I’m watching the YouTube learning series called “Introduction to OpenMP” in order to get a better understanding of how I can use the framework for my second project in advanced operating systems. You might find the below notes useful if you don’t want to sit through the entire video series.
Introduction to OpenMP: 02 part 1 Module 1
Summary
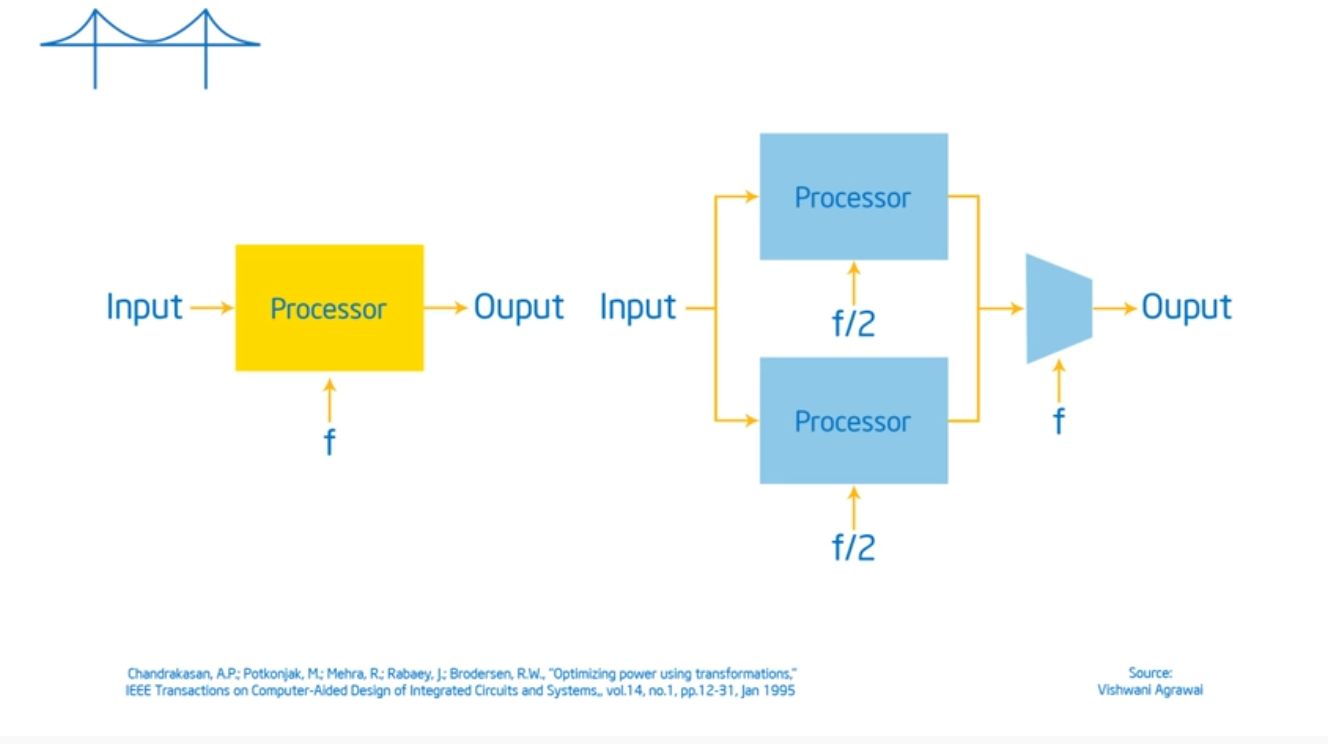
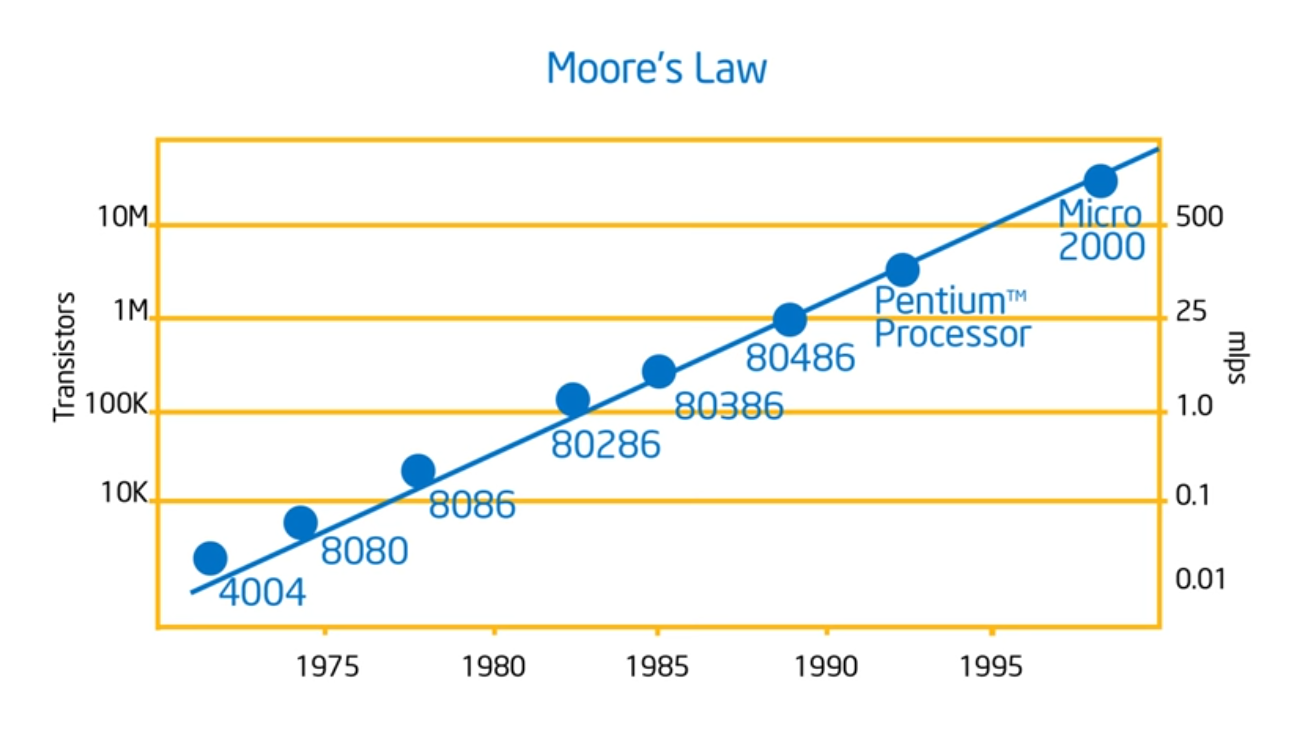
Neat that he’s going over the history, talking about Moore’s Law. The key take