
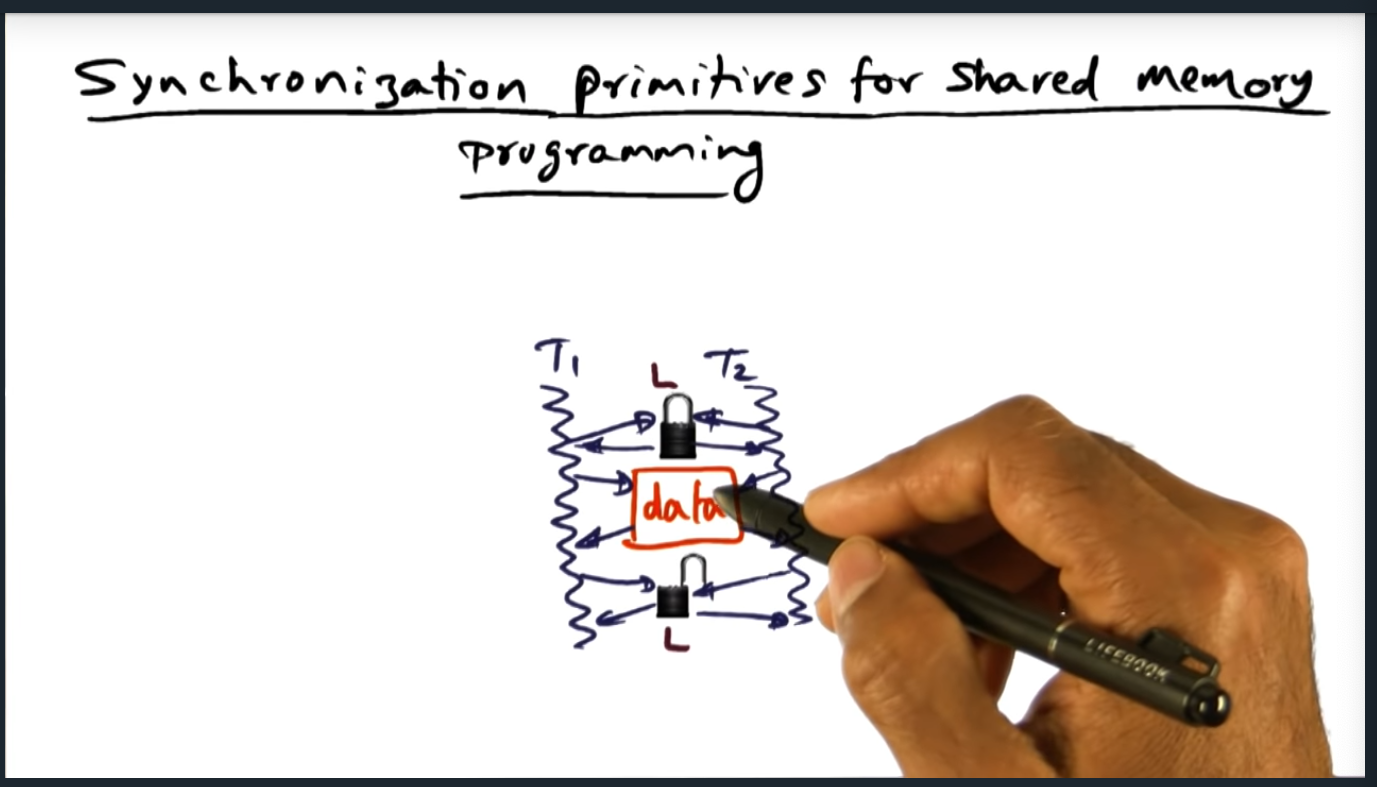
I broke down the synchronization topic into two parts and this will cover material up to and including the array based queuing lock. I’ll follow up with part 2 tomorrow, which will include the linked list based queuing lock.
There a couple different types of synchronization primitives: mutual exclusion and barrier synchronization. Mutual exclusion ensures that only one thread (or process) at a time can write to a shared data structure, whereas barrier synchronization ensures that all threads (or processes) reach a certain point in the code before continuing. The rest of this summary focuses on the different ways we as operating system designers can implement mutual exclusion and offer it as a primitive to system programmers.
To implement a mutual exclusion lock, three instructions need to be bundled together: reading, checking, writing. These three operations must happen atomically, all together and at once. To this end, we need to leverage the underlying hardware’s instructions such as fetch_and_set, fetch_and_increment, or fetch_and_phi.
Whatever way we implement the lock, we must evaluate our implementation with three performance characteristics:
- Latency (how long to acquire the lock)
- Waiting time (how long must a single thread must wait before acquiring the lock)
- Contention (how long long to acquire lock when multiple thread compete)
In this section, I’ll list each of the implementations ordered in most basic to most advanced
- Naive Spin Lock – a simple while loop that calls test_and_set atomic operation. Downside? Lots of bus traffic for cache invalidation or cache updating. What can we do instead?
