ENOTSUP stands for “Error – not supported” and it is one of the many error codes defined in the error header file.
I recently learned about this specific error code when reviewing a pull request that my colleague had submitted. His code review contained an outline — a skeleton — of how we envisioned laying out a new control plane process that would allow upcoming dataplane processes to integrate with.
And he kept this initial revision very concise, only defining the signature of the functions and simply returning the error code ENOTSUP.
The advice of returning relevant error codes applies not only to the C programming language, but applies to other languages too, like Python. But instead of error codes, you should instead raise specific Exceptions.
Who cares
So what’s so special about a one liner that returns this specific error code?
Well, he could’ve instead added a comment and simply returned negative one (i.e. -1). That approach would’ve done the job just fine. But what I like about him returning a specific error code is that doing so conveys intent. It breathes meaning into the code. With that one liner, the reader (me and other developers on the team) immediately get a sense that that code will be replaced and filled in in future revisions.
Example
Say you are building a map reduce framework and in your design, you are going to spawn a thread for each of phases (e.g. map, reduce). And let’s also say you are working on this project with a partner, who is responsible for implementing the map part of the system. Leaving them a breadcrumb would be helpful:
int worker_thread_do_map(uint32_t thread_id)
{
/* implement feature here and return valid error code */
return -ENOTSUP;
}
int worker_thread_do_reduce(uint32_t thread_id)
{
return -ENOTSUP;
}
The take away
The take away here is that we, as developers, should try and convey meaning and intent for the reader, the human sitting behind the computer. Cause we’re not just writing for our compiler and computer. We’re writing for our fellow craftsman.
In my mid twenties, I was blessed to receive some of the best career, and quite frankly, life advice. During that period of my life, I was working as a director of technology, leading a small group of engineers. But I was getting ready to throw in the towel. I lacked both the experience and confidence needed. So I reached out to my friend Brian, asking him if he knew anyone who could help me with “executive coaching”. Thankfully, Brian connected me with a C level executive: let’s call him Phil (that’s actually his name).
Prod, provoke, encourage
When I met Phil at the Jerry’s Deli located in the valley, one of the first things he flat out told me was that executive coaching is bullshit. Despite that belief, he essentially coached me and gave me some sage advice that now I get to pass on.
Seth Godin once stated that “About six times in my life, I have met somebody, who, in the moment, prodded me, provoked me, encouraged me, and something came out on the other side”.
Phil is one of those 6 people in my life.
The best career and life advice
The sage advice is simple and sounds similar to Nic Haralambous’s advice “Plan in decades. Think in years. Work in months. Live in days”. But Phil’s advice offers a different perspective, another angle:
20s for education. 30s for experience. 40s for career
This advice stuck with me and helps me (re) calibrate my goals and values. Of course, life takes its own twists and turns. But as the Dwight Eisenhower said “Plans are worthless, but planning is everything”
What does that look like in practice?
20s for education is NOT synonymous with school. It really means soaking up as much as possible. This learning might take place in school but not exclusively. Because learning can happen anywhere and everywhere.
Fail and fail a lot.
For us tech folks, this might be learning a new programming language, dissecting the ins and outs of your compiler, picking up marketing or public speaking skills.
The list goes on and on.
30s for experience. This is where the rubber meets the road. Where theory and practice intersect. This may mean you want to switch roles (like how I switched from being a systems engineer to a software developer) or switch companies so that you can apply all that hard earned knowledge that you acquired in your twenties.
Finally, 30s will feed into your 40s, where you get to establish your career. Maybe working for a small company, where you get to wear a bunch of hats. Maybe for a large corporation, where you hone in or specialize in a particular niche. Or maybe as an entrepreneur, building your own product or service.
Now what?
I’m actually revisiting these words of wisdom. Right now. For the last six months or so, I’ve been overly focused on an upcoming promotion from a mid to senior level engineer at Amazon. Instead of chasing this new title — cause that’s all it really is — I’d rather redirect my focus and make mistakes, stretch myself and find opportunities that put me in a uncomfortable (but growth inducing) experiences.
As a software developer, you will sooner or later lead a software development project. Of course it would be nice and ideal to relegate the responsibility of project management to a dedicated project manager — but not all of us are afforded that luxury. And let’s face it: many of us rather be heads down designing the software or writing the actual code. That being said, if you find yourself in a situation in which you need to manage a project, here are a few tips.
Write down notes during every meeting and send them out
During every meeting (related to the project), take down notes. Capture who said what, what did they promise, and when will they deliver that promise. I personally find this difficult because I don’t want to feel like I’m micromanaging or stepping on people’s toes. But really, we’re just communicating and the lack of communication a major contributor to failed project.
Another reason why I think sending an e-mail once the meeting ends is that keeps others (and ourselves) accountable, partiallyu due to the Hawthorn Effect, which suggests that some people work harder and perform better when they are participants in an experiment (Source: verywellmind).
Create a work plan and share your estimates with others
I hate estimating my tasks. Because more often than not, my estimates are off — sometimes by a little, sometimes by a lot — due to hidden assumptions. That being said, there are ways to improve the accuracy of your estimates.
As humans, we tend to be overly optimistic, assuming that everything will go according to plan. But I recommend a different approach. Be a pessimist.Assume everything will go wrong. Then, after playing devil’s advocate, find the middle (realistic) ground. And if want to take it even further, acknowledge your estimation biases and use formal techniques for mitigating those biases.
Stop searching for the the perfect project management tool
Although I wholeheartedly agree that having the right tool for the right job is important, I’ve reached the conclusion based off of my own personal experiences that when I’m constantly hunting for the perfect project management software (e.g. Microsoft Office Project, OmniPlanner) I’m really just procrastinating.
So, start off simple. Just do a brain dump. Write every task down — lay it all out. Type all the tasks in Microsoft Word or Notepad if you have to. But get it out of your brain. Then, for each task, include the name of the task, a one to two sentence description, an estimate in days, the risks (i.e. low, medium, high), and the dependencies for that task. No need to go overboard and write down an entire novel. Again — strike a balance.
In 2019, Sal Khan wrote a letter to his past self as a reflection exercise and made that letter public and published it on his blog. Thanks Sal.
Inspired by his post and this reflection exercise, I decided to write a letter from my future self (Matt in 2029). In other words, I wrote the letter from future Matt (2029) to present Matt (2019). Of course, I wrote this letter before the global pandemic, before my first daughter born. So much has changed since a year ago. That being said, the exercise is super valuable and allows me to gauge whether I am walking the course that I had once charted.
And I think you should also do the same reflection exercise. Set aside about an hour. Just lay it all out. Then, set the letter aside and revisit it six months from now, a year from now, five years from now. You’ll be surprised how accurate (and inaccurate) your predictions are.
A letter to myself
Dear 2019 Matt,
You see that wife of yours? Go give her a big wet kiss on the lips. Then throw your arms around her, giving her a big bear hug. Hold it. Now tell her you love her — I’ll wait while you do it — because you really don’t tell her enough. Have no fear: she’s not going anywhere. And while you are at it, kiss Metric on the nose and pat Mushroom on the head. They’re both in doggy heaven now, smiling down on me, 2029 Future Matt.
Moving on, here are some suggestions.
First off, up your Vietnamese speaking skills (and your written skills while you are at it). Seriously. You are a Vietnamese American man. Vietnamese — the mother tongue of your two, refugee parents. Use the language to connect (and reconnect) with your loved ones, friends and family, especially your grandma. It’s important Matt — she’s no longer around. Don’t make the mistake of not being able to not only articulate and share your thoughts and feelings and your life story, but listen to her stories. How did she do it all — having kids at 19 and then fleeing Vietnam without a lick of English? Separately, don’t you want your children to speak the language as well?
Next up, get involved with the community. I understand you are naturally introverted and insular. But you aren’t alone: join a community of like minded people. People who care about the things you care about. Cannot find that community? Make one. Like your wife tells you — you are a community builder. You have this ability to attract and bring people together, make them feel comfortable under their own skin (since that’s something you’ve worked so hard on: learning to accept yourself).
Keep up the singing and guitar lessons. They’ve come in handy. No — future you is not a rock star and you are not touring across the globe. But you’ve breathed music into your children’s lives. They’re constantly yanking on your t-shirt, inviting you to sing and dance. And of course you do it because you not only love them to pieces but you want to teach them how to be comfortable under their own skin. That’s important to you because you know what it feels like not feel completely okay with who you are.
Keep plugging away at that Computer Science Master’s program from Georgia Tech. It’s serving a couple purposes. On one hand, you are doing it because you are mastering your craft, learning the ins and outs of your discipline. On the other hand, you know there’s shadow side to why you are doing it: you can feel a bit insecure at times (even though you don’t let it show) since you are in the big leagues, working at Amazon and being surrounded smart folks with their fancy degrees. But once you finish up that program, use that lunch time to actually have lunch with folks instead of studying.
Now, on the emotional side, keep walking that path of forgiveness. Remember that Oprah interview you watched, the interview with Wade and James, the two brave men speaking out about their sexual abuse from Michael Jackson? Remember what James Safechuck poignantly said: forgiveness is not a line you cross, but a path you take. With that quote in mind, learn not only how to forgive yourself for the things you’ve done and people you hurt but learn how to forgive others around you — like your father. Yes, he’s still around but he’s old now: 70. He doesn’t have that much time left on this earth. Basically, keep up with what you are doing: you no longer imagine what life could be if things were different. No. That’s not you anymore and future you is proud.
One more thing: reintroduce meditation to your life. Cause 2029 is crazier than you’d expect, even more so than now. You think Trump being the president is ludicrous ? Can you guess who is the president in 2029?
So far, I’ve been naming a bunch of things for you to do and for to think about. But also take it easy on yourself. Acknowledge how far you have come. You are piling so much on your plate: you are working full time as a software engineer at Amazon, playing husband 24 x 7, walking the dogs at 06:30 AM every morning (from your cozy 2 story Northgate house to Maple Leaf park) because the dogs deserve daily exercise to keep them healthy, taking singing lessons every Tuesday evening, mastering the fret board of your guitar, refining your writing skills.
I know your mind constantly races. You want to be a good husband (you are). You want to be a good son (you are). You want to be a good brother (you are). You want to be a good father (you will be).
While reading Advanced Operating Systems research paper, I found myself following the citations, flipping to the last page and scribbling down the referenced papers because I want to learn more about database systems. In particular, I’m interested in learning more about building reliable software that withstand unexpected failures by using transactions, the techniques and methods. On a separate note, I really do think that Georgia Tech’s OMSCS program should offer a more advanced database course since the introduction to database system seems to only cover high level concepts such as SQL queries and writing web applications, two areas that I’ve already been exposed to in the past.
