The operating system maintains a per process data structure called a page table, creating a protection domain and hardware address space: another virtualization technique. This page table maps the virtual address space to physical frame number (PFN).
The same virtualization technique is adopted by hypervisors (e.g. VMWare). They too have the responsibility of mapping the guest operating system’s “physical address” space (from the perspective of the guest VM) to the underlying “machine page numbers”. These physical address to machine page number mappings are maintained by the guest operating system in a para virtualized system, and maintained by the hypervisor in a fully virtualized environment.
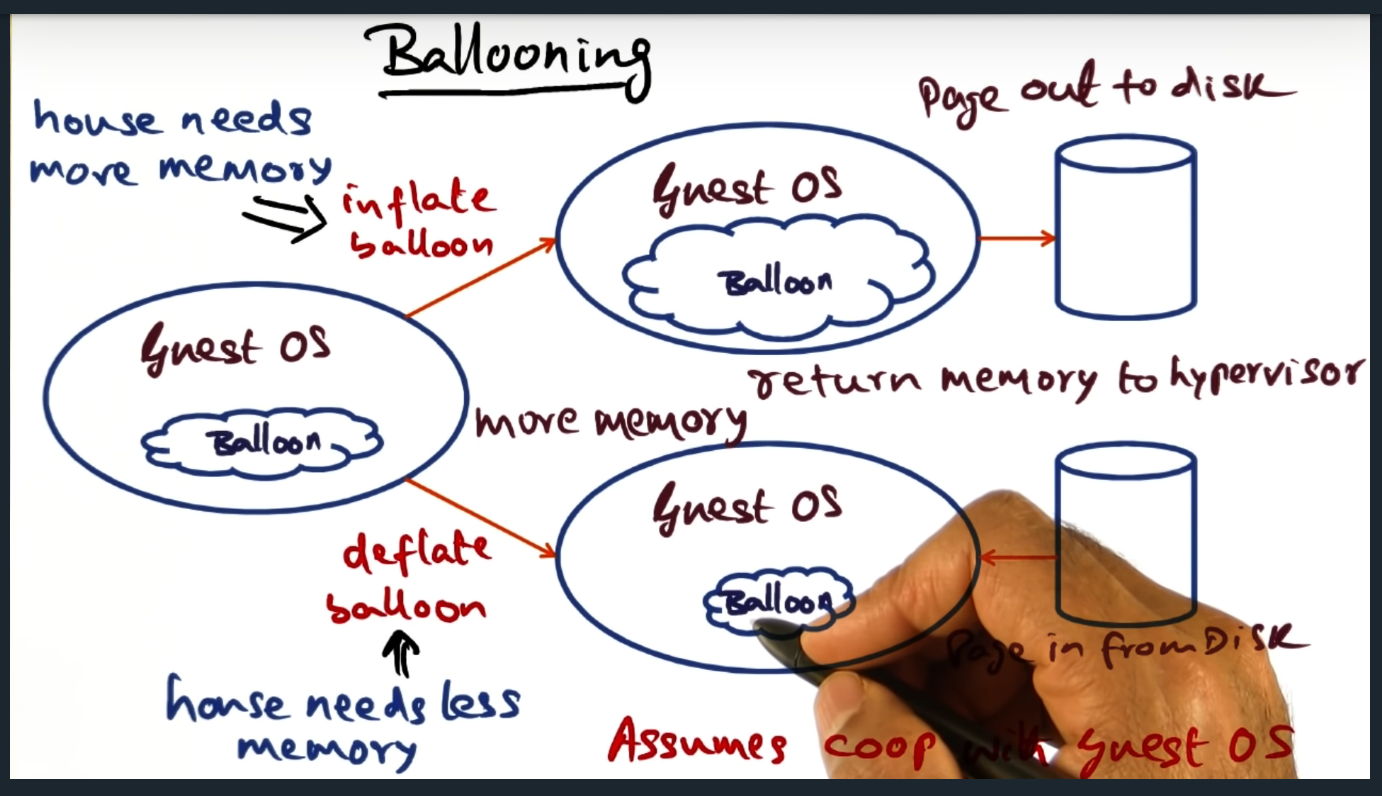
In both fully virtualized and para virtualized environments, memory mapping is done efficienctly. In the former, the guest VM will send traps and in response, the hypervisor will perform its mapping translation. But in a para virtualized environment, the hypervisor leans on the guest virtual machine much more, via a balloon driver. In a nutshell, the balloon driver pushes the responsibility of handling memory pressure from the hypervisor to the guest machine. The balloon driver, installed on the guest operating system, inflates when hypervisor wants the guest OS free memory. The beauty of this approach is that If the guest OS is not memory constrained, no swapping occurs: the guest VM just removes an entry in its free-list. When the hypervisor wants to increase the memory for a VM, it signals (through the same private communication channel) the balloon driver to deflate, signaling the guest OS to page in and increase the size of its memory footprint.
