Yesterday … was exhausting. A few times throughout the day I actually felt my body shut down and I nearly fell asleep while working. Although I cumulatively got like 7.5 hours of sleep, my sleep was constantly interrupted since Elliott has been (presumably) teething and letting out these screams at 1:00 AM and 3:00AM and 04:00 AM, the screams piercing through out thin walls and echoing throughout the rest of the house.
On top of all this, I felt so overwhelmed with the house move, knowing that we only have just a few days left and there’s so much left to do still. But fortunately Jess and I partnered up and split some tasks up between the two of us. That really helped.
What did I learn
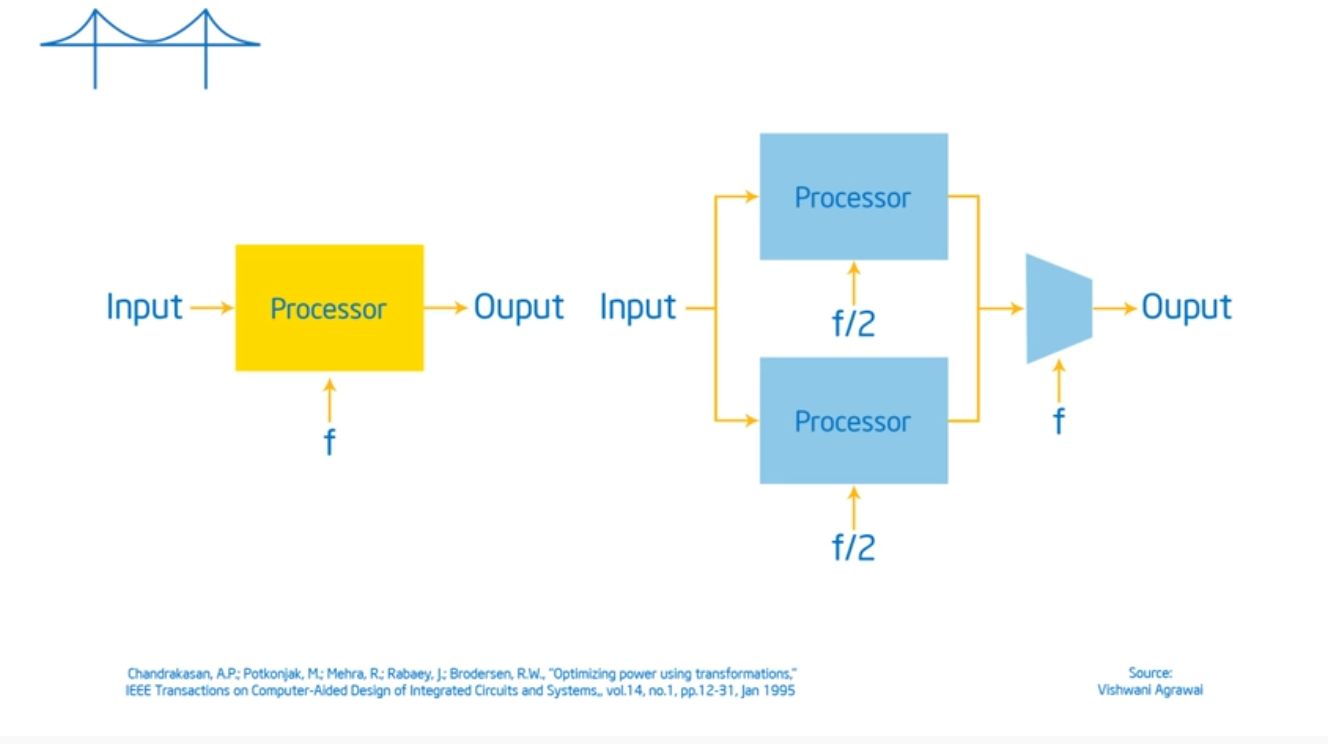
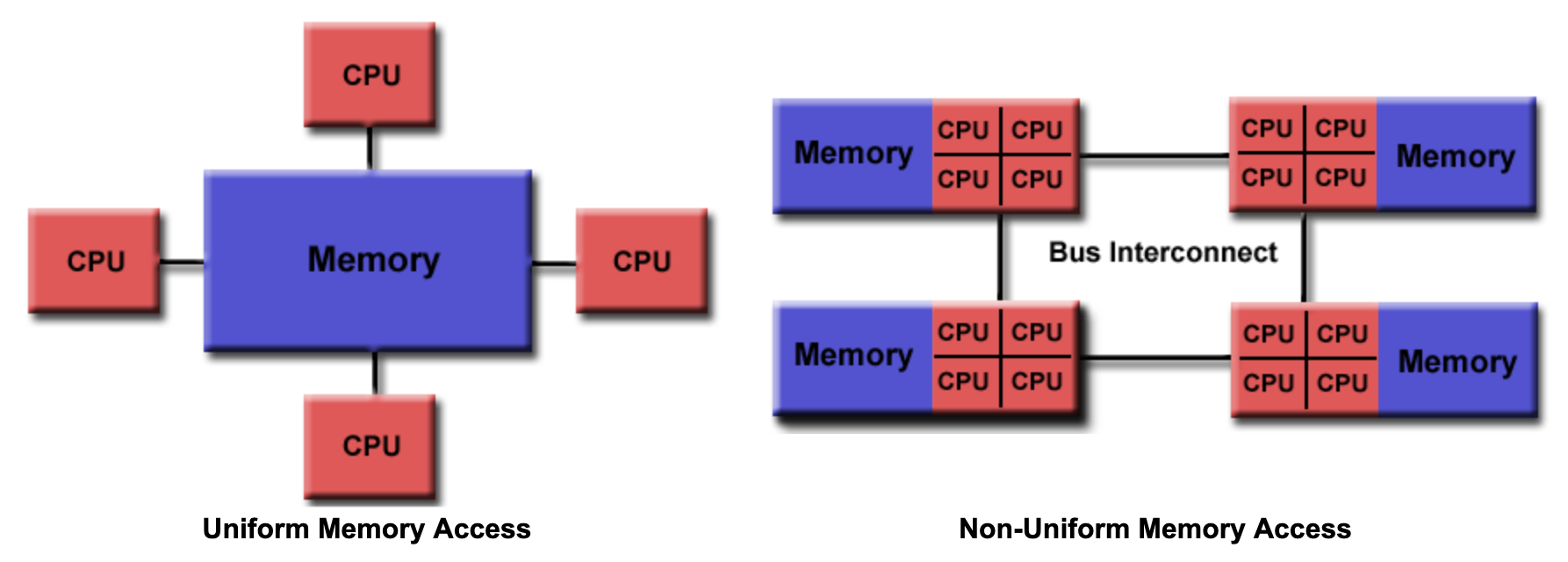
The last true symmetric multiprocessor machine was around the late 1980s. I thought that they were much more prevalent but it appears that most of the hardware today run on non uniformed memory access (NUMA) machines
How to identify and trace concurrent events between processes (a little more difficult than I had originally anticipated) using a good old pen and paper
Politics
Watched about 30 minutes of the first debate between Joe Biden and Donald Trump. Honestly, it’s like watching a circus. Trump constantly interrupts Joe Biden and Joe Biden often goes completely off topic. For example, while talking about his position on supporting the military, he brings up the fact that his son served in the military and currently recovering from drug addiction. While nice to know …. I wonder, it’s totally irrelevant to the conversation.
