
I learned that with an L3 Microkernel approach, each OS runs in their own address space and that they are indistinguishable from the end-user applications running in user land. Because they run in user land, it seems intuitive that this kill performance due to border crossings (not just necessarily context switching, but address space switching and inter process communication). Turns out that this performance loss has been debunked and that border crossings do not cost 900 cycles — this number can be dropped to around 100 cycles if the mikrokernel, unlike Mach, stray away from writing code that is platform dependent. In other words, the expensive border crossing was a result of a heavy code base, code with portability as one of its main goals.
L02d: The L3 Microkernel Approach
Summary
Learned why you might not need to flush TLB on context switch with address space tag in the TLB.
Introduction
Summary
Focus on this lesson is evaluating L3, a micro kernel based design, a system and design with a contrarian view point
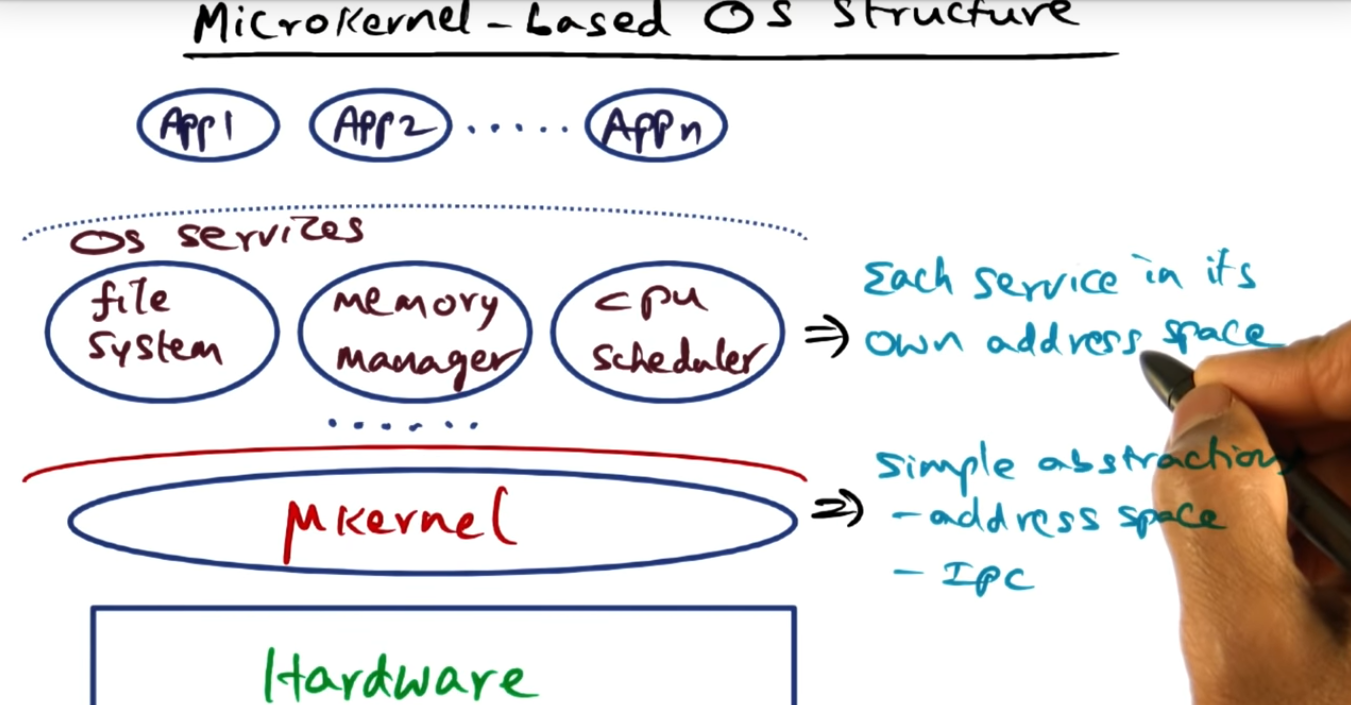
Microkernel-Based OS Structure
Summary
Each of the OS services run in their own address space, the services indistinguishable from applications running in user space
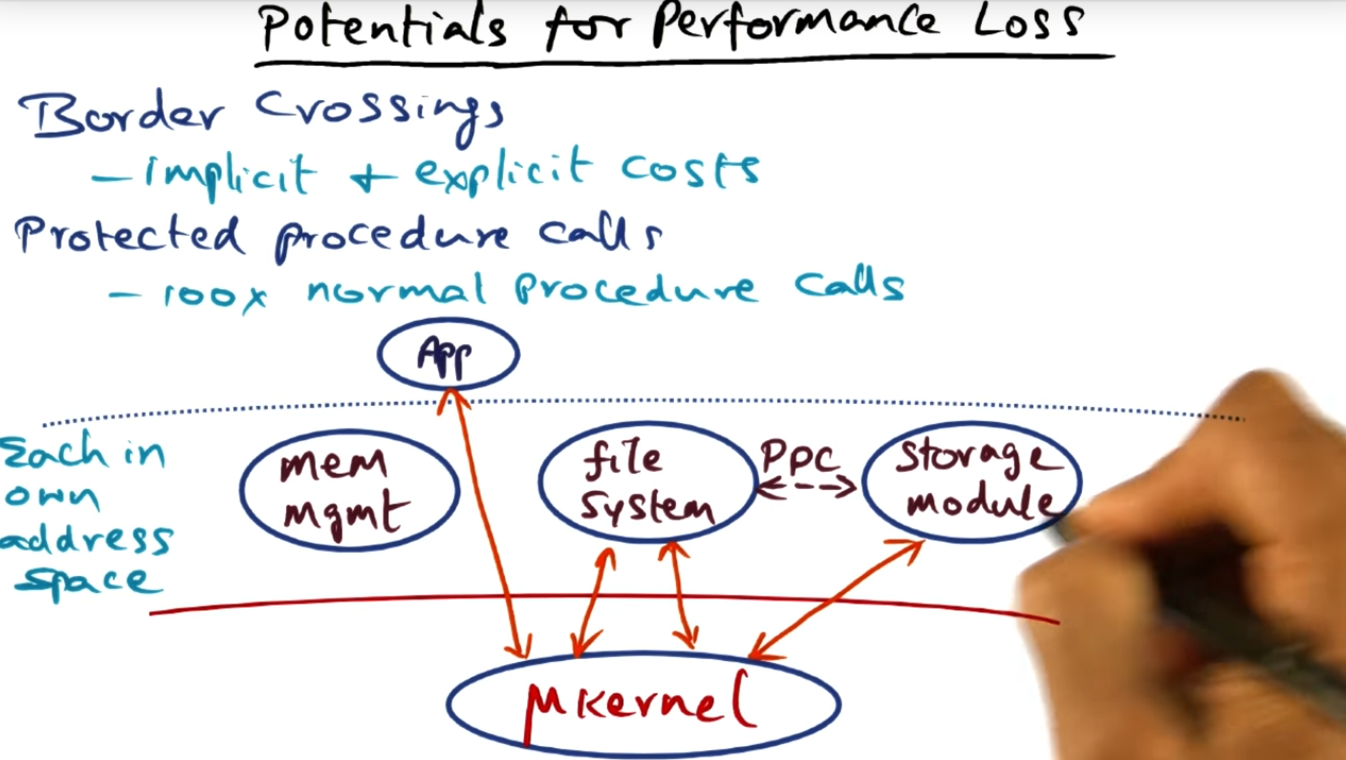
Potentials for Performance Loss
Summary
The primary performance killer is border crossings, between user space and privileged space, a crossing required for user applications and well as operating system services. Also, that’s the explicit cost. There’s an implicit cost of procedure calls as well: loss of locality
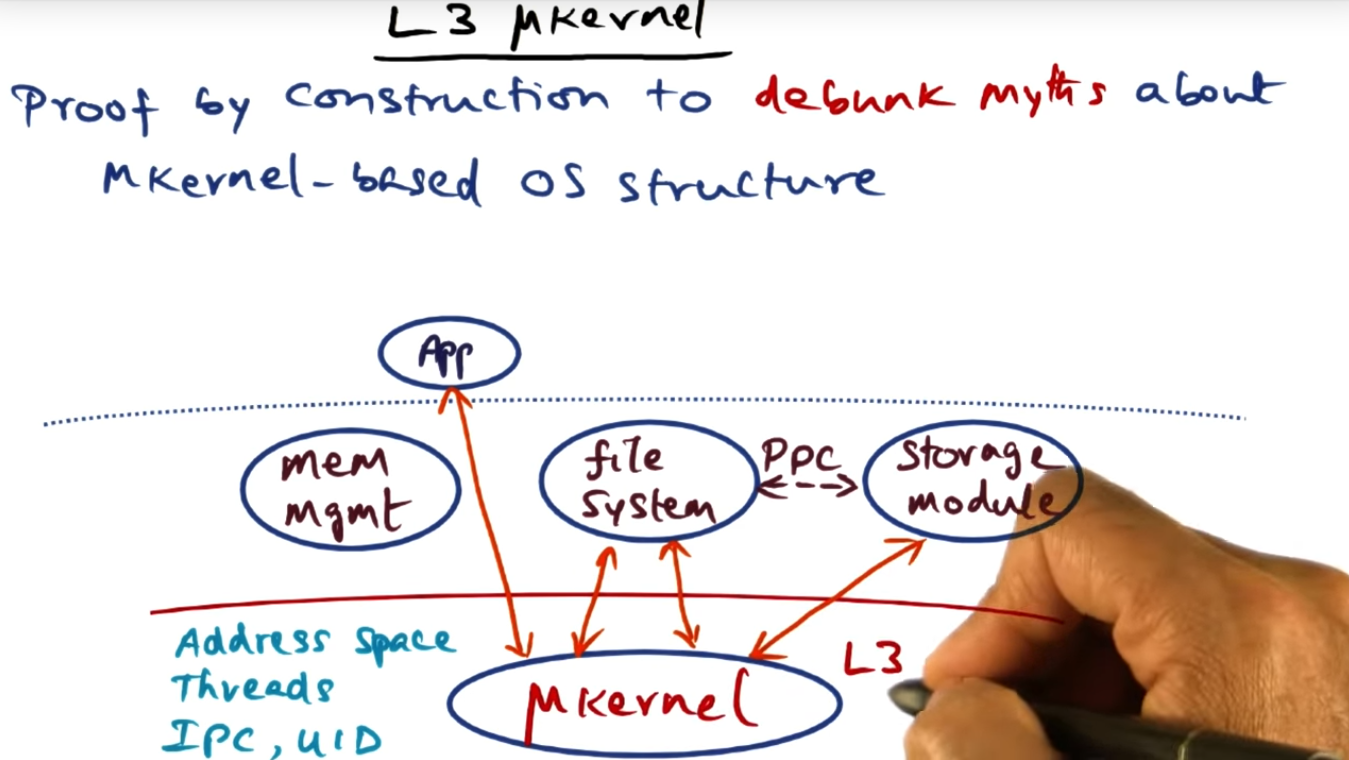
L3 Microkernel
Summary
L3 Microkernel argues that the OS structure is sound but what really needs to be the focus is efficient implementation since its possible to share hardware address space while offering protection domains for the OS services. How that works? Will find out soon
