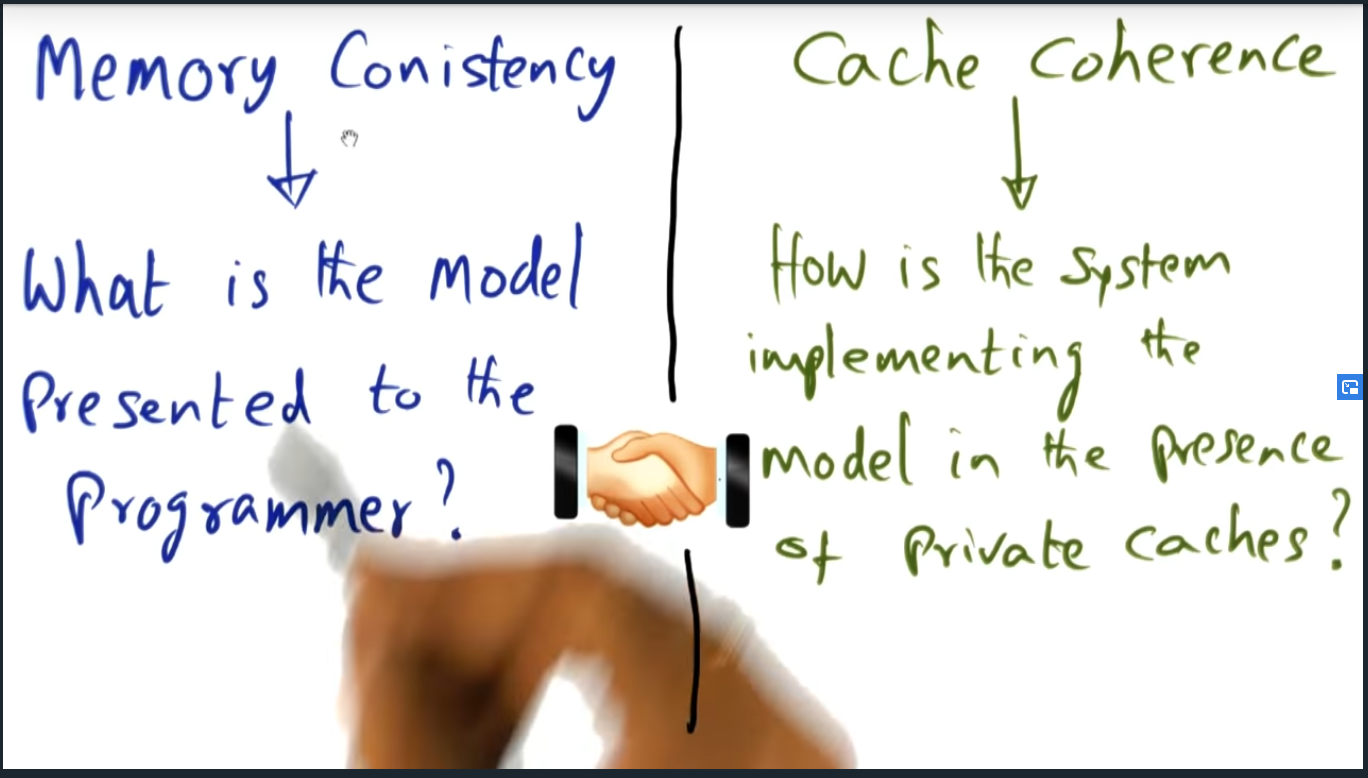
You need to take away the following two themes for shared memory machine model:
- Difference and relationship between cache coherence (dealt with in hardware) and cache consistency (handled by the operating system)
- The different memory machine models (e.g. dance hall, symmetric multiprocessing, and distributed shared memory architecture)
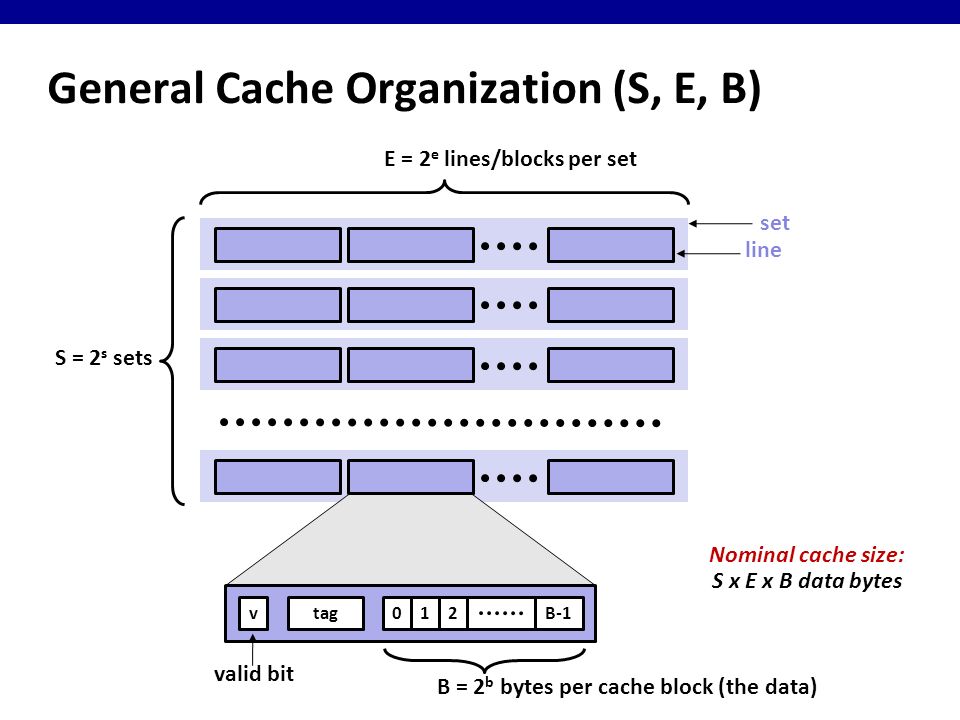
