
I divided studying into two sessions: one in the morning (around 04:30 am) and one in the evening after work and after my daughter has gone to bed. In the morning, I completed the administrative tasks and watched lectures that cover new material and in the evening I refreshed my memory by taking the operating systems review course.

Study Session
Administrative Tasks
Yesterday I was able to put in about 3 of study time, half the time in the early morning at 04:45 AM and half the time after work at around 06:00 pm. In the morning, while still somewhat drowsy, I completed the administrative tasks: setting up notifications in Canvas, introducing myself in Piazza, on-boarding to a new proctoring platform called Honorlock (so annoying since this software requires installing the Chrome browser, no support for Firefox).

Advanced OS material (Lesson 1)
After completing the administrative tasks, I started watching lesson 1, covering the first two modules titled “Principles of Abstraction” and “Hardware Resources”, both sequence of videos pretty short in length (maybe 10 minutes for each module). The former introduced the concept of abstraction, defining it as an interface that hides complexity of the subcomponents. In addition, the module describes the different levels of abstraction, starting from a transistor, all the way to the application layer, including all the components in between: logic gates, sequence and combination logic elements, machine organization, instruction set architecture (ISA), System Software, and Applications. In the second module, we cover the two types of buses — system bus (high speed) and I/O bus — and how they are connected via a bridge, the component responsible for proxying and controlling access to these buses.
That was what I covered in the morning. During my second study session in the evening, I actually context switched (OS term) from watching advanced operating system lectures to the course refresher that cover the operating system fundamentals, a course refresher, intended to provide a recap of undergraduate OS materials.
Course Refresher
During this course refresher, my brain started slowly recalling the various system concepts of memory systems. Here’s a quick recap of what I was able to remember from taking four system courses (i.e. computer organization, operating systems, high performance computing architecture, and compilers):
- Naive Memory Model – Normally we think that memory access is fast. But that’s an oversimplification and it is much more nuanced. In fact, underneath the hood, there are cache systems (i.e. L1, L2, L3 cache)
- Cache Motivation – We can speed up memory access by a factor of 10 by introducing a cache. That speed up can reduce the number of cycles from 100 down to a meager 4. Continuing with this example, a 99% hit rate will yield 4.96 cycles on average, 90% hit rate of 13.6 cycles (huge difference)
- Memory Hierarchy – Given that we want the cache rate to be high and fast, how do we make the right trade offs? By creating a memory hierarchy: registers, L1, L2, L3, then memory, which can also serve as a cache for disks too. As we move down the hierarchy, speed reduces as well as the cost.
- Locality and Cache Blocks – To populate our cache, we apply two heuristics: temporal (i.e. address we just accessed we are more likely to access again) and space locality (i.e. addresses adjacent to most recent address are more likely to be accessed). We store addresses in cache blocks, which can vary in size depending on design
- Direct Mapping – Each memory address can live in only one cache line. This is easy to manage but one downside is thrashing, a situation in which one cache line continues to get evicted over and over despite other cache lines unused.
- Set Associative Mapping – One way to overcome the limitation of direct mapping (mentioned previously) is to use set associative mappings: a cache line can live in multiple cache lines. The trade off? Need to implement some sort of cache evication algorithm (e.g. least recently used) and will need to look up tag (most significant bits of the address) in multiple cache lines
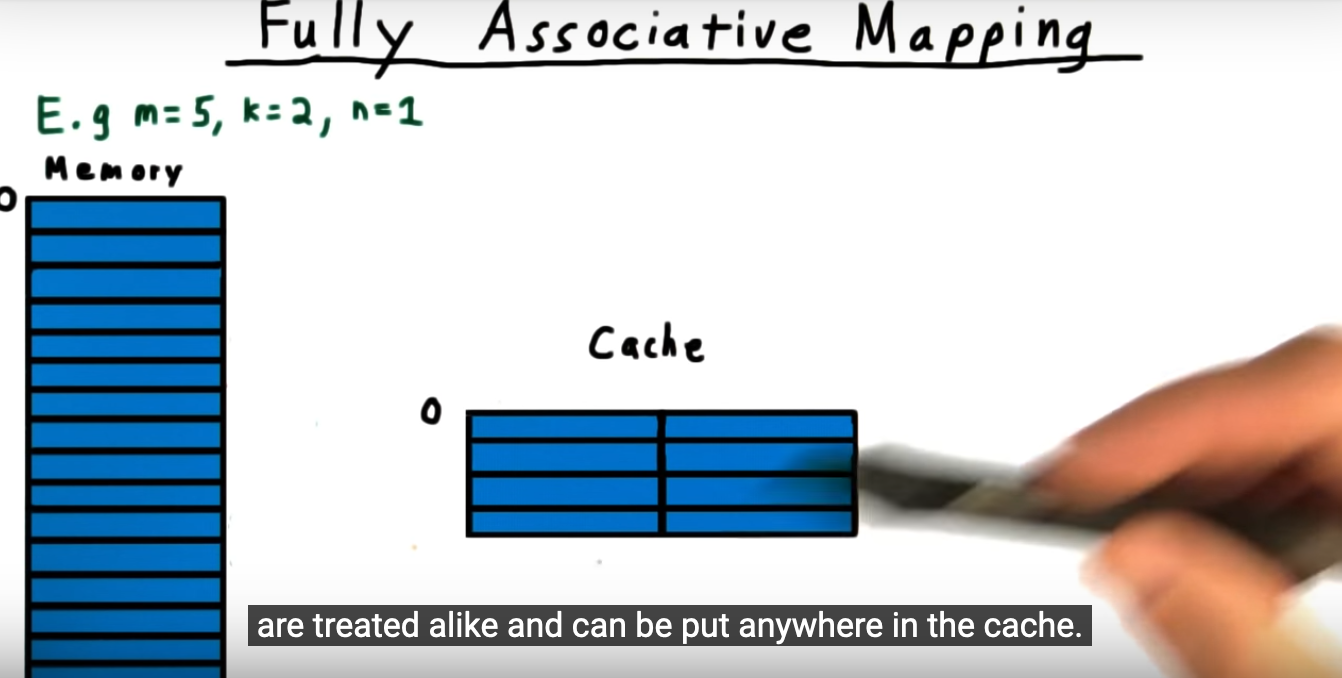
- Fully Associative set – Any address can live at any cache line. Basically, the index bits (equal to number of cache entries) is now 0 (when it was previously equal to number of cache entries). Similiar to both the direct and set associative sets, we still use the offset (n bits, where n is equal to number of bytes within each block)
- Write Policy – write-through (write to both cache and memory, keeping two consistent) and write-back (only writes to cache, beneficial when writing to same block many times before being evicted) and write-allocate (read into cache, then choose one of the two write strategies) and no-write-allocate (bypass cache and just write to memory). The relationship between these policies?
Summary
Reviewing the course materials is worth it. I particularly liked reviewing caches and reveled in the fact that I remembered how to calculating the tags (adding the index and offset bits, subtracting them from the address space). Seeing the same topics over and over reminds me of what’s important in systems and computer organization.