

As mentioned previously, there are different types of synchronization primitives that us operating system designers offer. If as an application designer you nee to ensure only one thread can access a piece of shared memory at a time, use a mutual exclusion synchronization primitive. But what about a different scenario in which you need all threads to reach a certain point in the code and only once all threads reach that point do they continue? That’s where a barrier synchronization comes into play.
This post covers two types of barrier synchronizations. The first is the naive, centralized barrier and the second is the a tree barrier.
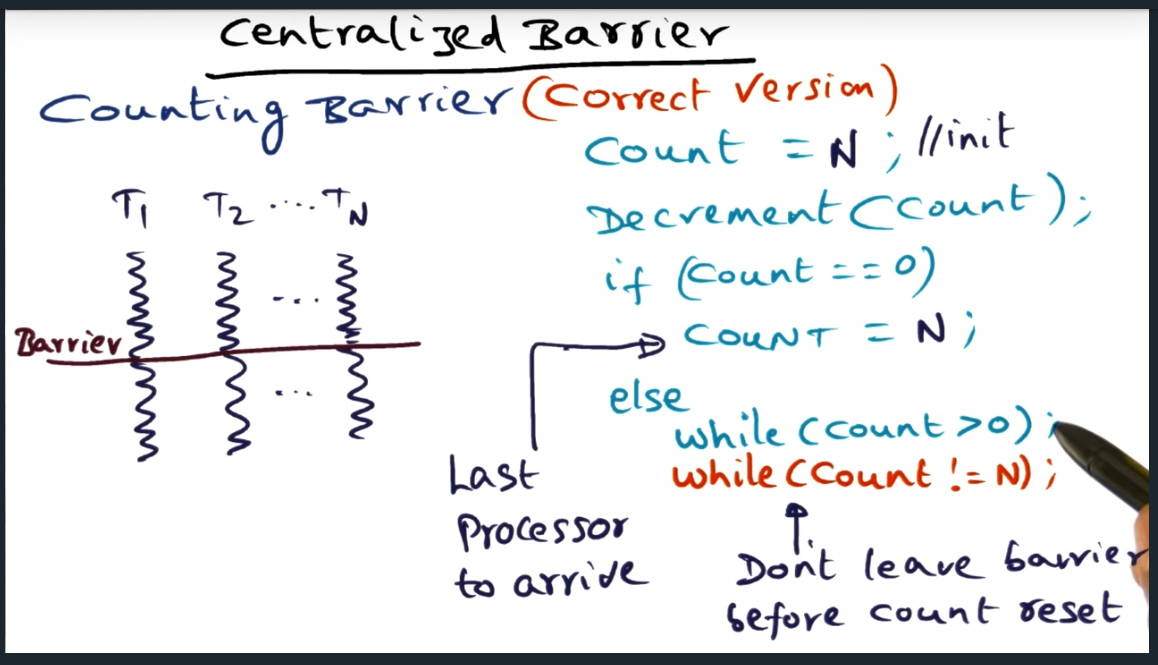
In a centralized barrier, we basically have a global count variable and as each thread enters the barrier, they decrement the shared count variable. After decrementing the count, threads will hit a predicate and branch: if the count is not zero, then the thread enters a busy spin loop, spinning while the count is greater than zero. However, if after decrementing the counter equals zero, then that means all threads have arrived at the end of the barrier synchronization.
Simple enough, right? Yes it is, but the devil is in the details because there’s a subtle bug, a subtle edge case. It is entirely possible (based off of the code snippet below) that when the last thread enters the barrier and decrements the count, all the other threads suddenly move beyond the barrier (since the count is not greater than zero). In other words, the last thread never gets to reset the count back to N number of threads.
How to avoid this problem? Simple: add another while loop that guarantees that the threads do not leave the barrier until the counter gets reset. Very elegant. Very simple.