Finally, the hypervisor employs another memory technique known as oblivious page sharing. With this technique, the hypervisor runs a hashing algorithm in a background process, creating a hash of each of memory contents of each page. If two or more virtual machines contain the same page, then the hypervisor just creates a “copy-on-write” page, reducing the memory footprint.
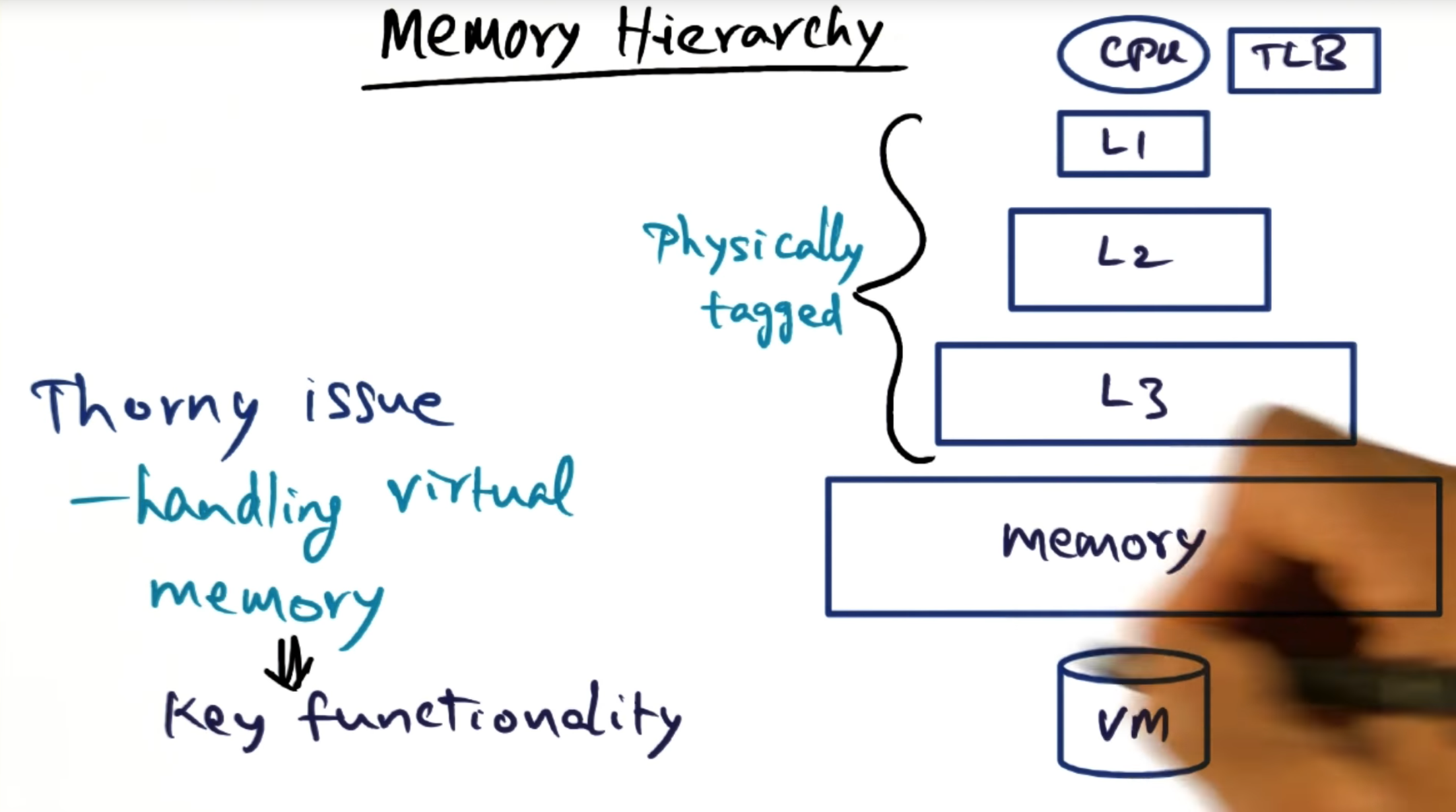
Memory Hierarchy
Summary
The main thorny issue of virtual memory is translating virtual address to physical mapping; caches are physically tagged so not a major source of issues there.
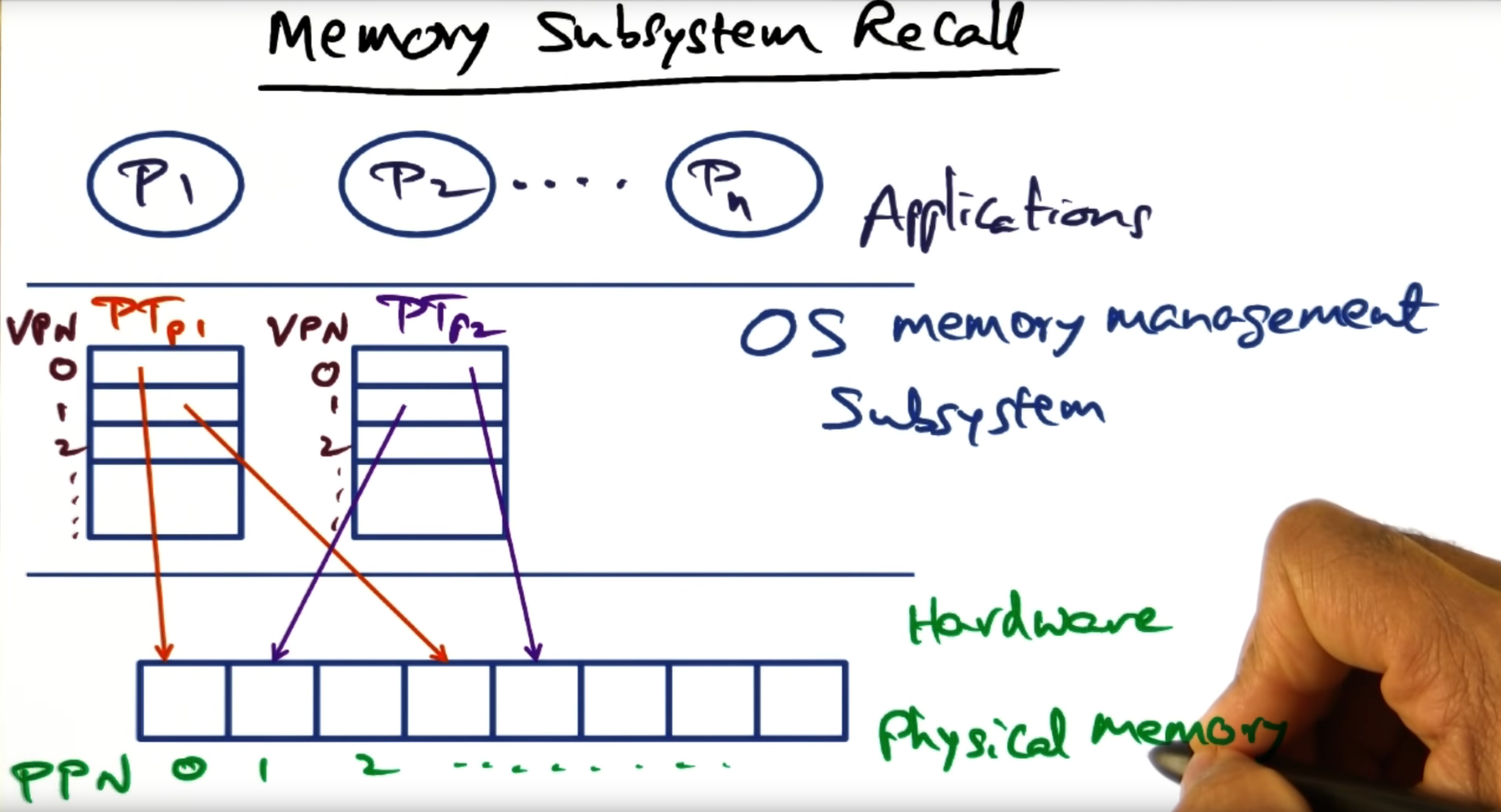
Memory Subsystem Recall
Summary
A process has its own protection domain and hardware address space. This separation is made possible thanks to virtualization. To support memory virtualization, we maintain a per process data structure