away now is that hardware designers are now going to optimize for power and software developers have to write parallel programs: there’s no free lunch. No magic compiler that will take sequential code and turn it into parallel code. Performance now c
Introduction to OpenMP – 02 Part 2 Module 1
Summary
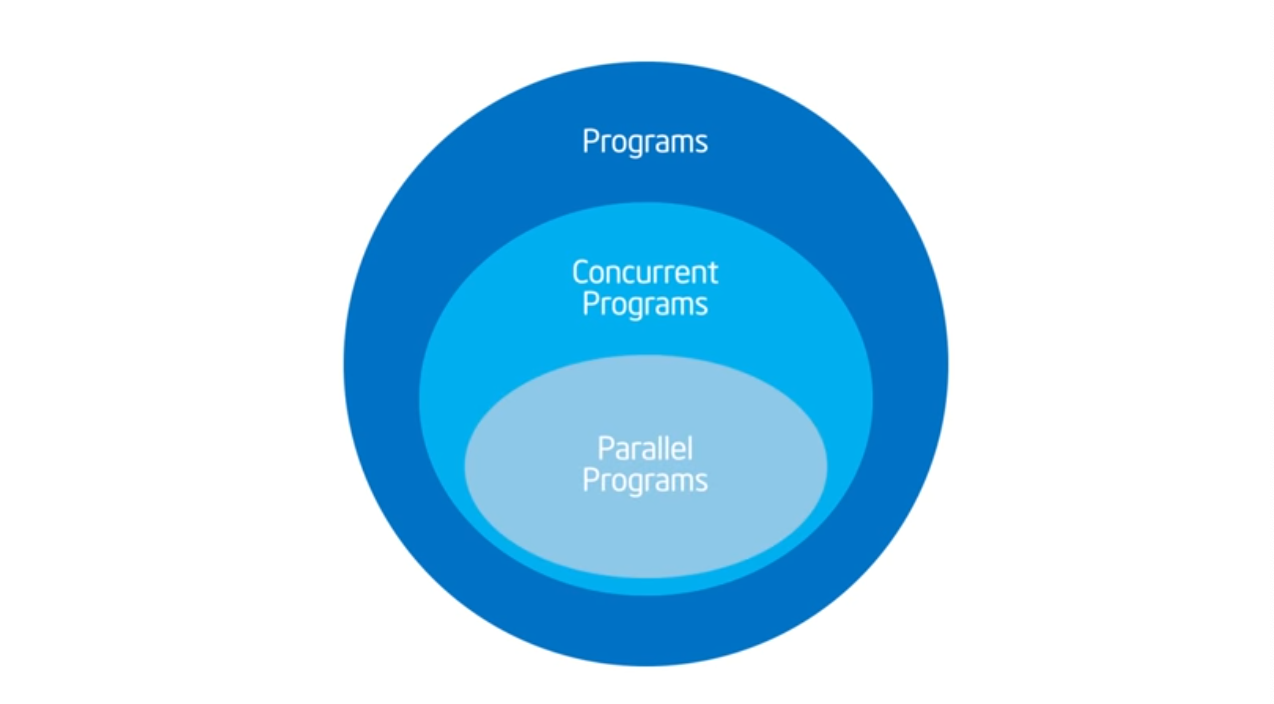
The last step should be picking up the OpenMP Library (or any other parallel programming library). What should be done firs and foremost is breaking down