I serendipitously stumbled on another Zettelkasten desktop application called Zettlr. Perusing the online forum over at Zettelkasten.de, I had noticed that at least three of four members repping the app in their signatures. Naturally, I was curious so I followed the scent on the trail and loaded up the Zettlr website in my browser.
After skimming through the description, I decided to test drive the application.
And so far, I am really loving the application. It’s beautiful. It’s use friendly. It sparks joy.
Sure, the application is still in an infancy and has a few rough edges: the application fails to open up external third party application links (e.g. DevonThink) and the support for markdown tables is clunky at best and sometimes the cursor lags behind when I’m typing at my top speed. However, none of these issues are deal breakers. And I’m certain that, overtime, the application’s performance will be improved.
Top features
Keyboard shortcuts. Want to generate a unique identifier for your note card? Type in “CTRL + L” and the app will spit out a timestamp that serves as a unique ID for other cards to reference. Just plain awesome. How about inserting a markdown hyperlink? Well, just select some text and then press “CTRL + K”, the text converted to a markdown based hyperlink. And these two shortcuts are just the tip of the iceberg.
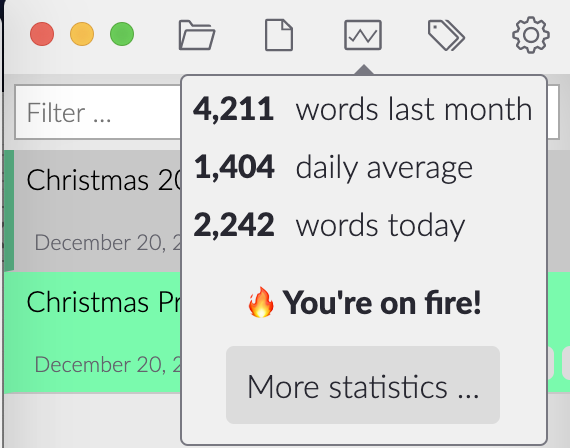
Built-in statistics. Check out at a glance how many words you are writing daily.
Writing is on fire!
Built in emojiis. I didn’t anticipate that I would enjoy inserting emojiis into my documents. Of course, I don’t over do it and only sprinkle them sparingly. Regardless, they add a nice little touch, a spark of joy in the creative writing process.
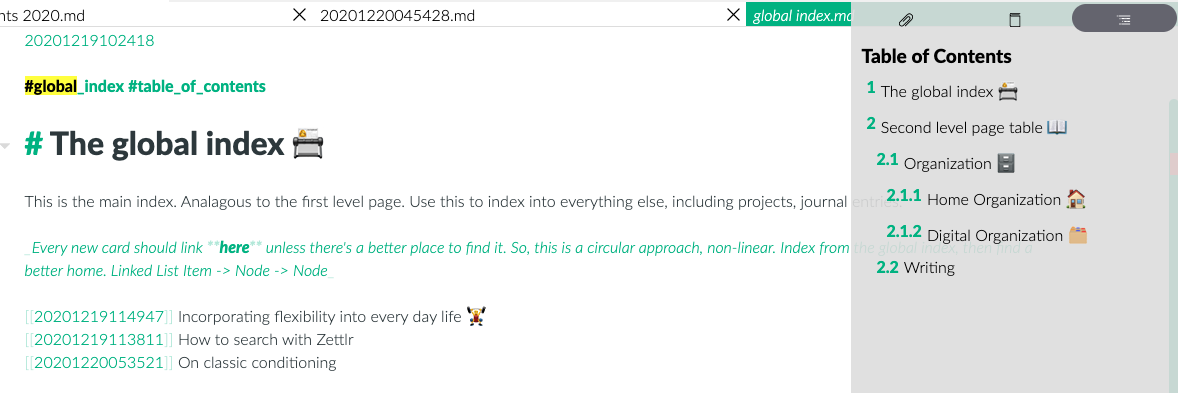
Auto-generated table of contents. By marking down your content with appropriate headings, you get a beautiful table of contents located in the side bar (which renders the emojiis nicely too).
Zettlr: Emojii support and auto-generated table of contents
Wrapping up
Overall, I love the application so far (again: it’s only been about 3 days). I’m certain I’ll discover other blesmishes as I continue to use the application. Regardless, Zettlr allows me to enjoy creating content: I’m able to achieve a sense of flow, often losing myself in the process, thanks to both the aesthetically pleasing interface as well as the low cost of context switching between reading, editing, writing and searching.
The original paper “Recovery management in quicksilver” introduces a transaction manager that’s responsible for managing servers and coordinates transactions. The below notes discusses how this operating system handles failures and how it makes recovery management a first class citizen.
Cleaning up state orphan processes
Cleaning up stale orphan processes
Key Words: Ophaned, breadcrumbs, stateless
In client/server systems, state gets created that may be orphaned, due to a process crash or some unexpected failure. Regardless, state (e.g. persistent data structures, network resources) need to be cleaned up
Introduction
Key Words: first class citizen, afterthought, quicksilver
Quicksilver asks if we can make recovery a first class citizen since its so critical to the system
Quiz Introduction
Key Words: robust, performance
Users want their cake and eat it too: they want both performance and robustness from failures. But is that possible?
Quicksilver
Key Words: orphaned, memory leaks
IBM identified problems and researched this topic in the early 1980s
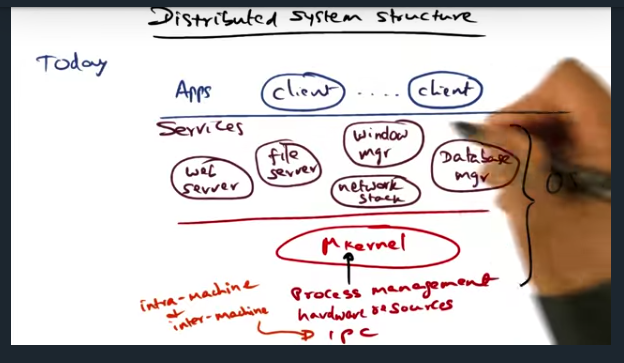
Distributed System Structure
Distributed System Structure
Key Words: microkernel, performance, IPC, RPC
A structure of multiple tiers allows extensibility while maintaining high performance
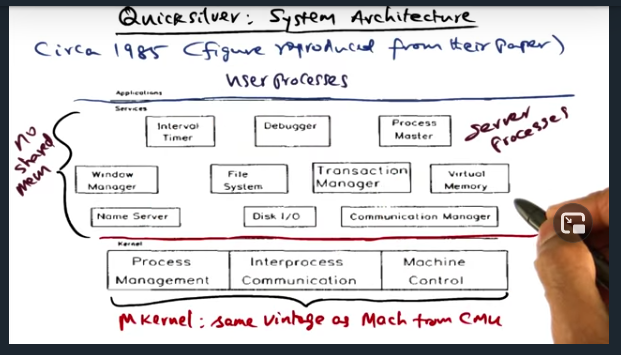
Quicksilver System Architecture
Quicksilver: system architecture
Key Words: transaction manager
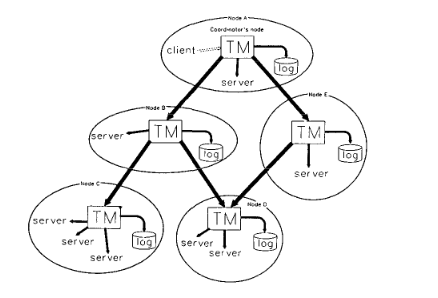
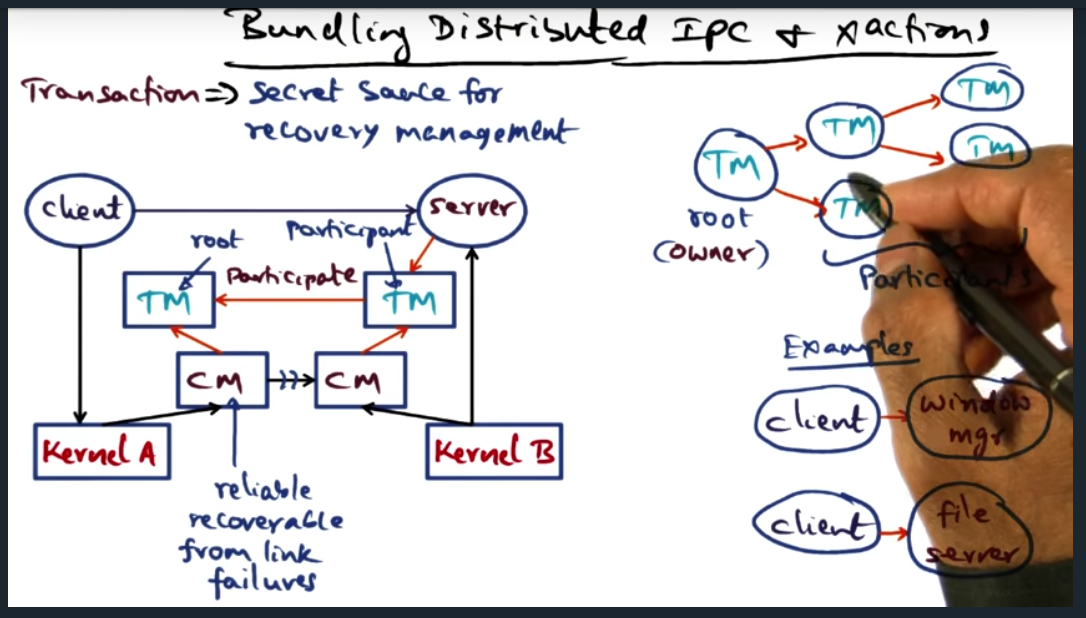
Quicksilver is the first network operating system to propose transactions for recovery management. To that end, there’s a “Transaction Manager” available as a system service (implemented as a server process)
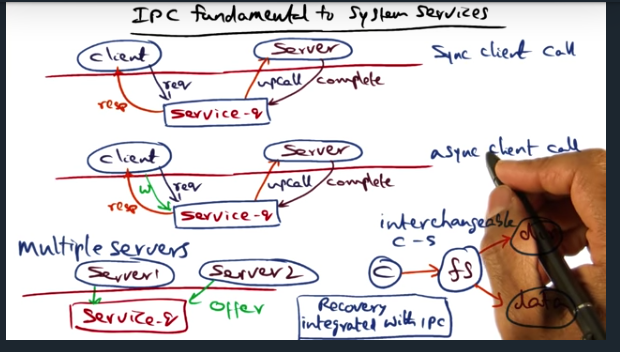
IPC is fundamental to building system services. And there are two ways to communicate with the service: synchronously (via an upcall) and asynchronously. Either, the center of this IPC communication is the service_q, which allows multiple servers to perform the body of work and allows multiple clients to enqueue their request
During a transaction, there is state that should be recoverable in the event of a failure. To this end, we build transactions (provided by the OS), the secret sauce for recovery management
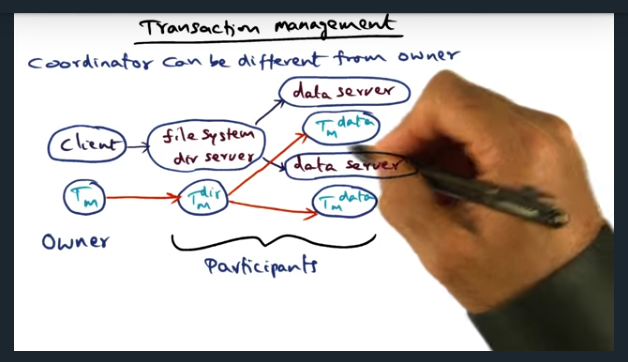
When a client requests a file, the client’s transaction manager becomes the owner (and root) of the transaction tree. Each of the other nodes are participants. However, since client is suspeptible to failing, ownership can be transferred to other participants, allowing the other participants to clean up the state in the event of a failure
Many types of failures are possible: connection failure, client failure, subordinate transaction manager failure. To handle these failures, transaction managers must periodically store the state of the node into a checkpoint record, which can be used for potential recovery
Commit Initiated by Coordinator
Commit initiated by Coordinator
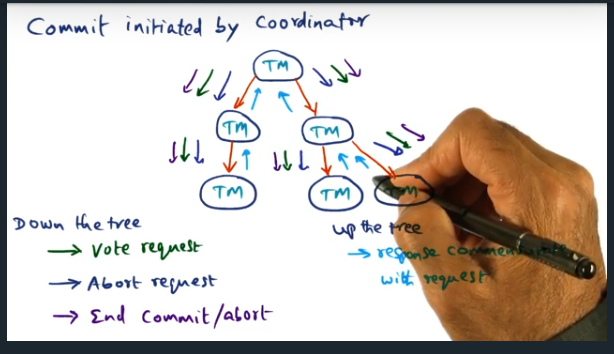
Key Words: Coordinator, two phase commit protocol
Coordinator can send different types of messages down the tree (i.e. vote request, abort request, end commit/abort). These messages help clean up the state of the distributed system. For more complicated systems, like a file system, may need to implement a two phased commit protocol
Upshot of Bundling IPC and Recovery
Upshot of bundling IPC and Recovery
Key Words: IPC, in memory logs, window of vulnerability, trade offs
No extra communication needed for recovery: just ride on top of IPC. In other words, we have the breadcrumbs and the transaction manager data, which can be recovered
Need to careful about choosing mechanism available in OS since log force impacts performance heavily, since that requires synchronous IO
Conclusion
Key Words: Storage class memories
Ideas in quicksilver are still present in contemporary systems today. The concepts made their way into LRVM (lightweight recoverable virtual machine) and in 2000, found resurgence in Texas operating system
This post is a cliff notes version I scrapped together after reading the paper Operating Systems Transactions. Although I strongly recommend you read the paper if you are interested in how the authors pulled inspiration from database systems to create a transactional operating system, this post should give you a good high overview if you are short on time and need a quick and shallow understanding.
Abstract
System transactions enable application developers to update OS resources in an ACID (atomic, consistent, isolated, and durable) fashion.
TxOS is a variant of Linux that implements system transactions using new techniques, allowing fairness between system transactions and non-transaction activities
Introduction
The difficulty lies in making updates to multiple files (or shared data structures) at the same time. One example of this is updating user accounts, which requires making changes to the following files: /etc/passwd, /etc/shadow, /etc/group
One way for ensuring that a file is atomically updates is by using a “rename” operation, this system call replacing the contents of a file.
But for more complex updates, we’ll need to use something like flock for handling mutual exclusion. These advisory locks are just that: advisory. Meaning, someone can bypass these control, like an administrator, and just update the file directly.
Although one approach to fix these concurrency problems is by adding more and more system calls. But instead of taking this approach of constantly identifying and eliminating race conditions, why not percolate the responsibility up to the end user, by allowing system transactions?
These system transactions is what the paper proposes and this technique allows developers to group their transaction using system calls: sys_xbegin() and sysx_xend().
This paper focuses on a new approach to OS implementation and demonstrates the utility of system transactions by creating multiple prototypes.
Motivating Examples
Section covers two common application consistency problems: software upgrade and security
Both above examples and their race conditions can be solved by using ”’system transactions”’
Software installation or upgrade
Upgrading software is common but difficult
There are other approaches, each with their own drawbacks
One example is using a checkpoint based system. With checpoints, system can rollback. However, files not under the control of the checkpoint cannot be restored.
To work around the shortcomings of checkpoint, system transactions can be used to atomically roll forward or rollback the entire installation.
Eliminating races for security
Another type of attack is interleaving a symbolic link in between a user’s access and open system calls
By using transactions, the symbolic link is serialized (or ordered) either before or after and cannot see partial updates
The approach of adding transactions is more effective long term, instead of fixing race conditions as they pop up
Overview
System transactions make it easy on the developer to implement
Remainder of section describes the API and semantics
System Transactions
System transactions provide ACID (atomic, consistent, isolation, durability) semantics – but instead of at the database level, at the operating system level
Essentially, application programmer wraps their code in sys_xbegin() and sys_xend()
System transaction semantics
Similar to database semantics, system transactions are serializable and recoverable
Transactions are atomic and can be rolled back to a previous state
Transactions are durable (i.e. once transaction results are committed, they survive system crashes)
Kernel enforces the following invariant: only a single writer at a time (per object)
If there are multiple writers, system will detect this condition and abort one of the writers
Kernel enforces serialization
Durability is an option
Interaction of transactional and non-transactional threads
Serialization of transaction and non-transational updates is caclled strong isolation
Other implementations do not take a strong stance on the subject and are semantically murkey
By taking a strong stance, we can avoid unexpected behavior in the presence of non-transactional updates
System transaction progress
OS guarantees system transactions do not livelock with other system transactions
If two transactions are in progress, OS will select one of the transactions to commit, while restarting the other transaction
OS can enforce policies to limit abuse of transactions, similar to how OS can control access to memory, disk space, kernel threads etc
System transactions for system state
Key point: system transactions provide ACID semantics for system state but not for application state
When a system transaction aborts, OS will restore kernel data structures, but not touch or revert application state
Communication Model
Application programmer is responsible for not adding code that will communicate outside of a transaction. For example, by adding a request to a non-transactional thread, the application may deadlock
TxOS overview
TXOS Design
System transactions guarantee strong isolation
Interoperability and fairness
Whether or not a thread is a transactional or non transactional thread, it must check for conflicting annotation when accessing a kernel object
Often this check is done at the same time when a thread acquires a lock on the object
When there’s a conflict between a transaction and non-transactional thread, this is called asymmetric conflict. Instead of aborting the transaction, TxOS will suspend the non-transactional thread, promoting fairness between transactions and non-transactional threads.
Managing transactional state
Historically, databases and transactional OS will update data in place and maintain an undo log: this is known as eager version management
”Isn’t the undo log approach the approach the light recoverable virtual machine takes?”