called a page table, the page table mapping virtual addresses to physical frame numbers (remember: page table entries contain the PFN)
Memory Management and Hypervisor
Summary
The hypervisor has no insight into the page tables for the processes running on the instances (see Figure). That is, Windows and Linux serve as the boundary, the protection domain.
Memory Manager Zoomed Out
Summary
Although the virtual machines operating systems think that they allocate contiguous memory, they are not: the hypervisor must partition the physical address space among multiple instances and not all of the operating system instances can start at the same physical memory address (i.e. 0x00).
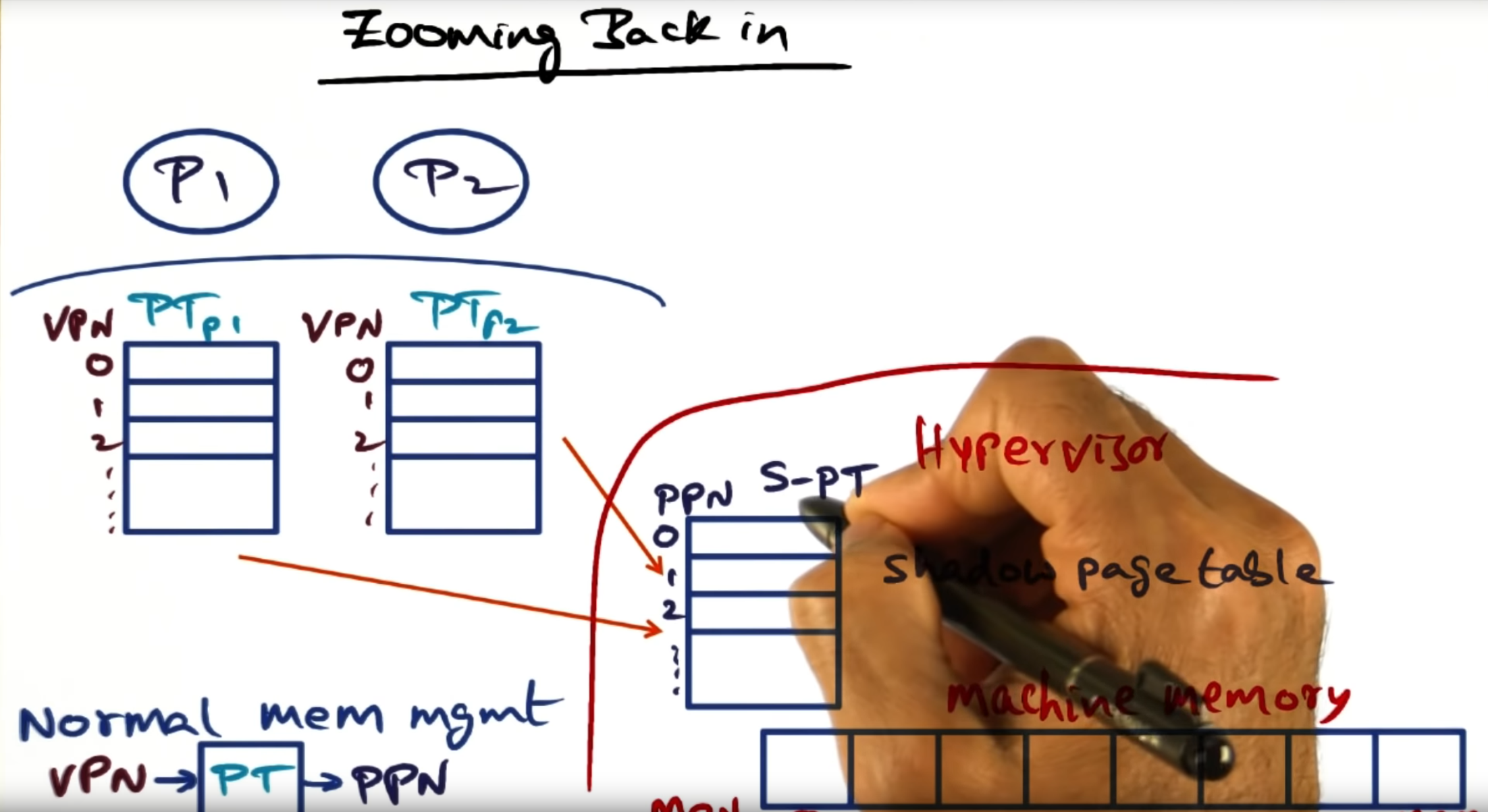
Zooming Back in
Summary
Hypervisor maintains a shadow page table that maps the physical page numbers (PPN) to the underlying hardware machine page numbers (MPN)
