

This is a continuation of me attempting to answer the midterm questions without peeking at the answers. Part 1 covered questions from OS Structures and this post (part 2) covers virtualization and includes questions revolving around memory management in hypervisors and how to test-and-set atomic operations work.
A few useful links I found while trying to answer my own questions:
Virtualization
Question 2d
VM1 is experiencing memory pressure. VM2 has excess memory it is not using. There are balloon drivers installed in both VM1 and VM2. Give the sequence through which the memory ownership moves from VM2 to VM1.
My Guess
- Hypervisor (via a private communication channel) signals VM2’s balloon driver to expand
- VM2 will page out (i.e. from memory to swap if necessary)
- Hypervisor (again, via a private communication channel) signals VM1’s balloon driver to deflate
- VM1 will page in (i.e. from swap to memory if necessary)
- Essentially, balloon driver mechanisms shifts the memory pressure burden from the hypervisor to the guest operating system
Solution
- Hypervisor (Host) contacts balloon driver in VM2 via private channel that exists between itself and the driver and instructs balloon device driver to inflate, which causes balloon driver to request memory from Guest OS running in VM2
- If balloon driver’s memory allocation request exceeds that of Guest OS’s available physical memory, Guest OS swaps to disk unwanted pages from the current memory footprint of all its running processes
- Balloon driver returns the physical memory thus obtained from the guest to the Hypervisor (through the channel available for its communication with the hypervisor), providing more free memory to the Host
- Hypervisor contacts VM1 balloon driver via private channel, passes the freed up physical memory, and instructs balloon driver to deflate which results in the guest VM1 acquiring more physical memory.
- This completes the transfer of ownership for the memory released by VM2 to VM1
Reflection
- I was correct about the private communication channel (hooray)
- No mention of swapping in the solution though (interesting)
- No mention of memory pressure responsibility moving from hypervisor to guest OS
- I forgot to mention that the guest OS’s response includes the pages freed up by the balloon driver during inflation
Question 2e
VM1 has a page fault on vpn2. From the disk, the page is brought into a machine page mpn2. As the page is being brought in from the disk, the hypervisor computes a hash of the page contents. If the hash matches the hash of an already existing machine page mpn1 (belonging to another virtual machine VM2), can the hypervisor free up mpn2 and set up the mapping for vpn2 to mpn1? (Justify your answer)
My Guess
I think that the hypervisor can map VPN2 to MPN1. However, it’s much more nuanced than that. The question refers to the memory sharing technique. The hypervisor actually needs to set the flag on a copy-on-write metadata attribute on the page table entry so that if there are any writes (to VPN1 or VPN2) then the hypervisor will then create a copy of the memory addresses.
Solution
- Even though the hash of mpn2 matches the hash of mpn1, this initial match can only be considered a hint since the content of mpn1 could have changed since its hash was originally computed
- This means we must do a full comparison between mpn1 and mpn2 to ensure they still have the same content
- If the content hashes are still the same, then we modify the mapping for vpn2 to point to mpn1, mark the entry as CoW, and free up mpn2 since it is no longer needed
Reflection
- Need to mention that hypervisor must perform an another hash computation just in case VPN1 had change (if I recall correctly, this hash is computed only once when the page is allocated)
- Call out that mpn2 will be freed up (with the caveat that the MPN1 entry will be marked as copy on write, as I had mentioned)
Question 2f
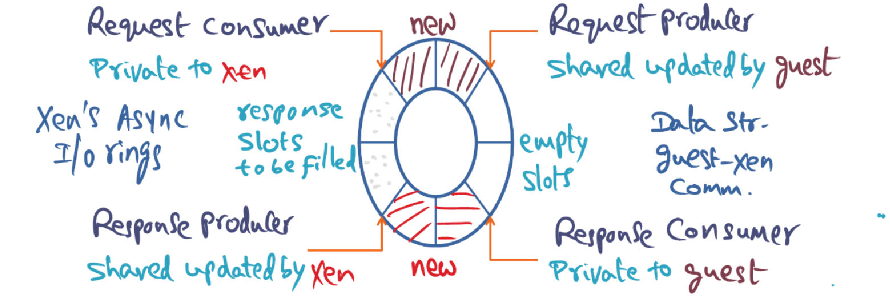
Above pictures shows the I/O ring data structure used in Xen to facilitate communication between the guest OS and Xen. Guest-OS places a request in a free descriptor in the I/O ring using the “Request Producer” pointer.
- Why is this pointer a shared pointer with Xen?
- Why is it not necessary for the guest-OS to get mutual exclusion lock to update this shared pointer?
- Xen is the “Response Producer”. Is it possible for Xen to be in a situation where there are no slots available to put in a response? Justify your answer.
My Guess
1. Why is the pointer a shared pointer with Xen
- Shared pointer because we do not want to copy buffer from user into privileged space.
