Today marks my last day at Amazon Web Services. The last 5 years have flown by. Typically, when I share the news with my colleagues or friends or family, their response is almost always “Where are you heading next?”.
Having a job lined up is the logical, rational and responsible thing to do before making a career transition. A plan is not only the safe thing to do, but probably even the right thing to do, especially if you have a family you need to financially support. And up until recently, I started really doubting myself, questioning my decision to leave a career behind without a bullet-proof plan.
But then, I start to reflect on the last 10 years and all of the leaps of faith I took. In retrospect, many of those past decisions made no sense whatsoever.
At least not at that time.
Seven years ago, I left my position as a director of technology at Fox and with nothing lined up, reduced my belongings to a single suit case, moving to London for a girl I had only briefly met for 2 hours while volunteering at an orphanage in Vietnam. When I booked my flight from Los Angeles to London, almost everyone was like, “Matt — you just met her. This makes no sense.”
They were right. It made no sense.
Around the same time, another leap of faith: confessing to my family and friends that I was living a double life and subsequently checking myself into rehab and therapy. Many could not fathom why I was asking for help since issues, especially around addiction, was something our family didn’t talk about. Shame and guilt was something we kept ourselves, something one battles alone, in isolation.
Again, my decision made no sense.
But now, looking back, those decisions were a no brainer. That relationship I took a shot on blossomed into a beautiful marriage. And attending therapy every week for the past 5 years quite literally saved my life from imploding into total chaos. These decisions , making no sense at the time, were made out of pure instinct.
But somehow, they make total sense now.
Because it’s always easy to connect the dots looking backwards — never forwards.
So here I am, right now, my instinct nudging me to take yet another leap of faith. It’s as if I have this magic crystal ball, showing me loud and clear what my path is: a reimagined life centered around family.
How is this all going to pan out?
No clue.
But it’ll probably all make sense 5 years from now.
You launched your service and rapidly onboarding customers. You’re moving fast, repeatedly deploying one new feature after another. But with the uptick in releases, bugs are creeping in and you’re finding yourself having to troubleshoot, rollback, squash bugs, and then redeploy changes. Moving fast but breaking things. What can you do to quickly detect issues — before your customers report them?
Canaries.
In this post, you’ll learn about the concept of canaries, example code, best practices, and other considerations including both maintenance and financial implications with running them.
Back in early 1900s, canaries were used by miners for detecting carbon monoxide and other dangerous gases. Miners would bring their canaries down with them to the coalmine and when their canary stopped chirping, it was time for the everyone to immediately evacuate.
In the context of computing systems, canaries perform end-to-end testing, aiming to exercise the entire software stack of your application: they behave like your end-users, emulating customer behavior. Canaries are just pieces of software that are always running and constantly monitoring the state of your system; they emit metrics into your monitoring system (more discussion on monitoring in a separate post), which then triggers an alarm when some defined threshold breaches.
What do canaries offer?
Canaries answer the question: “Is my service running?” More sophisticated canaries can offer a deeper look into your service. Instead of canaries just emitting a binary 1 or 0 — up or down — they can be designed such that they emit more meaningful metrics that measure latency from the client’s perspective.
First steps with building your canary
If you don’t have any canaries running that monitor your system, you don’t necessarily have to start with rolling your own. Your first canary can require little to no code. One way to gain immediate visibility into your system would be to use synthetic monitoring services such as BetterUptime or PingDom or StatusCake. These services offer a web interface, allowing you to configure HTTP(s) endpoints that their canaries will periodically poll. When their systems detect an issue (e.g. TCP connection failing, bad HTTP response), they can send you email or text notifications.
Or if your systems are deployed in Amazon Web Services, you can write Python or Node scripts that integrate with CloudWatch (click here for Amazon CloudWatch documentation).
But if you are interested in developing your own custom canaries that do more than a simple probe, read on.
Where to begin
Remember, canaries should behave just like real customers. Your customer might be a real human being or another piece of software. Regardless of the type of customer, you’ll want to start simple.
Similar to the managed services describe above, your first canary should start with emitting a simple metric into your monitoring system, indicating whether the endpoint is up or down. For example, if you have a web service, perform a vanilla HTTP GET. When successful, the canary will emit http_get_homepage_success=1 and under failure, http_get_homepage_success=0.
Example canary – monitoring cache layer
Imagine you have a simple key/value store system that serves as a caching layer. To monitor this layer, every minute our canary will: 1) perform a write 2) perform a read 3) validate the response.
