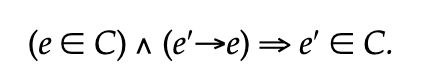I just finished Spring 2021 at Georgia Tech OMSCS and published a farewell note on the classroom’s forum (i.e. Piazza platform) and would like to share that here:
This was one hell of a semester! Hats off to professor Ada and our great TAs — I learned a great deal about both theoretical and practical distributing computing knowledge, experiencing first hand how tweaking a retry timer by a few hundred milliseconds can make or break your day.
But above all else, thanks to all the other students in this class, I felt extremely supported, more supported than any of the 8 courses I had previously taken in the program.
More than once throughout the class I contemplated just throwing in the towel. The last couple projects in particular really wore me out mentally and emotionally (e.g. 10 hours troubleshooting for a one-line fix to pass one single test) and if it wasn’t for the constant support of all my peers over Piazza and Slack, I would’ve probably not only dropped from the course but the journey itself would’ve felt a lot more isolating, especially in the midst of the pandemic.
Now, there are definitely rough edges with this course, particularly around pacing on the last couple projects. But given that this was the first semester that distributed computing was offered as part of OMSCS, I anticipated minor bumps coming into this class and have no doubts that the logistics will get smoothed out over the next couple semesters.
Finally, for those of you graduating this semester, congratulations! Way to go out with a bang. And for the rest of us, see you next semester!
Thanks again for all the support and let’s stay connected (contact info below). Now, time for a much needed nap after taking the final exam:
The above diagram I diagrammed illustrates the impact to a network packet when setting the maximum segment size in iperf3. With an MSS of 1436, the segment (i.e. TCP payload) ends up 1424, due to the overhead of the 12 byte TCP options.
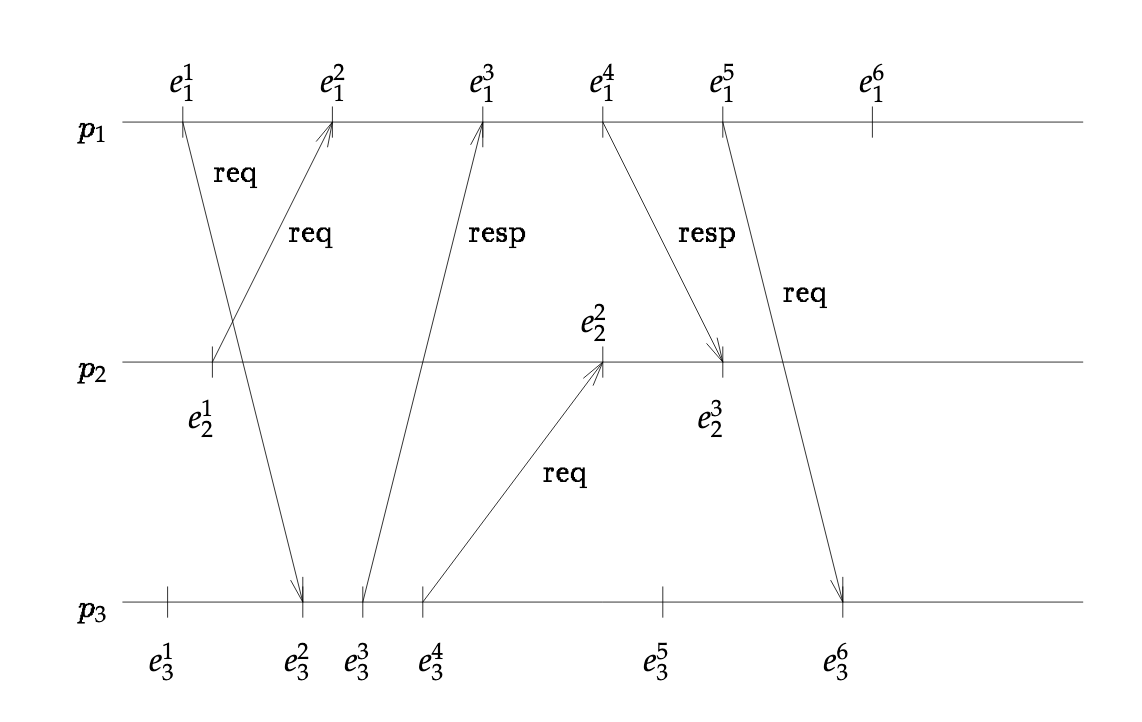
In “Consistent Global States of Distributed Systems: Fundamental Concepts and Mechanisms”, the authors propose capturing a distributed system’s computation using a time series graph. Each row in the graph represents a process (e.g. P1, P2, P3), and each tick (e.g. e1, e2) within that row represent a an event: a local event, a send message event, a receive message event. For example, looking at the figure above, P1’s event is a local event but P1’s second event represents the reception of the message sent from P2.
