
This blog post contains notes I took on memory segmentation, from “OS in Three Easy Pieces Chapter 16”, one strategy for implementing virtual memory systems. In the next blog post, I’ll cover a different approach: paging.
16.1 Segmentation: Generalized Base / Bounds
Summary
We use segmentation to divide the virtual address space into three distinct segments: code, stack and heap. This technique allows us to accommodate processes with large address spaces.
16.2 Which segment are we referring to ?
Summary
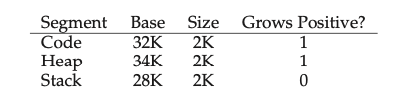
How do hardware know which segment that the request is referring to? Are we requesting memory for stack, heap, or code? Well, there are two approaches: an explicit and implicit approach. For the explicit, we reserve 2 bits at the top of the address. So 00 might refer to code, and 01 might refer to heap, and 10 might refer to the stack. But there’s an implicit approach, too. If the address is based off of the stack base pointer, then we check the stack segment.
16.3 What about the stack?
Summary
Why do we need special consideration for the stack? Because the stack grows backwards, from a higher memory address to lower. Because of this, we need an additional flag to tell the hardware whether the segment grows up or down.
16.4 Support for sharing
Summary
Systems designers realized that with segmenting, processes can share memory with each other. In particular, they could share code segments and in order to support this feature, hardware must add an additional bit to the memory metadata. In particular, the “Protection” field tells us whether or not the segment can be read and executed or can be read and written to. Obviously, for code sharing, we need the segment to be read-execute only.
16.5 Fine-grained vs Coarse-grained Segmentation Fault
Summary
Breaking the address space into (3) segments is considered coarse-grained and some designers preferred a more flexible address space, with a large number of smaller segments, known as fine-grained. The idea behind this was that the designers thought they could learn about which segments were in use and could utilize memory more effectively. Not sure if they were right, though.
16.6 OS Support
Summary
There are two issues with segmentation: a pre-existing problem is how to handle context switches and the second is how to handle external fragmentation? With segmentation, we no longer have a contiguous block of addresses for the process. Instead, we chop them up. So what happens if the stack or heap requires 20KB and although we have 24KB, there’s no continuous space? Well, there are several approaches, the first being extremely inefficient: a background process runs and re-arranges the blocks into contiguous blocks: this approach is extremely inefficient. Another approach is to maintain some sort of free-list and there is a long list of algorithms (e.g. first-fit, worst-fit). Regardless of algorithm, we cannot avoid this issue called external fragmentation.
16.7 Summary
Summary
Segmentation helps accomplish a more effective virtualization of memory but it does not come without cost or complexities. The primary issue is external fragmentation and the second issue is that the if the segments do not line up exactly, then we waste lots of memory.