RioVista picks up where LRVM left off and aims for a performance conscience transaction. In other words, how can RioVista reduce the overhead of synchronous I/O, attracting system designers to use transactions
System Crash
Two types of failures: power failure and software failure
Key Words: power crash, software crash, UPS power supply
Super interesting concept that makes total sense (I’m guessing this is actually implemented in reality). Take a portion of the memory and battery back it up so that it survives crashes
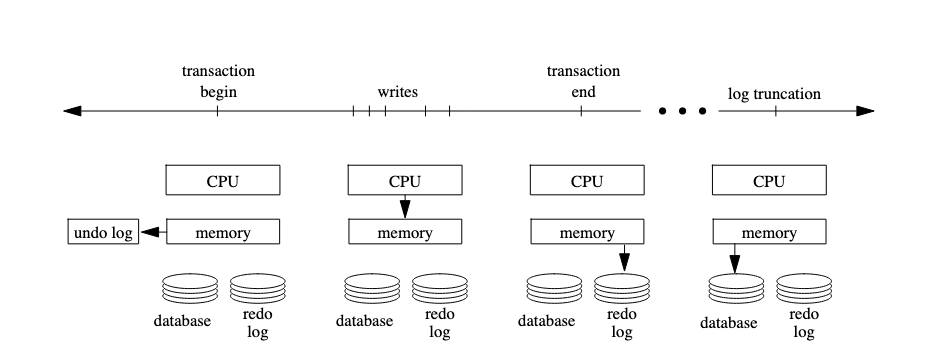
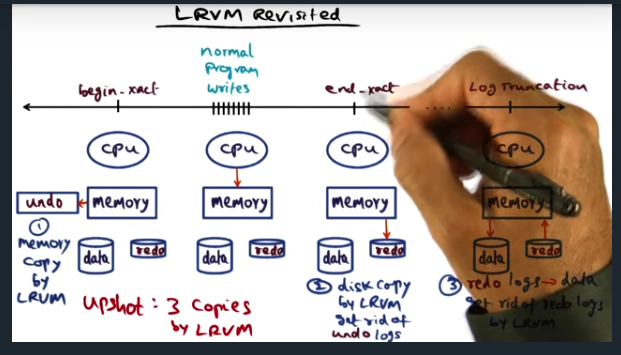
LRVM Revisited
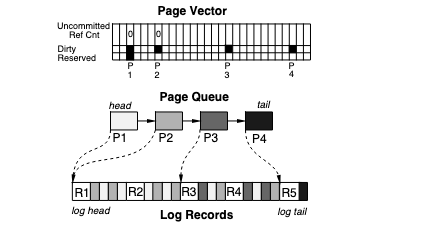
Upshot: 3 copies by LRVM
Key Words: undo record, window of vulnerability
In short, LRVM can be broken down into begin transaction, end transaction. In the former, portion of memory segment is copied into a backup. At the end of the transaction, data persisted to disk (blocking operation, but can be bypassed with NO_FLUSH option). Basically, increasing vulnerability of system to power failures in favor of performance. So, how will a battery backed memory region help?
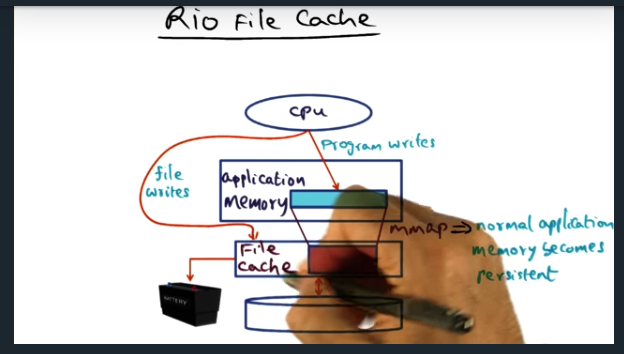
Rio File Cache
Creating a battery backed file cache to handle power failures
In a nutshell, we’ll use a battery backed file cache so that writes to disk can be arbitrarily delayed
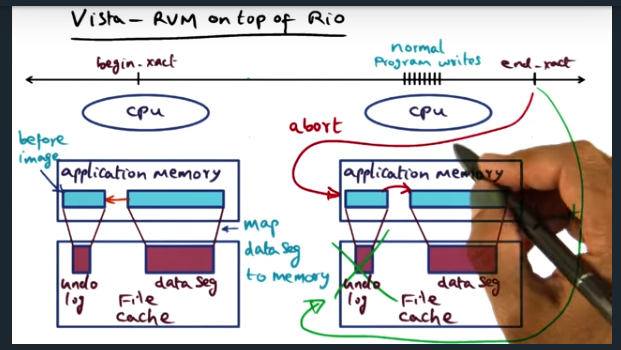
Vista RVM on Top of RIO
Vista – RMV on top of Rio
Key Words: undo log, file cache, end transaction, memory resisdent
Vista is a library that offers same semantics of LRVM. During commit, throw away the undo log; during abort, restore old image back to virtual memory. The application memory is now backed by file cache, which is backed by a power. So no more writes to disk
Crash Recovery
Key Words: idempotency
Brilliant to make the crash recovery mechanism the exact same scenario as an abort transaction: less code and less edge cases. And if the crash recovery fails: no problem. The instruction itself is idempontent
Vista Simplicity
Key Words: checkpoint
RioVista simplifies the code, reducing 10K of code down to 700. Vista has no redo logs, no truncation, all thanks to a single assumption: battery back DRAM for portion of memory
Conclusion
Key Words: assumption
By assuming there’s only software crashes (not power), we can come to an entirely different design
As system designers, we can make persistence into the virtual memory manager, offering persistence to application developers. However, it’s no easy feat: we need to ensure that the solution performs well. To this end, the virtual machine manager offers an API that allows developer to wrap their code in transactions; underneath the hood, the virtual machine manager uses redo logs that persists the user changes to disk which can defend against failures.
We can bake persistent into the virtual memory manager (VMM) but building an abstraction is not enough. Instead, we need to ensure that the solution is performant and instead of committing each VMM change to disk, we aggregate them into a log sequence (just like the previous approaches in distributed file system) so that 1) we write in a contiguous block
Server Design
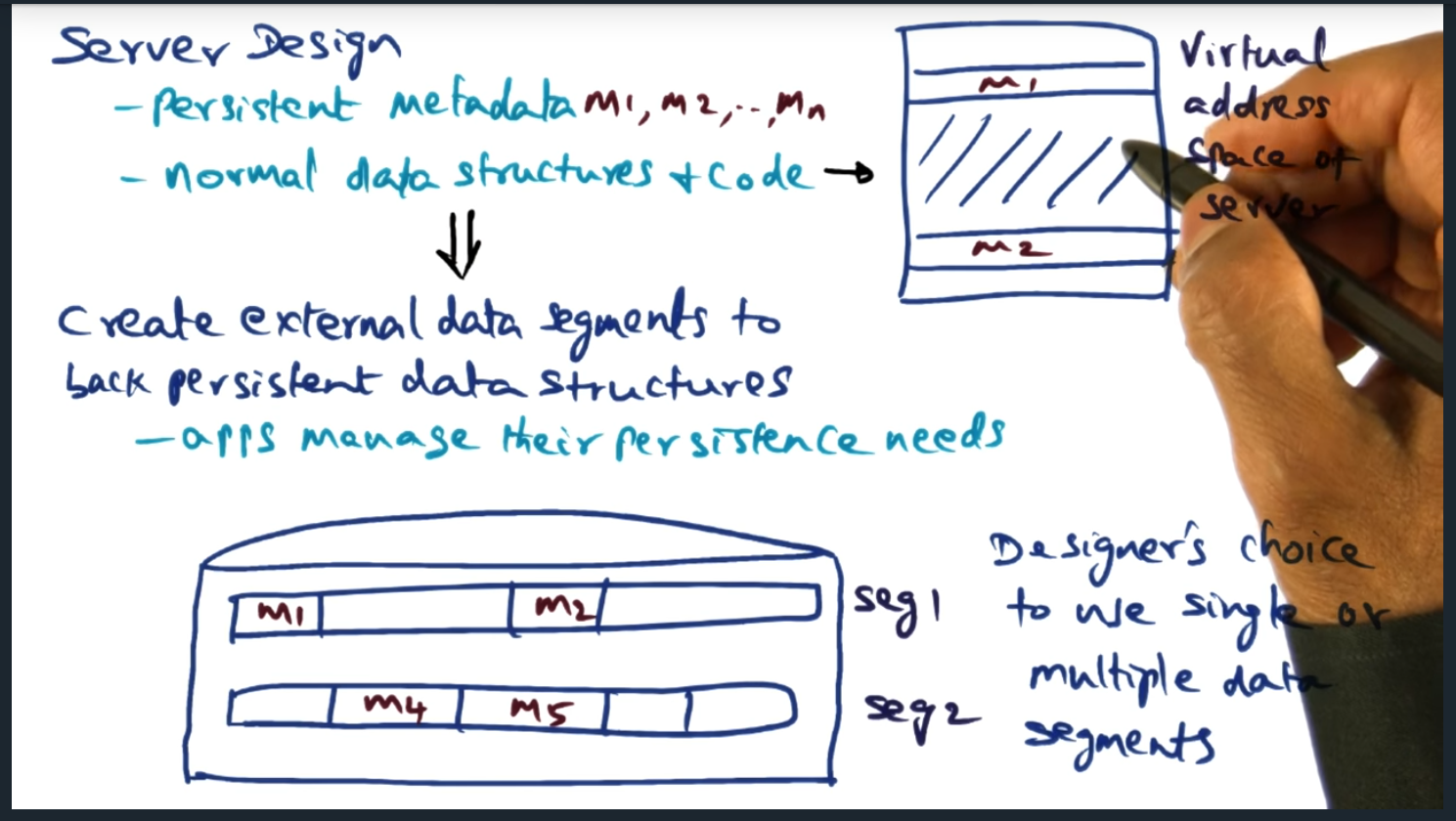
Server Design – persist metadata, normal data structures
Key Words: inodes, external data segment
The designer of the application gets to decide which virtual addresses will be persisted to external data storage
Server Design (continued)
Key Words: inodes, external data segment
The virtual memory manager offers external data segments, allowing the underlying application to map portions of its virtual address space to segments backed by disk. The model is simple, flexible, and performant. In a nutshell, when the application boots up, the application selects which portions of memory must be persisted, giving the application developer full control
RVM Primitives
Key Words: transaction
RVM Primitives: initialization, body of server code
There are three main primitives: initialize, map, and unmap. And within the body of the application code, we use transactions: begin transaction, end transaction, abort transaction, and set range. The only non obvious statement is set_range: this tells the RVM runtime the specific range of addresses within a given transaction that will be touched. Meaning, when we perform a map (during initialization), there’s a larger memory range and then we create transactions within that memory range
RVM Primitives (continued)
RVM Primitives – transaction code and miscellaneous options
Key Words: truncation, flush, truncate
Although RVM automatically handles the writing of segments (flushing to disk and truncating log records), application developers can call those procedures explicitly
How the Server uses the primitives
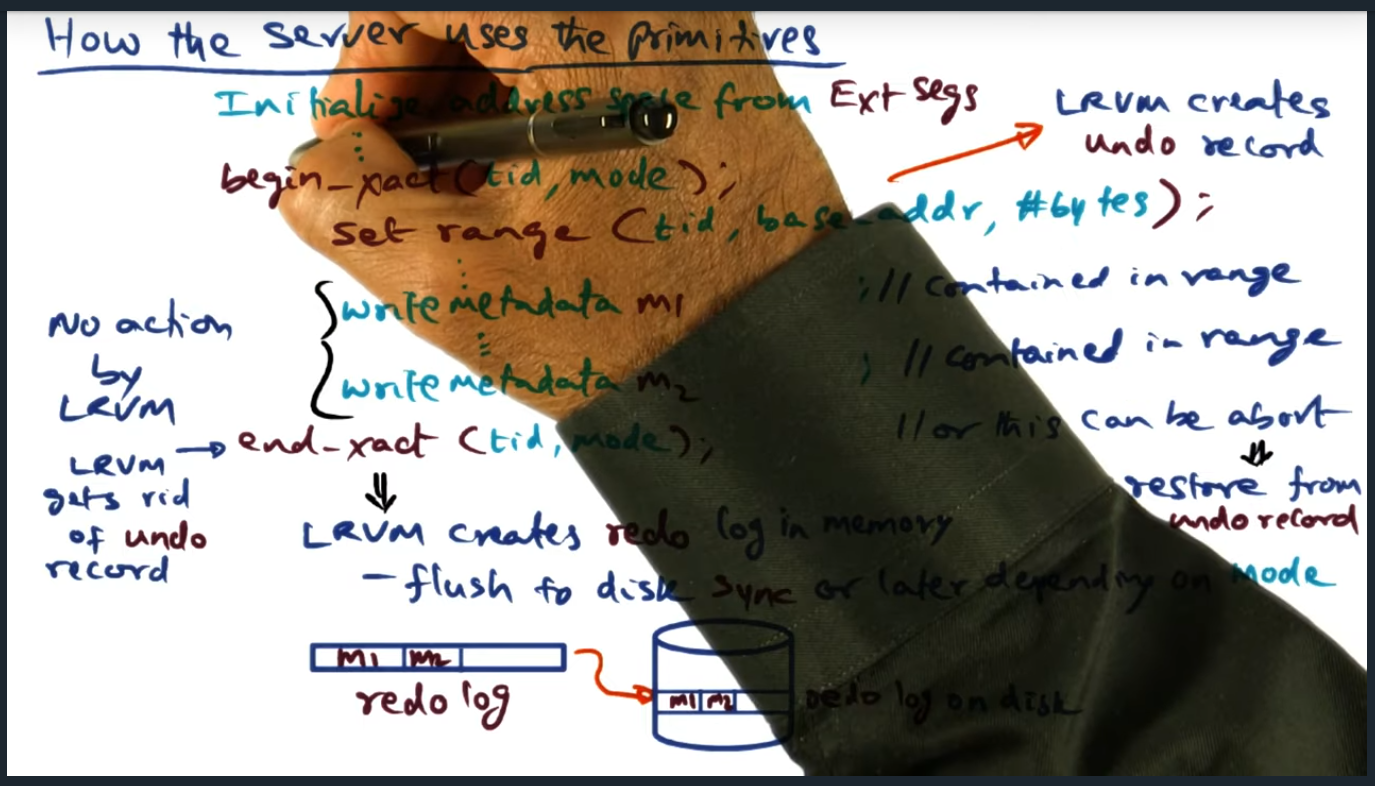
How the server uses the primitives – begin and end transaction
Key Words: critical section, transaction, undo record
When transaction begins, the LRVM creates an undo record: a copy of the range specified, allowing a rollback in the event an abort occurs
How the Server uses the primitives (continued)
How the server uses the primitives – transaction details
Key Words: undo record, flush, persistence
During end transaction, the in memory redo log will get flushed to disk. However, by passing in a specific mode, developer can explicitly not call flush (i.e. not block) and flush the transaction themselves
Transaction Optimizations
Transaction Optimizations – ways to optimize the transaction
Key Words: window of vulnerability
With no_restore mode in begin transaction, there’s no need to create a in memory copy; similarly, no need to flush immediately with lazy persistence; the trade off here is that there’s an increase window of vulnerability
Redo log allows traversal in both directions (reverse for recovery) and only new values are written to the log: this implementation allows good performance
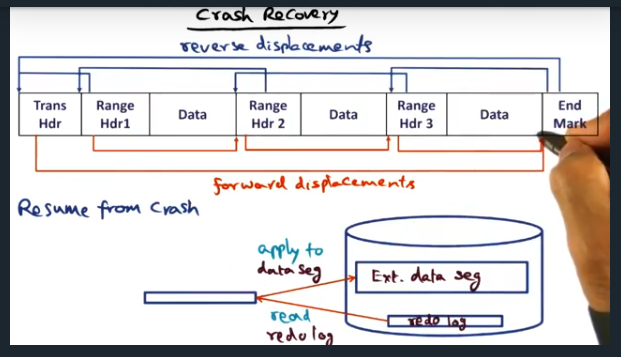
Crash Recovery
Crash Recovery – resuming from a crash
Key Words: crash recovery
In order to recover from a crash, the system traverses the redo log, using the reverse displacement.Then, each range of memory (along with the changes) are applied
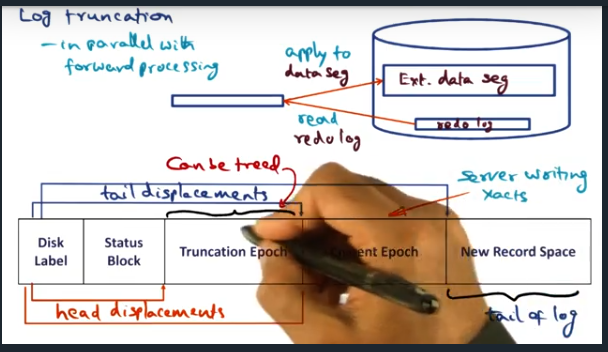
Log Truncation
Log truncation – runs in parallel with forward processing
Key Words: log truncation, epoch
Log truncation is probably the most complex part of LRVM. There’s a constant tug and pull between performance and crash recovery. Ensuring that we can recover is a main feature but it adds overhead and complexity since we want the system to make forward progress while recovering. This end, the algorithm breaks up data into epochs
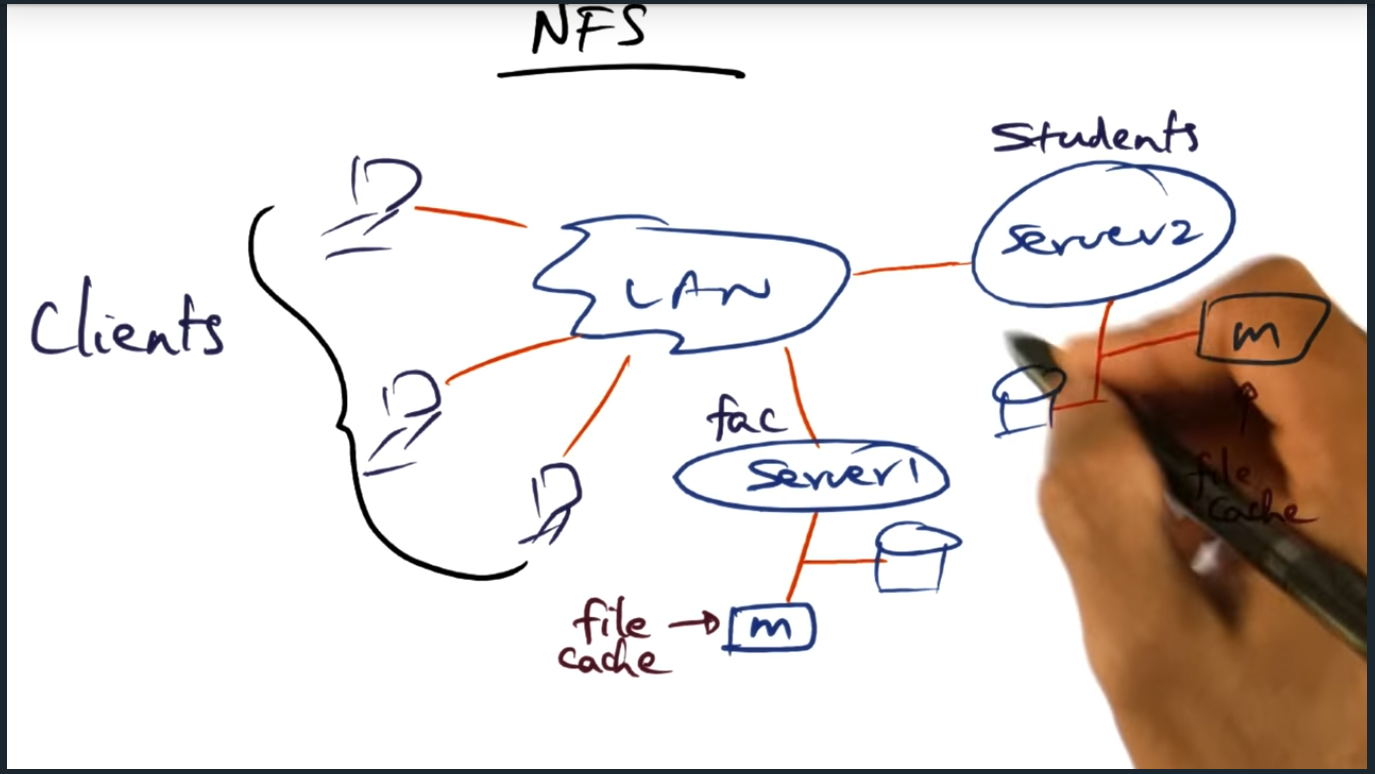
This lesson introduces network file system (NFS) and presents the problems with it, bottlenecks including limited cache and expensive input/output (I/O) operations. These problems motivate the need for a distributed file system, in which there is no longer a centralized server. Instead, there are multiple clients and servers that play various roles including serving data
Quiz
Key Words: computer science history
Sun built the first ever network file system back in 1985
NFS (network file system)
NFS – clients and server
Key Words: NFS, cache, metadata, distributed file system
A single server that stores entire network file system will bottle neck for several reasons, including limited cache (due to memory), expensive I/O operations (for retrieving file metadata). So the main question is this: can we somehow build a distributed file system?
