I’m watching the YouTube learning series called “Introduction to OpenMP” in order to get a better understanding of how I can use the framework for my second project in advanced operating systems. You might find the below notes useful if you don’t want to sit through the entire video series.
Introduction to OpenMP: 02 part 1 Module 1
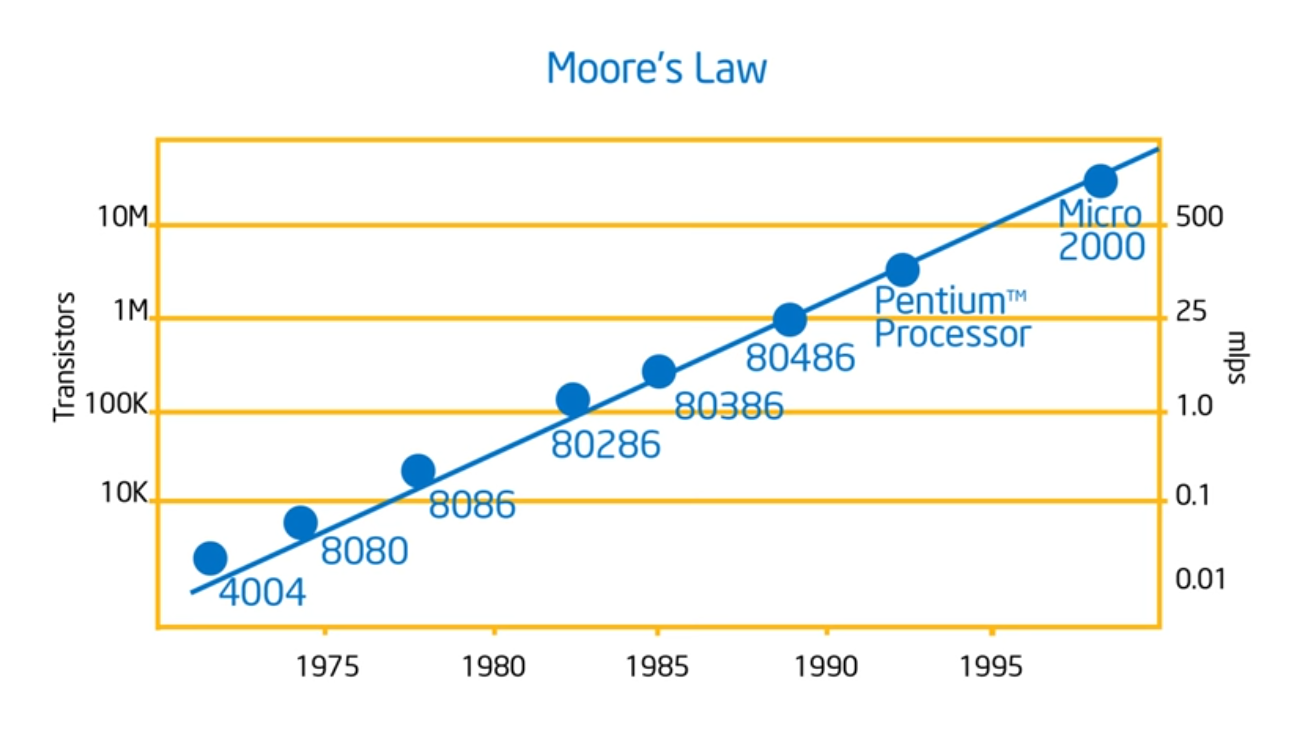
Moore’s Law
Summary
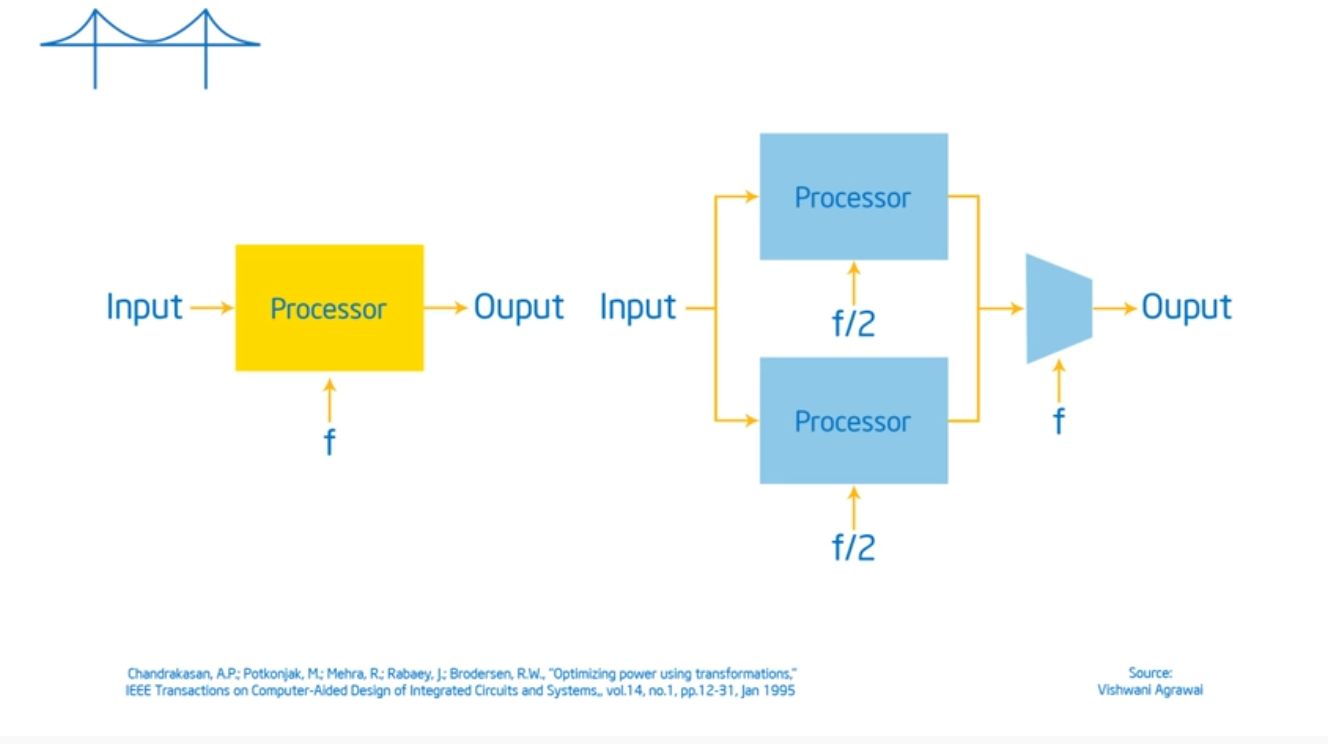
Neat that he’s going over the history, talking about Moore’s Law. The key take away now is that hardware designers are now going to optimize for power and software developers have to write parallel programs: there’s no free lunch. No magic compiler that will take sequential code and turn it into parallel code. Performance now c