In eager version management, systems hold lock until the commit is completed and is also known as two-phase locking
Deadlocking can happen and one typical strategy is to expose a timeout parameter to users
Too short of a timeout starves long transactions. Too long of a deadlock and can starve performance (this is a trade off, of course)
Unfortunately, eager version management can kill performance since the transaction must process its redo log and jeopardizes system’s overall performance
Therefore, TxOS uses lazy version management, operating on private copies of data structures
Main disadvantage of lazy versioning is the additional commit latency due to copying updates of the underlying data structures
Integration with transactional memory
Again, system transactions protect system state: not application state
Users can integrate iwth user level transaction memory systems if they want to protect application state
System calls are forbidden during user transactions since allowing so would violate transactional semantics
TxOS Kernel Implementation
Versioning data
TxOS applies a technique that’s borrowed from software transactional memory systems
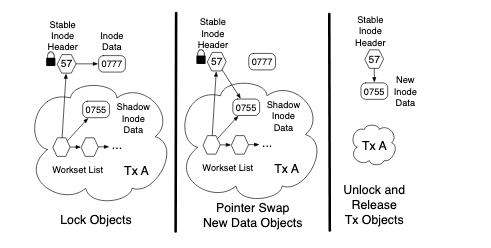
During a transaction, a private copy of the object is made: this is known as a the shadow object
The other object is known as “stable”
During the commit, shadow object replaces the stable
A naive approach would be to simply replace the stable pointer, since the object may be the target of pointers from several other objects
For efficient commit of lazy versioned data, need to break up data into header and data.
”Really fascinating technique…”
Maintain a header and the header pointers to the object’s data. That means, other objects always access data via the header, the header never replaced by a transaction
Transactional code always has speculative object
The header splits data into different payloads, allowing the data to be accessed disjointly
OS garbage collects via read-copy update
Although read only data avoids cost of duplicating data, doing so complicates the programming model slightly
Ultimately, RCU is a technique that supports efficient, concurrent access to read-mostly data.
Conflict detection and resolution
TxOS provides transactions for 150 of 303 system calls in Linux
Providing transactions for these subset system calls requires an additional 3,300 lines of code – just for transaction management alone
A conflict occurs when transaction is about to write to an object but that object has been written by another transaction
Header information is used to determine the reader count (necessary for garbage collection)
A non-null writer pointer indicates an active transactional writer. Similarly, an empty reader lists means there are no readers
All conflicts are arbitrated by the contention manager
During a conflict, the contention manager arbitrates by using an osprio policy: the process with the higher scheduling process wins. But if both processes have the same priority, then the older one wins: this policy is known as timestamp.
Asymmetric conflicts
non-transactional threads cannot be rolled back, although transactional threads can always be rolled back. That being said, there must be mechanism to resolve the conflict in favor of the transactional thread otherwise that policy always favor the non-transactional thread
non-transactional threads cannot be rolled back but they can be preemted, a recent feature of Linux
Minimizing conflicts on lists
Kernel relies heavily on linked lists data structures
Managing transaction state
TxOS adds transaction objects to the kernel
Inside of transaction struct, the status (probably an alias to uint8_t) is updated atomically with a compare and swap operation
If transaction system call cannot complete because of conflict, it must abort
Roll back is possible by saving register state on the stack at the beginning of the system call, in the “checkpointed_registers” field
During abort, restore register state and call longjmp
Certain operations must not be done until commit; these operations are stored in deferred_ops. Similarly, some operations must be done during abort, and these operations are stored in undo_ops field.
Workset_list is a skip list that contains references to all objects in the transaction and the transaction’s private copies
Commit protocol
When sys_xend (i.e. transaction ends), transaction acquires lock for all items in (above mentioned) workset.