- Caching Spin Lock – Almost identical to the previous implementation but instead of spinning on a while loop, we spin on a read, followed by a check for test_and_set. This reduces noisy bus traffic of test_and_test (which again, bypasses cache and writes to memory, every time)
- Spinlock with delay – Adds a delay to each test_and_test. This reduces spurious checks and ensures that not all threads perform test_and_set at the same time
- Ticket Lock – Each new request that arrives obtains a ticket. This methodology is analogous to a how a deli hands out tickets for their customers; it is fair but still signals all other threads to wake up
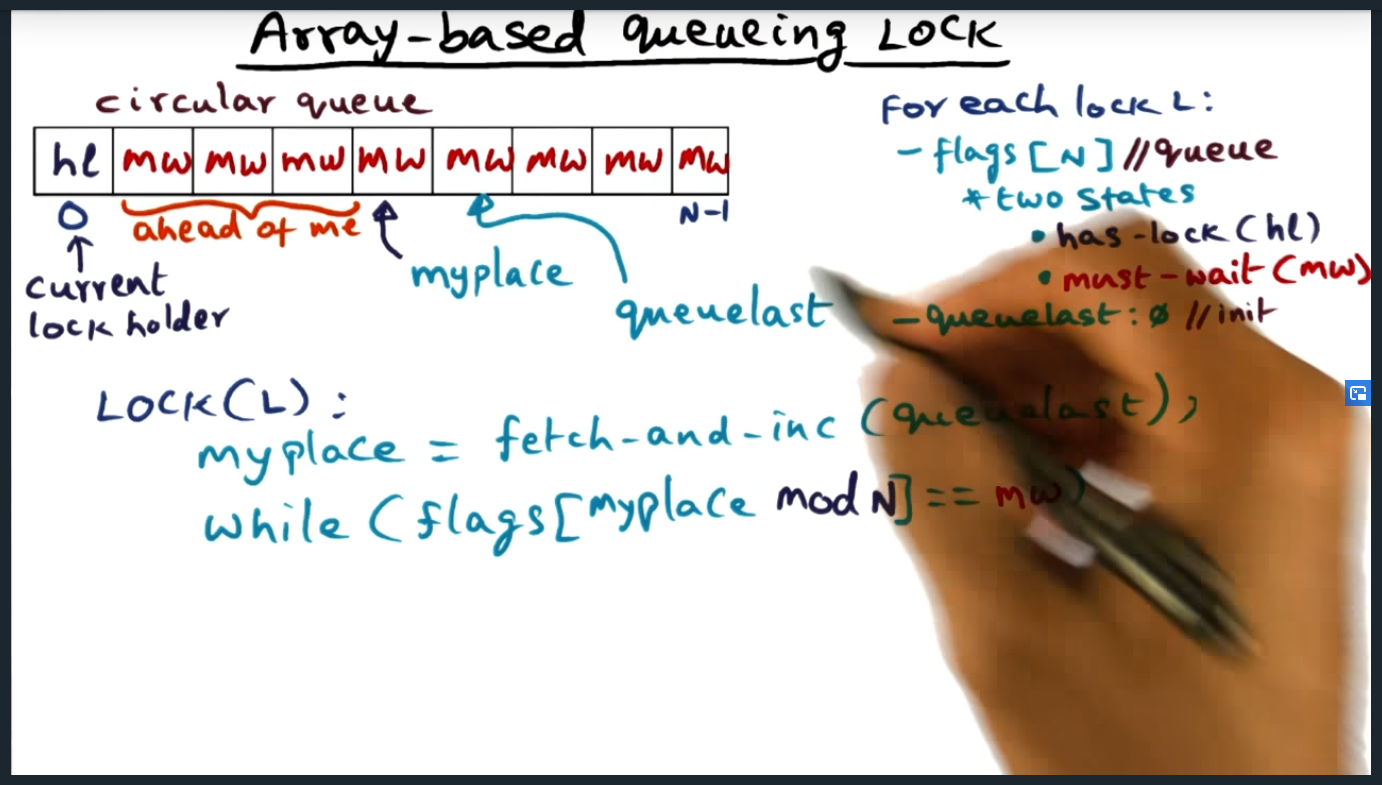
- Array based queuing lock – An array that is N in size (where N is the number of processors). Each entry in the array can be in one of two states: has lock and must-wait. Fair and efficient. But trades off space: each lock gets its own array with N entries where N is number of processors. Can be expensive for machines with thousands of processors and potentially wasteful if not all of them contend for the lock
Lesson Summary
Summary
There are two types of locks: exclusive and shared lock. Exclusive lock guarantees that one and only one thread can access/write data to a location. Shared allows multiple readers, but guaranteeing no other thread is writing at that time.