Introduction to OpenMP – 02 Part 2 Module 1
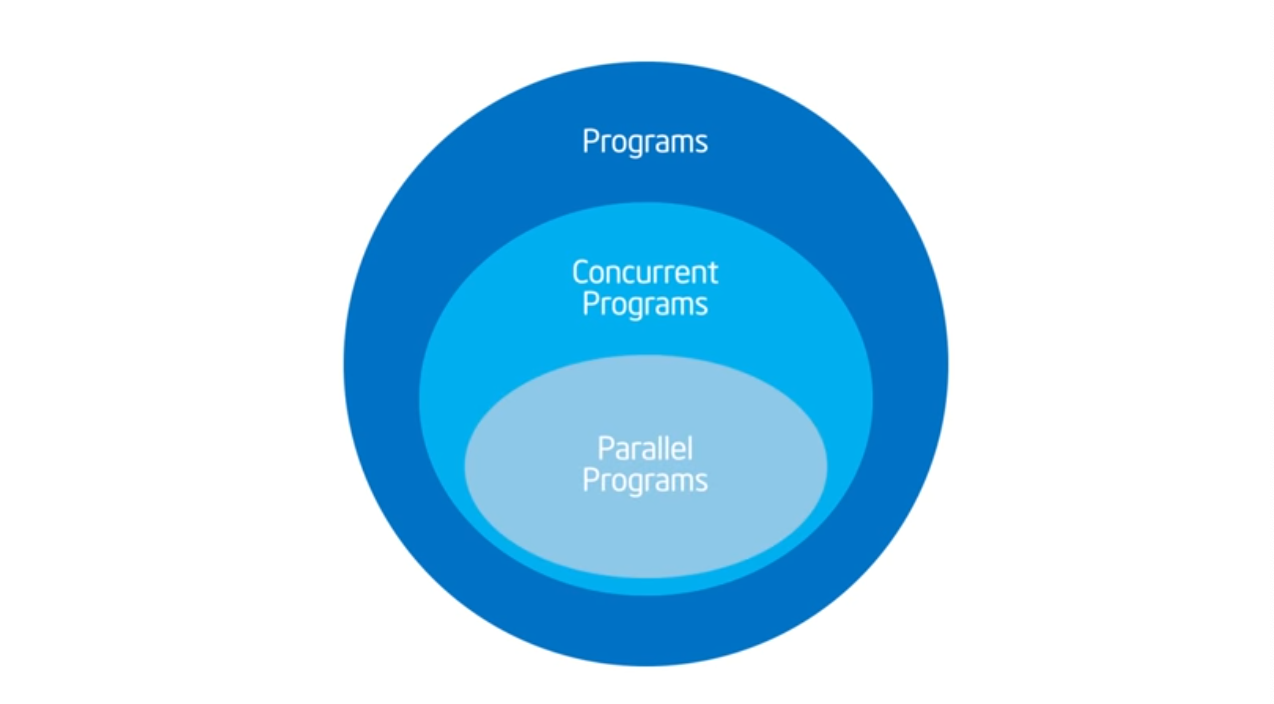
Concurrency vs Parallelism
Summary
The last step should be picking up the OpenMP Library (or any other parallel programming library). What should be done firs and foremost is breaking down your problem (the act of this has not been able to automated) into concurrent parts (this requires understanding of the problem space) and then figure out which can run in parallel. Once you figure that out, then you can use compiler syntactical magic (i.e. pragmas) to direct your compiler and then sprinkle some additional pragmas that will help the compiler tell where the code should enter and where it should exit.