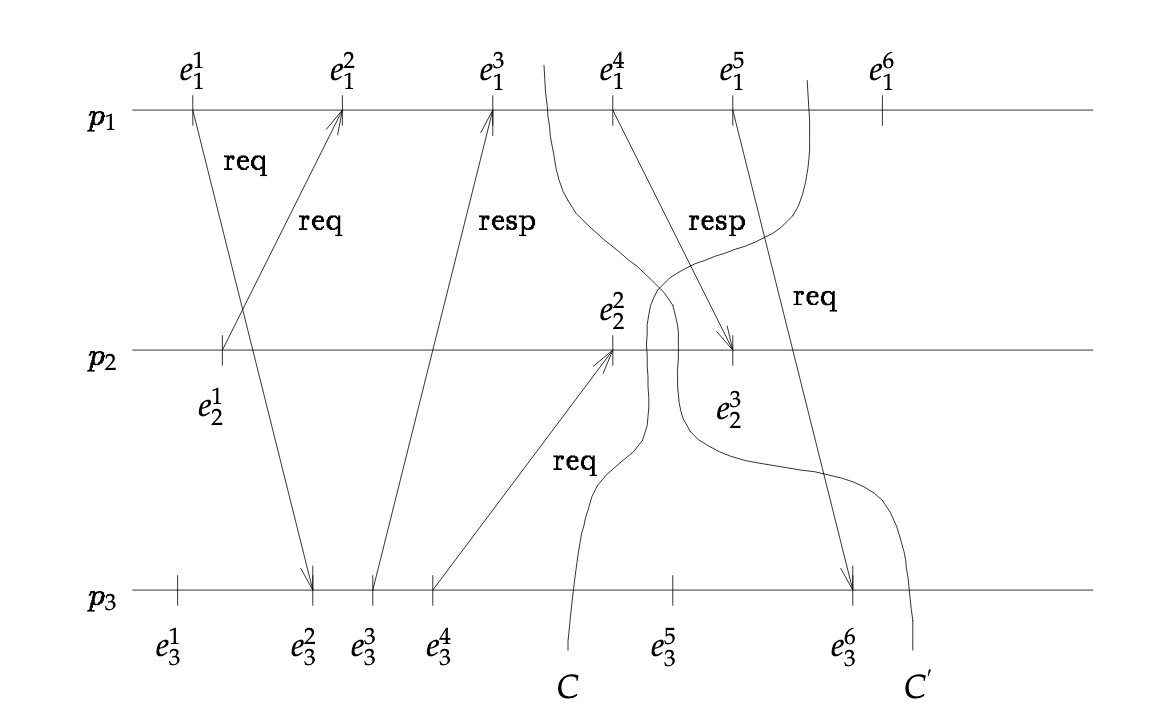
Snapshot of distributed system using cuts
Now, say we wanted to take a snapshot in time of all the processes. How do we model the system’s state? Well, the authors describe a technique they call cuts. Essentially, a cut is a tuple, each element signifying each process’s last event (i.e. called a frontier) that should be considered part of the snapshot state.
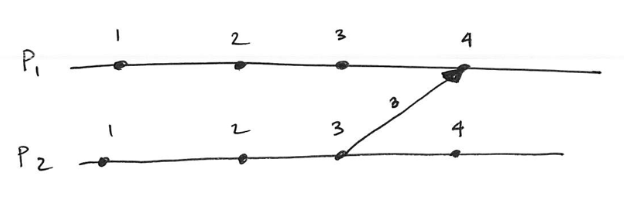
Cuts of a distributed computation
In the figure above, two cuts exist. The first cut is (5, 2, 4), the second cut (3,2,6). For the first cut, we include P1’s events up to (and including) event 5. For the same cut, we include P2’s events up to (and including) event 2.
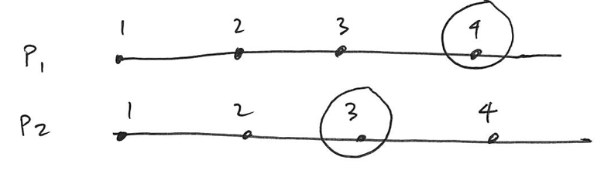
Consistent versus Inconsistent
Now, there are two types of cuts. Consistent and inconsistent cuts. Returning back to the figure above, the first cut (C) is considered “consistent” while the latter (C’) “inconsistent”.
