If just download the libvert application development guide, click here.
How to build the documentation
libvrt broken documentation
The libvrt developer documentation link is broken (i.e. HTTP 404). But I need the development guide for my advanced OS course so I downloaded the repository and built the documentation from source. If you want to do the same (instead of downloading the PDF I rendered above) you can execute the following instructions:
Project 1 was released last evening at 08:59 PM PST and this morning, I decided to start on the project by reading through the overview and get the lay of the land. For this project, we’ll need to deliver to operating system components: a scheduler and a memory coordinator (not even sure what that means exactly).
So what I’m doing as part of this post is just taking a snapshot of the questions I have and topics I do not understand, topics that I’ll probably understand in much more depth as the project progresses. More often than not, I often dismissive of all the work I put in over the semester and this post is one way to honor the time and commitment.
Overall, this project’s difficulty sits in the right place — not too hard but not too easy. The sweet spot for Deliberate Practice.
Questions I have
What algorithm should I implement for my scheduler?
What algorithms fit the needs for this project
What the heck is a memory coordinator?
Why do we have a memory coordinator? What’s it purpose?
How do you measure the success of a memory coordinator?
How do I use libvrt library?
What is QEMU?
Where does the scheduler sit in relationship to the operating system?
How will I get the hypervisor to invoke my scheduler versus another scheduler?
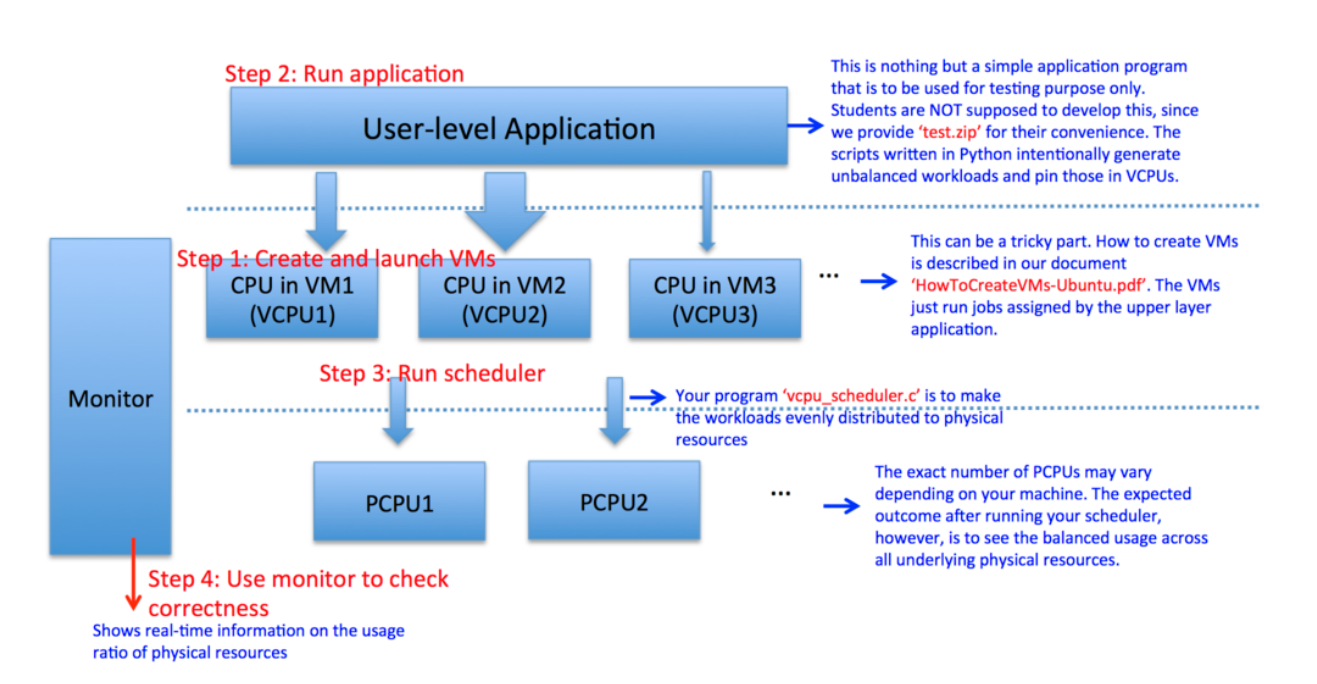
Project Requirements
You need to implement two separate C programs, one for vCPU scheduler (vcpu_scheduler.c) and another for memory coordinator (memory_coordinator.c)
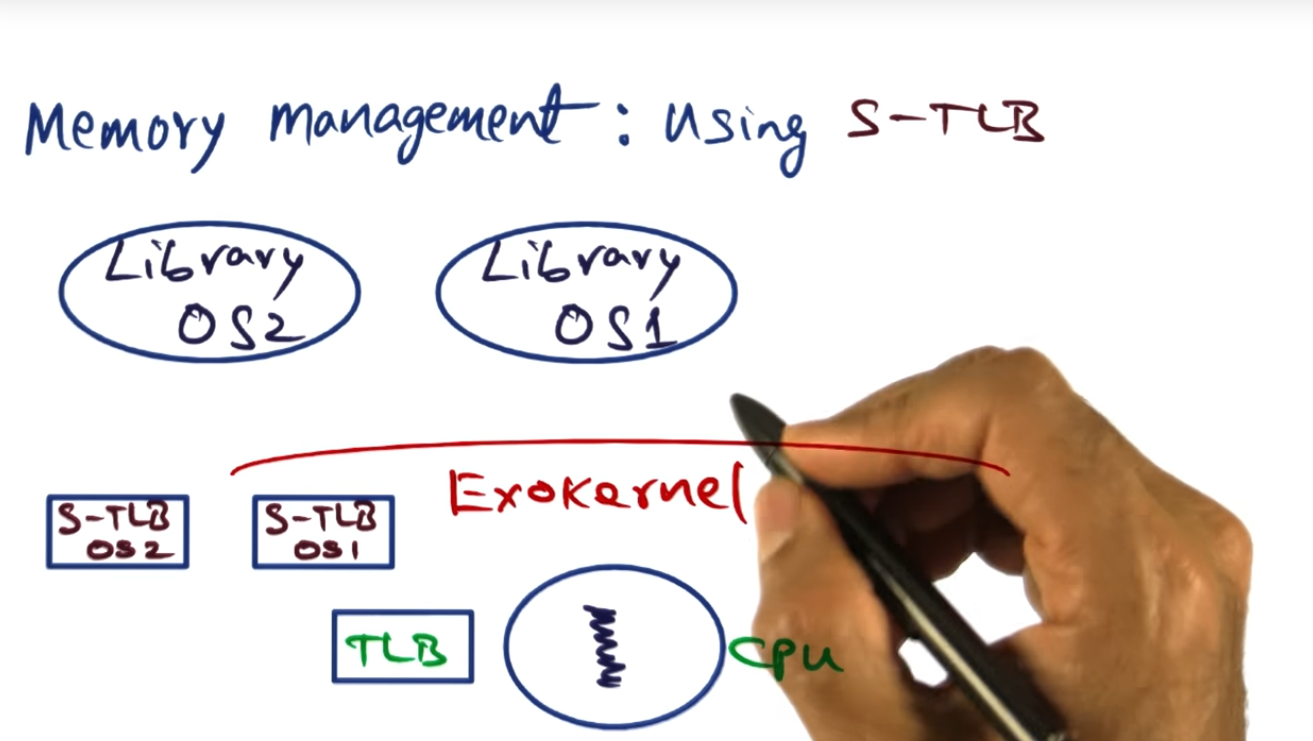
Unlike the SPIN OS Structure, exokernel approaches extensibility by decoupling the authorization to hardware from its actual use, by using something called secure bindings. OS libraries will request secure bindings, the Exokernel returning an encrypted key that grants that particular service to specific resources.
