
Remote procedure call (RPC) is a framework offered within operating systems (OS) to develop client/server systems and they promote good software engineering practices and promote logical protection domains . But without careful consideration, RPC calls (unlike simple procedure calls) can be cost prohibitive in terms over overhead incurred when marshaling data from client to server (and back).
Out of the box and with no optimization, an RPC costs four memory copy operations: client to kernel, kernel to server, server to kernel, kernel to client. On the second copy operation, the kernel makes an upcall into the server stub, unmarshaling the marshalled data from the client. To reduce these overhead, us OS designers need a way to reduce the cost.
To this end, we will reduce the number of copies by using a shard buffer space that gets set up by the kernel during binding, when the client initializes a connection to the server.
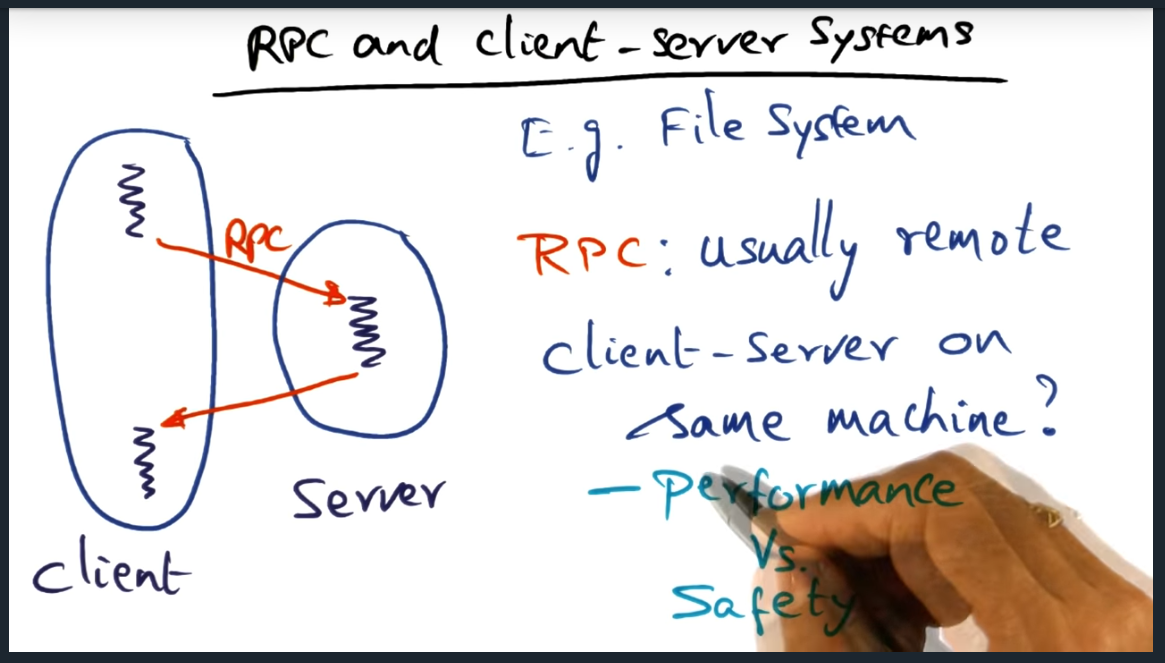
RPC and Client Server Systems
Summary
We want the protection and want the performance: how do we achieve that?
RPC vs Simple Procedure Call
Summary
An RPC call, happens at run time (not compile time) and there’s a ton of overhead. Two traps involved. First is call trap from client; return trap (from server). Two context switches: switch from client to server and then server (when its done) back to client.