Cache coherence is the promise delivered by the underlying hardware architecture. The hardware guarantees employs one of two techniques: write invalidate or write update. In the latter, when a memory address gets updated by one of the cores, the system will send a message on the bus to invalidate the cache entry stored in all the other private caches. In the former, the system will instead update all the private caches with the correct data. Regardless, the mechanism in which cache is maintained is an implementation detail that’s not privy to the operating system.
Although the OS has not insight into how the hardware delivers cache coherence, the OS does rely on the cache coherence to build cache consistency, the hardware and software working in harmony.
Shared Memory Machine Model
Summary
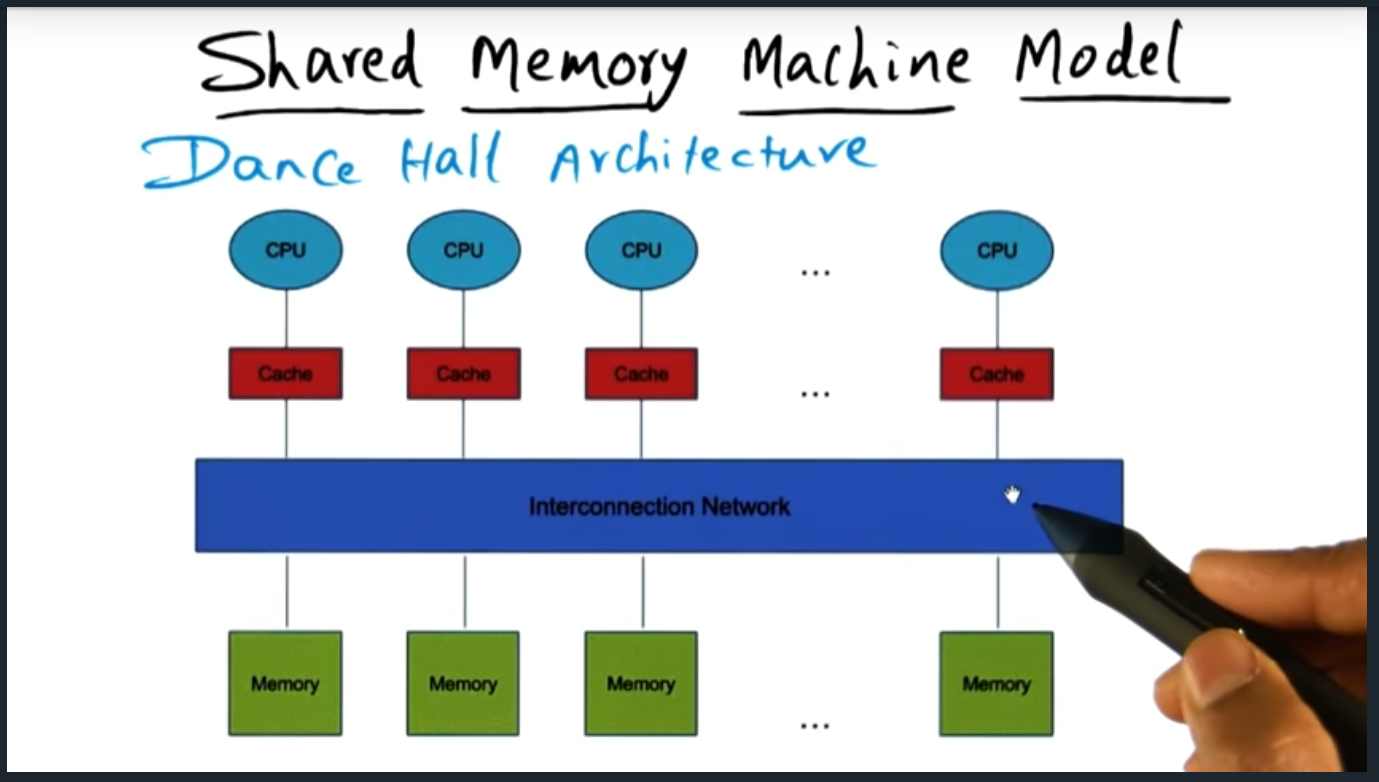
