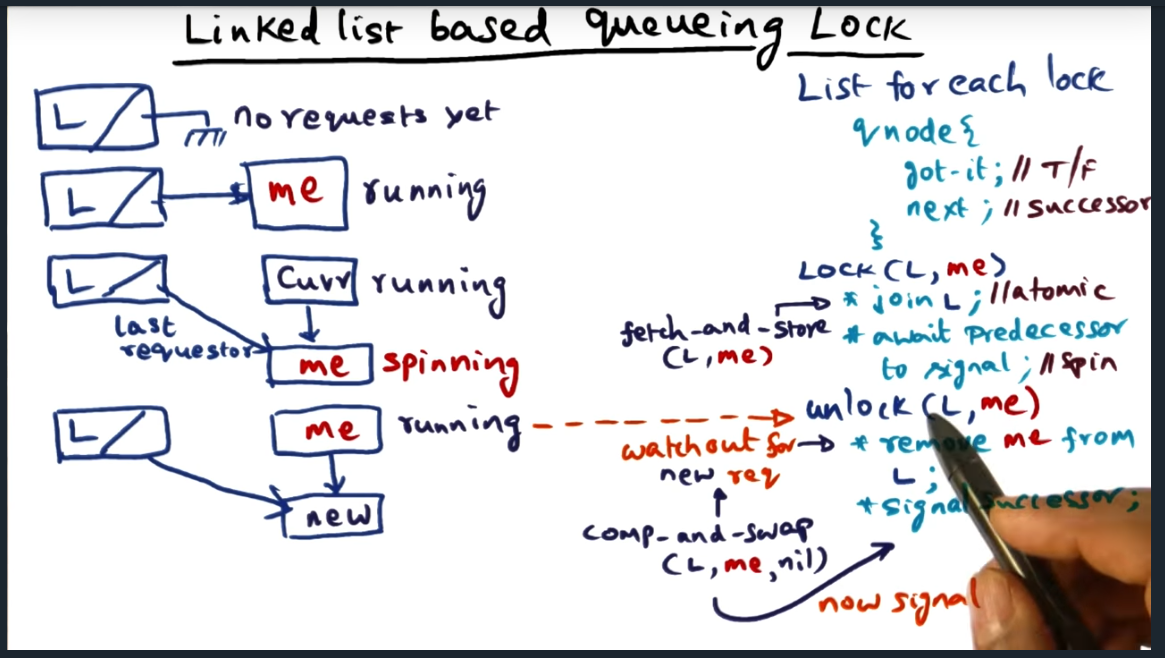
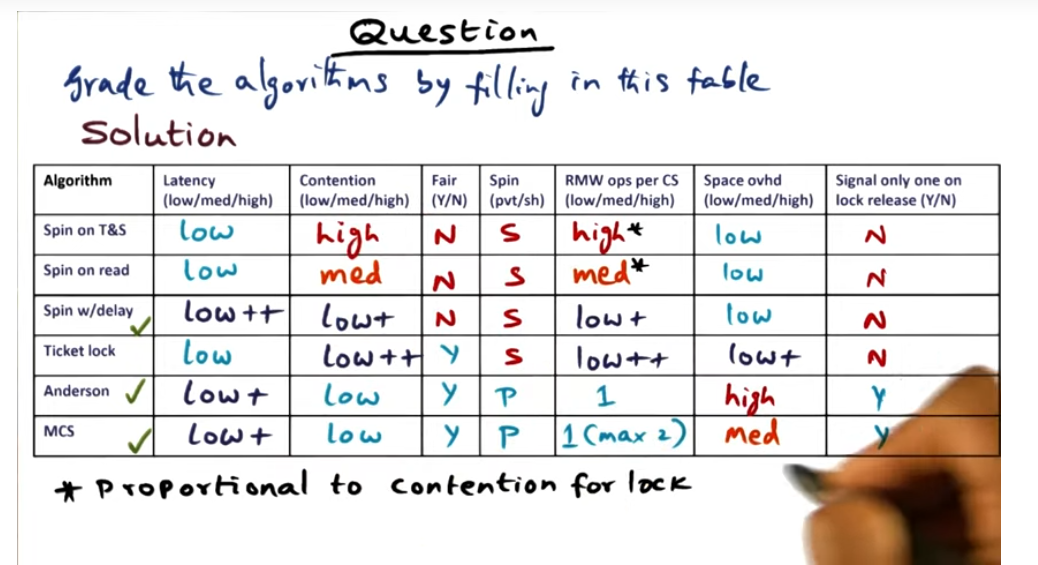
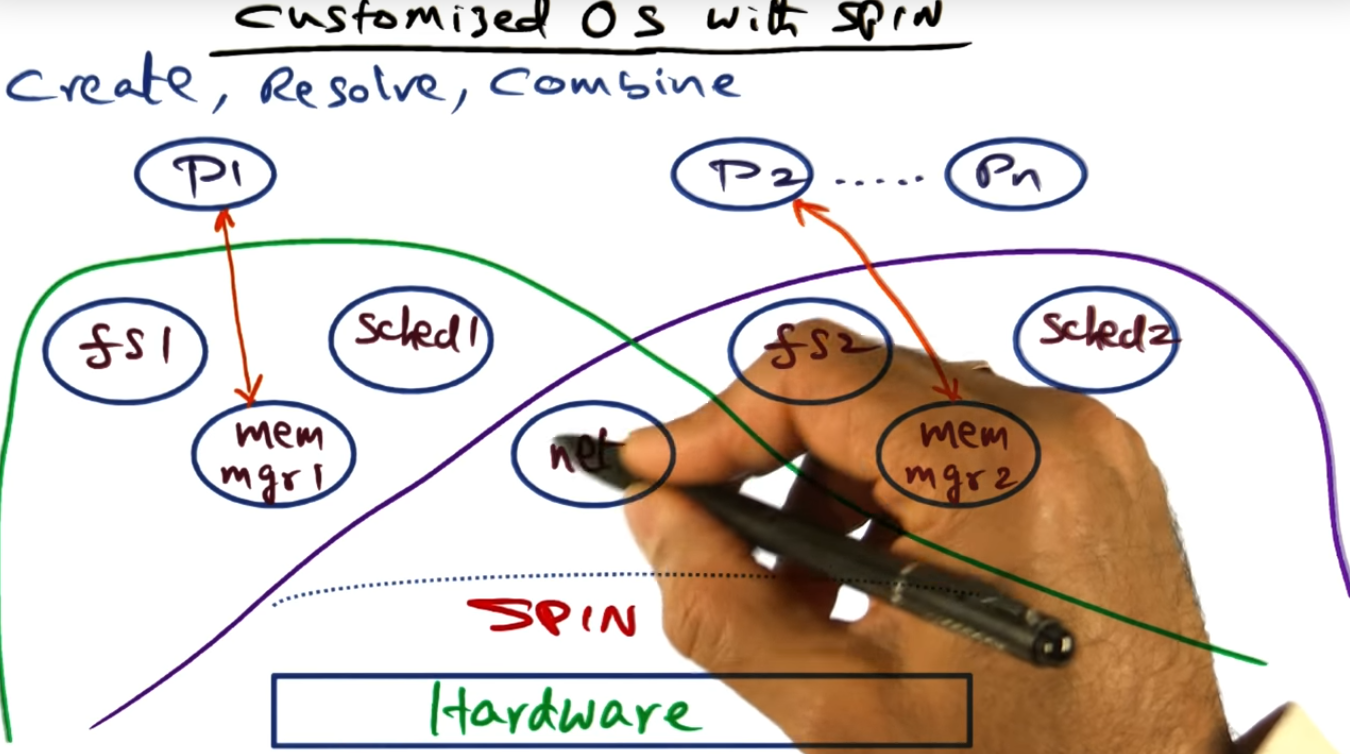
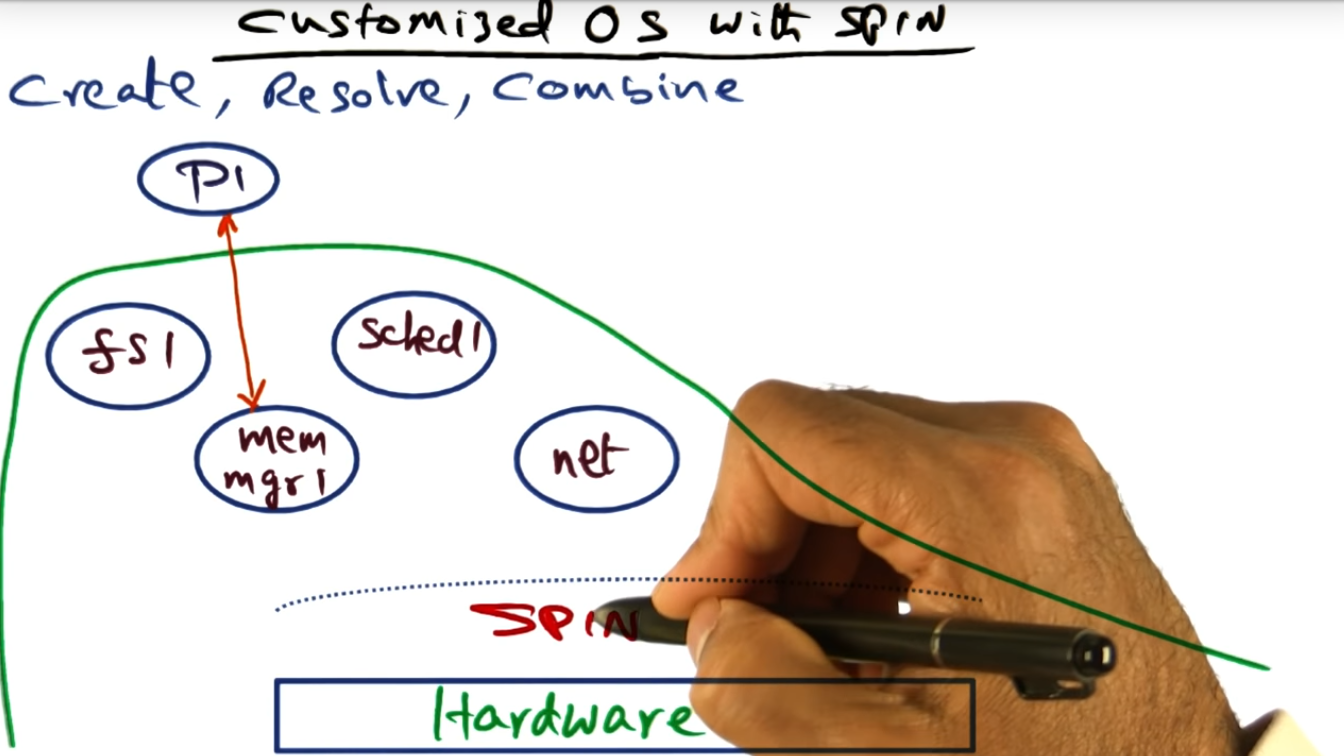
Overview
In this post, I’m sharing five tips that I’ve picked up over the last 2 years in the program. At the time of this writing, I’m wrapping up my 7th course (advanced operating systems) in the OMSCS program. This means that I have 3 more courses to complete until I graduate with my masters in computer science from Georgia Tech.
This post assumes that you are already enrolled as a student in the program. If you are still on the fence as to whether or not you should join the program, check out Adrian’s blog post on “Georgia Tech Review: yes, maybe, no”. Very shortly, I’ll post my own thoughts and recommendations on whether or not I think you should join the program.
Five Tips
Prerequisites
Before enrolling in a course, check the course’s homepage for recommended prerequisites. Once you are officially accepted into the program, you’ll soon discover that unlike undergraduate, you can enroll in courses despite not meeting prerequisites. The upside of this relaxed approach is that students who are really eager to take a course can do so (assuming seats are available). The downside is that if you are not prepared for the course, you’ll be way in over your head and likely will drop the