Family and Friends
Jess and I operated as a team yesterday. Together in the morning, we signed an hours worth of paperwork with a notary sent by the escrow company. After, we divided and conquered. She and Elliott performed the final walk through in Renton while I sorted out how to get us internet (so painful dealing with internet sales representatives) and then I drove to Wells Fargo for my scheduled appointment to transfer the big amount for the down payment of the house.
Interesting Quotes or Idioms
Prime the pump (from video lecture series in Distributed System, Quiz on “relation”)
I’m watching the YouTube learning series called “Introduction to OpenMP” in order to get a better understanding of how I can use the framework for my second project in advanced operating systems. You might find the below notes useful if you don’t want to sit through the entire video series.
Introduction to OpenMP: 02 part 1 Module 1
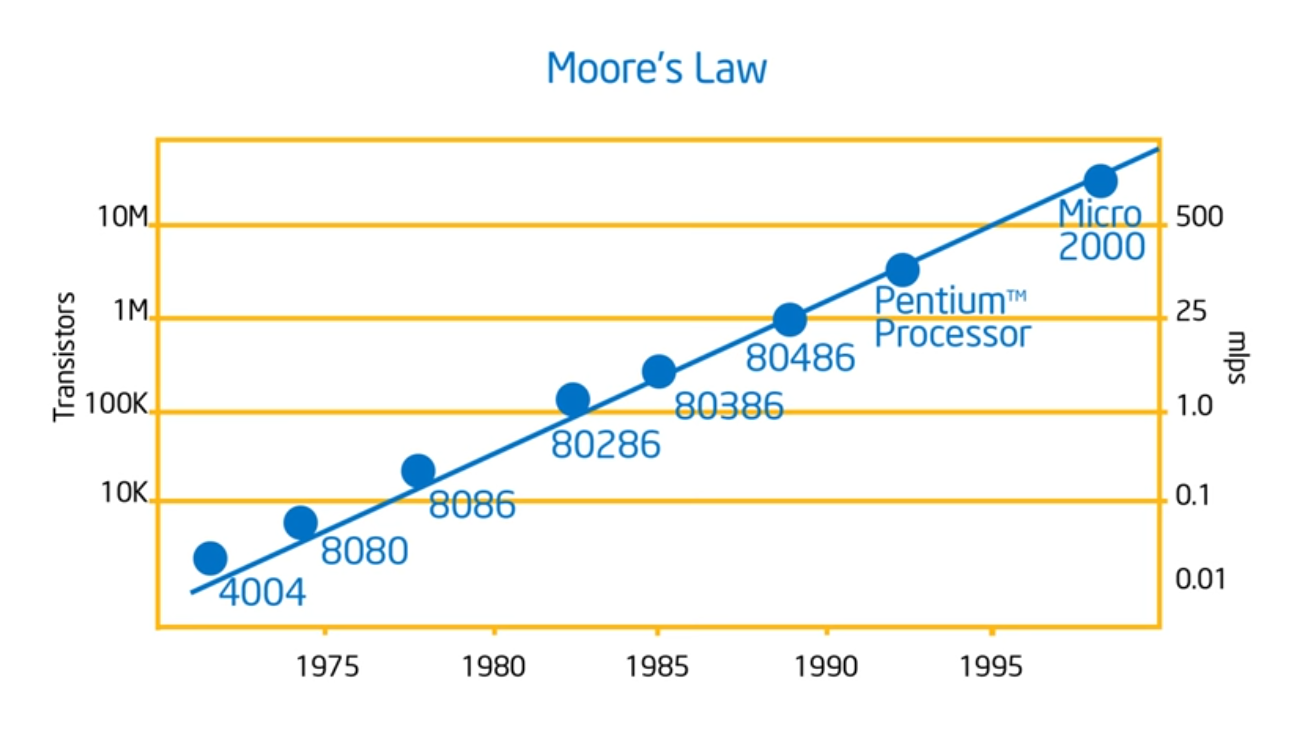
Moore’s Law
Summary
Neat that he’s going over the history, talking about Moore’s Law. The key take away now is that hardware designers are now going to optimize for power and software developers have to write parallel programs: there’s no free lunch. No magic compiler that will take sequential code and turn it into parallel code. Performance now c
Introduction to OpenMP – 02 Part 2 Module 1
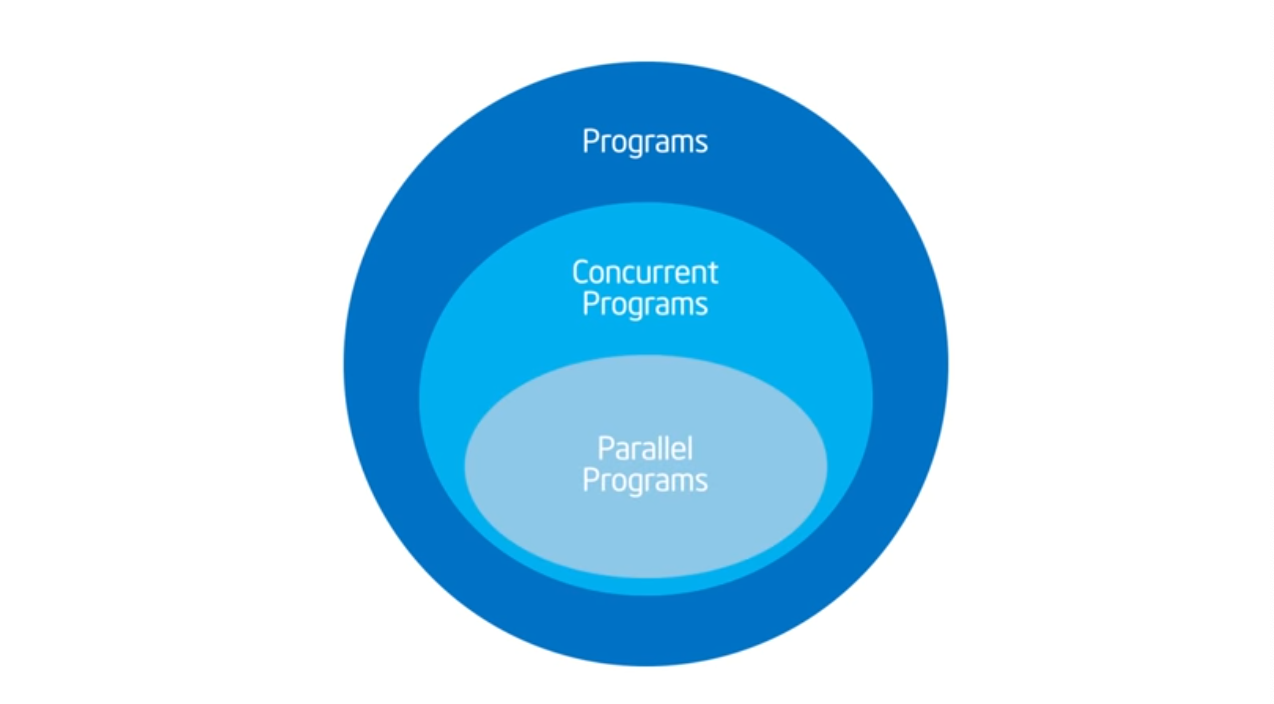
Concurrency vs Parallelism
Summary
The last step should be picking up the OpenMP Library (or any other parallel programming library). What should be done firs and foremost is breaking down your problem (the act of this has not been able to automated) into concurrent parts (this requires understanding of the problem space) and then figure out which can run in parallel. Once you figure that out, then you can use compiler syntactical magic (i.e. pragmas) to direct your compiler and then sprinkle some additional pragmas that will help the compiler tell where the code should enter and where it should exit.