- By having a shared pointer, the xen hypervisor can simply access the actual buffer (without copying)
2. Why is it not necessary for the guest-OS to get mutual exclusion lock to update this shared pointer?
- Isn’t the guest OS the only writer to this shared pointer?
- The guest OS is responsible for freeing the page once (and only once) the request is fulfilled (this positive confirmation is detected when the hypervisor places a response on the shared ring buffer)
3. Xen is the “Response Producer”. Is it possible for Xen to be in a situation where there are no slots available to put in a response? Justify your answer.
- My intuition is no (but let me think and try to justify my answer)
- I’m staying no with the assumption that the private response consumer’s pointer position is initialized at the half way park in the buffer. That way, if the guest OS’s producer pointer catches up and meets with the response consumer pointer, the guest OS will stop producing.
Solution
- This shared pointer informs Xen of the pending requests in the ring. Xen’s request consumer pointer will consume up until the request producer pointer.
- The guest-OS is the only writer i.e. it is solely responsible for updating this shared pointer by advancing it, while Xen only reads from it. There is no possibility of a race condition which precludes the need of a mutual execution lock.
- Two answers
- This is not possible. Xen puts in the response in the same slot from where it originally consumed the request.It consumes the request by advancing the consumer pointer which frees up a slot. Once the response is available, it puts it in the freed-up slot by advancing the response producer pointer.
- This is possible. Xen often uses these “requests” as ways for the OS to
specify where to put incoming data (e.g. network traffic). Consequently, if Xen receives too much network traffic and runs out of requests, the “response producer” may want to create a “response,” but have no requests to respond into.
Reflection
- Got the first two answers correct (just need to a be a little more specific around the consumer pointer consuming up until the request producer pointer)
- Not entirely sure how both answers (i.e. not possible and possible) are acceptable.
Parallel Systems
Question

- Show the execution sequence for the instructions executed by P1 and P2 that would yield the above results.
- Is the output: c is 0 and d is 1 possible? Why or why not?
My Guesses
- c and d both 0 means that thread T2 ran to completion and was scheduled before Thread T1 executed
- c and d both 1 means that thread T1 ran to completion and then Thread T2 ran
- c is 1 and d is 0 means that Thread T1 Instruction 1 ran, followed by both Thread T2’s instructions
The situation in which c is 0 and d is 1 is not possible assuming sequential consistency. However, that situation is possible if that consistency is not guaranteed by the compiler.
Solution
1) I3, I4, I1, I2
2) I1, I2, I3, I4
3) I1, I3, I4, I2
This is possible because even though the processor P1 presents the memory updates in program order to the interconnect, there is no guarantee that the order will be preserved by the interconnect, and could result in messages getting re-ordered (e.g., if there are multiple communication paths from P1 to P2 in the interconnect).
Reflection
I got the ordering of the threads correctly however apparently got the answer wrong about the program order. I would argue that my answer is a bit more specific since I call out the assumption of the consistency model effecting whether or not the messages will be sent/received in order.
Question 3b
Consider a Non-Cache-Coherent (NCC)NUMA architecture. Processors P1 and P2 have memory location X resident in their respective caches.
Initially X = 0;
P1 writes 42 into X
Subsequently P2 reads X
What value is P2 expected to get? Why?
Guess
Since there’s no cache coherence guarantee, P2 will read in 0. However, I am curious, how the value will get propagated to P2’s cache. In a normal cache coherent system there will be a cache invalidate or write update … but how does it all work in a non cache coherent architecture? Who’s responsibility is it then to update the cache. Would it be the OS? That doesn’t sound right to me.
Solution
0. In NUMA, each processor would have a local cache storing X value. When P1 writes 42 to X, P2 would not invalidate the copy of X in its cache due to non-cache-coherence. Rather, it would read the local value which is still set to zero.
Reflection
How would the new value ever get propagated to P2? I’m assuming in software somehow, not hardware.
Question 3c
Test-and-Set (T&S) is by definition an atomic instruction for a single processor. In a cache-coherent shared memory multiprocessor, multiple processors could be executing T&S simultaneously on the same memory location. Thus T&S should be globally atomic. How is this achieved (Note there may be multiple correct implementations, giving any one is sufficient)?
My Guess
- My guess would be that the requests will enter some sort of FIFO queue
- But how would the hardware actually care this out ….
Solution
There are multiple ways this could be enforced:
- Bypassing the cache entirely and ensuring that the memory controller
for the said memory location executes the T&S semantics atomically. - Locking the memory bus to stop other operations on the shared address
- Exclusive ownership within the caching protocol (and atomic RMW of your exclusively owned cache line)
- A multi-part but speculative operation within your cache (failing and retrying if another processor reads/writes the memory location between the beginning and end)
Reflection
Okay I was way off the mark here. But the answers do actually make sense. Thinking back at the lectures, T+S would cause lots of bus traffic so a more optimized version would be read followed by a T+S, T+S bypassing cache every time. The other answers make sense too, especially locking the memory bus.