your problem (the act of this has not been able to automated) into concurrent parts (this requires understanding of the problem space) and then figure out which can run in parallel. Once you figure that out, then you can use compiler syntactical magic (i.e. pragmas) to direct your compiler and then sprinkle some additional pragmas that will help the compiler tell where the code should enter and where it should exit.
Introduction to OpenMP – 03 Module 02
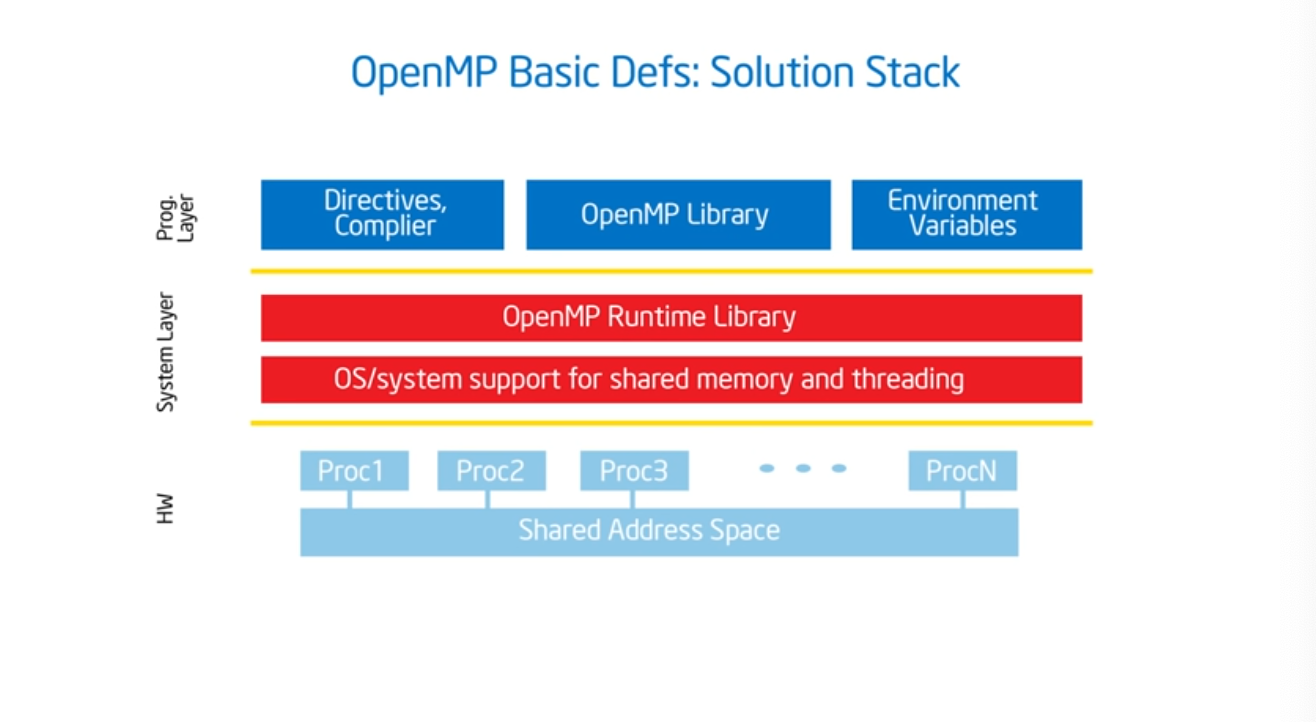
