I’m now half way through Distributed Computing course at Georgia Tech and us students are now tackling the penultimate project: building a replicated state machine using PAXOS. This project will be challenging (probably going to require 40+ hours) and it’ll put my theoretical knowledge to the test and reflect back, in a couple weeks, how much I learned.
Presently, here’s my little understanding of the consensus algorithm:
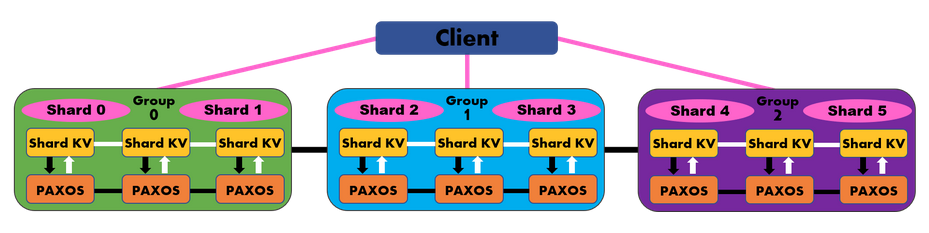
Current PAXOS understanding
- Servers play different roles – Proposer, Acceptor, Learner
- Proposers send proposals that monotonically increase
- Proposals are accepted if and only if a majority of the quorum accept them
- The 2PC (2 phased commit) protocol essentially tells us whether or not a particular transaction is committed or aborted
- Guaranteeing linearzability means that, from the clients perspective, real time (i.e. wall clock) should be respected and the client should view the system as if there is a single replica
Future PAXOS understanding
- How exactly PAXOS guarantees consensus via its 2 phased commit protocol
- How does a server determine its role (or does it play multiple roles)
- How to handle the edge cases (say two proposals arrive at the same time)
- What role does a client play? Does it serve as a proposer?
- How does leader election work in PAXOS?
- Should I just try and mimic the Python based code described in Paxos made moderately difficult
- How will replication work as the number of nodes in the system scales (say from 3 to 5 to 10)
- How to detect (and perhaps avoid) split brain (i.e. multiple leaders)
References
- Majority quorum can be defined as floor(n/2) + 1
- Python implementation described https://www.cs.cornell.edu/courses/cs7412/2011sp/paxos.pdf