Introduction to OpenMP – 03 Module 02
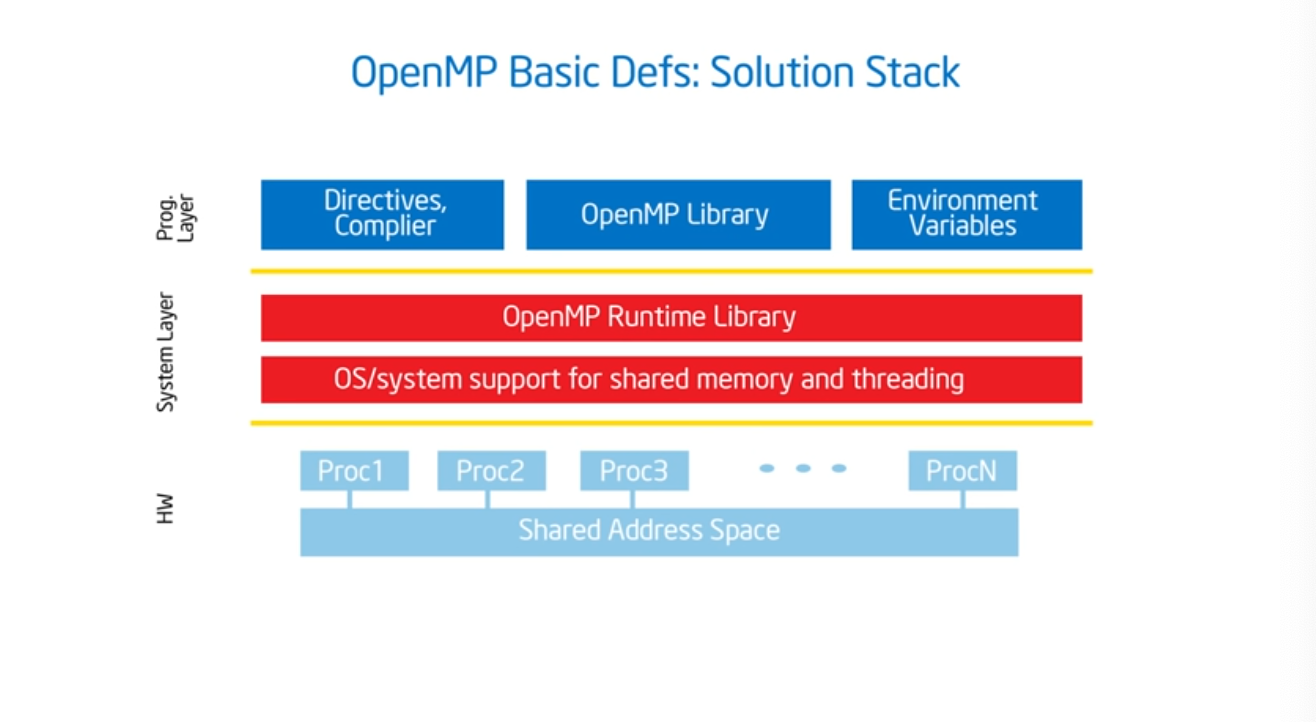
OpenMP Solution Stack
Summary
It’s highly likely that the compiler that you are using already supports OpenMP. For gcc, pass in -fopenmp. And then include the prototype, and add some syntactic sugar (i.e. #pragma amp parallel) which basically gives the program a bunch of threads.
Introduction to OpenMP: 04 Discussion 1
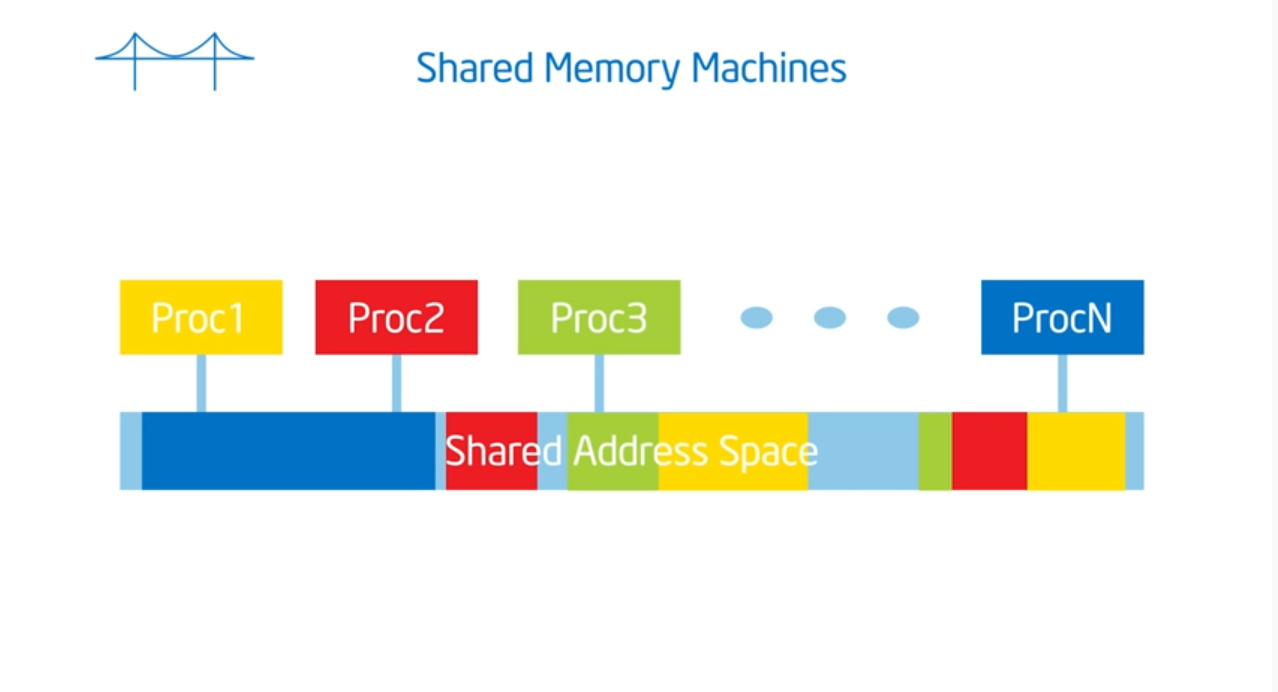
Shared address space
Summary
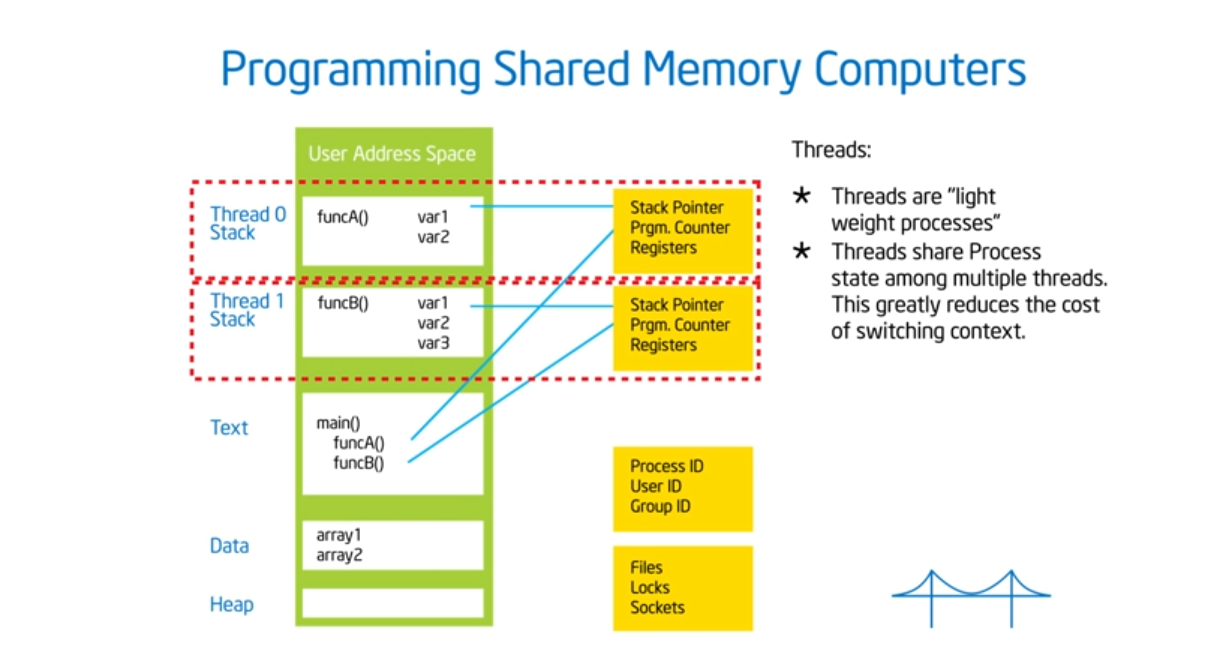
OpenMP assumes a shared memory address space architecture. The last true SMP (symmetric multi-processor) machine was in the late 1980s so most machines now run on NUMA (non uniformed multiple access) architectures. To exploit this architecture, we need to schedule our threads intelligently (which map to the same heap but contain different stacks) and place data in our cache’s as close as possible to their private caches. And, just like the professor said in advanced