
OS for parallel machines
Summary
There are many challenges that the OS faces when building for parallel machines: size bloat (features OS just has to run), memory latency (1000:1 ratio) and numa effects (one process accessing another process’s memory across the network), false sharing (although I’m not entirely sure whether false sharing is a net positive, net negative, or just natural)
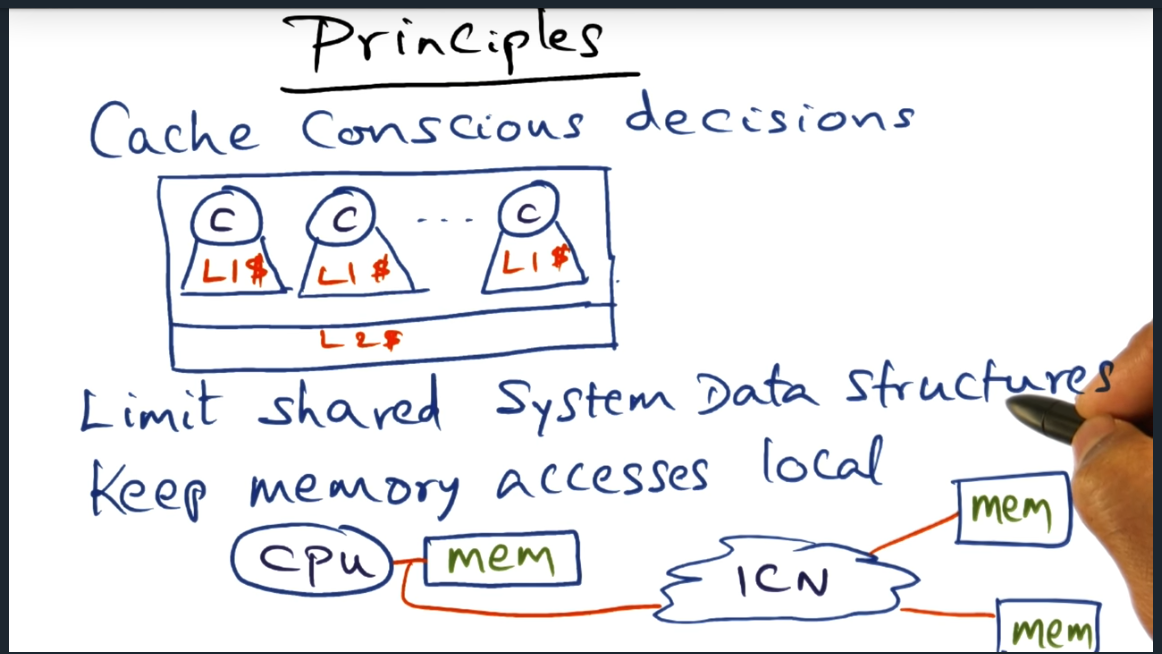
Principles
Summary
Two principles to keep in mind while designing operating systems for parallel systems. First it to make sure that we are making cache conscious decisions (i.e. pay attention to locality, exploit affinity during scheduling, reduce amount of sharing). Second, keep memory accesses local.
Refresher on Page Fault Service
Summary
Look up TLB. If no miss, great. But if there’s a miss and page not in memory, then OS must go to disk and retrieve the page, update the page table entry. This is all fine and dandy but the complication lies in the center part of the photo since accessing the file system and updating the page frame might need to be done serially since that’s a shared resource between threads. So … what we can do instead?
Parallel OS + Page Fault Service
Summary
There are two scenarios for parallel OS, one easy scenario and one hard. The easy scenario is multi-process (not multi-threaded) since threads are independent and page tables are distinct, requiring zero serialization. The second scenario is difficult because threads share the same virtual address space and have the same page table, shared data in the TLB. So how can we structure our data structures so that threads running on one process are not shared with other threads running on another physical processor?
Recipe for Scalable Structure in Parallel OS
Summary
Difficult dilemma for operating system designer. As designers, we want to ensure concurrency by minimizing sharing of data structures and when we need to share, we want to replicate or partition data to 1) avoid locking 2) increase concurrency
Tornado’s Secret Sauce
Summary
The OS creates a clustered object and the caller (i.e. developer) decides degree of clustering (e.g. singleton, one per core, one per physical CPU). The clustering (i.e. splitting of object into multiple representations underneath the hood) falls on to the responsibility of the OS itself, the OS bypassing the hardware cache coherence.
Traditional Structure
Summary
For virtual memory, we have shared/centralized data structures — but how do we avoid them?
Objectization of Memory
Summary
We break the centralized PCB (i.e. process control block) into regions, each region backed by a file cache manager. When thread needs to access address space, must access specific region.
Objectize Structure of VM Manager
Summary
Holy hell — what a long lecture video (10 minutes). Basically, we walk through workflow of a page fault in a objected structure. Here’s what happens. Page fault occurs with a miss. Process inspects virtual address and knows which region to consult with. Each region, backed by its file cache manager, will talk to the COR (cache object representation) which will perform translation of page, the page eventually fetched from DRAM. Different parts of system will have different representation. The process is shared and can be a singleton (same with COR), but region will be partitioned, same with FCM.
Advantages of Clustered Object
Summary
A single object make underneath the hood have multiple representations. This same object references enables less locking of data structures, opening up opportunities for scaling services like page fault handling
Implementation of Clustered Object
Summary
Tornado incrementally optimizes system. To this end, tornado creates a translation table that maps object references (a common object) to the processor specific representation. But if obj reference does not reside in t translation table, then OS must refer to the miss handling table. Since this miss handling table is partitioned and not global, we also need a global translation table that handles global misses and has knowledge of location of partition data.
Non Hierarchical Locking
Summary
Hierarchical locking kills concurrency (imagine two threads sharing process object). What can we do instead? How about referencing counting (so cool to see code from work bridge the theoretically and practical gap), eliminating need for hierarchical locking. With a reference count, we achieve existence guarantee!
Non Hierarchical Locking + Existence Guarantee (continued)
Summary
The reference count (i.e. existence guarantee) provides same facility of hierarchical locking but promote concurrency
Dynamic Memory Allocation
Summary
We need dynamic memory allocation to be scalable. So how about breaking the heap up into segments and threads requesting additional memory can do so from specific partition. This helps avoid false sharing (so this answers my question I had a few days ago: false sharing on NUMA nodes is a bad thing, well bad for performance)
IPC
Summary
With objects at the center of the system, we need an efficient IPC (inter process communication) to avoid context switches. Also, should point out that objects that are replicated must be kept consistent (during writes) by the software (i.e. the operating system) since hardware can only manage coherence at the physical memory level. One more thing, the professor mentioned LRPC but I don’t remember studying this topic at all and don’t recall how we can avoid a context switch if two threads calling one another are living on the same physical CPU.
Tornado Summary
Summary
Key points is that we use an object oriented design to promote scalability and utilize reference counting for implementing a non hierarchical locking, promoting concurrency. Moreover, OS should optimize the common case (like page fault handling service or dynamic memory allocation)
Summary of Ideas in Corey System
Summary
Similar to Tornado, but 3 take aways: address ranges provided directly to application, file descriptor can be private (and note shared), dedicated cores for kernel activity (helps locality).
Virtualization to the Rescue
Summary
Cellular disco is a VMM that runs as a very thin layer, intercepting requests (like I/O) and rewriting them, providing very low overhead and showing by construction the feasibility of a thin virtual machine management.