
This lesson introduces network file system (NFS) and presents the problems with it, bottlenecks including limited cache and expensive input/output (I/O) operations. These problems motivate the need for a distributed file system, in which there is no longer a centralized server. Instead, there are multiple clients and servers that play various roles including serving data
Quiz
Key Words: computer science history
Sun built the first ever network file system back in 1985
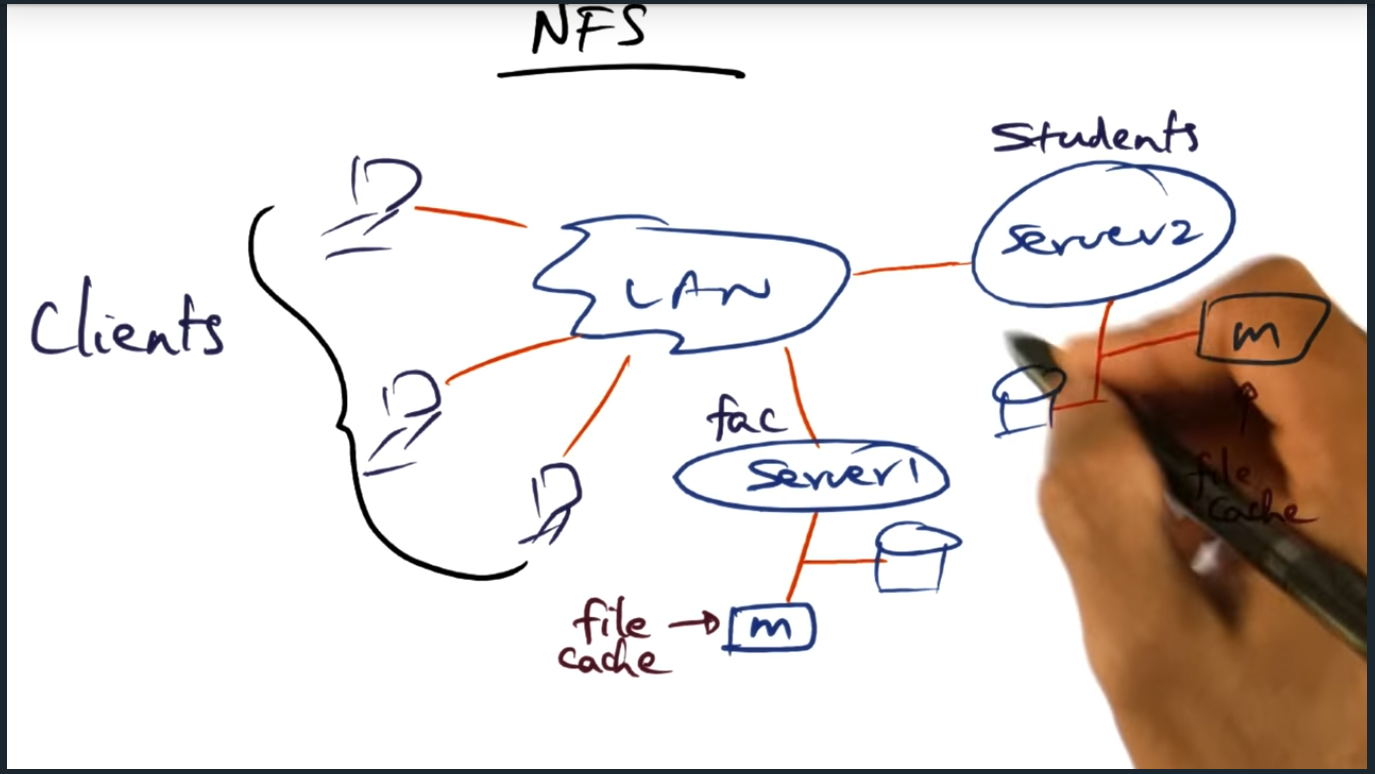
NFS (network file system)
Key Words: NFS, cache, metadata, distributed file system
A single server that stores entire network file system will bottle neck for several reasons, including limited cache (due to memory), expensive I/O operations (for retrieving file metadata). So the main question is this: can we somehow build a distributed file system?