Strikes against the Microkernel
Summary
Three explicit strikes of providing application level service in a microkernel structure (i.e. border crossings, address space switches, thread switches and IPC requiring the kernel. One implicit cost: memory subsystem and loss of locality
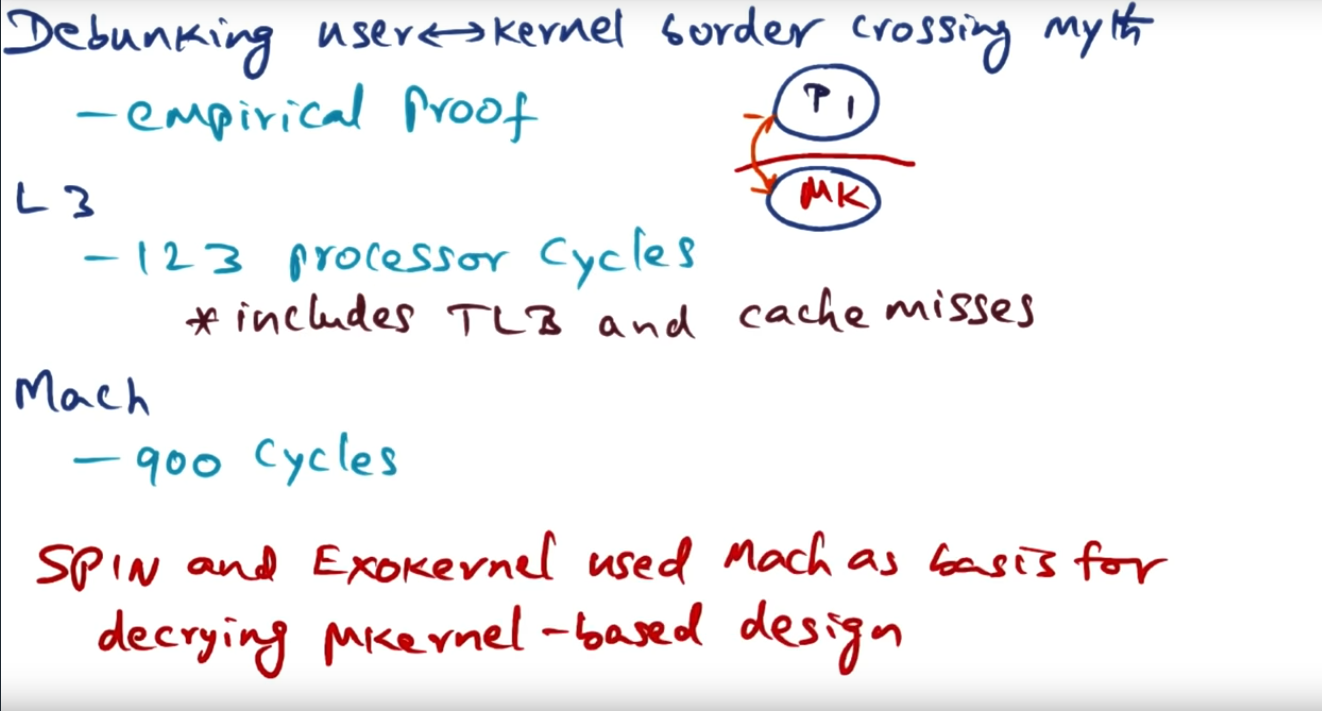
Debunking User Kernel Borer Crossing Myth
Summary
SPIN and Exokernel used Mach as basis for decrying micro kernel based design. In reality, the border crossing costs is much cheaper: 123 processor cycles versus 900 cycles (in March)
Address Space Switches
Summary
For address space switch, do you need to flush the TLB? It depends. I learned that for address space tags (basically a flag for a process ID), you do not have to. But I also thought that if you used a virtually indexed physically tagged address you don’t have to either.
Address Space Switches with AS Tagged TLB
Summary
With address space tags (discussed in previous section), you do not need to flush the TLB during a context switch. This is because the hardware will not check two fields: the tag and the AS (i.e. the process ID). If and only if those two attributes match do we have a TLB hit).
Liedke’s Suggestions for Avoiding a TLB Flush
Summary
Basically leverage the hardware’s capabilities, like segment registers. By defining a protection domain, the hardware will check whether or not the virtual address being translated falls between the lower and upper bound defined in the segment registered, the base and bound registers. Still don’t understand how/why we can use multiple protection domains.
Large Protection Domains
Summary
If a process occupies all the hardware, then there are explicit and implicit costs. Explicit in the sense that a TLB flush may take up to 800+ CPU cycles. Implicit in the sense that we lose locality
Upshot for Address space switching?