Why?
A consistent, according to the authors, can be defined using mathematical notation.
Definition of consistent cut
If that’s not clear, they offer another explanation: “In other words, a consistent cut is left closed under the causal precedence relation.”
Inconsistent cut in layman terms
Okay, what does this really mean? I still find it a bit confusing, so let me try to form it in my own words.
If an event (event_x) within tuple was caused by another event (event_y), then the causal event (event_y) must be included within the tuple. As an example, take a look back at the figure above. P3’s event 6 was caused by P1’s event 5. However, the cut’s frontier event for process 1 is event 3, failing to include P1’s event 5. Therefore, this cut can be classified as inconsistent.
Apparently, this paper is a seminal piece of work that goes on to describe and prove that, given a single process failure within a distributed system, the underlying system cannot achieve consensus (i.e. the nodes cannot reach a state where they all agree on some proposed value). That’s right: not difficult, but impossible. Assuming that this theorem holds true, how the hell do we even build robust distributed systems that can tolerate failure? Surely there must be a way. Otherwise, how the hell do popular cloud services like Amazon S3 and Amazon DynamoDB guarantee high availability and consistency.
My gut tells me that the authors of the paper — Fischer, Lynch, Patterson — make strict assumptions about the underlying system. And if we can somehow relax these assumptions, then we can in fact build highly available distributed systems. But, I’ll find out soon since I’ll be reading both this paper as well as another seminal piece of work “Paxos made simple” by Leslie Lamport.
For the last couple days, I’ve been watching the distributed systems video lectures and reading the recommended papers that cover logical clocks. Even after making multiple passes on the material, the concepts just haven’t clicked: I cannot wrap my mind around why Lamport’s clocks satisfy only consistency — not strong consistency. But now I think I have a handle on it after sketching a few of my own process diagrams (below).
Before jumping into the examples, let’s first define strong consistency. We can categorize a system as strongly consistent if and only if, we can compare any two related event’s timestamps — and only the timestamps — and conclude that the two events are causally related. In other words, can we say “event A caused event B” just by inspecting their timestamps. In short, the timestamps must carry enough information to determine causality.
Example: Time Diagram of Distributed Execution
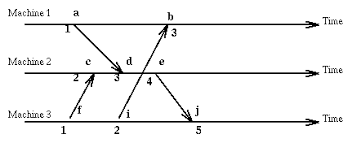
In my example below, I’ve limited the diagram to two process: P1 and P2.
P1 executes three of its own events (i.e. event 1, event 2, event 3) and receives an event (i.e. event 4) from P2. P2 executes 2 events (i.e. event 1, event 2), sends a message (i.e. event 3) to P1, then P4 executes a fourth and final event. To show the sending of a message, I’ve drawn an error connecting the two events, (P2, 3) to (P1, 4).
Logical clocks with an arrow from P2 to P1, showing causality between events (P2, 3) and (P1, 4)
Cool. This diagram makes sense. It’s obvious from the arrow that (P2, 3) caused (P1, 4). But for the purposes of understanding why Lamport’s clocks are not strongly consistently, let’s remove the arrow from the diagram and see if we can reach the same conclusion of causality by inspecting only the timestamps.
Removing arrow that connects (P2, 3) to (P1, 4)
Next, let’s turn our attention to the timestamps themselves.
Can we in any way say that (P2, 3) caused (P4, 4)?
Just by comparing only the timestamps, what can we determine?
We can say that the event with the lower timestamp happened before the event with the higher timestamp. But that’s it: we cannot make any guarantees that event 3 caused event 4. So the timestamps in themselves do not carry sufficient information to determine causality.
If Lamport’s scalar clocks do not determine causality, what can we use instead? Vector clocks! I’ll cover these types of clocks in a separate, future blog post.
Cognitive biases (built-in patterns of thinking) and fallacies (errors in thoughts) creep into our every day lives, sometimes with us not even knowing it. For example, ever wonder why you work just a little harder, a little quicker, when you think someone is standing over your shoulder, watching you? This is known as the Hawthorne effect: people tend to change their behaviors when they know (or think) they are being watched.