Papers
Concurrent programming and building highly-concurrent transasctional objects: M. Herlihy and E. Koskinen. Transactional boosting: A methodology for highly-concurrent transactional objects. In PPoPP, 2008.
Creation of a transactional operating system called TxLinux: H. Ramadan, C. Rossbach, D. Porter, O. Hofmann,
A. Bhandari, and E. Witchel. MetaTM/TxLinux: Transactional memory for an operating system. In ISCA,
2007
One of the most cited books on database transactions (my guess is Gray is the father of database systems): J. Gray and A. Reuter. Transaction Processing: Concepts and Techniques. Morgan Kaufmann, 1993.
Introduces a new primitive called a transactional spinlock: C. Rossbach, O. Hofmann, D. Porter, H. Ramadan,
A. Bhandari, and E. Witchel. TxLinux: Using and managing
transactional memory in an operating system. In SOSP, 2007.
Concurrently writing to lists – M. Herlihy and E. Koskinen. Transactional boosting: A methodology for highly-concurrent transactional objects. In PPoPP, 2008.
Skip lists – W. Pugh. Skip lists: a probabilistic alternative to balanced trees. Communications of the ACM, 33:668–676, 1990.
Two phased commit protocols – J. Gray. Notes on data base operating systems. In Operating Systems, An Advanced Course. Springer-Verlag, 1978.
This post is a cliff notes version I scrapped together after reading the paper Operating Systems Transactions. Although I strongly recommend you read the paper if you are interested in how the authors pulled inspiration from database systems to create a transactional operating system, this post should give you a good high overview if you are short on time and need a quick and shallow understanding.
Abstract
System transactions enable application developers to update OS resources in an ACID (atomic, consistent, isolated, and durable) fashion.
TxOS is a variant of Linux that implements system transactions using new techniques, allowing fairness between system transactions and non-transaction activities
Introduction
The difficulty lies in making updates to multiple files (or shared data structures) at the same time. One example of this is updating user accounts, which requires making changes to the following files: /etc/passwd, /etc/shadow, /etc/group
One way for ensuring that a file is atomically updates is by using a “rename” operation, this system call replacing the contents of a file.
But for more complex updates, we’ll need to use something like flock for handling mutual exclusion. These advisory locks are just that: advisory. Meaning, someone can bypass these control, like an administrator, and just update the file directly.
Although one approach to fix these concurrency problems is by adding more and more system calls. But instead of taking this approach of constantly identifying and eliminating race conditions, why not percolate the responsibility up to the end user, by allowing system transactions?
These system transactions is what the paper proposes and this technique allows developers to group their transaction using system calls: sys_xbegin() and sysx_xend().
This paper focuses on a new approach to OS implementation and demonstrates the utility of system transactions by creating multiple prototypes.
Motivating Examples
Section covers two common application consistency problems: software upgrade and security
Both above examples and their race conditions can be solved by using ”’system transactions”’
Software installation or upgrade
Upgrading software is common but difficult
There are other approaches, each with their own drawbacks
One example is using a checkpoint based system. With checpoints, system can rollback. However, files not under the control of the checkpoint cannot be restored.
To work around the shortcomings of checkpoint, system transactions can be used to atomically roll forward or rollback the entire installation.
Eliminating races for security
Another type of attack is interleaving a symbolic link in between a user’s access and open system calls
By using transactions, the symbolic link is serialized (or ordered) either before or after and cannot see partial updates
The approach of adding transactions is more effective long term, instead of fixing race conditions as they pop up
Overview
System transactions make it easy on the developer to implement
Remainder of section describes the API and semantics
System Transactions
System transactions provide ACID (atomic, consistent, isolation, durability) semantics – but instead of at the database level, at the operating system level
Essentially, application programmer wraps their code in sys_xbegin() and sys_xend()
System transaction semantics
Similar to database semantics, system transactions are serializable and recoverable
Transactions are atomic and can be rolled back to a previous state
Transactions are durable (i.e. once transaction results are committed, they survive system crashes)
Kernel enforces the following invariant: only a single writer at a time (per object)
If there are multiple writers, system will detect this condition and abort one of the writers
Kernel enforces serialization
Durability is an option
Interaction of transactional and non-transactional threads
Serialization of transaction and non-transational updates is caclled strong isolation
Other implementations do not take a strong stance on the subject and are semantically murkey
By taking a strong stance, we can avoid unexpected behavior in the presence of non-transactional updates
System transaction progress
OS guarantees system transactions do not livelock with other system transactions
If two transactions are in progress, OS will select one of the transactions to commit, while restarting the other transaction
OS can enforce policies to limit abuse of transactions, similar to how OS can control access to memory, disk space, kernel threads etc
System transactions for system state
Key point: system transactions provide ACID semantics for system state but not for application state
When a system transaction aborts, OS will restore kernel data structures, but not touch or revert application state
Communication Model
Application programmer is responsible for not adding code that will communicate outside of a transaction. For example, by adding a request to a non-transactional thread, the application may deadlock
TxOS overview
TXOS Design
System transactions guarantee strong isolation
Interoperability and fairness
Whether or not a thread is a transactional or non transactional thread, it must check for conflicting annotation when accessing a kernel object
Often this check is done at the same time when a thread acquires a lock on the object
When there’s a conflict between a transaction and non-transactional thread, this is called asymmetric conflict. Instead of aborting the transaction, TxOS will suspend the non-transactional thread, promoting fairness between transactions and non-transactional threads.
Managing transactional state
Historically, databases and transactional OS will update data in place and maintain an undo log: this is known as eager version management
”Isn’t the undo log approach the approach the light recoverable virtual machine takes?”
In eager version management, systems hold lock until the commit is completed and is also known as two-phase locking
Deadlocking can happen and one typical strategy is to expose a timeout parameter to users
Too short of a timeout starves long transactions. Too long of a deadlock and can starve performance (this is a trade off, of course)
Unfortunately, eager version management can kill performance since the transaction must process its redo log and jeopardizes system’s overall performance
Therefore, TxOS uses lazy version management, operating on private copies of data structures
Main disadvantage of lazy versioning is the additional commit latency due to copying updates of the underlying data structures
Integration with transactional memory
Again, system transactions protect system state: not application state
Users can integrate iwth user level transaction memory systems if they want to protect application state
System calls are forbidden during user transactions since allowing so would violate transactional semantics
TxOS Kernel Implementation
Versioning data
TxOS applies a technique that’s borrowed from software transactional memory systems
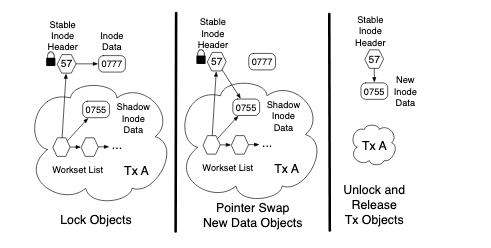
During a transaction, a private copy of the object is made: this is known as a the shadow object
The other object is known as “stable”
During the commit, shadow object replaces the stable
A naive approach would be to simply replace the stable pointer, since the object may be the target of pointers from several other objects
For efficient commit of lazy versioned data, need to break up data into header and data.
”Really fascinating technique…”
Maintain a header and the header pointers to the object’s data. That means, other objects always access data via the header, the header never replaced by a transaction
Transactional code always has speculative object
The header splits data into different payloads, allowing the data to be accessed disjointly
OS garbage collects via read-copy update
Although read only data avoids cost of duplicating data, doing so complicates the programming model slightly
Ultimately, RCU is a technique that supports efficient, concurrent access to read-mostly data.
Conflict detection and resolution
TxOS provides transactions for 150 of 303 system calls in Linux
Providing transactions for these subset system calls requires an additional 3,300 lines of code – just for transaction management alone
A conflict occurs when transaction is about to write to an object but that object has been written by another transaction
Header information is used to determine the reader count (necessary for garbage collection)
A non-null writer pointer indicates an active transactional writer. Similarly, an empty reader lists means there are no readers
All conflicts are arbitrated by the contention manager
During a conflict, the contention manager arbitrates by using an osprio policy: the process with the higher scheduling process wins. But if both processes have the same priority, then the older one wins: this policy is known as timestamp.
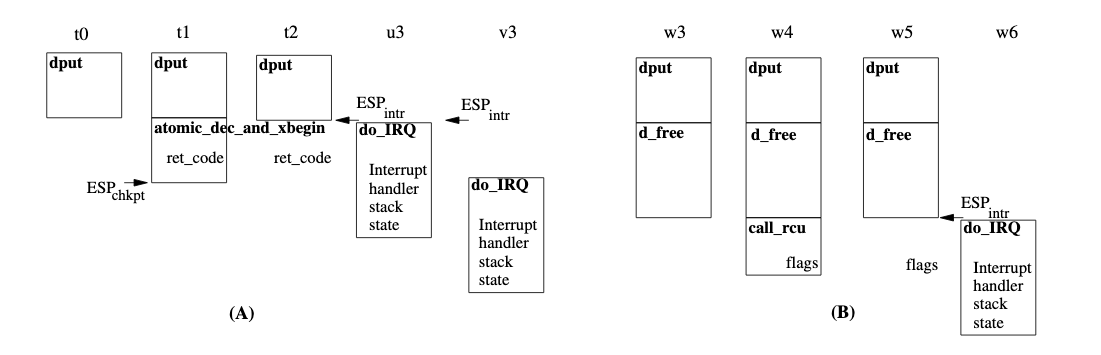
Asymmetric conflicts
non-transactional threads cannot be rolled back, although transactional threads can always be rolled back. That being said, there must be mechanism to resolve the conflict in favor of the transactional thread otherwise that policy always favor the non-transactional thread
non-transactional threads cannot be rolled back but they can be preemted, a recent feature of Linux
Minimizing conflicts on lists
Kernel relies heavily on linked lists data structures
Managing transaction state
TxOS adds transaction objects to the kernel
Inside of transaction struct, the status (probably an alias to uint8_t) is updated atomically with a compare and swap operation
If transaction system call cannot complete because of conflict, it must abort
Roll back is possible by saving register state on the stack at the beginning of the system call, in the “checkpointed_registers” field
During abort, restore register state and call longjmp
Certain operations must not be done until commit; these operations are stored in deferred_ops. Similarly, some operations must be done during abort, and these operations are stored in undo_ops field.