Introduction to OpenMP – 03 Module 02
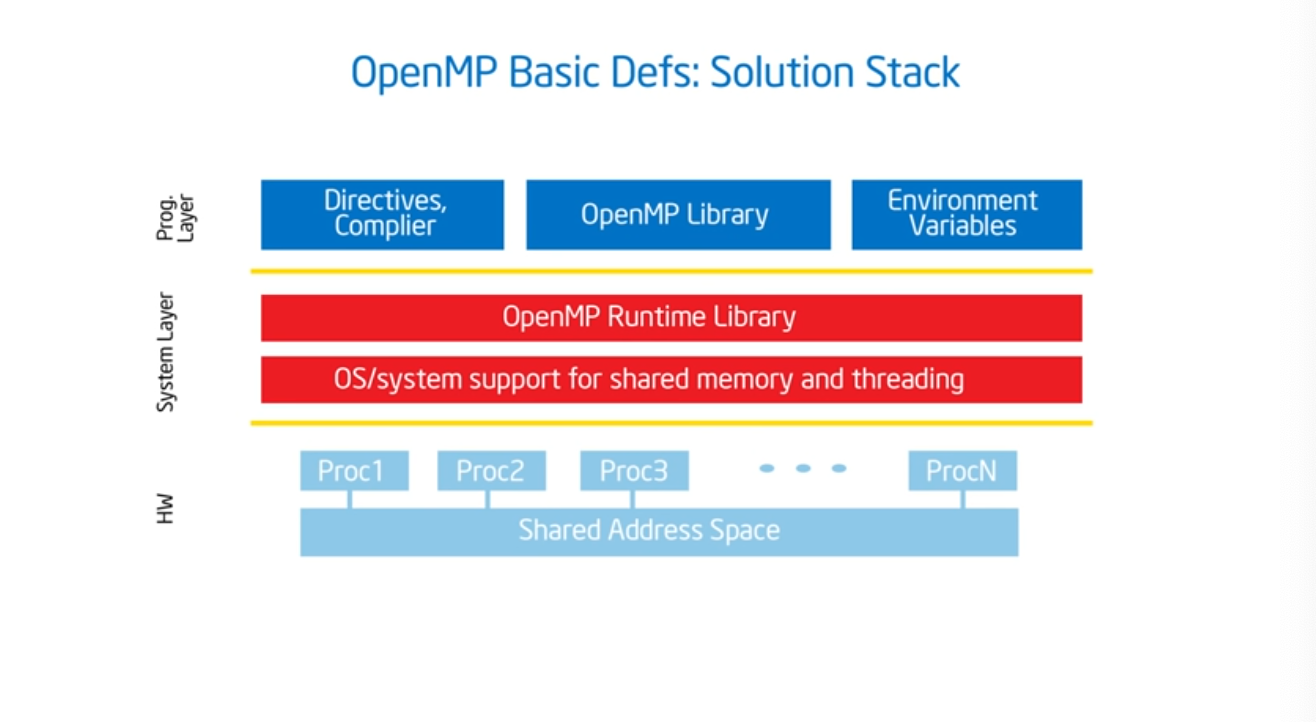
OpenMP Solution Stack
Summary
It’s highly likely that the compiler that you are using already supports OpenMP. For gcc, pass in -fopenmp. And then include the prototype, and add some syntactic sugar (i.e. #pragma amp parallel) which basically gives the program a bunch of threads.
Introduction to OpenMP: 04 Discussion 1
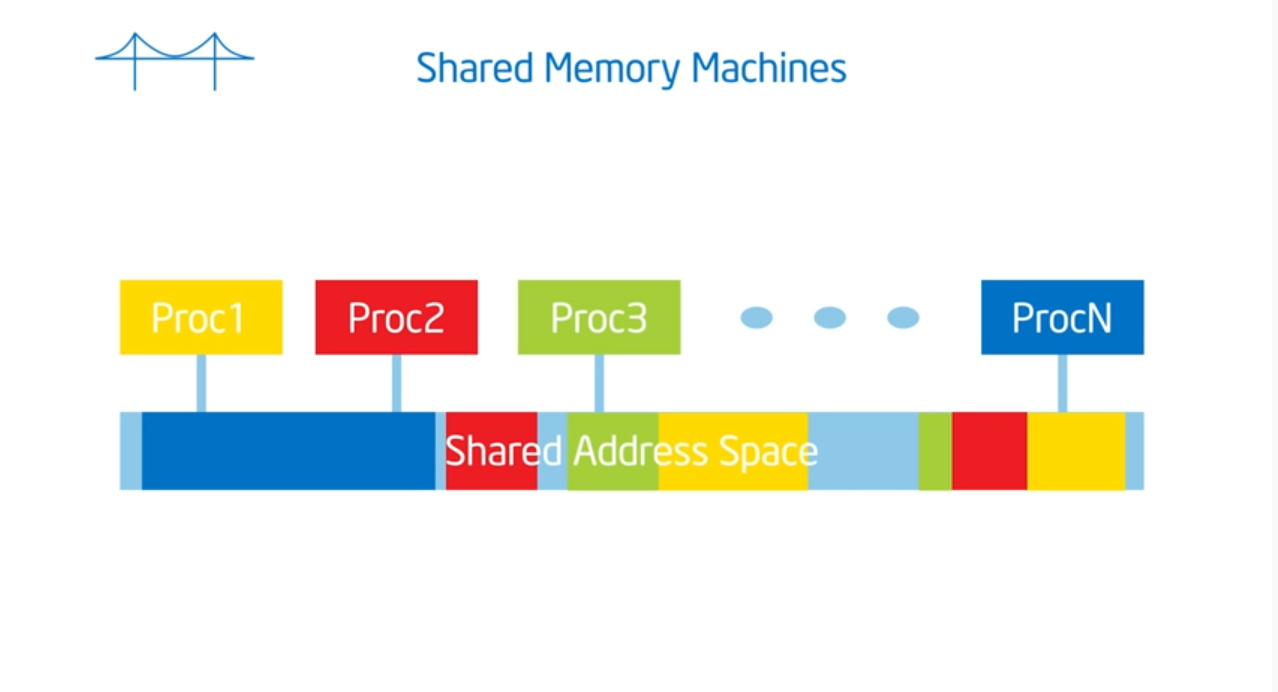
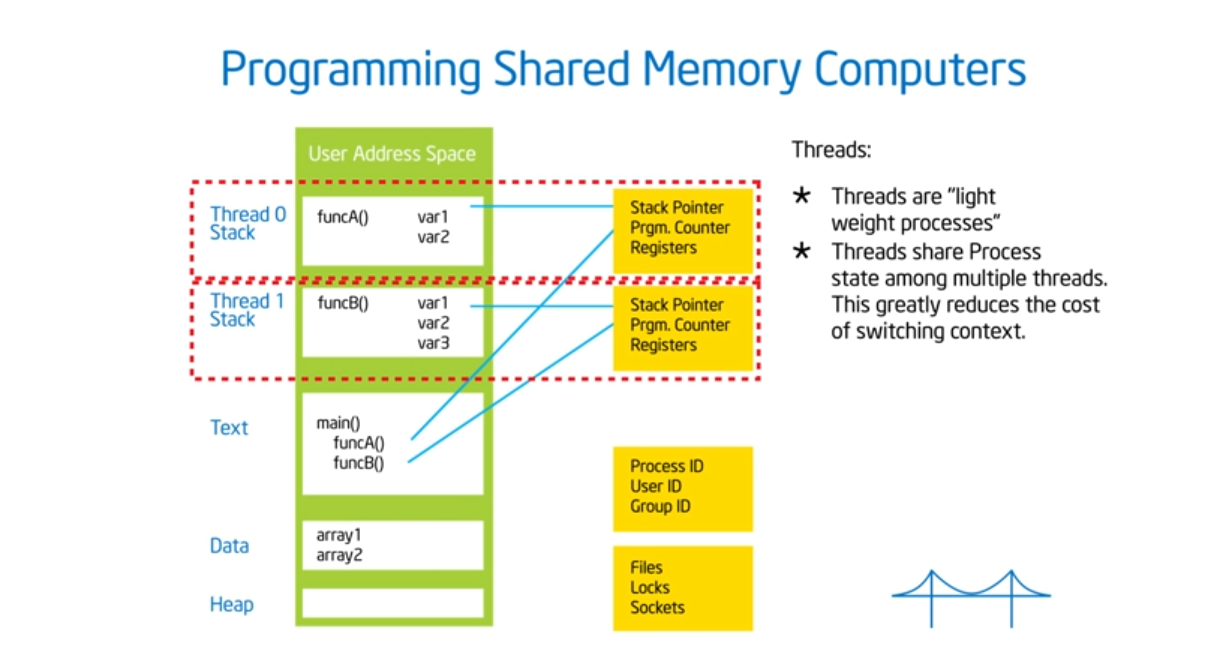
Shared address space
Summary
OpenMP assumes a shared memory address space architecture. The last true SMP (symmetric multi-processor) machine was in the late 1980s so most machines now run on NUMA (non uniformed multiple access) architectures. To exploit this architecture, we need to schedule our threads intelligently (which map to the same heap but contain different stacks) and place data in our cache’s as close as possible to their private caches. And, just like the professor said in advanced OS, we need to limit global data sharing and limit (as much as possible) the use of synchronization variables since they both slow down performance
How did society overcome the Spanish Flu and how did the people during that time return back to normal? I doubt some vaccination ended the pandemic… so how did we all get over it? And how will it be the same (or different) this time around with COVID-19 ?
Feelings
Excited to watch lectures on Distributed Systems a topic I’ve been interesting in for a very long time. Funny how I actually build distributed systems at work but don’t have my computer science foundation on the topic except I’ve done one off research on CAP theorem etc
Throughout the entire day I was just extremely fatigued from waking up due to screams that little Elliott let out throughout the night. I’m guessing she’s teething?
What did I learn
How to use pragma C preprocessor with OpenMP. Although at work we have some pragma definitions, I haven’t myself dove into why and how. I’m still confused as to the exact details of the pragma definitions but seems like (in this particular case) that by putting in pragma omp parallel, we are signaling the compiler to inject some code that will run once on each processor
Family and Friends Matter
Walked the dogs at Northacres park with little Elliott and Jess. Elliott looked super cute with the neon orange beanie that her mom bought her on Amazon
Graduate School
Glad I took the exam the day before yesterday (instead of yesterday, when the window to take the exam closes) since I was completely drained of energy yesterday. Honestly, if I had taken the exam last night, I’m pretty confident I would’ve bombed it
Watched a couple lecture videos on Distributed Systems and learned a couple new terms like event computation time and message computation time
Watched the first couple video tutorials on OpenMP, the YouTube learning series taught by Tim Mattson, one of the original and core developers of the library.
Administrative