Who keeps the PPN MPN Mapping
Summary
For fully virtualization, the PPN->MPN lives in the hypervisor. But in a para virtualization, it might make sense to live in the guest operating system.
Shadow page table
Summary
Similar to a normal operating system, the hypervisor contains the address of the page table (stored in some register) that lives in memory. Not much different than a normal OS, I would say
Efficient Mapping (Full Virtualization)
Summary
In a fully virtualized guest operating system, the hypervisor will trap calls and perform the translation from virtual private number (VPN) to the machine private number (MPN), bypassing the guest OS entirely
Efficient Mapping (Para virtualization)
Summary
Dynamically Increasing Memory
Summary
What can we do when there’s little to no physical/machine memory left and the guest OS needs more? Should we steal from one guest VM for another? Or can we somehow get a guest VM to voluntarily free up some of its pages?
Ballooning
Summary
Hypervisor installs a driver in the guest operating, the driver serving as a private channel that only the hypervisor can access. The hypervisor will balloon the driver, signaling to the guest OS to page out to disk. And then it can also signal to the guest OS to default, signaling to page in.
Sharing memory across virtual machines
Summary
One way to achieve memory sharing is to have the guest operating system cooperate with the hypervisor. The underlying guest virtual machine will signal, to the hypervisor, that a page residing in the guest OS will be marked as copy on write, allowing other guest virtual machines to share the same page. But when the page is written to, then hypervisor must copy that page. What are the trade offs?