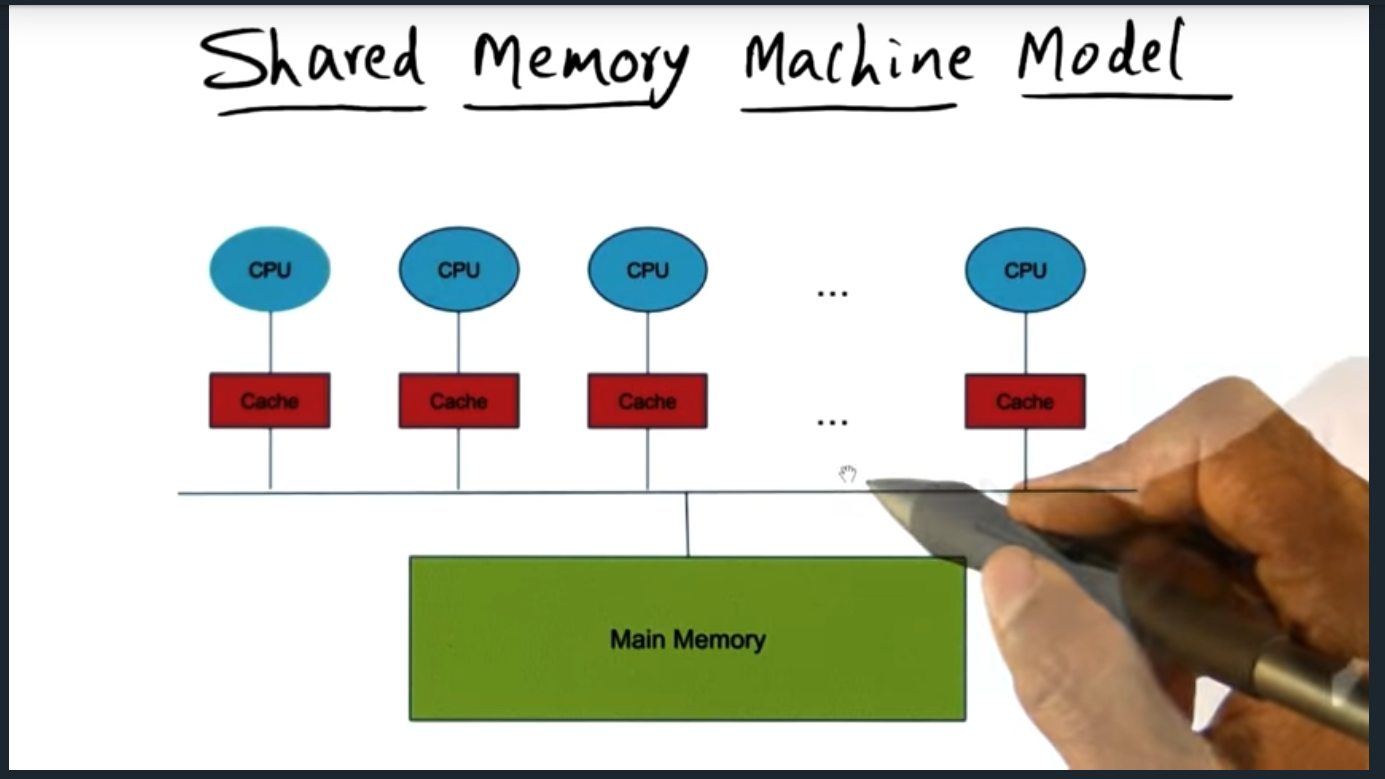
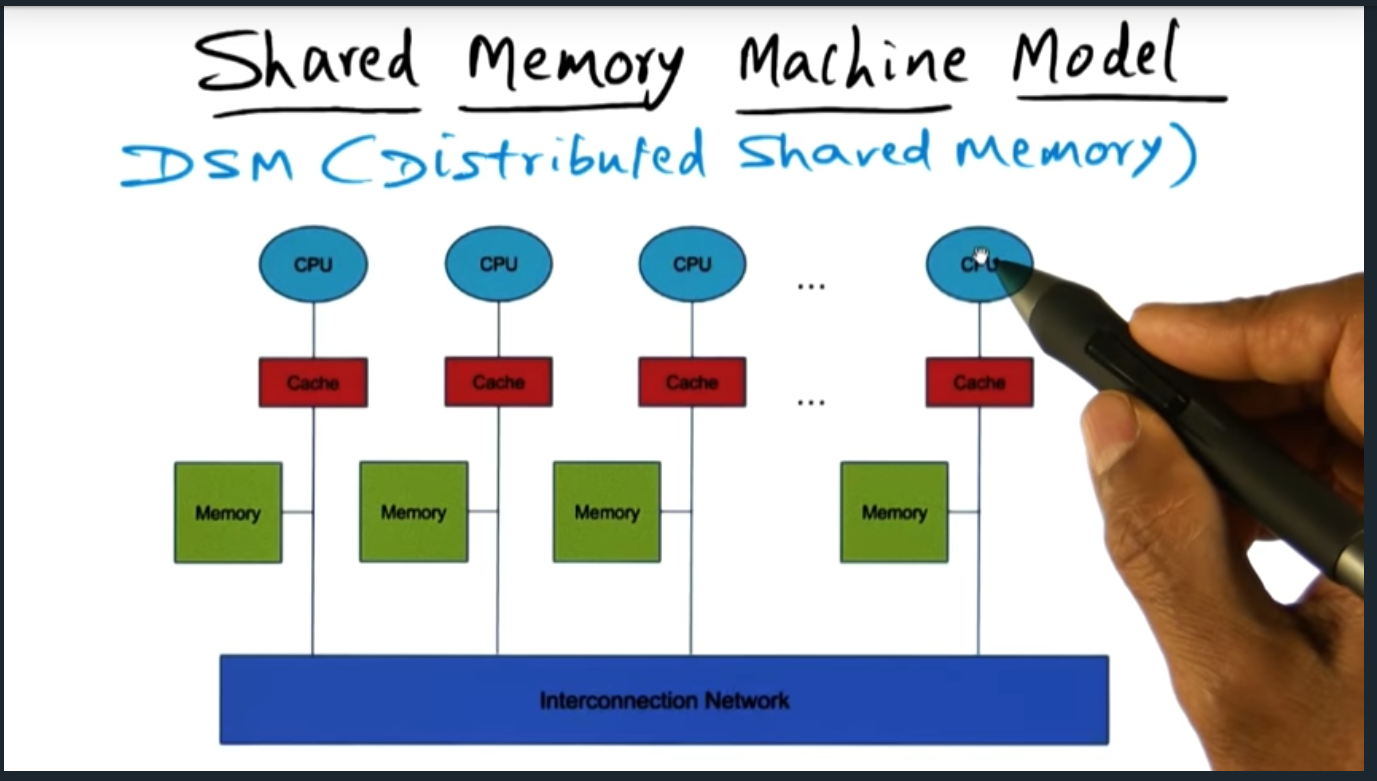
There are three memory architecture: dance hall (each CPU has its own memory), SMP (from perspective of each CPU, access to memory is the same as other CPU), and Distributed shared memory architecture (some cache and some memory is faster to access for a given CPU). Lecture doesn’t go much deeper than this but I’m super curious as to the distributed architecture.