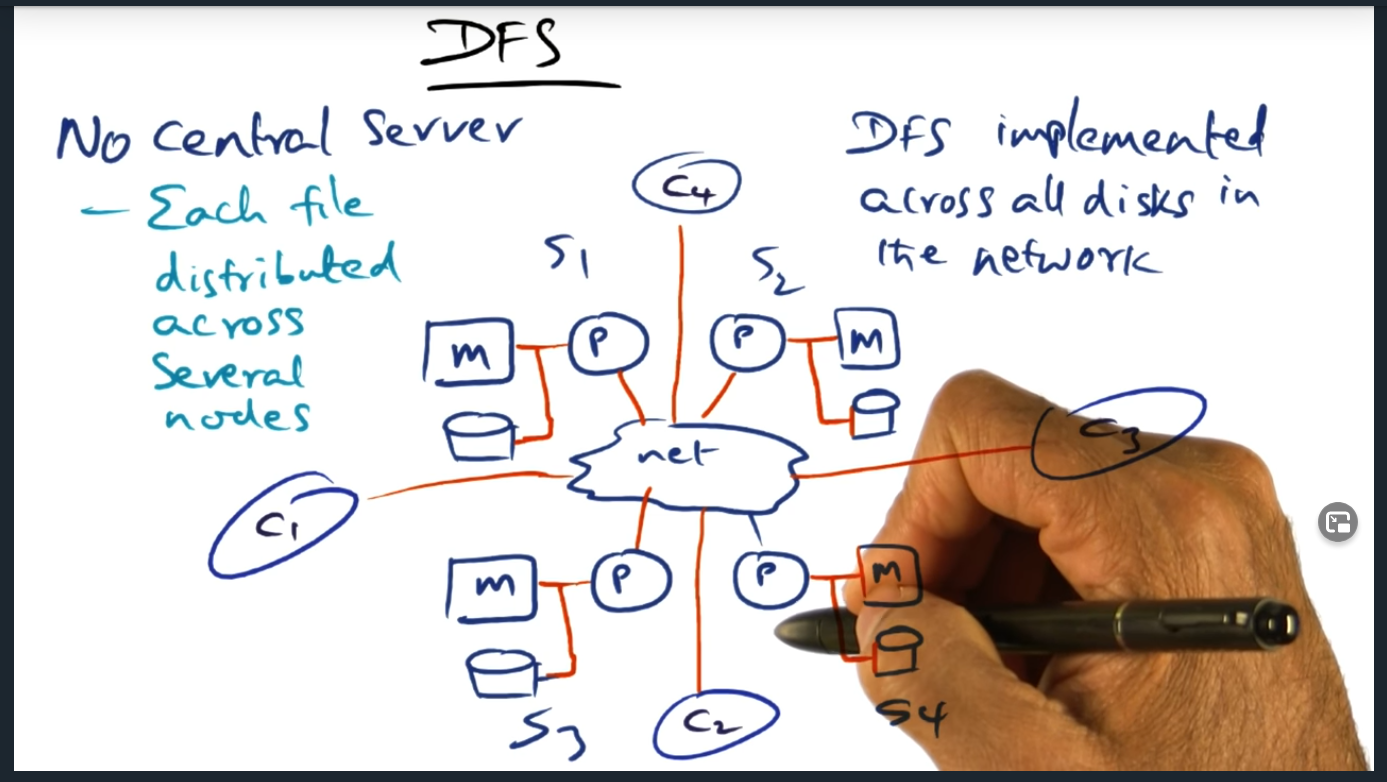
DFS (distributed file system)
Distributed File Server – each file distributed across several nodes
Key Words: Distributed file server
The key idea here is that there is no longer a centralized server. Moreover, each client (and server) can play the role of serving data, caching data, and managing files
Lesson Outline
Key Words: cooperative caching, caching, cache
We want to cluster the memory of all the nodes for cooperative caching and avoid accessing disk (unless absolutely necessary)
Preliminaries (Striping a file to multiple disks)
Key Words: Raid, ECC, stripe
Key idea is to write files across multiple disks. By adding more disks, we increase the probability of failure (remember computing those failures from high performance computing architecture?) so we introduce a ECC (error correcting) disk to handle failures. The downside of striping is that it’s expensive, not just in cost (per disk) but expensive in terms of overhead for small files (since a small file needs to be striped across multiple disks)
Preliminaries
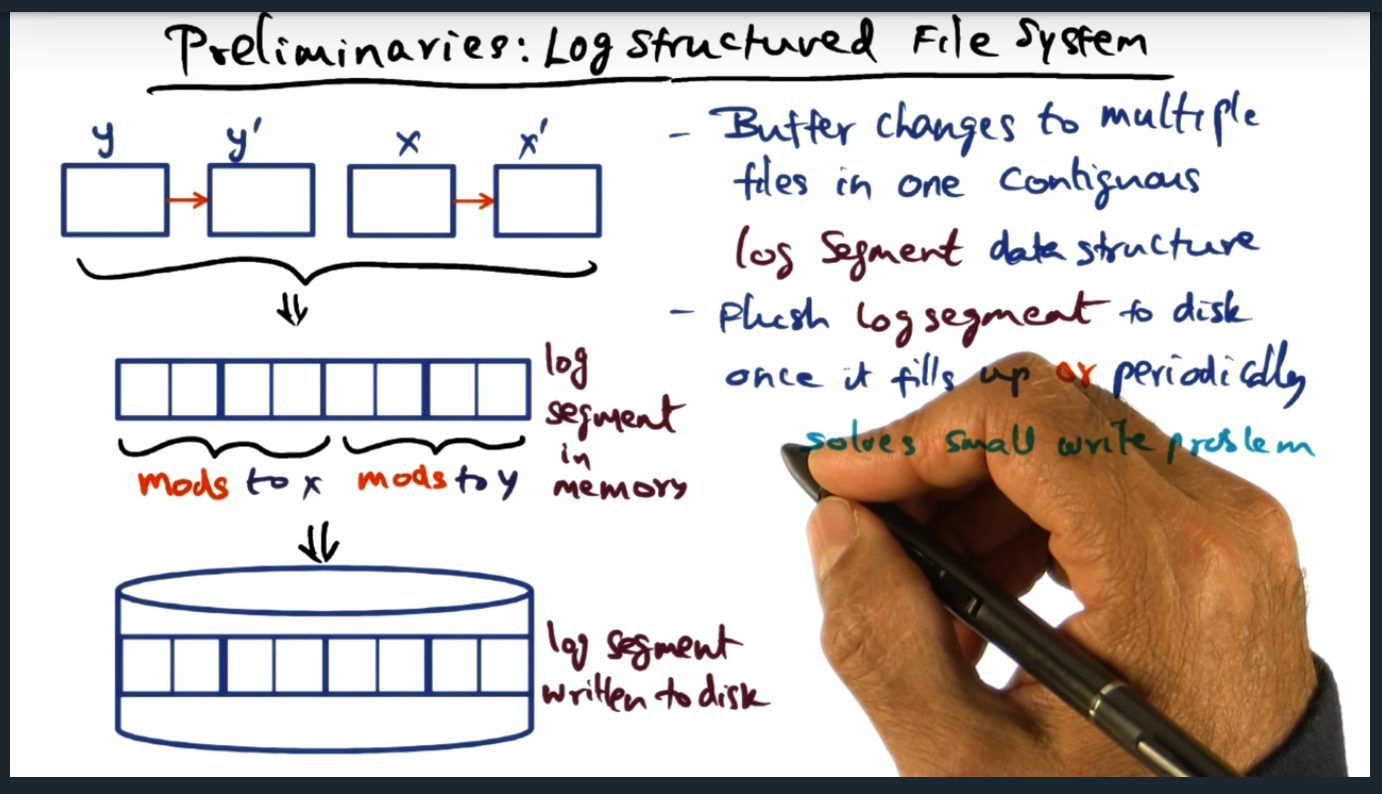
Preliminaries: Log structured file system
Key Words: Log structured file system, log segment data structure, journaling file system
In a log structured file system, the file system will store changes to a log segment data structure, the file system periodically flushing the changes to disk. Now, anytime a read happens, the file is constructed and computed based off of the delta (i.e. logs). The main problem this all solves is the small file problem (the issue with striping across multiple disks using raid). With log structure, we now can stripe the log segment, reducing the penalty of having small files
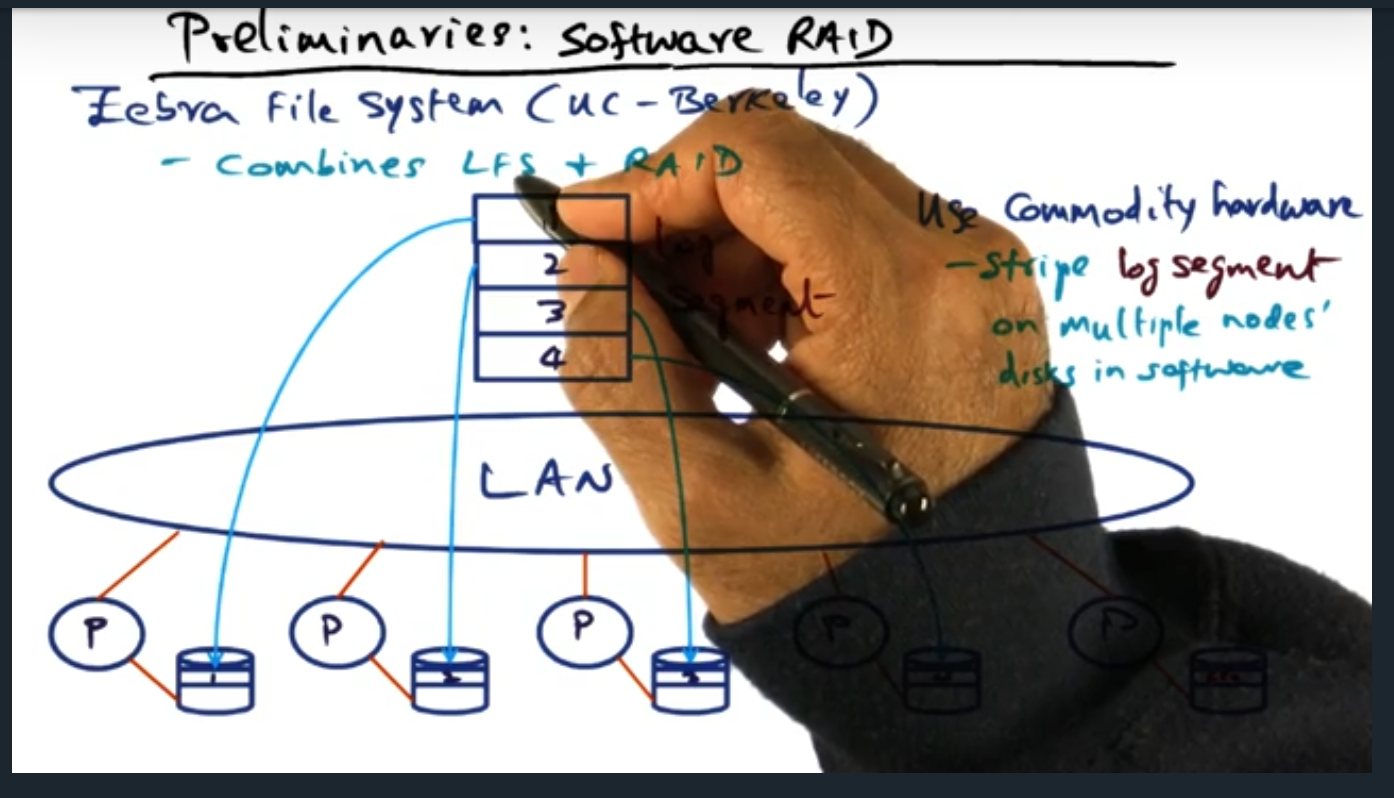
Preliminaries Software (RAID)
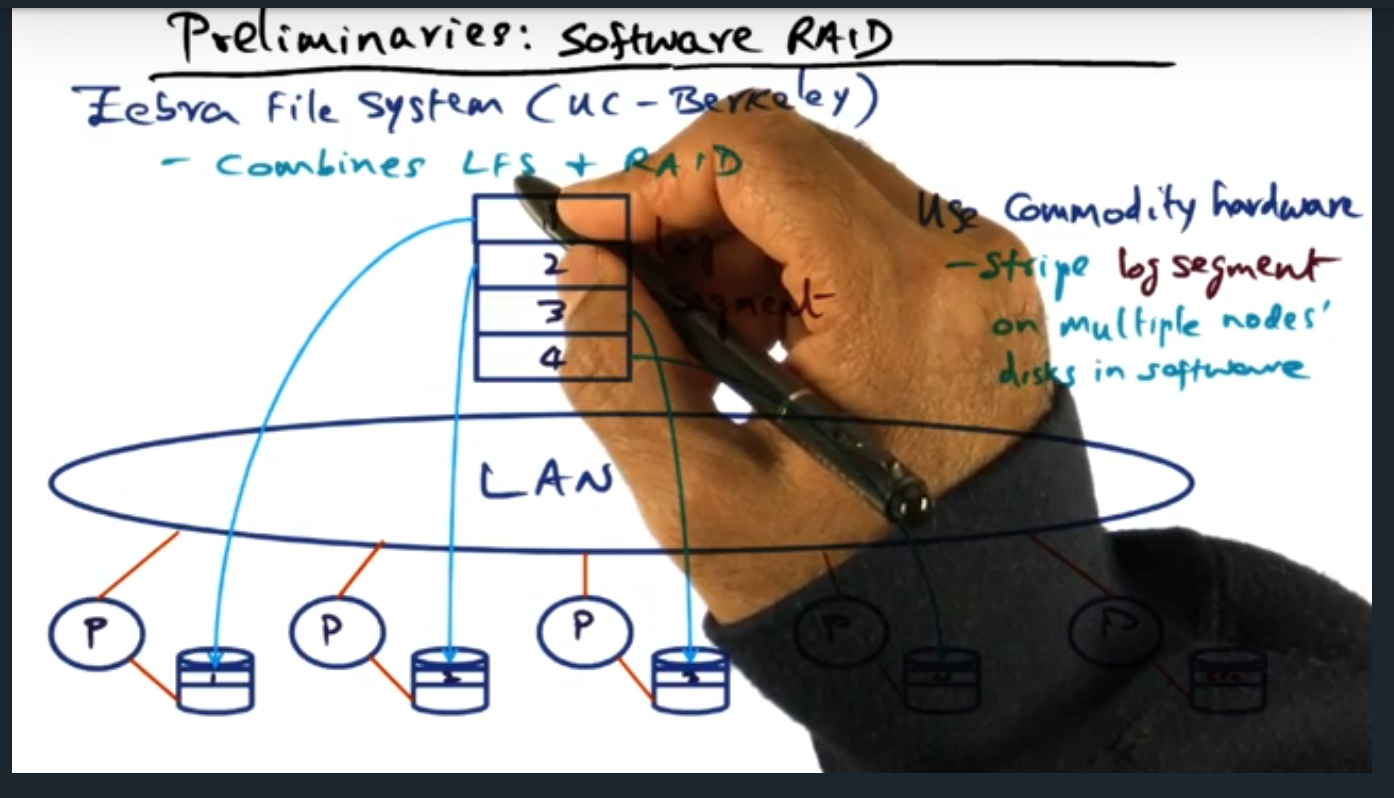
Preliminaries – Software Raid
Key Words: zebra file system, log file structure
The zebra file system combines two techniques for handling failures: log file structure (for solving the small file problem) and software raid. Essentially, error correction lives on a separate drive
Putting them all together plus more
Pputting them all together: log based, cooperative caching, dynamic management, subsetting, distributed
Key Words: distributed file system, zebra file system
The XFS file system puts all of this together, standing on top of the shoulders who built Zebra and built cooperating caching. XFS also adds new technology that will be discussed in later videos
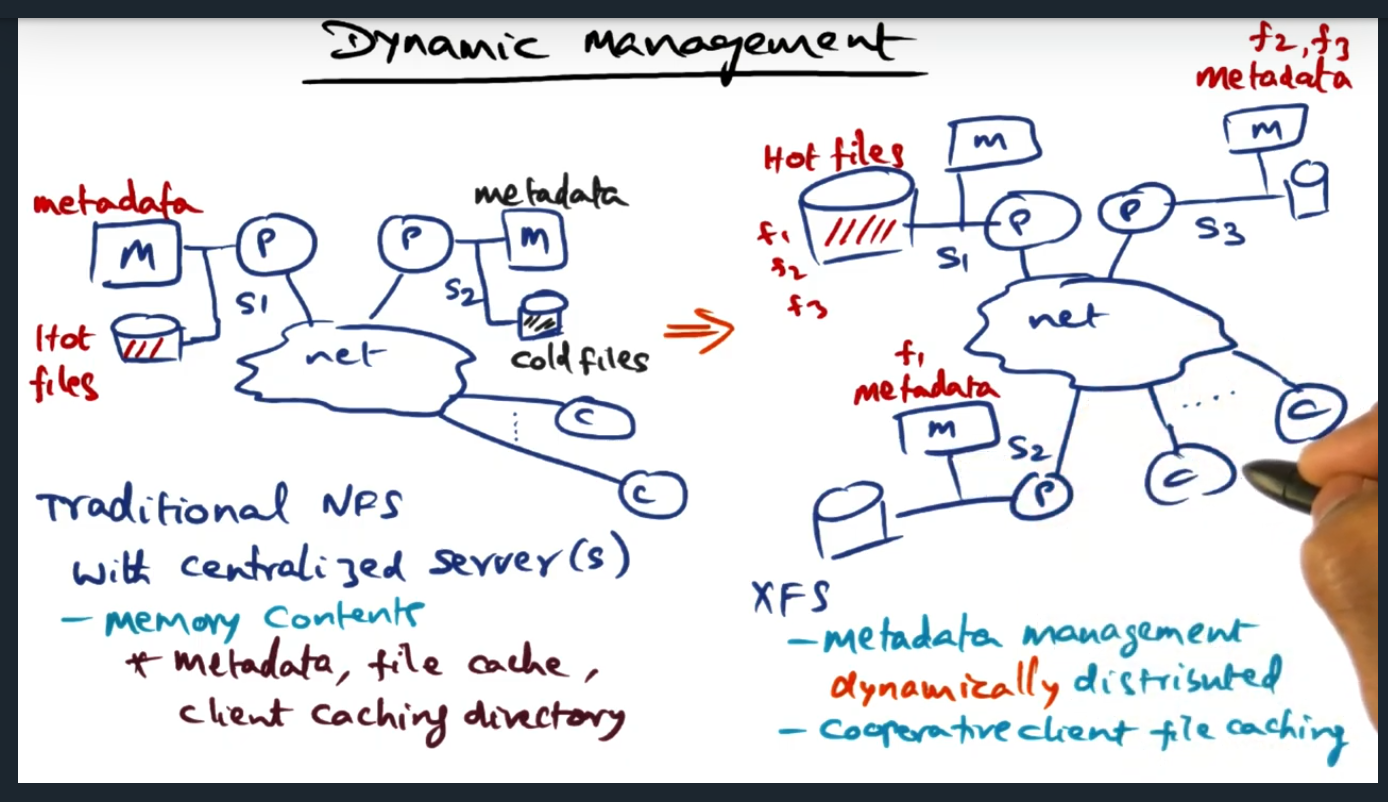
Dynamic Management
Dynamic Management
