I remember designing a large-scale distributed system as an AWS software engineer. Amazon’s philosophy that “you build it, you own it” means that engineers must, at all times, understand how their underlying systems work. You’re expected to describe the behavior of your system and answer questions based on just a glance at your dashboards.
Is the system up or down? Are customers experiencing any issues? How many requests have been received at the P50, P90, or P99 levels?
With millions of customers using the system every second, it’s critical to quickly pinpoint problems, ideally without resorting to other means of troubleshooting (like diving through log files). Being able to detect issues rapidly requires effective use of AWS CloudWatch.
If you are new to instrumenting code and just beginning to publish custom metrics to CloudWatch, there are some subtle gotchas to beware of, one of which is only publishing metrics when the system is performing work. In other words, during periods of rest, the system can fail to provide metrics with zero value, which may make it difficult to distinguish between the following two scenarios:
- The system is online/available, but there’s no user activity
- The system is offline/unavailable
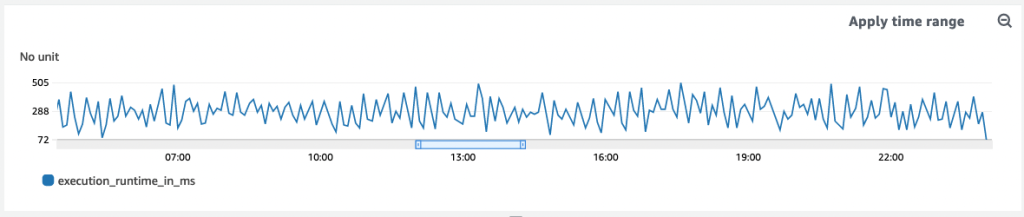
To differentiate the two, your software must constantly publish metrics even when the system sits idle. Otherwise, you end up with a graph that looks like this:

What jumps out to you?
Yup, the gaps. They stand out because they represent missing data points. Do they mean we recently deployed an update with a bug that’s causing intermittent crashes? Is our system being affected by flaky hardware? Is the underlying network periodically dropping packets?
It could be anything.
Or, as in this case, nothing at all: just no activity.
No answer is not a real answer
[We] shouldn’t take absence of evidence as confirmation in either direction
Maya Shankar on Slight Change of Plans: Who is Scott Menke
Yesterday, my wife and I took our daughter to the local farmer’s market. While I was getting the stroller out of the car, my wife and daughter sat down to enjoy some donuts. An older gentleman came up and asked my wife whether she would be his partner for some square dancing; he was wearing a leather waistcoat and seemed friendly enough, so she said yes. During the dance, one of the instructors called out a complex set of directions and then asked if everyone understood and was ready to give it a go. All the newbie dancers just looked around nervously, to which he replied:
“Wonderful. I’ll take your silence as consent.”
For the record, silence never equates to consent. However, this does serve as a good analogy for the issue being discussed here about monitoring software systems. Getting no response from his students didn’t really tell the dance instructor that they were all set, and getting no metrics from our system doesn’t really tell us that our system is all set. No answer is not a real answer.
When it comes to monitoring and operating large software systems, we steer away from making any assumptions. We want data. “Lots,” as my three-year-old daughter would say.
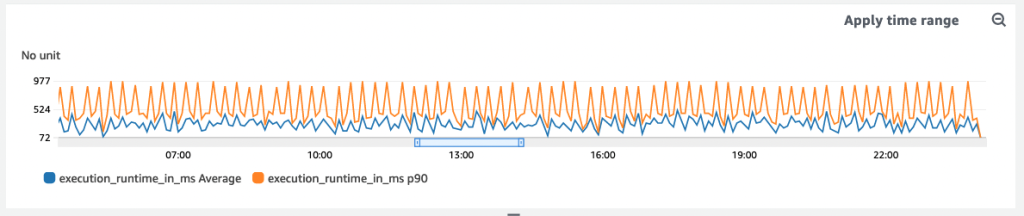
Back to our graph above: The gaps between data points represent idle times when the underlying system was not performing any meaningful work. Instead of not publishing a metric during those periods, we’ll now emit a counter with a value set to zero, which makes the new graph look like this:

With the previous gaps now filled with data points, we now know that the system is up and running — it’s alive, just not handling any requests. The system wasn’t misbehaving, just idle. And now, if we see a graph that still has gaps, we know there’s a problem to investigate.
Lesson learned
We’ve now seen that any gaps in data can lead to unnecessary confusion. Even when the system is not performing any meaningful work , or not not processing any requests, we want to publish metrics, even if their values are zero. This way we can always know what’s really going on.