One other way that the exokernel manages these underlying OS services is via CPU scheduling. The exokernel maintains a linear vector “time slots”, allotting each OS service a certain amount of time to run on the CPU.
Exokernel also introduces the concept of a STLB (software translation lookaside buffer), the STLB improving performance since, during each process context switch, the exokernel will copy the hardware TLB to a software TLB structure and when the process runs again, the exokernel will copy the software TLB back into the hardware, eliminating the need for a TLB flush.
Exokernel Approach to Extensibility
Summary
Library OS requests access to a specific hardware resource. If access granted, exokernel returns an encrypted key which will be used for future keys
Examples of Candidate Resources
Summary
An OS library will perform some action, sending the Exokernel its encrypted key, and once Exokernel accepts that request, the data processing is cheap. Like packet processing: OS library requests to install predicates for packet filtering; once predicates installed, exokernel will invoke those rules on behalf.
Implementing Secure Bindings
Summary
There are three mechanisms for implementing secure bindings. First is hardware mechanisms, like fetching the TLB. Second would be software, like caching the hardware TLB inside of the OS, avoiding the cost of flushing the TLB during a context switch. And third would be downloading code into the kernel, a feature analogous to SPIN’s approach with logical domains. I don’t really understand these concepts quite yet: it’s all a bit abstract, for now.
Default Core Services in Exokernel
Default Core Services in Exokernel
Summary
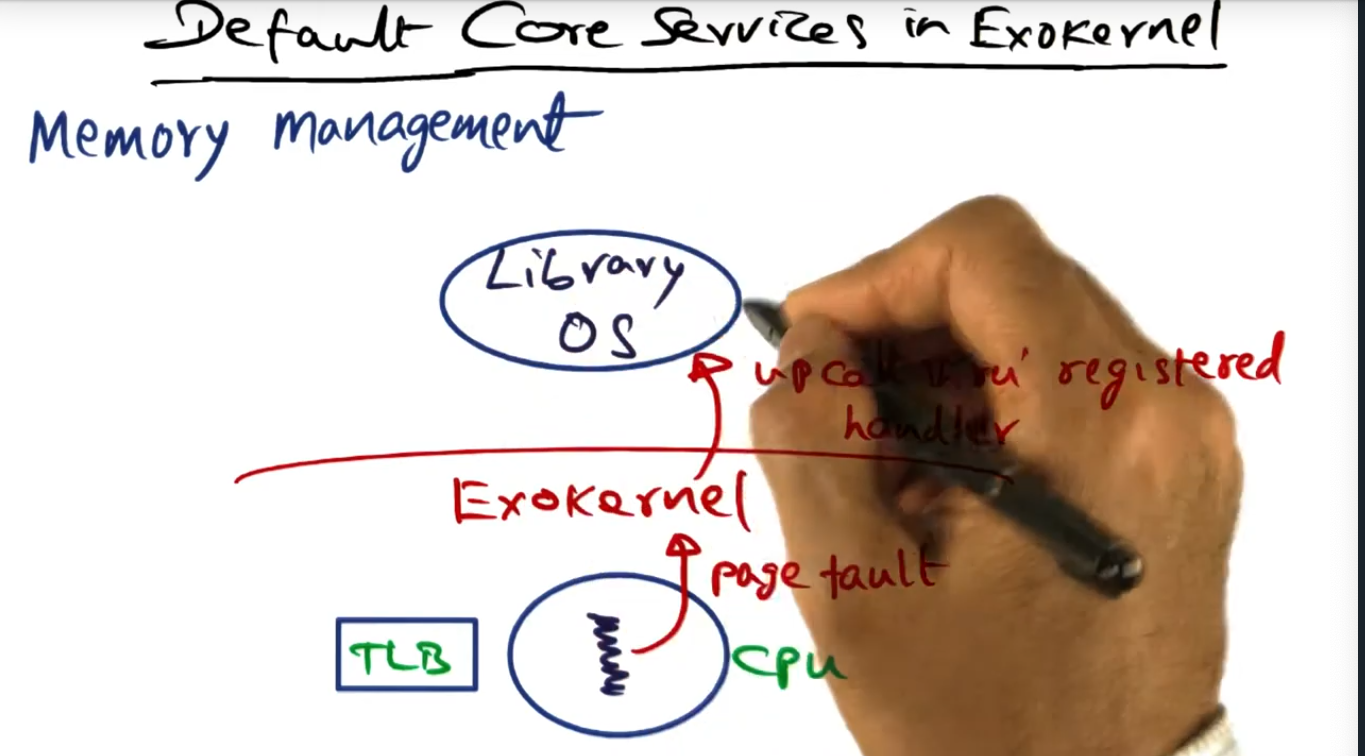
For memory management, the library OS will handle the page fault (uncalled through the register) by presenting a mapping (with the secure binding) to the Exokernel, the Exokernel installing the mapping in the TLB (hardware), this step requiring privileged access.
Secure Binding
Summary
As the instructor put it, this is all a bit dicey. Both SPIN and Exokernel allow library OS privilege for pure performance but how do we guarantee that the insertion of code into the kernel is done … securely? Safely? Will find out soon, probably over the next couple videos
Memory Management using Software TLB
Software TLB
Summary
In exokernel, during a context switch, the hardware TLB for a process is copied into a STLB (software TLB) and during a context switch, new process’s software TLB will be preloaded by the Exokernel. Of course, if there’s a TLB cache miss, then the standard page fault workflow happens
Default Core Services in Exokernel (continued)
Default Core Services continued
Summary
Three is a linear vector of “time slots”, each OS service reserving a slot for its service. If the OS service runs longer than the allotted quantum, the exokernel will punish it, reducing its time slot in the next run. Time is bounded to perform the saving of the context.
Revocation of Resources
Summary
Exokernel can revoke or reclaim permission from a Library OS, the OS sending an up call (and passing a repossession vector) to the Library OS, informing the library OS that it may need to stash away its resources (on disk).