OS, we need to limit global data sharing and limit (as much as possible) the use of synchronization variables since they both slow down performance
Part 1 of barrier synchronization covers my notes on the first couple types of synchronization barriers including the naive centralized barrier and the slightly more advanced tree barrier. This post is a continuation and covers the three other barriers: MCS barrier, tournament barrier , dissemination barrier.
Summary
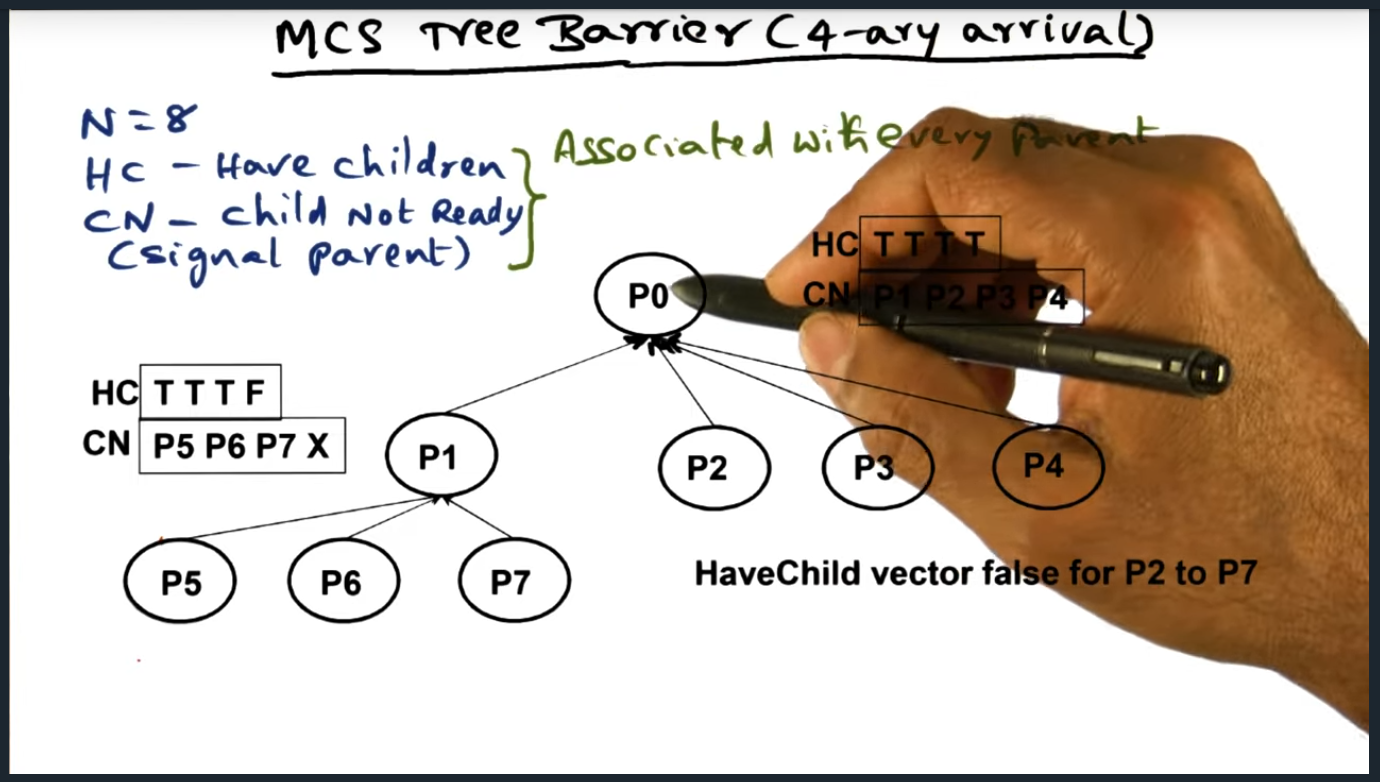
In the MCS tree barrier, there are two separate data structures that must be maintained. The first data structure (a 4-ary tree, each node containing a maximum of four children) handling the arrival of the processes and the second data structure handling the signaling and waking up of all other processes. In a nutshell, each parent node holds pointers to their children’s structure, allowing the parent process to wake up the children once all other children have arrived.