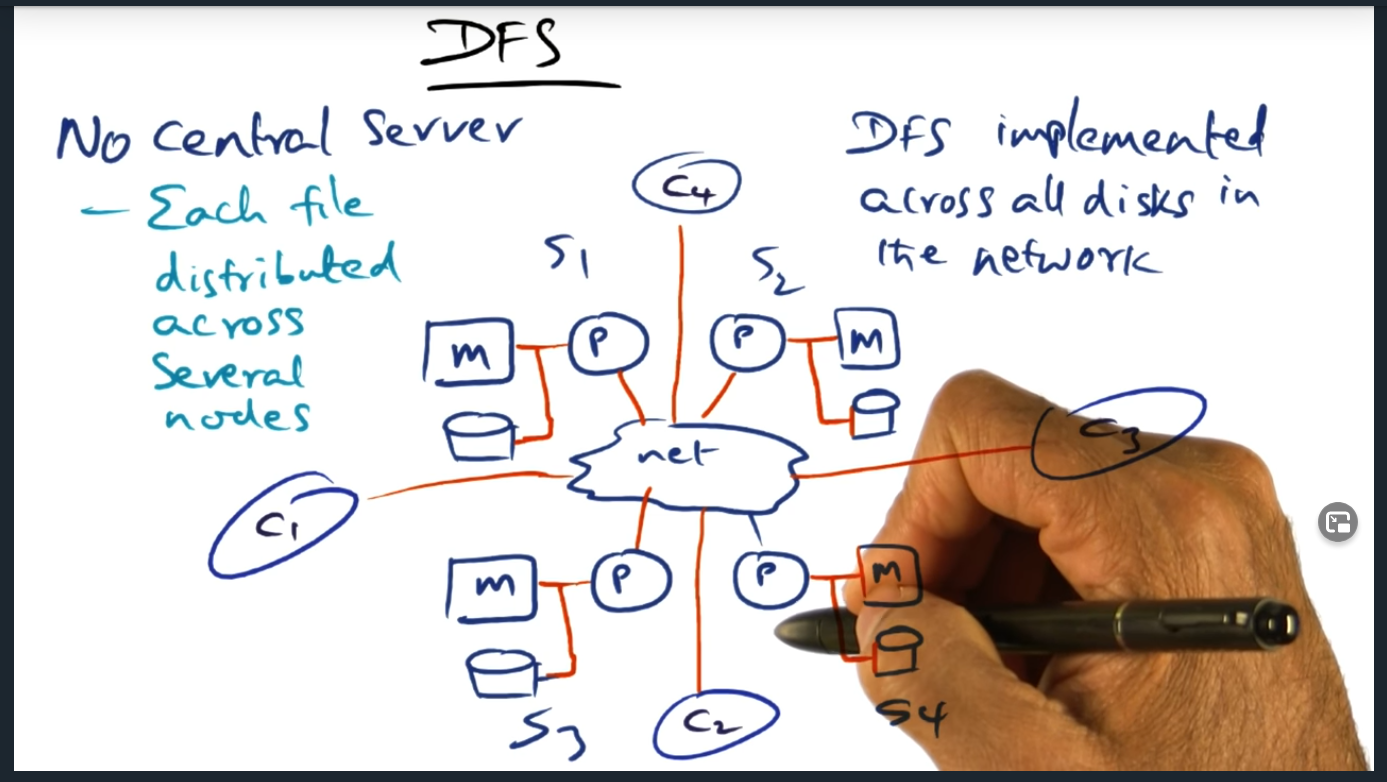
DFS (distributed file system)
Key Words: Distributed file server
The key idea here is that there is no longer a centralized server. Moreover, each client (and server) can play the role of serving data, caching data, and managing files
Lesson Outline
Key Words: cooperative caching, caching, cache
We want to cluster the memory of all the nodes for cooperative caching and avoid accessing disk (unless absolutely necessary)
Preliminaries (Striping a file to multiple disks)
Key Words: Raid, ECC, stripe
Key idea is to write files across multiple disks. By adding more disks, we increase the probability of failure (remember computing those failures from high performance