
Introduction
Summary
Lamport’s theories provided deterministic execution for non determinism exists due to vagaries of the network. Will discuss techniques to make OS efficient for network communication (interface to kernel and inside the kernel network protocol stack)
Latency Quiz
Summary
What’s the difference between latency and throughput. Latency is 1 minute and throughput is 5 per minute (reminds of me pipelining from graduate introduction to operating systems as well as high performance computing architecture). Key idea: throughput is not the inverse of latency.
Latency vs Throughput
Summary
Key Words: Latency, Throughput, RPC, Bandwidth
Definitions of latency is elapsed time for event and throughput are the number of events per unit time, measured by bandwidth. As OS designers, we want to limit the latency for communication
Components of RPC Latency
Summary
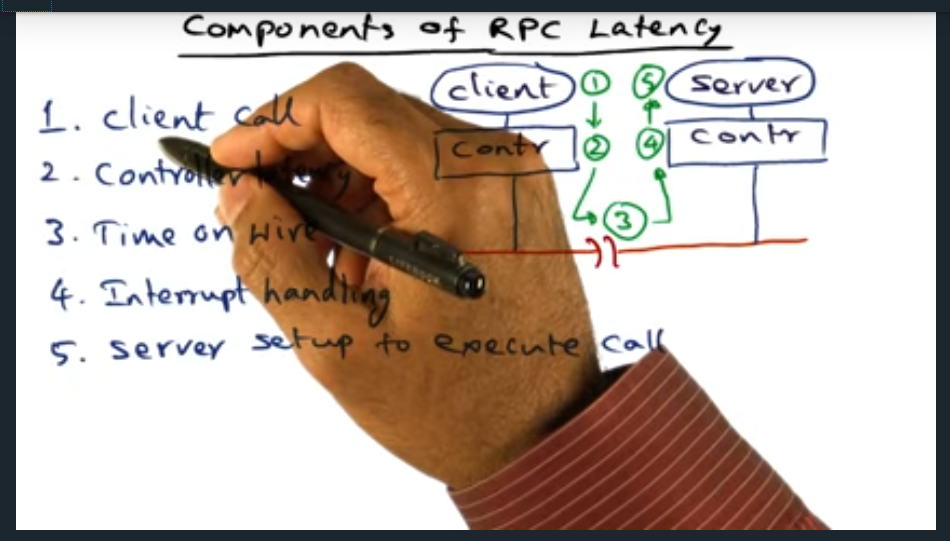
There are five sources of latency with RPC: client call, controller latency, time on wire, interrupt handling, server setup and execute call (and then the same costs in reverse, in the return path)
Sources of Overhead on RPC
Summary
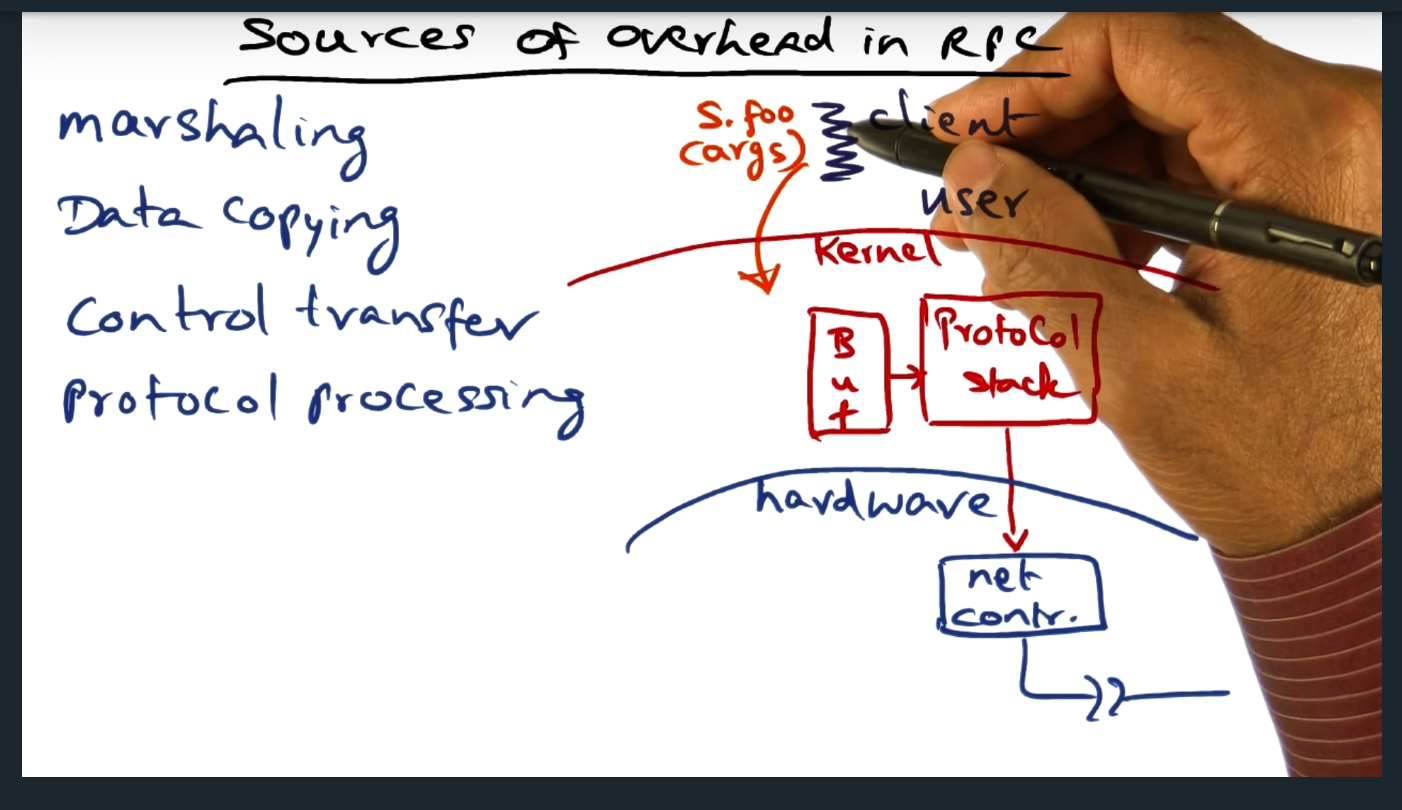
Although the client thinks the RPC call looks like a normal procedure, there’s much more overhead: marshaling, data copying, control transfer, protocol processing. So, how do we limit the overhead? By leveraging hardware (more on this next)
Marshaling and Data Copying
Summary
Key Words: Marshaling, RPC message, DMA
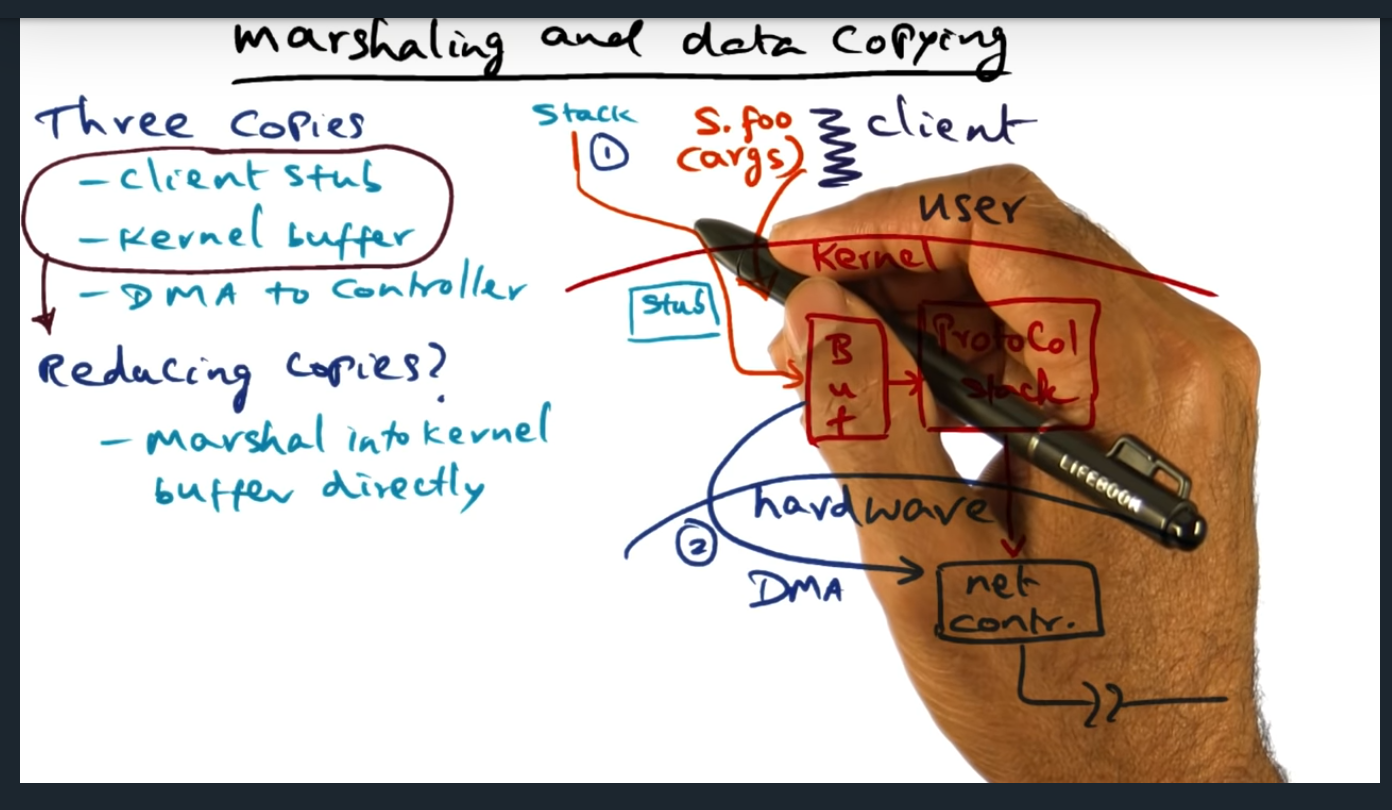