Disassembled our wooden kitchen table using my Makita drill and the allen wrench adapter. I broke down the table so that it would fit inside the 3 yard waste bin that I rented from Seattle Public Utilities for the week. My hope is that we dump our unnecessary junk instead of packing them into boxes and hauling it to the new house
Scheduled a 20 ft. U-Haul truck for the move. I had to call into the help line because I want a one way drop-off (i.e. from Seattle to Renton) but their website doesn’t currently allow you to extend the number of days you are renting a truck. I also learned that U-Haul has very low inventory and they currently forbid renting trucks for more than one day (unless it’s a one way drop off)
Confirmed two appointments for the day: in person notary (due to COVID-19) for signing paperwork for the house and Wells Fargo appointment to transfer escrow money.
Work
Lots of back to back meetings yesterday and some unexpected ones (e.g. a 05:30 pm invite for a project that I’m leading)
Added some counters to my code to verify the behavior of my new feature that I’m developing
The purpose of this post is to take a snapshot of my understanding before I begin working on project 2: implementing (two) synchronization barriers. Although I picked up some theoretical knowledge from both this course (i.e. advanced operating systems) and GIOS (i.e. graduate introduction to operating systems) on barrier synchronization, I actually never implemented barriers so I’m very much looking forward to working on this project and bridging the gap between theory and practice.
What I do know
Conceptual understanding of the various types of barriers (e.g. centralized, tree based, MCS, tournament, dissemination)
Purpose of sense reversal (i.e. determine which barrier one is in)
Advantages of using an MCS barrier over a dissemination barrier when using a shared memory bus due to serialization and lack of parallel messages
What I don’t know
What OpenMP is and how it is different than MPI. Are the two the same or related somehow?
How the various barriers will perform based on the architecture (i.e. 8 way shared multi-processor system)
How to hook the barriers into some higher level user application? Will I be using the barriers for a producer/consumer type of application? Will I need to write that application or just the barrier itself?
What primitives will be available? Will I need to leverage some hardware atomic operations (my guess is yes)
Walked the dogs at Magnuson Park. Elliott and Jess joined too since Elliott has been waking up so early these days (around 05:45 AM). Trying to get the dogs to capitalize on these amazing off leash parks in North Seattle, before we move to Renton (in just a few days)
Cancelled war room meeting so that I could instead so I could have a pizza party with my next door neighbors and their two children. My neighbor’s daughter in particular was really looking forward to having a picnic party since there’s only a few days left until my wife and I and the rest of our entire pack move to Renton. Upon reflection, cancelling the war room was the right decision since I’ll remember this pizza party for years to come.