Putting it all together
Summary
While a library OS’s thread is running, an external event will be kicked up to the running process to determine what to do next
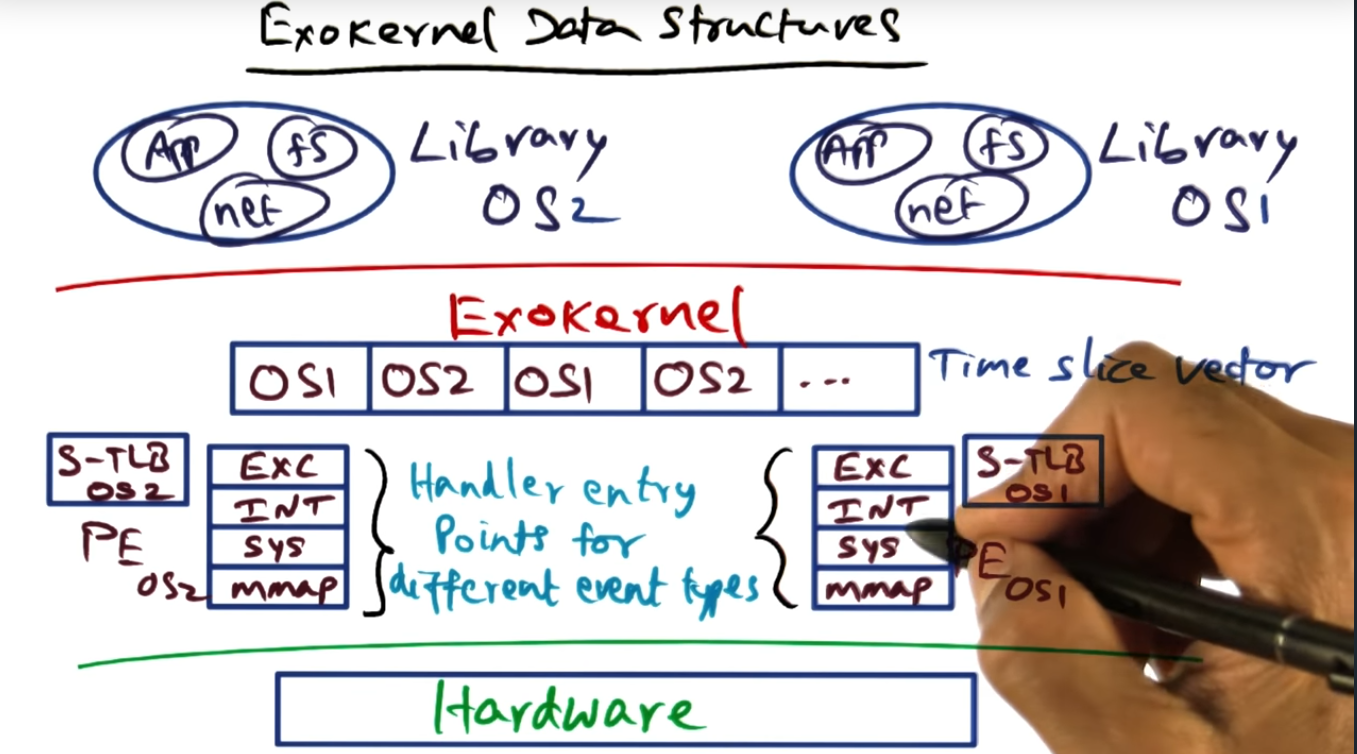
Exokernel Data Structures
Exokernel Data Structures
Summary
Exokernel maintains a data structure for each of the running library OS, maintaining a software TLB that gets loaded during a context switch
Performance Results of Spin and Exokernel
Summary
Absolute numbers are meaningless: it’s the trends that count.
The concept of border crossing pops up over and over again. This is a new term I never heard of prior to this class. The term is almost synonymous to a context switch but it is subtly different in the sense that a context switch (switch from one process to another or one thread to another) can occur without a border crossing, without changing the underlying hardware address space.
SPIN attempts to enforce protection at the compiler level, by using a restrictive language called Modula-3. Unlike the C language, where you can cast a pointer to whatever data structure you like, Modula-3 enforces type safety, only allowing the developer to cast a pointer to specific types of data structures that they had already specified earlier in the code.
SPIN offers extensibility by allowing different types of OS services to co-exist with one another.
But what are the trade offs with SPIN, when compared with Microkernel and Exokernel?
It appears that SPIN would be more performant than Microkernel due to no border crossings while maintaining flexibilty (multiple types of OS services that cater to application processes) and security (via logical protection domains) with Modula-3, allowing code OS services library code to co-locate with kernel code.
Introduction
Customizing OS with SPIN
Summary
SPIN and Exokernel take two different paths to achieving extensibility. These designs overcome the issue of Microkernel, which compromises in performance due to border crossings, and monolithic, which does not lend itself to extensibility
