Introduction
Summary
Lessons will be broken down into three modules: GMS (i.e. can we use peer memory for paging across LAN) and DSM (i.e. can we make the cluster appear as a shared memory machine) and DFS (i.e. can we use cluster memory for cooperative caching of files)
Context for Global Memory Systems
Summary
Key Words: working set
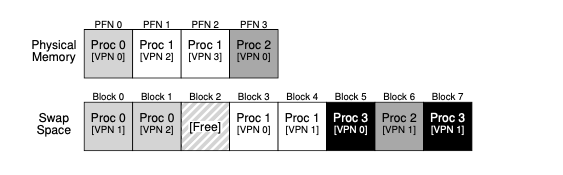
Core idea behind GMS is when there’s a page fault, instead of checking disk, check the cluster memory instead. Most importantly, no dirty pages (does not complicate the behavior): the disk always has copies of the pages
GMS Basics

Summary
With GMS, a physical node carves out its physical memory into two areas: local (for working set) and global (servicing other nodes as part of being in the “community”). This global cache is analagous to a virtual memory manager in the sense that the GSM does not need to worry about data coherence: that’s the job of the upper applications.
Handling Page Faults Case 1
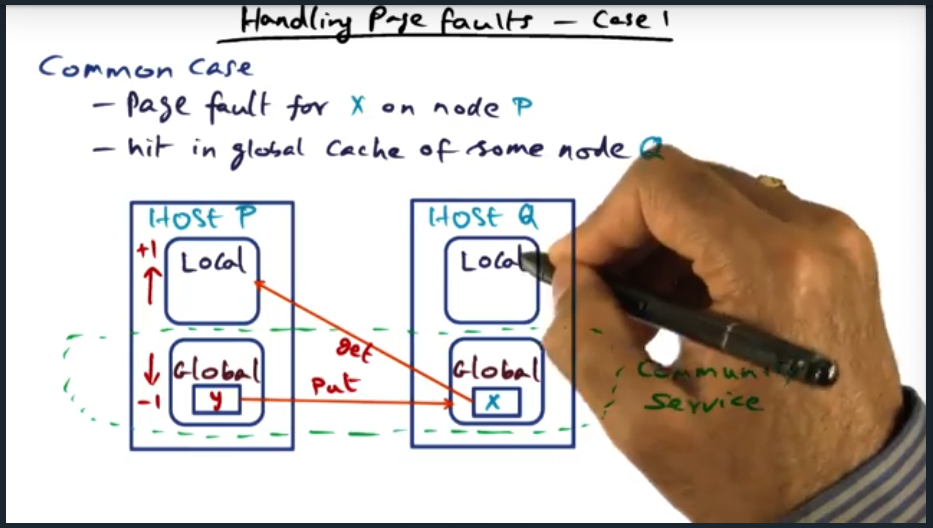
Summary
Most common use case is a page fault on a local node. When the page fault occurs, the node will get the data from some other node’s global cache, increase its local memory footprint by 1 page, and correspondingly decrease its global memory footprint by 1 page.
Handling Page Fault Case 2
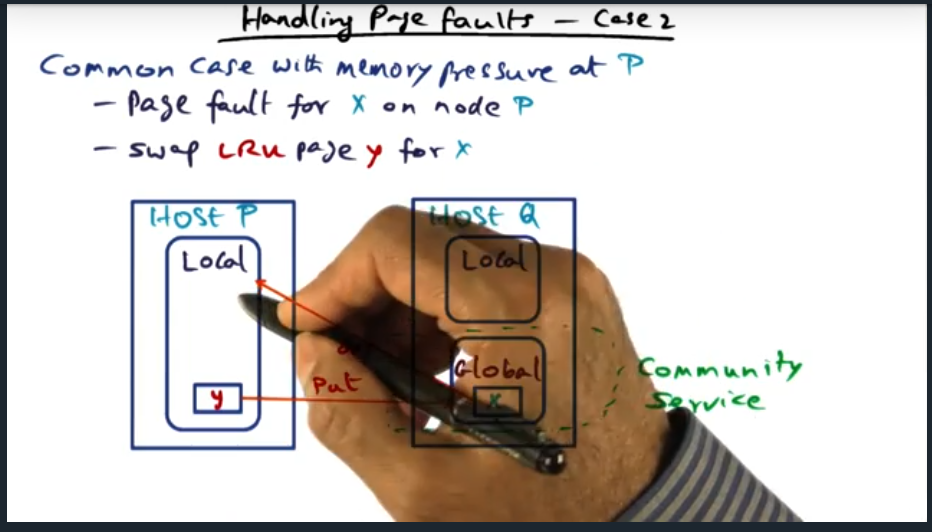
Summary
In the situation which a node has no global memory (i.e. its local memory entirely consumed by working set), then the host handle a page fault by evicting a local page (i.e. finding a victim, usually through LRU page replacement policy), then requesting some page from another node’s global memory (i.e. the community service). What’s important to call out here is that there’s no changes in the number of local pages and no change in the number of global pages for the node.
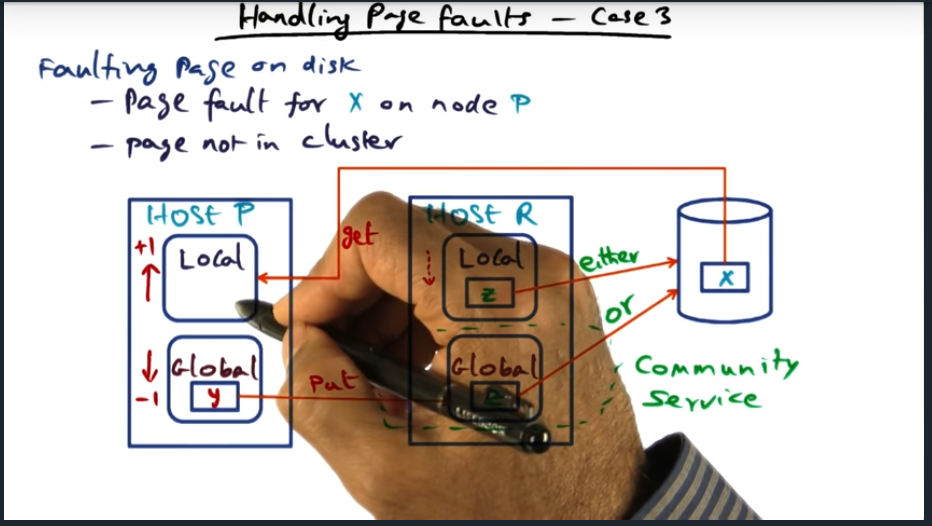
Handling Page Fault Case 3
Summary
Key Words: LRU, eviction, page fault
Key Take away here is that if the globally oldest page lives in local memory, then we can free it up and expand the globally available memory for community service. Also, something that cleared up for me is this: all pages sitting in the global memory are considered clean since global memory is just a facility as part of the page faulting process so we can assume all pages are clean. But that’s not true for local pages, meaning, if we evict a page from local memory and its dirty, we must first write it out to disk
Handling Page Faults Case 4

Summary
This is a tricky scenario, the only scenario in which a page lives in the working set on two nodes simultaneously.
Local and Global Boundary Quiz

Summary
Difficult quiz, actually. On Disk is not applicable for Node Q with Page X. And depends what happens with globally LRU (least recently used) stored in local, or global, part.
Behavior of Algorithm
Summary
Basically, if there’s an idle node, its main responsibility will be accommodating peer pages. But once the node becomes busy, it will move pages into its working set