During the client RPC call, the message is copied three times. First, from stack to RPC message; second from RPC message into kernel buffer; third, from kernel buffer (via DMA) to the network controller. How can we avoid this? One approach (and there are others, discussed in the next video, hopefully) is to install the client stub directly in the kernel, creating the client stub during instantiation. Trade offs? Well, kernel would need to trust the RPC client, that’s for sure
Marshaling and Data Copying (continued)
Summary
Key Words: Shared descriptors
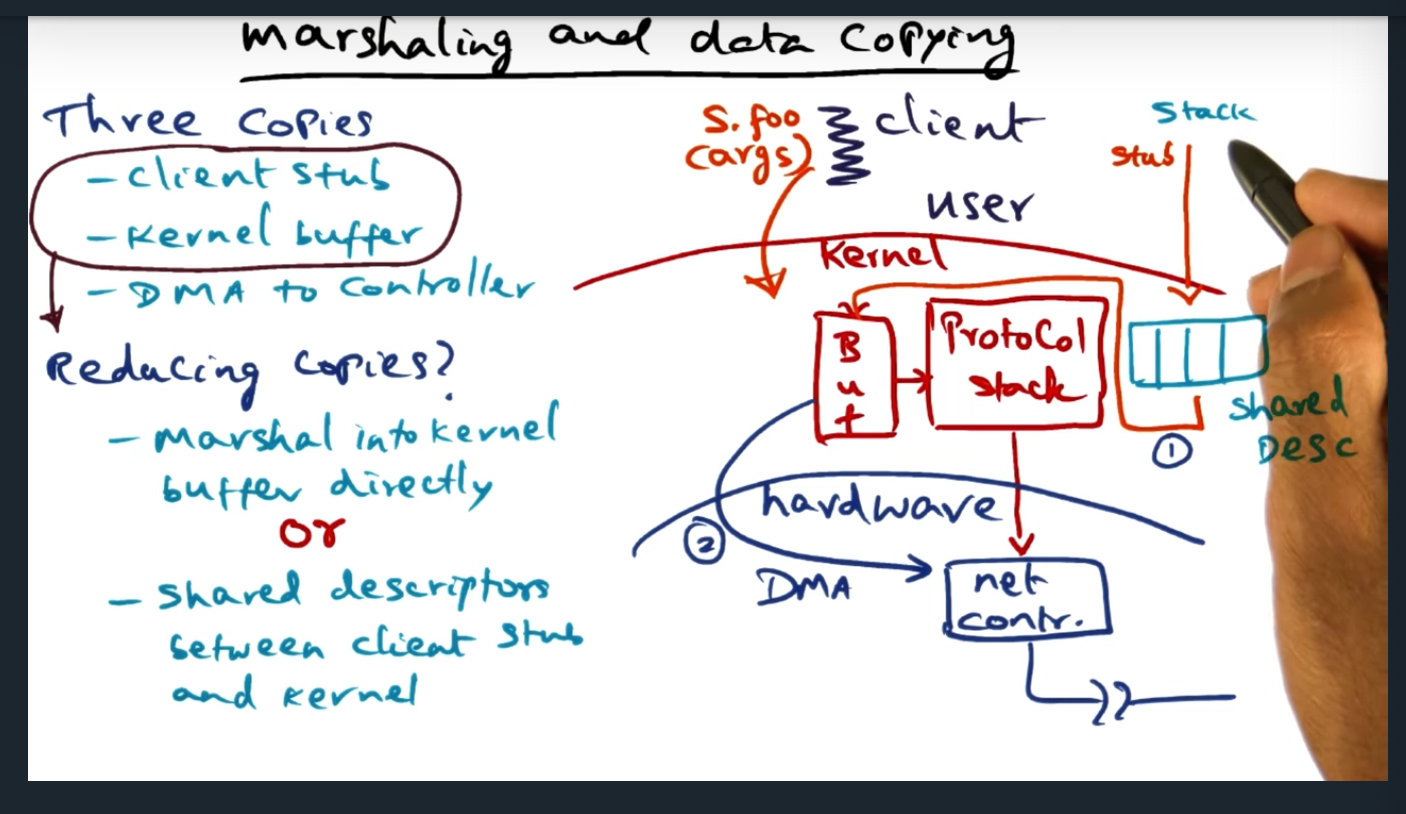
An alternative to placing the client stub in the kernel, the client stub instead can provide some additional metadata (in the form of shared descriptors) and this allows the client to avoid converting the stack arguments into an RPC packet. The shared descriptors are basically TLV (i.e. type, length, value) and provides enough