What we are shooting for in OS Structure
Summary
We want flexibility similar to a microkernel based approach but also want protection and performance of monolithic. We want the best of both worlds: performance protection flexibility
Approaches to Extensibility
Damn, this is a super long video (8 minutes, compared to the other one to two minute videos prior)
Capability based
Hydra OS (1981)
Summary
Hydra did not fully achieve its goal of extensibility
Micro Kernel Based
Summary
Performance took a back seat, since the focus was on extensibility and portability. Bad press for micro kernel based due to the twin goals.
SPIN approach to extensibility
Summary
By co locating the kernel and extension in the same hardware space, the extensions are cheap as procedure call. Doing this by depending on a strongly typed language to provide safety
Logical Protection Domains
Summary
Using a programing language called Modula3, which doesn’t appear to be popular in practice, we can enforce protection at the logical level. This programming language, unlike C, restricts casting pointers to random data structures, only allowing the cast to a particular data type.
Spin mechanisms for protection domains
Summary
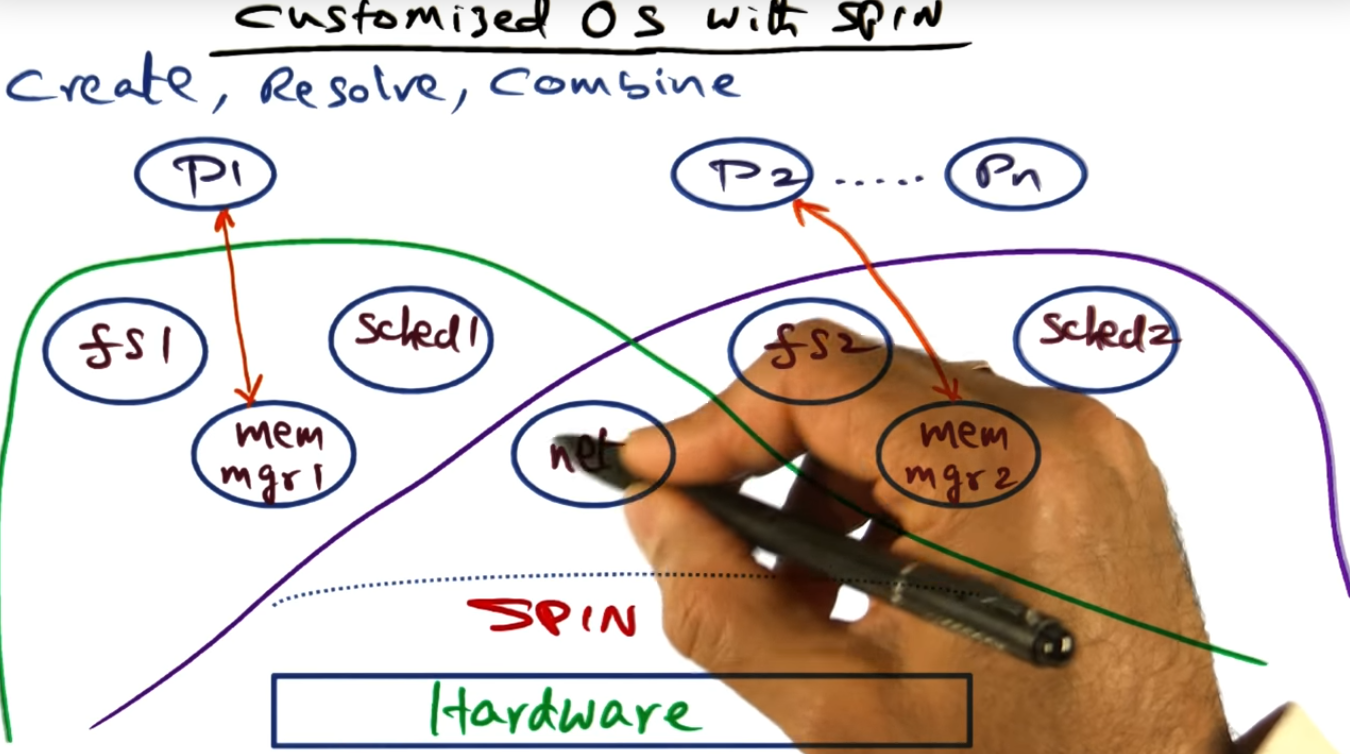
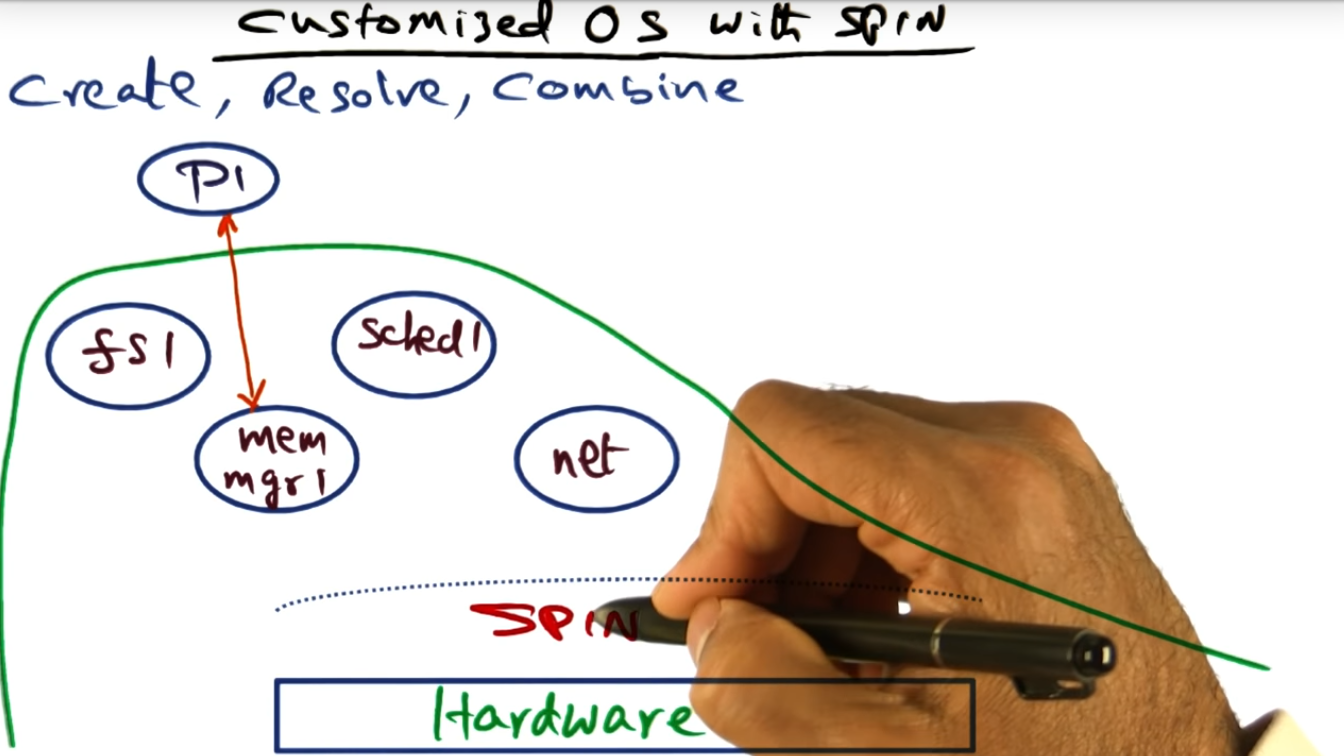
The secret sauce of protection and performance are the mechanisms of creating (i.e. expose entry points), resolving (i.e. leverage other entry points), and combining of logical protection domains
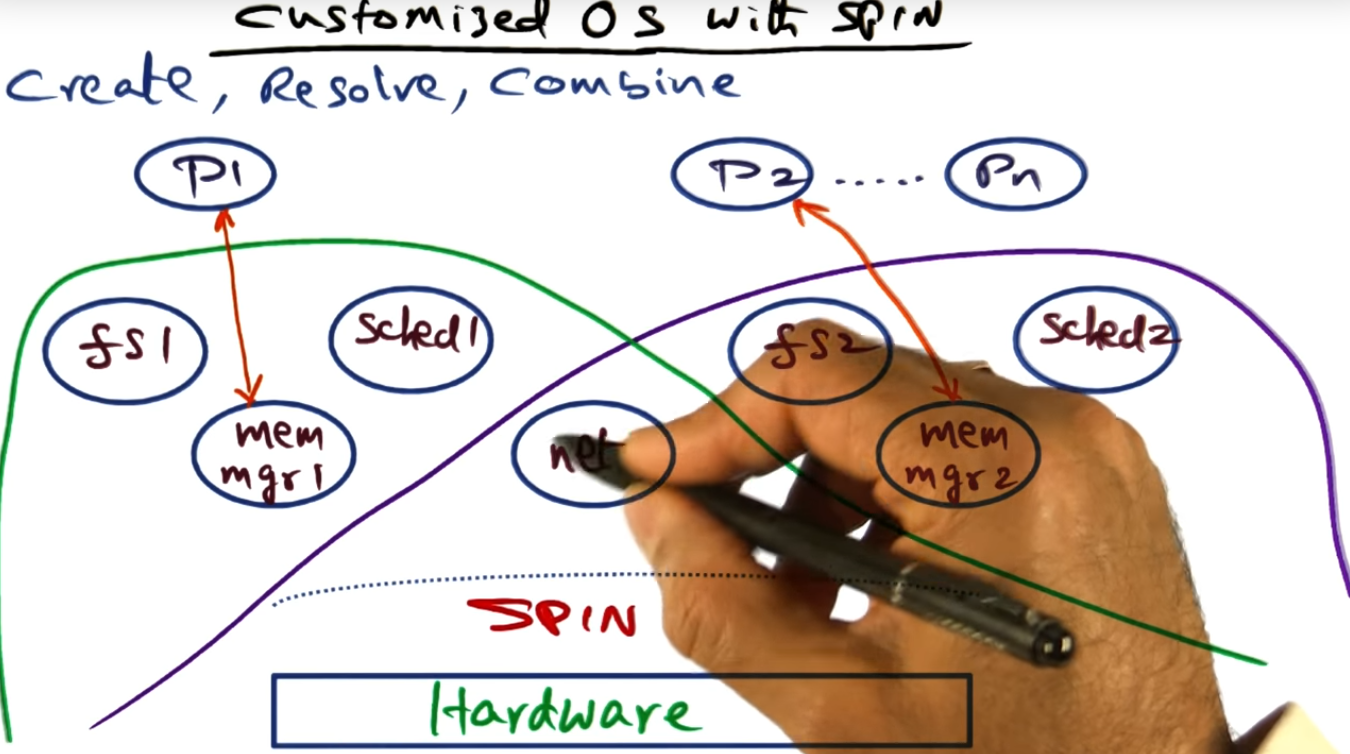
Customized OS with Spin
Another example of SPIN os customization
Summary
There can be multiple file systems (written in Modula3), each file system catering to their callers, and each file system using the same underlying hardware address space. And they can share modules with one another, like the networking entry point.