Workset_list is a skip list that contains references to all objects in the transaction and the transaction’s private copies
Commit protocol
When sys_xend (i.e. transaction ends), transaction acquires lock for all items in (above mentioned) workset.
Once all locks are acquired, transaction performs one final check in its status word and verifies that the status has been set to abort.
Abort protocol
Abort must happen when transaction detects that it lost a conflict
Transaction must decrement the reference count and free the shadow objects
User level transactions
Can only support user-level transactions by coordinating commit of application state with system transaction’s commit
Lock-based STM requirements
Used a simplified variant of two-phase commit protocol
Essentially, user uses sys_xend() system call and must inspect the return code so that the user application can then decide what to do based off of the system call’s transaction
TxOS Kernel Subsystems
Remainder will discuss ACID semantics
Example will include ext3 file system
Transactional file system
Managed versioned data in the virtual filesystem layer
File system only needs to provide atomic updates to stable storage (i.e. via a journal)
By guaranteeing writes are done in a single journal transaction, ext3 is now transactional
Multi-process transactions
Forked children execute until sys_xend() or the process exits
Signal delivery
Application can decide whether to defer a signal until a later point
If deferred, signals are placed into queue
Future work
TxOS does not provide transactional semantics for all OS resources
If attempting to use transaction on unsupported resource, transaction will be aborted
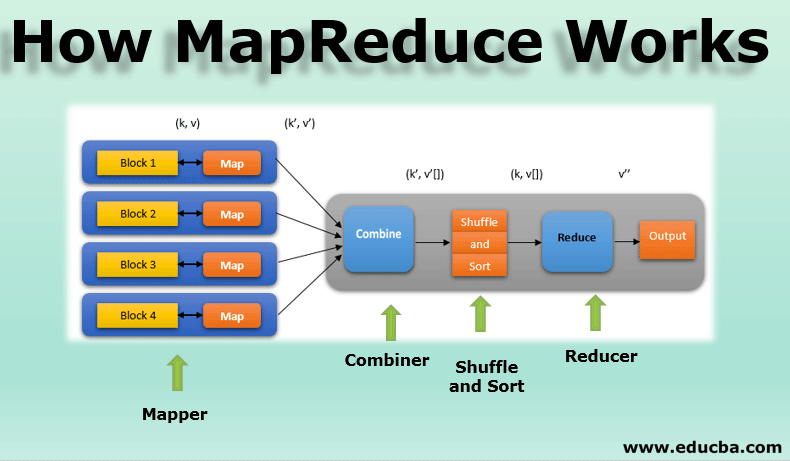
Like my previous posts on snapshotting my understanding of gRPC and shapshotting my understanding of barrier synchronization, this post captures my understanding of MapReduce, a technology I’ve never been exposed to before. The purpose of these types of posts is to allow future self to look back and be proud of what I learned since the time I’m pouring into my graduate studies takes away time from my family and my other aspirations.
Anyways, when it comes to MapReduce, I pretty much know nothing beyond a very high level and superficial understanding: there’s a map step followed by a reduce step. Seriously — that’s it. So I’m hoping that, once I finish reading the original MapReduce paper and once I complete Project 4 (essentially building a MapReduce framework using gRPC), I’ll have a significantly better understanding of MapReduce. More importantly, I can apply some of my learnings to future projects.
Some questions I have:
How does MapReduce parallelize work?
What are some of the assumptions and trade offs of the MapReduce framework?
What are some work loads that are not suitable for MapReduce?
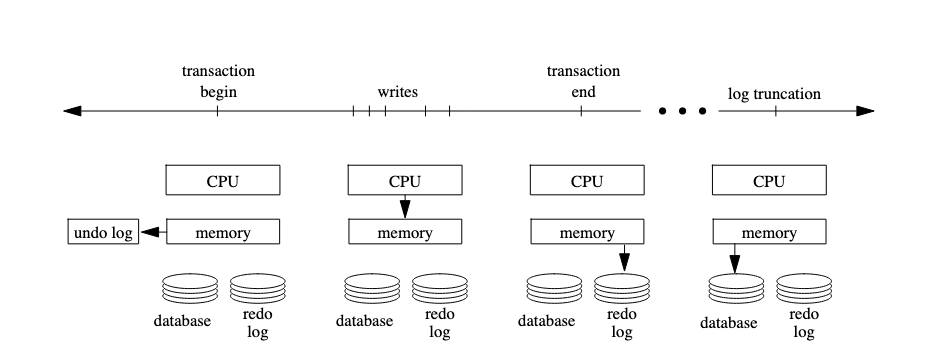
RioVista picks up where LRVM left off and aims for a performance conscience transaction. In other words, how can RioVista reduce the overhead of synchronous I/O, attracting system designers to use transactions
System Crash
Two types of failures: power failure and software failure
Key Words: power crash, software crash, UPS power supply
Super interesting concept that makes total sense (I’m guessing this is actually implemented in reality). Take a portion of the memory and battery back it up so that it survives crashes
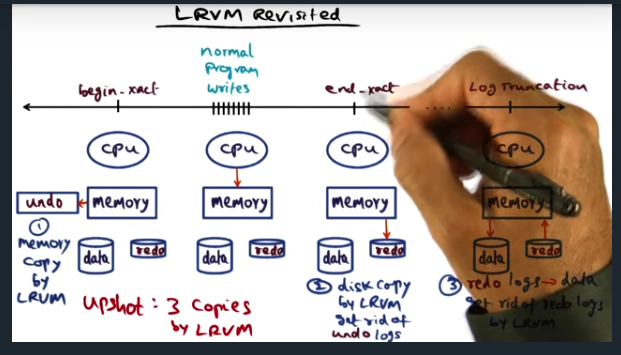
LRVM Revisited
Upshot: 3 copies by LRVM
Key Words: undo record, window of vulnerability
In short, LRVM can be broken down into begin transaction, end transaction. In the former, portion of memory segment is copied into a backup. At the end of the transaction, data persisted to disk (blocking operation, but can be bypassed with NO_FLUSH option). Basically, increasing vulnerability of system to power failures in favor of performance. So, how will a battery backed memory region help?
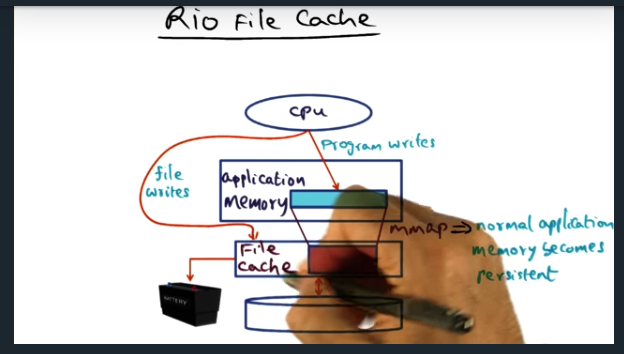
Rio File Cache
Creating a battery backed file cache to handle power failures
In a nutshell, we’ll use a battery backed file cache so that writes to disk can be arbitrarily delayed
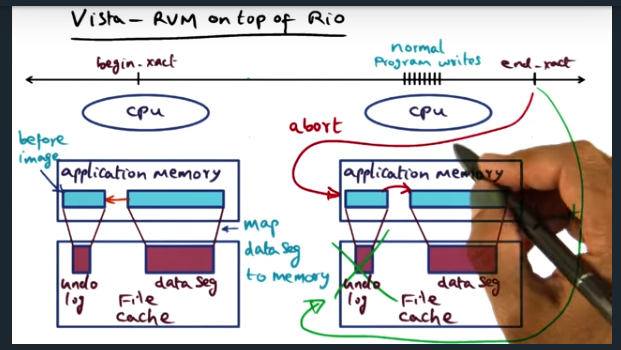
Vista RVM on Top of RIO
Vista – RMV on top of Rio
Key Words: undo log, file cache, end transaction, memory resisdent
Vista is a library that offers same semantics of LRVM. During commit, throw away the undo log; during abort, restore old image back to virtual memory. The application memory is now backed by file cache, which is backed by a power. So no more writes to disk
Crash Recovery
Key Words: idempotency
Brilliant to make the crash recovery mechanism the exact same scenario as an abort transaction: less code and less edge cases. And if the crash recovery fails: no problem. The instruction itself is idempontent
Vista Simplicity
Key Words: checkpoint
RioVista simplifies the code, reducing 10K of code down to 700. Vista has no redo logs, no truncation, all thanks to a single assumption: battery back DRAM for portion of memory
Conclusion
Key Words: assumption
By assuming there’s only software crashes (not power), we can come to an entirely different design
As system designers, we can make persistence into the virtual memory manager, offering persistence to application developers. However, it’s no easy feat: we need to ensure that the solution performs well. To this end, the virtual machine manager offers an API that allows developer to wrap their code in transactions; underneath the hood, the virtual machine manager uses redo logs that persists the user changes to disk which can defend against failures.
