Summary and main take away
As system designers, we can make persistence into the virtual memory manager, offering persistence to application developers. However, it’s no easy feat: we need to ensure that the solution performs well. To this end, the virtual machine manager offers an API that allows developer to wrap their code in transactions; underneath the hood, the virtual machine manager uses redo logs that persists the user changes to disk which can defend against failures.
Persistence

Key Words: inode, subsystem, virtual memory management, log sequence
We can bake persistent into the virtual memory manager (VMM) but building an abstraction is not enough. Instead, we need to ensure that the solution is performant and instead of committing each VMM change to disk, we aggregate them into a log sequence (just like the previous approaches in distributed file system) so that 1) we write in a contiguous block
Server Design
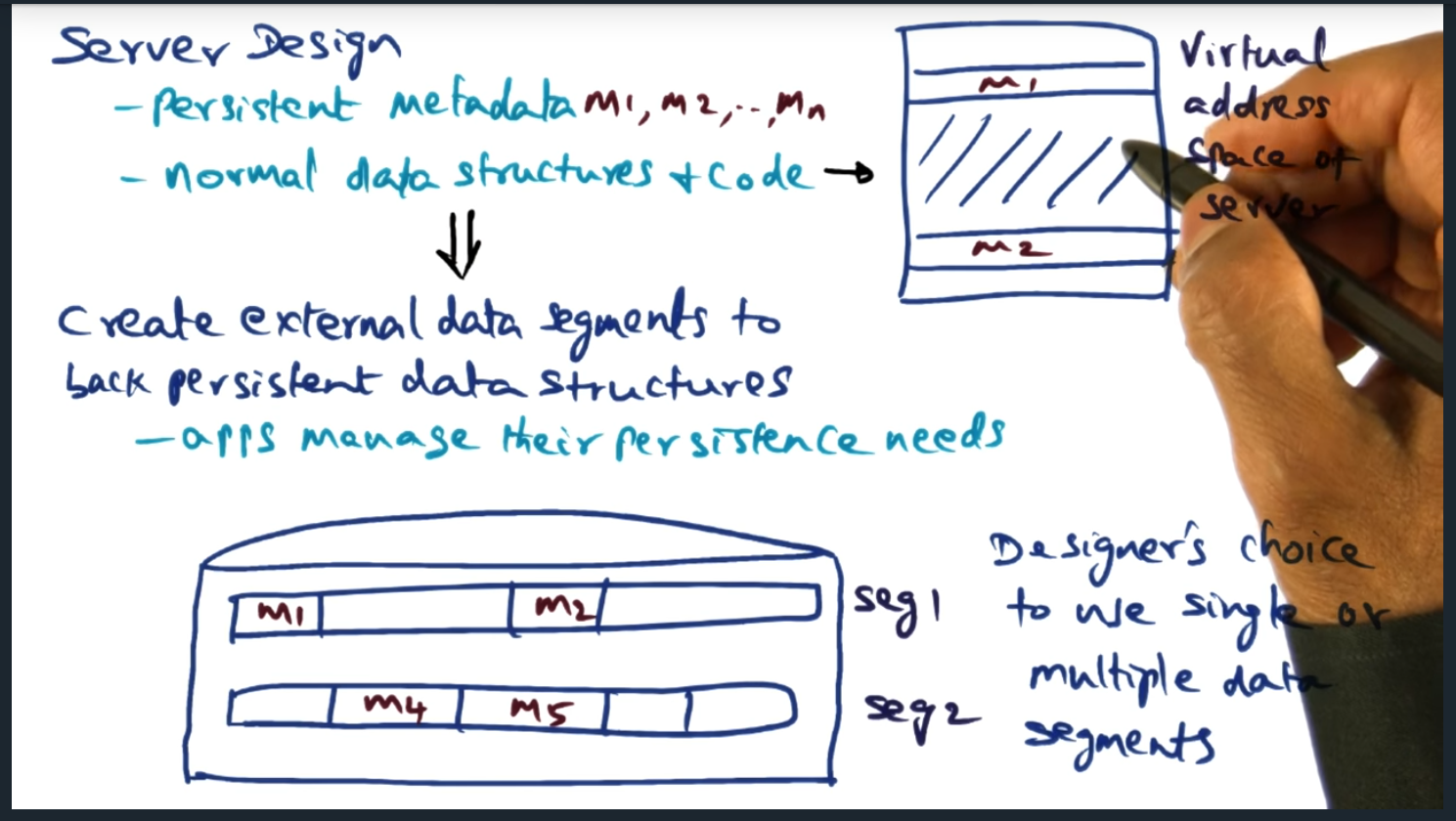
Key Words: inodes, external data segment
The designer of the application gets to decide which virtual addresses will be persisted to external data storage
Server Design (continued)
Key Words: inodes, external data segment
The virtual memory manager offers external data segments, allowing the underlying application to map portions of its virtual address space to segments backed by disk. The model is simple, flexible, and performant. In a nutshell, when the application boots up, the application selects which portions of memory must be persisted, giving the application developer full control
RVM Primitives
Key Words: transaction