Once all locks are acquired, transaction performs one final check in its status word and verifies that the status has been set to abort.
Abort protocol
Abort must happen when transaction detects that it lost a conflict
Transaction must decrement the reference count and free the shadow objects
User level transactions
Can only support user-level transactions by coordinating commit of application state with system transaction’s commit
Lock-based STM requirements
Used a simplified variant of two-phase commit protocol
Essentially, user uses sys_xend() system call and must inspect the return code so that the user application can then decide what to do based off of the system call’s transaction
TxOS Kernel Subsystems
Remainder will discuss ACID semantics
Example will include ext3 file system
Transactional file system
Managed versioned data in the virtual filesystem layer
File system only needs to provide atomic updates to stable storage (i.e. via a journal)
By guaranteeing writes are done in a single journal transaction, ext3 is now transactional
Multi-process transactions
Forked children execute until sys_xend() or the process exits
Signal delivery
Application can decide whether to defer a signal until a later point
If deferred, signals are placed into queue
Future work
TxOS does not provide transactional semantics for all OS resources
If attempting to use transaction on unsupported resource, transaction will be aborted
As system designers, we can make persistence into the virtual memory manager, offering persistence to application developers. However, it’s no easy feat: we need to ensure that the solution performs well. To this end, the virtual machine manager offers an API that allows developer to wrap their code in transactions; underneath the hood, the virtual machine manager uses redo logs that persists the user changes to disk which can defend against failures.
We can bake persistent into the virtual memory manager (VMM) but building an abstraction is not enough. Instead, we need to ensure that the solution is performant and instead of committing each VMM change to disk, we aggregate them into a log sequence (just like the previous approaches in distributed file system) so that 1) we write in a contiguous block
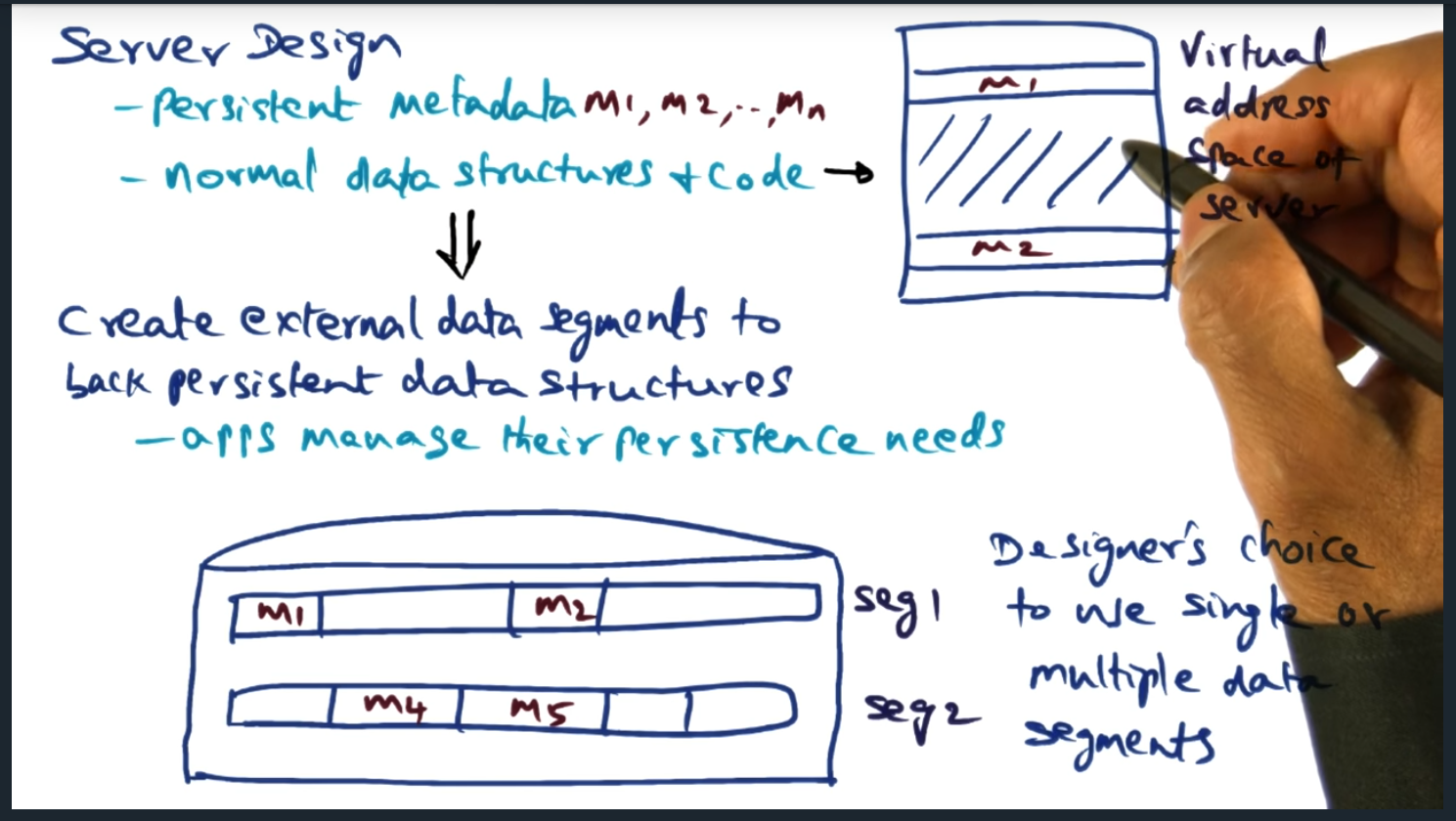
Server Design
Server Design – persist metadata, normal data structures
Key Words: inodes, external data segment
The designer of the application gets to decide which virtual addresses will be persisted to external data storage
Server Design (continued)
Key Words: inodes, external data segment
The virtual memory manager offers external data segments, allowing the underlying application to map portions of its virtual address space to segments backed by disk. The model is simple, flexible, and performant. In a nutshell, when the application boots up, the application selects which portions of memory must be persisted, giving the application developer full control
RVM Primitives
Key Words: transaction
RVM Primitives: initialization, body of server code
There are three main primitives: initialize, map, and unmap. And within the body of the application code, we use transactions: begin transaction, end transaction, abort transaction, and set range. The only non obvious statement is set_range: this tells the RVM runtime the specific range of addresses within a given transaction that will be touched. Meaning, when we perform a map (during initialization), there’s a larger memory range and then we create transactions within that memory range
RVM Primitives (continued)
RVM Primitives – transaction code and miscellaneous options
Key Words: truncation, flush, truncate
Although RVM automatically handles the writing of segments (flushing to disk and truncating log records), application developers can call those procedures explicitly
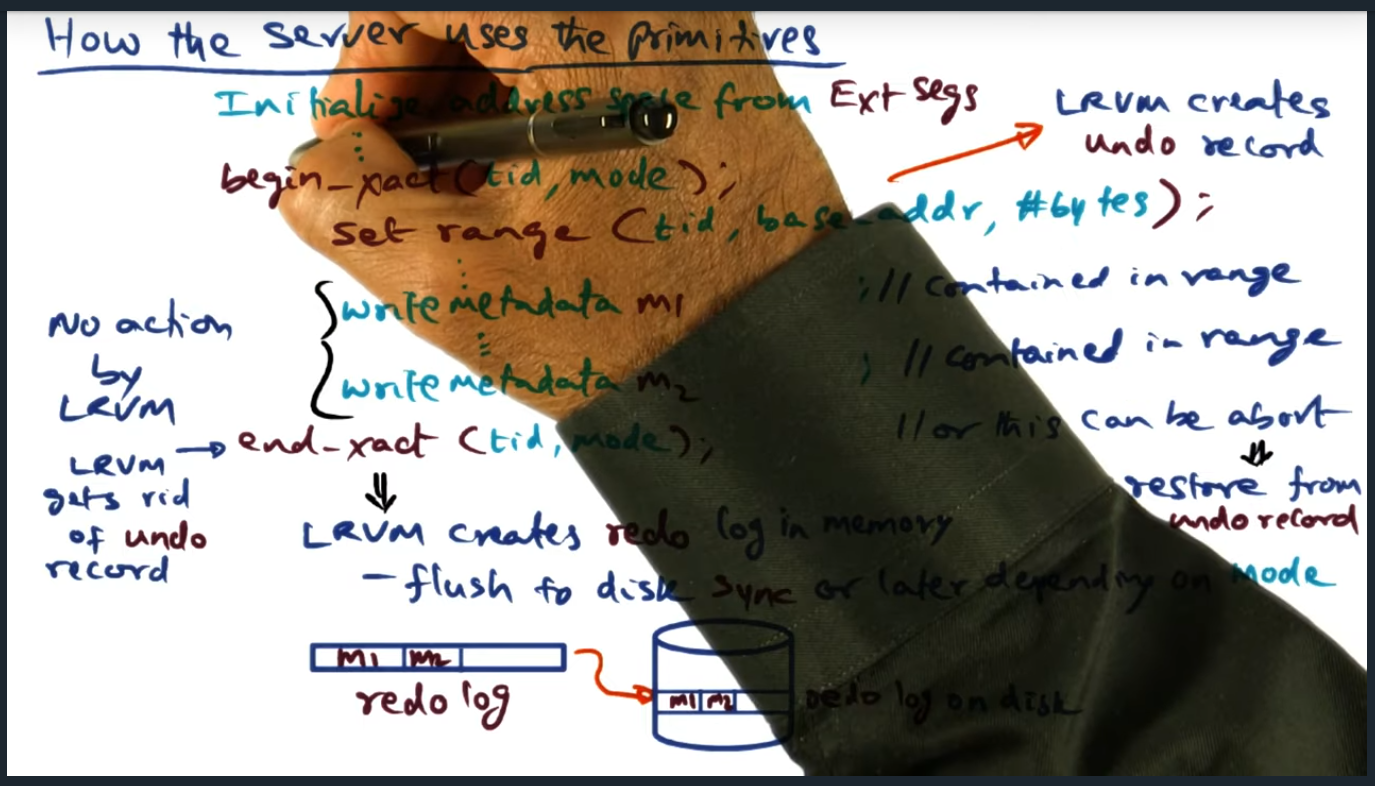
How the Server uses the primitives
How the server uses the primitives – begin and end transaction
Key Words: critical section, transaction, undo record
When transaction begins, the LRVM creates an undo record: a copy of the range specified, allowing a rollback in the event an abort occurs
How the Server uses the primitives (continued)
How the server uses the primitives – transaction details
Key Words: undo record, flush, persistence
During end transaction, the in memory redo log will get flushed to disk. However, by passing in a specific mode, developer can explicitly not call flush (i.e. not block) and flush the transaction themselves
