
Students in the Georgia Tech program collaborate with one another — and collaborate with professors and teacher assistants — through a platform called Piazza. But at the end of the semester, this forum shuts off to read only mode, meaning we all lose connection with one another.
Because of this, I recently created an e-mail list called computing-systems@omscs-social.com for other Georgia Tech Students who are interested in staying in touch. The motivation behind the mailing list is to share job opportunities, connect with other working professionals, and perhaps most important: provide peer support for one another. This felt like a natural next step since the study sessions (called “war rooms”) that I hosted were pretty successful.
But after posting a link on Piazza and sharing the idea, only 1 out of 70 people signed up. Total failure, right?
Sort of.
The lack of people signing up for the mailing list reaffirms two of my believes. First, the entire notion of “build it and they will come” is not true. Especially as software developers, we know that we can build the most shiny, most magical, most performant piece of software … and nobody can care.
The second belief is that failures are a good thing. According to the late Randy Pausch, these setbacks are what we likes to call brick walls:
The brick walls are there for a reason. The brick walls are not there to keep us out. The brick walls are there to give us a chance to show how badly we want something. Because the brick walls are there to stop the people who don’t want it badly enough. They’re there to stop the other people.
– Randy Pausch
In order to grow, you need to fail — a lot — because there’s no linear path to success.
You can see this pattern of trial and error with Josh Pigard’s most recent venture that he recently sold for $4 million: big success, right? Yes, definitely.
But notice all his other failed projects listed on his personal website.
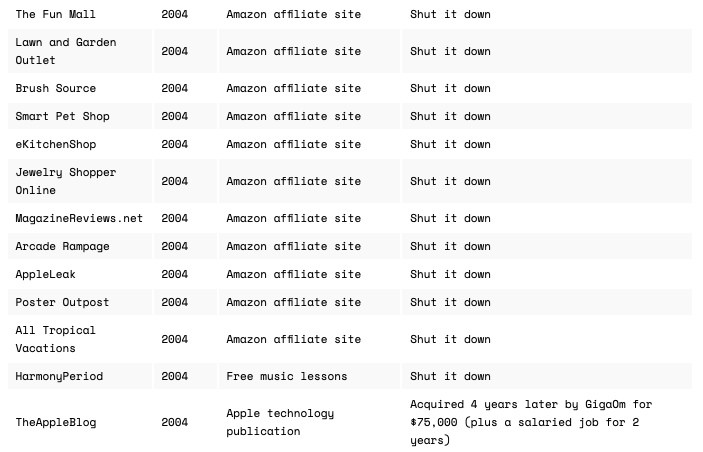
On some level, the above are considered failures since the projects ultimately shut down. But that’s not how I see it. I’d like to think that Josh learned a lot of things from those failures, which fed and led him to building and selling his company.
From this example alone, I think I can take away a lot of lessons learned. In particular, like my wife, I am a perfectionist. I want — sometimes need — things to be perfect. But that’s surface level, only what maybe the outside can see. There’s a shadow side.
Really, like many others, I have imposter syndrome. I’m constantly worried that I’m going to get exposed as some sham. My response to imposter syndrome? Striving to be right all the time. And I believe that taken too far, trying to be right all the time can stunt growth because to grow — personally and professionally — I need to constantly be experimenting, tinkering, trying out things that might just fail.
To wrap things up: will I shut down and abandon the mailing list? Maybe. Maybe not.