We can bake persistent into the virtual memory manager (VMM) but building an abstraction is not enough. Instead, we need to ensure that the solution is performant and instead of committing each VMM change to disk, we aggregate them into a log sequence (just like the previous approaches in distributed file system) so that 1) we write in a contiguous block
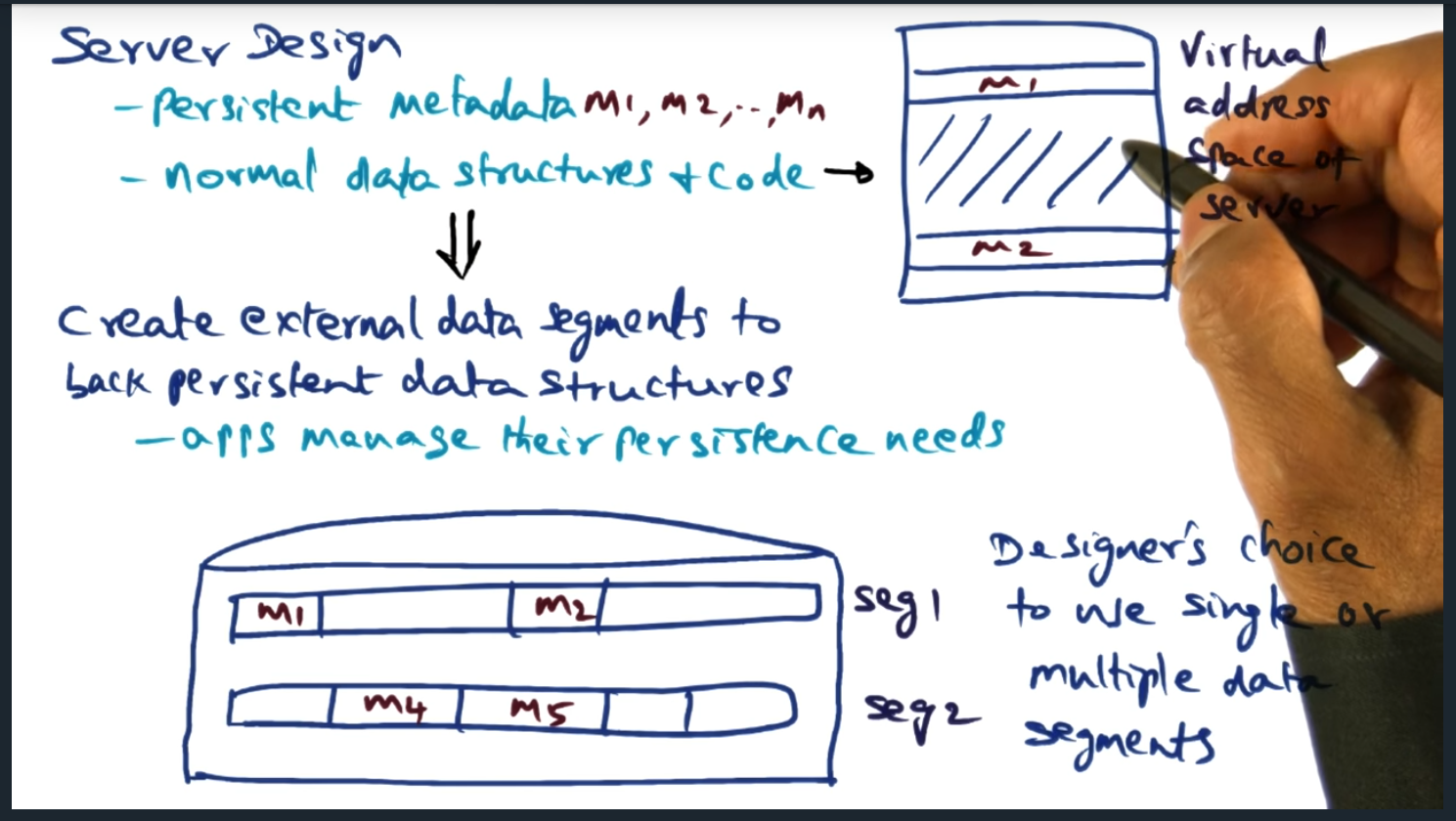
Server Design
Server Design – persist metadata, normal data structures
Key Words: inodes, external data segment
The designer of the application gets to decide which virtual addresses will be persisted to external data storage
Server Design (continued)
Key Words: inodes, external data segment
The virtual memory manager offers external data segments, allowing the underlying application to map portions of its virtual address space to segments backed by disk. The model is simple, flexible, and performant. In a nutshell, when the application boots up, the application selects which portions of memory must be persisted, giving the application developer full control
RVM Primitives
Key Words: transaction
RVM Primitives: initialization, body of server code
There are three main primitives: initialize, map, and unmap. And within the body of the application code, we use transactions: begin transaction, end transaction, abort transaction, and set range. The only non obvious statement is set_range: this tells the RVM runtime the specific range of addresses within a given transaction that will be touched. Meaning, when we perform a map (during initialization), there’s a larger memory range and then we create transactions within that memory range
RVM Primitives (continued)
RVM Primitives – transaction code and miscellaneous options
Key Words: truncation, flush, truncate
Although RVM automatically handles the writing of segments (flushing to disk and truncating log records), application developers can call those procedures explicitly
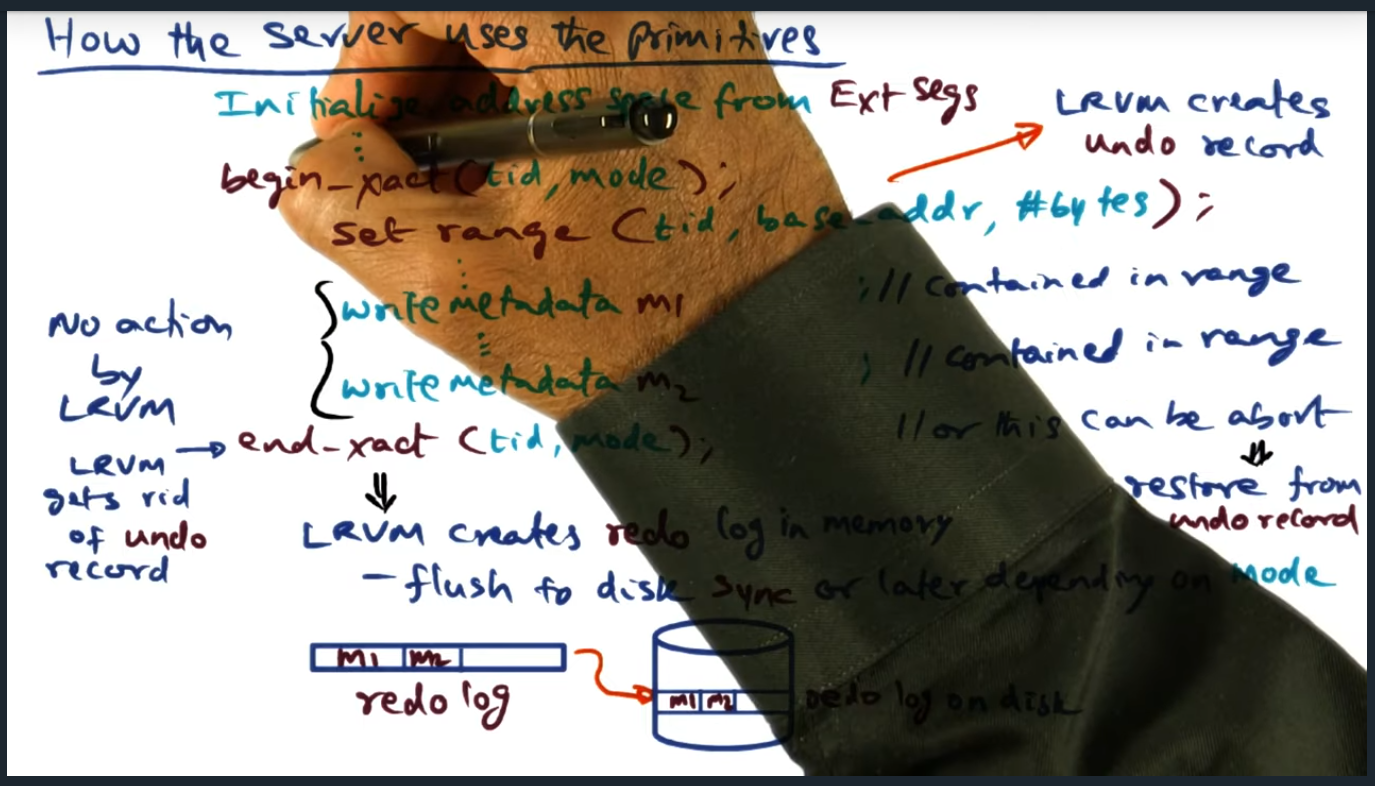
How the Server uses the primitives
How the server uses the primitives – begin and end transaction
