
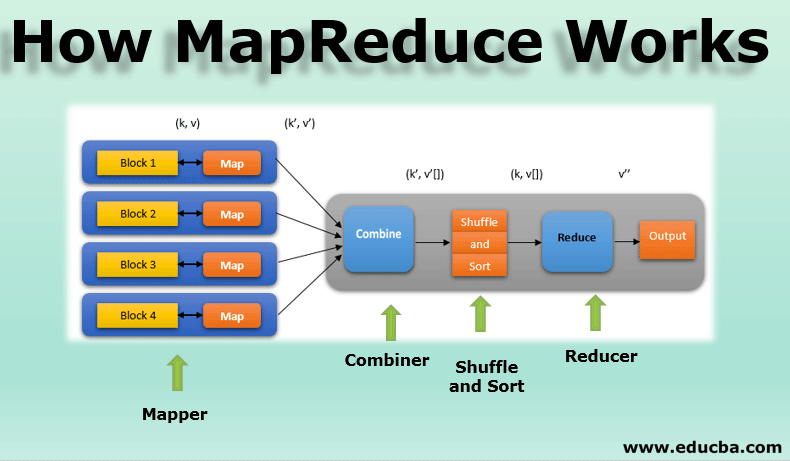
Like my previous posts on snapshotting my understanding of gRPC and shapshotting my understanding of barrier synchronization, this post captures my understanding of MapReduce, a technology I’ve never been exposed to before. The purpose of these types of posts is to allow future self to look back and be proud of what I learned since the time I’m pouring into my graduate studies takes away time from my family and my other aspirations.
Anyways, when it comes to MapReduce, I pretty much know nothing beyond a very high level and superficial understanding: there’s a map step followed by a reduce step. Seriously — that’s it. So I’m hoping that, once I finish reading the original MapReduce paper and once I complete Project 4 (essentially building a MapReduce framework using gRPC), I’ll have a significantly better understanding of MapReduce. More importantly, I can apply some of my learnings to future projects.
Some questions I have:
- How does MapReduce parallelize work?
- What are some of the assumptions and trade offs of the MapReduce framework?
- What are some work loads that are not suitable for MapReduce?