course within the first few weeks since many courses are front loaded. For example, thinking about taking advanced operating systems? Before jumping the gun, take the diagnostic exam. Doing so will help you gauge whether or not you set up for success.
Time management
Manage your time by setting and schedule and sticking to it. If you are an early bird like me, carve out 50 minutes early in the morning, take a shot of your expresso, and get cracking. Set specific times in which you will sit down and study (e.g. watch lectures, review notes, work on a project) and aim to stick to that schedule (as a new parent, I understand that plans often can easily be foiled).
Trade offs
Know when and what to slip or sacrifice. This is super important. We all 24 hours in a day. And we all have other responsibilities such as a full time job or children to take care of. Or something unexpectedly will just pop up in your life that demands your attention. That’s okay. Graduate school (and doing well in graduate school) is important. But there will be other competing motivators and sometimes, you’ll have to sacrifice your grade. That’s okay.
Expectations
Know what you want to get out of the program. What are you trying to get out of the program? Or what are you trying to get out of the current course you are enrolled in? Are you here to learn and improve your craft? Then focus on that. Or are you here to get a good grade? Then do that. Are you here to expand your network and potentially apply to a PhD program? Then make sure you attend the office hours and meet with the professors.
Course reviews
Read the reviews on OMSCentral. If you haven’t read reviews on OMSCentral.com for the courses you plan to take (or are currently taking), please go and do that. Right now. On that website, you’ll find reviews from former students. They give you a better sense of what you’ll learn, what projects you’ll tackle, how engaged the professor is , whether the grades are curved, how difficulty the exams are, and maybe most important: how many hours you should expect to put into the course.
Notifications
Create e-mail (or text) notifications in your calendar for upcoming due dates. It sucks when you forget that an upcoming assignment is due soon. Sucks even more when you find out that the due date has passed. Although you can rely on Canvas (Georgia Tech’s current system for managing their courses), I still recommend using your own system.
Summary
The above tips do not guarantee a smooth journey. Chaos will somehow creep its way into our time and things will get derailed. That’s okay. Take a deep breathe and revisit the tip above on prioritization. Remind yourself why you are in graduate school. Now go out there and kick some ass.