Synchronization Primitives
Summary
Another type of synchronization primitive (instead of mutual exclusion) is a barrier. A barrier basically ensures that all threads reach a certain execution point and only then can the threads advance. Similar to real life when you get to a restaurant and you cannot be seated until all your party arrives. That’s an example of a barrier.
Programmer’s Intent Quiz
Summary
We can write that enforces barrier with a simple while loop (but its inefficient) using atomic reads and writes
Programmer’s Intent Explanation
Summary
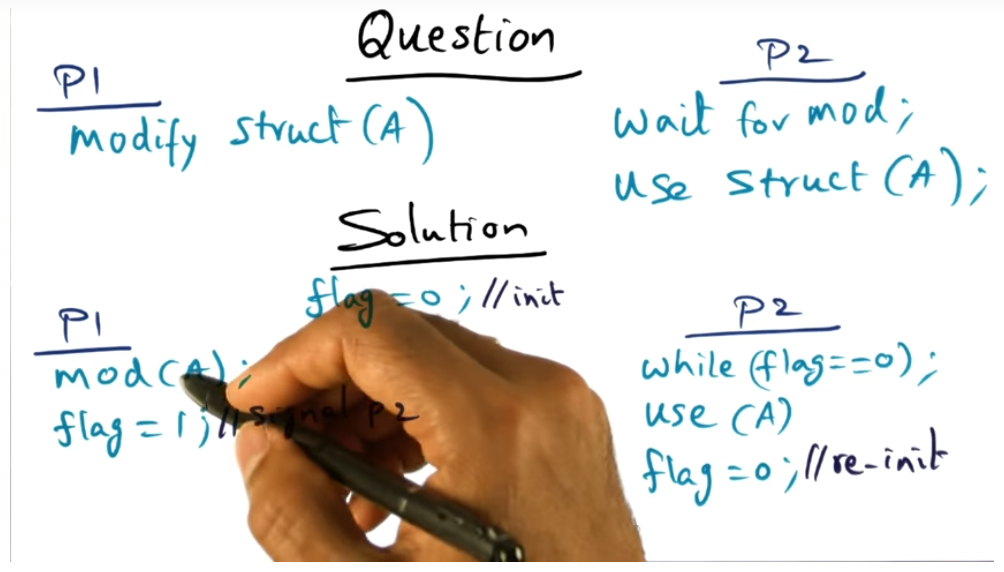
Because of the atomic reads and writers offered by the instruction set, we can easily use a flag to coordinator between processes. But are these instructions sufficient for creating a mutual exclusion lock primitive?
Atomic Operations
Summary
The instruction set ensures that each read and write operation is atomic. But if we need to implement a lock, there are three instructions (read, check, write) that need to be bundled together into a single instruction by the hardware. This grouping can be done in one of three ways: test_and_set or (generically) fetch_and_increment or fetch_and_phi
Scalability Issues with Synchronization
Summary
What are the three types of performance issues with implementing a lock? Which of the two are under the control of the OS designer? The three scalability issues are as follows: latency (time to acquire lock) and waiting time (how long does a thread wait until it acquires the lock) and contention (how long does it take, when all threads are competing to acquire lock, for lock to be given to a single thread). The first and third (i.e. latency and contention) are under the control of the OS designer. The second is not: waiting time is largely driven by the application itself because the critical section might be very long.
Naive Spinlock (Spin on T+S)
Summary
Why is the SPIN lock is considered naive? How does it work? Although the professor did not explicitly call out why the SPIN lock is naive, I can guess why (and my guess will be confirmed in the next slide, during the quiz). Basically, each thread is eating up CPU cycles by performing the test and test. Why not just signal them instead? That would be more efficient. But, as usual, nothing is free so there must be a trade off in terms of complexity or cost. But returning back to how the naive scheduler works, it’s basically a while loop with the test_and_test (semantically guaranteeing on a single thread will receive the lock).