Key Words: critical section, transaction, undo record
When transaction begins, the LRVM creates an undo record: a copy of the range specified, allowing a rollback in the event an abort occurs
How the Server uses the primitives (continued)
How the server uses the primitives – transaction details
Key Words: undo record, flush, persistence
During end transaction, the in memory redo log will get flushed to disk. However, by passing in a specific mode, developer can explicitly not call flush (i.e. not block) and flush the transaction themselves
Transaction Optimizations
Transaction Optimizations – ways to optimize the transaction
Key Words: window of vulnerability
With no_restore mode in begin transaction, there’s no need to create a in memory copy; similarly, no need to flush immediately with lazy persistence; the trade off here is that there’s an increase window of vulnerability
Redo log allows traversal in both directions (reverse for recovery) and only new values are written to the log: this implementation allows good performance
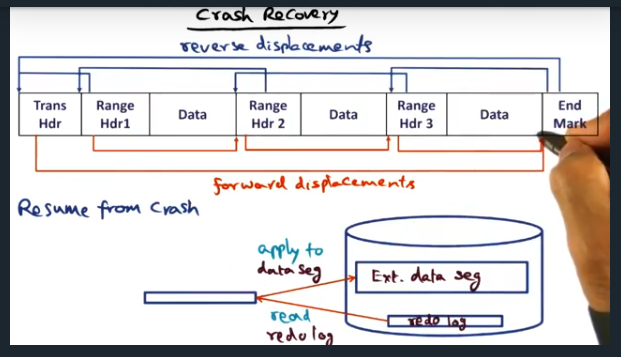
Crash Recovery
Crash Recovery – resuming from a crash
Key Words: crash recovery
In order to recover from a crash, the system traverses the redo log, using the reverse displacement.Then, each range of memory (along with the changes) are applied
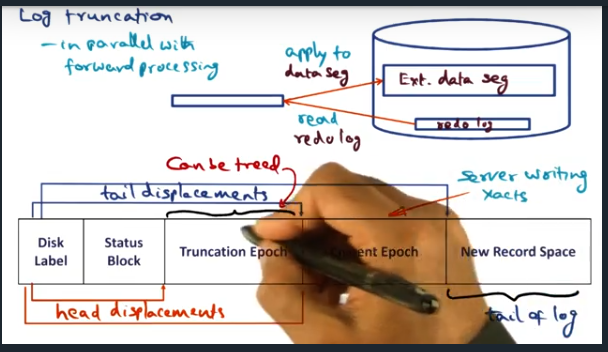
Log Truncation
Log truncation – runs in parallel with forward processing
Key Words: log truncation, epoch
Log truncation is probably the most complex part of LRVM. There’s a constant tug and pull between performance and crash recovery. Ensuring that we can recover is a main feature but it adds overhead and complexity since we want the system to make forward progress while recovering. This end, the algorithm breaks up data into epochs
This lesson introduces network file system (NFS) and presents the problems with it, bottlenecks including limited cache and expensive input/output (I/O) operations. These problems motivate the need for a distributed file system, in which there is no longer a centralized server. Instead, there are multiple clients and servers that play various roles including serving data