Summary
Small address space then no problem (in terms of expensive costs) for context switching. Large address space becomes problematic because of not only flushing the TLB but more costly is the lost in locality, not having a warm cache
Thread switches and IPC
Summary
The third myth that L3 Microkernel debunks is the expensive cost of thread switching. By construction (not entirely sure what this means or how this is proved)
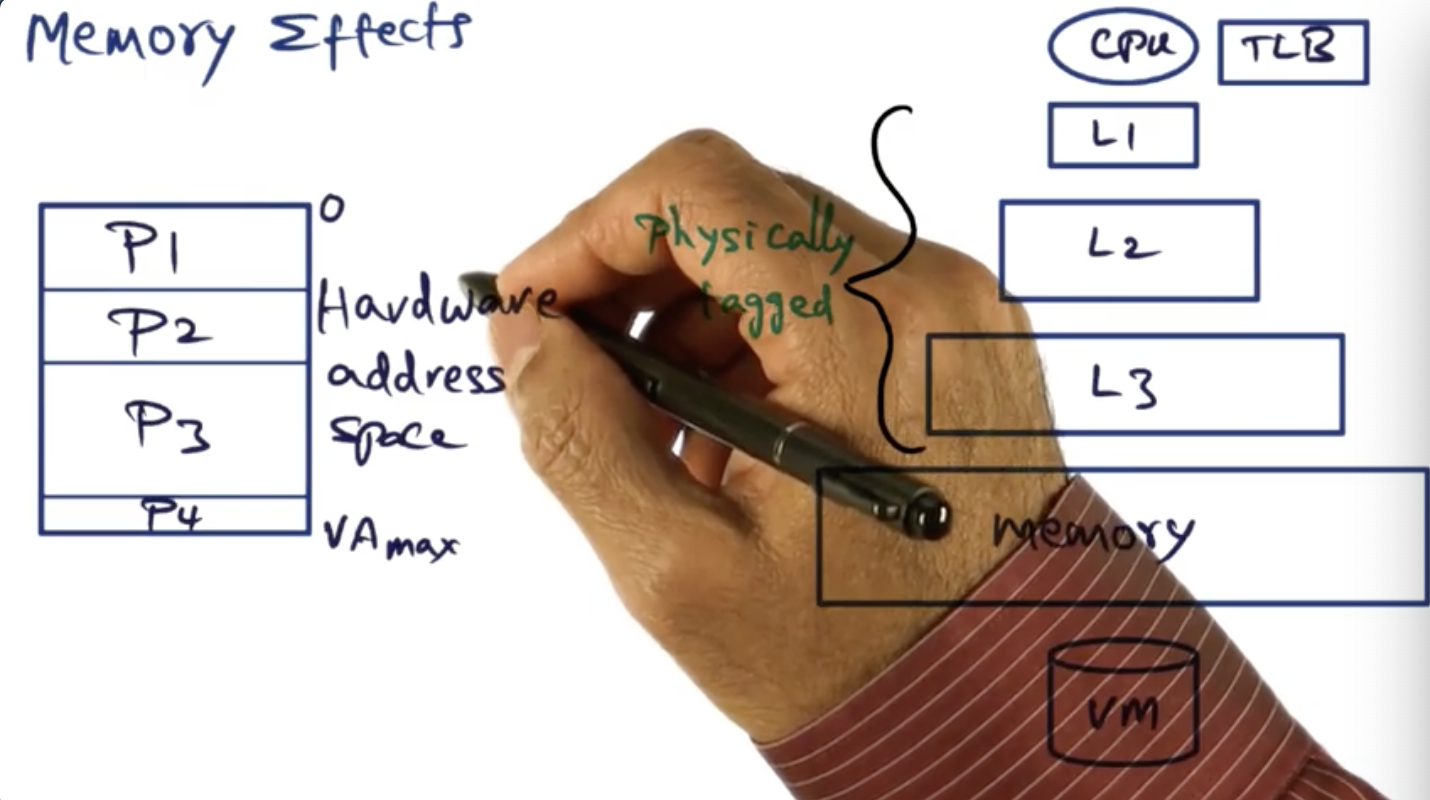
Memory Effects
Summary
Implicit costs can be debunked by putting protection domains in the same hardware address space, but requires that we use segment registers to protect processes from one another. For large protection domains, the costs cannot be avoided
Reasons for Mach’s expensive border crossing
Summary
Because Mach’s focus was on portability, there’s code bloat and as a result, there’s less locality and incurs longer latency for border crossing. In short, Mach’s memory footprint (due to code bloat and portability) is the main culprit, not the actual philosophy of micro kernel