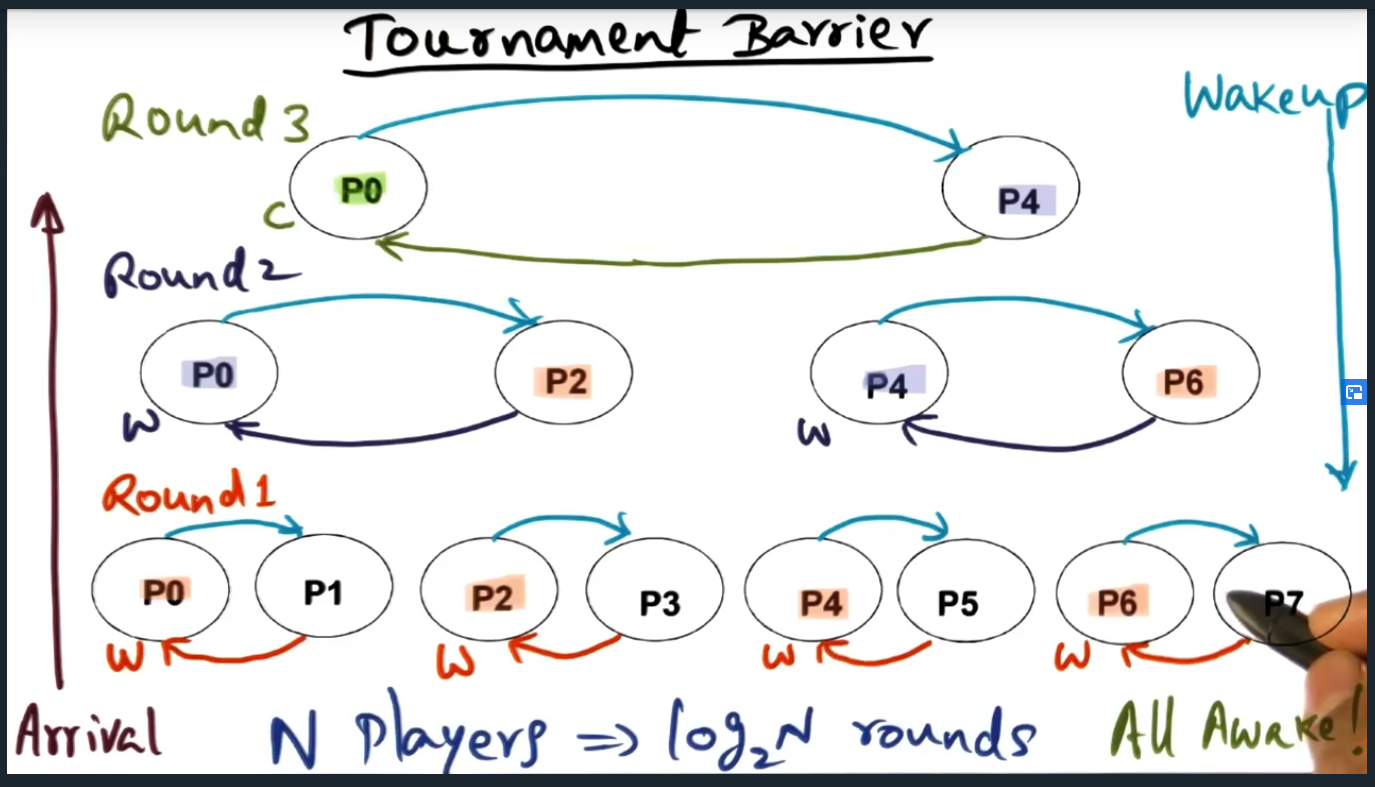
The tournament barrier constructs a tree too and at each level are two processes competing against one another. These competitions, however, are fixed: the algorithm predetermines which process will advanced to the next round. The winners percolate up the tree and at the top most level, the final winner signals and wakes up the loser. This waking up of the loser happens at each lower level until all nodes are woken up.
The dissemination protocol reminds me of a gossip protocol. With this algorithm, all nodes detect convergence (i.e. all processes arrived) once every process receives a message from all other processes (this is the key take away); a process receives one (and only one) message per round. The runtime complexity of this algorithm is nlogn (coefficient of n because during each round n messages, one message sent from one node to its ordained neighbor).
The algorithms described thus far share a common requirement: they all require sense reversal.
MCS Tree Barrier (Binary Wakeup)
MCS Tree barrier with its “has child” vector
Summary
Okay, I think I understand what’s going on. There are two separate data structures that need to be maintained for the MCS tree barrier. The first data structure handles the arrival (this is the 4-ary tree) and the second (binary tree) handles the signaling and waking up of all the other processes. The reason why the latter works so well is that by design, we know the position of each of the nodes and each parent contains a pointer to their children, allowing them to easily signal the wake up.