Key Words: Hot spot, metadata, metadata management
In a traditional NFS server, data blocks reside on disk and memory includes metadata. But in a distributed file system, we’ll extend caching to the client as well
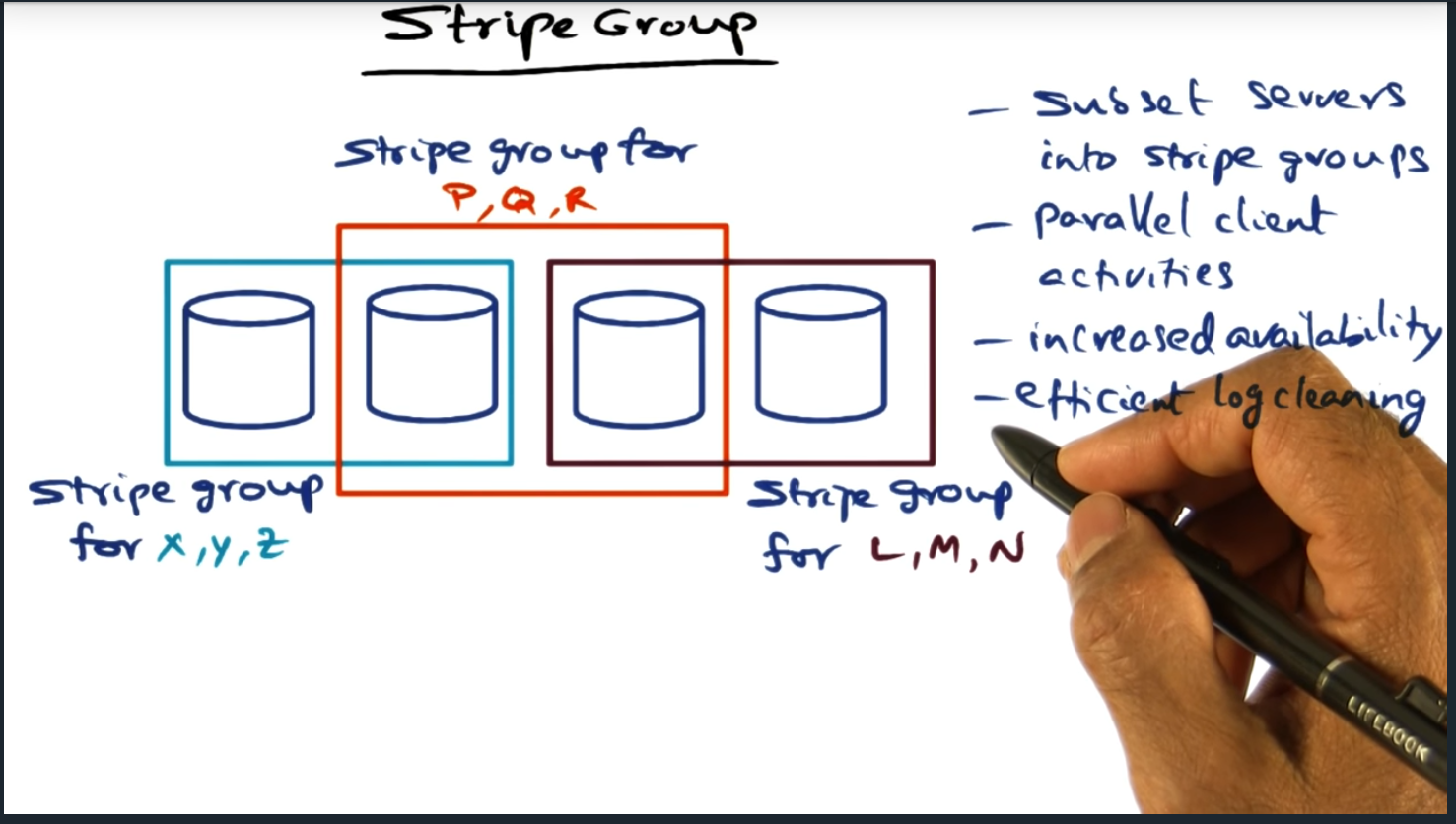
Log Based Striping and Stripe Groups
Log based striping and stripe groups
Key Words: append only data structure, stripe group
Each client maintains its own append only log data structure, the client periodically flushing the contents to the storage nodes. And to prevent reintroducing the small file problem, each log fragment will only be written to a subset of the storage nodes, those subset of nodes called the stripe group
Stripe Group
Stripe Group
Key Words: log cleaning
By dividing the disks into stripe groups, we promote parallel client activities and increases availability
Cooperating Caching
Cooperative Caching
Key Words: coherence, token, metadata, state
When a client requests to write (to a block), the manager (who maintains state, in the form of metadata, about each client) will cache invalidate the clients and grant the writer a token to write for a limited amount of time
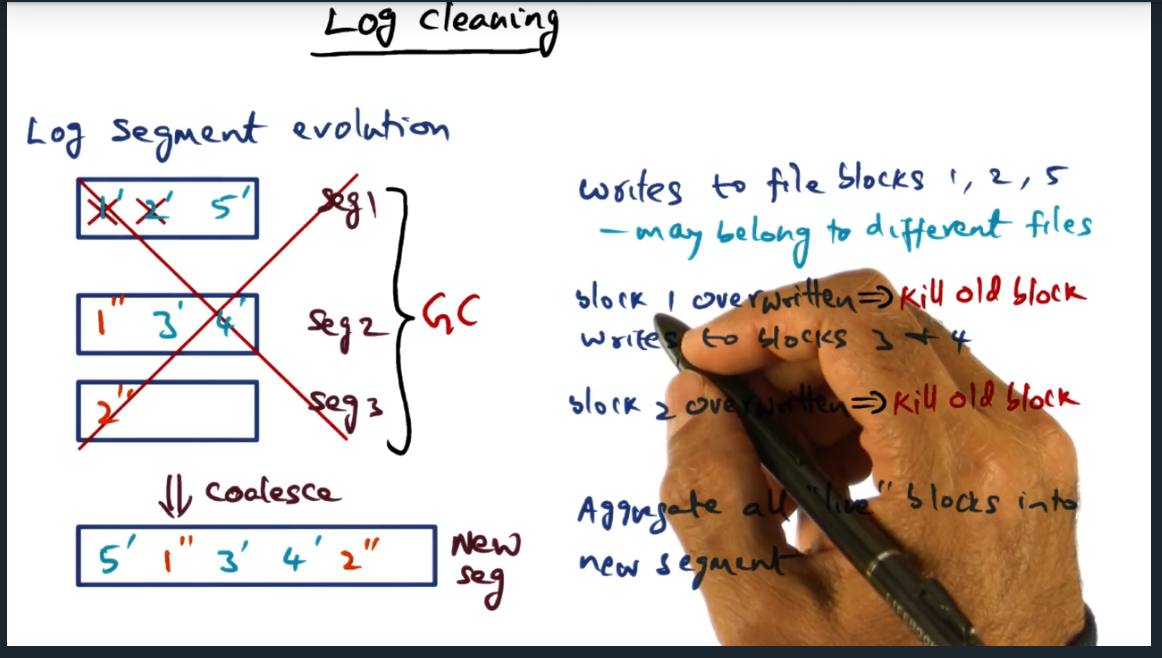
Log Cleaning
Log Cleaning
Key Words: prime, coalesce, log cleaning
Periodically, node will coalesce all the log segment differences into a single, new segment and then run a garbage collection to clean up old segments
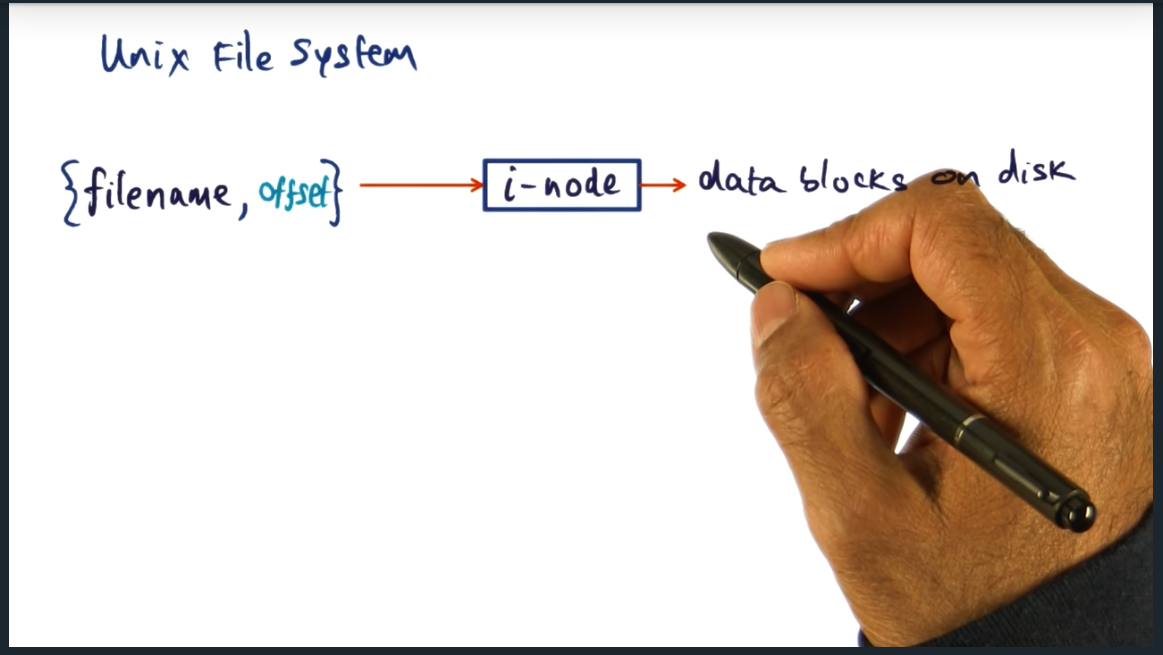
Unix File System
Unix File System
Key Words: inode, mapping
On any unix file system, there are inodes, which map filenames to data blocks on disk
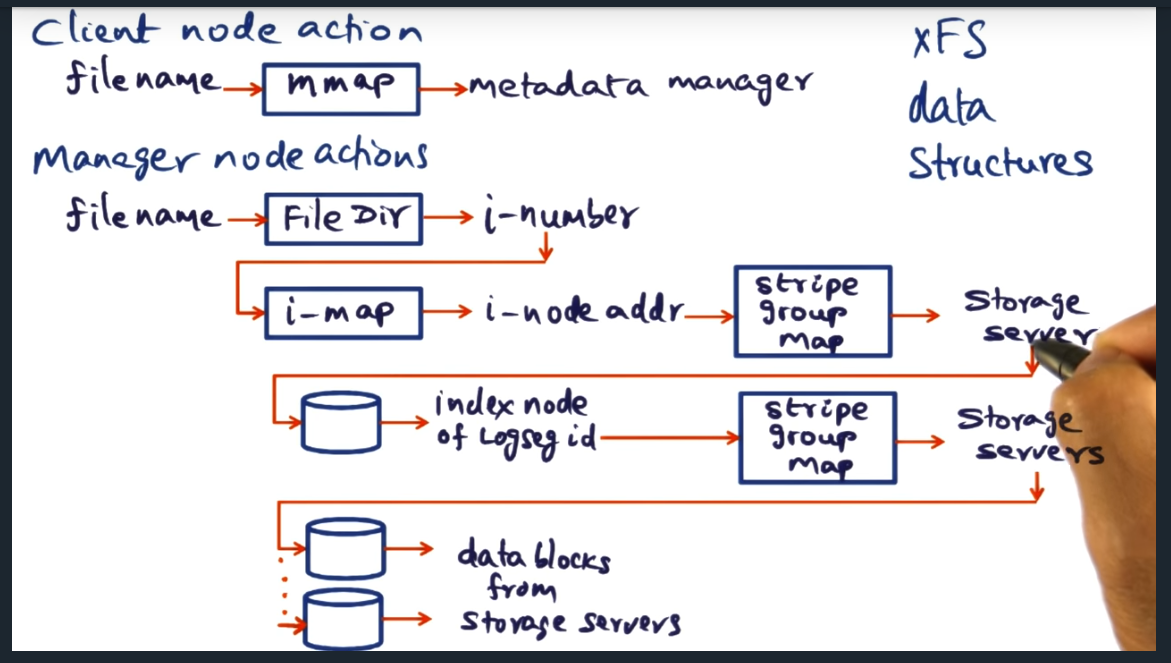
XFS Data Structures
XFS Data Structures
Key Words: directory, map
Manager node maintains data structures to map a filename to the actual data blocks from the storage servers. Some data structures include the file directory, and i_map, and stripe group map
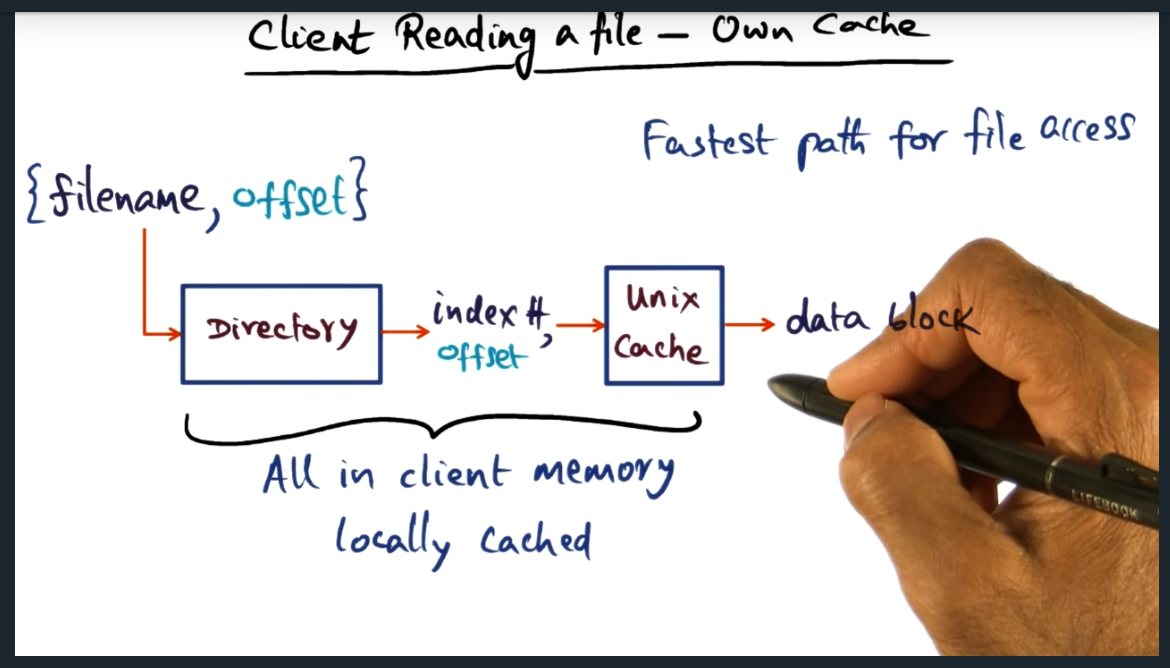
Client Reading a file own cache
Client Reading a file – own cache
Key Words: Pathological
There are three scenarios for client reading a file. The first (i.e. best case) is when the data blocks sit in the unix cache of the host itself. The second scenario is the client querying the manager, and the manager signals another peer to send its cache (instead of retrieving from disk). The worst case is the pathological case (i.e. see previous slide) where we have to go through the entire road map of talking to manager, then looking up metadata for the stripe group, and eventually pulling data from the disk
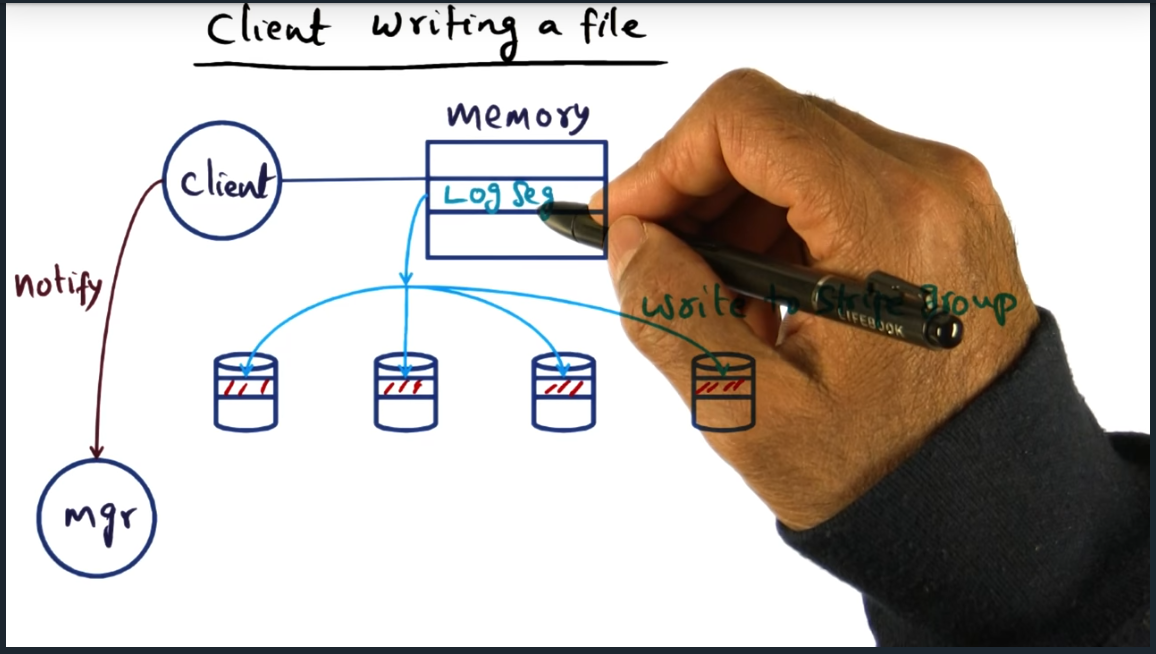
Client Writing a File