information for the kernel to DMA the data to the network controller. To me, this feels a lot like the strategy that the Xen Hypervisor employs for ring buffers for communicating between guest VM and kernel
Control Transfer
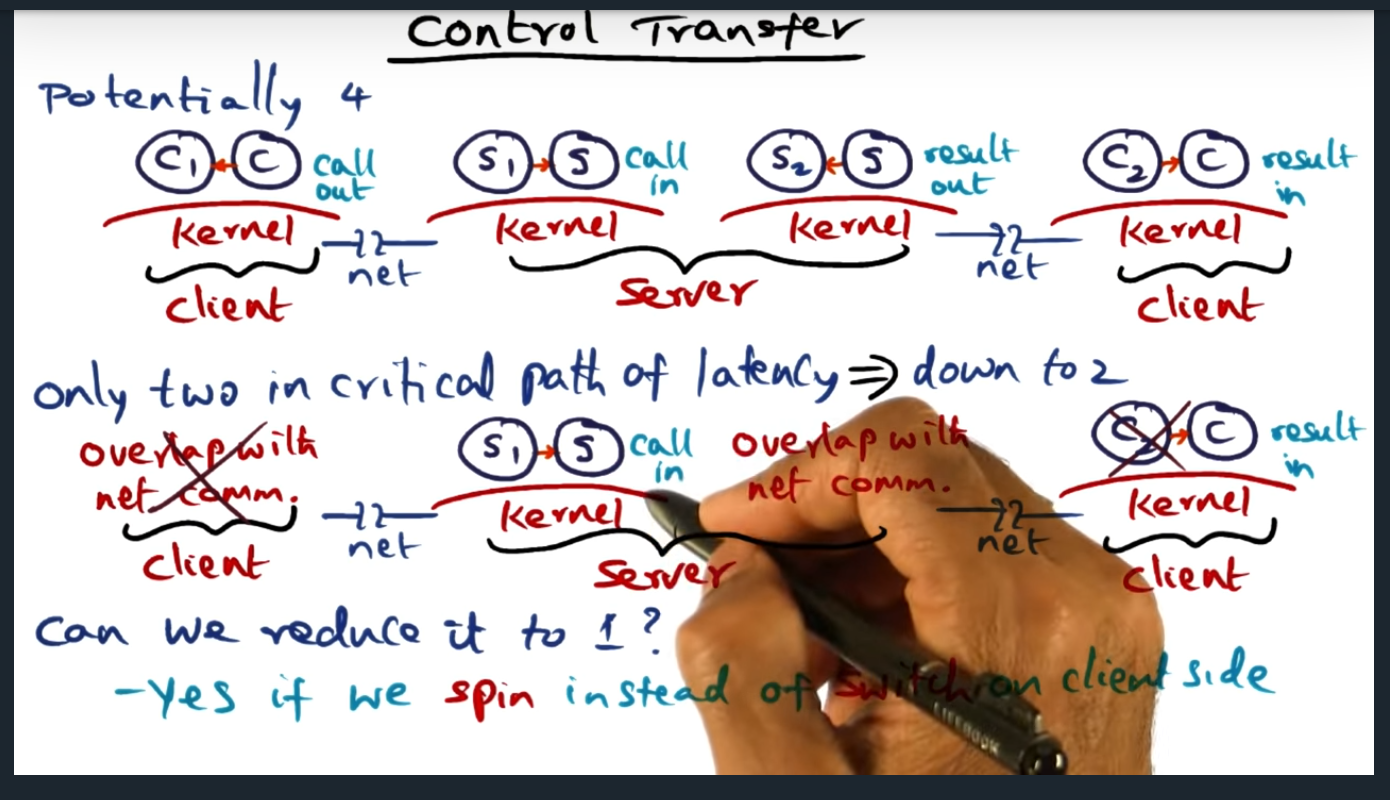
Summary
Key Words: Critical Path
This is the second source of overhead. Bsaically have four context switches, one in the client (client to kernel), two in the server (for kernel to call server app, and then from server app out to kernel), and one final switch from kernel back to client (the response)
The professor mentions “critical path” a couple times, but not sure what he means by that (thanks to my classmates, they answered my question in a Piazza Post: the critical path refers to the network transactions that cannot be run parallel and the length of the critical path is the number of network transactions that must be run sequentially (or how long it takes in wall time)
Control Transfer (continued)
Summary
We can eliminate a context switch on the client side, by making sure the client spins instead of switching (we had switched before in make good use of the CPU)
Protocol Processing

Summary
Assuming that RPC runs over lan, we can eliminate latency (but trading off reliability) by not using acknowledgements, relying on the underlying hardware to perform checksums, eliminating buffering (for retransmissions)
Protocol Processing (continued)
Summary
Eliminate client buffer and overlap server side buffering
Conclusion
Summary
Reduce total latency between client and server by reducing number of copies, reducing number of context switches, and making protocol lean and mean