Took Elliott to Maple Leaf Park for about 20 minutes. She loves loves loves sitting on the kitty bridge and watching other kids play. Seriously. She’ll sit there and just smile at them, completely happy to just be outside. I never thought I would enjoy being a father so much. Honestly, I would’ve thought that taking my kids to the park would be boring and feel like an obligation but it’s just the opposite.
During dinner Elliott sat in her own little chair like a little adult for the first time, following Avery’s lead
Took Elliott with me to The Grateful Bread to pick up challah for Jess while she received in home physical therapy. After buying a couple loafs, Elliott and I sat outside of the cafe, her on my lap while I was wearing a mask (again, still in the midst of the COVID-19 pandemic). Felt nice just to sit outside and tear up little pieces of Challah for her to eat
Graduate School
Crammed heavily for the mid term exam (below). Took the exam last night instead of today (which is a good call since I’m absolutely shattered today, my sleep interrupted several times because I was still able to hear Elliott let out war like screams throughout the night … I think she’s teething)
Took the remotely proctored exam for advanced operating systems (AOS). I really think that studying with the Anki software for about an hour paid off. Otherwise, I don’t think I would’ve been able to answer questions around Exokernel and questions around the hypercalls.
Music
Had another wonderful guitar lesson yesterday with Jared. We focused on going over new inversions that should spice up some of my song writing since I feel like I’m in a rut these days, all my songs sorted of sounding the same since I’m playing them in the same voicings. But I should take a moment and step back and appreciate that I can even write songs and can even apply music theory that I picked up over the last couple years
Jared and I got to talking about marketing and he mentioned an author called Seth Godin and how (without realizing it) I’m sort of applying the techniques from his book. In any case, I should check out that author’s book (just no time right now).
Miscellaneous
Packed up my wide monitors and mechanical keyboard that were previously laid out desk office. Just a couple more days until we are out of this house in Seattle and moving to Renton
This past week, I skipped writing my daily reviews for two days in a row because I was really pressed for time. On the days that I skipped, I immediately started studying for the midterm exam as soon as I woke up. Looking back, I regret not writing anything down. Because I’ve already forgotten the events from those days, the memories lost.
In the future, when I’m under the gun I think I should still do my daily reviews going even if that means typing out only 5 bullet points. To that end, I’m going to limit the time for my daily reviews and return to time bounding the activity to 15 minutes. I’m hoping that setting an upper bound on those reviews will encourage me to rapidly write something (or anything) down, which is much better than writing nothing down.
Looking back at last week
Writing
Published 4 daily reviews (missing Friday and Saturday reflections)
Introduced a “what did I learn” section in my reviews (super helpful to capture the knowledge I acquired, even if they are in small doses)
Graduate School
Launched an online study group (i.e. war room) so us students could collaborate over video in preparation for the upcoming midterm. Overall, the war rooms were super beneficial (and fun as well), not only for me but for others. Lots of discussions happened. Made me re-realize that although writing does help solidify my understanding of a subject so does speaking about the topic. Also, hearing people’s others questions and answers help me understand the material more deeply.
Things I learned
To build high performance parallel systems we want to limit sharing global data structures. By reducing sharing, we limit locking, an expensive operation.
Heavy use of typedef keyword with enums creates cleaner C code
Learned that hierarchical locking (or locking in general) hinders system performance, preventing concurrency. What should we do instead? Reference counting for existence guarantee.
Writing a simple line parser in C one has to protect against so many edge cases
Most of the C string functions return pointers (e.g. strnstr for locating substring)
Learned how you can ensure that you are not statically creating a large data structure by using the -w-larger-than=byte_size compiler option
Able to visualize what an IPv6 data structure looks like underneath the hood: 16 char bytes. Also these are big endian, the least significant bit starting first.
Writing a simple line parser in C one has to protect against so many edge cases
Most of the C string functions return pointers (e.g. strnstr for locating substring)
Learned how you can ensure that you are not statically creating a large data structure by using the -w-larger-than=byte_size compiler option
Able to visualize what an IPv6 data structure looks like underneath the hood: 16 char bytes. Also these are big endian, the least significant bit starting first.
I spent a few minutes fiddling with my Anki settings yesterday, modifying the options for the advanced operating systems deck that I had created to help me prepare for the midterm. Although Anki’s default settings are great for committing knowledge and facts over a long period of time (thanks to its internal algorithm exploiting the forgetting curve), it’s also pretty good for cramming.
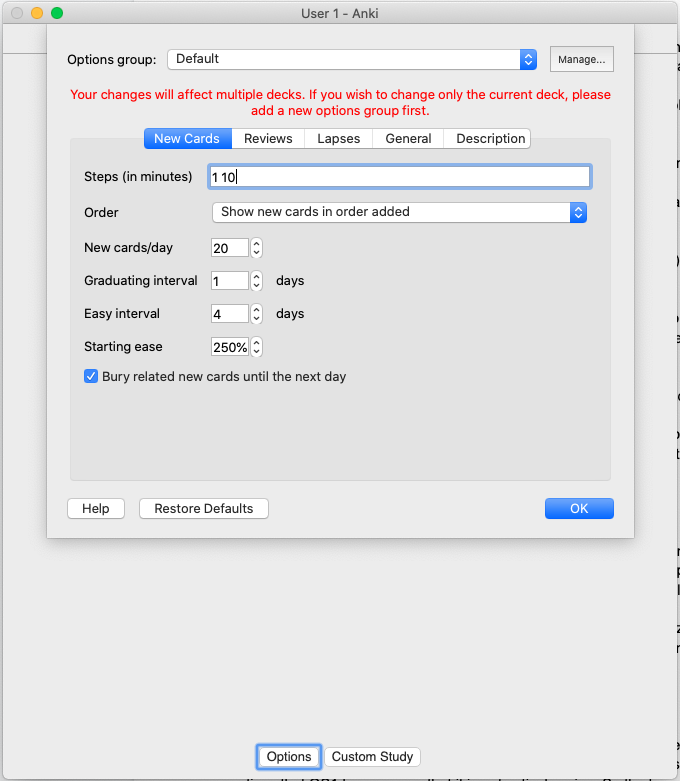
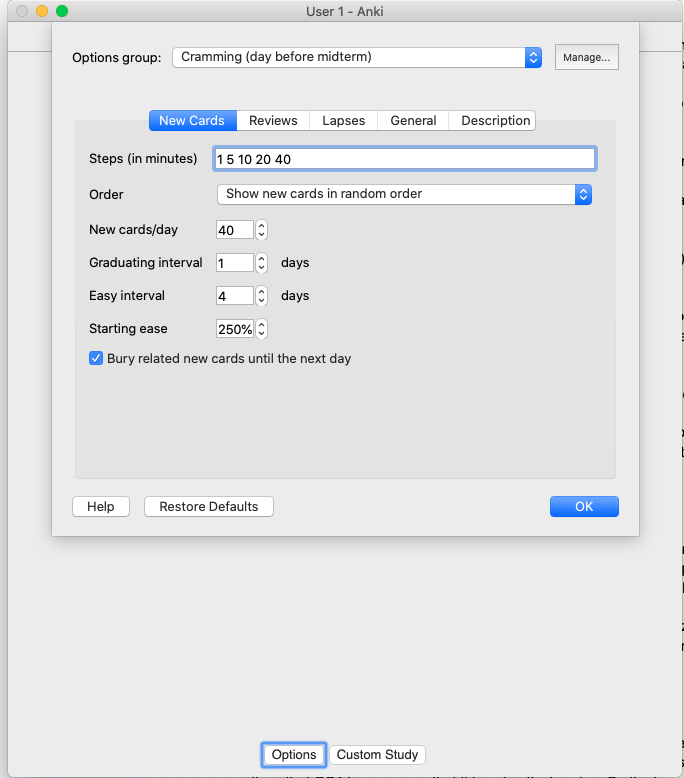
Although I don’t fully understand all the settings, here’s what I ended up tweaking some of the settings to. The top picture shows the default settings and the picture below it shows what I set them to (only for this particular deck).