VM Oblivious Page Sharing
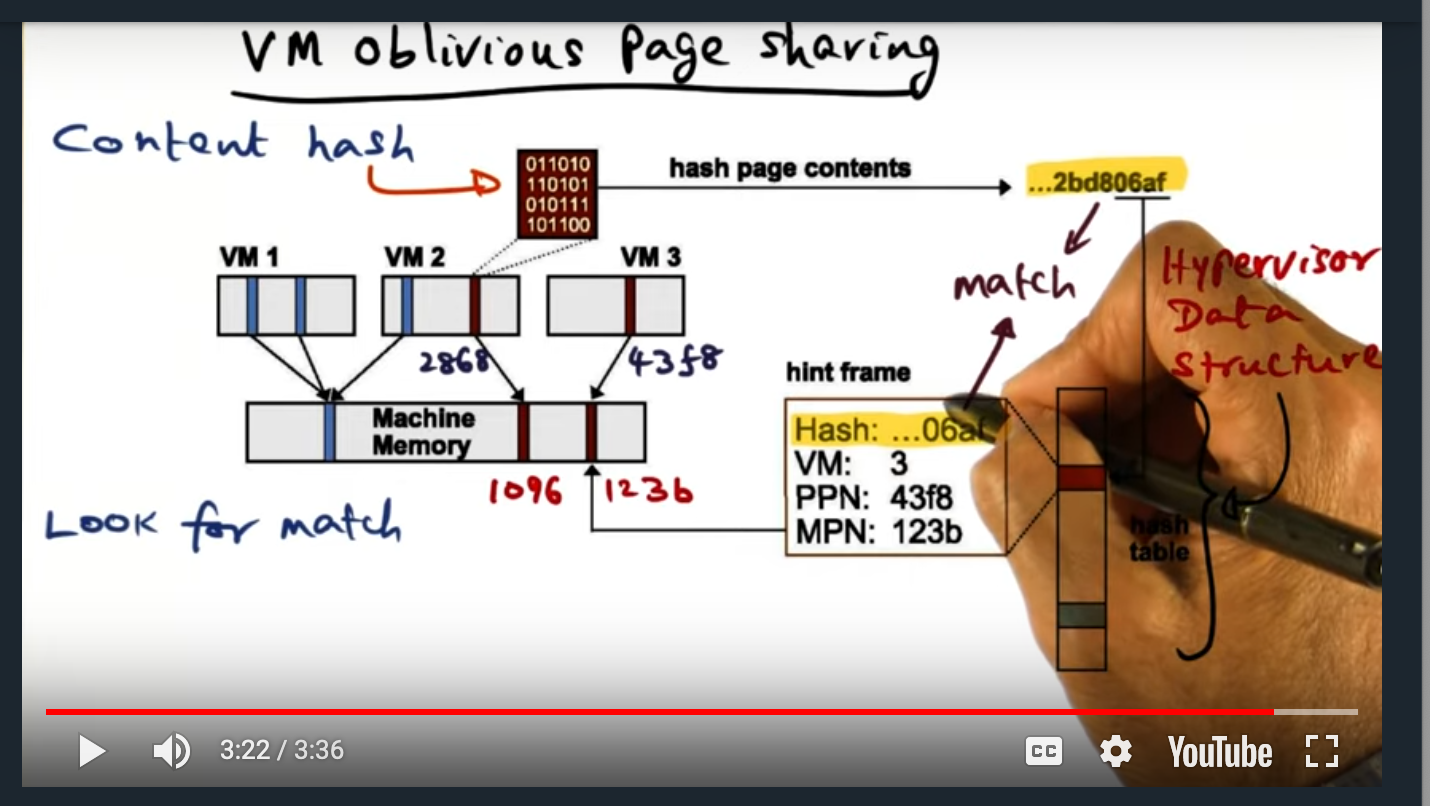
Summary
VMWare ESX maintains a data structure that maps content hash to pages, allowing the hypervisor get a “hint” of whether or not a page can be shared. If the content hash matches, then the hypervisor will perform a full content comparison (more on that in the next slide)
Successful Match
Summary
Hypervisor process runs in the background, since this is a fairly intensive operation, and will update guest VMs pages as “copy-on-write”, only running this process when the hypervisor is lightly loaded
Memory Allocation Policies
Summary
So far, discussion has focused on mechanisms, not policies. Given memory is such a precious resource, a fair policy with me dynamic-idle adjusted shares approach. A certain percentage (50% in the case of ESX) of memory will be taken away if its idle, a tax if you will.