Transaction Optimizations
Transaction Optimizations – ways to optimize the transaction
Key Words: window of vulnerability
With no_restore mode in begin transaction, there’s no need to create a in memory copy; similarly, no need to flush immediately with lazy persistence; the trade off here is that there’s an increase window of vulnerability
Redo log allows traversal in both directions (reverse for recovery) and only new values are written to the log: this implementation allows good performance
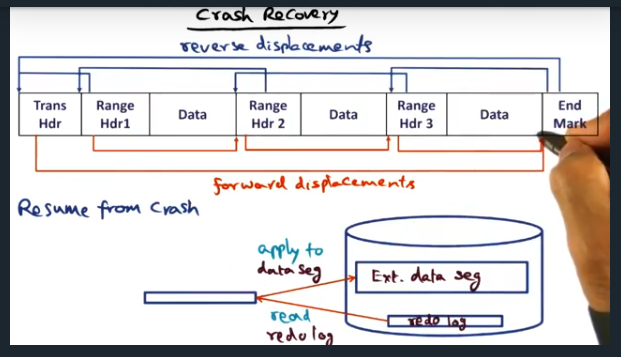
Crash Recovery
Crash Recovery – resuming from a crash
Key Words: crash recovery
In order to recover from a crash, the system traverses the redo log, using the reverse displacement.Then, each range of memory (along with the changes) are applied
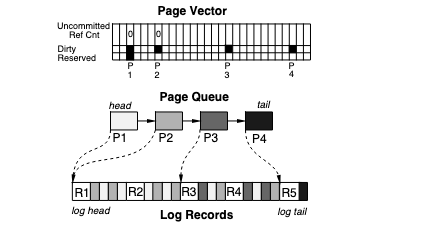
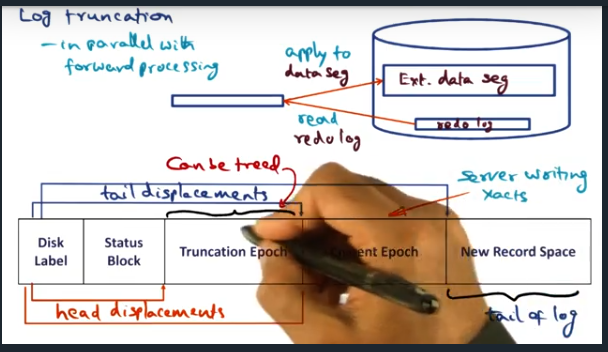
Log Truncation
Log truncation – runs in parallel with forward processing
Key Words: log truncation, epoch
Log truncation is probably the most complex part of LRVM. There’s a constant tug and pull between performance and crash recovery. Ensuring that we can recover is a main feature but it adds overhead and complexity since we want the system to make forward progress while recovering. This end, the algorithm breaks up data into epochs
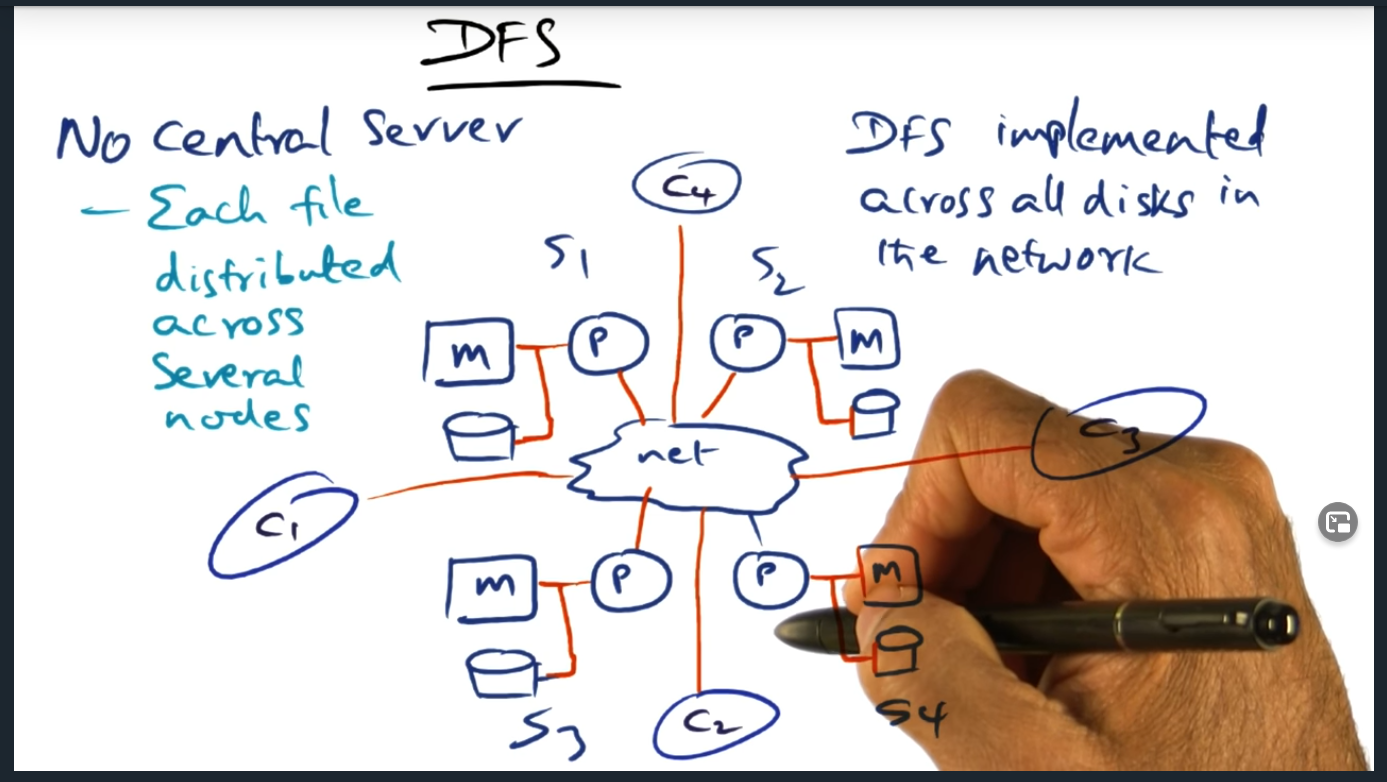
This lesson introduces network file system (NFS) and presents the problems with it, bottlenecks including limited cache and expensive input/output (I/O) operations. These problems motivate the need for a distributed file system, in which there is no longer a centralized server. Instead, there are multiple clients and servers that play various roles including serving data
Quiz
Key Words: computer science history
Sun built the first ever network file system back in 1985
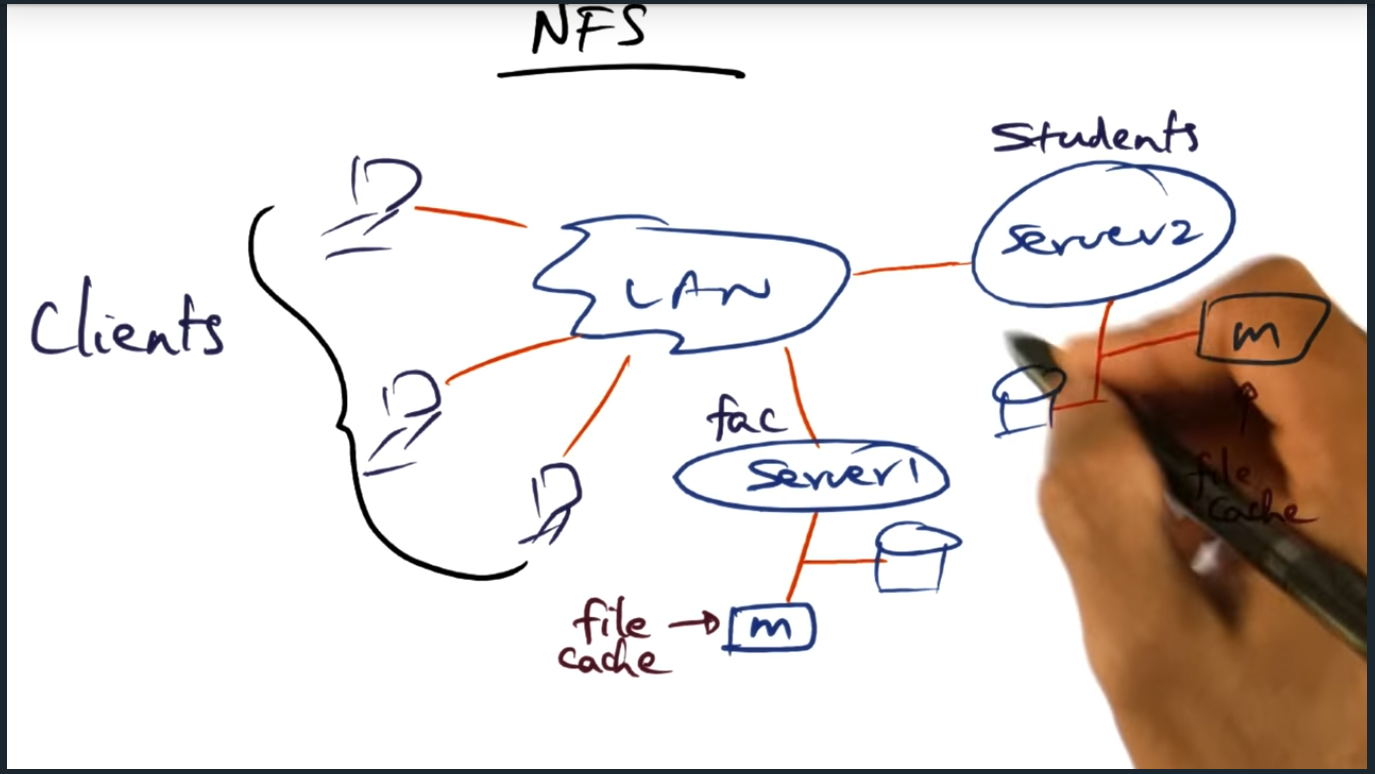
NFS (network file system)
NFS – clients and server
Key Words: NFS, cache, metadata, distributed file system
A single server that stores entire network file system will bottle neck for several reasons, including limited cache (due to memory), expensive I/O operations (for retrieving file metadata). So the main question is this: can we somehow build a distributed file system?
DFS (distributed file system)
Distributed File Server – each file distributed across several nodes
Key Words: Distributed file server
The key idea here is that there is no longer a centralized server. Moreover, each client (and server) can play the role of serving data, caching data, and managing files
Lesson Outline
Key Words: cooperative caching, caching, cache
We want to cluster the memory of all the nodes for cooperative caching and avoid accessing disk (unless absolutely necessary)
Preliminaries (Striping a file to multiple disks)
Key Words: Raid, ECC, stripe
Key idea is to write files across multiple disks. By adding more disks, we increase the probability of failure (remember computing those failures from high performance computing architecture?) so we introduce a ECC (error correcting) disk to handle failures. The downside of striping is that it’s expensive, not just in cost (per disk) but expensive in terms of overhead for small files (since a small file needs to be striped across multiple disks)
Preliminaries
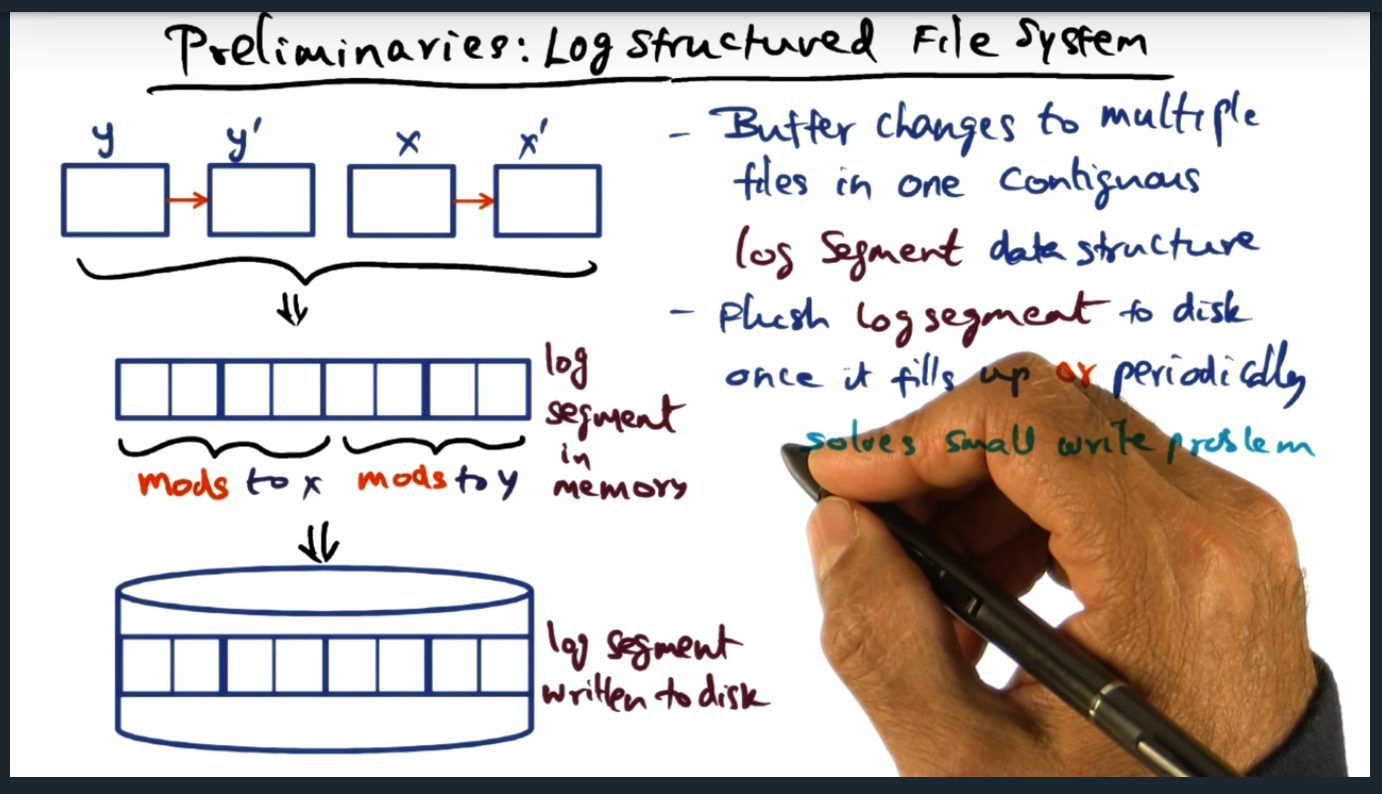
Preliminaries: Log structured file system
Key Words: Log structured file system, log segment data structure, journaling file system
In a log structured file system, the file system will store changes to a log segment data structure, the file system periodically flushing the changes to disk. Now, anytime a read happens, the file is constructed and computed based off of the delta (i.e. logs). The main problem this all solves is the small file problem (the issue with striping across multiple disks using raid). With log structure, we now can stripe the log segment, reducing the penalty of having small files
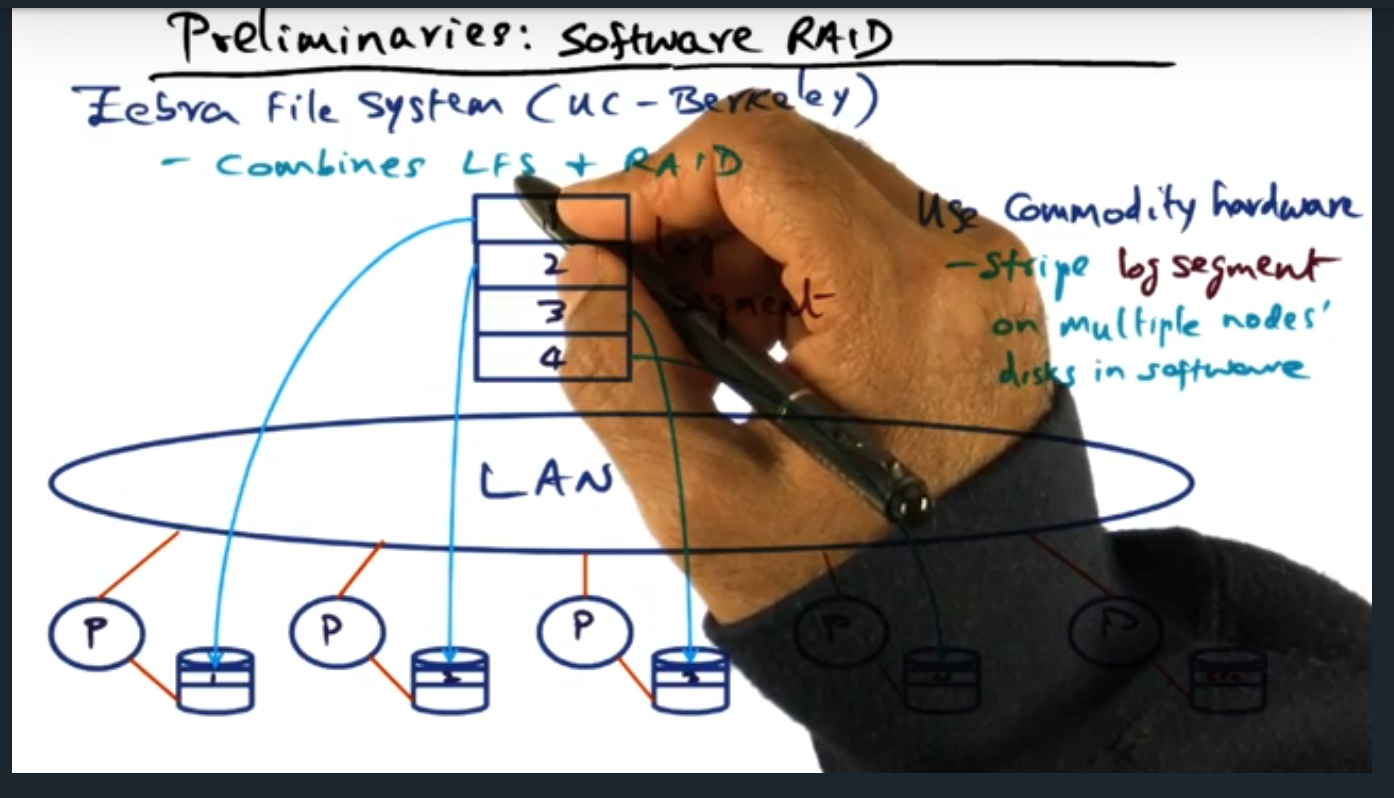
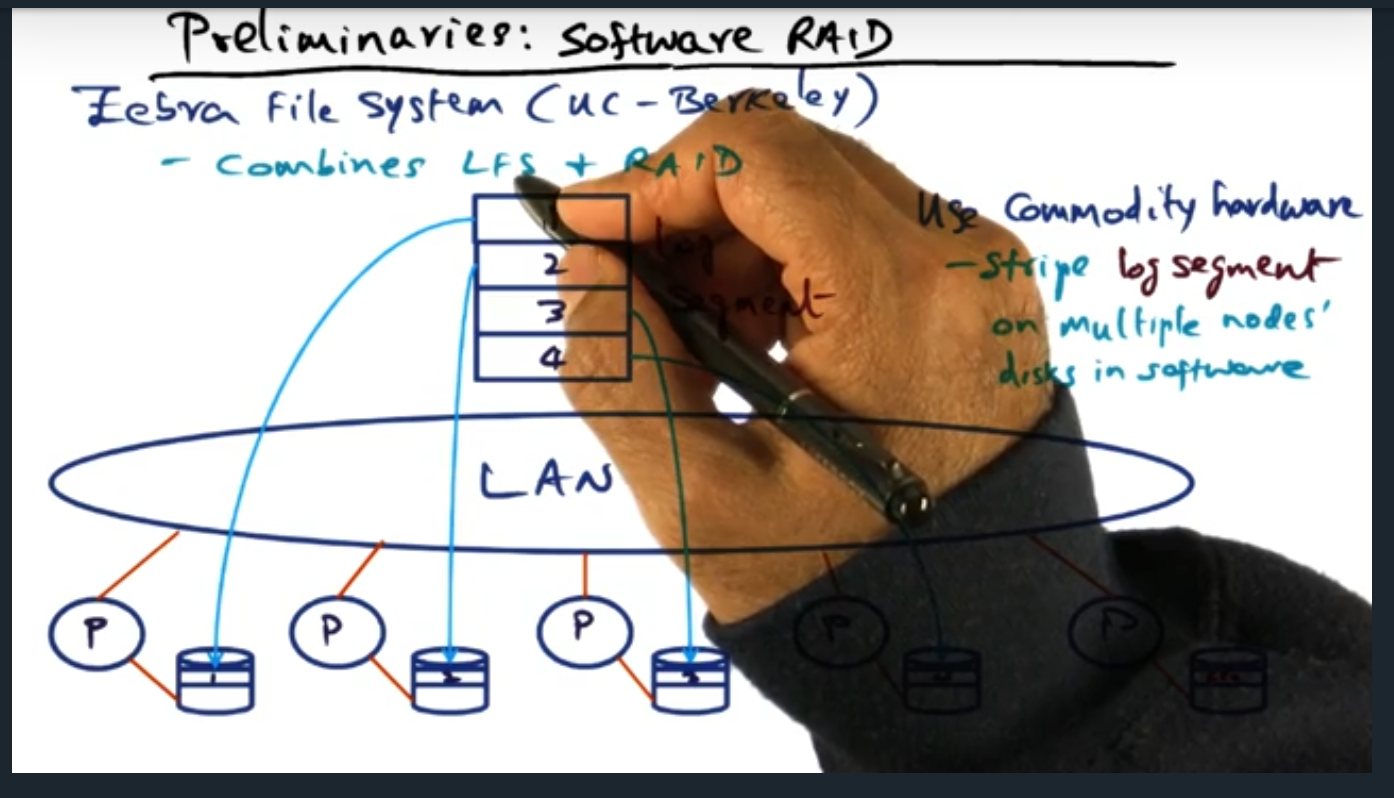
Preliminaries Software (RAID)
Preliminaries – Software Raid
Key Words: zebra file system, log file structure
The zebra file system combines two techniques for handling failures: log file structure (for solving the small file problem) and software raid. Essentially, error correction lives on a separate drive
Putting them all together plus more