computing architecture?) so we introduce a ECC (error correcting) disk to handle failures. The downside of striping is that it’s expensive, not just in cost (per disk) but expensive in terms of overhead for small files (since a small file needs to be striped across multiple disks)
Preliminaries
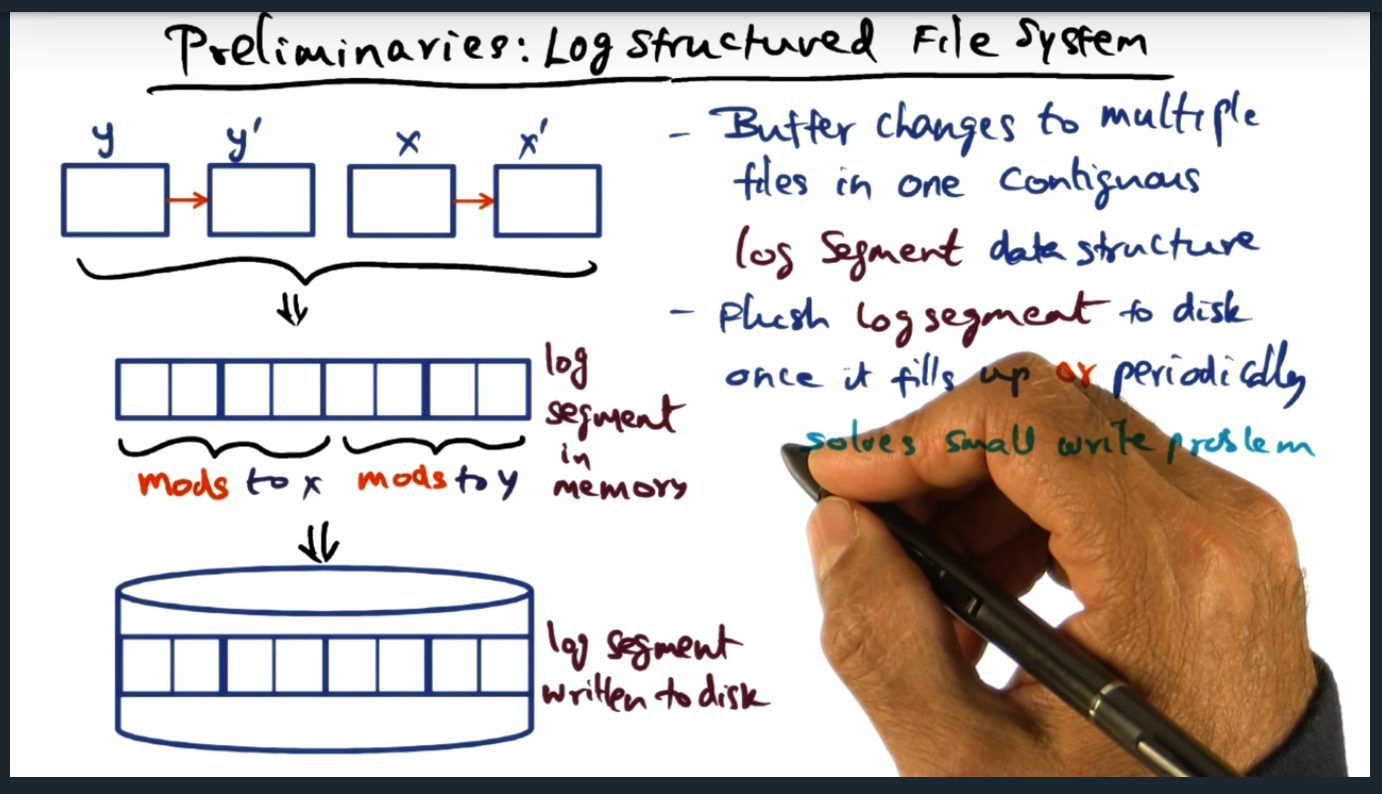
Key Words: Log structured file system, log segment data structure, journaling file system
In a log structured file system, the file system will store changes to a log segment data structure, the file system periodically flushing the changes to disk. Now, anytime a read happens, the file is constructed and computed based off of the delta (i.e. logs). The main problem this all