[code lang=”python”]
while(True):
successful_run = False
try: put_response = cache_put(‘foo’, ‘bar’)
write_successful = put_response == ‘OK’
Publish_metric(‘cache_engine_successful_write’, write_successful)
value = cache_get(‘foo’) successful_read = value = ‘bar’ publish_metric(‘cache_engine_successful_read’, is_successful_read)
canary_successful_run = True
Except as error:
log_exception(“Canary failed due to error: %s” % error)
Finally:
Publish_metric(‘cache_engine_canary_successful_run’, int(successful_run))
sleep_for_in_seconds = 60 sleep(sleep_for_in_seconds)
[/code]
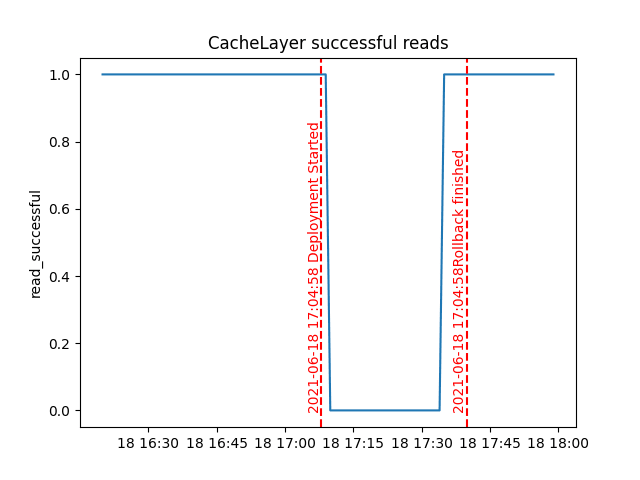
Cache Engine failure during deployment
With this canary in place emitting metrics, we might then choose to integrate the canary with our code deployment pipeline. In the example below, I triggered a code deployment (riddled with bugs) and the canary detected an issue, triggering an automatic rollback:
Best Practices
The above code example was very unsophisticated and you’ll want to keep the following best practices in mind:
The canaries should NOT interfere with real user experience. Although a good canary should test different behaviors/states of your system, they should in no way interfere with the real user experience. That is, their side effects should be self contained.
They should always be on, always running, and should be testing at a regular intervals. Ideally, the canary runs frequently (e.g. every 15 seconds, every 1 minute).
The alarms that you create when your canary reports an issue should only trigger off more than one datapoint. If your alarms fire off on a single data point, you increase the likelihood of false alarms, engaging your service teams unnecessarily.
Integrate the canary into your continuous integration/continuous deployment pipeline. Essentially, the deployment system should monitor the metrics that the canary emits and if an error is detected for more then N minutes, the deployment should automatically roll back (more of safety of automated rollbacks in a separate post)
When rolling your own canary, do more than just inspect the HTTP headers. Success criteria should be more than verifying that the HTTP status code is a 200 OK. If your web services returns payload in the form of JSON, analyze the payload and verify that it’s both syntactically and semantically correct.
Cost of canaries
Of course, canaries are not free. Regardless of whether or not you rely on a third party service or roll your own, you’ll need to be aware of the maintenance and financial costs.
Maintenance
A canary is just another piece of software. The underlying implementation may be just few bash scripts cobbled together or full blown client application. In either case, you need to maintain them just like any other code package.
Financial Costs
How often is the canary running? How many instances of the canary are running? Are they geographically distributed to test from different locations? These are some of the questions that you must ask since they impact the cost of running them.
Beyond canaries
When building systems, you want a canary that behaves like your customer, one that allows you to quickly detect issues as soon as your service(s) chokes. If you are vending an API, then your canary should exercise the different URIs. If you testing the front end, then your canary can be programmed mimic a customer using a browser using libraries such as selenium.
Canaries are a great place to start if you are just launching a service. But there’s a lot more work required to create an operationally robust service. You’ll want to inject failures into your system. You’ll want a crystal clear understanding of how your system should behave when its dependencies fail. These are some of the topics that I’ll cover in the next series of blog posts.
Let’s Connect
Let’s connect and talk more about software and devops. Follow me on Twitter: @memattchung
I sometimes witness new engineers (or even seasoned engineers new to the company) submit code reviews that end up sitting idle, gaining zero traction. Often, these code reviews get published but comments never flow in, leaving the developer left scratching their head, wondering why nobody seems to be taking a look. To help avoid this situation, check out the 3 tips below for more effective code reviews.
3 tips for more effective code reviews
Try out the three tips for more effective code reviews. In short, you should:
Assume nobody cares
Strive for bite sized changes
Add a descriptive summary
1. Assume nobody cares
After you hit the publish button, don’t expect other developers to flock to your code review. In fact, it’s safe to assume that nobody cares. I know, that sounds a bit harsh but as Neil Strauss suggests,
“Your challenge is to assume — to count on — the completely apathy of the reader. And from there, make them interested.”