Shared Memory and Caches
Summary
Because each CPU has its own private cache, we may run into a problem known as cache coherence. This situation can occur if the caches tied to each CPU contain different values for the same memory address. To resolve this, we need a memory consistency model.
Quiz: Processes
Summary
Quiz tests us by offering two processes, each using shared memory, each updating different variables. Then the quiz asks us what are the possible values for the variables. Apart from the last one, all are possible, the last one would break the intuition of a memory consistency model (discussed next)
Memory consistency model
Summary
Introduces the sequential consistency memory model, a model that exhibits two characteristics: program order and arbitrary interleaving. This Isi analogous to someone shuffling a deck of cards.
Sequential Consistency and cache coherence (Quiz)
Summary

Which of the following are possible values for the following instructions
Hardware Cache Coherence
Summary
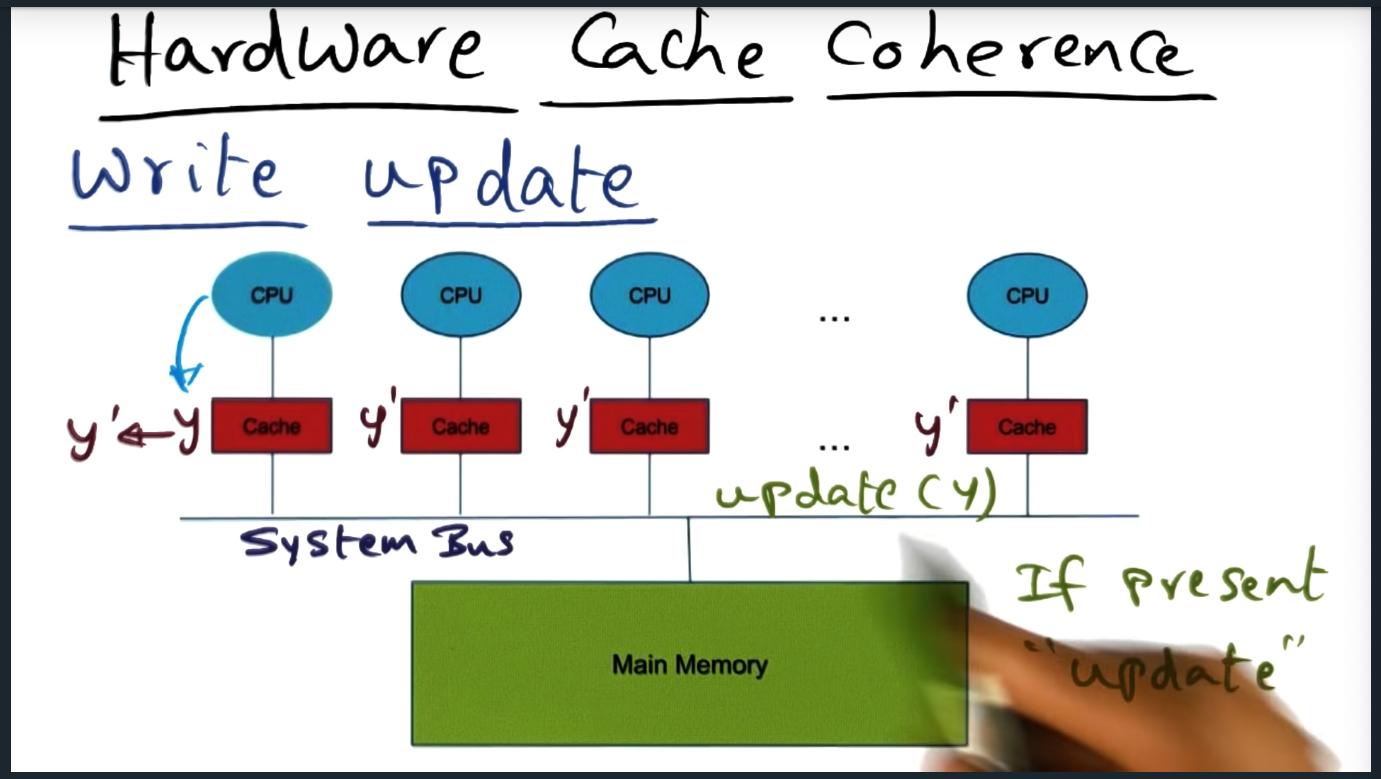
There are two strategies for maintaining cache coherence. Write invalidate and write update. In the former, the system bus will broadcast an invalidate message if one of the other cache’s modifies an address in its private cache. In the latter, the system must will send an update message to each of the cache’s, each cache updating it’s private cache with the correct data. Obviously, the lecture oversimplifies the intricacies of maintaining a coherent cache (and if you want to learn more, check out the high performance computing architecture lectures — or maybe future modules in this course will cover this in more detail)
Scalability
Summary
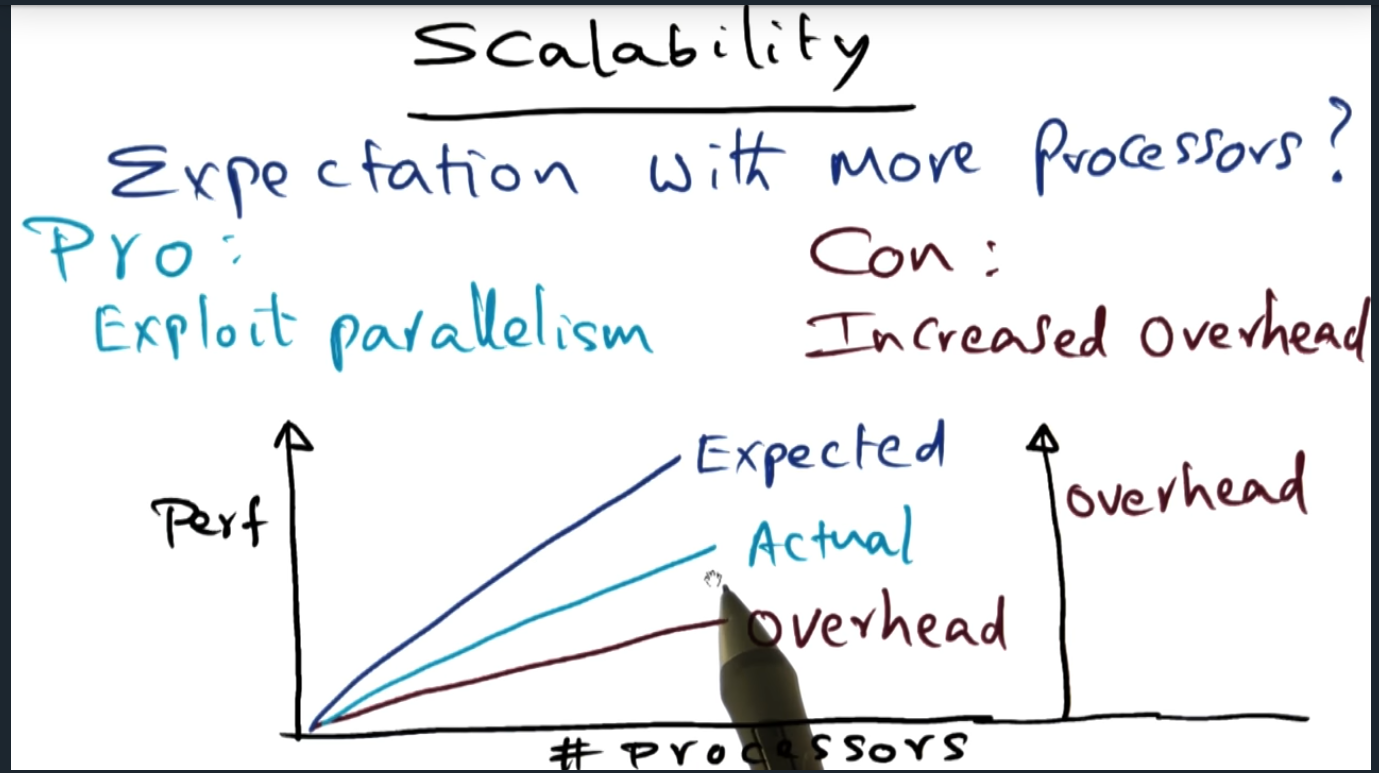
Adding processors increase parallelism and improves performance. However, performance will decrease due to additional overhead of maintaining the bus (another example of making trade offs and how nothing is free).