solves is the small file problem (the issue with striping across multiple disks using raid). With log structure, we now can stripe the log segment, reducing the penalty of having small files
Preliminaries Software (RAID)
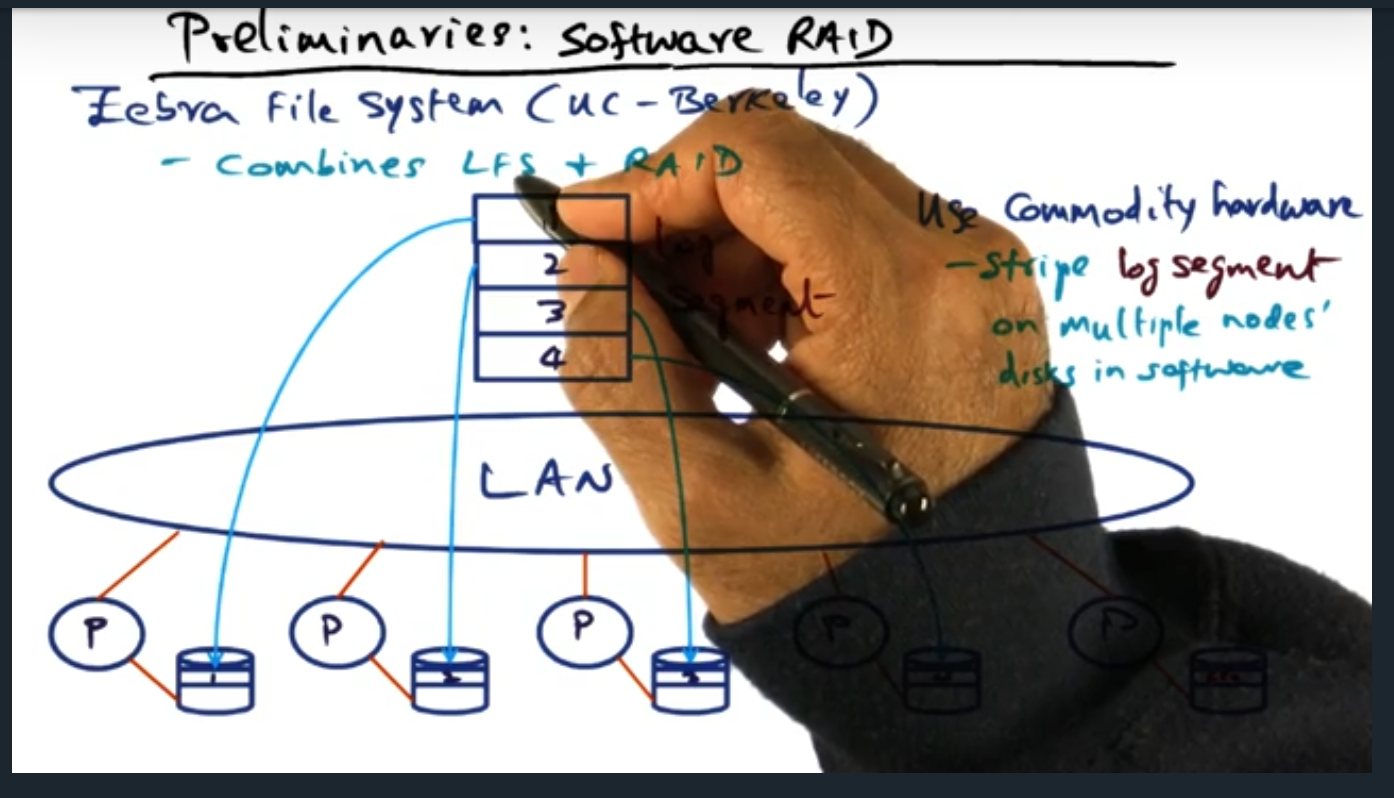
Key Words: zebra file system, log file structure
The zebra file system combines two techniques for handling failures: log file structure (for solving the small file problem) and software raid. Essentially, error correction lives on a separate drive
Putting them all together plus more

Key Words: distributed file system, zebra file system
The XFS file system puts all of this together, standing on top of the shoulders who built Zebra and built cooperating caching. XFS also adds new technology that will be discussed in later videos