Quiz
Key Words: computer science history
Sun built the first ever network file system back in 1985
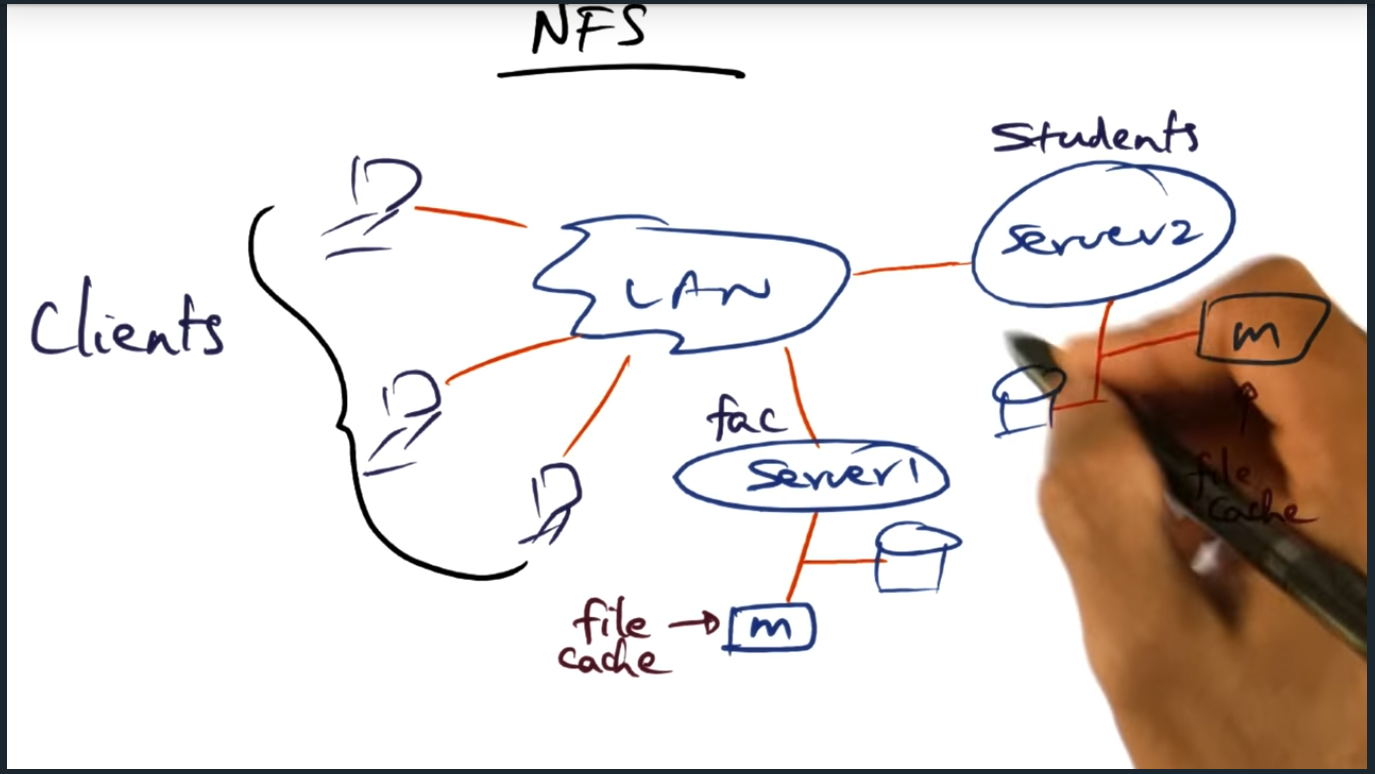
NFS (network file system)
NFS – clients and server
Key Words: NFS, cache, metadata, distributed file system
A single server that stores entire network file system will bottle neck for several reasons, including limited cache (due to memory), expensive I/O operations (for retrieving file metadata). So the main question is this: can we somehow build a distributed file system?
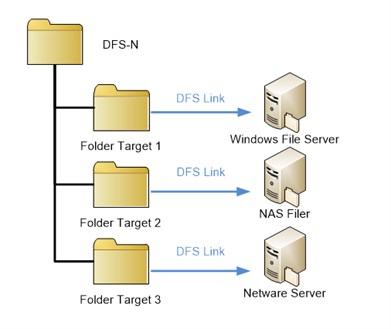
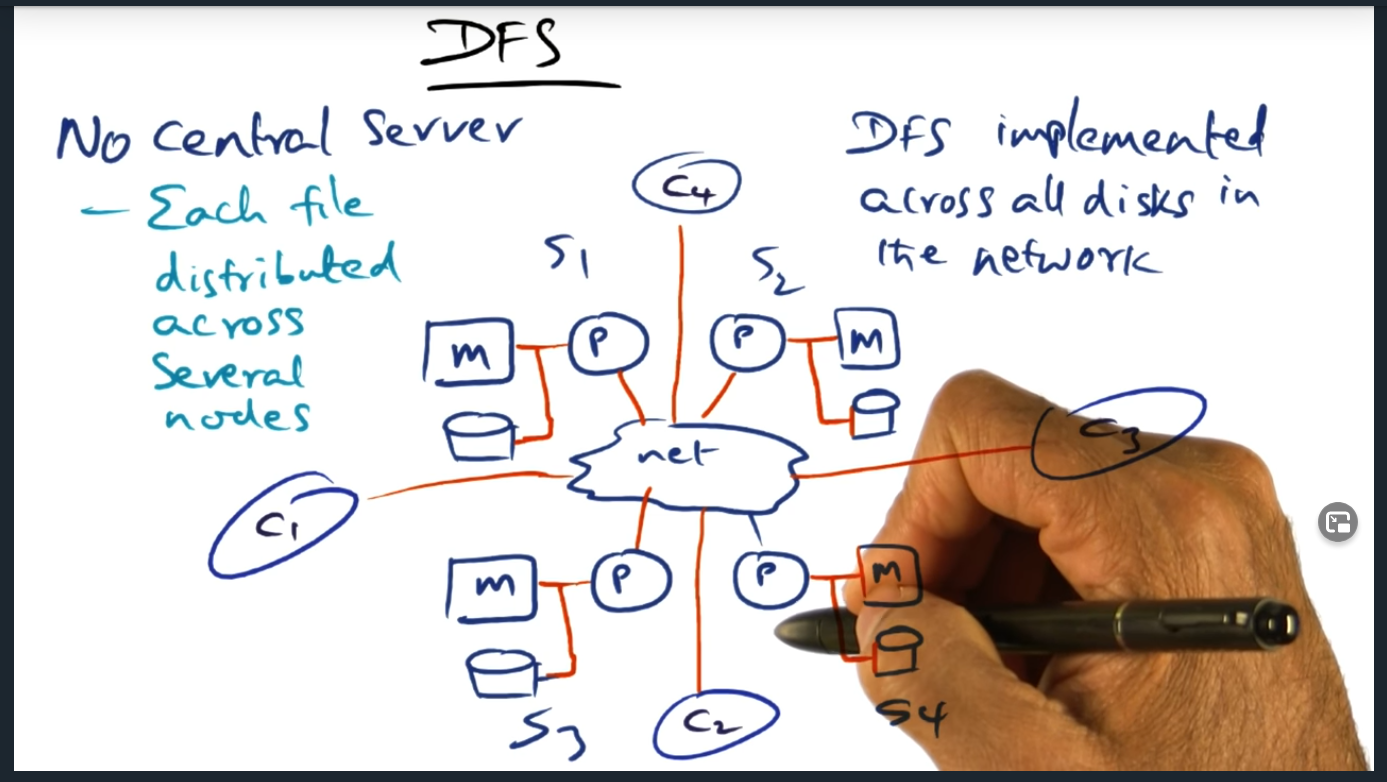
DFS (distributed file system)
Distributed File Server – each file distributed across several nodes
Key Words: Distributed file server
The key idea here is that there is no longer a centralized server. Moreover, each client (and server) can play the role of serving data, caching data, and managing files
Lesson Outline
Key Words: cooperative caching, caching, cache
We want to cluster the memory of all the nodes for cooperative caching and avoid accessing disk (unless absolutely necessary)
Preliminaries (Striping a file to multiple disks)
Key Words: Raid, ECC, stripe
Key idea is to write files across multiple disks. By adding more disks, we increase the probability of failure (remember computing those failures from high performance computing architecture?) so we introduce a ECC (error correcting) disk to handle failures. The downside of striping is that it’s expensive, not just in cost (per disk) but expensive in terms of overhead for small files (since a small file needs to be striped across multiple disks)
Preliminaries
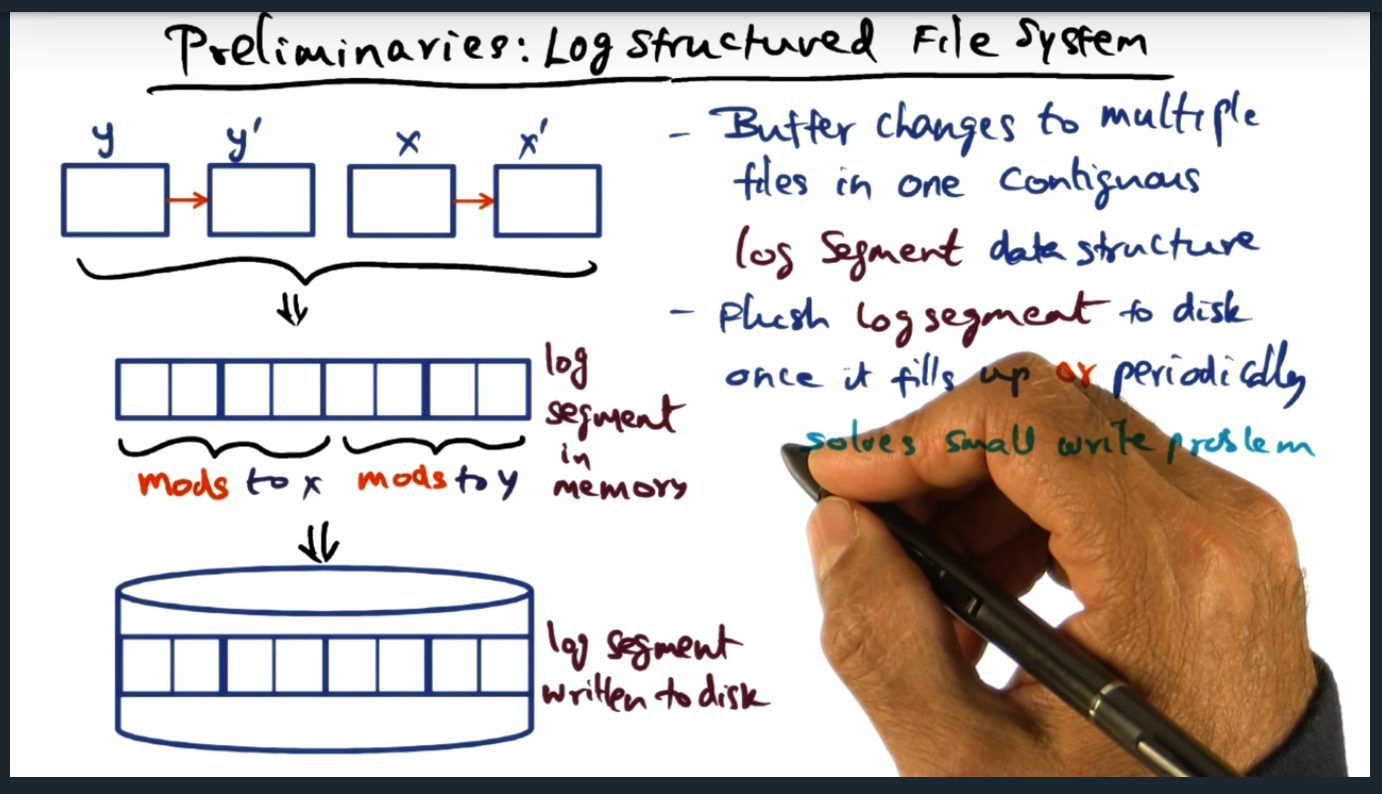
Preliminaries: Log structured file system
Key Words: Log structured file system, log segment data structure, journaling file system