Kernel Copies Quiz
Summary
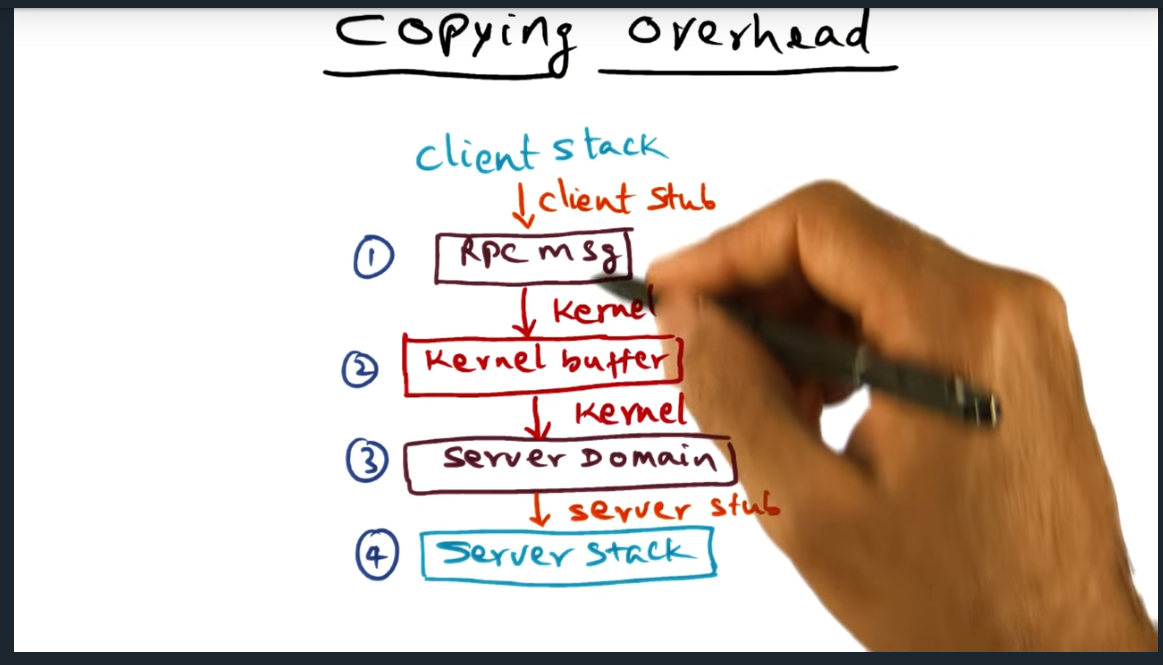
For every RPC call, there are four copies: from client address space, into kernel space, from kernel buffer to server, from server to kernel, finally from kernel back to client (for the response)
Copying Overhead
Summary
Client Server RPC calls require the kernel to perform four copies, each way. Need to emulate the stack with the RPC framework. Client Stack (rpc message) -> Kernel -> Server -> Server Stack. Same thing backwards
Making RPC Cheap
Summary
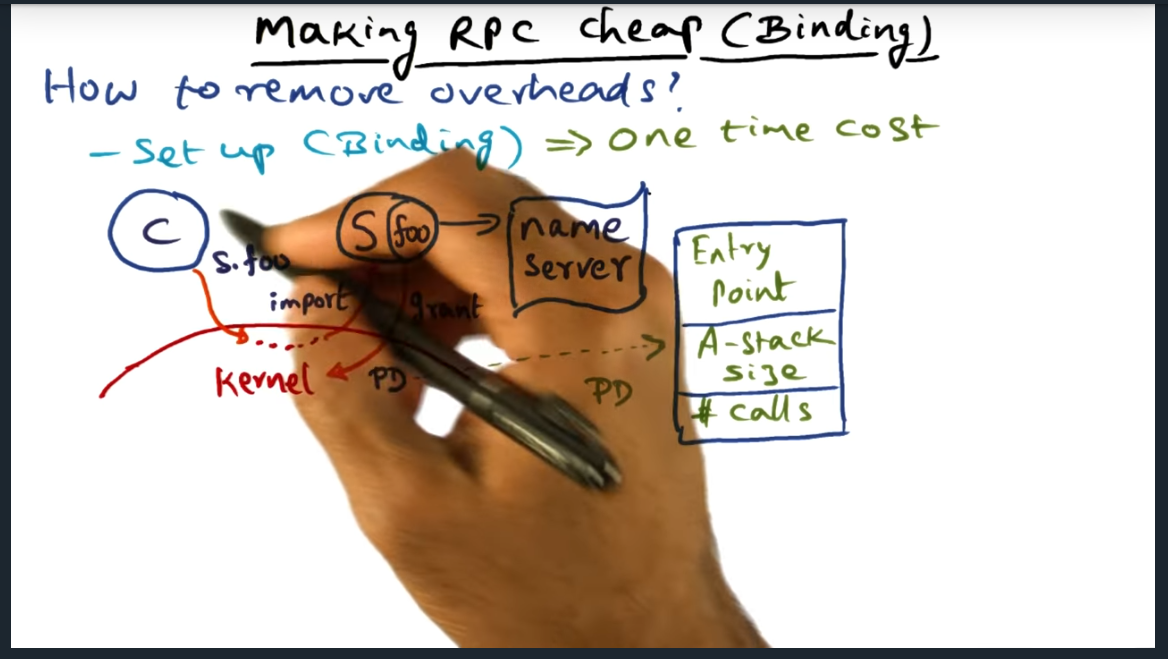
Kernel is involved in setting up communication between client and server. Kernel makes an up call into the server, checking if the client is bonafide. If validation passes, kernel creates a PD (a procedure descriptor) that contains the three following: entry point (probably a pointer, I think), stack size, and number of calls (that the server can support simultaneously).