Pputting them all together: log based, cooperative caching, dynamic management, subsetting, distributed
Key Words: distributed file system, zebra file system
The XFS file system puts all of this together, standing on top of the shoulders who built Zebra and built cooperating caching. XFS also adds new technology that will be discussed in later videos
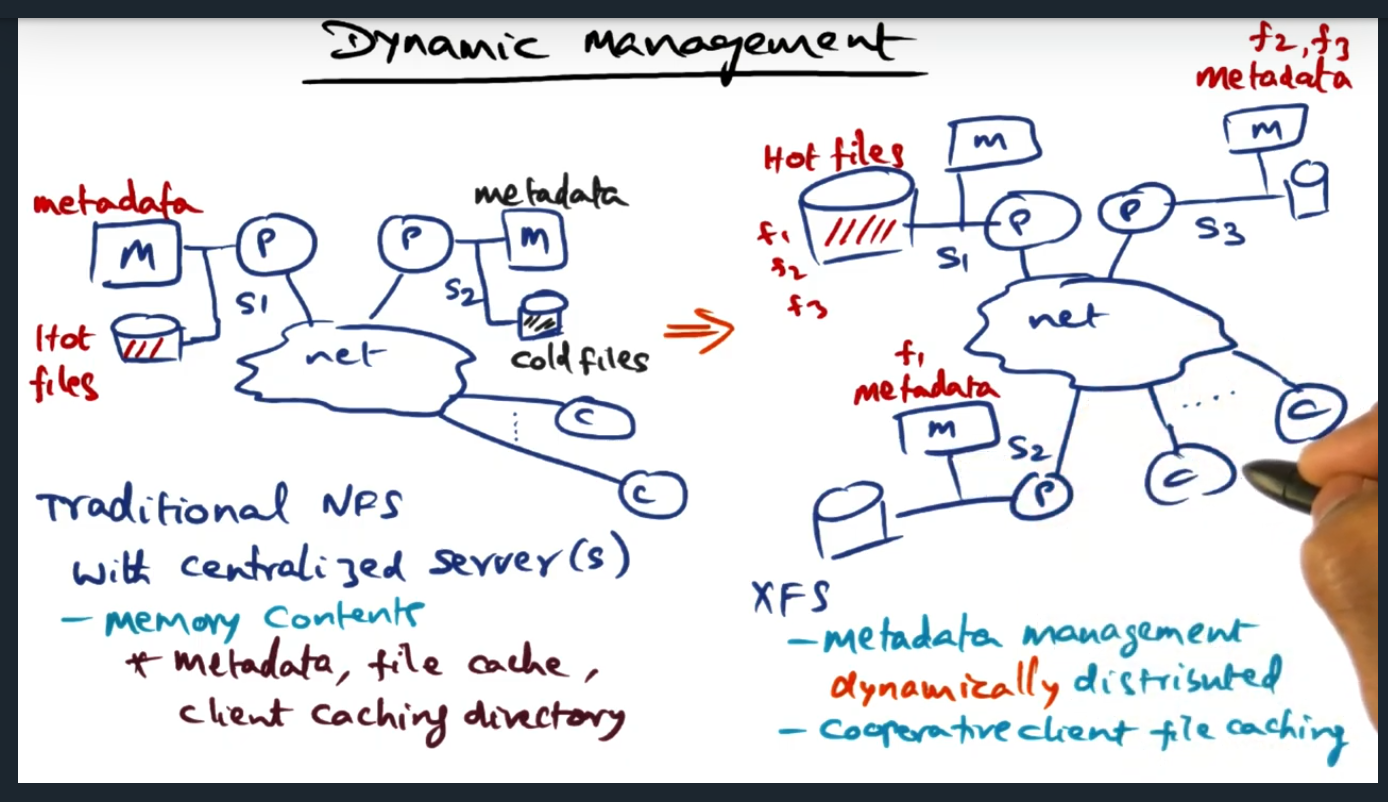
Dynamic Management
Dynamic Management
Key Words: Hot spot, metadata, metadata management
In a traditional NFS server, data blocks reside on disk and memory includes metadata. But in a distributed file system, we’ll extend caching to the client as well
Log Based Striping and Stripe Groups
Log based striping and stripe groups
Key Words: append only data structure, stripe group
Each client maintains its own append only log data structure, the client periodically flushing the contents to the storage nodes. And to prevent reintroducing the small file problem, each log fragment will only be written to a subset of the storage nodes, those subset of nodes called the stripe group
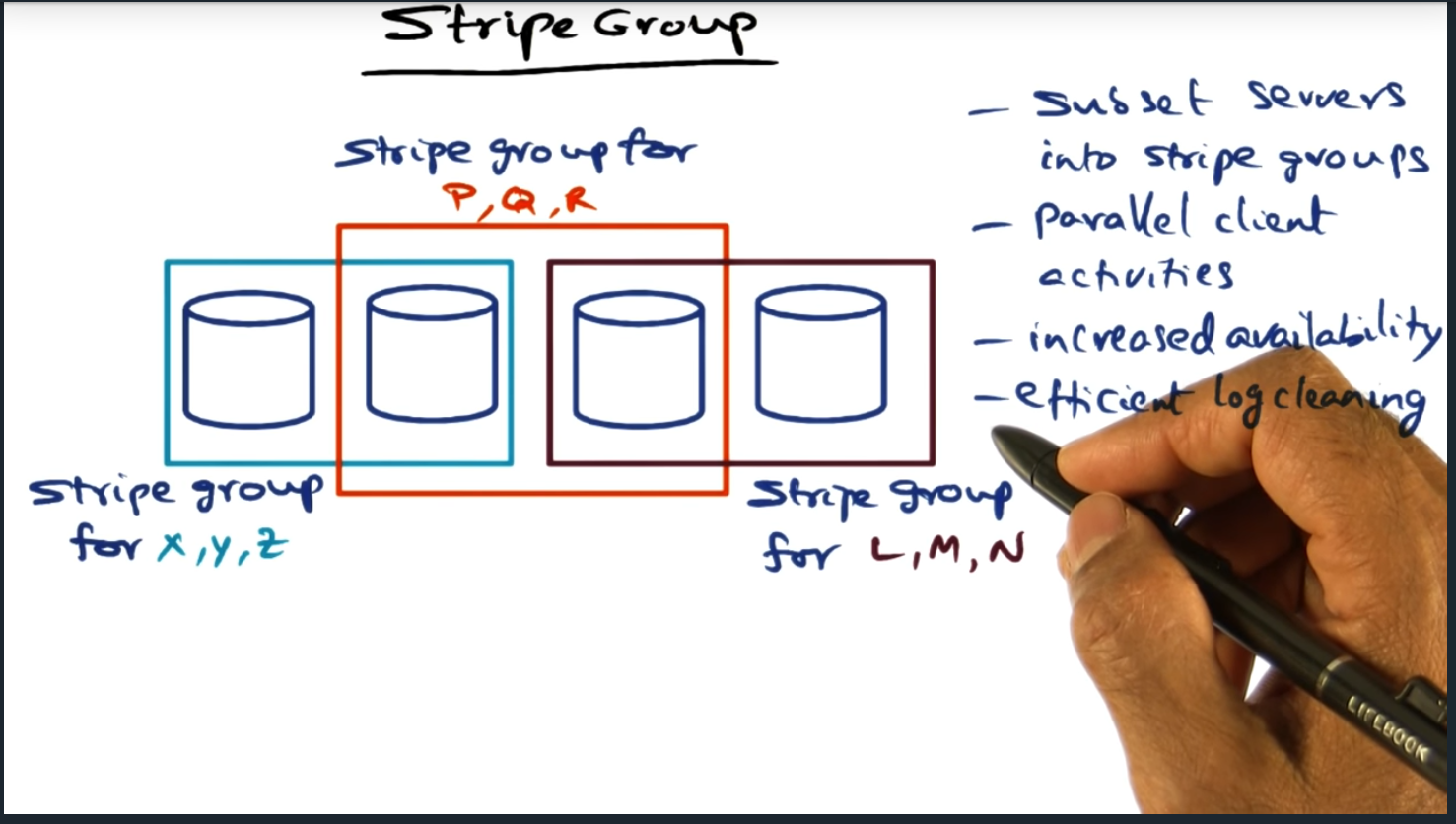
Stripe Group
Stripe Group
Key Words: log cleaning
By dividing the disks into stripe groups, we promote parallel client activities and increases availability
Cooperating Caching
Cooperative Caching
Key Words: coherence, token, metadata, state
When a client requests to write (to a block), the manager (who maintains state, in the form of metadata, about each client) will cache invalidate the clients and grant the writer a token to write for a limited amount of time
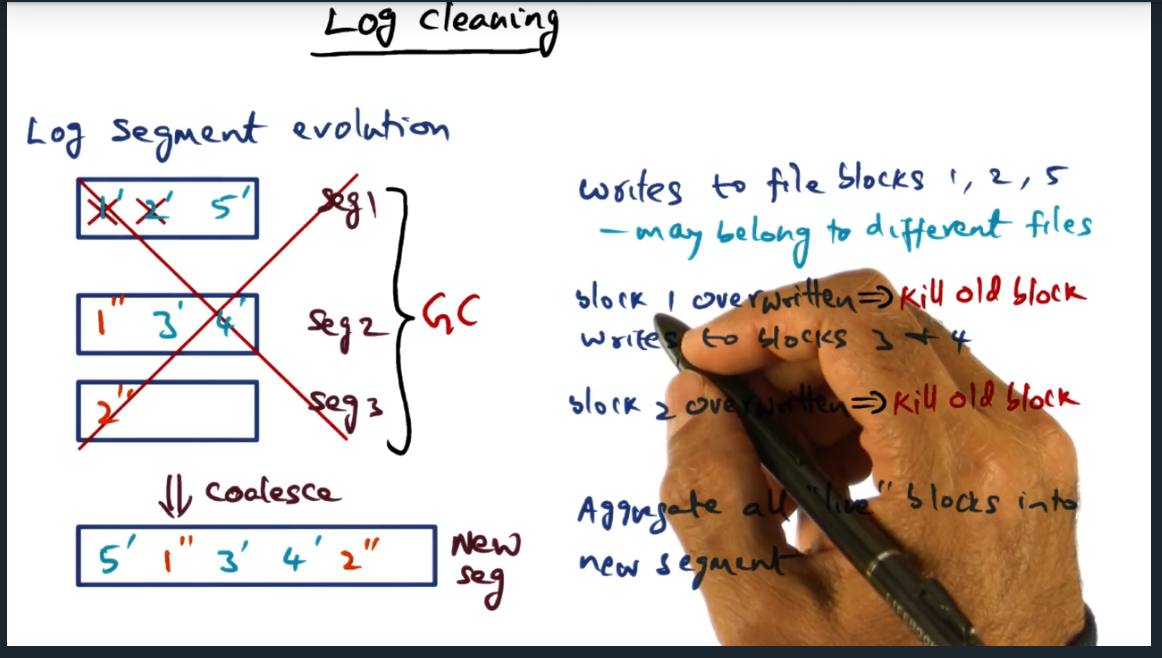
Log Cleaning
Log Cleaning
Key Words: prime, coalesce, log cleaning
Periodically, node will coalesce all the log segment differences into a single, new segment and then run a garbage collection to clean up old segments
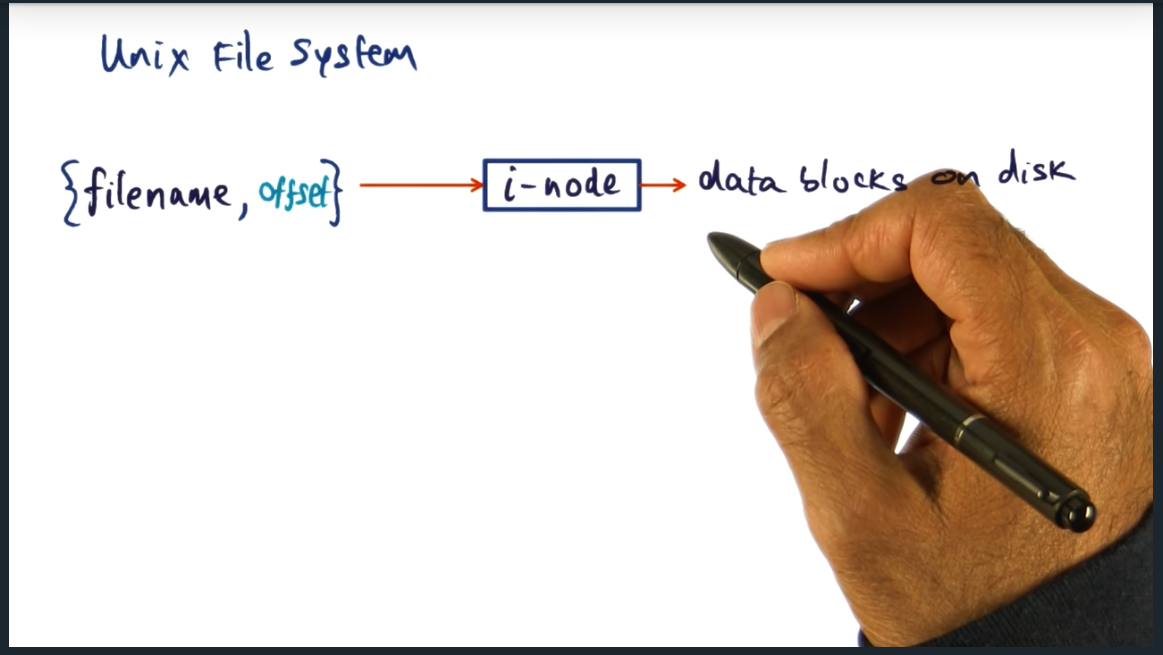
Unix File System
Unix File System
Key Words: inode, mapping
On any unix file system, there are inodes, which map filenames to data blocks on disk
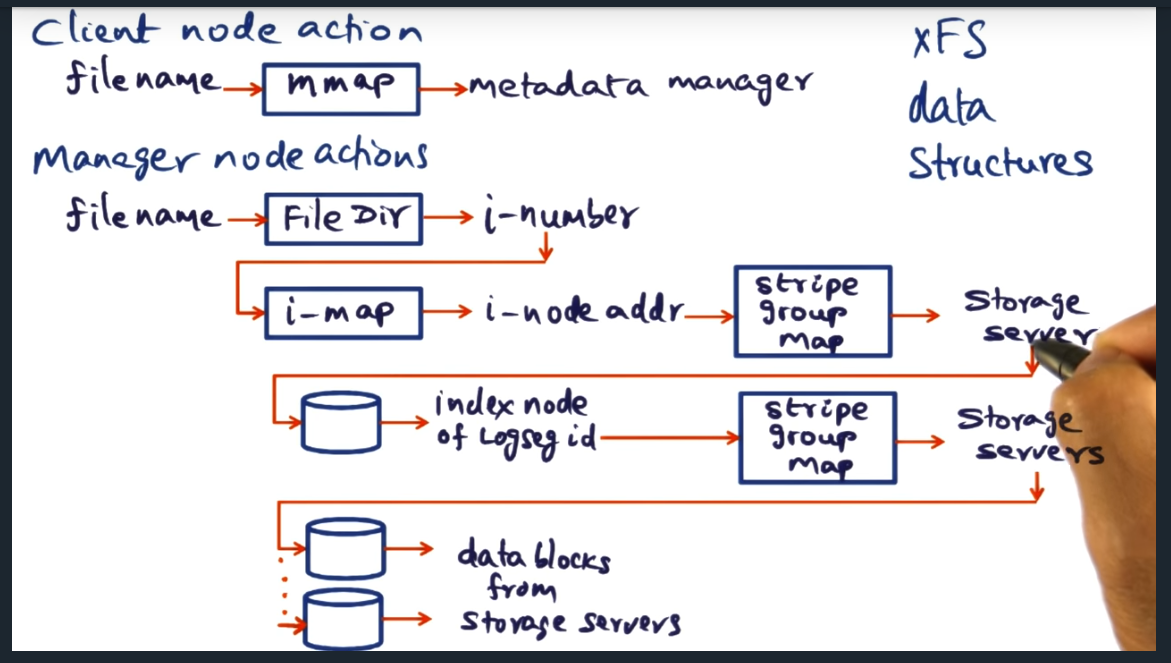
XFS Data Structures
XFS Data Structures
Key Words: directory, map
Manager node maintains data structures to map a filename to the actual data blocks from the storage servers. Some data structures include the file directory, and i_map, and stripe group map
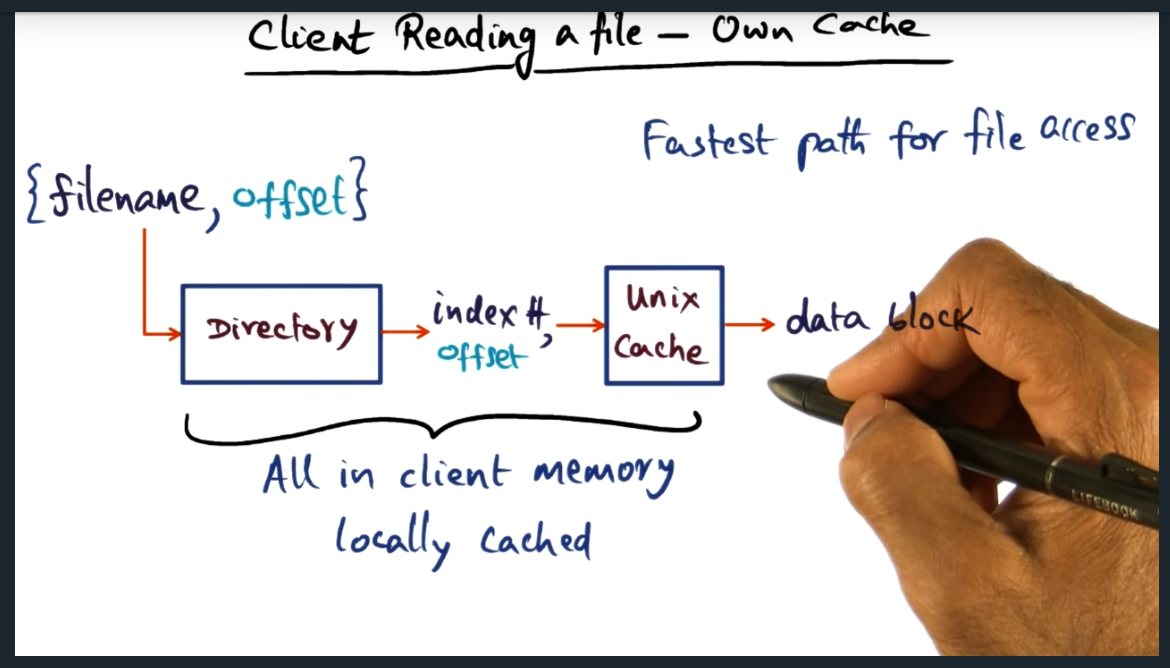
Client Reading a file own cache
Client Reading a file – own cache
Key Words: Pathological
There are three scenarios for client reading a file. The first (i.e. best case) is when the data blocks sit in the unix cache of the host itself. The second scenario is the client querying the manager, and the manager signals another peer to send its cache (instead of retrieving from disk). The worst case is the pathological case (i.e. see previous slide) where we have to go through the entire road map of talking to manager, then looking up metadata for the stripe group, and eventually pulling data from the disk
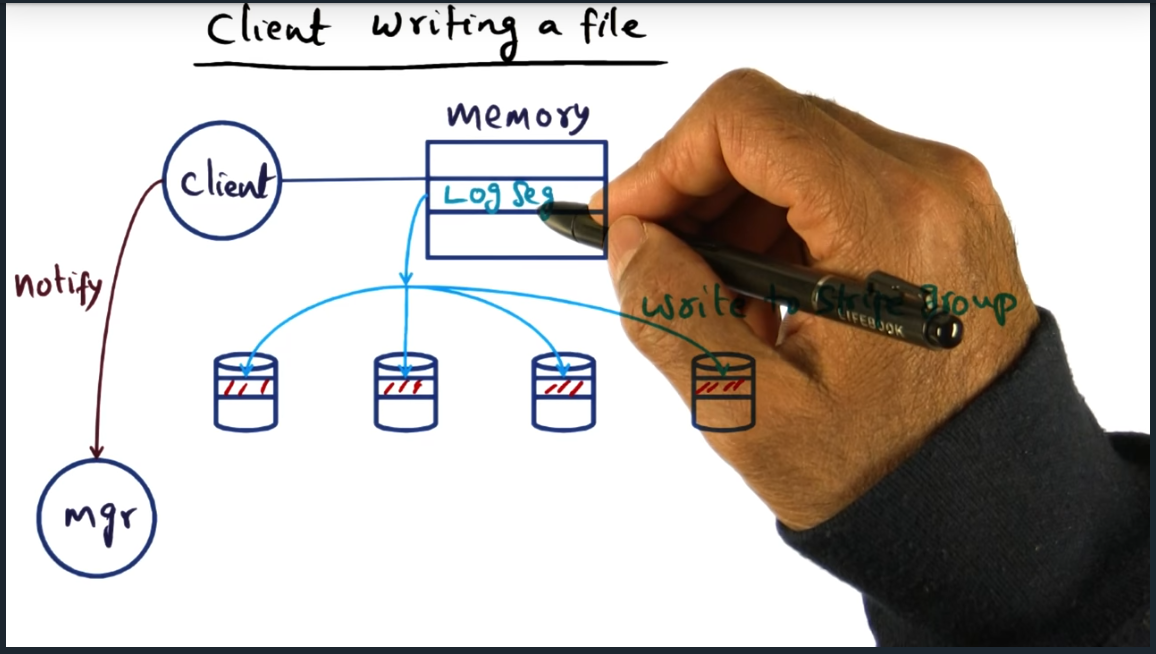
Client Writing a File
Client Writing a file
Key Words: distributed log cleaning
When writing, client will send updates to its log segments and then update the manager (so manager has up to date metadata)
Conclusion
Techniques for building file systems can be reused for other distributed systems
in the concrete example (screenshot below), P1 instructions that update memory (e.g. flag = 1) can be run in parallel with that of P2 because of release consistency model
Advantage of RC over SC
Summary
In a nutshell, we gain performance in a shared memory model using release consistency by overlapping computation with communication, because we no longer wait for coherence actions for every memory access
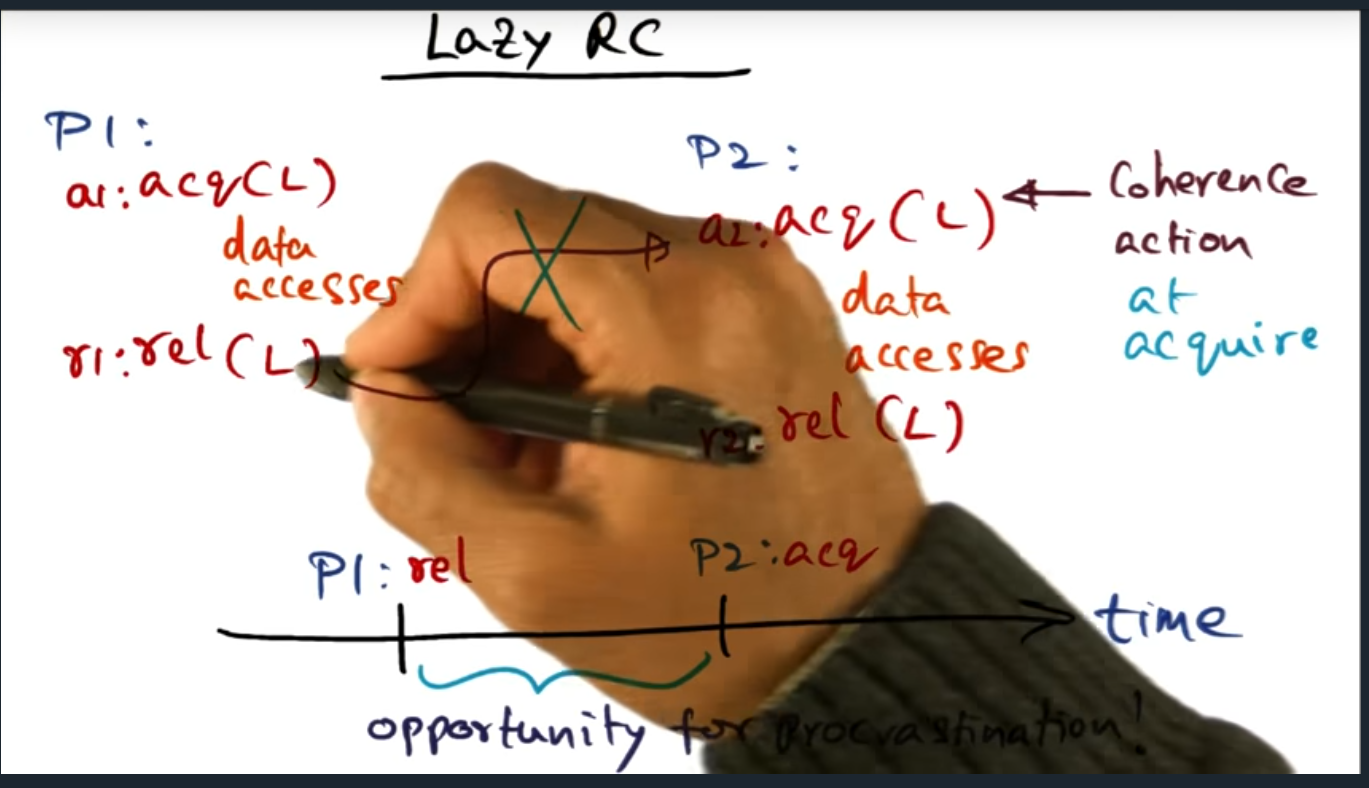
Lazy RC (release consistency)
Lazy Release Consistency
Summary
Key Words: Eager
The main idea here is that the “release consistency” is eager, in the sense that cache coherence traffic is generated immediately after unlock occurs. But with lazy RC, we defer that cache coherence traffic until the acquisition
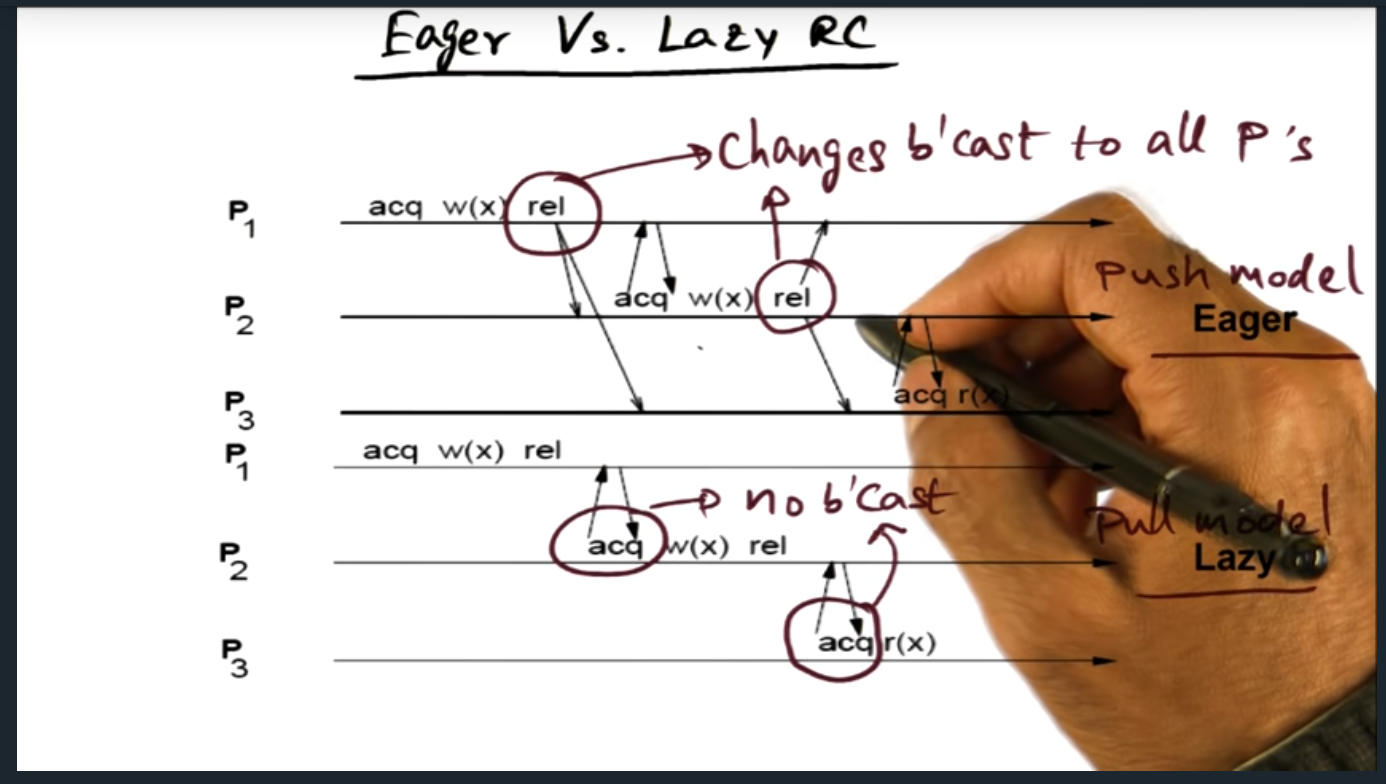
Eager vs Lazy RC
Eager vs Lazy Consistency
Summary
Key Words: Eager, Lazy
Basically, eager and lazy goes boils down to a push (i.e. eager) versus pull (i.e. lazy) model. In the former, every time the lock is released, coherence traffic broadcasts to all other processes
Pros and Cons of Lazy and Eager
Summary