Client Writing a file
Key Words: distributed log cleaning
When writing, client will send updates to its log segments and then update the manager (so manager has up to date metadata)
Conclusion
Techniques for building file systems can be reused for other distributed systems
in the concrete example (screenshot below), P1 instructions that update memory (e.g. flag = 1) can be run in parallel with that of P2 because of release consistency model
Advantage of RC over SC
Summary
In a nutshell, we gain performance in a shared memory model using release consistency by overlapping computation with communication, because we no longer wait for coherence actions for every memory access
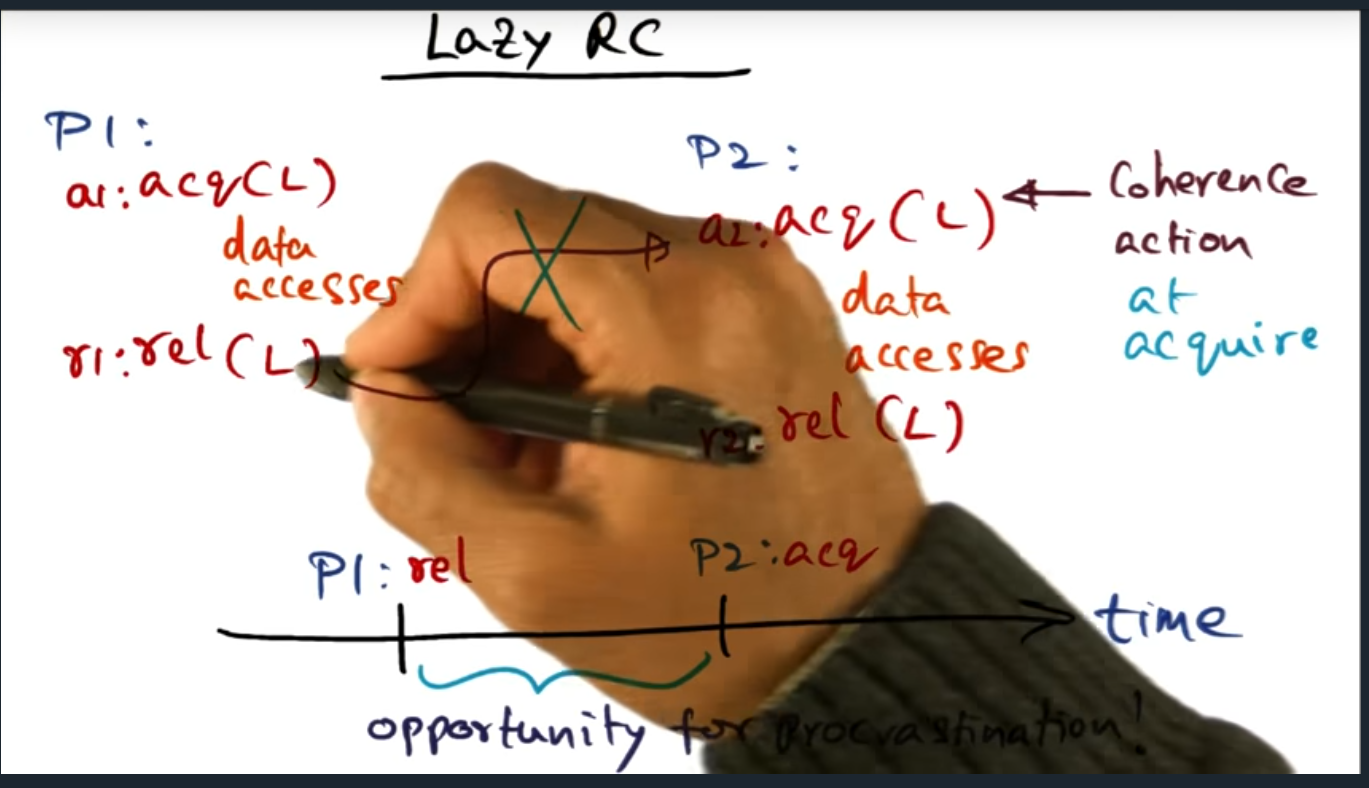
Lazy RC (release consistency)
Lazy Release Consistency
Summary
Key Words: Eager
The main idea here is that the “release consistency” is eager, in the sense that cache coherence traffic is generated immediately after unlock occurs. But with lazy RC, we defer that cache coherence traffic until the acquisition
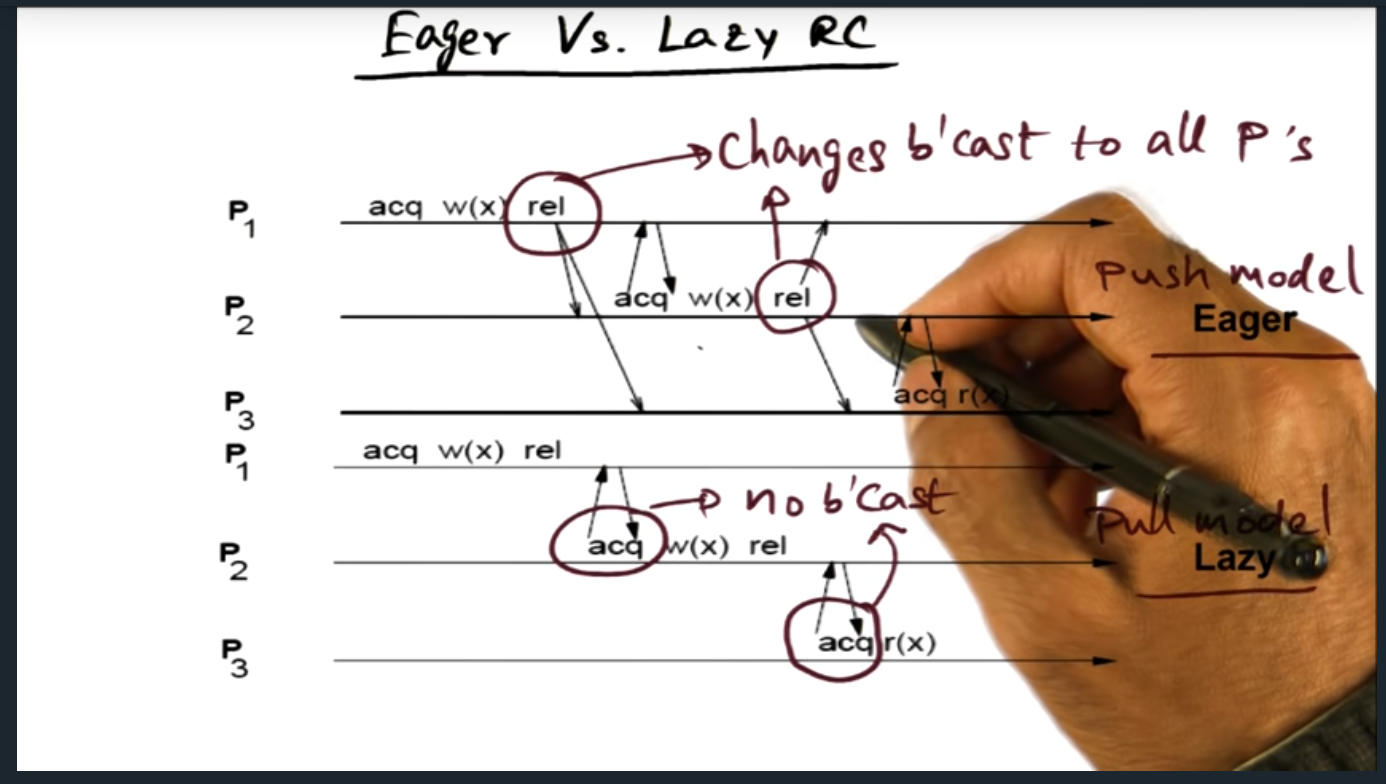
Eager vs Lazy RC
Eager vs Lazy Consistency
Summary
Key Words: Eager, Lazy
Basically, eager and lazy goes boils down to a push (i.e. eager) versus pull (i.e. lazy) model. In the former, every time the lock is released, coherence traffic broadcasts to all other processes
Pros and Cons of Lazy and Eager
Summary
Advantage of lazy (over eager) is that there are less messages however there will be more latency during acquisition
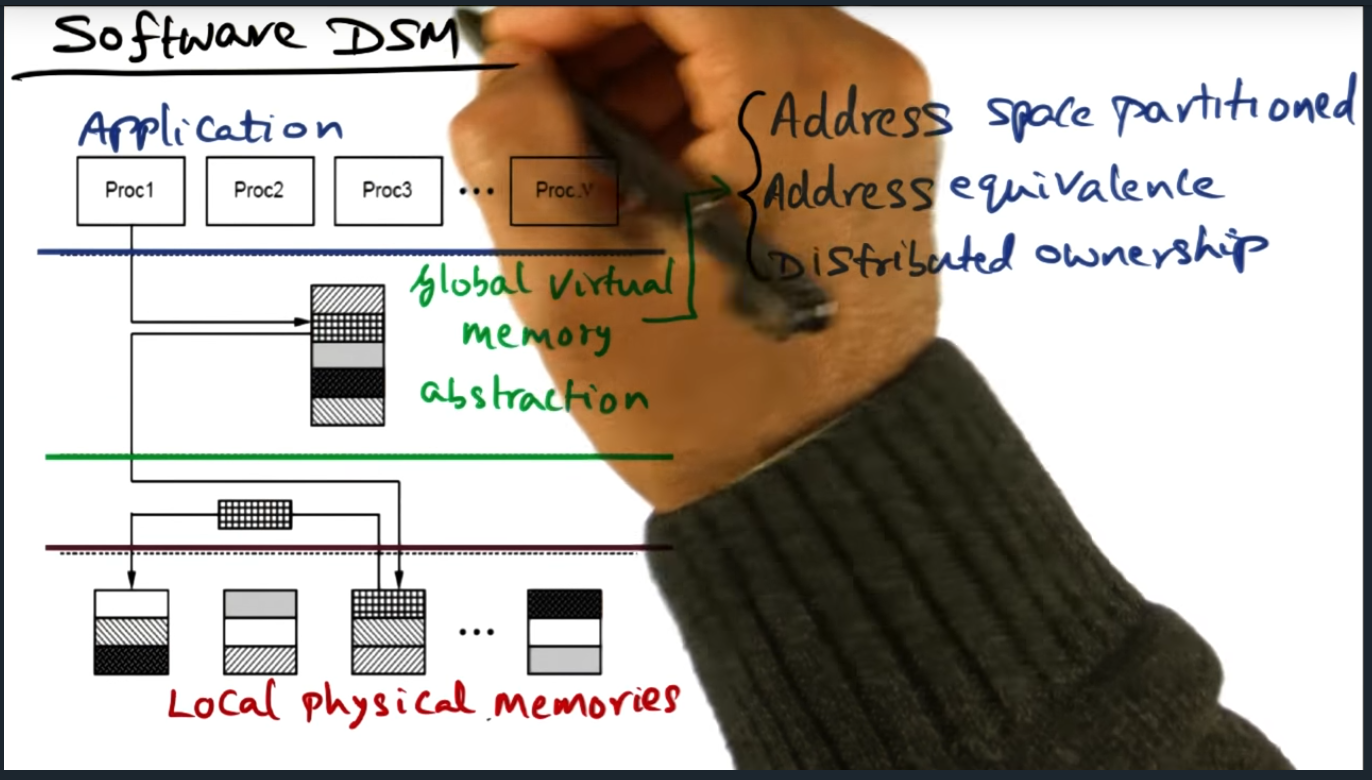
Software DSM
Software DSM
Summary
Address space is partitioned, meaning each processor is responsible for a certain set of pages. This model of ownership is a distributed, and each node holds metadata about the page and is responsible for sending coherence traffic (at the software level)
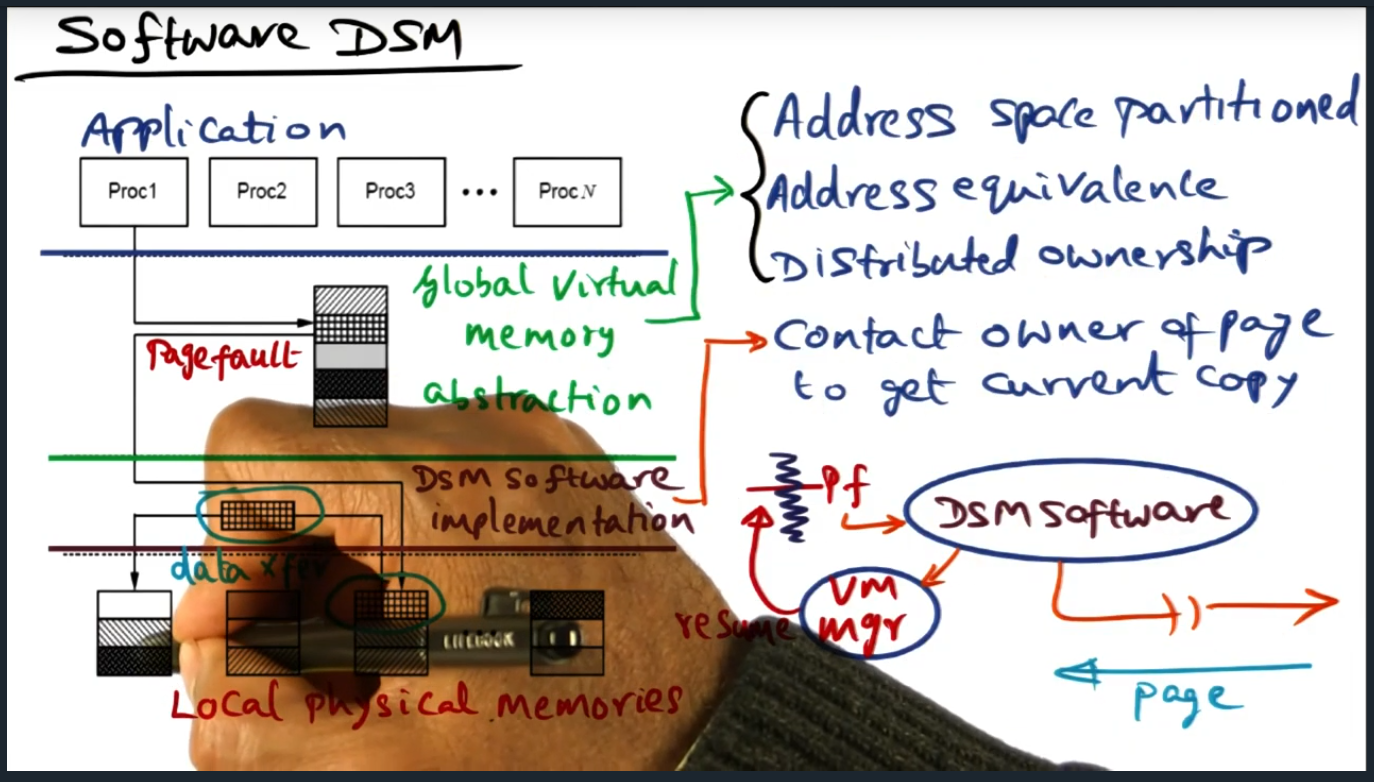
Software DSM (Continued)
Software DSM (continued)
Summary
Key Words: false sharing
DSM software runs on each processor (cool idea) in a single writer multiple reader model. This model can be problematic because, coupled with false sharing, will cause significant bus traffic that ping pongs updates when multiple data structures live within the same cache line (or page)
LRC with Mutli-Writer Coherence Protocol
Lazy Release Consistency with multi-writer coherence
Summary
With lazy release consistency, a process will (during the critical section) generate a diff of the pages that have been modified, the diff later applied when another process performs updates to those same pages
LRC with Multi-Writer Coherence Protocol (Continued)