Making RPC Cheap (Binding)
Summary
Key Take away here is that the kernel performs the one-time set up operation of setting up the binding, the kernel allocating shared buffers (as I had correctly guessed) and authenticating the client. The shared buffers basically contain the arguments in the stack (and presumably I’ll find out soon how data flows back). Separately, I learned a new term called “up calls”.
Making RPC Cheap (actual calls)
Summary
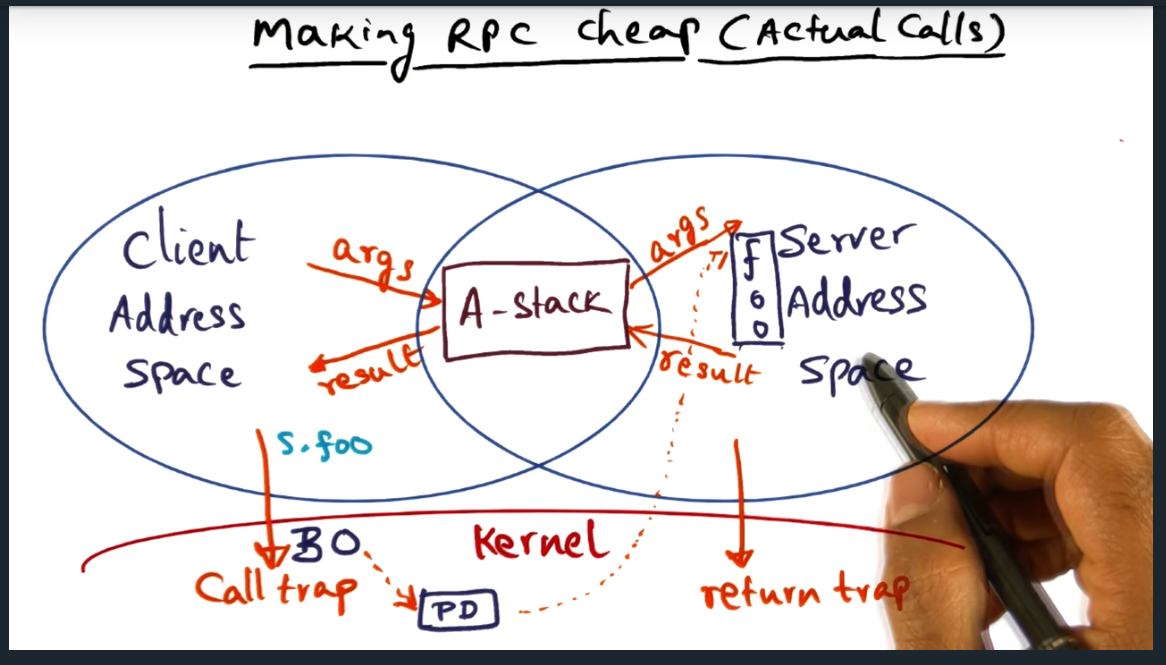
A (argument) shared buffer can only contain values passed by value, not reference, since the client and server cannot access each other’s address spaces. The professor also mentioned something about the client thread executing in the address space of the server, an optimization technique, but I’m not really following.
Making RPC Cheap (Actual Calls) continued
Summary
Stack arguments are copied from “A stack” (i.e. shared buffer) to “E” stack (execution). Still don’t understand the entire concept of “doctoring” and “redoctoring”: will need to read the research paper or at least skim it
Making RPC Cheap (Actual Calls) Continued
Summary
Okay the concept is starting to make sense. Instead of the kernel copying data, the new approach is that the kernel steps back and allows the client (in user space) copy data (no serialization, since semantics are well understood between client and server) into shared memory. So now, no more kernel copying, just two copies: marshal and unmarshal. Marshal copies from client to server. And from server to client.
Making RPC Cheap Summary
Summary
Explicit costs with new approach: 1) client trap and validating BO (binding operation) 2) Switching protection domain from client to server 3) Return trap to go back into client address space. But there are also implicit costs like loss of locality
RPC on SMP
Summary
Can exploit multiple CPUs by keeping cache warm by dedicating processors to servers
RPC on SMP Summary
Summary
The entire gist is this: make RPC cheap so that we can promote good software engineering practices and leverage the protection domains that RPC offers.