Summary
Distributed systems are everywhere: social media, internet of things, single server systems — all part of larger, distributed systems. But how do you define a distributed system? A distributed system is, according to Leslie Lamport (father of distributed computing), a system in which failure of some component (or node) impacts the larger system, rendering the whole system either unstable or unusable.
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable – Leslie Lamport

To better understand distributed systems, we can model their behaviors using nodes and messages. Nodes send messages to one another, over unreliable communication links in a 1:1 or 1:N fashion. Because of the assumed flaky communication, messages may never arrive due to node failure. This simple model of nodes and messages, however, does not take the nodes capturing events into consideration; for this, our model must be extended into a slightly more complex one, introducing the concept of “state” being stored at each node.
When evaluating distributed system, we can and should leverage models. Without them, we’d have to rely on building prototypes and running experiments to prove our system; this approach is untenable due to issues such as lack of resources or due to the scale of the system, which may require hundreds of thousands of nodes. When selecting a model, we want ensure that it can accurately represent the problem and be used to analyze the solution. In other words, the model should hold two qualities: accurate and tractable.

Building distributed systems can be difficult for three reasons: asynchrony, failures, consistency. Will a system assume messages are sent immediately within a fixed amount of time? Or will it be asynchronous, potentially losing messages? How will the system handle the different types of failures: total, grey, byzantine (cannot tell, misbehaving) ? How will the system remain consistent if we introduce caching or replication? All of these things are part of the larger 8 fallacies of distributed computing systems.
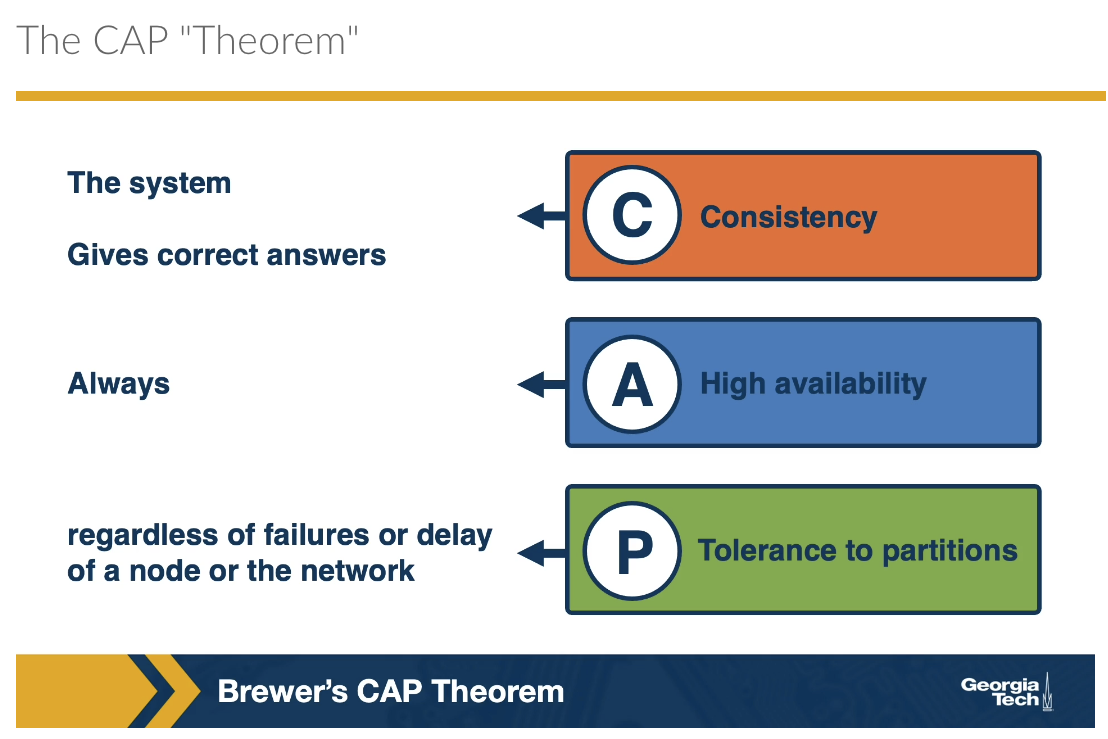
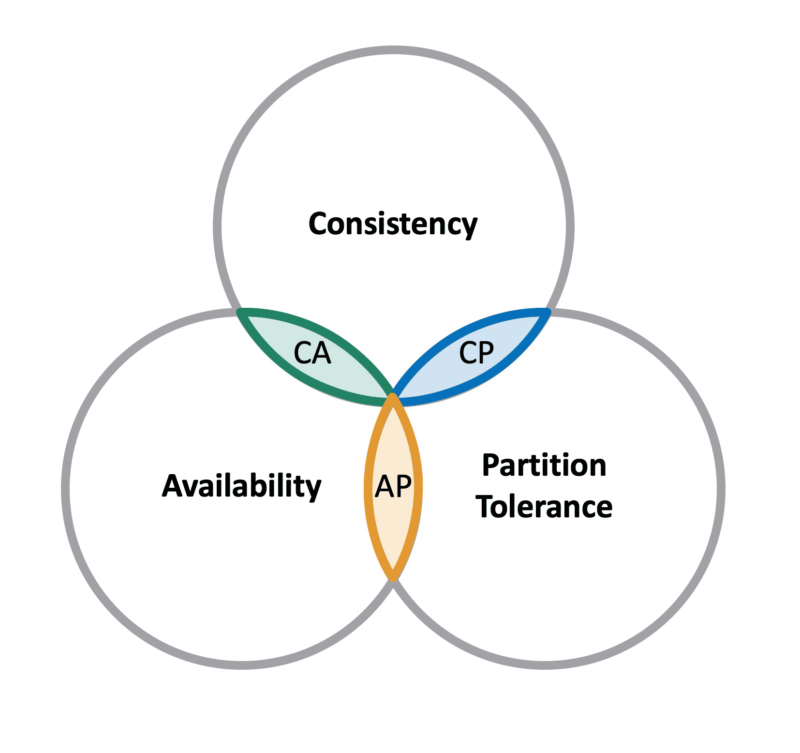
Ultimately, when it comes to building reliable and robust systems, we cannot have our cake and eat it too. Choose 2 out of the 3 properties: consistency, availability, partitioning. This tradeoff is known as CAP theorem (which has not been proven and is only a theorey). If you want availability and partitioning (e.g. cassandra, dynamodb), then you sacrifice consistency; similarly, if you want consistency and partitioning (e.g. MySQL, Megastore), you sacrifice availability.