Tournament Barrier
Tournament Barrier – fixed competitions. Winner holds the responsibility to wake up the losers
Summary
Construct a tree and at the lowest level are all the nodes (i.e. processors) and each processor competes with one another, although the round is fixed, fixed in the sense that the winner is predetermined. Spin location is statically determined at every level
Tournament Barrier (Continued)
Summary
Two important aspects: arrival moves up the tree with match fixing. Then each winner is responsible for waking up the “losers”, traversing back down. Curious, what sort of data structure? I can see an array or a tree …
Tournament Barrier (Continued)
Summary
Lots of similarity with sense reversing tree algorithm
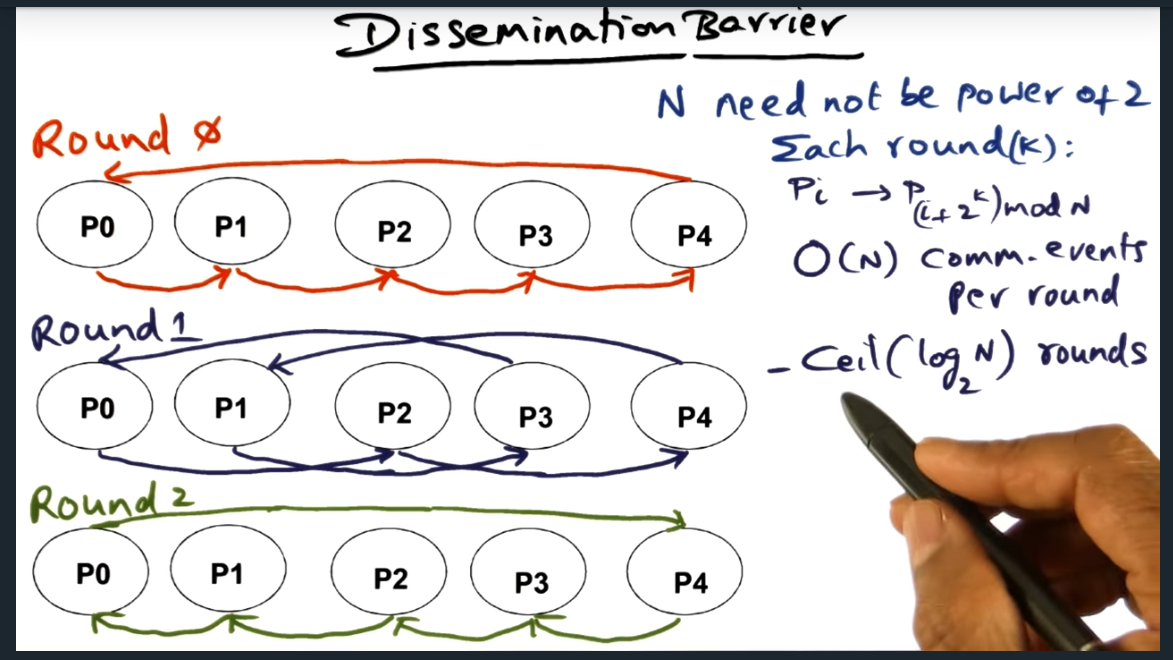
Dissemination Barrier
Dissemination Barrier – gossip like protocol
Summary
Ordered communication: like a well orchestrated gossip like protocol. Each process will send a message to ordained peer during that “round”. But I’m curious, do we need multiple rounds?
Dissemination Barrier (continued)
Summary
Gossip in each round differs in the sense the ordained neighbor changes based off of Pi -> P(I + 2^k) mod n. Will probably need to read up on the paper to get a better understanding of the point of the rounds ..
Quiz: Barrier Completion
Summary
Key point here that I just figured out is this: every processor needs to hear from every other processor. So, it’s log2N with a ceiling since N rounds must not be a power of 2 (still not sure what that means exactly)
Dissemination Barrier (continued)
Summary
All barriers need sense reversal. Dissemination barrier is no exception. This barrier technique works for NCC and clusters.Every round has N messages. Communication complexity is nlogn (where N is number of messages) and log(n). Total communication nlogn because N messages must be sent every round, no exception
Performance Evaluation
Summary
Most important question to ask when choosing and evaluating performance is: what is the trend? Not exact numbers, but trends.
As mentioned previously, there are different types of synchronization primitives that us operating system designers offer. If as an application designer you nee to ensure only one thread can access a piece of shared memory at a time, use a mutual exclusion synchronization primitive. But what about a different scenario in which you need all threads to reach a certain point in the code and only once all threads reach that point do they continue? That’s where a barrier synchronization comes into play.
This post covers two types of barrier synchronizations. The first is the naive, centralized barrier and the second is the a tree barrier.