Summary
Need to be able to apply multiple diffs in a row, say Xd and Xd’ (i.e. prime)
LRC with Multi Writer Coherence Protocol (Continued)
Summary
Key Words: Multi-writer
The same page can be modified at the same time by multiple threads, just so as long as a separate lock is used
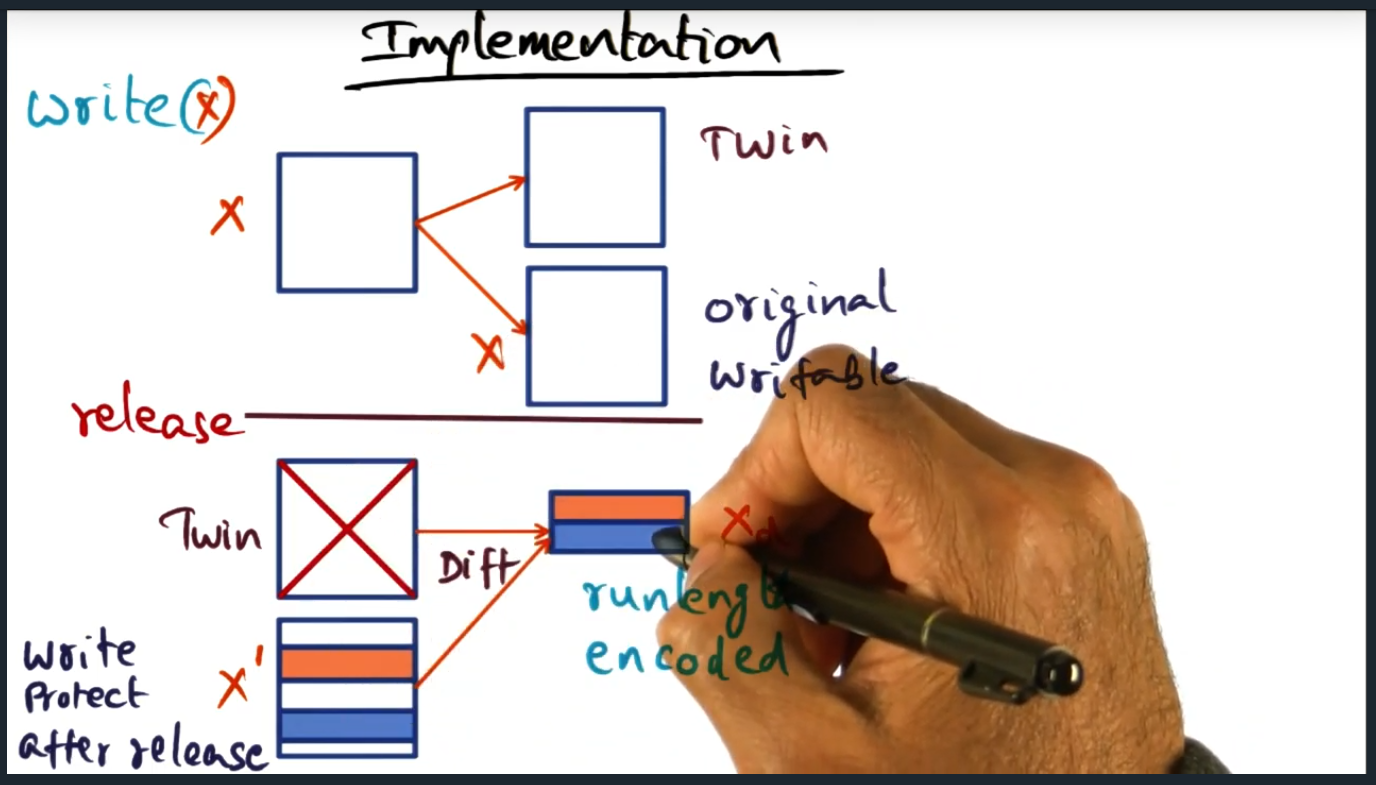
Implementation
Implementation of LRC
Summary
Key Words: Run-length encoded
During a write operation (inside of a lock), a twin page will get created, essentially a copy of the original page. Then, during release, a run-length encoded diff is computed. Following this step, the memory access is then write protected
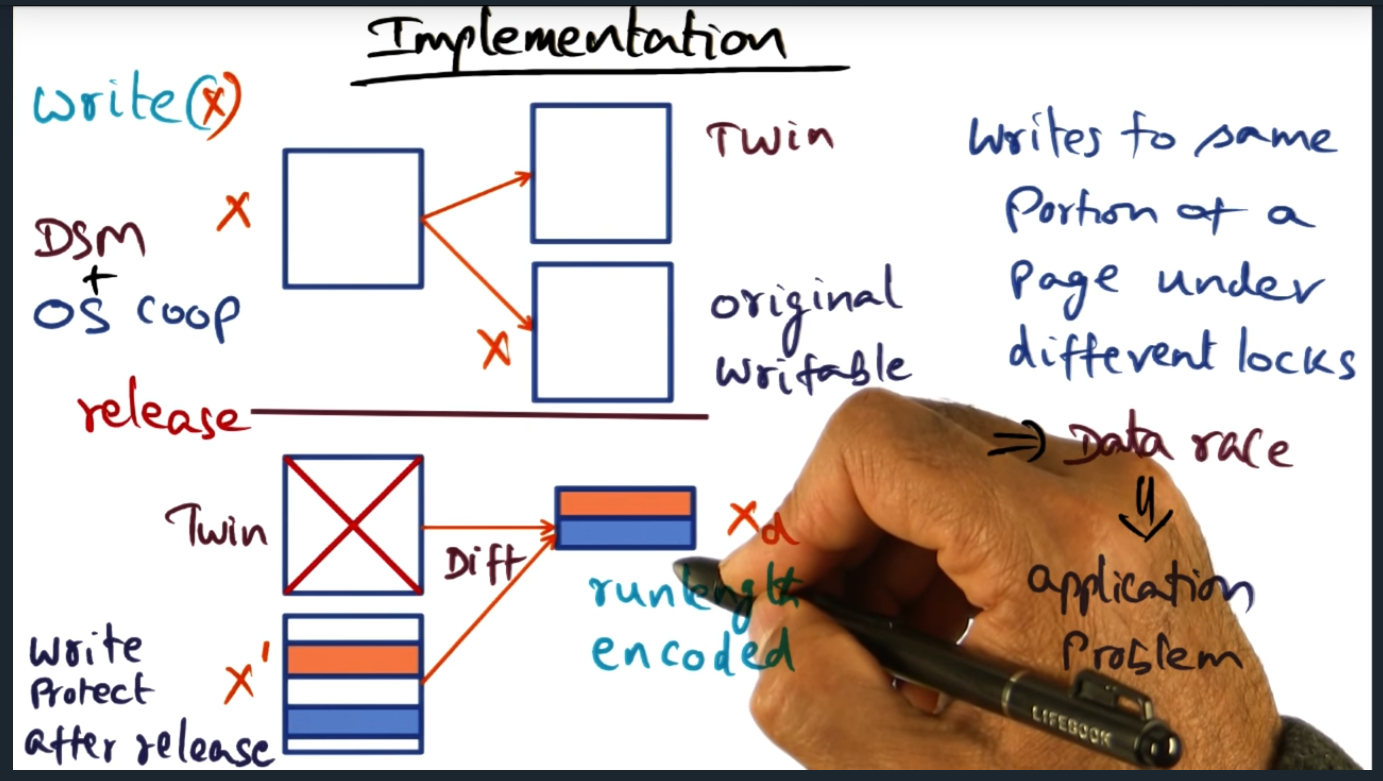
Implementation (continued)
LRC Implementation (Continued)
Summary
Key Words: Data Race, watermark, garbage collection
A daemon process (in every node) wakes up periodically and if the number of diffs exceed the watermark threshold, then daemon will apply diffs to original page. All in all, keep in mind that there’s overhead involved with this solution: overhead with space (for the twin page) and overhead in runtime (due to computing the run-length encoded diff)
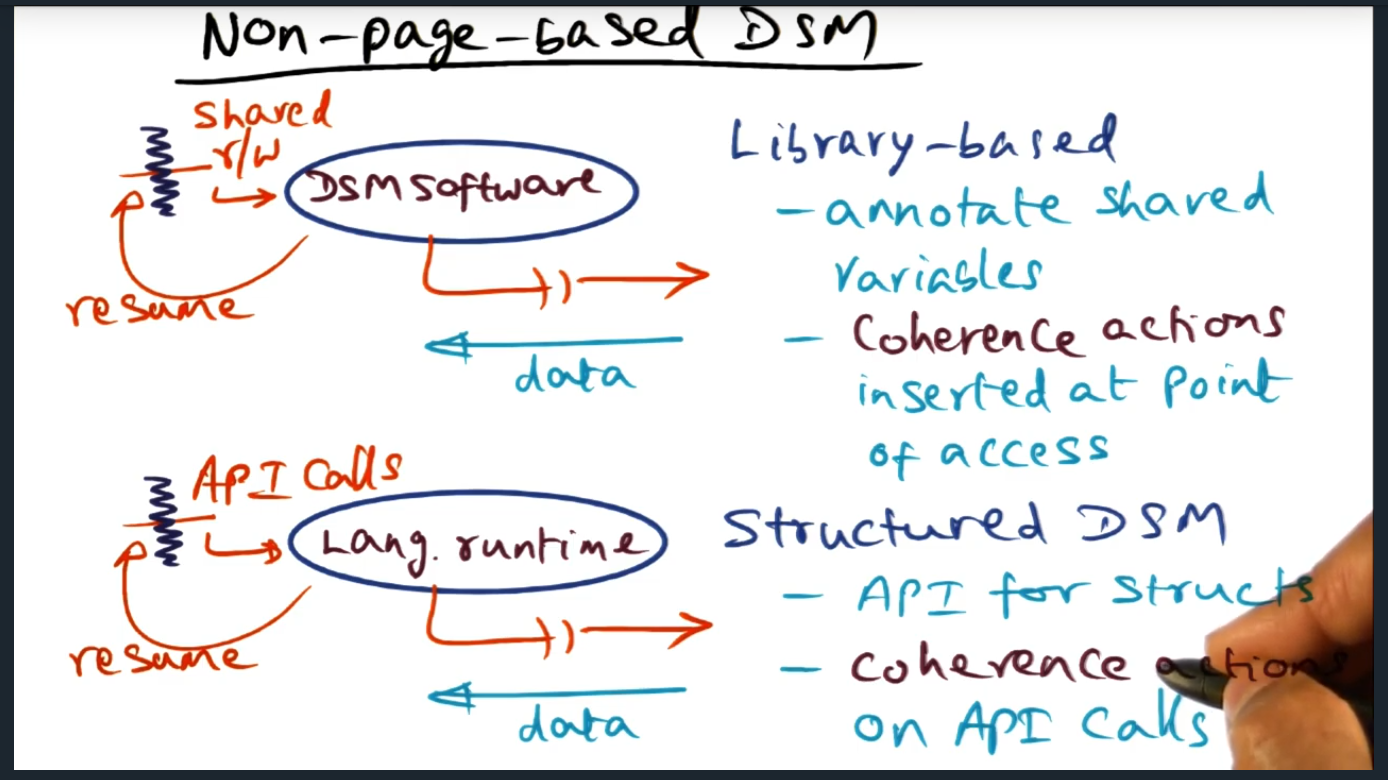
Non Page Based DSM
Non-page-based DSM
Summary
Two types of library based that offer alternatives, both that do not require OS support. The two approaches are library-based (variable granularity) and structured DSM (API for structures that triggers coherence actions)
Scalability
Scalability
Summary
Do our (i.e. programmer’s) expectations get met as the number of processors increase: does performance increase accordingly as well? Yes, but there’s substantial overhead. To be fair, the same is true with true shared memory multiple processor
Before starting project 2 (for my advanced operating systems course), I took a snapshot of my understanding of synchronization barriers. In retrospect, I’m glad I took 10 minutes out of my day to jot down what I did (and did not) know because now, I get a clearer pictur eof what I learned. Overall, I feel the project was worthwhile and I gained not only some theoretical knowledge of computer science but I was also able to flex my C development skills, writing about 500 lines of code.
Discovered a subtle race condition with lecture’s pseudo code
Just by looking at the diagram below, it’s not obvious that there’s a subtle race condition hidden. I only was able to identify it after whipping up some code (below) and analyzing the concurrent flows. I elaborate a little more on the race condition — which results in a deadlock — in this blog post.