Or how about situations when we are trying to solve a problem but reach for the same tool (i.e. using a hammer)? That might be the exposure effect, people preferring the same tools, processes — just because they are familiar.
Essentially, cognitive biases and fallacies trick us: they throw off our memory, perception, and rationality. So we must surface these blind spots to the forefront of our brains when designing and building distributed systems.
8 Fallacies
According to Schneider, there are 8 fallacies that bite distributed system designers. These fallacies stood the test of time. They were drafted over 25 years ago; designers have been building distributed systems for over 55 years. Despite advances in technology, these fallacies still remain true today.
1. The network is reliable
2. Latency is zero
3. Bandwidth is infinite
4. The network is secure
5. Topology doesn’t change
6. There is one administrator
7. Transport cost is zero
8. The network is homogeneous
Notice anything in common among these fallacies? They all tend to revolve around assumptions we make about the underlying communication, the network.
Network assumptions
I wouldn’t go as far and networks are fragile, but failures (e.g. hardware failure, power outages, faulty cable) happen on a daily basis. Sometimes, these failures are not observed by our users, their traffic being automatically routing towards an alternative — albeit sometimes a little slower — path; their dropped messages being resent thanks to the underlying (transport) communication protocol.
So, what does this mean for you, the system designer?
To overcome network hiccups, we should either “use a communication medium that supplies full reliable message” or employ the following messaging techniques: retry, acknowledge important messages, identify/ignore duplicates, reorder messages (or do not depend on message order), and very message integrity.
In addition to hardening our software, be prepared to thoroughly stress test your system. You’ll want to hamper network performance: drop messages, increase latency, congest the pipes. How well can your system tolerate these conditions? Can your system sustain these performance degradations? Or does your system fail in unexpected ways?
Main takeaway
In short, we should assume that the failure is unreliable and in response we should both employ techniques (e.g. retry messages) that harden our system as well as thoroughly test our systems/software under non-ideal conditions including device failures, congestion, increased latency.
References