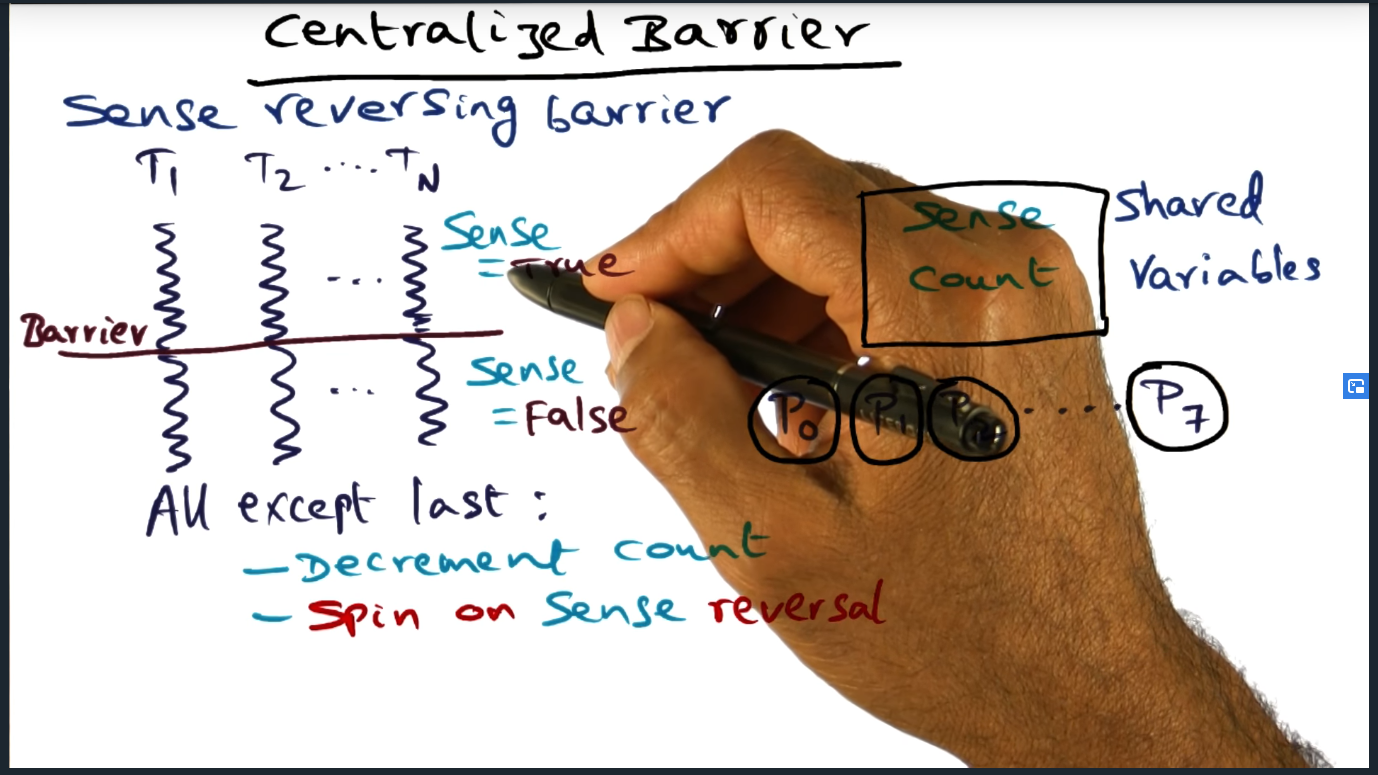
One way to optimize the centralized barrier is to introduce a sense reversing barrier (as I described in “making sense of the sense reversing barrier”).
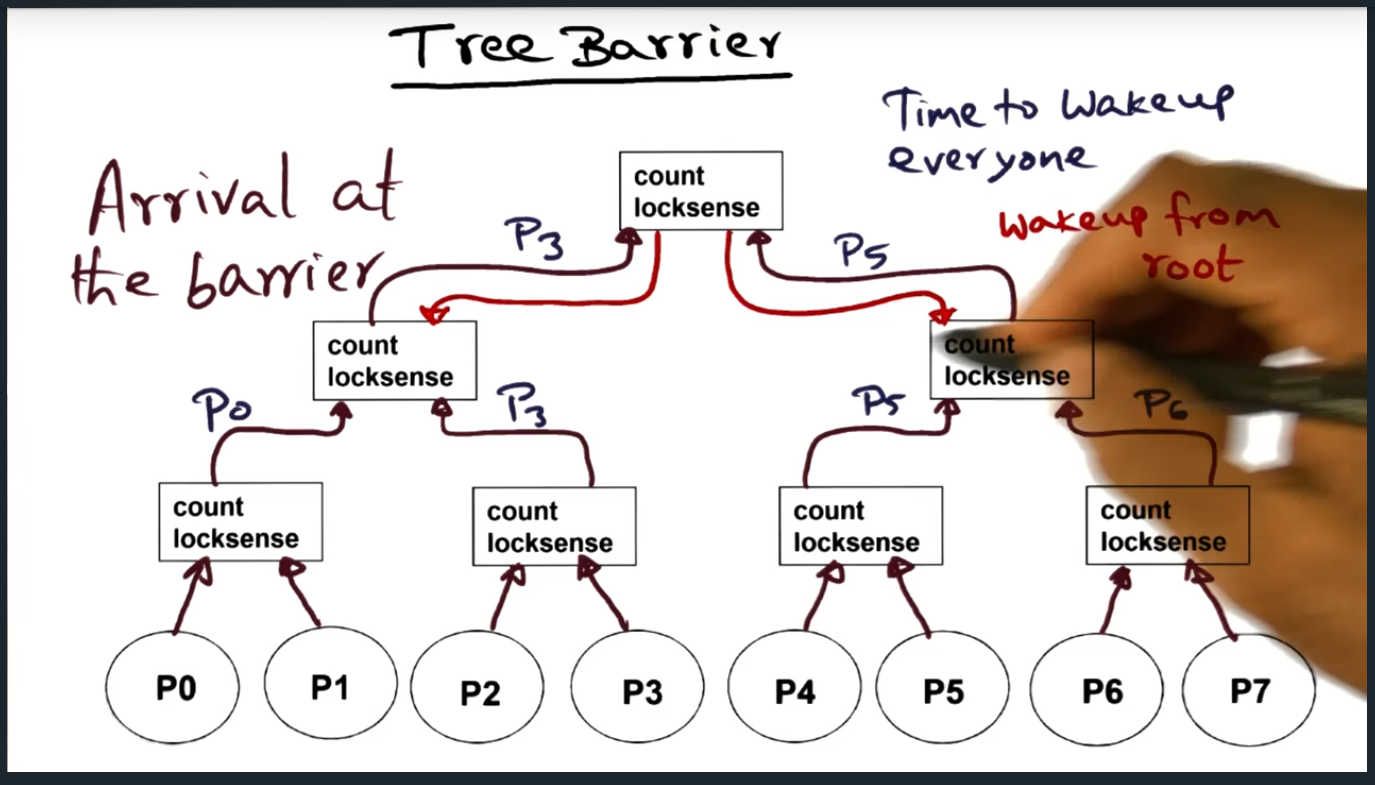
The next type of barrier is a tree barrier. The tree barrier groups multiple process together at multiple levels (number of levels is logn where n is the number of processors), each group maintaining its own count and local sense variables. The benefit? Each group spins on its own locksense. Downside? The spin location is dynamic, not static and can impede performance on NUMA architectures.
Centralized Barrier
Summary
Centralized barrier synchronization is pretty simple: keep a counter that decrements as each thread reaches the barrier. Every thread/process will spin until the last thread arrives, at which point the last thread will reset the barrier counter so that it can be used later on
Problems with Algorithm
Summary
Race condition: last thread, while updating the counter, all other threads move forward
Counting Barrier
Summary
Such a simple and elegant solution by adding a second spin loop (still inefficient, but neat nonetheless). Sense reverse barrier algorithm
Sense Reversing Barrier
Summary
One way to optimize the centralized barrier is to introduce a sense reversing barrier. Essentially, each process maintains its own unique local “sense” that flips from 0 to 1 (or 1 to 0) each time synchronization barrier is needed. This local variable is compared against a shared flag and only when the two are equal can all the threads/processes proceed past the current barrier and move on to the next
Tree Barrier
Summary
Group processes (or threads) and each group has its own shared variables (count and lock sense). Before flipping the lock sense, the final process needs to move “up to the next level” and check if all other processors have arrived at the next level. Things are getting a little more spicy and complicated with this type of barrier
Tree Barrier (Continued)
Summary
With a tree barrier, a process arrives at its group (of count and lock sense), and will decrement the count variable and will then check the lock sense variable. If lock sense is not equal, then spin. If last
Tree Barrier (continued)
Summary
Once the last process reaches the root, it’s their responsibility to begin waking up the lower levels, traversing back down the tree. At each level, they will be flipping the lock sense flag
Tree Barrier (Continued)
Summary
As always, there’s a trade off or hidden downside with this implementation. First, the spin location is not statically determined. This dynamic allocation may be problematic, especially on NUMA (non uniformed memory access architecture) architecture, because a process may be spinning on a remote memory location. But my question is, are there any systems that do not offer coherence?