Dynamic Management
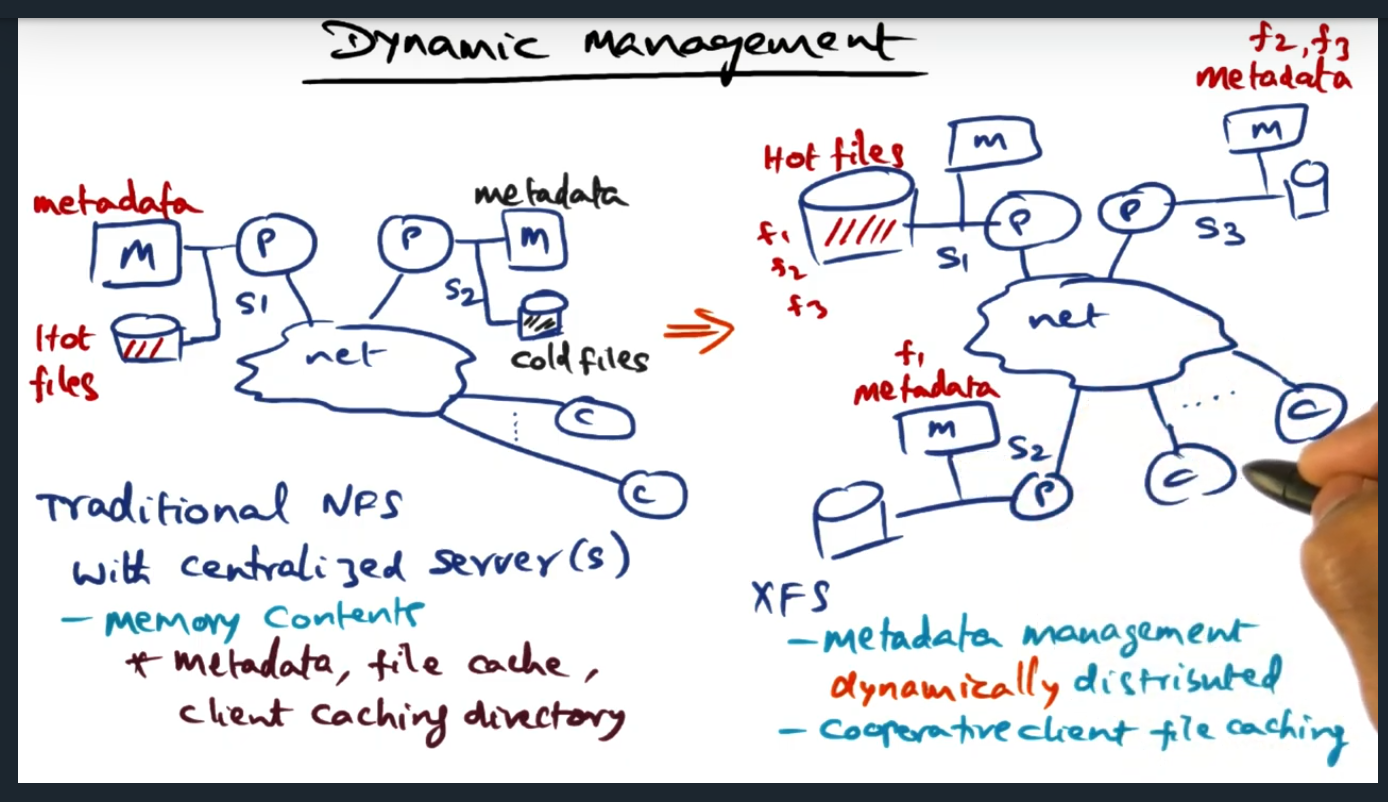
Key Words: Hot spot, metadata, metadata management
In a traditional NFS server, data blocks reside on disk and memory includes metadata. But in a distributed file system, we’ll extend caching to the client as well
Log Based Striping and Stripe Groups

Key Words: append only data structure, stripe group
Each client maintains its own append only log data structure, the client periodically flushing the contents to the storage nodes. And to prevent reintroducing the small file problem, each log fragment will only be written to a subset of the storage nodes, those subset of nodes called the stripe group
