Audience: Intermediate to advanced software developers (or startup technical chief technology officers) who build on the cloud and want to scale their software systems
Are you a software developer building scalable web services serving hundreds, thousands, or millions of users? If you haven’t already considered defining and adding upper limits to your systems— such as restricting the number of requests per second or the maximum request size—then you should. Ideally, you want to do this before releasing your software to production.
The truth is that web services can get knocked offline for all sorts of reasons.
It could be transient network failures. Or cheeky software bugs.
But some of the hairiest outages that I’ve witnessed first-hand? The most memorable ones? They’ve happened when a system either hit an unknown limit on a third dependency (e.g. a file system limit or network limit), or there was a lack of a limit that allowed too much damage (e.g. permitting unlimited number of transactions per second).
Let’s start by looking at some major Amazon Web Services (AWS) outages. In the first incident, an unknown limit was hit and rocked AWS Kinesis offline. In the second incident, the lack of a limit crippled AWS S3 when a command was mistyped during routine maintenance.
The enemy: unknown system limits
AWS Kinesis, a service for processing large-scale data streams, went offline for over 17 hours on November 25, 2020,[1] when the system’s underlying servers unexpectedly hit an unknown system limit, bringing the entire service to its knees.
On that day, AWS Kinesis was undergoing routine system maintenance, the service operators increasing capacity by adding additional hosts to the front-end fleet that is responsible for routing customer requests. By design, every front-end host is aware of every other front-end host in the fleet. To communicate among themselves, each host spins up a dedicated OS thread. For example, if there are 1,000 front-end hosts, then every host spins up 999 operating system threads. This means that for each server, the number of operating system threads grows directly in proportion to the total number servers.

Unfortunately, during this scale-up event, the front-end hosts hit the maximum OS system thread count limit, which caused the front-end hosts to fail to route requests. Although increasing the OS thread limit was considered as a viable option, the engineers concluded that changing a system-wide parameter across thousands of hosts without prior thorough testing might have potentially introduced other undesirable behavior. (You just never know.) Accordingly, the Kinesis service team opted to roll back the changes (i.e., they removed the recently added hosts) and slowly rebooted their system; after 17 hours, the system fully recovered.
While the AWS Kinesis team discovered and fixed the maximum operating system thread count limit, they recognized that other unknown limits were probably lurking. For this reason, their follow-up plans included modifying their architecture in an effort to provide “better protection against any future unknown scaling limit.”
AWS Kinesis’s decision to defend against and anticipate future unknown issues is the right approach: there will always be unknown unknowns. It’s something you can always count on. Not only is the team aware of their blind spots, but they are also aware of limits that are unknown to themselves as well as others, the fourth quadrant in the Johari window:
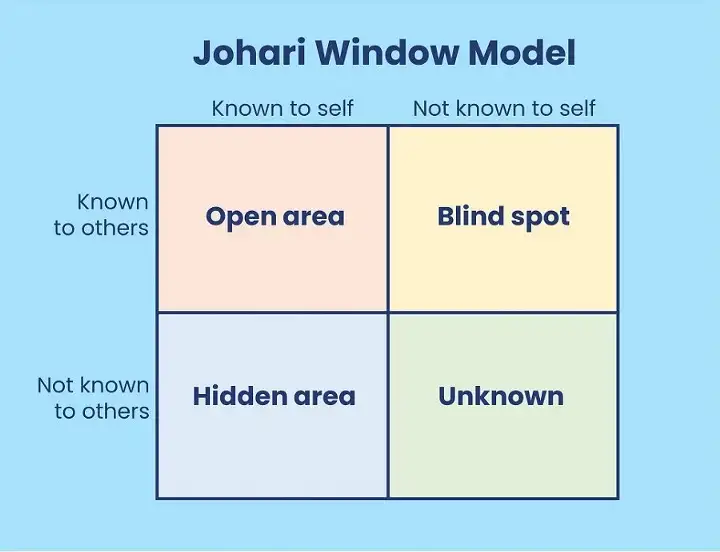
At first, it may seem as though the operating system limit was the real problem. However, it was really how the underlying architecture responded to hitting the limit that needed to be resolved. AWS Kinesis, as previously mentioned, decided to address that as part of its rearchitecturing effort.