1. Hunt Pragmatic Thinking and Learning: Refactor your wetware
2. https://fallacyinlogic.com/fallacy-vs-bias/
The original paper “Recovery management in quicksilver” introduces a transaction manager that’s responsible for managing servers and coordinates transactions. The below notes discusses how this operating system handles failures and how it makes recovery management a first class citizen.
Cleaning up state orphan processes
Cleaning up stale orphan processes
Key Words: Ophaned, breadcrumbs, stateless
In client/server systems, state gets created that may be orphaned, due to a process crash or some unexpected failure. Regardless, state (e.g. persistent data structures, network resources) need to be cleaned up
Introduction
Key Words: first class citizen, afterthought, quicksilver
Quicksilver asks if we can make recovery a first class citizen since its so critical to the system
Quiz Introduction
Key Words: robust, performance
Users want their cake and eat it too: they want both performance and robustness from failures. But is that possible?
Quicksilver
Key Words: orphaned, memory leaks
IBM identified problems and researched this topic in the early 1980s
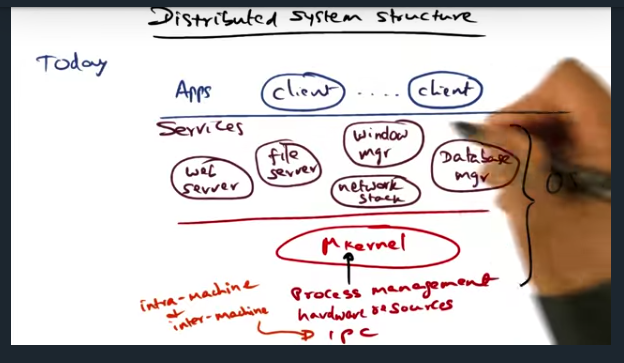
Distributed System Structure
Distributed System Structure
Key Words: microkernel, performance, IPC, RPC
A structure of multiple tiers allows extensibility while maintaining high performance
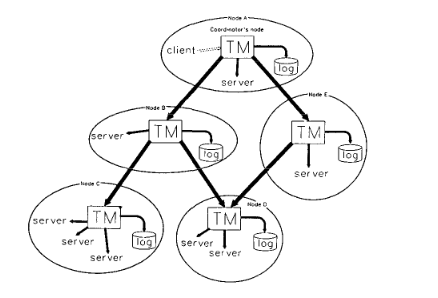
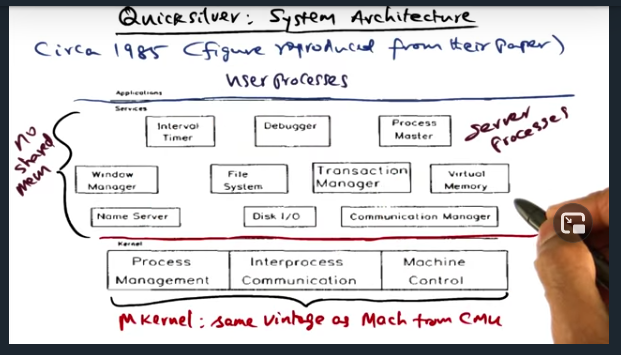
Quicksilver System Architecture
Quicksilver: system architecture
Key Words: transaction manager
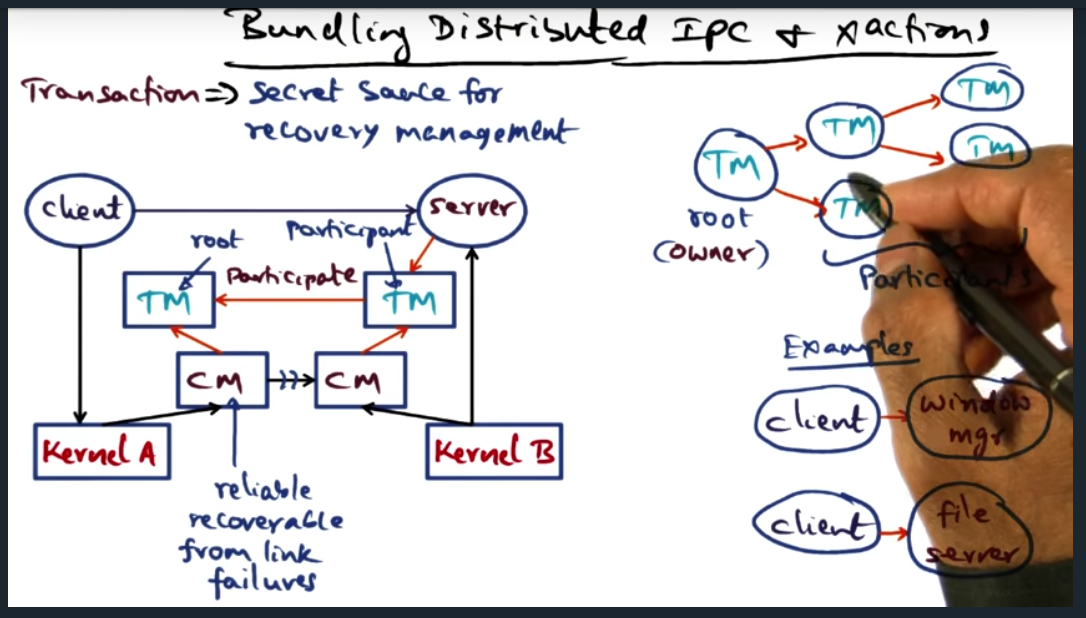
Quicksilver is the first network operating system to propose transactions for recovery management. To that end, there’s a “Transaction Manager” available as a system service (implemented as a server process)
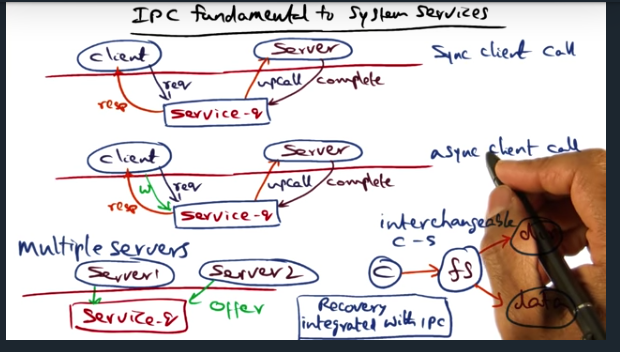
IPC is fundamental to building system services. And there are two ways to communicate with the service: synchronously (via an upcall) and asynchronously. Either, the center of this IPC communication is the service_q, which allows multiple servers to perform the body of work and allows multiple clients to enqueue their request
During a transaction, there is state that should be recoverable in the event of a failure. To this end, we build transactions (provided by the OS), the secret sauce for recovery management
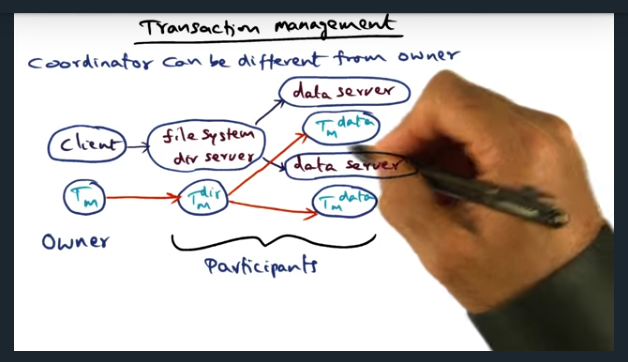