Example Extensions
Summary
Example of Unix Servers implementing their OS on SPIN as well as a video server / display client building on top of spin
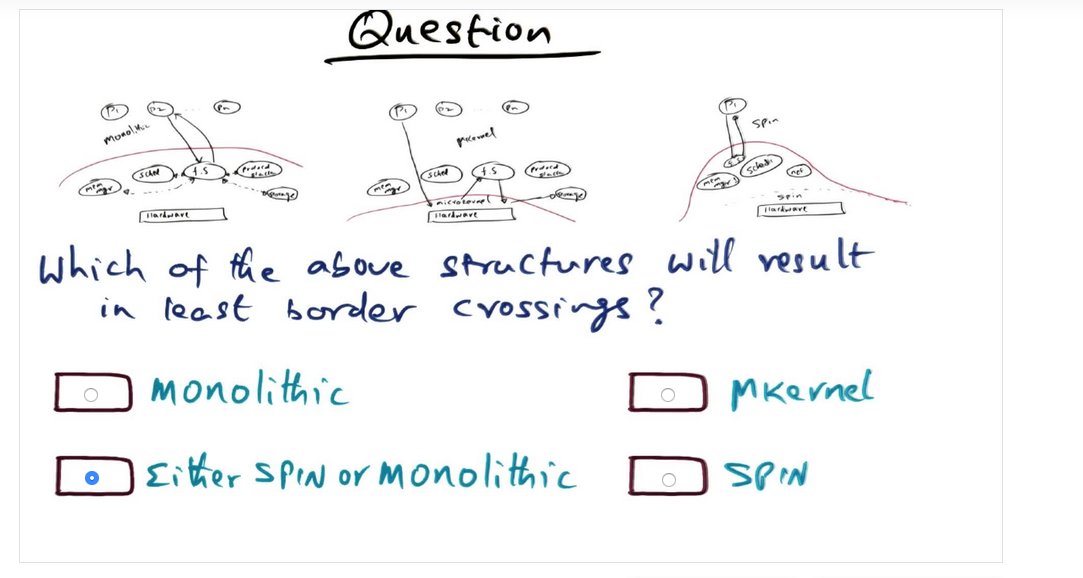
Quiz: Border Crossings
Quiz: Least likely for border crossing
Summary
Microkernel and SPIN offer performance since they limit the border crossings. In SPIN, Logical domains do not require border crossings
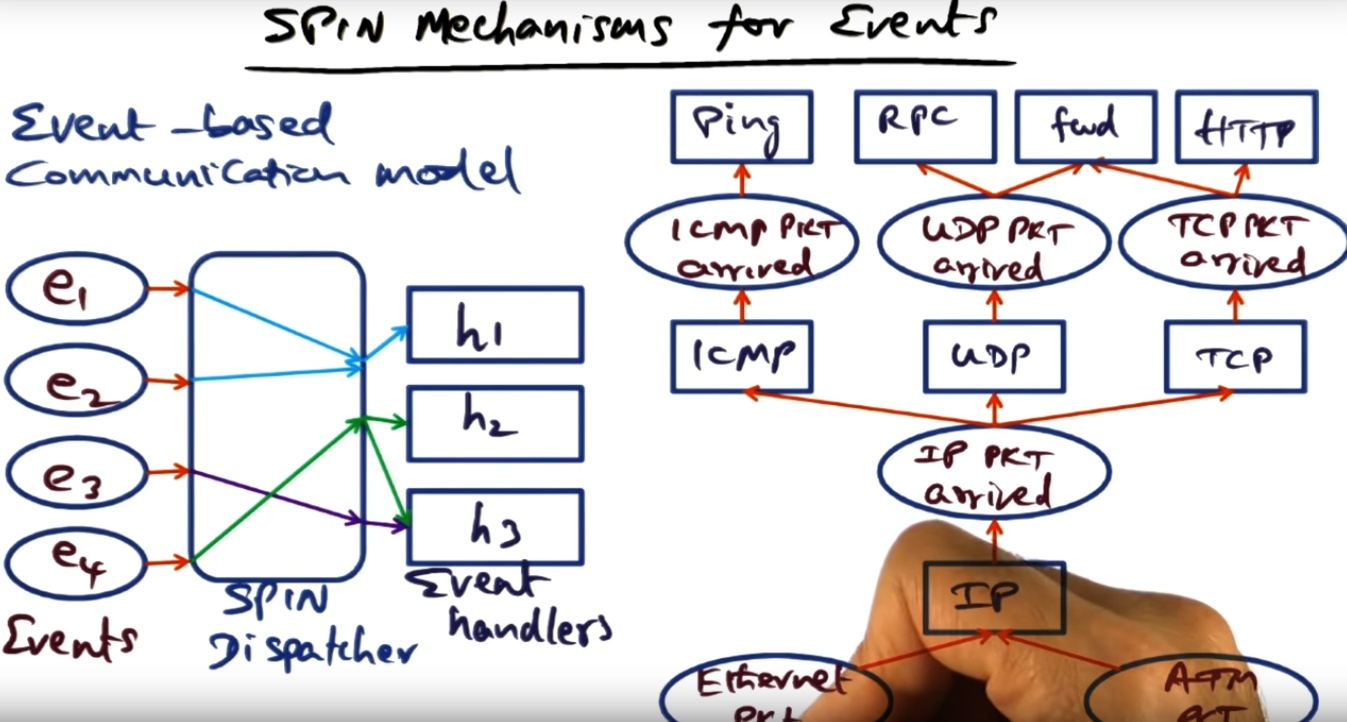
SPIN Mechanisms for Events
SPIN classifies three types of event handling: one-to-one, one-to-many, many-to-one
Summary
To handle events (like packet arrival) we can have a 1:1 mapping, 1:N mapping or N:1 mapping. For 1:1, an example would be an ICMP packet arriving and the 1 ICMP handler running. In a 1:N mapping, the IP packet arrived event runs and signals three other event handlers like ICMP, UDP, or TCP. Then finally, there is a N:1, and an example of this is an Ethernet and ATM packet event arrives but both funnel into the IP handler
Default Core Services in SPIN
Summary
SPIN offers core services like memory management, CPU scheduling etc. And SPIN will provide a header file that OS programmers need to implement. Remember: these implementations talk to each other through well defined interfaces, offering protection, but are also performant cause there are no border crossings)
Default Core Services in SPIN (Continued)
Summary
Provides primitives, the interface function definition. The semantics are up to the extension itself. SPIN makes sure extensions get time on scheduler
For advanced operating systems course, us students are required to sign up for (at least) two research papers that we summarize. Although two papers doesn’t sound like much, many former students of the course suggested ignore the other research papers and instead, focus on watching the lectures (which do cover the papers, sort of), banging out the software project, and (sadly) performing rote memorization based off of previous exams (I’ll need to get my Anki set up for this, stat).
Reviews on OMSCentral related to reading papers
I gave up on trying to read all the papers, electing to focus on projects and memorize the lectures instead. It worked out ok for me, and I averaged 18 hours a week on this course anyway. YMMV.