In a log structured file system, the file system will store changes to a log segment data structure, the file system periodically flushing the changes to disk. Now, anytime a read happens, the file is constructed and computed based off of the delta (i.e. logs). The main problem this all solves is the small file problem (the issue with striping across multiple disks using raid). With log structure, we now can stripe the log segment, reducing the penalty of having small files
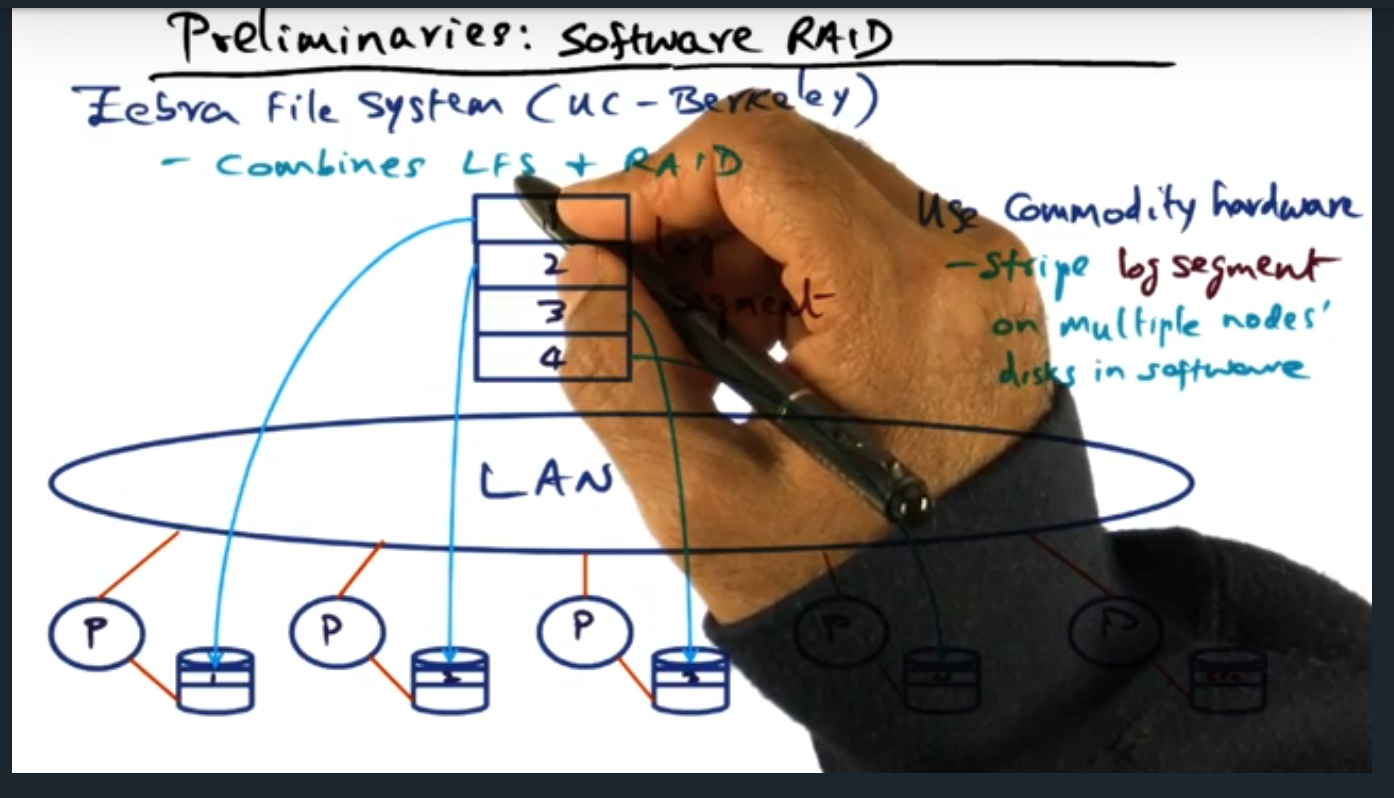
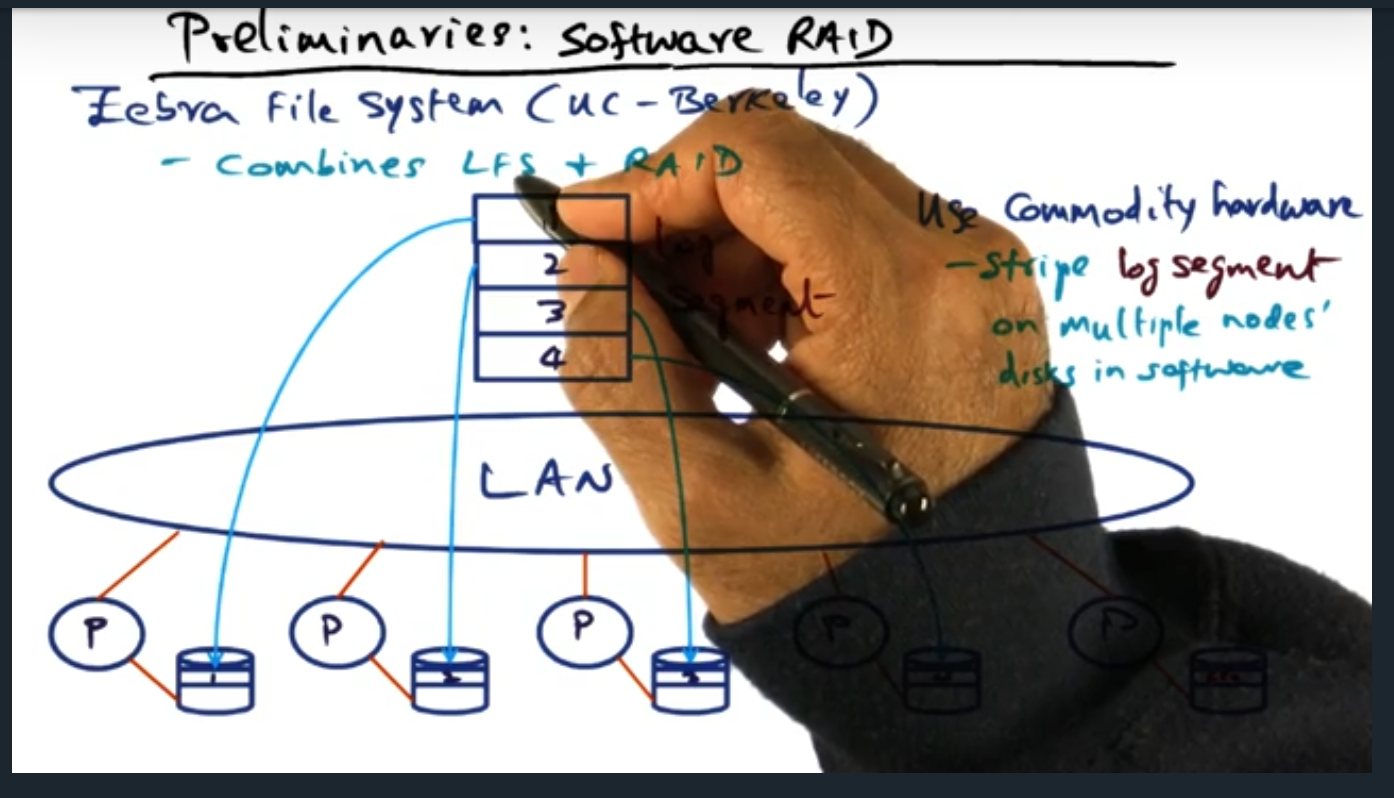
Preliminaries Software (RAID)
Preliminaries – Software Raid
Key Words: zebra file system, log file structure
The zebra file system combines two techniques for handling failures: log file structure (for solving the small file problem) and software raid. Essentially, error correction lives on a separate drive
Putting them all together plus more
Pputting them all together: log based, cooperative caching, dynamic management, subsetting, distributed
Key Words: distributed file system, zebra file system
The XFS file system puts all of this together, standing on top of the shoulders who built Zebra and built cooperating caching. XFS also adds new technology that will be discussed in later videos
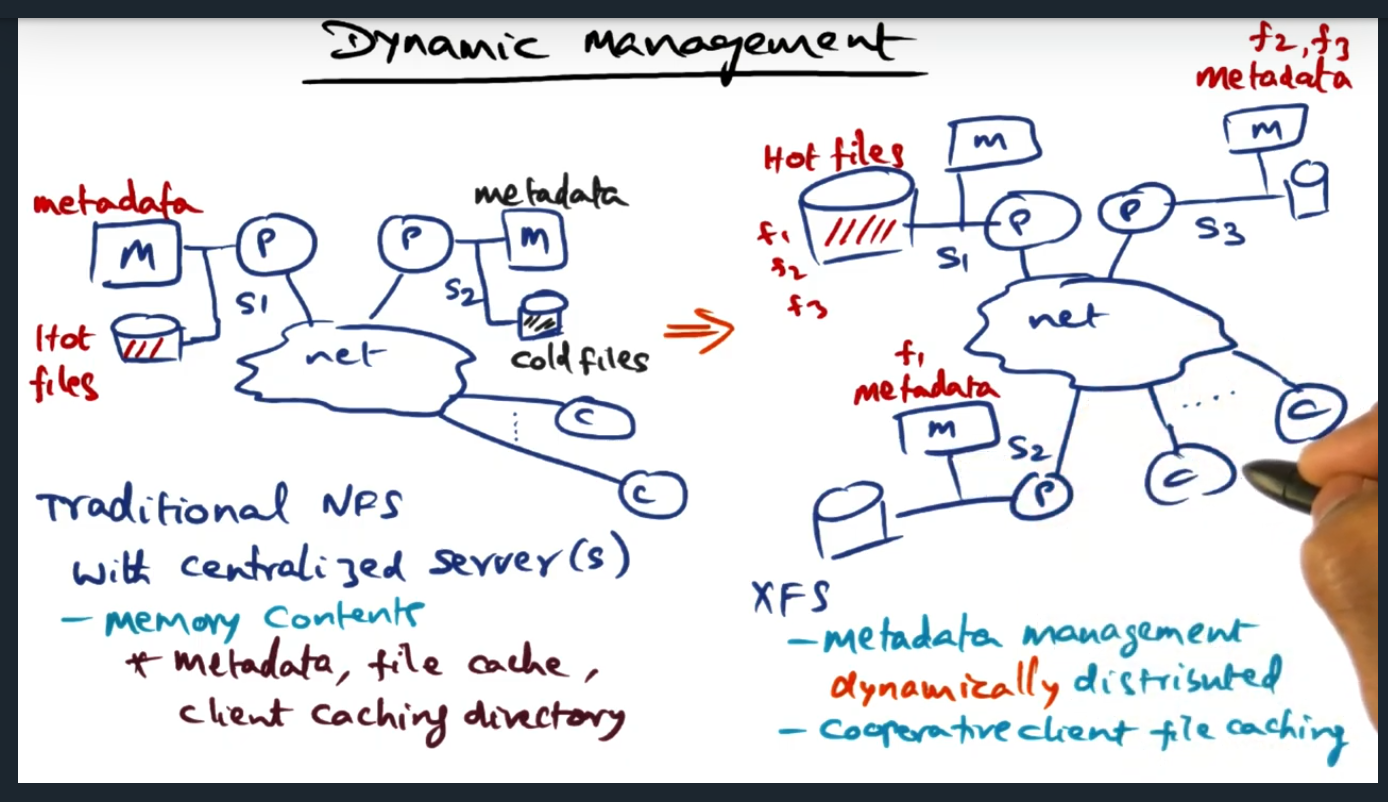
Dynamic Management
Dynamic Management
Key Words: Hot spot, metadata, metadata management
In a traditional NFS server, data blocks reside on disk and memory includes metadata. But in a distributed file system, we’ll extend caching to the client as well
Log Based Striping and Stripe Groups
Log based striping and stripe groups
Key Words: append only data structure, stripe group
Each client maintains its own append only log data structure, the client periodically flushing the contents to the storage nodes. And to prevent reintroducing the small file problem, each log fragment will only be written to a subset of the storage nodes, those subset of nodes called the stripe group
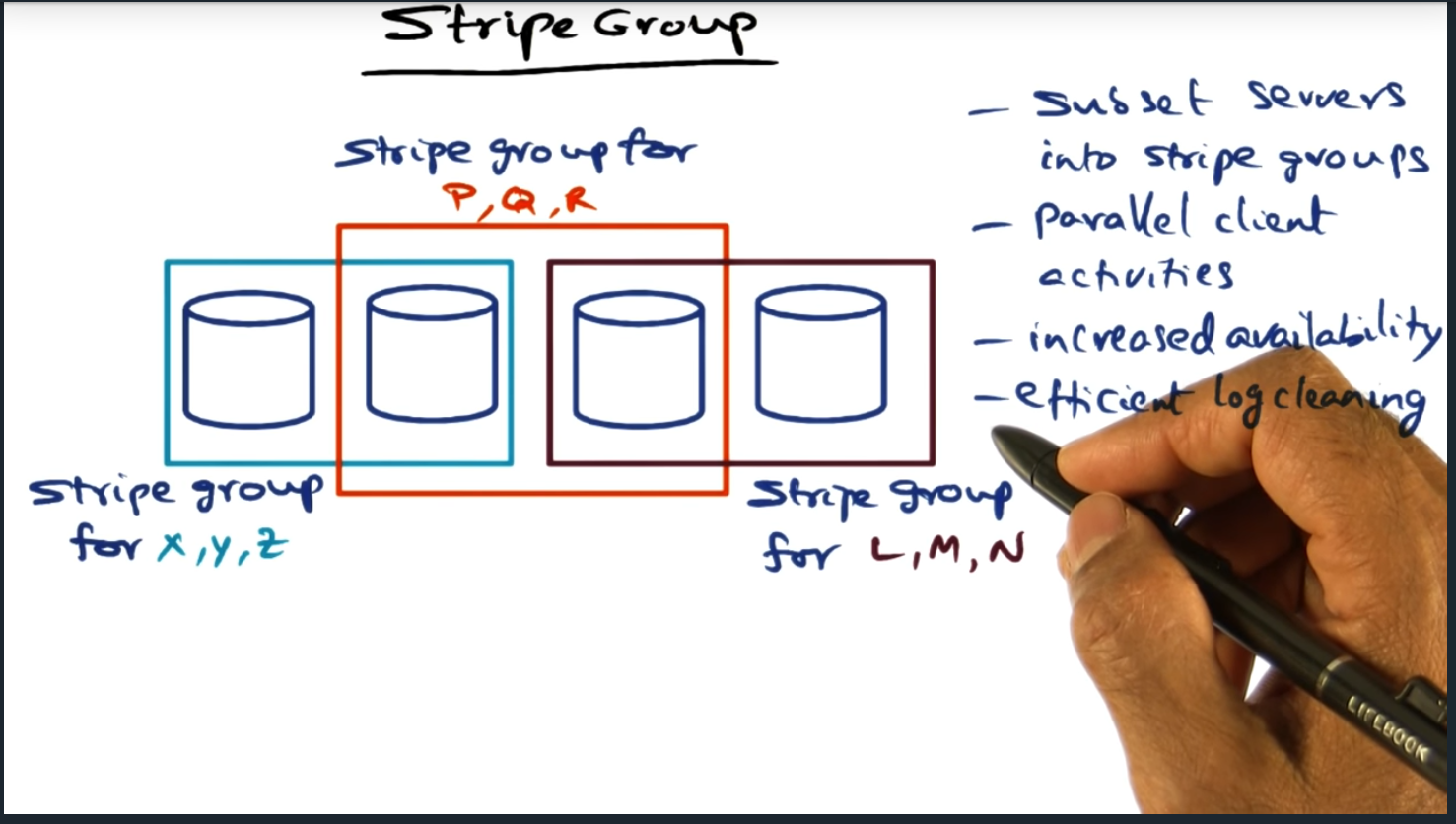
Stripe Group
Stripe Group
Key Words: log cleaning
By dividing the disks into stripe groups, we promote parallel client activities and increases availability