There are three main primitives: initialize, map, and unmap. And within the body of the application code, we use transactions: begin transaction, end transaction, abort transaction, and set range. The only non obvious statement is set_range: this tells the RVM runtime the specific range of addresses within a given transaction that will be touched. Meaning, when we perform a map (during initialization), there’s a larger memory range and then we create transactions within that memory range
RVM Primitives (continued)

Key Words: truncation, flush, truncate
Although RVM automatically handles the writing of segments (flushing to disk and truncating log records), application developers can call those procedures explicitly
How the Server uses the primitives
Key Words: critical section, transaction, undo record
When transaction begins, the LRVM creates an undo record: a copy of the range specified, allowing a rollback in the event an abort occurs
How the Server uses the primitives (continued)
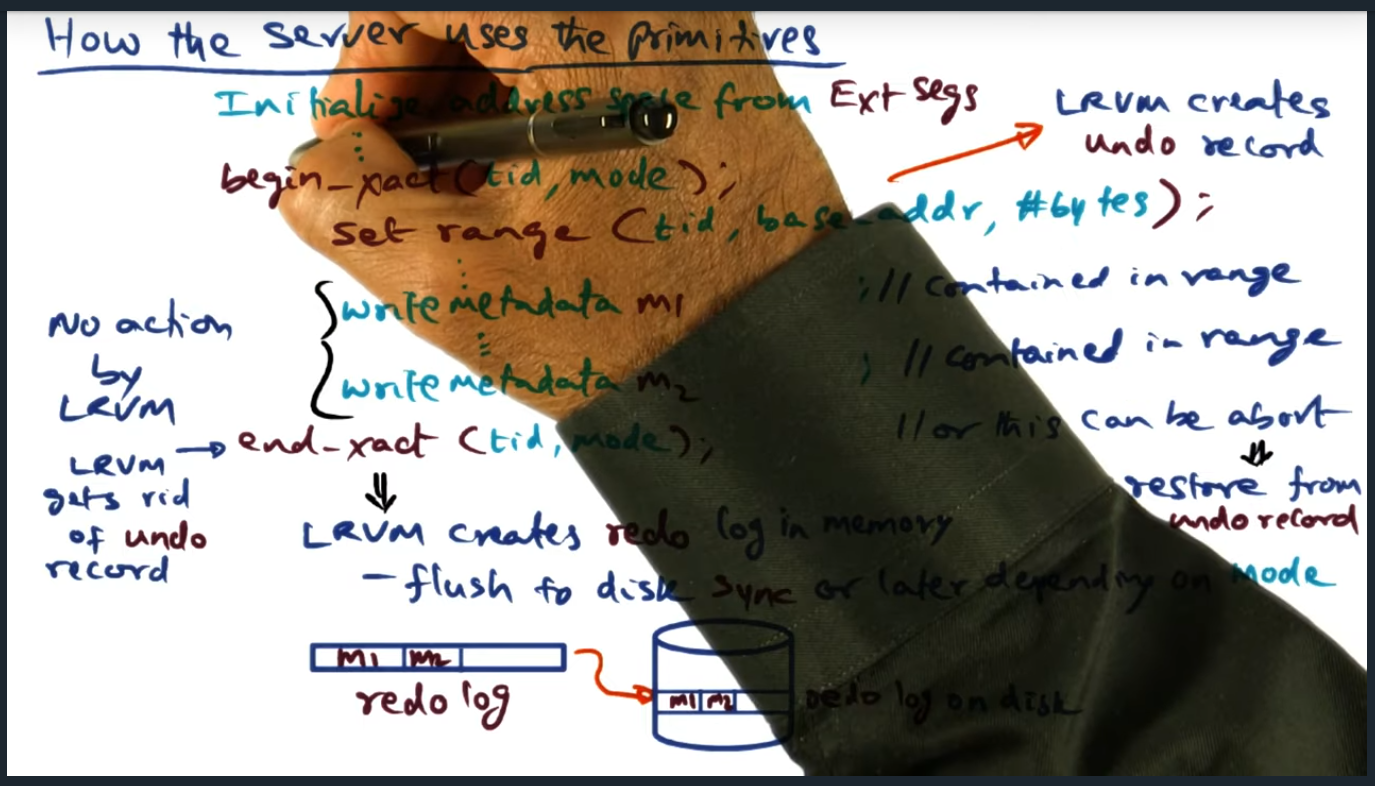
Key Words: undo record, flush, persistence
During end transaction, the in memory redo log will get flushed to disk. However, by passing in a specific mode, developer can explicitly not call flush (i.e. not block) and flush the transaction themselves
Transaction Optimizations