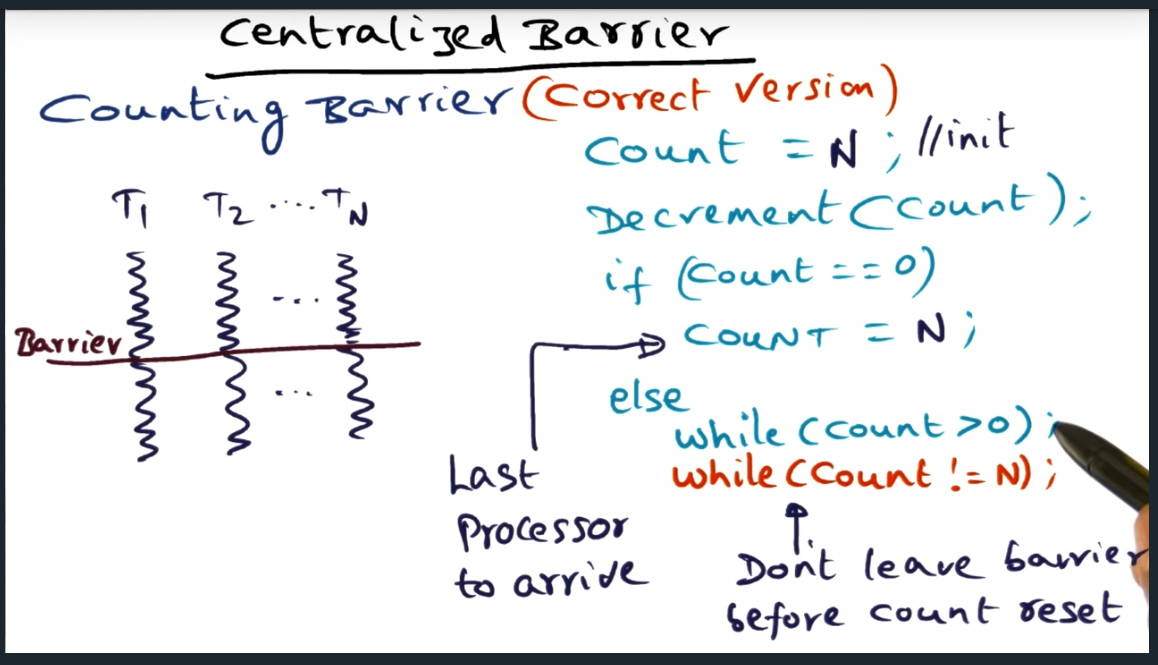
In a centralized barrier, we basically have a global count variable and as each thread enters the barrier, they decrement the shared count variable. After decrementing the count, threads will hit a predicate and branch: if the count is not zero, then the thread enters a busy spin loop, spinning while the count is greater than zero. However, if after decrementing the counter equals zero, then that means all threads have arrived at the end of the barrier synchronization.
Simple enough, right? Yes it is, but the devil is in the details because there’s a subtle bug, a subtle edge case. It is entirely possible (based off of the code snippet below) that when the last thread enters the barrier and decrements the count, all the other threads suddenly move beyond the barrier (since the count is not greater than zero). In other words, the last thread never gets to reset the count back to N number of threads.
How to avoid this problem? Simple: add another while loop that guarantees that the threads do not leave the barrier until the counter gets reset. Very elegant. Very simple.
The next type of barrier is a tree barrier. The tree barrier groups multiple process together at multiple levels (number of levels is logn where n is the number of processors), each group maintaining its own count and local sense variables. The benefit? Each group spins on its own locksense. Downside? The spin location is dynamic, not static and can impede performance on NUMA architectures.
Centralized Barrier
Centralized Barrier
Summary
Centralized barrier synchronization is pretty simple: keep a counter that decrements as each thread reaches the barrier. Every thread/process will spin until the last thread arrives, at which point the last thread will reset the barrier counter so that it can be used later on
Problems with Algorithm
Summary
Race condition: last thread, while updating the counter, all other threads move forward