The downside to me is the number of readings was, well, high. Somewhere around 45 papers are to be read during the semester, and most of them are foundational but also from an earlier time in computing. I enjoy newer research papers with tech I can relate to, so for me in general these were less enjoyable and more difficult to digest. Still worthwhile, I think, but more of a slog.
The sheer number of papers assigned could easily push the time commitment past 30 hours a week if a student were to read them all, but as most have noted, you can largely skip reading them. Even skipping papers, the lectures are long and are difficult to get through. The content is broad and I think it tries to cover too much ground.
Papers I’m going to read
So although I’ll probably skim most of the research papers, I’ll dig into the below papers in depth. Why did I choose these papers? Well, some of the other papers (on networking) played into my strengths, categories that I’m somewhat well versed on. As a result, I chose papers grouped under categories that I not only find interesting (distributed systems and failures + recovery mechanism) but categories I’m unfamiliar with.
Liu, Kreitz, van Renesse, Hickey, Hayden, Birman, Constable, “Building Reliable High Performance Communication Systems from Components “, 17th ACM Symposium on Operating System Principles, OS Review, Volume 33, Number 5, Dec. 1999.
D. Porter, O. Hofmann, C. Rossbach, A. Benn, E. Witchel, “Operating System Transactions“, SOSP’09.
Stretch goal
Lamport, L., “Time, Clocks, and the Ordering of Events in a Distributed System”, Communications of the ACM, 21, 7, pgs. 558-565, July 1978.
I’m really struggling to intimately understanding virtually index privately tagged concept. From a high level, I get that VIPT is an optimization technique, parallelizing both the translation of virtual addresses to physical and the cache look up of the physical address. This seems impossible at first since the cache depends on the physical frame number (PFN).
So in order to accomplish this, we’ll use the some bits of the VPN to search in the TLB and then the least significant bits when searching the cache. This makes sense. But what I don’t quite fully don’t understand is why we have to limit the size of the cache in order to avoid aliasing (i.e. different virtual addresses that end up mapping to the same physical frame).
Thinking out loud here … I suppose that if the index of the physical bits bleed into the virtual address, then we actually do not avoid the aliasing problem, the issue of having more than one virtual address map to the same physical frame.
Ok, I think I got it.
But what’s the catch?
You only can have a very small cache, the size equal to the page size multiplied by the set associativity. This means that the only way to increase the size of the cache is by increasing the associativity which ultimately increases the look up time as well since the cache has to look the tag up across multiple cache lines.
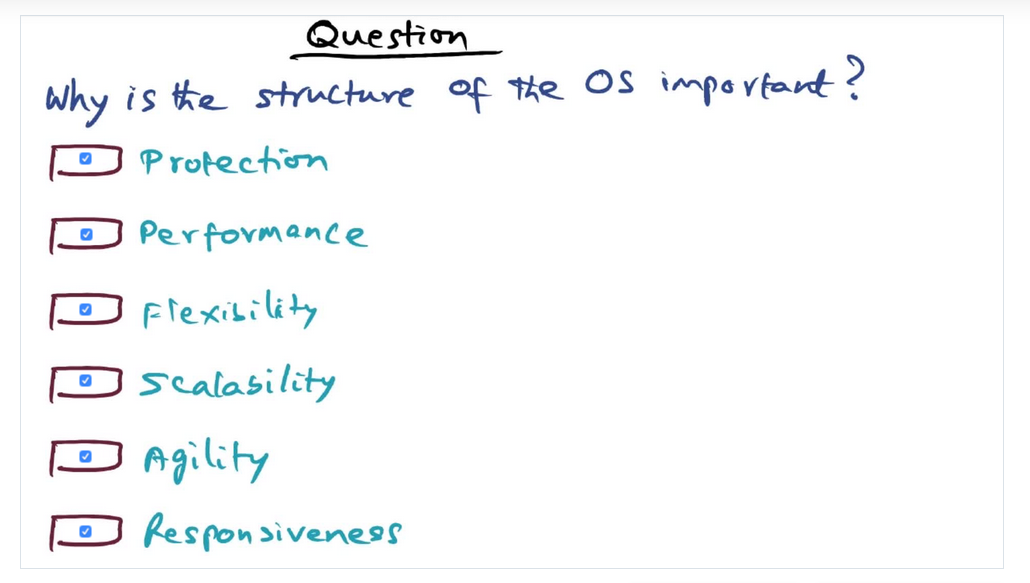
In the context of an operating system, what does structure even mean and why is it important? Structure determines how the operating system serves application in regards to the underlying hardware and how it balances the following qualities: protection, performance, flexibility, scalability, agility, and responsiveness.
To obtain the above qualities, several designs exist including monolithic and microkernel. In a monolithic OS, there’s a division between applications running in user space vs the operating system’s core services (e.g. file systems, memory, scheduling). Taking this division a step further is microkernel design, separating the core services from the kernel, the core services all running in user space. There are trade offs between each approach. Monolithic operating systems improve performance, reducing the number of system calls between user and privileged mode, a trade off that microkernel operating systems sacrifice. However, microkernel operating systems offer greater extensibilty, allowoing applications to select which OS core services cater to their needs.
Introduction
Summary
Will study structure of OS, whatever that means. To this end, we’ll learn about SPIN and Exokernel approaches, two terms I’m unfamiliar with, and then a micro kernel)
Quiz: OS System Services
Summary
I got most of the services, apart from inter process communication (IPC) and thread scheduling, I named the others including access to I/O devices, access to network, memory management (protection, sharing, demand paging)
OS Structure
Summary
Structure determines how OS serves applications and the underlying hardware
Goals of OS Structure
Summary
There are six goals of an OS: protection (users themselves and between users, and of course the OS), performance (the time taken for OS to carry out its service), Flexibility (not one size fits all and should be able to adapt to different applications), Scalability (essentially if hardware improves, so should the speed of the operating system), Agility (how quickly can the OS respond to changing environment), responsiveness (does OS react to events, liken I/O, quickly)
Commercial OS
Summary
Apparently I’ll learn that somehow, system designers can have their cake and eat it too. That is, they do can achieve both performance without really sacrificing protection and flexibility. How? Who knows, though I should find out soon
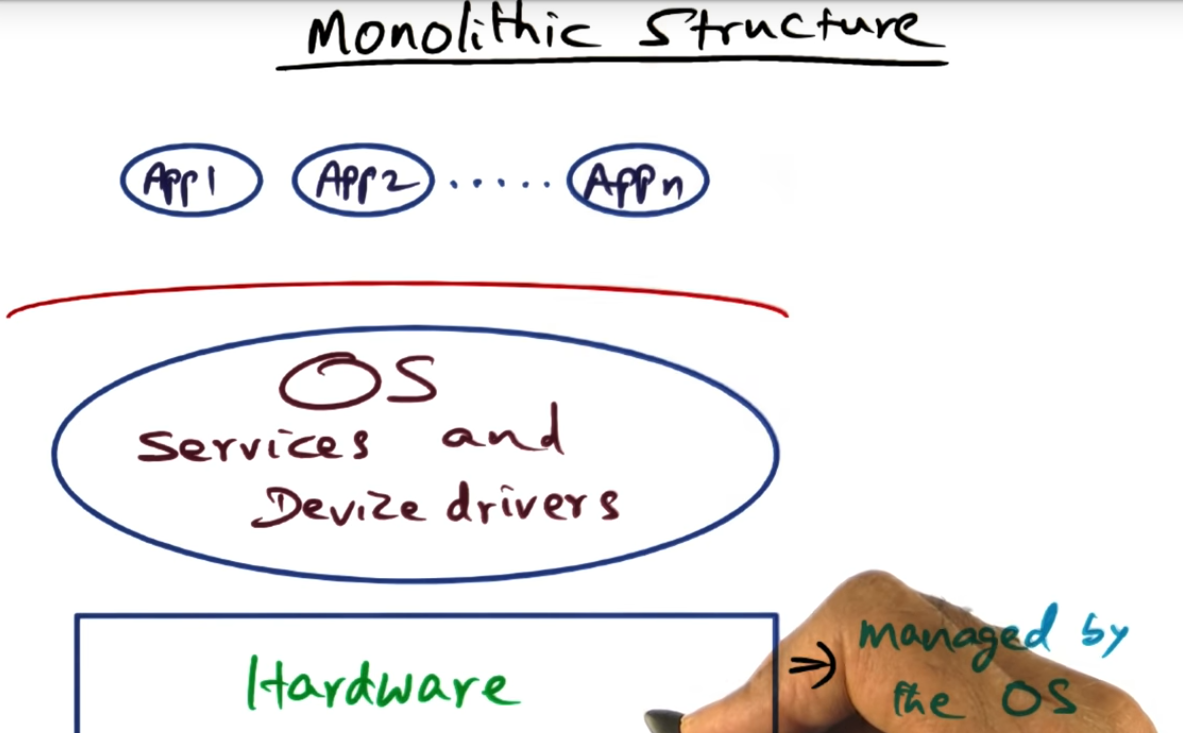
Monolithic Structure
Summary
Monolithic OS – division between applications and OS core services (e.g. file system, memory addressing, scheduling)
Why do we call it a monolithic structure? Because the big blob (see photo) contains all the services (e.g. file system, network access, memory management, scheduling) offered by the operating system
DOSlike Structure
Summary
At a glance, the DOS like structure seems indistinguishable from monolithic. But how is it different?