Summary
It’s highly likely that the compiler that you are using already supports OpenMP. For gcc, pass in -fopenmp. And then include the prototype, and add some syntactic sugar (i.e. #pragma amp parallel) which basically gives the program a bunch of threads.
Introduction to OpenMP: 04 Discussion 1
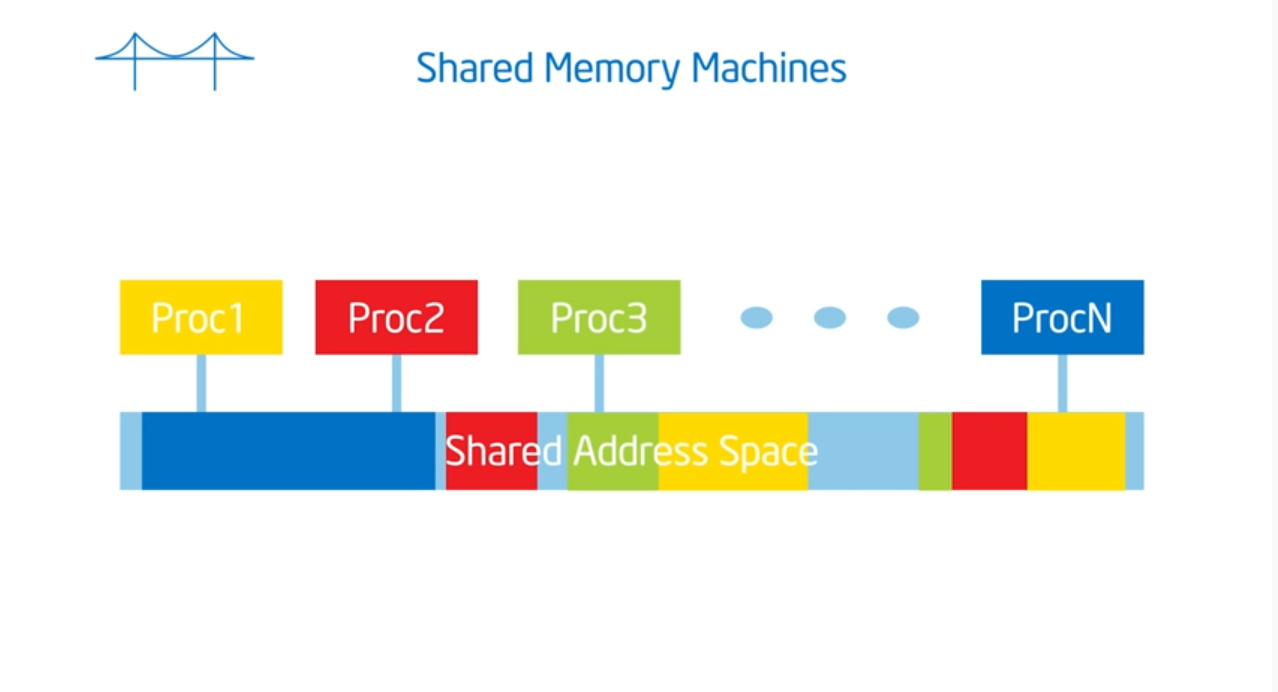
Summary
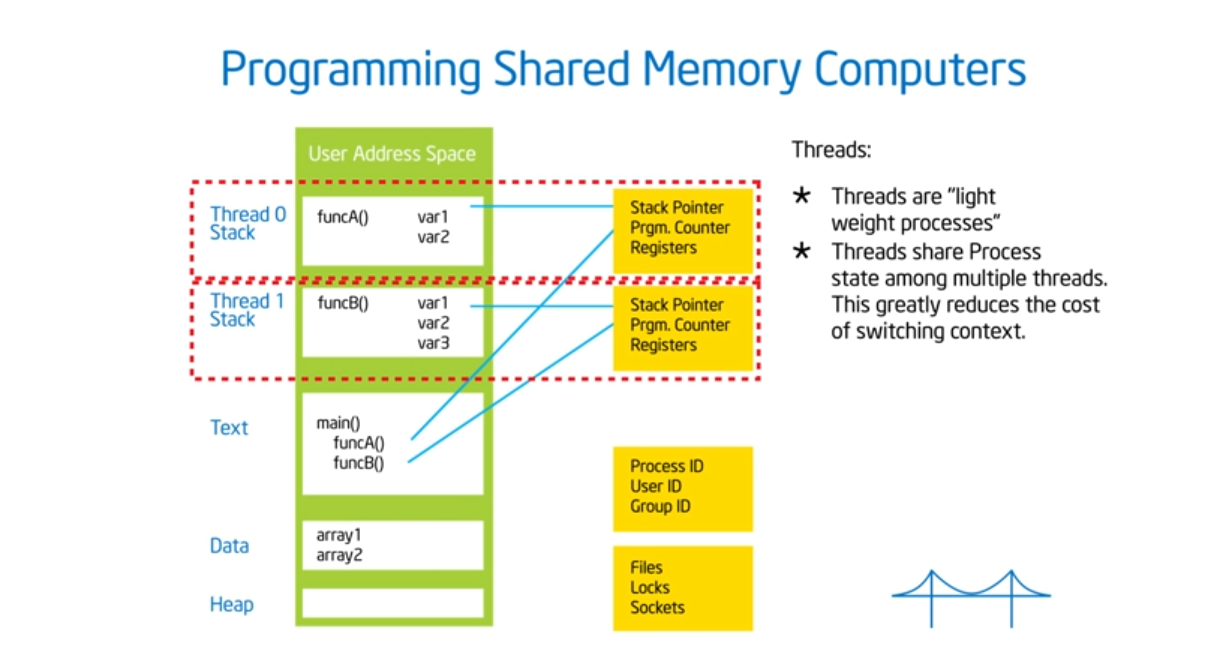
OpenMP assumes a shared memory address space architecture. The last true SMP (symmetric multi-processor) machine was in the late 1980s so most machines now run on NUMA (non uniformed multiple access) architectures. To exploit this architecture, we need to schedule our threads intelligently (which map to the same heap but contain different stacks) and place data in our cache’s as close as possible to their private caches. And, just like the professor said in advanced OS, we need to limit global data sharing and limit (as much as possible) the use of synchronization variables since they both slow down performance