No bounds means unlimited damage
AWS Kinesis suffered an outage due to hitting an unknown system limit, but in the following example, we’ll see how a system without limits can also inadvertently cause an outage.
On February 28, 2017, the popular AWS S3 (object store) web service failed to process requests: GET, LIST, PUT, and DELETE. In a public service announcement,[2] AWS stated that “one of the inputs to the command was entered incorrectly and a larger set of servers was removed than intended.”
In short, a typo.

Figure 3 – Source: https://www.intralinks.com
Now, server maintenance is fairly a routine operation. Sometimes new hosts are added to address an uptick in traffic; at other times, hosts fail (or hardware becomes deprecated) and need to be replaced. Despite being a routine operation, a limit should be placed on the number of hosts that can be removed. AWS recognized this missing safety limit causing an impact: “While removal of capacity is a key operational practice, in this instance, the tool used allowed too much capacity to be removed too quickly.”
A practical approach to uncovering limits
How do we uncover unknown system limits? How do we go about setting limits on our own systems? In both cases, we can start scratching the surface with a three-pronged approach: asking questions, reading documentation, and load testing.
Asking questions
Whether it’s done as part of a formal premortem or a part of your system design, there are some questions that you can ask yourself when it comes to introducing system limits to your web service. The questions will vary depending on the specific type of system you are building, but here are a few good, generic starting points:
- What are the known system limits?
- How does our system behave when those system limits are hit?
- Are there any limits we can put in place to protect our customers?
- Are there any limits we can put in place to protect ourselves?
- How many requests per second do we allow from a single customer?
- How many requests per second do we allow cumulatively across all customers?
- What’s the maximum payload size per request?
- How will we get notified when limits are close to being hit?
- How will we get notified when limits are hit?
Again, there are a million other questions you could/should be asking, but the above can serve as a starting point.
Reading documentation
If you’re lucky, either your own system software or third-party software will include technical documentation. Assuming that it is available, use it to familiarize yourself with the limitations.
Let’s look at a few different examples of how we might uncover some third-party dependency limits.
Example 1: Route53 Service
Imagine that you plan on using Amazon Web Services Route53 to provision DNS zones that will host your DNS records. (Shout out to my former colleagues still holding down the fort there. Before integrating with Route53, let’s step through the user documentation.
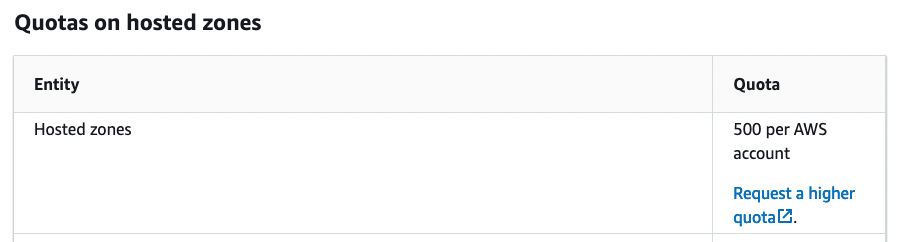
Figure 4
According to the documentation,[3] we cannot create an unlimited number of hosted zones: A single AWS account is capped at creating 500 zones. That’s a reasonable default value, and it is unlikely that you’ll need a higher quota (although, if you do, you can request a higher quota by reaching out to AWS directly).
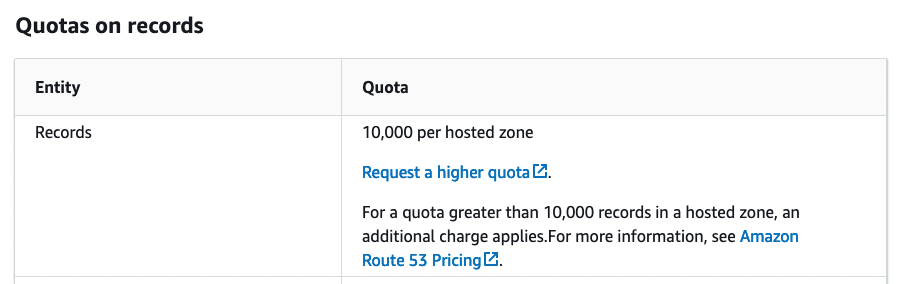
Figure 5
Similarly, within a single DNS zone, a maximum of 10,000 records can be created. Again, that’s a reasonable limit. However, it’s important to note—even as a thought exercise—how your system will behave if you theoretically hit these limits.