Counting Barrier
Summary
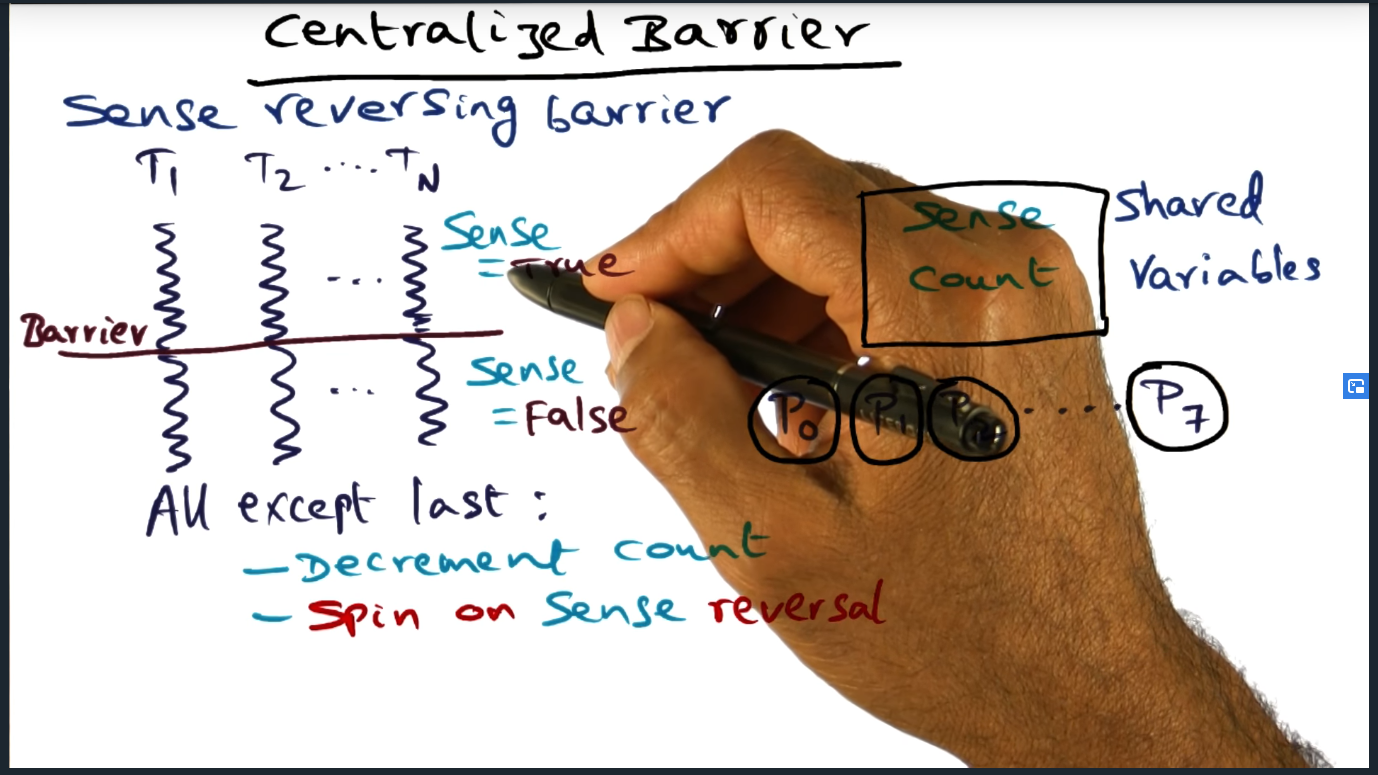
Such a simple and elegant solution by adding a second spin loop (still inefficient, but neat nonetheless). Sense reverse barrier algorithm
Sense Reversing Barrier
Sense Reversing Barrier
Summary
One way to optimize the centralized barrier is to introduce a sense reversing barrier. Essentially, each process maintains its own unique local “sense” that flips from 0 to 1 (or 1 to 0) each time synchronization barrier is needed. This local variable is compared against a shared flag and only when the two are equal can all the threads/processes proceed past the current barrier and move on to the next
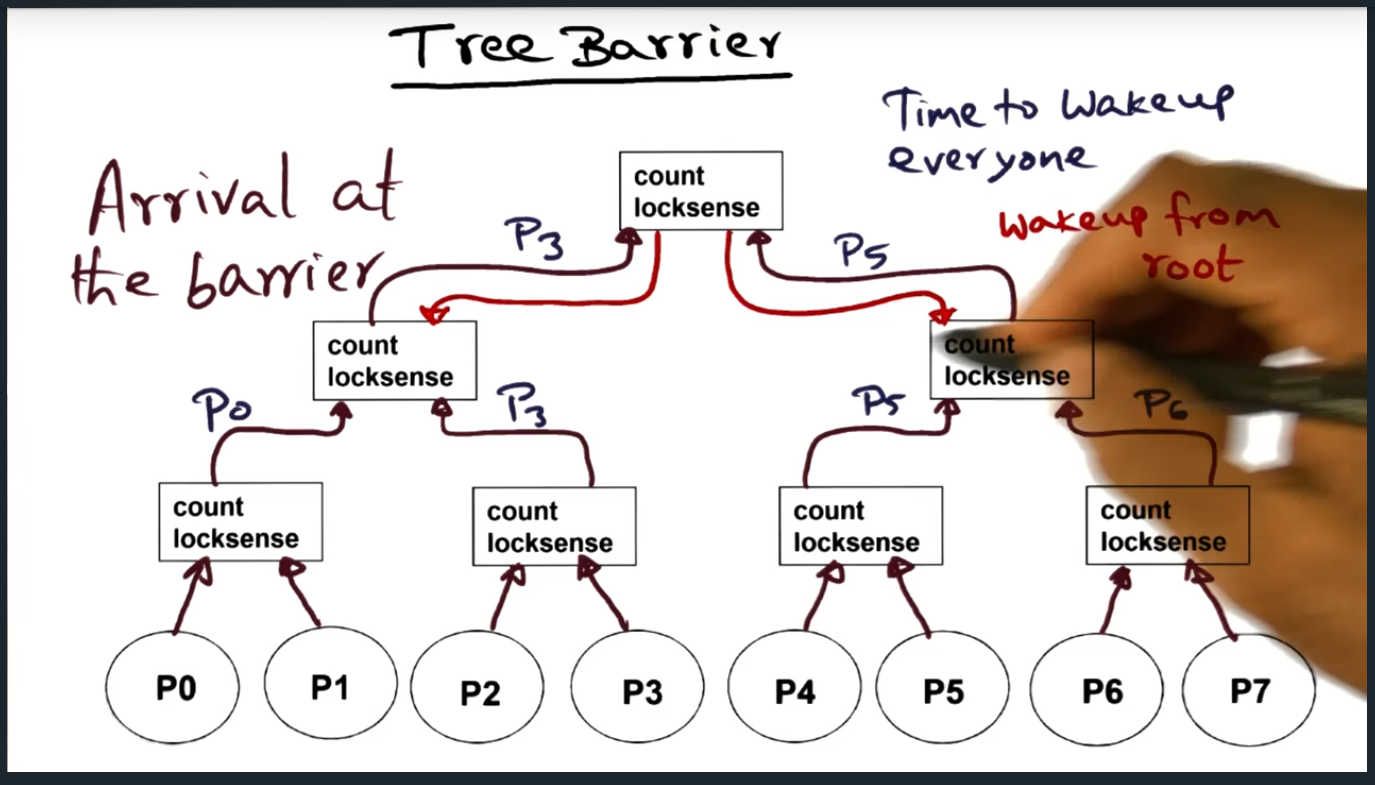
Tree Barrier
Tree Barrier
Summary
Group processes (or threads) and each group has its own shared variables (count and lock sense). Before flipping the lock sense, the final process needs to move “up to the next level” and check if all other processors have arrived at the next level. Things are getting a little more spicy and complicated with this type of barrier
Tree Barrier (Continued)
Summary
With a tree barrier, a process arrives at its group (of count and lock sense), and will decrement the count variable and will then check the lock sense variable. If lock sense is not equal, then spin. If last
Tree Barrier (continued)
Summary
Once the last process reaches the root, it’s their responsibility to begin waking up the lower levels, traversing back down the tree. At each level, they will be flipping the lock sense flag
Tree Barrier (Continued)
Summary
As always, there’s a trade off or hidden downside with this implementation. First, the spin location is not statically determined. This dynamic allocation may be problematic, especially on NUMA (non uniformed memory access architecture) architecture, because a process may be spinning on a remote memory location. But my question is, are there any systems that do not offer coherence?