Stripe Group
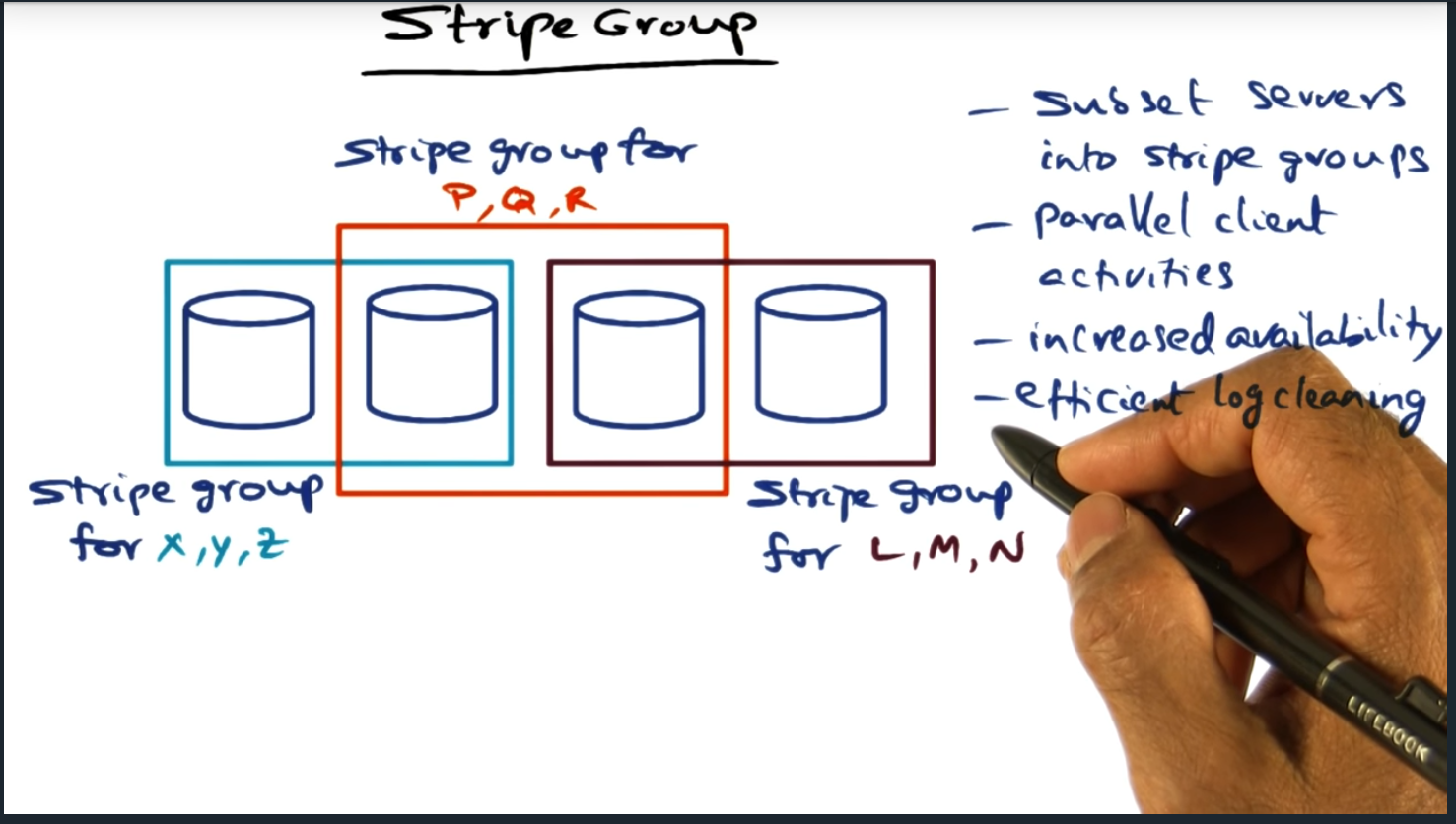
Key Words: log cleaning
By dividing the disks into stripe groups, we promote parallel client activities and increases availability
Cooperating Caching

Key Words: coherence, token, metadata, state
When a client requests to write (to a block), the manager (who maintains state, in the form of metadata, about each client) will cache invalidate the clients and grant the writer a token to write for a limited amount of time
Log Cleaning
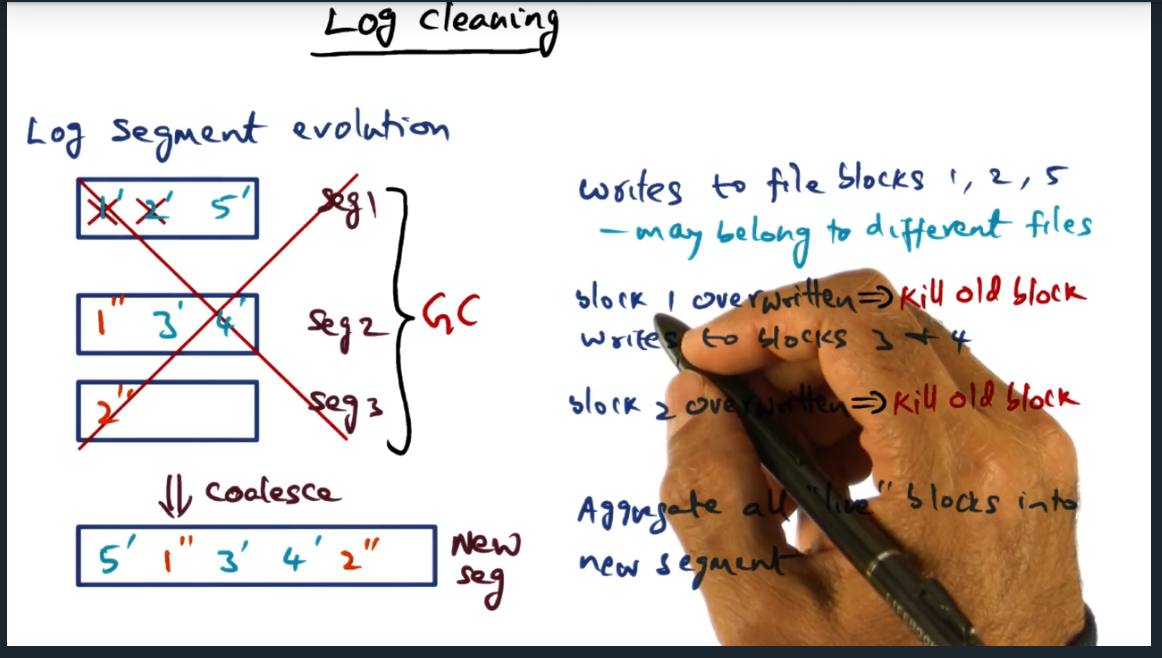
Key Words: prime, coalesce, log cleaning
Periodically, node will coalesce all the log segment differences into a single, new segment and then run a garbage collection to clean up old segments