Key Words: window of vulnerability
With no_restore mode in begin transaction, there’s no need to create a in memory copy; similarly, no need to flush immediately with lazy persistence; the trade off here is that there’s an increase window of vulnerability
Implementation

Key Words: forward displacement, transaction, reverse displacement
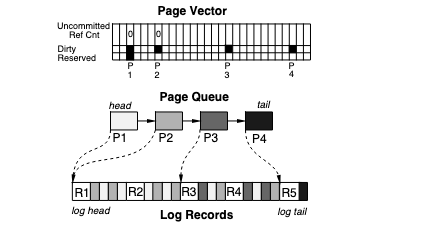
Redo log allows traversal in both directions (reverse for recovery) and only new values are written to the log: this implementation allows good performance
Crash Recovery
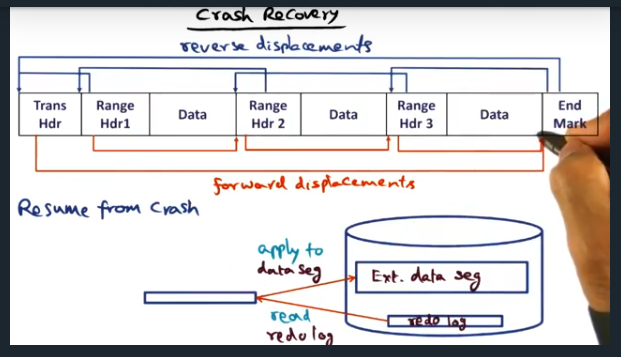
Key Words: crash recovery
In order to recover from a crash, the system traverses the redo log, using the reverse displacement.Then, each range of memory (along with the changes) are applied
Log Truncation
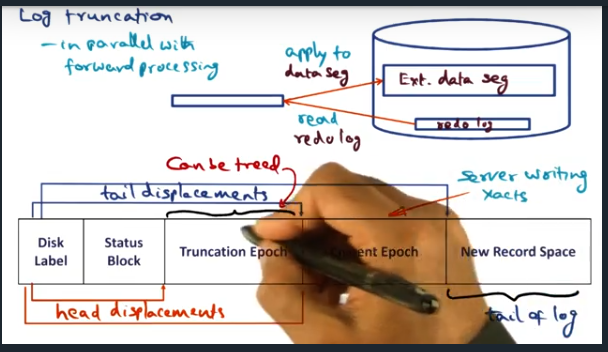
Key Words: log truncation, epoch
Log truncation is probably the most complex part of LRVM. There’s a constant tug and pull between performance and crash recovery. Ensuring that we can recover is a main feature but it adds overhead and complexity since we want the system to make forward progress while recovering. This end, the algorithm breaks up data into epochs