When a client requests a file, the client’s transaction manager becomes the owner (and root) of the transaction tree. Each of the other nodes are participants. However, since client is suspeptible to failing, ownership can be transferred to other participants, allowing the other participants to clean up the state in the event of a failure
Many types of failures are possible: connection failure, client failure, subordinate transaction manager failure. To handle these failures, transaction managers must periodically store the state of the node into a checkpoint record, which can be used for potential recovery
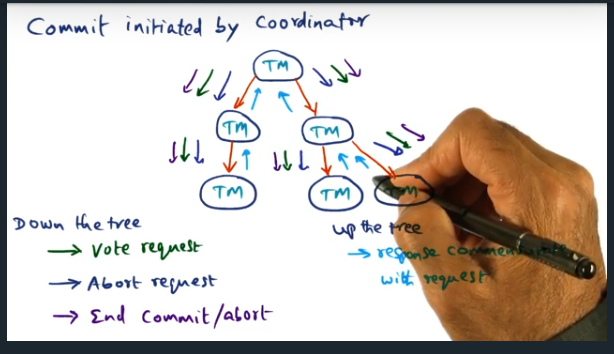
Commit Initiated by Coordinator
Commit initiated by Coordinator
Key Words: Coordinator, two phase commit protocol
Coordinator can send different types of messages down the tree (i.e. vote request, abort request, end commit/abort). These messages help clean up the state of the distributed system. For more complicated systems, like a file system, may need to implement a two phased commit protocol
Upshot of Bundling IPC and Recovery
Upshot of bundling IPC and Recovery
Key Words: IPC, in memory logs, window of vulnerability, trade offs
No extra communication needed for recovery: just ride on top of IPC. In other words, we have the breadcrumbs and the transaction manager data, which can be recovered
Need to careful about choosing mechanism available in OS since log force impacts performance heavily, since that requires synchronous IO
Conclusion
Key Words: Storage class memories
Ideas in quicksilver are still present in contemporary systems today. The concepts made their way into LRVM (lightweight recoverable virtual machine) and in 2000, found resurgence in Texas operating system
Like my previous posts on snapshotting my understanding of gRPC and shapshotting my understanding of barrier synchronization, this post captures my understanding of MapReduce, a technology I’ve never been exposed to before. The purpose of these types of posts is to allow future self to look back and be proud of what I learned since the time I’m pouring into my graduate studies takes away time from my family and my other aspirations.
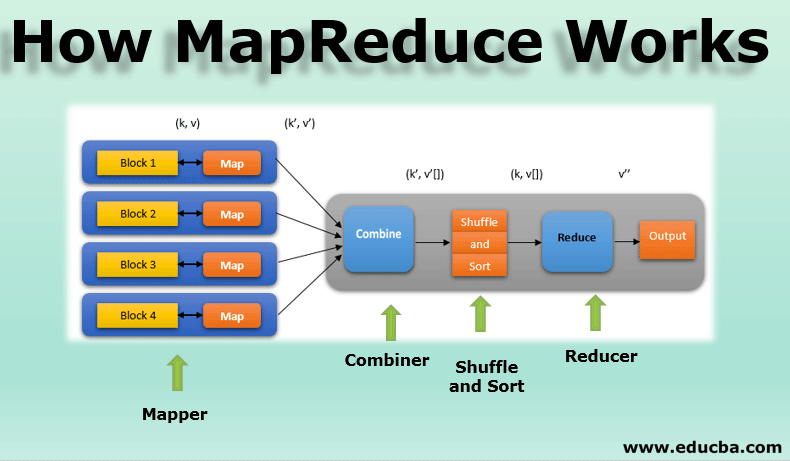
Anyways, when it comes to MapReduce, I pretty much know nothing beyond a very high level and superficial understanding: there’s a map step followed by a reduce step. Seriously — that’s it. So I’m hoping that, once I finish reading the original MapReduce paper and once I complete Project 4 (essentially building a MapReduce framework using gRPC), I’ll have a significantly better understanding of MapReduce. More importantly, I can apply some of my learnings to future projects.