Example 2: Python Least Recently Used (LRU) Library
The same principle of reading documentation applies to software library dependencies, too. Say you want to implement a least recently used (LRU) cache using Python’s built-in library functools.[4] By default, the LRU cache defaults the maximum number of elements defaults to 128 items. This limit can be increased or decreased, depending on your needs. However, the documentation reveals a surprising behavior when the argument passed in is set to “None”: The LRU can grow without any limits.

Like the AWS S3 example previously described, a system without limits can have unintended side effects. In this particular scenario with the LRU, an unbounded cache can lead to memory usage spiraling out of control, potentially eventually eating up all the underlying host’s memory and triggering the operating system to kill the process!
Load testing
There are whole books dedicated to load testing, and this article just scratches the surface. Still, I want to lightly touch on the topic since it’s not too uncommon for documentation — your own or third-party dependencies — to omit system limits. Again, by no means is the below a comprehensive load testing strategy; it should only serve as a starting point.
To begin load testing, start hammering your own system with requests, slowly ramping up the rate over time. One popular tool is Apache JMeter.[5] Begin with sending one request per second, then two, then three and so on, until the system’s behavior starts to change: Perhaps latency increases or the system falls over completely, unable to handle any requests. Maybe the system starts load shedding,[6] dropping requests after a certain rate. The idea is to identify the upper bound of the underlying system.
Another type of limit worth uncovering is the maximum size of a request. How does your system respond to requests that are 1 MB, 10 MB, 100 MB, 1 GB, and so on? Maybe there’s no maximum request size configured, and the system slows down to a crawl as the payload size increases. If discover that this is the case, you’ll want to set a limit and reject requests above a certain payload size.
After you are done load testing, document your findings. Write them in your internal wiki, or commit them directly into source code. One way or another, get it written down somewhere.
Next, you’ll want to start monitoring these limits, creating alarms, and setting up email (or pager) notifications at different thresholds. We’ll explore this topic more deeply in a separate post.
Summary
As we’ve seen, its important to uncover unknown system limits. Equally important is setting limits on our own systems, which protects both end users and the system itself. Identifying system limits, monitoring them, and scaling them is a discipline that requires ongoing attention and care, but these small investments can help your systems scale and hopefully reduce unexpected outages.
References
Python documentation. “Functools — Higher-Order Functions and Operations on Callable Objects.” Accessed December 20, 2022. https://docs.python.org/3/library/functools.html.
“Quotas – Amazon Route 53.” Accessed December 20, 2022. https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/DNSLimitations.html.
Amazon Web Services, Inc. “Summary of the Amazon Kinesis Event in the Northern Virginia (US-EAST-1) Region.” Accessed December 7, 2022. https://aws.amazon.com/message/11201/.
Amazon Web Services, Inc. “Summary of the Amazon S3 Service Disruption in the Northern Virginia (US-EAST-1) Region.” Accessed December 19, 2022. https://aws.amazon.com/message/41926/.
“There Are Unknown Unknowns.” In Wikipedia, December 9, 2022. https://en.wikipedia.org/w/index.php?title=There_are_unknown_unknowns&oldid=1126476638.
Amazon Web Services, Inc. “Using Load Shedding to Avoid Overload.” Accessed December 20, 2022. https://aws.amazon.com/builders-library/using-load-shedding-to-avoid-overload/.
[1] “Summary of the Amazon Kinesis Event in the Northern Virginia (US-EAST-1) Region.”
[2] “Summary of the Amazon S3 Service Disruption in the Northern Virginia (US-EAST-1) Region.”
[3] “Quotas – Amazon Route 53,” 53.
[4] “Functools — Higher-Order Functions and Operations on Callable Objects.”
[5] https://jmeter.apache.org/
[6] “Using Load Shedding to Avoid Overload.”
Leave a Reply