At some point in our careers, we all fall into this trap. We send out a review, one that lacks a clear description (see section below “Add a descriptive summary”) and then the code review would sometimes sits there, patiently waiting for someone to sprinkle comments. Sometimes, those comments never come.
Okay, it’s not that people don’t necessary care. It has more to do with the fact people are busy, with their own tasks and deliverable. They too are writing code that they are trying to ship. So your code review essentially pulls them away from delivering their own work. So, make it as easy as possible for them to review.
One way to do gain their attention is simply by giving them a heads up.
Before publishing your code review, send them an instant message or e-mail, giving them a heads up. Or if you are having a meeting with that person, tell them that you plan on sending out a code review and ask them if they can take a look at the code review. This puts your code review on their radars. And if you don’t see traction in an appropriate (which varies, depending on change and criticality), then follow up with them.
2. Strive for bite sized code reviews
Anything change beyond than 100-200 lines of code requires a significant amount of mental energy (unless the change itself is a trivial updates to comments or formatting). So how can you make it easier for your reviewer?
Aim for small, bite sized code reviews.
In my experience, a good rule of them is submit less than 100 lines of code. What if there’s no way your change can squeeze into double digits? Then consider breaking down the single code review into multiple, smaller sized code reviews and once all those independent code reviews are approved, submit a single code review that merges all those changes in atomically.
And if you still cannot break down a large code review into these lengths and find that it’s unavoidable to submit a large code review, then make sure you schedule a 15-30 minute meeting to discuss your large code review (I’ll create a separate blog post for this).
3. Add a descriptive summary for the change
I’m not suggesting you write a miniature novel when adding a description to your code review. But you’ll definitely need to write something with more substance than a one-liner: “Adds new module”. Rob Pike put’s it succinctly and his criteria for a good description includes “What, why, and background”.
In addition to adding this criteria, be sure to describe how you tested your code — or, better yet, ship your code review with unit tests. Brownie points if you explicitly call out what is out of scope. Limiting your scope reduces the possibility of unnecessary back-and-forth comments for a change that falls outside your scope.
Finally, if you want some stricter guidelines on how to write a good commit message, you might want to check out Kabir Nazir’s blog post on “How to write good commit messages.”
Summary
If you are having trouble with getting traction on your code reviews, try the above tips. Remember, it’s on you, the submitter of the code review, to make it as easy as possible for your reviews to leave comments (and approve).
Let’s chat more and connect! Follow me on Twitter: @memattchung
Since the pandemic hit the states back in February this year, I’ve been working remotely from home (such a blessing and a serious privilege). Working from home underscores the importance of time management, especially for someone like me who can either deeply fall into work mode for hours and hours (never breaking eyes away from screen) or scroll mindlessly on websites like Hacker News or Reddit. The former melts my mental health and the latter kills my productivity.
So to avoid either scenario — working too long or not working at all — I employ a Pomodoro technique1. The pomorodoro technique, which I picked up years ago when taking Learning How to Learn Course on Coursera, was invented in the early 1990s by Franscesco Cirillo. The basic premise is this: you set a timer for 25 minutes and work deeply for those 25 minutes. Once the alarm sounds, you break. The idea is that the technique improves your focus and promotes giving your brain some time off to relax.
So how do I use the Pomorodo technique in practice? What does it look like?
I use a kitchen timer, the TIMER YS-390 to be specific. This model hits all of my own personal requirements. The device has a dual count timer. I set the top timer to 50 minutes (my personal period of deep focus) and the bottom for 10 minutes; the 10 minutes is my grace period, allowing me to ease into my work (basically I cut myself some slack here). In addition to the dual timers, the alarm’s volume can be adjusted: no sound, low, high. I typically set the volume knob on low as to not frighten my daughter awake when she’s sleeping (my dentist’s rule: never wake a sleeping baby). And finally, the third feature I love is the physical cue. When either of the timers hit zero, the little button begins flashing red like a cop car. This makes it difficult to ignore and I find it really forces my eyes to break away from the screen.
So what happens when the timer sounds the alarm? I start by silencing it, hitting the silicone start/stop button, stepping away from the computer and if I’m lucky enough, take a 5-10 minute break with either my baby daughter (who is growing up way too fast) or wife or dogs (or if I’m really lucky, all four of them). This break, is also no exception, but instead of using my TIMER YS-390, I set a countdown alarm on my G-Shock watch.
Do I always break at the very moment the alarm sounds?
No. Sometimes I find that I’m really in the flow (for work or for graduate school or for writing on this blog) so what I do instead is quickly press the bottom right button, resetting the 10 minute timer. This allows me another grace period of deep work. It’s okay to not be so rigid and cut yourself some slack.