Cooperating Caching
Cooperative Caching
Key Words: coherence, token, metadata, state
When a client requests to write (to a block), the manager (who maintains state, in the form of metadata, about each client) will cache invalidate the clients and grant the writer a token to write for a limited amount of time
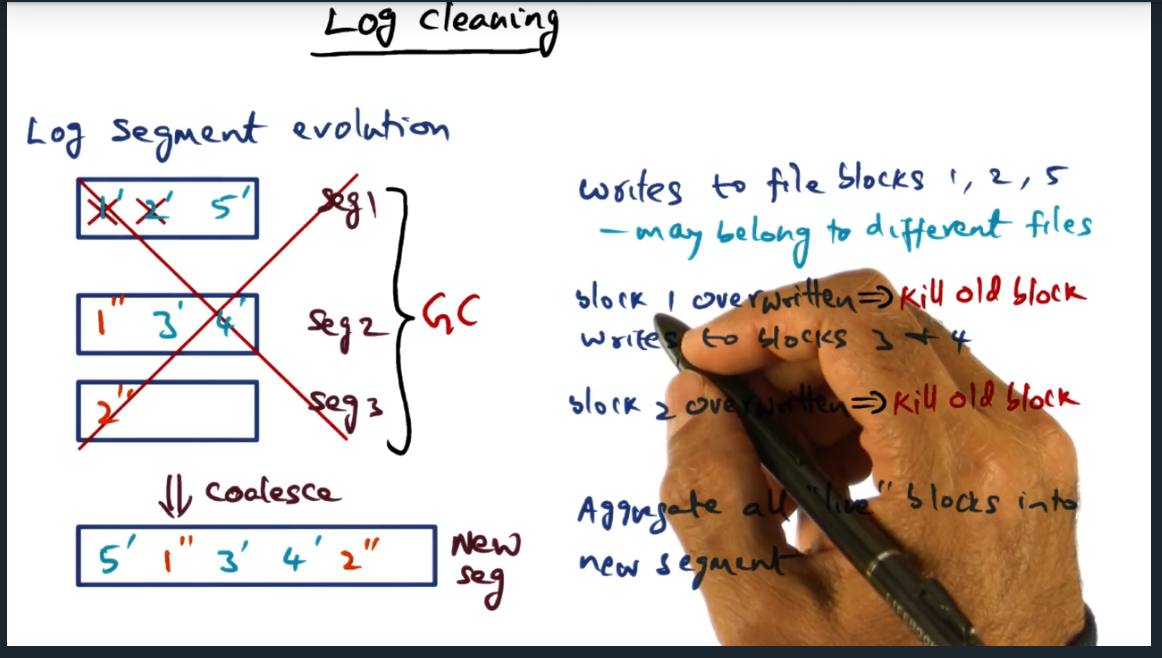
Log Cleaning
Log Cleaning
Key Words: prime, coalesce, log cleaning
Periodically, node will coalesce all the log segment differences into a single, new segment and then run a garbage collection to clean up old segments
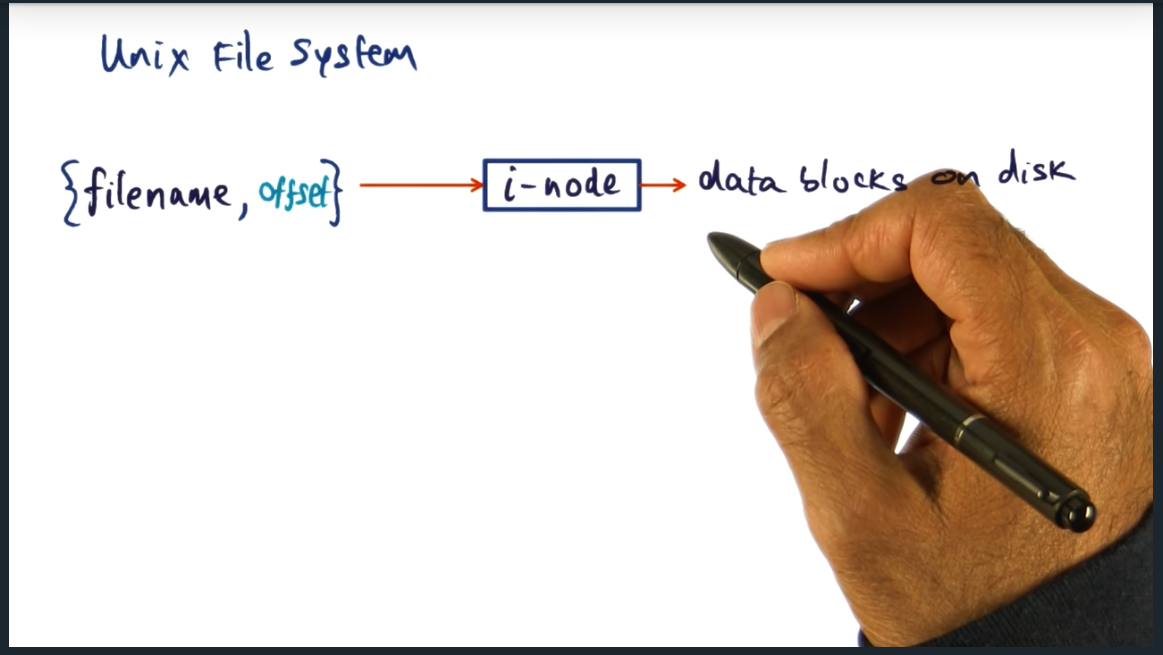
Unix File System
Unix File System
Key Words: inode, mapping
On any unix file system, there are inodes, which map filenames to data blocks on disk
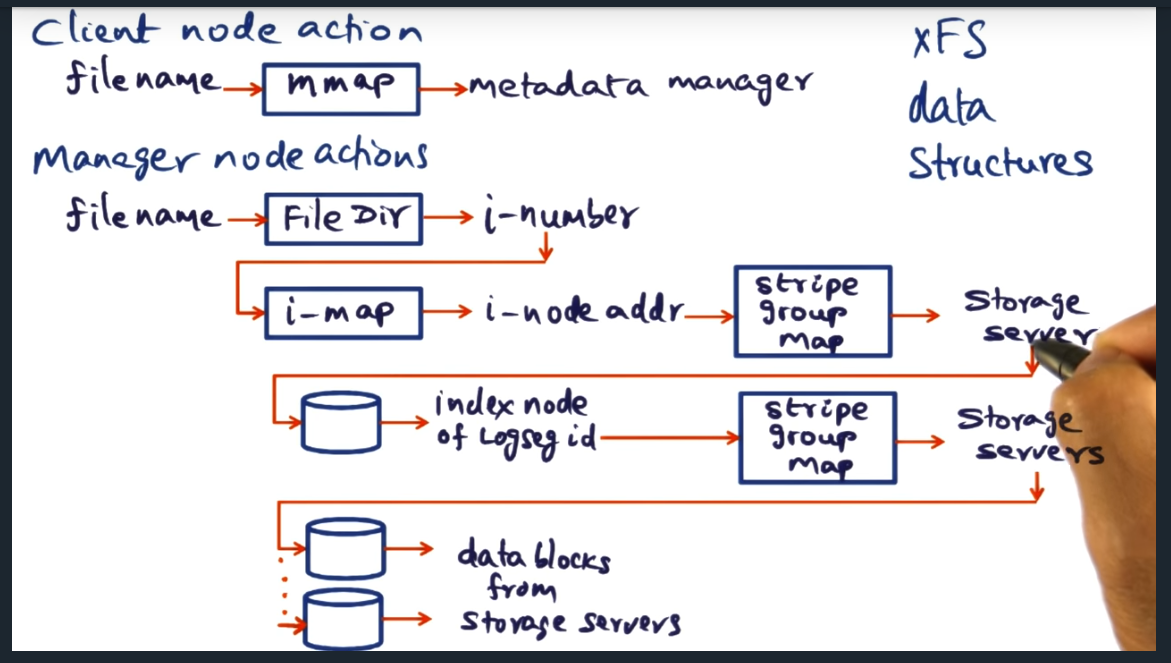
XFS Data Structures
XFS Data Structures
Key Words: directory, map
Manager node maintains data structures to map a filename to the actual data blocks from the storage servers. Some data structures include the file directory, and i_map, and stripe group map
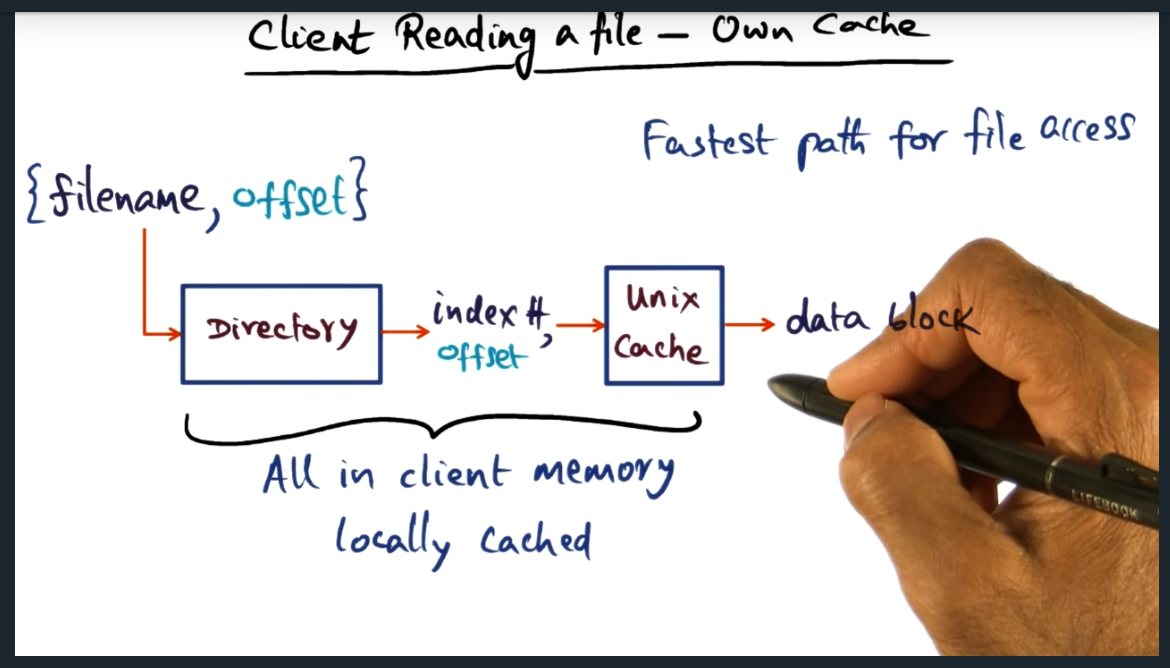
Client Reading a file own cache
Client Reading a file – own cache
Key Words: Pathological
There are three scenarios for client reading a file. The first (i.e. best case) is when the data blocks sit in the unix cache of the host itself. The second scenario is the client querying the manager, and the manager signals another peer to send its cache (instead of retrieving from disk). The worst case is the pathological case (i.e. see previous slide) where we have to go through the entire road map of talking to manager, then looking up metadata for the stripe group, and eventually pulling data from the disk
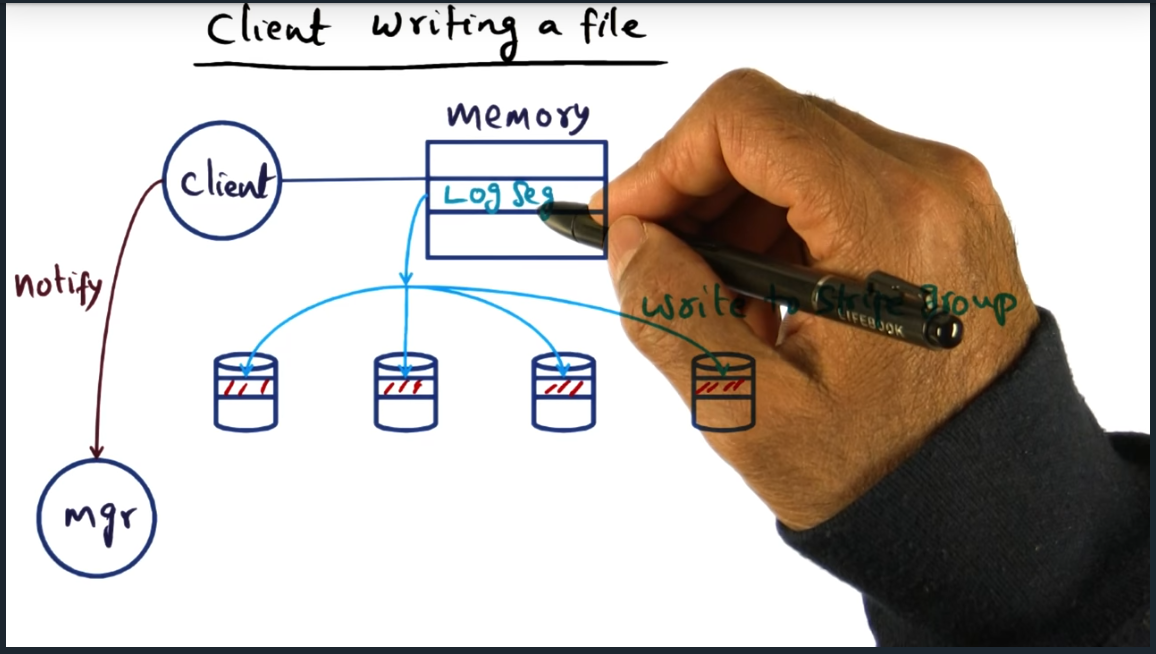
Client Writing a File
Client Writing a file
Key Words: distributed log cleaning
When writing, client will send updates to its log segments and then update the manager (so manager has up to date metadata)
Conclusion
Techniques for building file systems can be reused for other distributed systems