Centralized Barrier
[code lang=”C”]
/*
* Race condition possible here. Say 2 threads enter, thread A and
* thread B. Thread A scheduled first and is about to enter the while
* (count > 0) loop. But just before then, thread B enters (count == 0)
* and sets count = 2. At which point, we have a deadlock, thread A
* cannot break free out of the barrier
*
*/
if (count == 0) {
count = NUM_THREADS;
} else {
while (count > 0) {
printf("Spinning …. count = %d\n", count);
}
while (count != NUM_THREADS){
printf("Spinning on count\n");
}
}
[/code]
Data Structures and Algorithms
How to represent a tree based algorithm using multi-dimensional arrays in C
For both the dissemination and tournament barrier, I had to build multi-dimensional arrays in C. I initially had a difficult time envisioning the data structure described in the research papers, asking myself questions such as “what do I use to index into the first index?”. Initially, my intuition thought that for the tournament barrier, I’d index into the first array using the round ID but in fact you index into the array using the rank (or thread id) and that array stores the role for each round.
void flags_init(flags_t flags[MAX_ROUNDS])
{
int i,j,k;
for (i = 0; i < MAX_NUM_THREADS; i++) {
for (j = 0; j < PARITY_BIT; j++) {
for (k = 0; k < MAX_NUM_THREADS; k++) {
flags[i].myflags[j][k] = false;
}
}
}
}
[/code]
OpenMP and OpenMPI
Prior to starting I never heard of neither OpenMP nor OpenMPI. Overall, they are two impressive pieces of software that makes multi-threading (and message passing) way easier, much better than dealing with the Linux pthreads library.
Summary
Overall, the project was rewarding and my understanding of synchronization barriers (and the various flavors) were strengthen by hands on development. And if I ever need to write concurrent software for a professional project, I’ll definitely consider using OpenMP and OpenMPI instead of low level libraries like PThread.
I’m implementating the dissemination barrier (above) in C for my advanced OS course and I’m not quite sure I understand the pseudo code itself. In particular, I don’t get the point of the parity flag …. what’s the point of it? What problem does it solve? Isn’t the localsense variable sufficient to detect whether or not the threads (or processes) synchronized? I’m guessing that the parity flag helps with multiple invocations of the barrier but that’s just a hunch.
I’m watching the YouTube learning series called “Introduction to OpenMP” in order to get a better understanding of how I can use the framework for my second project in advanced operating systems. You might find the below notes useful if you don’t want to sit through the entire video series.
Introduction to OpenMP: 02 part 1 Module 1
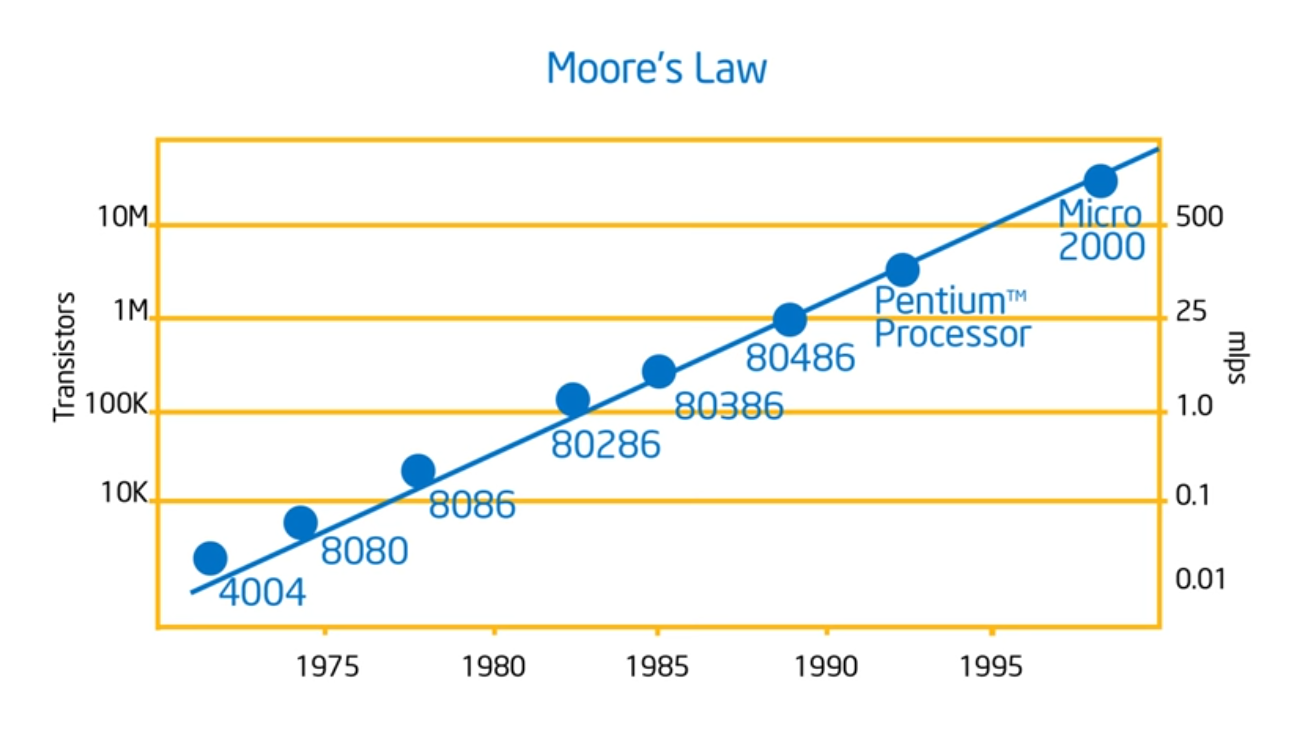
Moore’s Law
Summary
Neat that he’s going over the history, talking about Moore’s Law. The key take away now is that hardware designers are now going to optimize for power and software developers have to write parallel programs: there’s no free lunch. No magic compiler that will take sequential code and turn it into parallel code. Performance now c
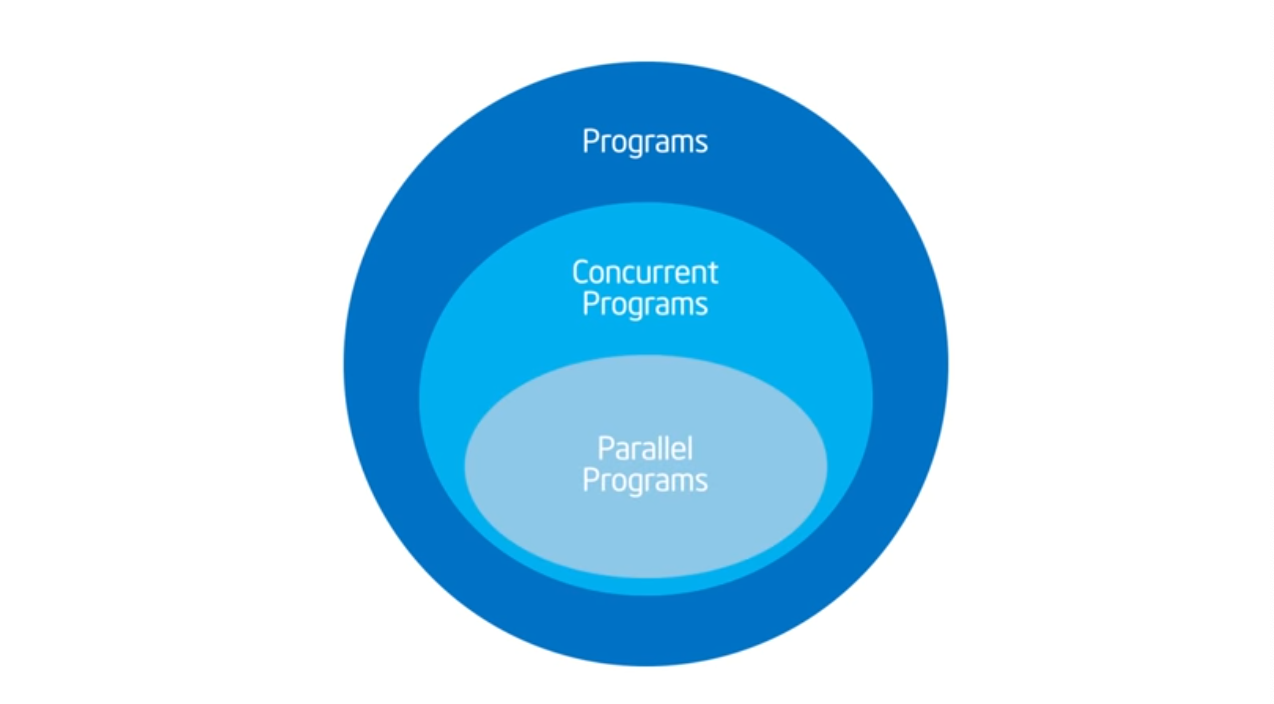
Introduction to OpenMP – 02 Part 2 Module 1
Concurrency vs Parallelism
Summary
The last step should be picking up the OpenMP Library (or any other parallel programming library). What should be done firs and foremost is breaking down your problem (the act of this has not been able to automated) into concurrent parts (this requires understanding of the problem space) and then figure out which can run in parallel. Once you figure that out, then you can use compiler syntactical magic (i.e. pragmas) to direct your compiler and then sprinkle some additional pragmas that will help the compiler tell where the code should enter and where it should exit.
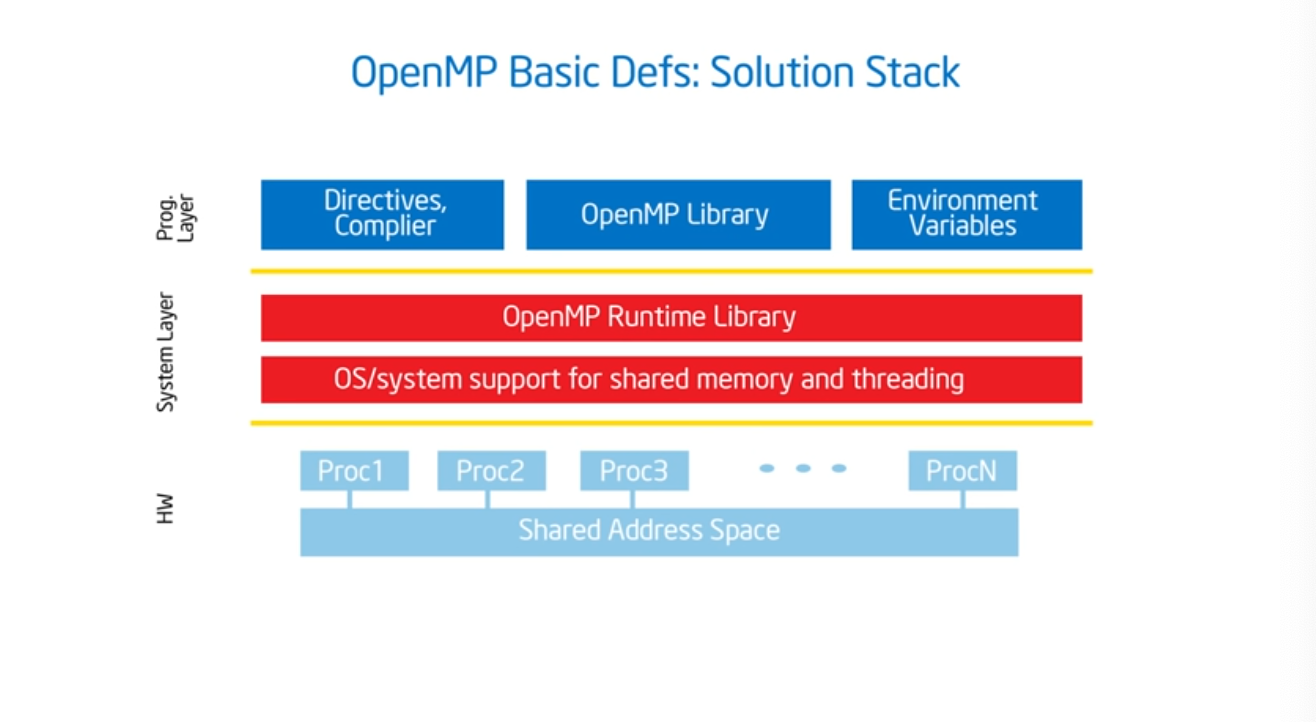
Introduction to OpenMP – 03 Module 02
OpenMP Solution Stack
Summary
It’s highly likely that the compiler that you are using already supports OpenMP. For gcc, pass in -fopenmp. And then include the prototype, and add some syntactic sugar (i.e. #pragma amp parallel) which basically gives the program a bunch of threads.
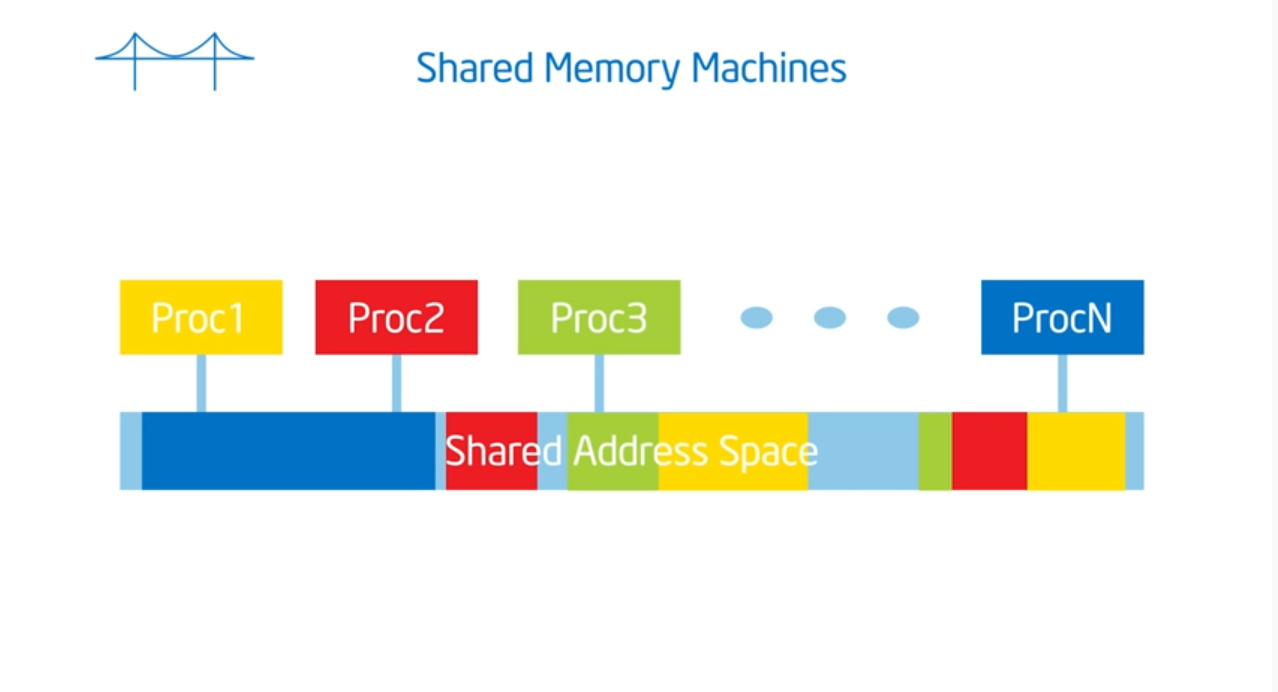
Introduction to OpenMP: 04 Discussion 1
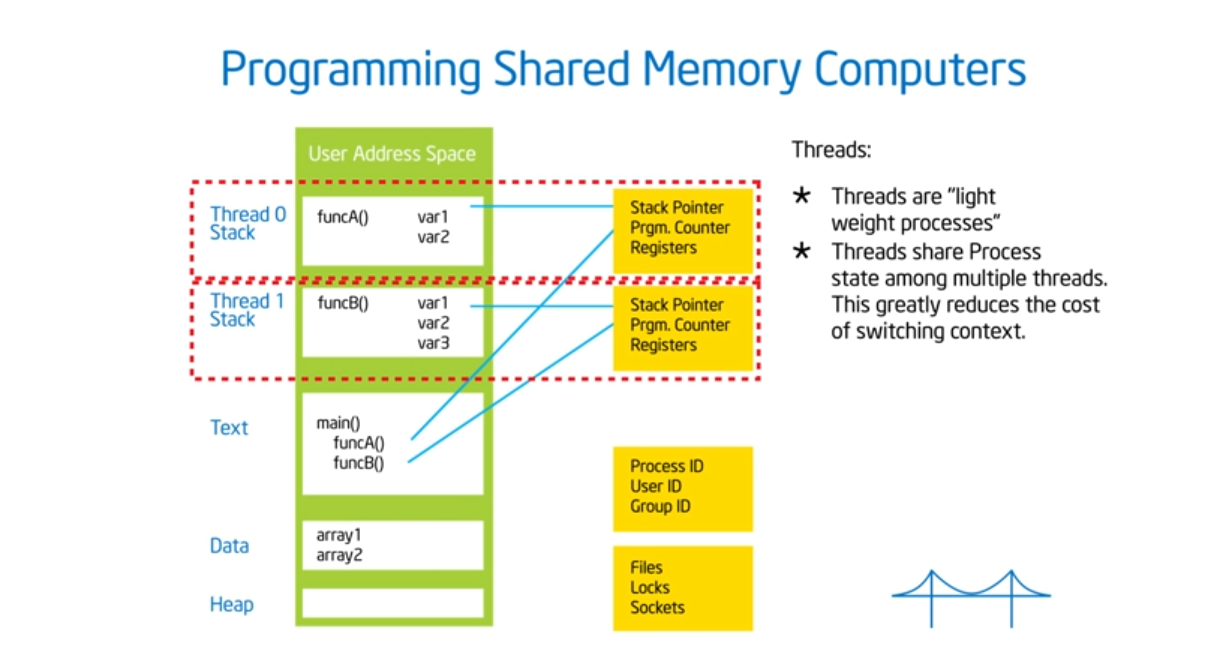
Shared address space
Summary
OpenMP assumes a shared memory address space architecture. The last true SMP (symmetric multi-processor) machine was in the late 1980s so most machines now run on NUMA (non uniformed multiple access) architectures. To exploit this architecture, we need to schedule our threads intelligently (which map to the same heap but contain different stacks) and place data in our cache’s as close as possible to their private caches. And, just like the professor said in advanced OS, we need to limit global data sharing and limit (as much as possible) the use of synchronization variables since they both slow down performance
Part 1 of barrier synchronization covers my notes on the first couple types of synchronization barriers including the naive centralized barrier and the slightly more advanced tree barrier. This post is a continuation and covers the three other barriers: MCS barrier, tournament barrier , dissemination barrier.