Unix File System
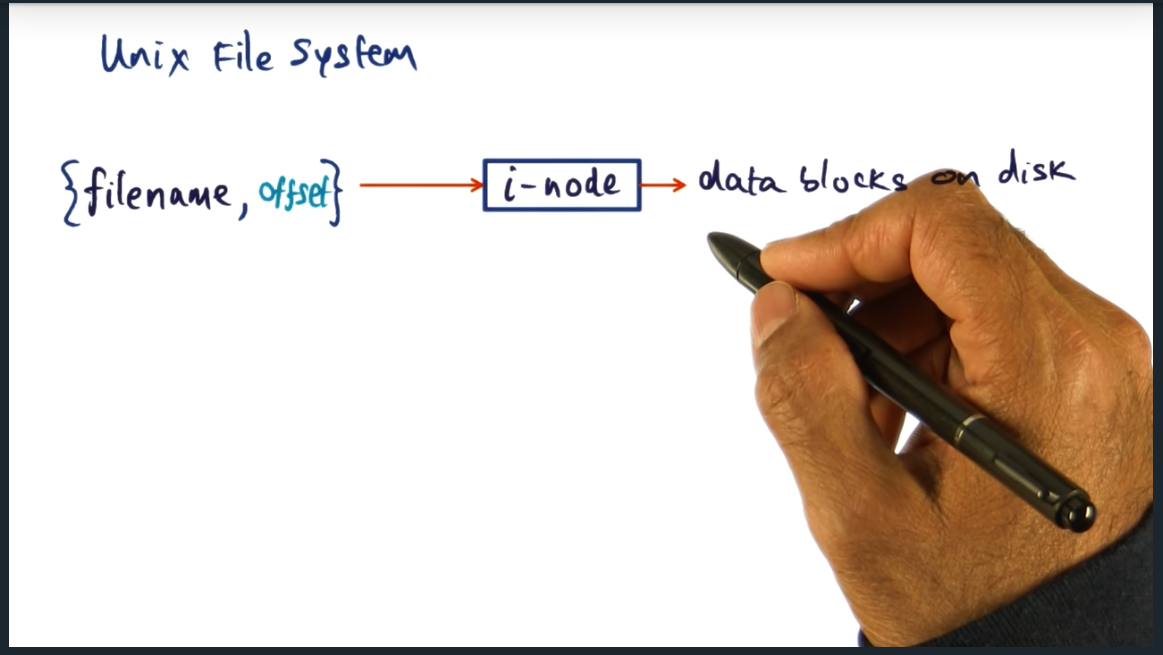
Key Words: inode, mapping
On any unix file system, there are inodes, which map filenames to data blocks on disk
XFS Data Structures
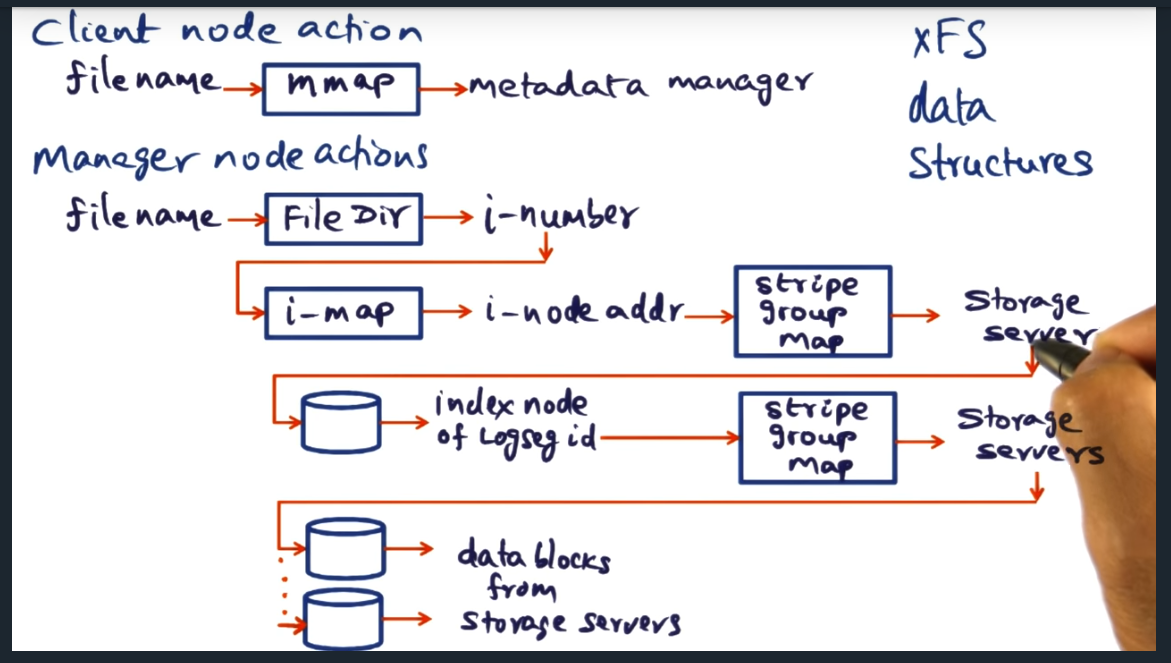
Key Words: directory, map
Manager node maintains data structures to map a filename to the actual data blocks from the storage servers. Some data structures include the file directory, and i_map, and stripe group map
Client Reading a file own cache
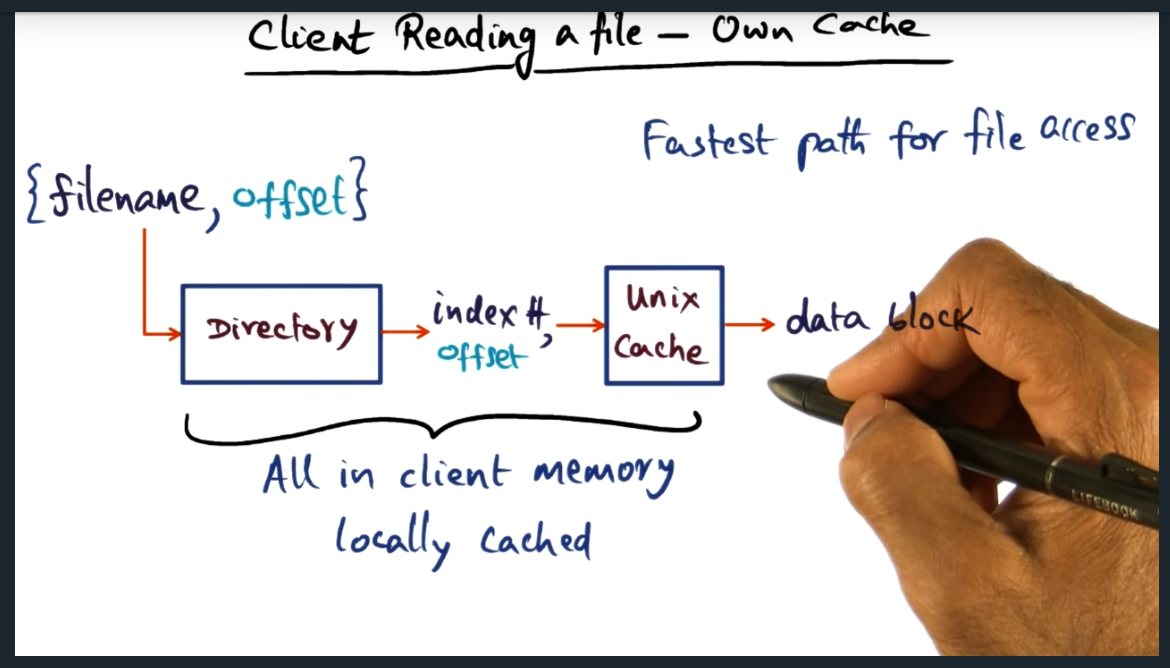
Key Words: Pathological
There are three scenarios for client reading a file. The first (i.e. best case) is when the data blocks sit in the unix