Advantage of lazy (over eager) is that there are less messages however there will be more latency during acquisition
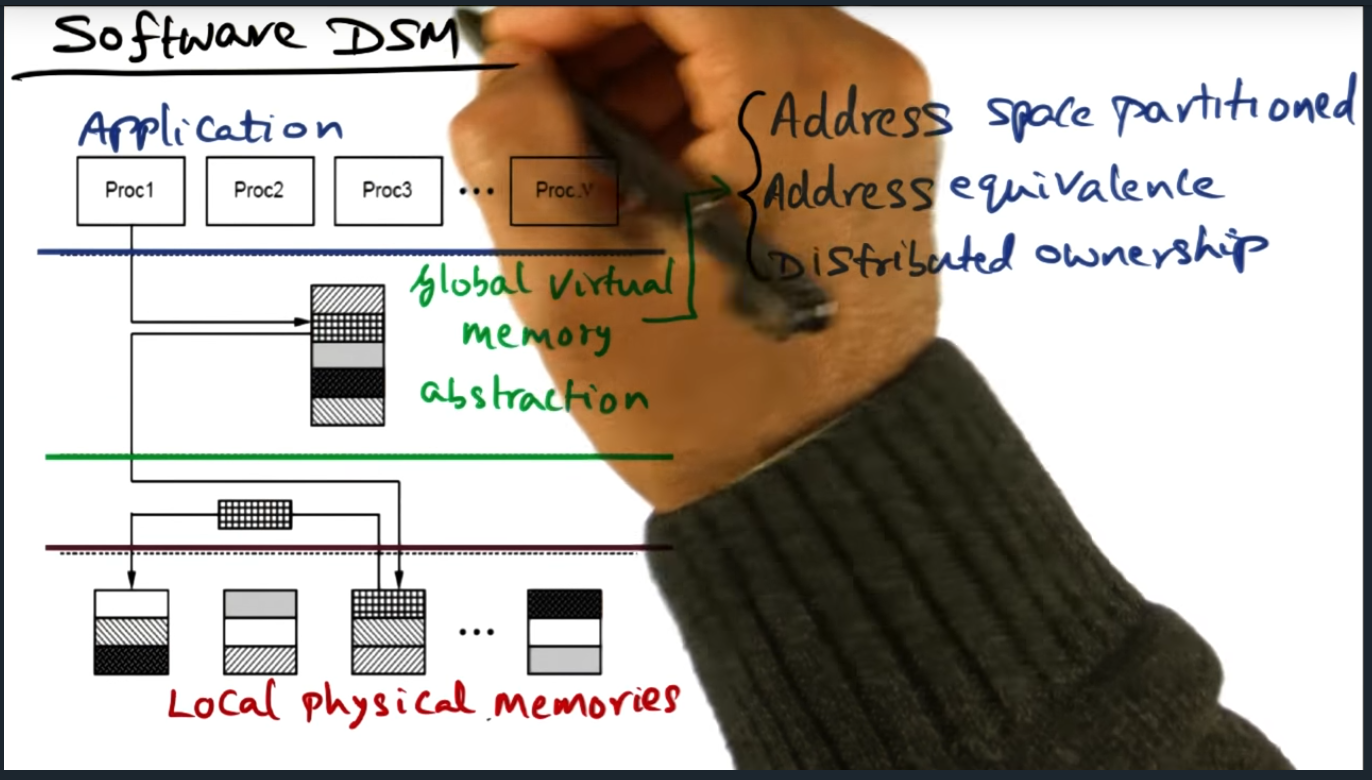
Software DSM
Software DSM
Summary
Address space is partitioned, meaning each processor is responsible for a certain set of pages. This model of ownership is a distributed, and each node holds metadata about the page and is responsible for sending coherence traffic (at the software level)
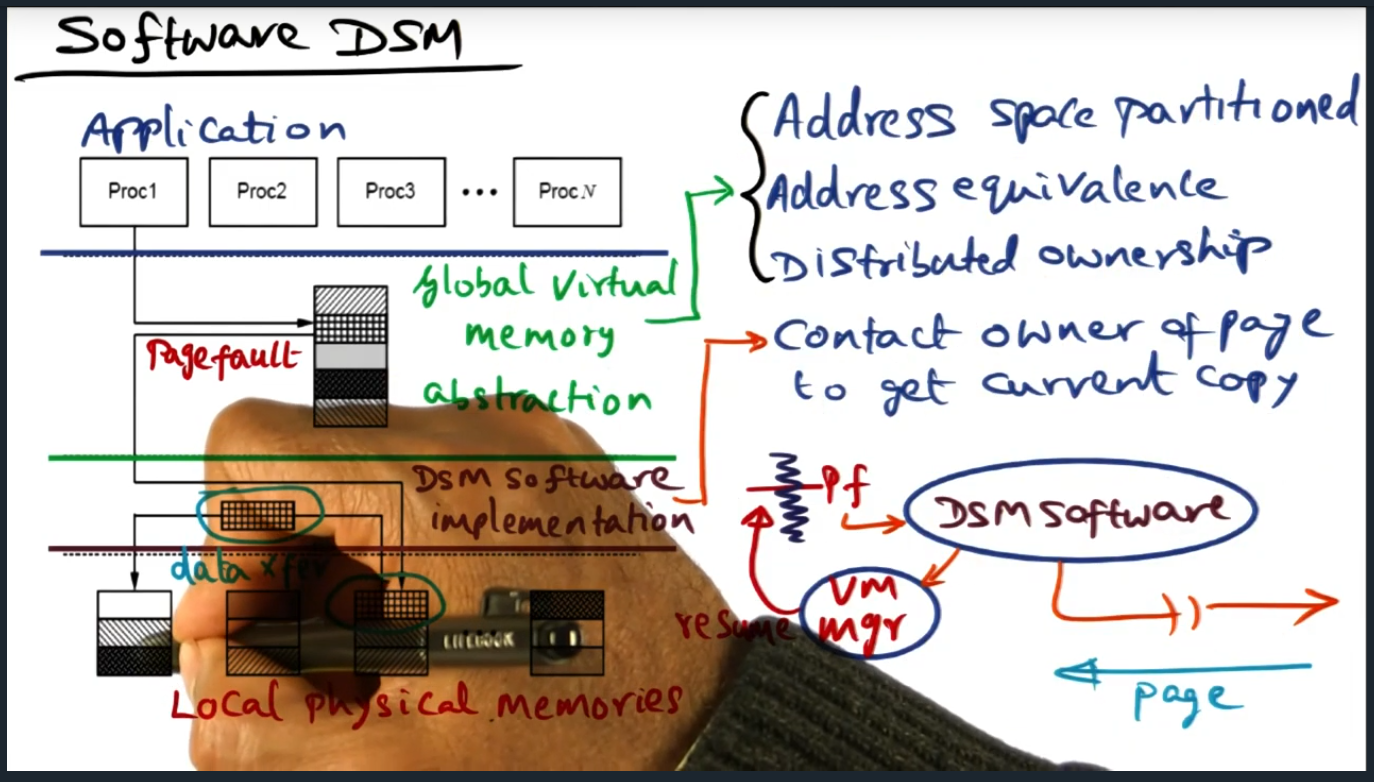
Software DSM (Continued)
Software DSM (continued)
Summary
Key Words: false sharing
DSM software runs on each processor (cool idea) in a single writer multiple reader model. This model can be problematic because, coupled with false sharing, will cause significant bus traffic that ping pongs updates when multiple data structures live within the same cache line (or page)
LRC with Mutli-Writer Coherence Protocol
Lazy Release Consistency with multi-writer coherence
Summary
With lazy release consistency, a process will (during the critical section) generate a diff of the pages that have been modified, the diff later applied when another process performs updates to those same pages
LRC with Multi-Writer Coherence Protocol (Continued)
Summary
Need to be able to apply multiple diffs in a row, say Xd and Xd’ (i.e. prime)
LRC with Multi Writer Coherence Protocol (Continued)
Summary
Key Words: Multi-writer
The same page can be modified at the same time by multiple threads, just so as long as a separate lock is used
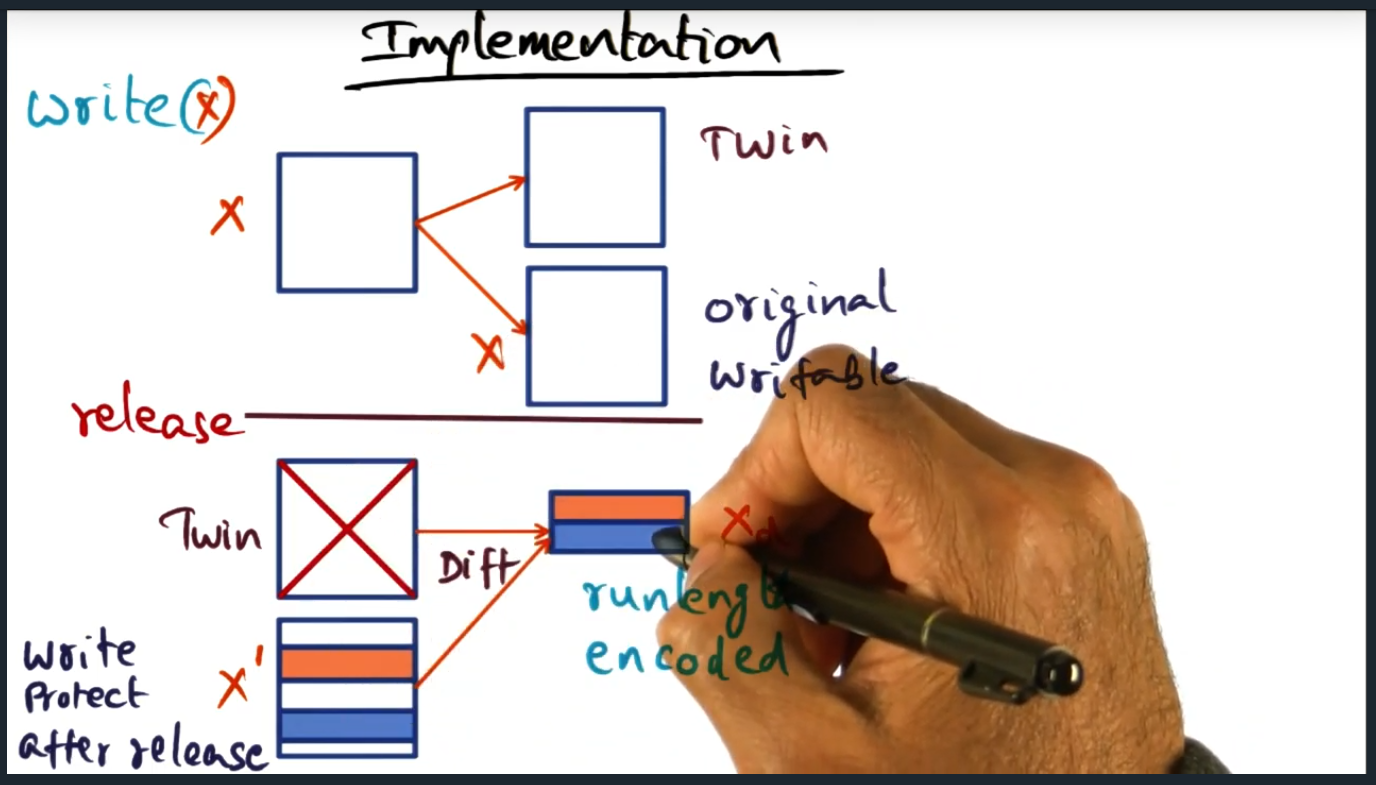
Implementation
Implementation of LRC
Summary
Key Words: Run-length encoded
During a write operation (inside of a lock), a twin page will get created, essentially a copy of the original page. Then, during release, a run-length encoded diff is computed. Following this step, the memory access is then write protected
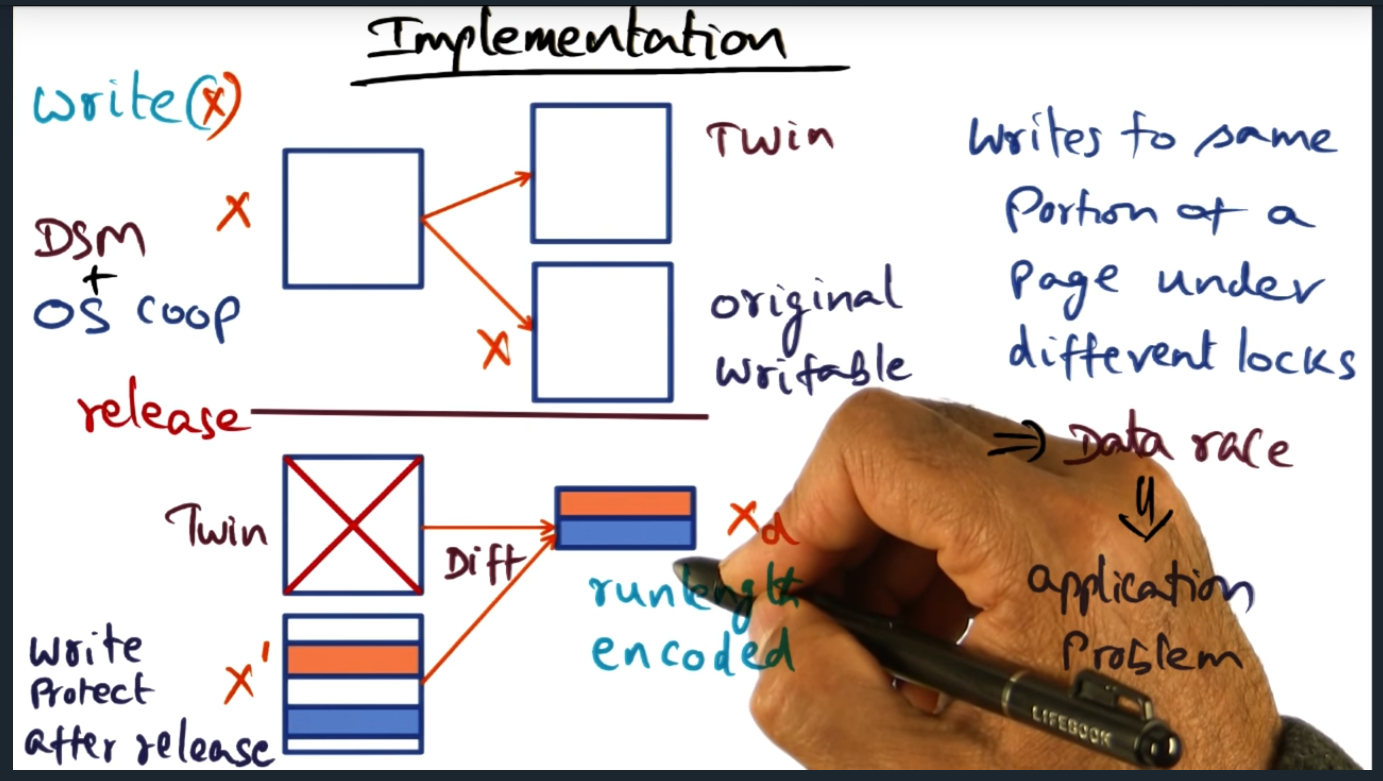
Implementation (continued)
LRC Implementation (Continued)
Summary
Key Words: Data Race, watermark, garbage collection
A daemon process (in every node) wakes up periodically and if the number of diffs exceed the watermark threshold, then daemon will apply diffs to original page. All in all, keep in mind that there’s overhead involved with this solution: overhead with space (for the twin page) and overhead in runtime (due to computing the run-length encoded diff)
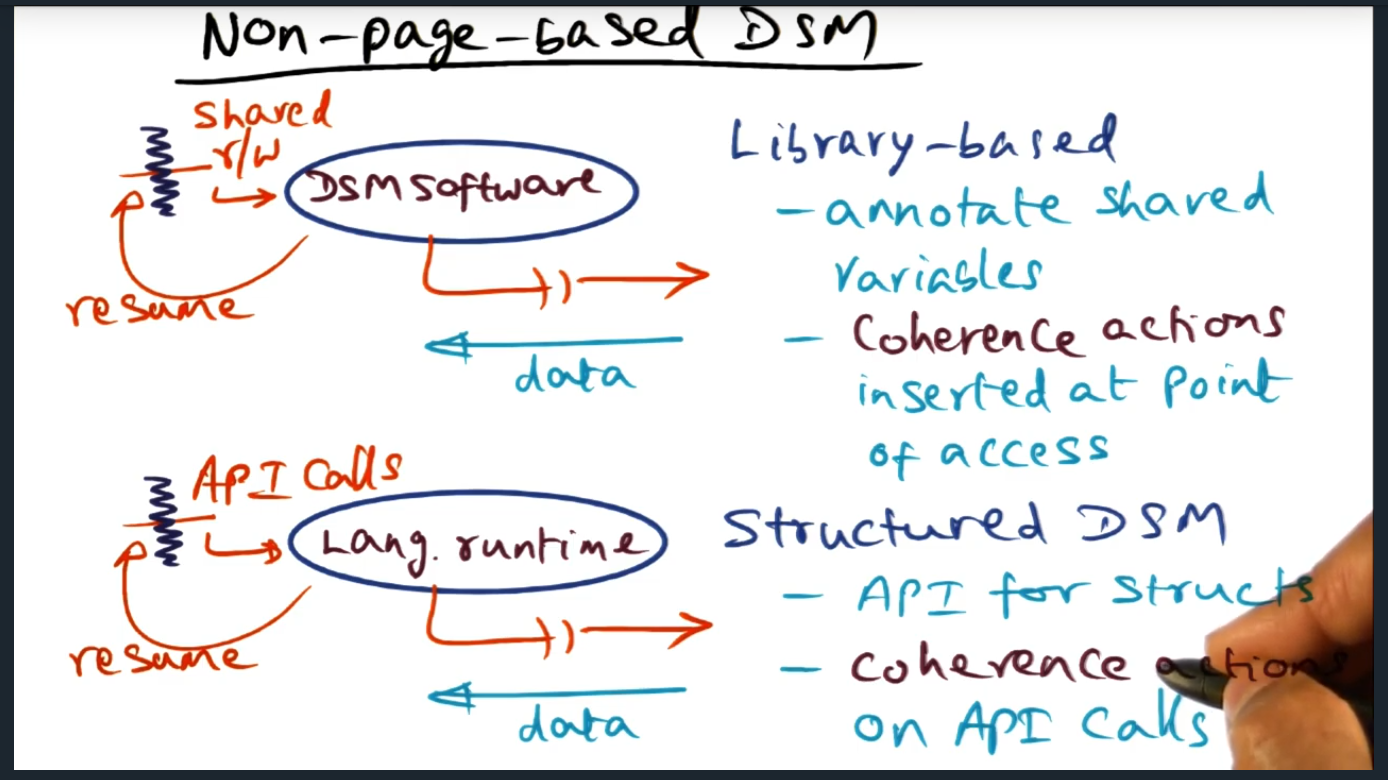
Non Page Based DSM
Non-page-based DSM
Summary
Two types of library based that offer alternatives, both that do not require OS support. The two approaches are library-based (variable granularity) and structured DSM (API for structures that triggers coherence actions)
Scalability
Scalability
Summary
Do our (i.e. programmer’s) expectations get met as the number of processors increase: does performance increase accordingly as well? Yes, but there’s substantial overhead. To be fair, the same is true with true shared memory multiple processor
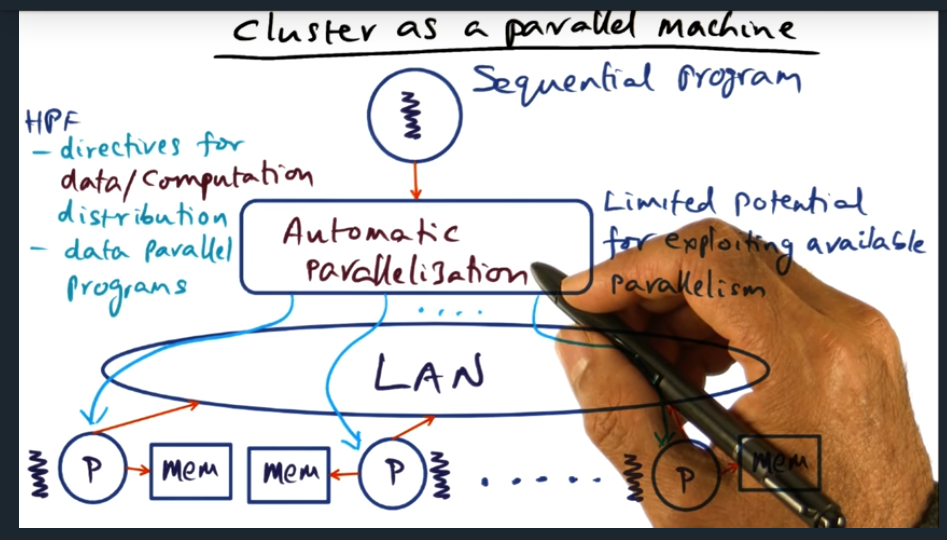
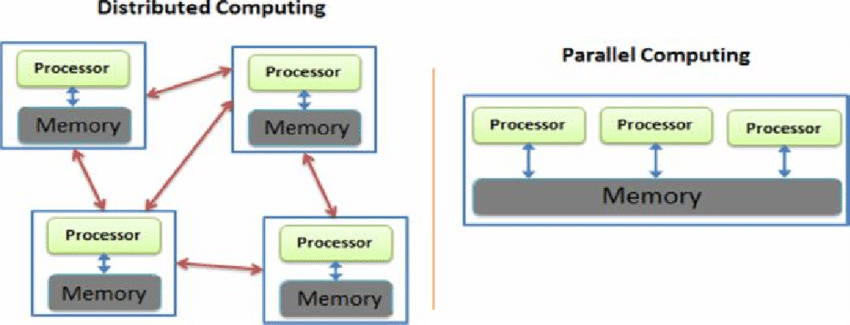
Main question is this: can we make a cluster look like a shared memory machine
Cluster as a parallel machine (sequential program)
Cluster as a parallel machine
Summary
One strategy is to not write explicit parallel programs and instead use language assisted features (like pragma) that signal to the compiler that this section be optimized. But, there are limitations with this implicit approach
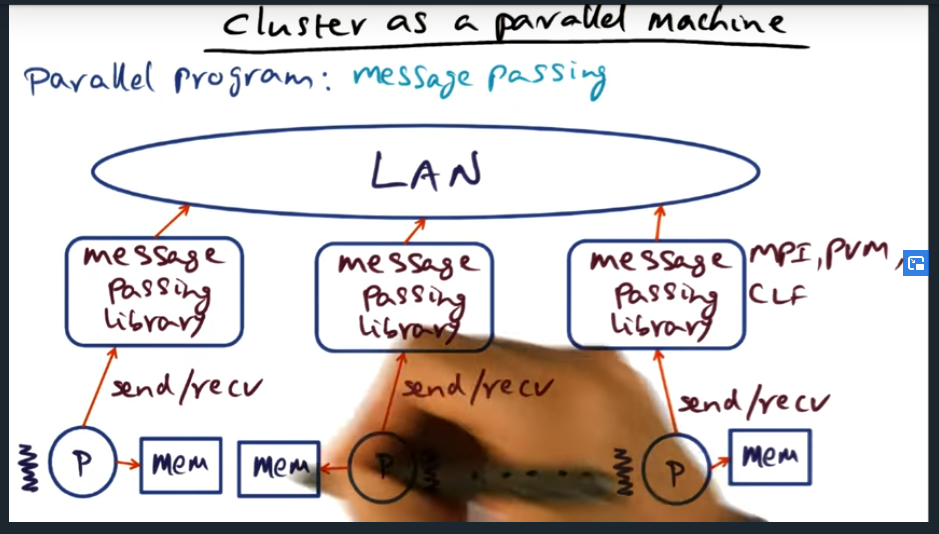
Cluster as a parallel machine (message passing)
Cluster as parallel machine (message passing)
Summary
Key Words: message passing
One (of two) styles for explicitly writing parallel programs is by using message passing. Certain libraries (e.g. MPI, PVM, CLF) use this technique and true to a process’s nature, the process does not share its memory and instead, if the process needs to communicate with another entity, it does so by message passing. The downside? More effort from the perspective of the application developer
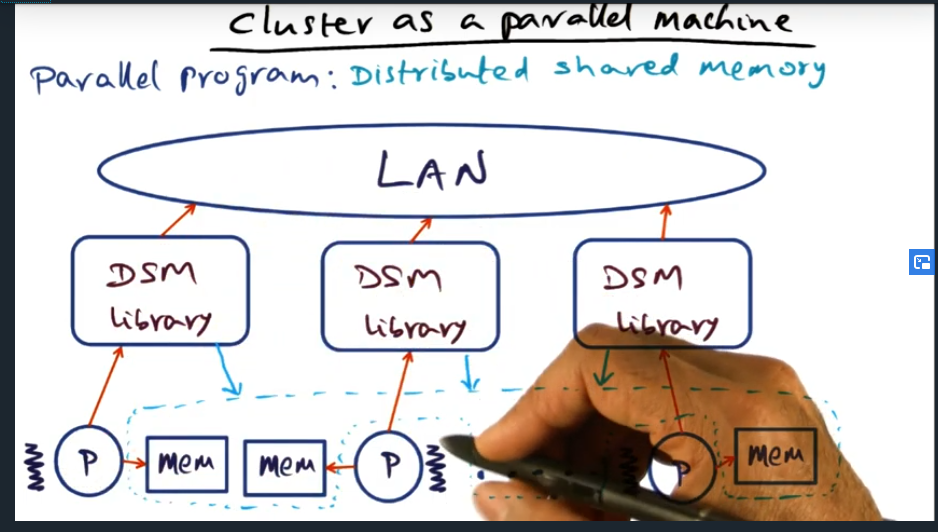
Cluster as a parallel machine (DSM)
Cluster as a parallel machine (parallel program)
Summary
The advantage of a DSM (distributed shared memory) is that an application developer can ease their way in, their style of programming need not change: they can still use locks, barriers, and pthreads styles, just the way they always have. So the DSM library provides this illusion of a large shared memory address space.