Summary
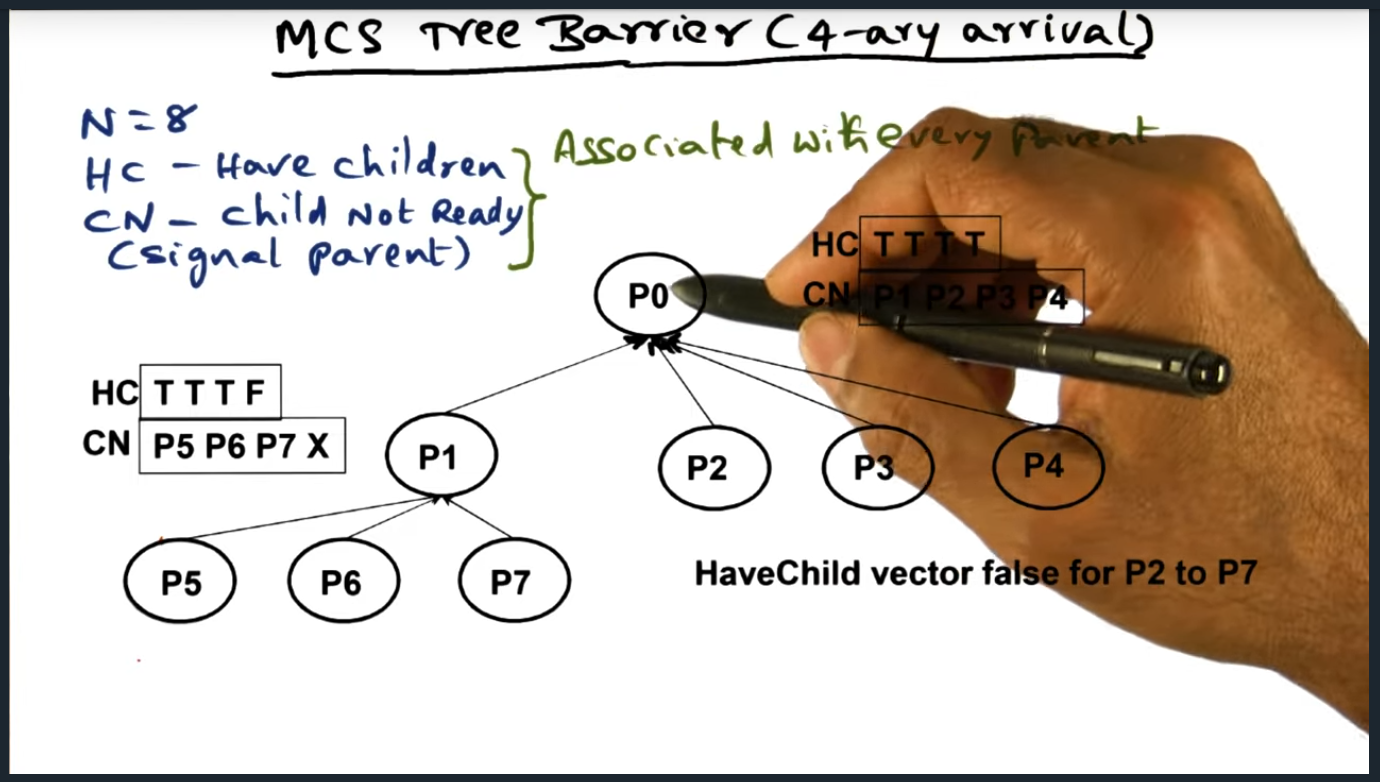
In the MCS tree barrier, there are two separate data structures that must be maintained. The first data structure (a 4-ary tree, each node containing a maximum of four children) handling the arrival of the processes and the second data structure handling the signaling and waking up of all other processes. In a nutshell, each parent node holds pointers to their children’s structure, allowing the parent process to wake up the children once all other children have arrived.
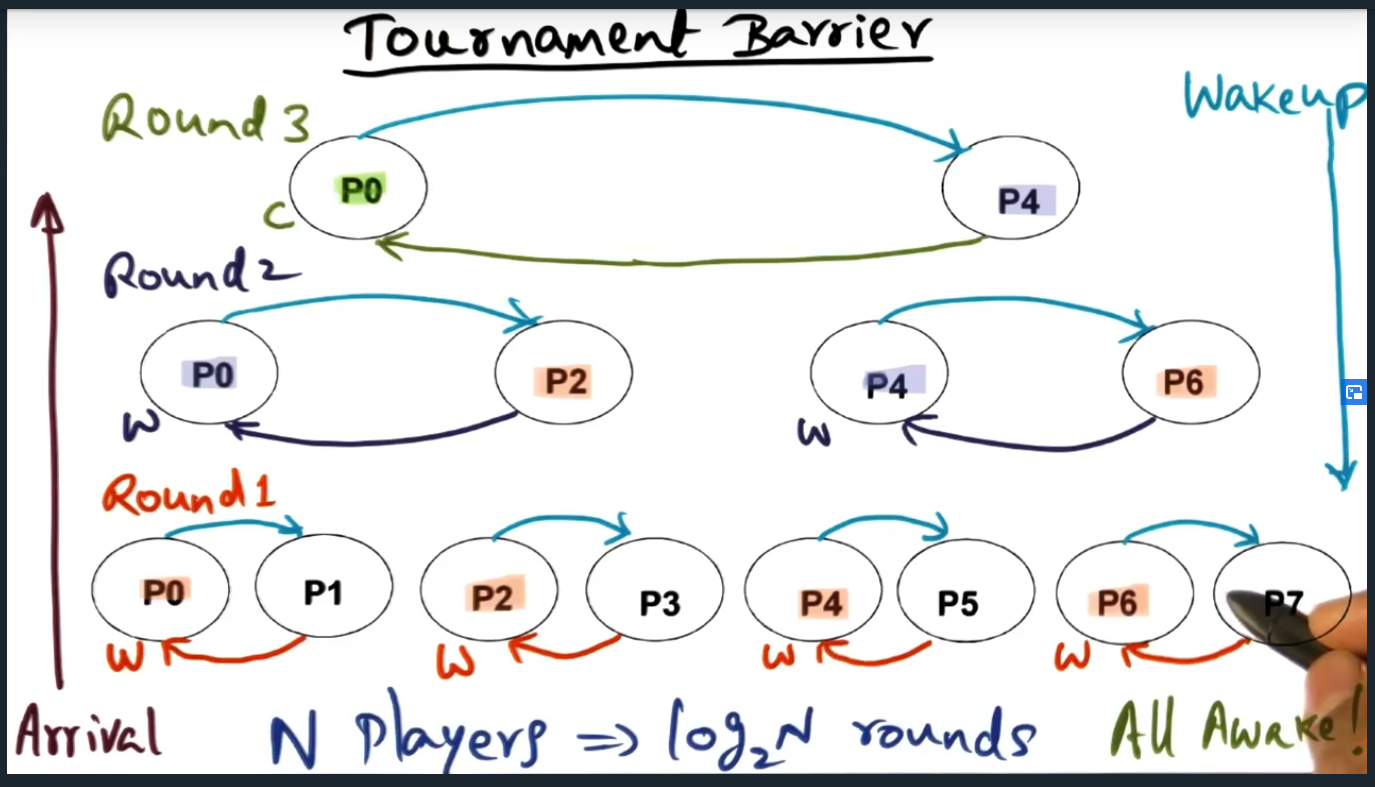
The tournament barrier constructs a tree too and at each level are two processes competing against one another. These competitions, however, are fixed: the algorithm predetermines which process will advanced to the next round. The winners percolate up the tree and at the top most level, the final winner signals and wakes up the loser. This waking up of the loser happens at each lower level until all nodes are woken up.
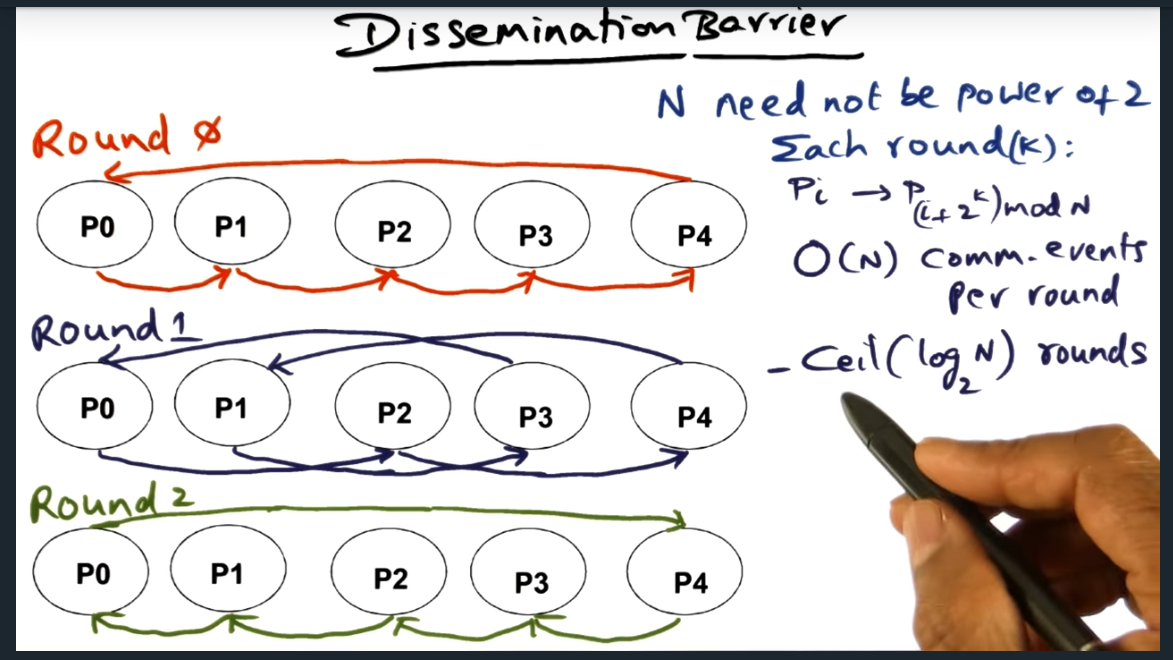
The dissemination protocol reminds me of a gossip protocol. With this algorithm, all nodes detect convergence (i.e. all processes arrived) once every process receives a message from all other processes (this is the key take away); a process receives one (and only one) message per round. The runtime complexity of this algorithm is nlogn (coefficient of n because during each round n messages, one message sent from one node to its ordained neighbor).
The algorithms described thus far share a common requirement: they all require sense reversal.
MCS Tree Barrier (Binary Wakeup)
MCS Tree barrier with its “has child” vector
Summary
Okay, I think I understand what’s going on. There are two separate data structures that need to be maintained for the MCS tree barrier. The first data structure handles the arrival (this is the 4-ary tree) and the second (binary tree) handles the signaling and waking up of all the other processes. The reason why the latter works so well is that by design, we know the position of each of the nodes and each parent contains a pointer to their children, allowing them to easily signal the wake up.
Tournament Barrier
Tournament Barrier – fixed competitions. Winner holds the responsibility to wake up the losers
Summary
Construct a tree and at the lowest level are all the nodes (i.e. processors) and each processor competes with one another, although the round is fixed, fixed in the sense that the winner is predetermined. Spin location is statically determined at every level
Tournament Barrier (Continued)
Summary
Two important aspects: arrival moves up the tree with match fixing. Then each winner is responsible for waking up the “losers”, traversing back down. Curious, what sort of data structure? I can see an array or a tree …
Tournament Barrier (Continued)
Summary
Lots of similarity with sense reversing tree algorithm
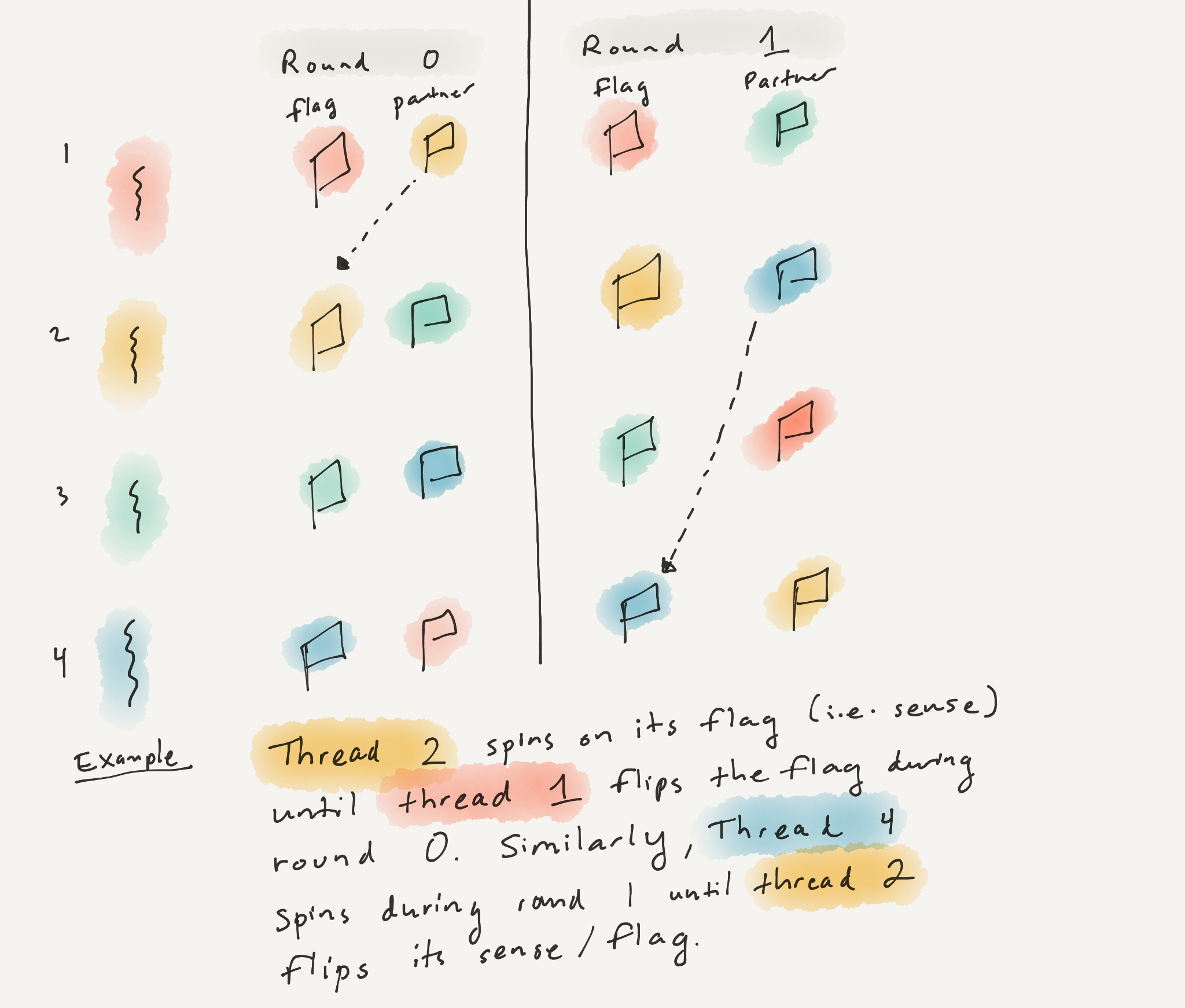
Dissemination Barrier
Dissemination Barrier – gossip like protocol
Summary
Ordered communication: like a well orchestrated gossip like protocol. Each process will send a message to ordained peer during that “round”. But I’m curious, do we need multiple rounds?
Dissemination Barrier (continued)
Summary
Gossip in each round differs in the sense the ordained neighbor changes based off of Pi -> P(I + 2^k) mod n. Will probably need to read up on the paper to get a better understanding of the point of the rounds ..
Quiz: Barrier Completion
Summary
Key point here that I just figured out is this: every processor needs to hear from every other processor. So, it’s log2N with a ceiling since N rounds must not be a power of 2 (still not sure what that means exactly)
Dissemination Barrier (continued)
Summary
All barriers need sense reversal. Dissemination barrier is no exception. This barrier technique works for NCC and clusters.Every round has N messages. Communication complexity is nlogn (where N is number of messages) and log(n). Total communication nlogn because N messages must be sent every round, no exception
Performance Evaluation
Summary
Most important question to ask when choosing and evaluating performance is: what is the trend? Not exact numbers, but trends.
