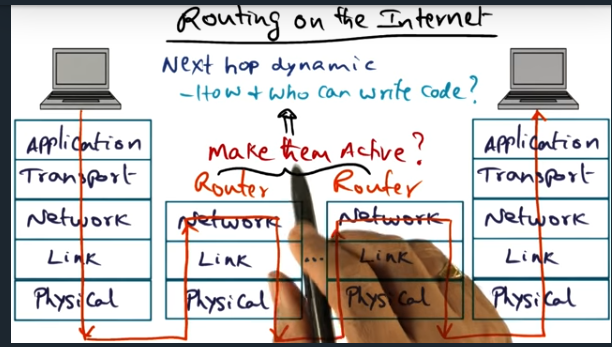
How do quickly and reliably route data
Routing on the Internet
Summary
Key Words: active network
The idea is that instead of each router performing a simple next hop look up, let’s make the routers smart and inject code in the packet that can influence the flow. How can we do this securely and safely? And without adversely impacting other flows
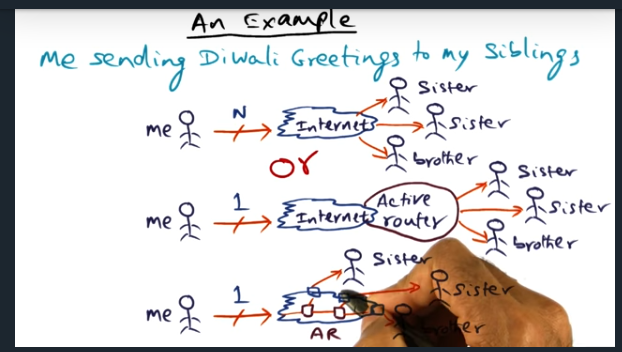
An Example
Summary
Key Words: Demultiplex
Nice example from the professor. Basically, packet looks like mutlicast stream. But instead, the sender sends a single message and an edge router will demultiplex the message, sending out that single message to multiple destinations
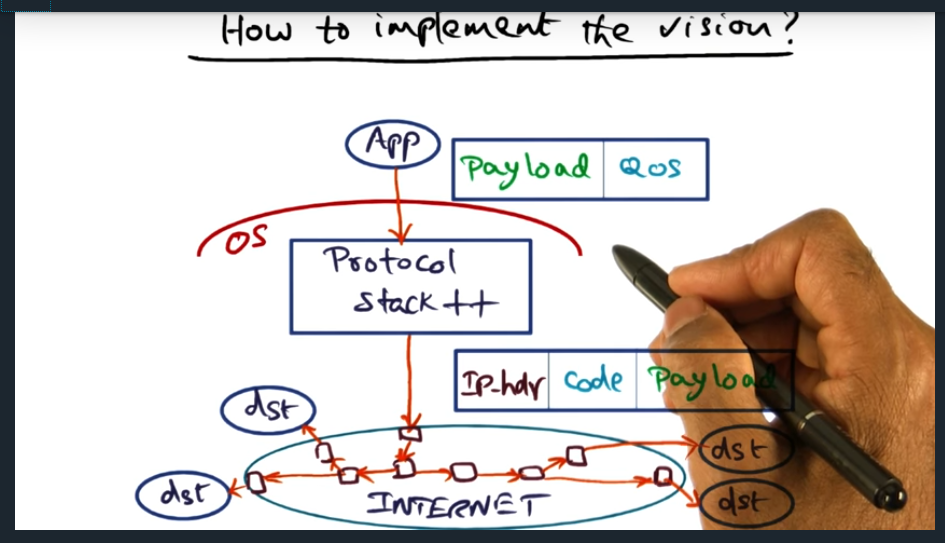
How to implement the vision
Summary
Essentially, application interfaces with the protocol stack, application sending its quality of service (QoS) requirements. Then, once this packet reaches protocol stack, the protocol stack will slap on an IPHeader with some code embedded inside the packet, the code later read in by routers up stream. But … how do we deal with the fact that not all routers participate? Routers are not open
ANTS
Summary
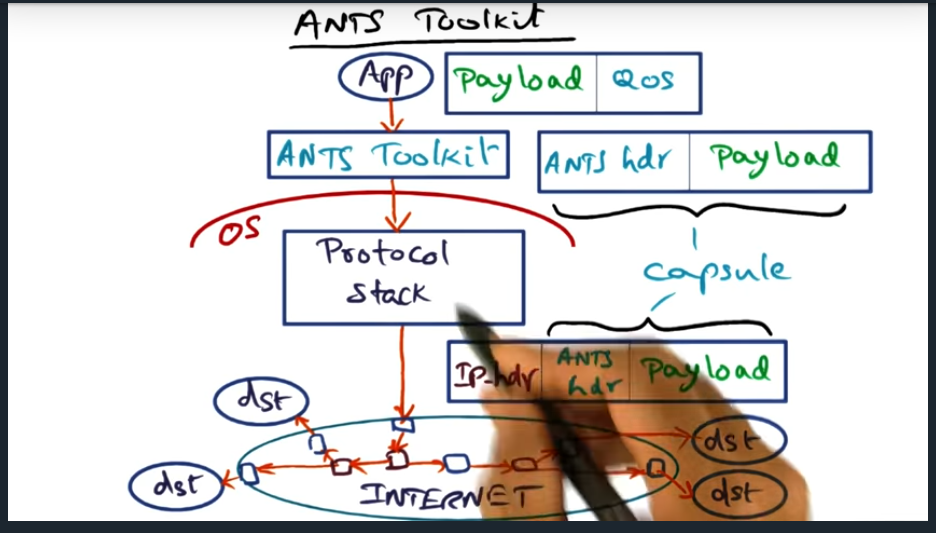
Key Words: Active Node Transfer System (ANTS), edge network
To carry out the vision, there’s active node transfer system, where the specialize nodes sit at the edge of the network. But my question still remains, if you need to send it out to multiple recipients, in different edge networks, feels like the source edge node will need to send more than one message
ANTS Capsule and API