Some questions I have:
How does MapReduce parallelize work?
What are some of the assumptions and trade offs of the MapReduce framework?
What are some work loads that are not suitable for MapReduce?
The idea is that instead of each router performing a simple next hop look up, let’s make the routers smart and inject code in the packet that can influence the flow. How can we do this securely and safely? And without adversely impacting other flows
An Example
Real life example of Active Networks
Summary
Key Words: Demultiplex
Nice example from the professor. Basically, packet looks like mutlicast stream. But instead, the sender sends a single message and an edge router will demultiplex the message, sending out that single message to multiple destinations
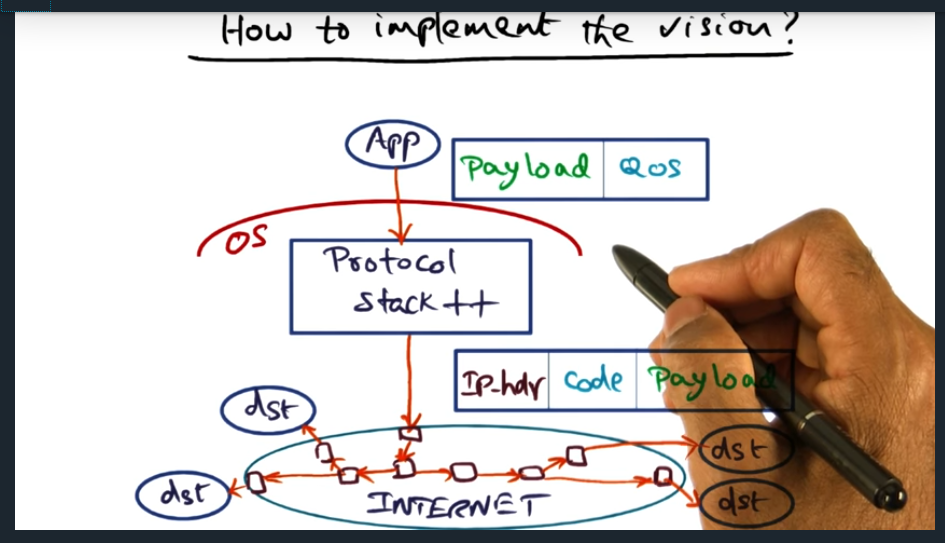
How to implement the vision
How to implement the vision
Summary
Essentially, application interfaces with the protocol stack, application sending its quality of service (QoS) requirements. Then, once this packet reaches protocol stack, the protocol stack will slap on an IPHeader with some code embedded inside the packet, the code later read in by routers up stream. But … how do we deal with the fact that not all routers participate? Routers are not open
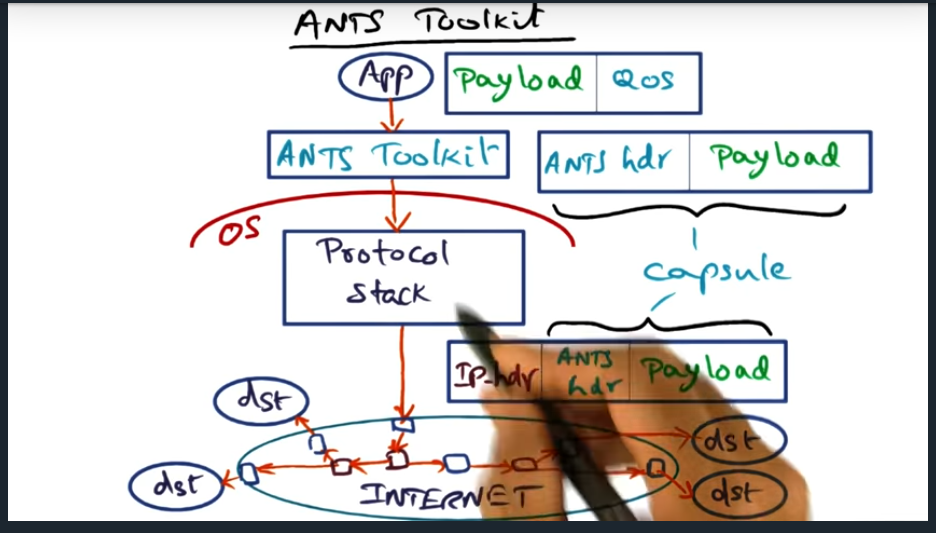
ANTS
Ants toolkit
Summary
Key Words: Active Node Transfer System (ANTS), edge network
To carry out the vision, there’s active node transfer system, where the specialize nodes sit at the edge of the network. But my question still remains, if you need to send it out to multiple recipients, in different edge networks, feels like the source edge node will need to send more than one message
ANTS Capsule and API
ANTS Capsule and API
Summary
Very minimal set of APIs. Most important to note is that the ANTS header does not contain executable code. Instead, the type field contains a reference and the router will then look up the code locally
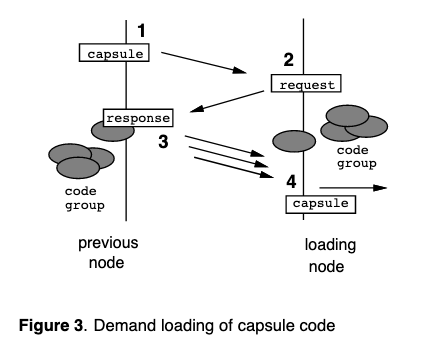
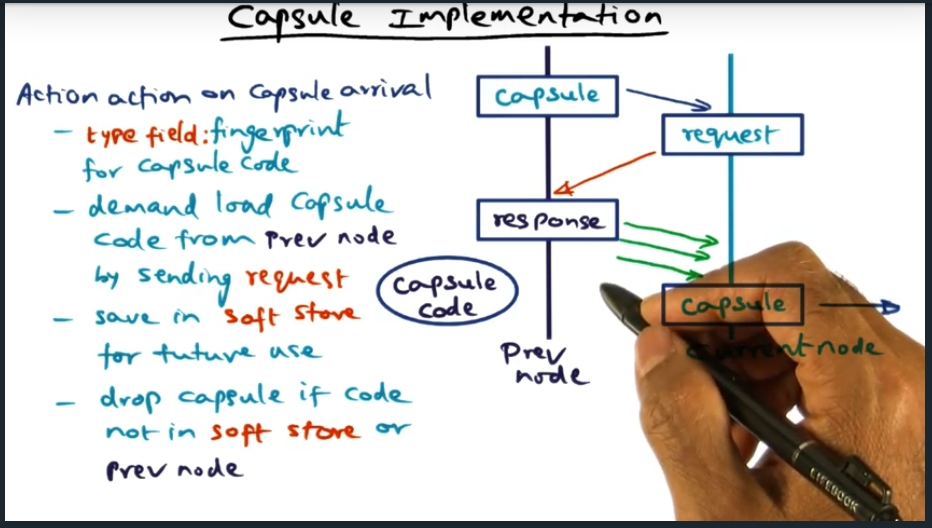
Capsule Implementation
What happens during capsule arrival
Summary