Quiz DOSlike Structure Pros and Cons
Summary
Seems like DOS allows applications to run in the same space as the OS, so no trapping is necessary: just a procedure call. Trade off here is lack of protection; the OS can get corrupted by a running application.
DOSlike Structure (continued)
Summary
DOSlike structure and its lack of protection is unacceptable for general purpose OS. On the other hand, monolitic structure reduces performance, while offering protection. But we need to also consider how we can customize and tailor needs of different applications — via customization
Opportunities for customization
Summary
Learned a little more about why customization might be important. I thought that page fault handling should be the same for every process but there’s a missed opportunity here. Since the OS sort of bets on processes not requiring the entire address space, this bet might be expensive if the page fault handler (along with the eviction algorithm) runs unnecessarily. SO perhaps OS can learn more about the process and inform the cache replacement policy
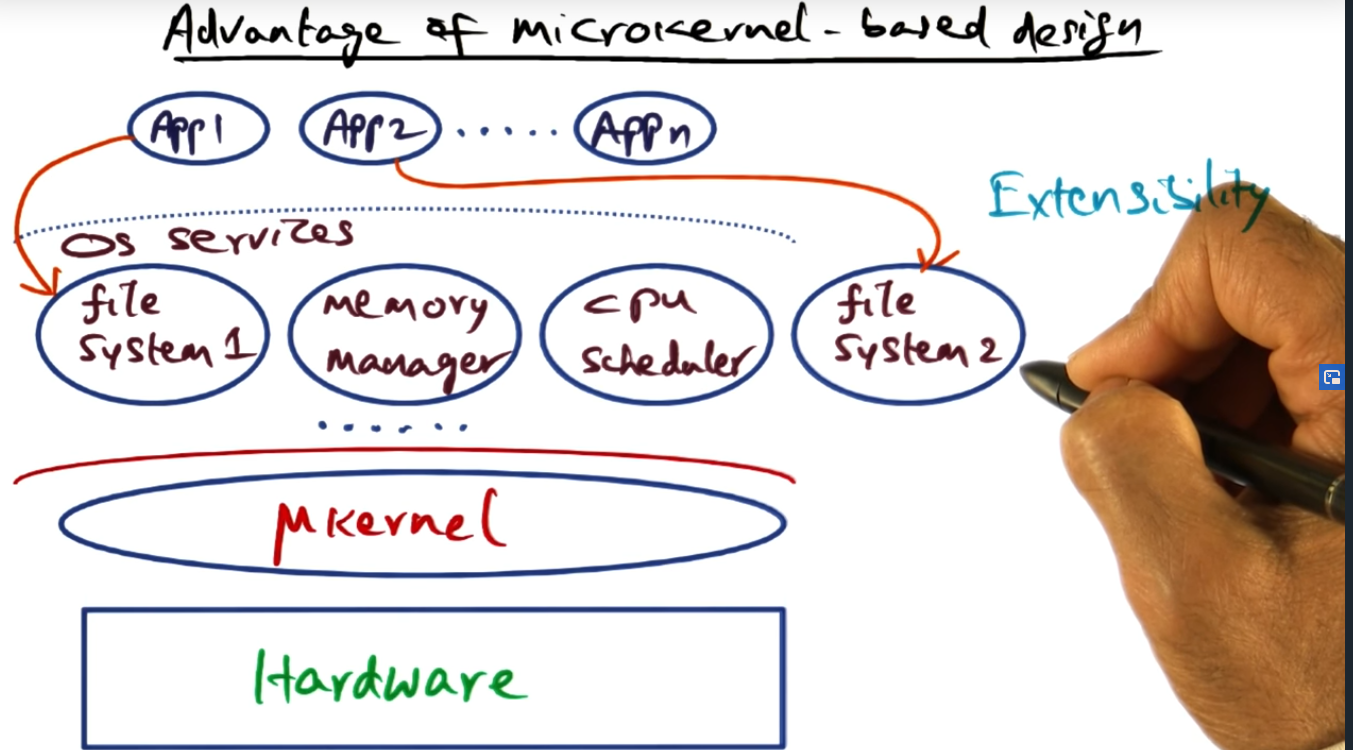
Microkernel based OS Structure
Summary
Microkernel OS – OS services run in user mode too, indistinguishable from user space apps.
Why the hell do we want to overcomplicate the OS design by introducing a microkernel based OS structure? What’s the gain here? Extensibility! Previously, application 1 and application 2 would access the file system or the memory manager or the scheduler. There’s lack of extensibility here. Also, each of those servers (e.g. file system, memory management, cpu scheduler) also run in user space and will still require some sort of IPC to talk to one another, requiring the servers to talk to the micro kernel via system calls. I’ll soon find out but I think this is expensive; that is, we are sacrificing performance, I think. Will find out shortly in next lesson
Downside to the Mikrokernel
Summary
Biggest down side with microkernel approach is potential performance hit. For application to talk to file system (or other servers), a lot of IPC is needed. Data flowing between services require IPC calls in order to Marshall data in and out between applications and servers, and between servers as well
Why performance loss
Summary
Memory locality changes since we need to context switch, dramatically impeding performance. Same goes with copying data between user space and system space. This strategy is unlike monolithic, which the servers can share data easily with one another, although a little more inflexible.