Summary
Very minimal set of APIs. Most important to note is that the ANTS header does not contain executable code. Instead, the type field contains a reference and the router will then look up the code locally
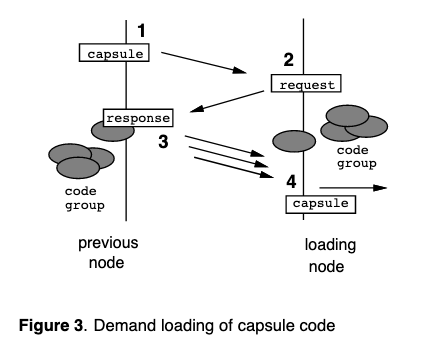
Capsule Implementation
Summary
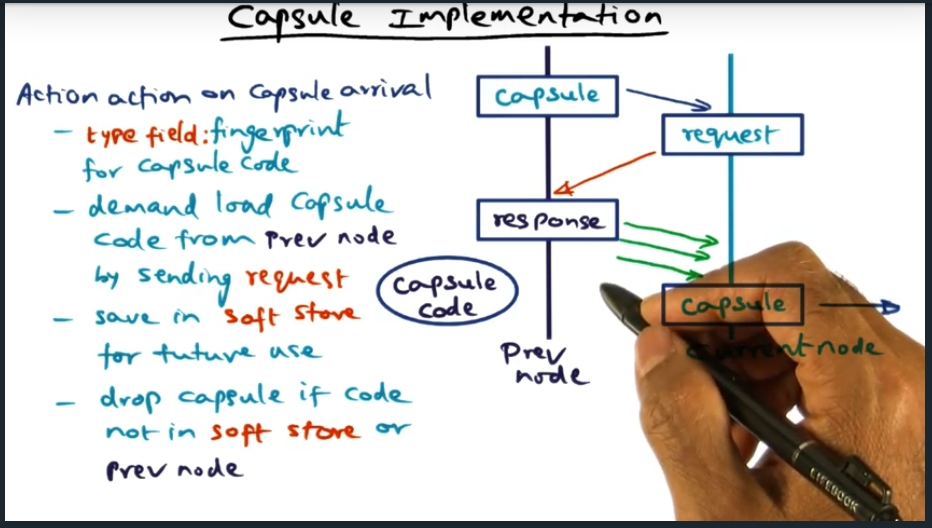
Capsule contains a fingerprint for capsule code, used to cryptographically verify capsule. If router does not have code locally stored in the soft store, will need to ask the prev node for the code (and again verifying capsule). Finally, soft store is essentially a cache.
Potential Applications

Summary
Active networks used for network functionality, not higher level applications. Basically, we’re adding an overlay network (again not sure how this all relates to advanced operating systems or distributed systems but interesting nonetheless)
Pros and Cons of Active Networks

Summary
Pros and Cons of Active Networks. On one hand, we have flexibility from the application perspective. But there are cons: protection threads (can be defended by: runtime safety using java sand boxing, prevent code spoofing using robust fingerprint, and restrict APIs for soft state integrity). From a resource management perspective, we’ll limit the restricted API to ensure code does not eat up lots of resources and finally, flooding the network is not really a problem since the internet is already susceptible to this.
Quiz
Summary
Some challenges include 1) need buy in from router vendors 2) ANTS software cannot match speed requirements
Feasible

Summary
Again, because router makers loath to open up network and software cannot match hardware routing, active networks can only sit at the edge of the network. Moreover, people are worried (as they should be) having arbitrary code running on public routing fabric
Conclusion
Summary
Active Networks way ahead of its time. Today, we are essentially using similar principles for software defined network