Capsule contains a fingerprint for capsule code, used to cryptographically verify capsule. If router does not have code locally stored in the soft store, will need to ask the prev node for the code (and again verifying capsule). Finally, soft store is essentially a cache.
Potential Applications
Potential Applications of active networks
Summary
Active networks used for network functionality, not higher level applications. Basically, we’re adding an overlay network (again not sure how this all relates to advanced operating systems or distributed systems but interesting nonetheless)
Pros and Cons of Active Networks
Pros and Cons of Active Networks
Summary
Pros and Cons of Active Networks. On one hand, we have flexibility from the application perspective. But there are cons: protection threads (can be defended by: runtime safety using java sand boxing, prevent code spoofing using robust fingerprint, and restrict APIs for soft state integrity). From a resource management perspective, we’ll limit the restricted API to ensure code does not eat up lots of resources and finally, flooding the network is not really a problem since the internet is already susceptible to this.
Quiz
Summary
Some challenges include 1) need buy in from router vendors 2) ANTS software cannot match speed requirements
Feasible
How feasible of Active Networks
Summary
Again, because router makers loath to open up network and software cannot match hardware routing, active networks can only sit at the edge of the network. Moreover, people are worried (as they should be) having arbitrary code running on public routing fabric
Conclusion
Summary
Active Networks way ahead of its time. Today, we are essentially using similar principles for software defined network
According to a stackoverflow post, Jacob Baskin states that an invariant is a property of the program state that is always true. Tieing that together with the original question that I had asked in the previous paragraph, I think what Leslie is trying to say is that because of the happening order event, we know that [in a distributed system] events will be always be partially ordered — not totally ordered.