History of shared memory systems
History of shared memory systems
Summary
In a nutshell, software DSM has its roots in the 80s, when Ivy league academics wanted to scale the SMP. And now, (in the 2000s), we are looking at clusters of symmetric memory processors.
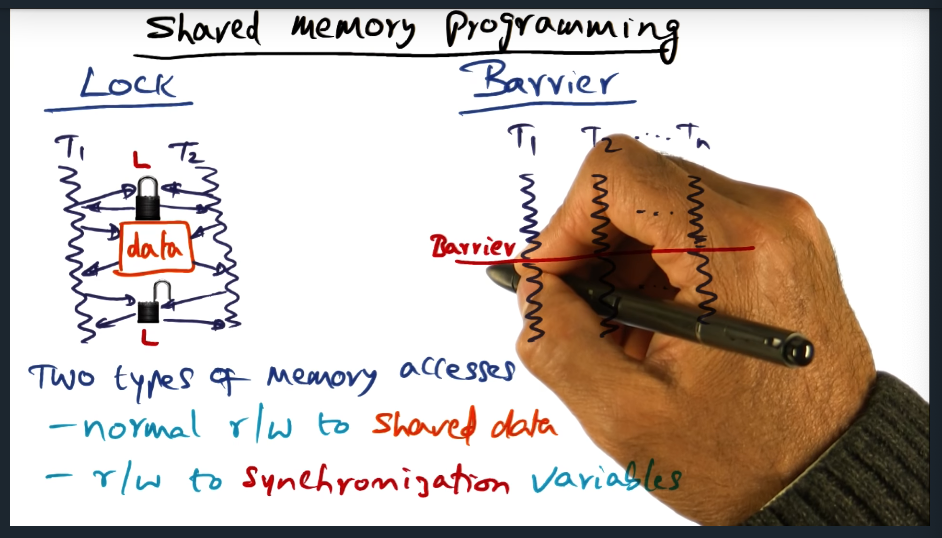
Shared Memory Programming
Shared Memory Programming
Summary
There are two types of synchronization: mutual exclusion and barrier. And two types of memory accesses: normal read/writes to shared data, and read/write to synchronization variables
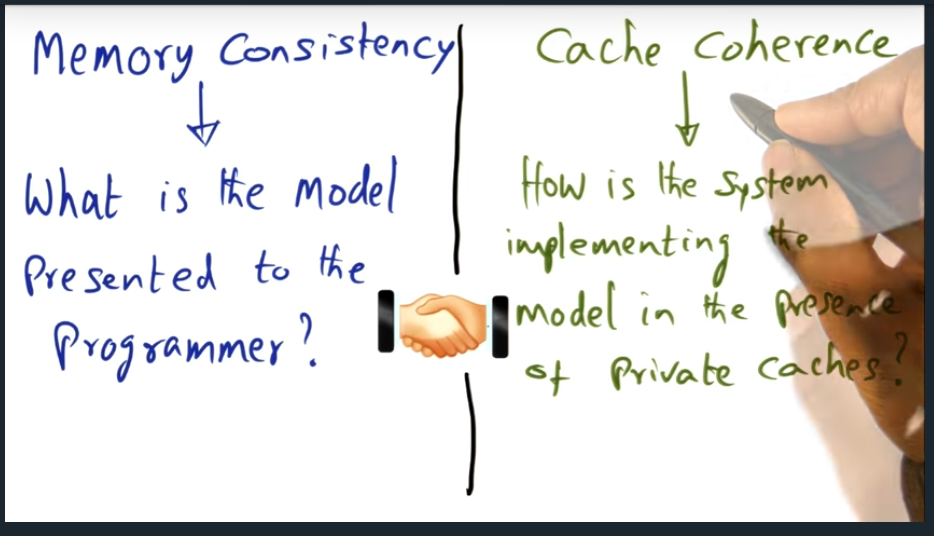
Memory consistency and cache coherence
Memory Consistency vs Cache Coherence
Summary
Key Words: Cache Coherence, Memory consistency
Memory consistency is the contract between programmer and the system and answers the question “when”: when will a change to the shared memory address space reflect in the other process’s private cache. And cache coherence answers the “how”, what mechanism will be used (cache invalidate or write update)
Sequential Consistency
Sequential Consistency
Summary
Key Words: Sequential Consistency
With sequential consistency, program order is respected, but there’s arbitrary interleaving. Meaning, each individual read/write operations are atomic on any processor
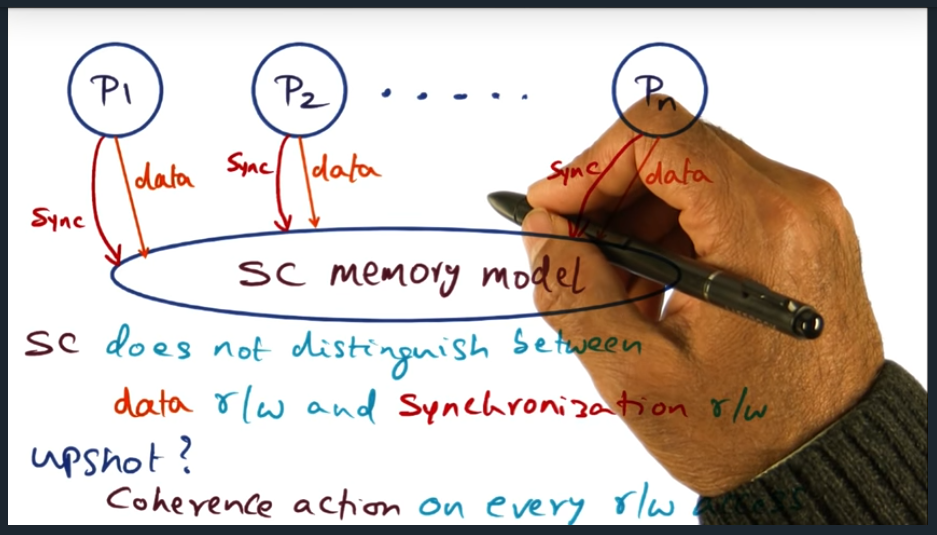
SC Memory Model
Sequential Consistency Model
Summary
With sequential consistency, the memory model does not distinguish a read/write access to a synchronization read/write access. Why is this important? Well, we always get the coherence action, regardless of memory access type
Typical Parallel Program
Typical Parallel Program
Summary
Okay, I think I get the main gist and what the author is trying to convey. Basically, since we cannot distinguish the reads and writes for memory accesses — from normal read/write versus synchronization read/write — then that means (although we called it out as a benefit earlier) cache coherence will continue to take place all throughout the critical section. But, the downside here is that that coherence traffic, is absolutely unnecessary. And really, what we probably want is that only after we unlock the critical section should the data within that critical section, be updated across all other processor cache
Release Consistency
Release Consistency
Summary
Key Words: release consistency
Release consistency is an alternative memory consistency model to sequential consistency. Unlike sequential consistency, which will block a process until coherence has been achieved for an instruction, release consistency will not block but will guarantee coherence when the lock has been released: this is a huge (in my opinion) performance improvement. Open question remains for me: does this coherence guarantee impact processes that are spinning on a variable, like a consumer
Lessons will be broken down into three modules: GMS (i.e. can we use peer memory for paging across LAN) and DSM (i.e. can we make the cluster appear as a shared memory machine) and DFS (i.e. can we use cluster memory for cooperative caching of files)
Context for Global Memory Systems
Summary
Key Words: working set
Core idea behind GMS is when there’s a page fault, instead of checking disk, check the cluster memory instead. Most importantly, no dirty pages (does not complicate the behavior): the disk always has copies of the pages
GMS Basics
Lesson Outline. GMS – how can we use peer memory for paging across LAN?
Summary
With GMS, a physical node carves out its physical memory into two areas: local (for working set) and global (servicing other nodes as part of being in the “community”). This global cache is analagous to a virtual memory manager in the sense that the GSM does not need to worry about data coherence: that’s the job of the upper applications.
Handling Page Faults Case 1
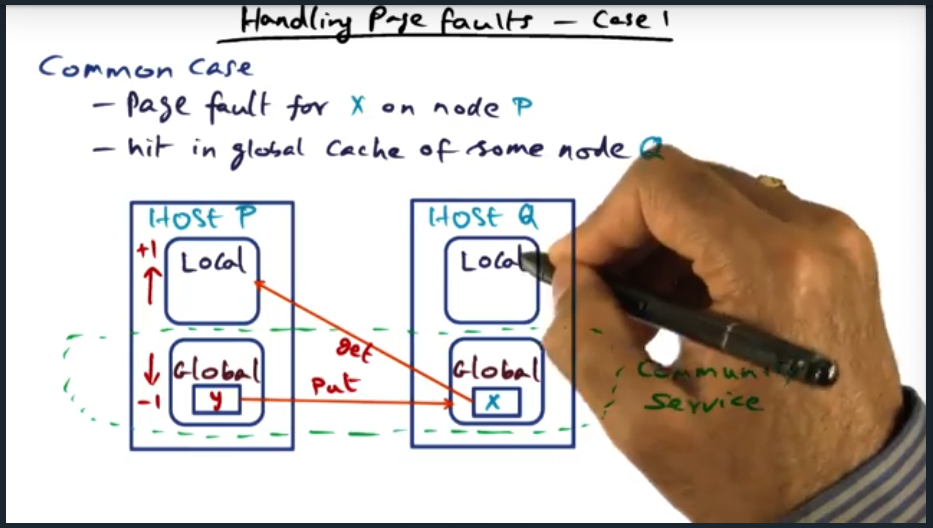
Handling Page Faults (Case 1)
Summary
Most common use case is a page fault on a local node. When the page fault occurs, the node will get the data from some other node’s global cache, increase its local memory footprint by 1 page, and correspondingly decrease its global memory footprint by 1 page.
Handling Page Fault Case 2
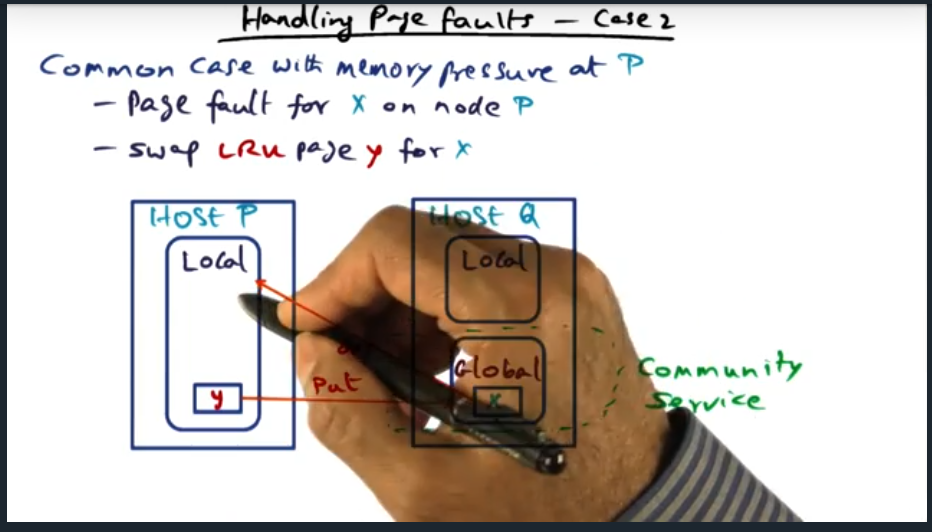
Handling Page Faults (Case 2)
Summary
In the situation which a node has no global memory (i.e. its local memory entirely consumed by working set), then the host handle a page fault by evicting a local page (i.e. finding a victim, usually through LRU page replacement policy), then requesting some page from another node’s global memory (i.e. the community service). What’s important to call out here is that there’s no changes in the number of local pages and no change in the number of global pages for the node.
Handling Page Fault Case 3
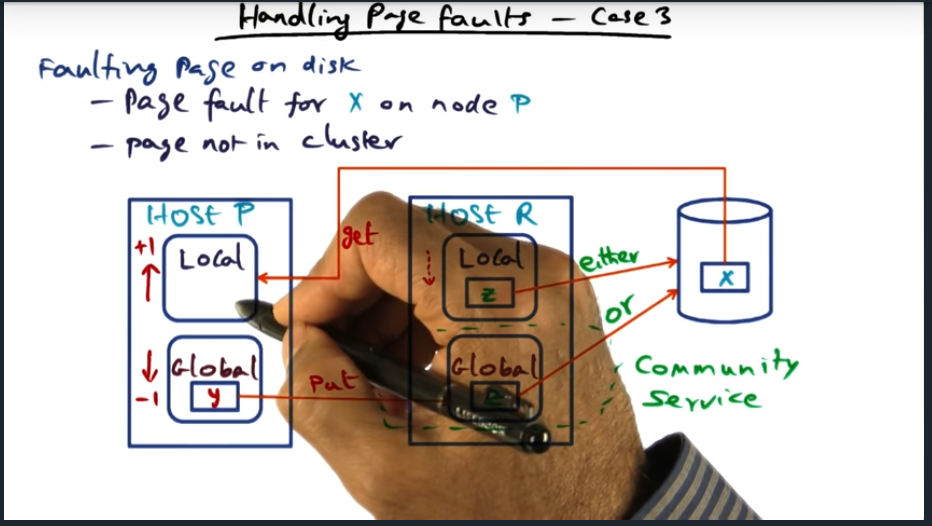
Handling Page Faults (Case 3)
Summary
Key Words: LRU, eviction, page fault
Key Take away here is that if the globally oldest page lives in local memory, then we can free it up and expand the globally available memory for community service. Also, something that cleared up for me is this: all pages sitting in the global memory are considered clean since global memory is just a facility as part of the page faulting process so we can assume all pages are clean. But that’s not true for local pages, meaning, if we evict a page from local memory and its dirty, we must first write it out to disk
Handling Page Faults Case 4
Handling Page Faults (Case 4)
Summary
This is a tricky scenario, the only scenario in which a page lives in the working set on two nodes simultaneously.
Local and Global Boundary Quiz
Local and Global Boundary Quiz
Summary
Difficult quiz, actually. On Disk is not applicable for Node Q with Page X. And depends what happens with globally LRU (least recently used) stored in local, or global, part.
Behavior of Algorithm
Summary
Basically, if there’s an idle node, its main responsibility will be accommodating peer pages. But once the node becomes busy, it will move pages into its working set
Lamport’s theories provided deterministic execution for non determinism exists due to vagaries of the network. Will discuss techniques to make OS efficient for network communication (interface to kernel and inside the kernel network protocol stack)
Latency Quiz
Summary
What’s the difference between latency and throughput. Latency is 1 minute and throughput is 5 per minute (reminds of me pipelining from graduate introduction to operating systems as well as high performance computing architecture). Key idea: throughput is not the inverse of latency.