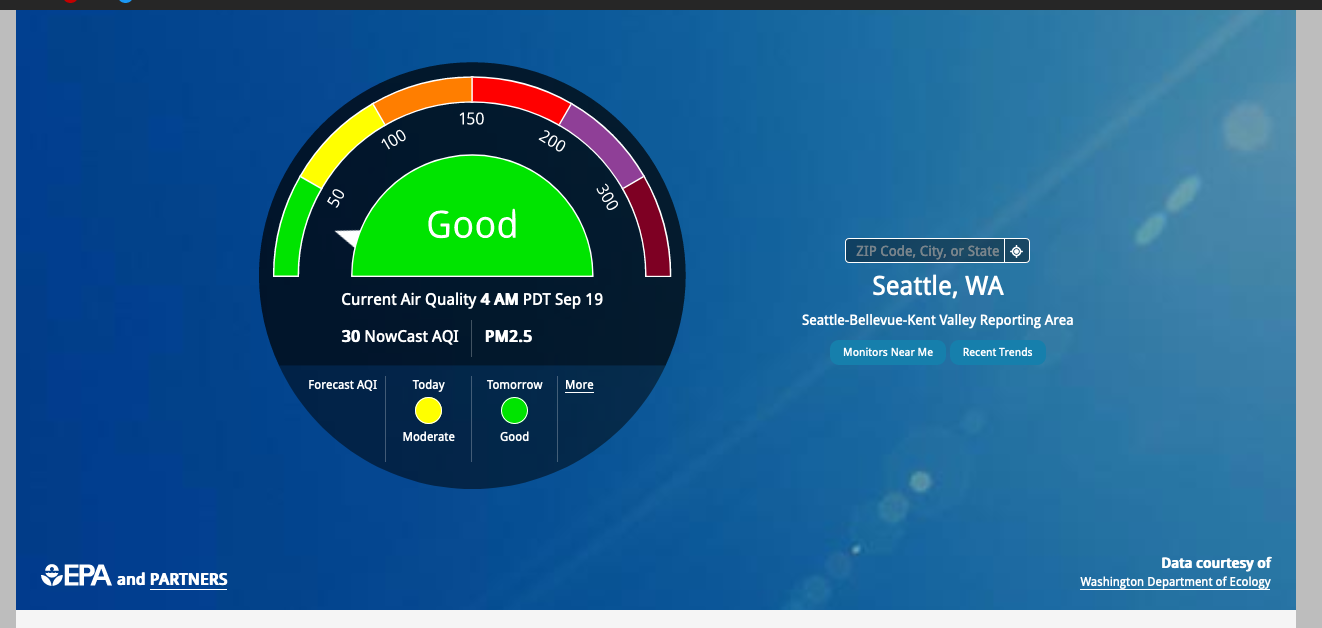
Hooray! Today is the first day in a couple weeks that air quality is considered good, at least according to the EPA. I’m so pleased and so grateful for clean air because my wife and daughter have not left the house since the wild fires started a week ago (or was it two weeks — I’ve lost concept of time since COVID hit) and today marks the first day we can as an entire family can go for a walk at a local park (it’s the little things in life) and breathe in that fresh, crisp pacific northwest air. Of course, we’ll still be wearing masks but hey, better than staying cooped up inside.
Yesterday
What I learned yesterday
Static assertion on C structures. This type of assertion fires off not at at run-time but at compile time. By asserting on the size of a structure, we can ensure that they are sized correctly. This sanity check can be useful in situations such as ensuring that your data structure will fit within your cache lines.
Writing
Published my daily review that I had to recover in WordPress since I had accidentally deleted the revision
Best parts of my day
Video chatting at the end of the work day with my colleague who I used to work with in Route 53, the organization I had left almost two years ago. It’s nice to speak to a familiar face and just shoot the shit.
Graduate School
Finished lectures on barrier synchronization (super long and but intellectually stimulating material)
Started watching lectures on lightweight RPC (remote procedure calls)
Submitted my project assignment
Met with a classmate of mine from advanced operating systems, the two of us video chatting over Zoom and describing our approaches to project 1 assignment
Work
Finished adding a simple performance optimization feature that takes advantage of the 64 byte cache lines, packing some cached structs with additional metadata squeezed into the third cache line.
Miscellaneous
Got my teeth cleaned at the dentist. What an unusual experience. Being in the midst of the pandemic for almost 8 months now I’ve forgotten what it feels like to talk to someone up close while not wearing a mask (of course the dentist and dental hygienist were wearing masks) so at first I felt a bit anxious. These days, any sort of appointments (medical or not) are calculated risks that we must all decide for ourselves.
Today
Writing
Publish Part 1 of Barrier Synchronization notes
Publish this post (my daily review)
Review my writing pipeline
Mental and Physical Health
Slip on my Freebird shoes and jog around the neighborhood for 10 minutes. Need to take advantage of the non polluted air that cleared up (thank you rain)
Swing by the local Cloud City coffee house and pick up a bottle of their in house Chai so that I can blend it in with oat milk at home.
Review my tasks and project and breakdown the house move into little milestones
Family
Take Mushroom to her grooming appointment. Although I put a stop gap measure in place so that she stops itching and wounding herself, the underlying issue is that she needs a haircut since her hair tends to develop knots.
Walk the dogs at either Magnuson or Marymoore Park. Because of the wild fires, everyone (dogs included) have been pretty much stuck inside the house.
Pack pack pack. 2 weeks until we move into our new home in Renton. At first, we were very anxious and uncertain about the move. Now, my wife and I are completely ready and completely committed to the idea.
As mentioned previously, there are different types of synchronization primitives that us operating system designers offer. If as an application designer you nee to ensure only one thread can access a piece of shared memory at a time, use a mutual exclusion synchronization primitive. But what about a different scenario in which you need all threads to reach a certain point in the code and only once all threads reach that point do they continue? That’s where a barrier synchronization comes into play.
This post covers two types of barrier synchronizations. The first is the naive, centralized barrier and the second is the a tree barrier.
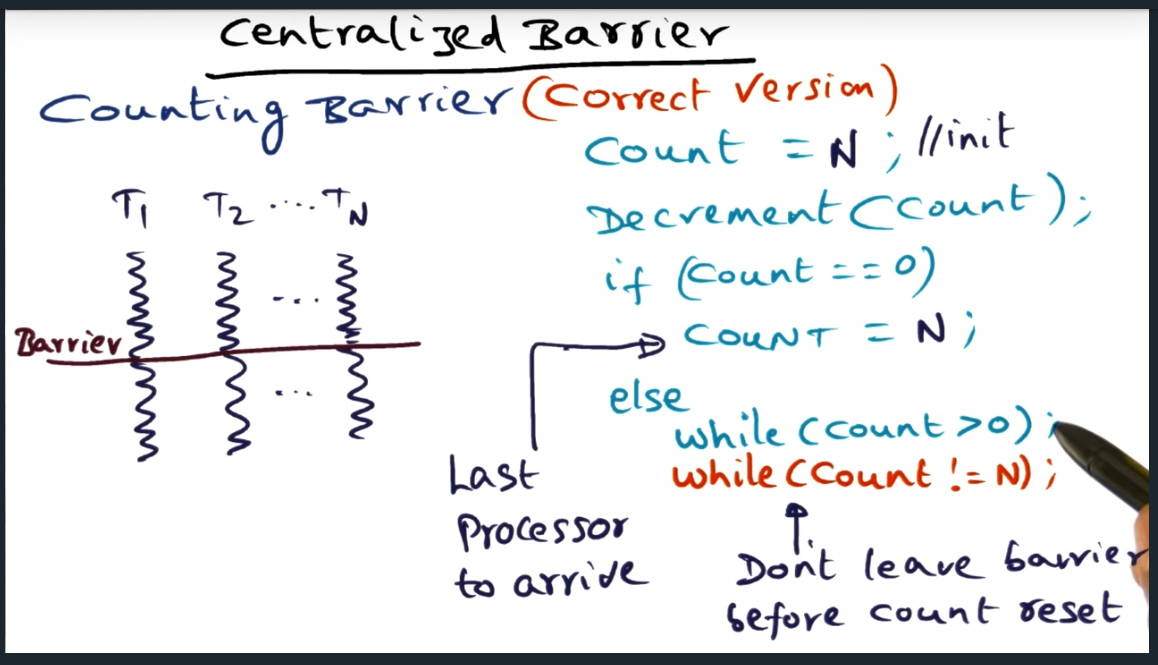
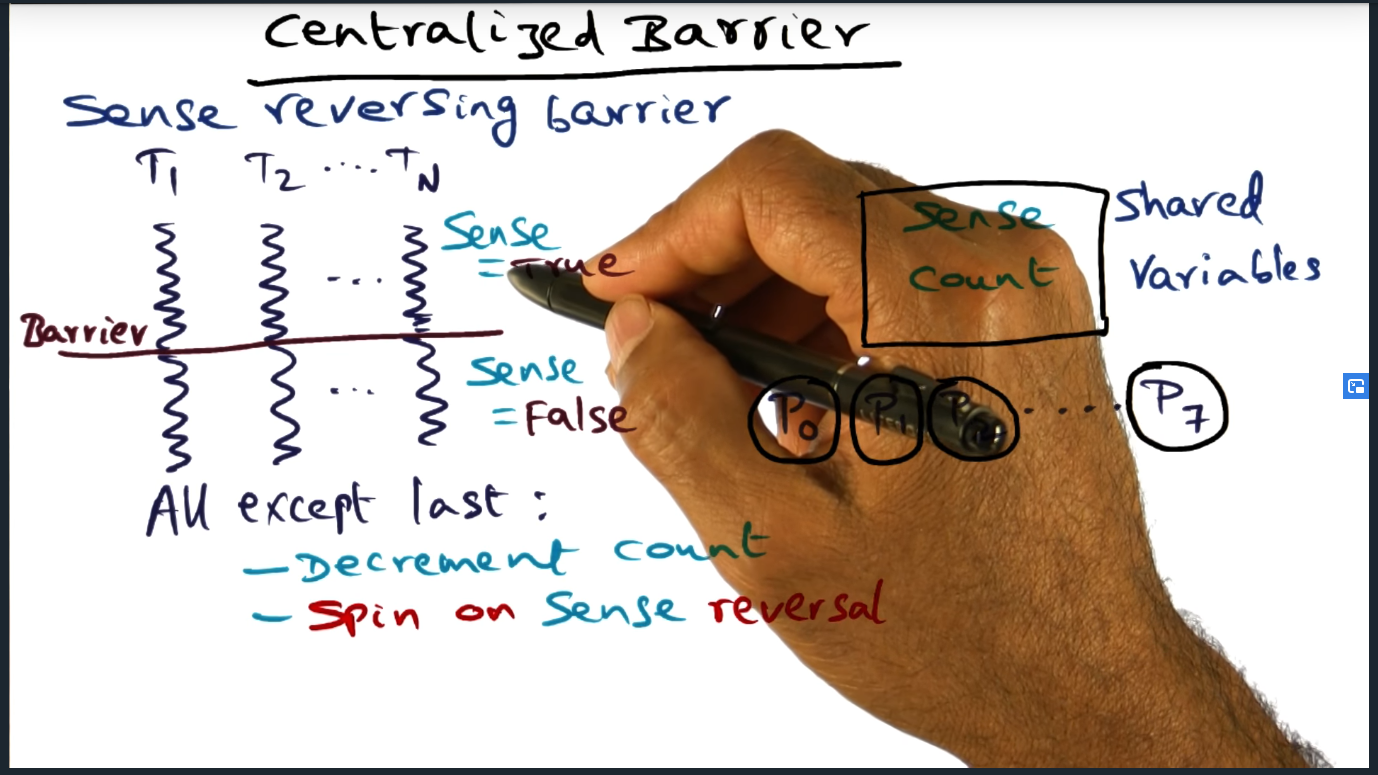
In a centralized barrier, we basically have a global count variable and as each thread enters the barrier, they decrement the shared count variable. After decrementing the count, threads will hit a predicate and branch: if the count is not zero, then the thread enters a busy spin loop, spinning while the count is greater than zero. However, if after decrementing the counter equals zero, then that means all threads have arrived at the end of the barrier synchronization.
Simple enough, right? Yes it is, but the devil is in the details because there’s a subtle bug, a subtle edge case. It is entirely possible (based off of the code snippet below) that when the last thread enters the barrier and decrements the count, all the other threads suddenly move beyond the barrier (since the count is not greater than zero). In other words, the last thread never gets to reset the count back to N number of threads.
How to avoid this problem? Simple: add another while loop that guarantees that the threads do not leave the barrier until the counter gets reset. Very elegant. Very simple.
The next type of barrier is a tree barrier. The tree barrier groups multiple process together at multiple levels (number of levels is logn where n is the number of processors), each group maintaining its own count and local sense variables. The benefit? Each group spins on its own locksense. Downside? The spin location is dynamic, not static and can impede performance on NUMA architectures.
Centralized Barrier
Centralized Barrier
Summary
Centralized barrier synchronization is pretty simple: keep a counter that decrements as each thread reaches the barrier. Every thread/process will spin until the last thread arrives, at which point the last thread will reset the barrier counter so that it can be used later on
Problems with Algorithm
Summary
Race condition: last thread, while updating the counter, all other threads move forward
Counting Barrier
Summary
Such a simple and elegant solution by adding a second spin loop (still inefficient, but neat nonetheless). Sense reverse barrier algorithm
Sense Reversing Barrier
Sense Reversing Barrier
Summary
One way to optimize the centralized barrier is to introduce a sense reversing barrier. Essentially, each process maintains its own unique local “sense” that flips from 0 to 1 (or 1 to 0) each time synchronization barrier is needed. This local variable is compared against a shared flag and only when the two are equal can all the threads/processes proceed past the current barrier and move on to the next
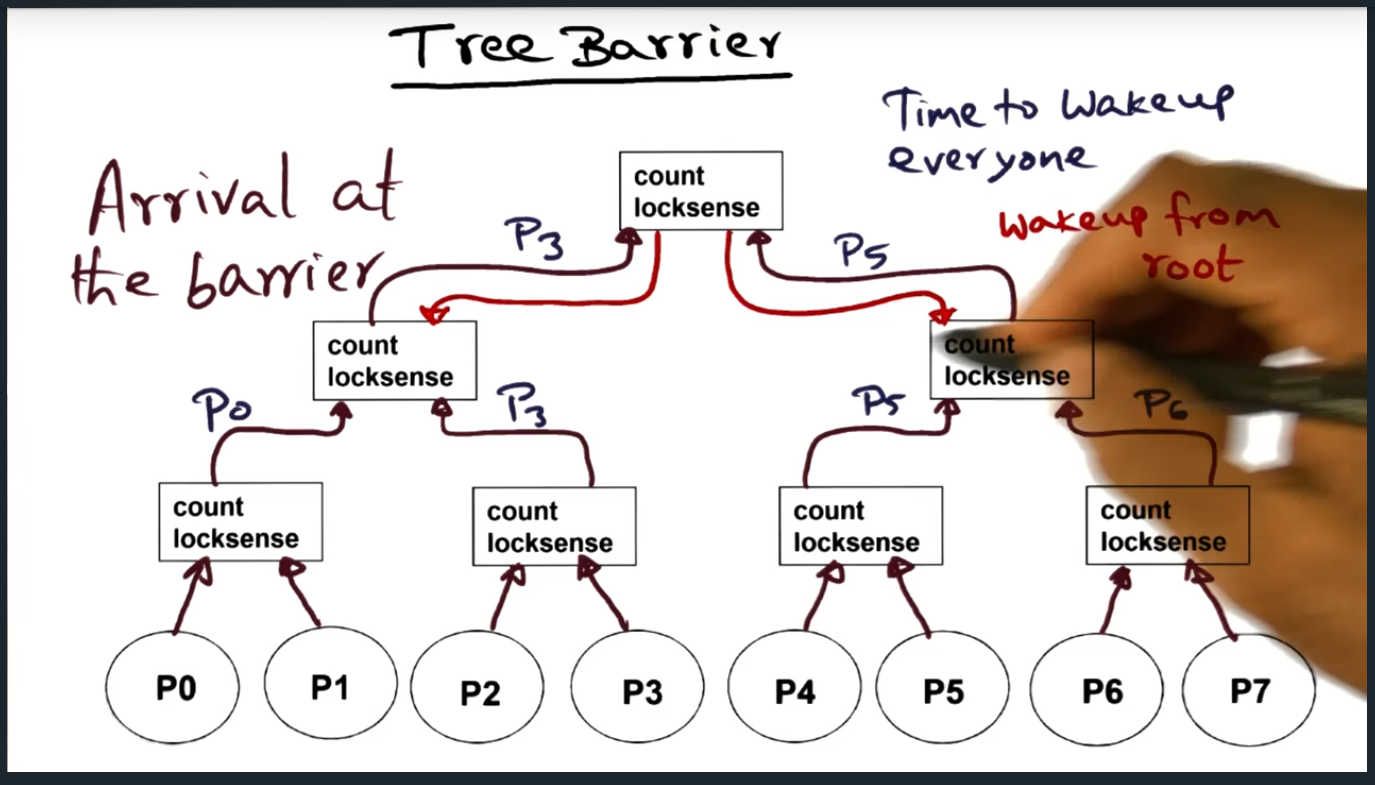
Tree Barrier
Tree Barrier
Summary
Group processes (or threads) and each group has its own shared variables (count and lock sense). Before flipping the lock sense, the final process needs to move “up to the next level” and check if all other processors have arrived at the next level. Things are getting a little more spicy and complicated with this type of barrier
Tree Barrier (Continued)
Summary
With a tree barrier, a process arrives at its group (of count and lock sense), and will decrement the count variable and will then check the lock sense variable. If lock sense is not equal, then spin. If last
Tree Barrier (continued)
Summary
Once the last process reaches the root, it’s their responsibility to begin waking up the lower levels, traversing back down the tree. At each level, they will be flipping the lock sense flag
Tree Barrier (Continued)
Summary
As always, there’s a trade off or hidden downside with this implementation. First, the spin location is not statically determined. This dynamic allocation may be problematic, especially on NUMA (non uniformed memory access architecture) architecture, because a process may be spinning on a remote memory location. But my question is, are there any systems that do not offer coherence?