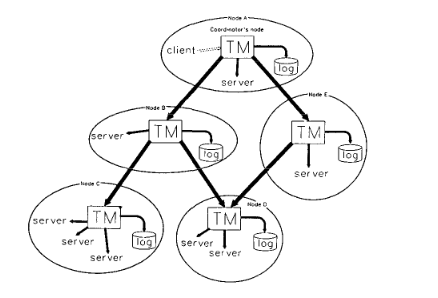
Why publish my studying techniques?
This semester, I manage to pull off an A not only for the midterm and final exams, but for the class as a whole. My intention of revealing my grade is not to boast (that’s poor taste), but to give some credibility to the techniques and strategies below, techniques and strategies (rooted in pedagogy) for someone who is working full time, someone who is is growing as a (freshly minted) father and husband, someone who pursues a wide array of other interests outside of graduate school. That being said, receiving the highest letter grade is not my goal in the program (although I admit it once was). My goal is to learn as much as I can, absorb as much computer science, connect the dots between all the other classes, bridge the gap between theory and practice, and apply the knowledge to my job as a software engineer.
Exam logistics
Assumptions
This blog post assumes that you can openly collaborate with other students. During my term (Fall 2020), us students shared our answers using a two pronged approach: studying with one another over Zoom (see my post on War Rooms) and comparing answers in a shared Google Document. Crowd source at its finest.
Time Bound
You have up to 3 days to take exams. And before the exam window opens, the study guides (i.e. all the previous exams bundled up in a .zip file) are published. That’s about a week for you to prepare. And once the exam window opens, the professor and teacher assistants publish the actual exam. That’s right: they provide all the questions (even then, the exam is no walk in the park). In other words, you walk into the exam with no surprises, knowing exactly what questions to expect.
Spaced repetition
To make the most use out of my time bounded study sessions, I apply three techniques rooted in research: forgetting curve, spacing effect, and testing effect (check out a paper I wrote titled “An argument for a spaced repetition standard”).
Put simply, instead of one massive, multi-hour study session, I break down the study sessions into a fistful of sessions, around five to ten, and spread the sessions across multiple days (i.e. “spaced repetition”), each session lasting anywhere between 10-20 minutes. During each study session, I test myself (i.e. “testing effect”) and try to answer questions just as I’m about to forget them (i.e. “forgetting curve”). With this approach, I optimize memory retention for both short and long term. This technique aligns with what Bacon stated back in 1620:
“If you read a piece of text through twenty times, you will not learn it by heart so easily as if you read it ten times while attempting to recite from time to time and consulting the text when your memory fails”.
Studying previous exams
Here’s how I study previous exams.
First, I create a blank page in Google Docs. Then, I select one of the previous exams (only one because of time constraints) and copy all of its questions into this blank document. Next, I attempt to answer each question on my own: no peeking at the solution guide! This is how I test myself.
After answering each question, I compare my guess — sometimes it is way off — with the answer printed in the answer sheet. If my answer is incorrect, I then copy the correct answer, word by word, below my original answer. The act of copying helps reinforces the right answer and positioning the two answers — mine and the correct one — next to each other helps me see the holes in my logic.
I apply this circular technique — copy question, answer question, compare the two, copy correct answer — for each question listed in the exam. Bear in mind that I apply this circular technique only once. Repetition will come in later when I study the actual final exam.
Studying final exam
Studying for the final exam approach closely resembles my circular technique (describe previously). The main difference is this: instead of only making a single pass through the questions, I make two passes. The first pass is the same (described above) circular technique of copying each questions and taking a stab at them. In the second pass, I review my answers against the collaborated google docs, where all the other students dump their answers.
Once my answer guide — not the collaborated Google Docs — is filled out with (hopefully) the right answers, I then the contents into my space repetition software: Anki. After copying, I simply rote memorize, drilling each questions into my head until I stop answering incorrectly, which normally takes about an hour in total, spread across 2 days.
Finally, after the spaced repetition sessions using Anki, with the contents of the exam sitting fresh in my working memory, I take the exam and simply brain dump my answers.
References
https://blog.mattchung.me/2020/09/27/my-anki-settings-for-cramming-for-an-exam/