I modified the order so that cards get displayed randomly (versus the default setting that presents the cards in the order that they were created), bumped up the number of cards per day to 35 (the total number of questions asked for the exam), and added additional steps so that the cards would recur more frequently before the system places the card in the review pile.
Because I don’t quite understand the easy interval and starting ease, I left those settings alone however I hope to understand them before the final exam so I can optimize the deck settings even more for the future final exam.
We’ll see how effective these settings were since I’ll report back once the grades get released for the exam, which I estimate will take about 2-3 weeks.
Default Anki Settings
Anki settings for advanced operating systems cramming
There are many challenges that the OS faces when building for parallel machines: size bloat (features OS just has to run), memory latency (1000:1 ratio) and numa effects (one process accessing another process’s memory across the network), false sharing (although I’m not entirely sure whether false sharing is a net positive, net negative, or just natural)
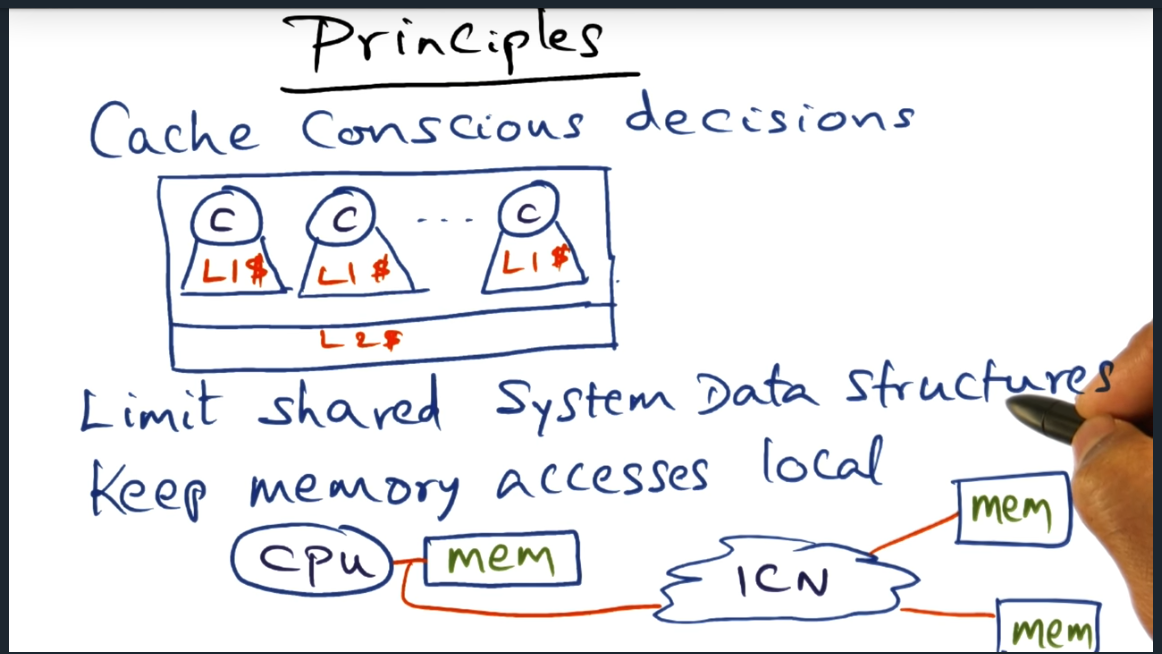
Principles
Summary
Two principles to keep in mind while designing operating systems for parallel systems. First it to make sure that we are making cache conscious decisions (i.e. pay attention to locality, exploit affinity during scheduling, reduce amount of sharing). Second, keep memory accesses local.
Refresher on Page Fault Service
Summary
Look up TLB. If no miss, great. But if there’s a miss and page not in memory, then OS must go to disk and retrieve the page, update the page table entry. This is all fine and dandy but the complication lies in the center part of the photo since accessing the file system and updating the page frame might need to be done serially since that’s a shared resource between threads. So … what we can do instead?
Parallel OS + Page Fault Service
Summary
There are two scenarios for parallel OS, one easy scenario and one hard. The easy scenario is multi-process (not multi-threaded) since threads are independent and page tables are distinct, requiring zero serialization. The second scenario is difficult because threads share the same virtual address space and have the same page table, shared data in the TLB. So how can we structure our data structures so that threads running on one process are not shared with other threads running on another physical processor?
Recipe for Scalable Structure in Parallel OS
Summary
Difficult dilemma for operating system designer. As designers, we want to ensure concurrency by minimizing sharing of data structures and when we need to share, we want to replicate or partition data to 1) avoid locking 2) increase concurrency
Tornado’s Secret Sauce
Summary
The OS creates a clustered object and the caller (i.e. developer) decides degree of clustering (e.g. singleton, one per core, one per physical CPU). The clustering (i.e. splitting of object into multiple representations underneath the hood) falls on to the responsibility of the OS itself, the OS bypassing the hardware cache coherence.
Traditional Structure
Summary
For virtual memory, we have shared/centralized data structures — but how do we avoid them?
Objectization of Memory
Summary
We break the centralized PCB (i.e. process control block) into regions, each region backed by a file cache manager. When thread needs to access address space, must access specific region.
Objectize Structure of VM Manager
Summary
Holy hell — what a long lecture video (10 minutes). Basically, we walk through workflow of a page fault in a objected structure. Here’s what happens. Page fault occurs with a miss. Process inspects virtual address and knows which region to consult with. Each region, backed by its file cache manager, will talk to the COR (cache object representation) which will perform translation of page, the page eventually fetched from DRAM. Different parts of system will have different representation. The process is shared and can be a singleton (same with COR), but region will be partitioned, same with FCM.
Advantages of Clustered Object
Summary
A single object make underneath the hood have multiple representations. This same object references enables less locking of data structures, opening up opportunities for scaling services like page fault handling
Implementation of Clustered Object
Summary
Tornado incrementally optimizes system. To this end, tornado creates a translation table that maps object references (a common object) to the processor specific representation. But if obj reference does not reside in t translation table, then OS must refer to the miss handling table. Since this miss handling table is partitioned and not global, we also need a global translation table that handles global misses and has knowledge of location of partition data.