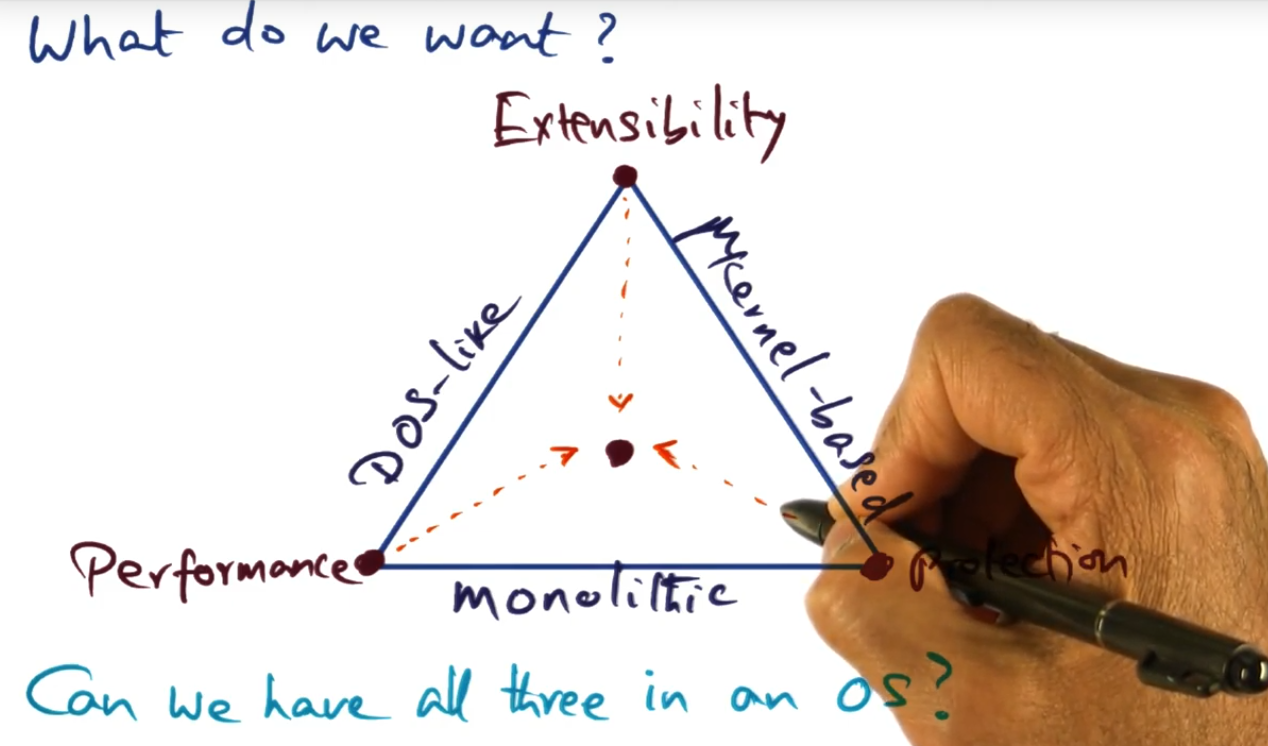
What do we want?
Summary
Trade off between performance, extensibility and protection
Is it possible to get the OS to exhibit all three desirable characteristics: performance, extensibility, and protection — at the same time? Apparently, there is, but I’ll have to wait until the next module
How can the OS make use of a larger, slower device to transparently provide the illusion of a large virtual address space?
Overview
Why try and create a large virtual address space, a virtual address space that is larger than the physical amount of address memory installed on the system? Well, the illusion of a larger virtual address space serves as a useful abstraction for application developers: they just request more memory and simply get it — thanks to the operating system.
Arpaci-Dusseau and Arpaci-Dusseau 2018) – Swap Space
To this end, the OS creates a memory hierarchy. At the top sits the fastest cache (L1 or L2 or L3) and at the bottom sits hard disks (as much as 10,000 slower). And the speed of the cache is inversely proportional to the cost. That is, fast cache is expensive and slow cache is cheap.
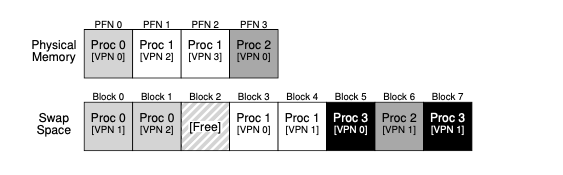
Essentially, the OS reserves portions of the disk as swap, the location in which memory is paged in (i.e. from disk to memory) and out of (from memory to disk). How does the OS determine which pages currently live in memory and which pages live on disk? By looking at the page table entry metadata. More specifically, if the present bit is set then the physical frame lives in memory. Otherwise, it lives on disk.
In the scenario when the page lives on disk, the page handler must get invoked. With the present bit set as 0, the page handler will find the memory living in swap (the address is also stored in the metadata of the page table entry), page the memory into either a physical frame (that was available or freed up by the page replacement policy), set the present bit equal to 1, and finally re-run the instruction that generated the page fault (i.e. memory access when present bit set to 0).
21.1 Swap Space
Summary
The swap space is orders of magnitude larger than physical memory, allowing OS to prevent a large amount of memory to the process and program developers
21.2 The Present Bit
Summary
The present bit is a flag that lets the translate lookaside buffer (TLB), hardware or OS software based, whether the physical frame number itself lives in memory or whether it has been swapped out to disk. If the bit/flag is set to 0, then we must invoke the pagefault handler. Also, the TLB locates the page table based off of the page table register but this rises another question for me: who’s responsibility it is to set the page table register. Probably the OS since the OS is responsible for this per process page table. The OS is a beast!
21.3 The Page Fault
Summary
The TLB checks the PTE and if the PTE’s present bit is set to 0, the page fault handler runs. The page fault handler will check the PTE’s metadata for the location / index of where the page table entry exists on disk (or whatever underlying swap mechanism). Then, the page fault handler will rerun the process and the TLB (hardware or software) will then update its cache. During this page fault workflow, the process is put into a blocked state so other processes can run: concurrency for the win!
21.4 What if Memory is Full
Summary
Need to invoke the page replacement policy (like an LRU)
21.5 Page Fault Control Flow
Summary
When a page fault occurs, the hardware (TLB) and software (OS) must carry out a sequence of actions, depending on the scenario. Focusing on the OS, if a page fault occurs, then the OS must fetch a new physical address, populate the page frame with the right contents, update the PTE, setting the valid bit equal to 1, update the PTE’s page frame number, then finally retry the instruction.
21.6 When replacements really occur
Summary
To optimize the address space and ensure there are always pages available, the swap (or page) daemon runs in the background, freeing up memory for running processes and for the OS.
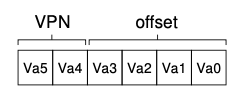
In my other blog post on memory segmentation, I talked about diving the process’s virtual address space into segments: code, heap, stack. Memory segmentation is just one approach to memory virtualization and another approach is paging. Whereas segmentation divides the address space into segments, paging chops up the space into fixed-sized pieces.
Each piece is divided into a virtual private number (VPN) and the offset; the number of bits that make up the offset is determined by the size of the page itself and the number of pages dictate the number of bits of the virtual private number.
To support the translation between virtual address to physical address, we need a page table, a per process data structure that maps the virtual address to the physical frame number (PFN).