Problems with Naive Spin Lock

Summary
Spin lock is naive for three reasons: too much contention (when lock is released, all threads, maybe thousands, will jump at the opportunity) and does not exploit cache (test and set by nature must bypass cache and go straight to memory) and disrupts useful work (only one process can make forward progress)
Caching Spinlock
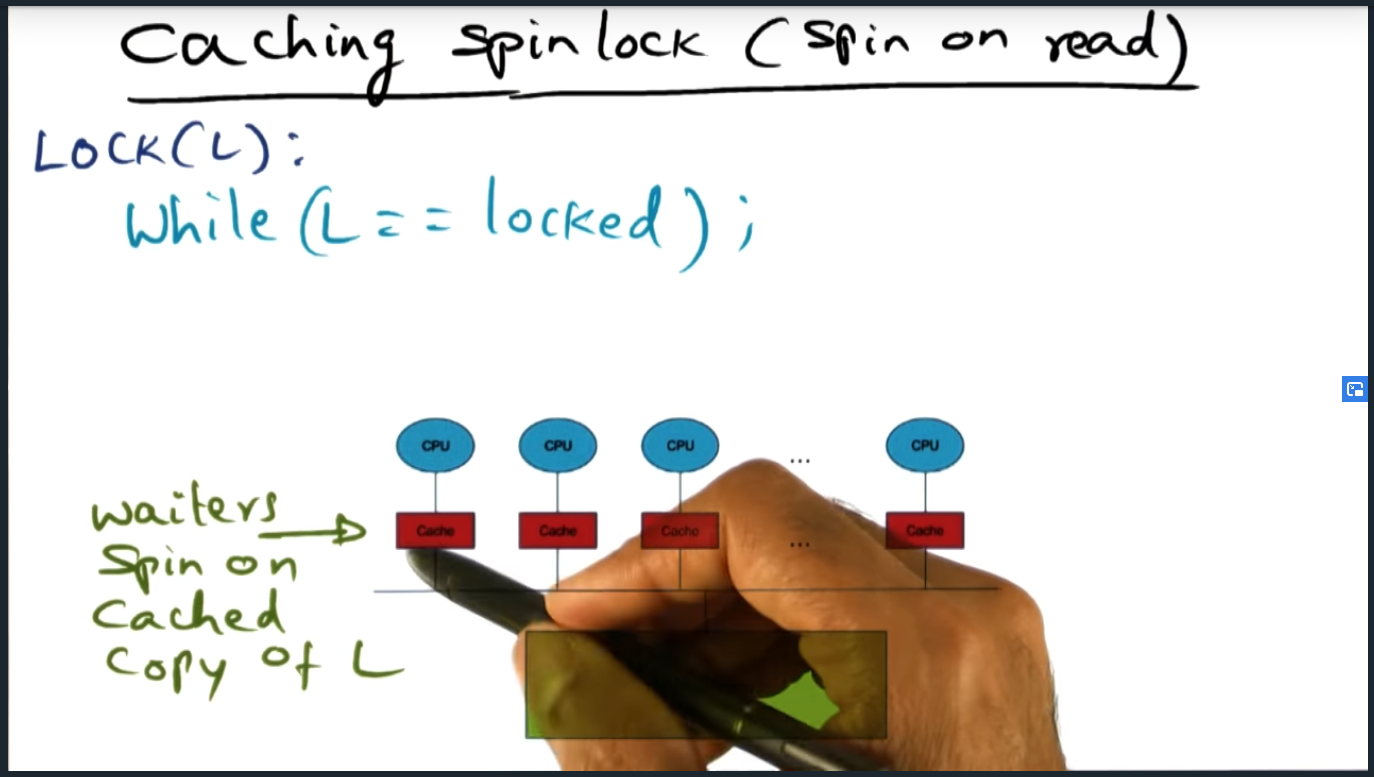
Summary
To take advantage of the cache, processors will first call while(L == locked), taking advantage of the cache. Once test_and_set occurs, all processors will then proceed with test_and_set. Can we do better than this?
Spinlocks with Delay
Summary
Any sort of delay will improve performance of a spin lock when compared to the naive solution
Ticket Lock
Summary
A fair algorithm that uses a deli or restaurant analogy: people who come before will get lock before people who come after. This is great for fairness, but performance still lacking in the sense that when a thread releases its lock, an update will be sent across the entire bus. I wonder: can this even be avoided or its the reality of the situation?
Spinlock Summary
Summary
A couple differentiations toptions 1) Read and Test and Test (no fairness) 2) Test and Set with Delay (no fairness) 3) Ticket Lock (fair but noisy). How can we do better? How can we only signal one and only thread to wake up and attempt to gain access to the lock? Apparently, I’ll learn this shortly, with queueing locks. This lesson reminds me of a conversation I had with my friend Martin around avoiding a busy while() loop for lock contention, a conversation we had maybe about a year or so ago (maybe even two years ago)
Array Based Queuing Lock
Summary
Create an array that is N in size (where N is the number of processors). Each entry in the array can be in one of two states: has lock and must-wait. Only one entry can ever be in has-lock state. I’m proud that I can understand the circular queue (just by looking at the array) with my understanding of the mod operator. But even so, I’m having a hard time understanding how we’ll use this data structure in real life.
Array Based Queuing Lock (continued)
Summary
Lock acquisition looks like: fetch and increment (queue last) followed by a while(flags[mypalce mod N] == must wait). Still not sure how this avoids generating cache bus traffic as described earlier…
Array-based queue lock
Summary

Using mod, we basically update the “next” entry in the array and set them to “has_lock”