Non Hierarchical Locking
Summary
Hierarchical locking kills concurrency (imagine two threads sharing process object). What can we do instead? How about referencing counting (so cool to see code from work bridge the theoretically and practical gap), eliminating need for hierarchical locking. With a reference count, we achieve existence guarantee!
Non Hierarchical Locking + Existence Guarantee (continued)
Summary
The reference count (i.e. existence guarantee) provides same facility of hierarchical locking but promote concurrency
Dynamic Memory Allocation
Summary
We need dynamic memory allocation to be scalable. So how about breaking the heap up into segments and threads requesting additional memory can do so from specific partition. This helps avoid false sharing (so this answers my question I had a few days ago: false sharing on NUMA nodes is a bad thing, well bad for performance)
IPC
Summary
With objects at the center of the system, we need an efficient IPC (inter process communication) to avoid context switches. Also, should point out that objects that are replicated must be kept consistent (during writes) by the software (i.e. the operating system) since hardware can only manage coherence at the physical memory level. One more thing, the professor mentioned LRPC but I don’t remember studying this topic at all and don’t recall how we can avoid a context switch if two threads calling one another are living on the same physical CPU.
Tornado Summary
Summary
Key points is that we use an object oriented design to promote scalability and utilize reference counting for implementing a non hierarchical locking, promoting concurrency. Moreover, OS should optimize the common case (like page fault handling service or dynamic memory allocation)
Summary of Ideas in Corey System
Summary
Similar to Tornado, but 3 take aways: address ranges provided directly to application, file descriptor can be private (and note shared), dedicated cores for kernel activity (helps locality).
Virtualization to the Rescue
Summary
Cellular disco is a VMM that runs as a very thin layer, intercepting requests (like I/O) and rewriting them, providing very low overhead and showing by construction the feasibility of a thin virtual machine management.
The algorithm is implemented on a cache coherent architecture with an invalidation-based shared-memory bus.
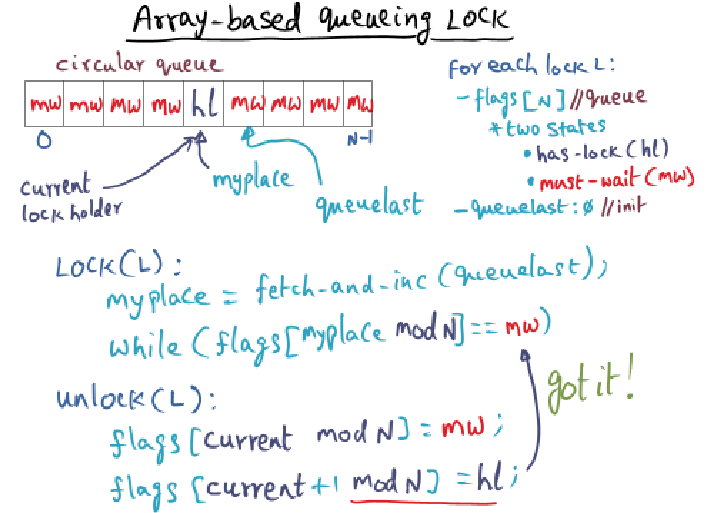
The circular queue is implemented as an array of consecutive bytes in memory such that each waiting thread has a distinct memory location to spin on. Let’s assume there are N threads (each running on distinct processors) waiting behind the current lock holder.
If I have N threads, and each one waits its turn to grab the lock once (for a total of N lock operations), I may see far more than N messages on the shared memory bus. Why is that?
My Guess
Wow .. I’m not entirely sure why you would see far more than N messages because I had thought each thread spins on its own private variable. And when the current lock holder bumps the subsequent array’s flag to has lock … wait. Okay, mid typing I think I get it. Even though each thread spins on its own variable, the bus will update all the other processor’s private cache, regardless of whether they are spinning on that variable.
Solution
This is due to false-sharing.
The cache-line is the unit of coherence maintenance and may contain
multiple contiguous bytes.
Each thread spin-waits for its flag (which is cached) to be set to hl.
In a cache-coherent architecture, any write performed on a shared
memory location invalidates the cache-line that contains the location
in peer caches.
All the threads that have their distinct spin locations in that same
cache line will receive cache invalidations.
This cascades into those threads having to refresh their caches by
contending on the shared memory bus.
Reflection
Right: the array belongs in the same cache line and the cache line may contain multiple contiguous bytes. We just talked about all of this during the last war room session.
Question 3e
Give the rationale for choosing to use a spinlock algorithm as opposed to blocking (i.e., de-scheduling) a thread that fails to get a lock.
My Guess
Reduced complexity for a spin lock algorithm
May be simpler to deal with when there’s no cache coherence offered by the hardware itself
Solution
Critical sections (governed by a lock) are small for well-structured parallel programs. Thus, cost of spinning on the lock is expected to be far lesser than the cost of context switching if the thread is de- scheduled.
Reflection
Key take away here is a reduced critical section and cheaper than a context switch
Question 3f
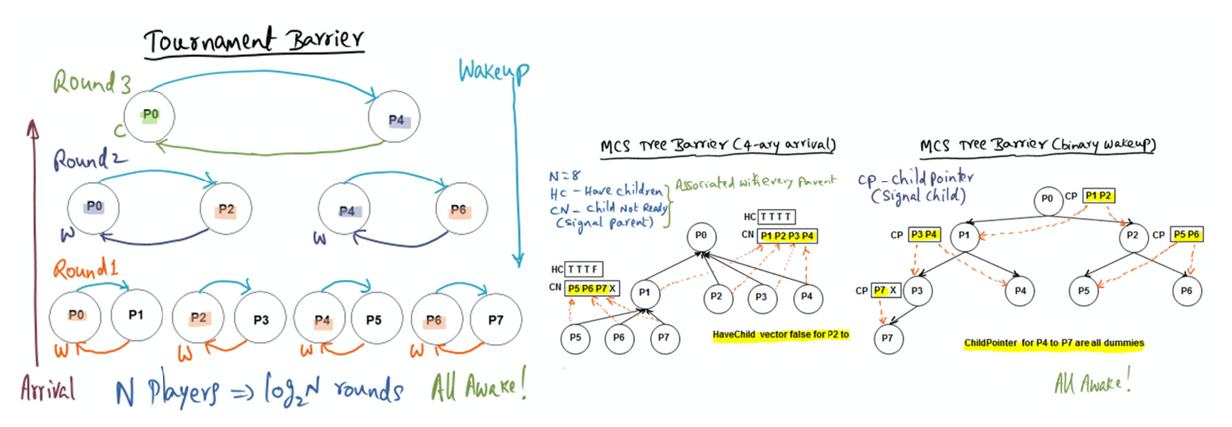
Tournament Barrier vs MCS Tree Barrier
(Answer True/False with justification)(No credit without justification)
In a large-scale CC-NUMA machine, which has a rich inter-connection network (as opposed to a single shared bus as in an SMP), MCS barrier is expected to perform better than tournament barrier.