cache of the host itself. The second scenario is the client querying the manager, and the manager signals another peer to send its cache (instead of retrieving from disk). The worst case is the pathological case (i.e. see previous slide) where we have to go through the entire road map of talking to manager, then looking up metadata for the stripe group, and eventually pulling data from the disk
Client Writing a File
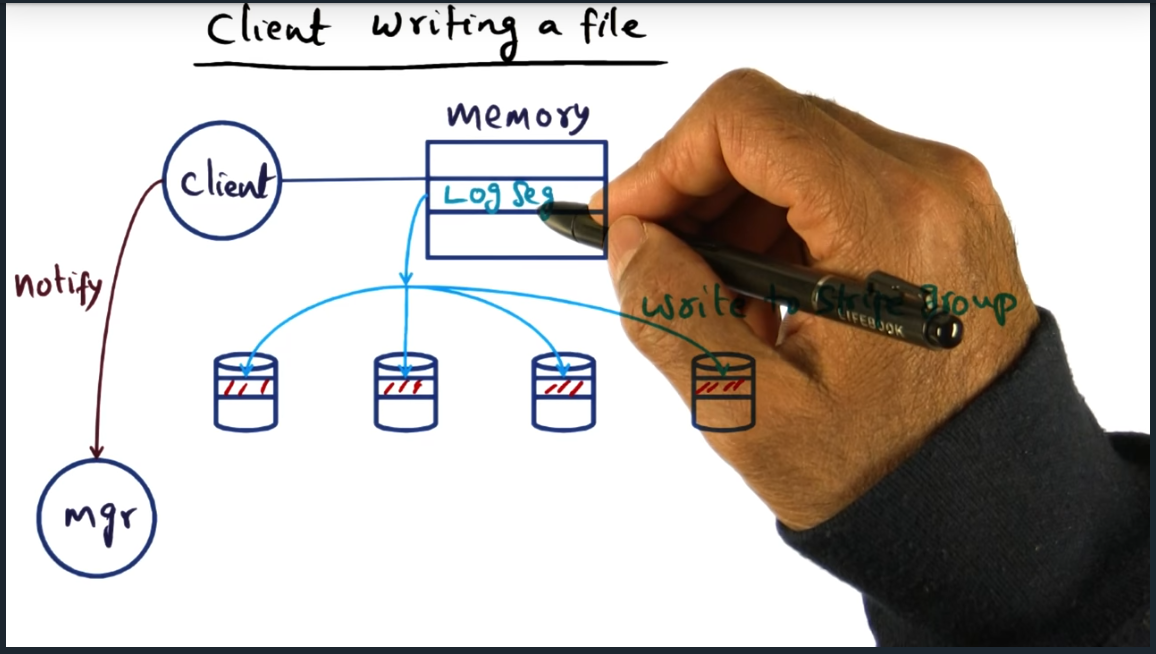
Key Words: distributed log cleaning
When writing, client will send updates to its log segments and then update the manager (so manager has up to date metadata)
Conclusion
Techniques for building file systems can be reused for other distributed systems