Guess
The answer is not obvious to me. What does having a CC (cache coherence) numa machine — with a rich interconnection network instead of a single shared bus — offer that would make us choose an MCS barrier over a tournament barrier …
The fact that there’s not a single shared bus makes me think that this becomes less of a bottle neck for cache invalidation (or cache update).
Solution
False. Tournament barrier can exploit the multiple paths available in the interconnect for parallel communication among the pair-wise contestants in each round. On the other hand, MCS due to its structure requires the children to communicate to the designated parent which may end up sequentializing the communication and not exploiting the available hardware parallelism in the interconnect.
Reflection
Sounds line the strict 1:N relationship between the parent and the children may cause a bottle neck (i.e. sequential communication).
3g Question
In a centralized counting barrier, the global variable “sense” informs a processor which barrier (0 or 1) it is currently in. For the tournament and dissemination barriers, how does a processor know which barrier (0 or 1) it is in?
Guess
I thought that regardless of which barrier (including tournament and dissemination), they all require sense reversal. But maybe …. not?
Maybe they don’t require a sense since the threads cannot proceed until they reach convergence. In the case of tournament, they are in the same barrier until the “winner” percolates and the signal to wake up trickles down. Same concept applies for dissemination.
Solution
Both these algorithms do not rely on globally shared data structures. Each processor knows “locally” when it is done with a barrier and is in the next phase of the computation. Thus, each processor can locally flip its sense flag, and use this local information in its communication with the other processors.
Reflection
Key take away here is that neither tournament nor sense barrier share global data structures. Therefore, each processor can flip its own sense flag.
3h
Tornado uses the concept of a “clustered” object which has the nice property that the object reference is the same regardless of where the reference originates. But a given object reference may get de-referenced to a specific representation of that object. Answer the following questions with respect to the concept of a clustered object.
The choice of representation for the clustered object is dictated by the application running on top of Tornado.
Guess
No. The choice of representation is determined by the operating system. So unless the OS itself is considered an application, I would disagree.
Solution
The applications see only the standard Unix interface. Clustered object is an implementation vehicle for Tornado for efficient implementation of system
services to increase concurrency and avoid serial bottlenecks. Thus choice of representation for a given clustered object is an implementation/optimization choice internal to Tornado for which the application program has no visibility.
Reflection
Key point here is that the applications see a standard Uni interface. And that the clustered object is an implementation detail for Tornado to 1) increase concurrency and 2) avoid serial bottlenecks (that’s why there are regions and file memory caches and so on).
Question 3h
Corey has the concept of “shares” that an application thread can use to give a “hint” to the kernel its intent to share or not share some resource it has been allocated by the kernel. How is this “hint” used by the kernel
Guess
The hint is used by the kernel to co-locate threads on the same process or in the case of “not sharing” ensure that there’s no shared memory data structure.
Answer
In a multicore processor, threads of the same application could be executing on different cores of the processor. If a resource allocated by the kernel to a particular thread (e.g., a file descriptor or a network handle) is NOT SHARED by that thread with other threads, it gives an opportunity for the kernel to optimize the representation of the associated kernel data structure in such a way as to avoid hardware coherence maintenance traffic among the cores.
Reflection
Similar theme to all the other questions: need to be very specific. Mainly, “allow kernel to optimize representation of data structure to avoid hardware coherence maintenance traffic among the cores.
Question 3j
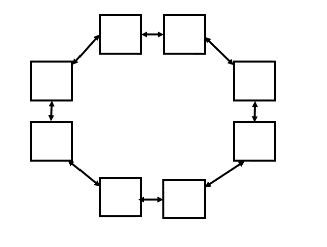
Imagine you have a shared-memory NUMA architecture with 8 cores whose caches are structured in a ring (as shown below). Each core’s cache can only communicate directly with the one next to it (communication with far cores has to propagate among all the caches between the cores). Overhead to contact a far memory is high (proportional to the distance in number of hops from the far memory) relative to computation that accesses only its local NUMA piece of the memory.
Rich architecture of shared-memory NUMA architecture
Would you expect the Tournament or Dissemination barrier to have the shortest worst-case latency in this scenario? Justify your answer. (assume nodes are laid out optimally to minimize communication commensurate with the two algorithms). Here we define latency as the time between when the last node enters the barrier, and the last node leaves the barrier.
Guess
In a dissemenation barrier, the algorithm is to hear back from (i+2^k) mod n. As a result, each process needs to talk to another distant processor.
Now what about Tournament barrier, where the rounds are pre determined?
I think with tournament barrier, we can fix the rounds such that the processors speak to its closest node?
Solution
Dissemination barrier would have the shortest worst-case latency in this scenario.
In the Tournament barrier, there are three rounds and since the caches can communicate with only the adjacent nodes directly, the latency differs in each round as follows:
First round: Tournament happens between adjacent nodes and as that can happen parallelly, the latency is 1.
Second round: Tournament happens between 2 pairs of nodes won from previous round which are at a distance 2 from their oppoent node. So, the latency is 2 (parallel execution between the 2 pairs).
Third round: Tournament happens between last pair of nodes which are at distance 4 from each other, making the latency 4.
The latency is therefore 7 for arrival. Similar communication happens while the nodes are woken up and the latency is 7 again. Hence, the latency caused by the tournament barrier after the last node arrives at the barrier is 7+7 = 14.
In the dissemination barrier, there are 3 rounds as well.
First round: Every node communicates with its adjacent node
(parallelly) and the latency is 1. (Here, the last node communicates
with the first node which are also connected directly).
Second round: Every node communicates with the node at a distance 2
from itself and the latency is 2.
Third round: Every node communicates with the node at a distance 4
from itself and the latency is 4. The latency is therefore 7.
Hence, we can see that dissemination barrier has shorter latency than the tournament barrier. Though the dissemination barrier involves a greater number of communication than the tournament barrier, since all the communication at each round can be done in parallel, the latency is lesser for it.
Reflection
Right, I forgot completely that with a tournament barrier, there needs to be back propagation to signal the wake up as well, unlike the dissementation barrier, which converges hearing from ceil(log2n) neighbors due to its parallel nature.
Held Elliott in my arms while we danced to her favorite song (above) titled called Breathing by Hamzaa. As soon as this song plays on our bluetooth sound bar speaker, Elliott immediately tosses her arms up in the air (even if her hands are full of food) and starts rocking back and forth. I hope she never loses the confidence to dance so freely like us adults.
What I am grateful for
A wife who I’ve learned to develop so much trust with over the years and one of the very few people that I can open up to completely and share thoughts that cycle through my head.
What I learned
Writing a simple line parser in C one has to protect against so many edge cases
Most of the C string functions return pointers (e.g. strnstr for locating substring)
Learned how you can ensure that you are not statically creating a large data structure by using the -w-larger-than=byte_size compiler option
Able to visualize what an IPv6 data structure looks like underneath the hood: 16 char bytes. Also these are big endian, the least significant bit starting first.
Work
Wrote some code that performed some string parsing (so many dang edge cases)