Latency vs Throughput
Summary
Key Words: Latency, Throughput, RPC, Bandwidth
Definitions of latency is elapsed time for event and throughput are the number of events per unit time, measured by bandwidth. As OS designers, we want to limit the latency for communication
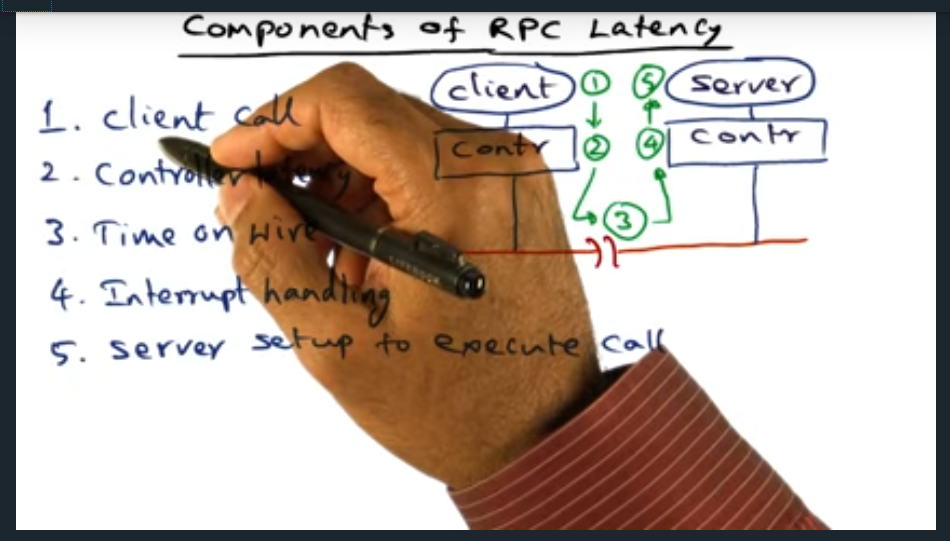
Components of RPC Latency
The five components of RPC: client call, controller latency, time on wire, interrupt handling, server setup to execute call
Summary
There are five sources of latency with RPC: client call, controller latency, time on wire, interrupt handling, server setup and execute call (and then the same costs in reverse, in the return path)
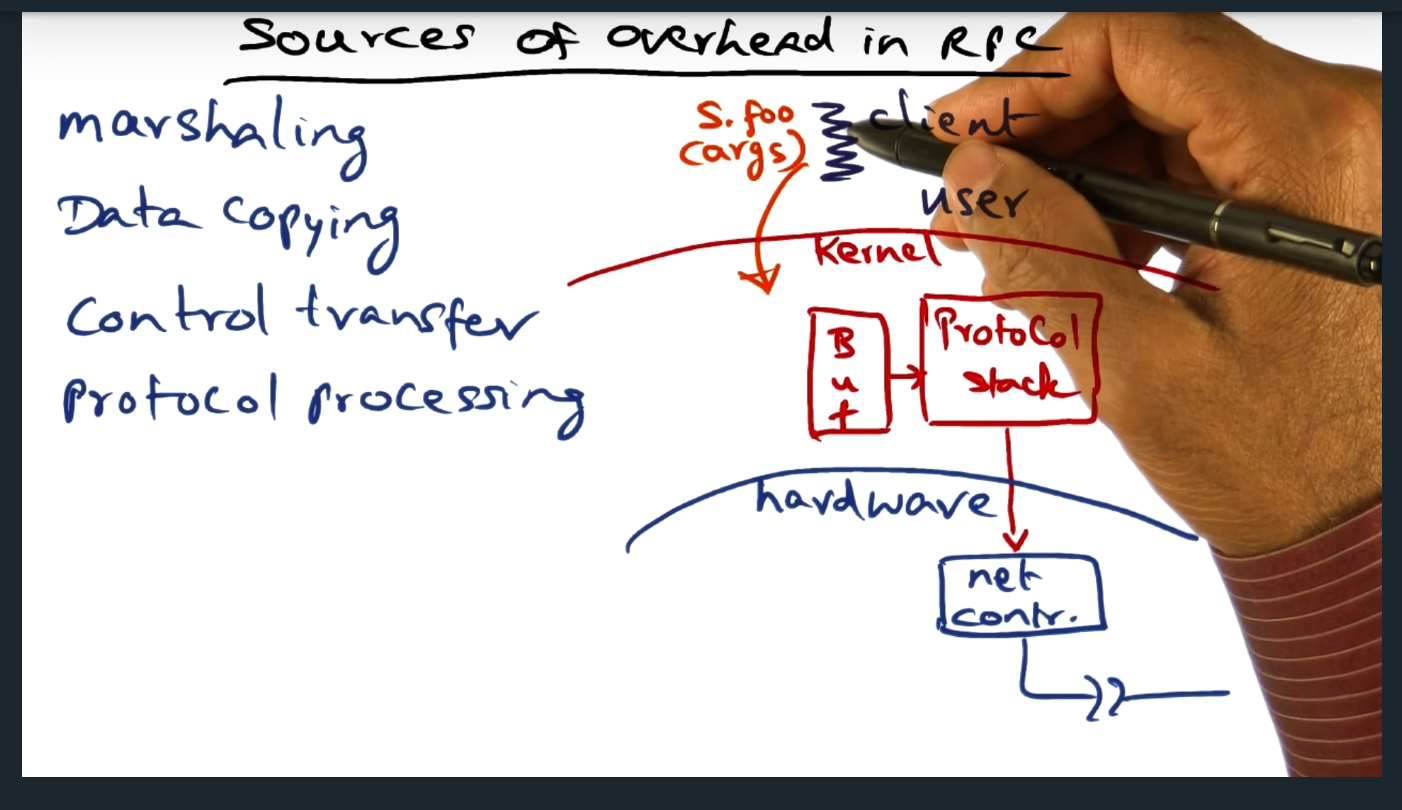
Sources of Overhead on RPC
Sources of overhead include: marshaling, data copying, control transfer, protocol processing
Summary
Although the client thinks the RPC call looks like a normal procedure, there’s much more overhead: marshaling, data copying, control transfer, protocol processing. So, how do we limit the overhead? By leveraging hardware (more on this next)
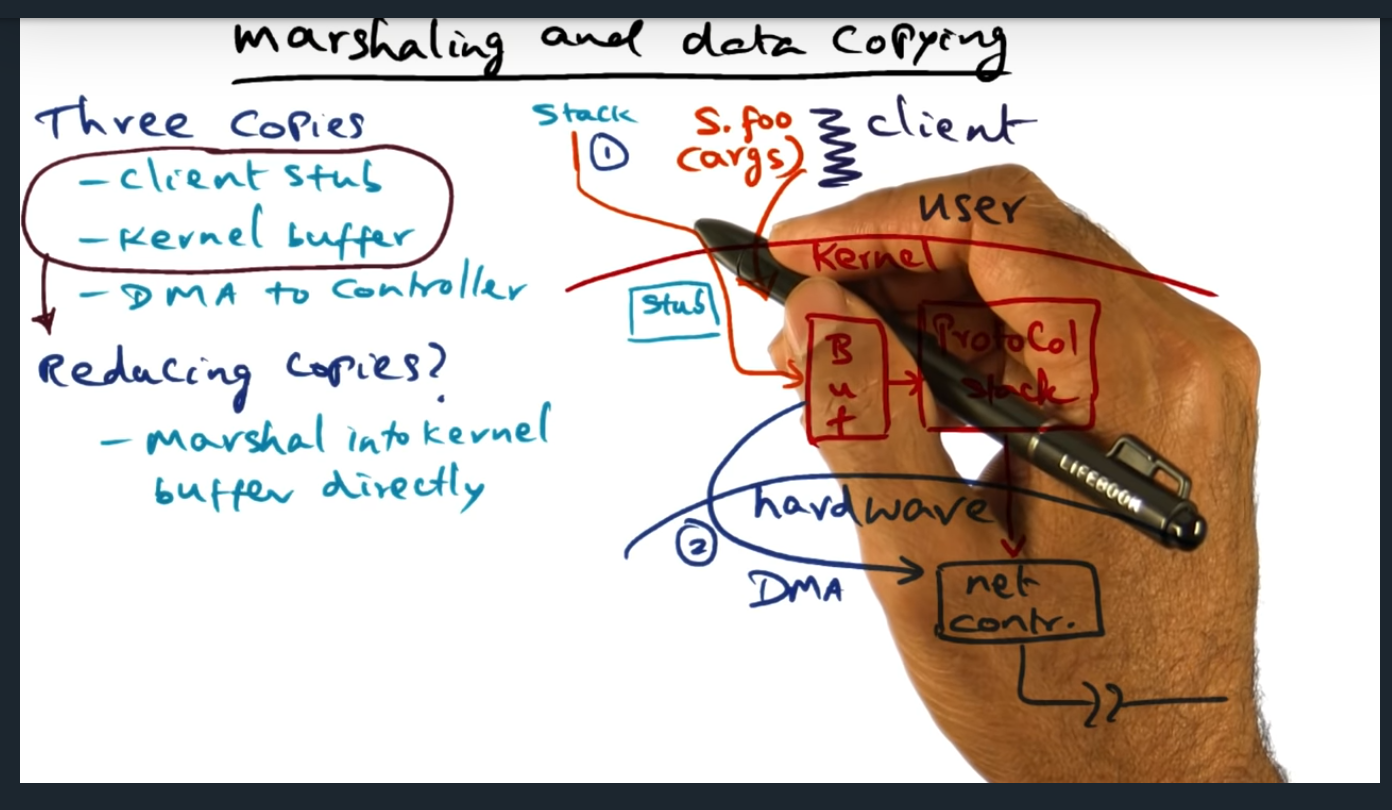
Marshaling and Data Copying
There are three copies: client stub, kernel buffer, DMA to controller
Summary
Key Words: Marshaling, RPC message, DMA
During the client RPC call, the message is copied three times. First, from stack to RPC message; second from RPC message into kernel buffer; third, from kernel buffer (via DMA) to the network controller. How can we avoid this? One approach (and there are others, discussed in the next video, hopefully) is to install the client stub directly in the kernel, creating the client stub during instantiation. Trade offs? Well, kernel would need to trust the RPC client, that’s for sure
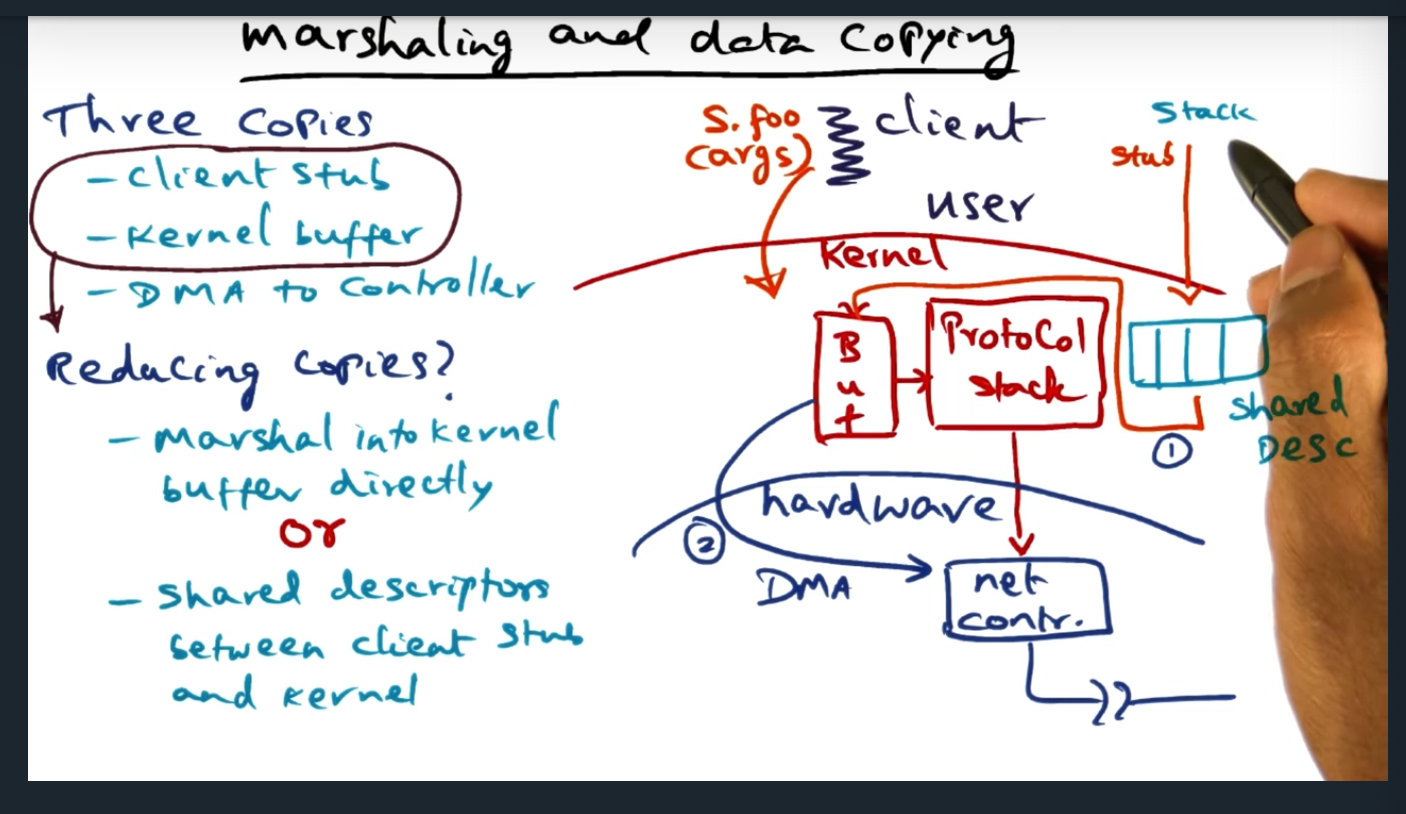
Marshaling and Data Copying (continued)
Reducing copies by 1) Marshal into kernel buffer directlry or 2) Shared descriptors between client stub and kernel
Summary
Key Words: Shared descriptors
An alternative to placing the client stub in the kernel, the client stub instead can provide some additional metadata (in the form of shared descriptors) and this allows the client to avoid converting the stack arguments into an RPC packet. The shared descriptors are basically TLV (i.e. type, length, value) and provides enough information for the kernel to DMA the data to the network controller. To me, this feels a lot like the strategy that the Xen Hypervisor employs for ring buffers for communicating between guest VM and kernel
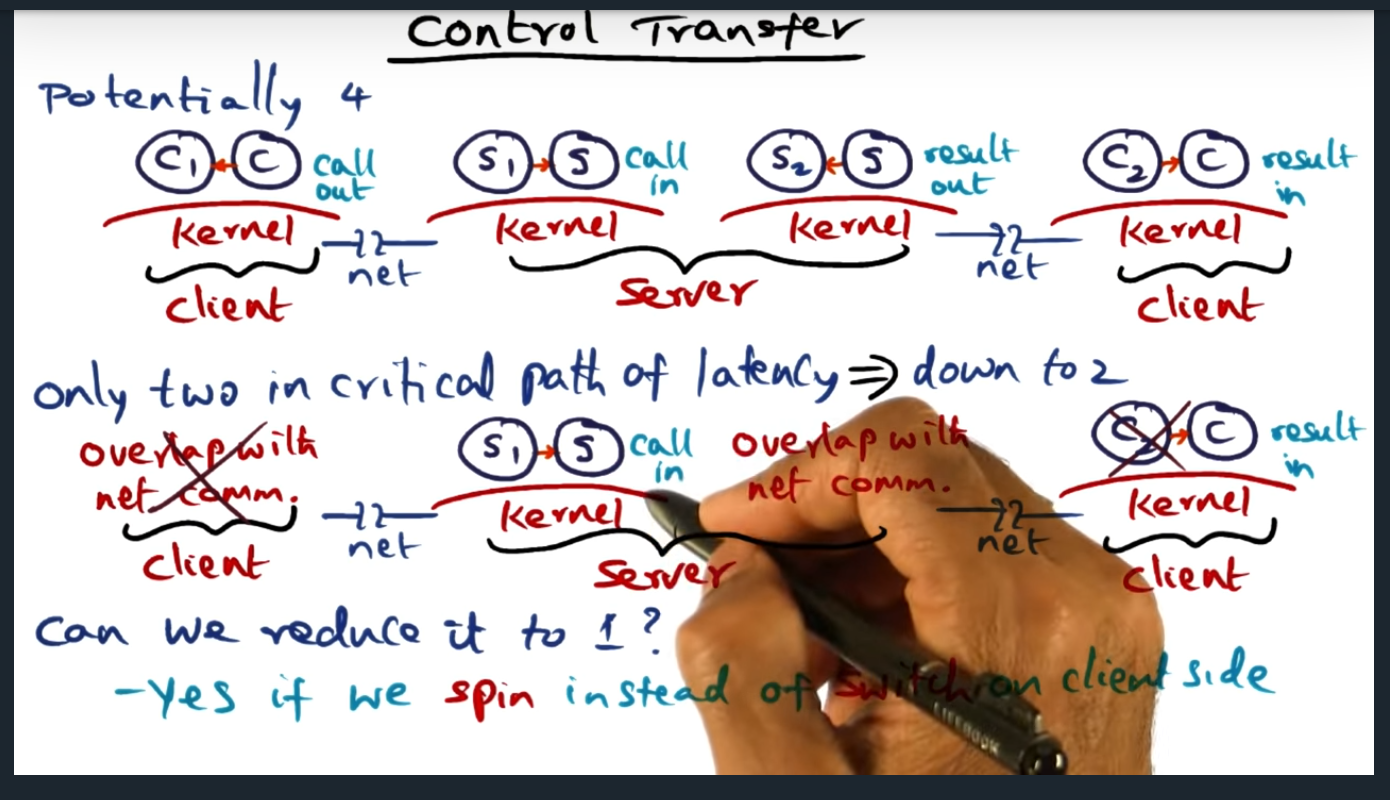
Control Transfer
Only two control transfers in the critical path, so we can reduce down to one
Summary
Key Words: Critical Path
This is the second source of overhead. Bsaically have four context switches, one in the client (client to kernel), two in the server (for kernel to call server app, and then from server app out to kernel), and one final switch from kernel back to client (the response)
The professor mentions “critical path” a couple times, but not sure what he means by that (thanks to my classmates, they answered my question in a Piazza Post: the critical path refers to the network transactions that cannot be run parallel and the length of the critical path is the number of network transactions that must be run sequentially (or how long it takes in wall time)
Control Transfer (continued)
Summary
We can eliminate a context switch on the client side, by making sure the client spins instead of switching (we had switched before in make good use of the CPU)
Protocol Processing
How to reduce latency at the transport layer
Summary
Assuming that RPC runs over lan, we can eliminate latency (but trading off reliability) by not using acknowledgements, relying on the underlying hardware to perform checksums, eliminating buffering (for retransmissions)
Protocol Processing (continued)
Summary
Eliminate client buffer and overlap server side buffering
Conclusion
Summary
Reduce total latency between client and server by reducing number of copies, reducing number of context switches, and making protocol lean and mean
Now that we talked about happened before events, we can talk about lamport clocks
Lamport’s Logical Clock
Summary
A logical clock that each process has and that clock monotonically increases as events unfold. For example, if event A happens before event B, then the event A’s clock (or counter value) must be less than that of B’s clock (or counter). The same applies between “happened before” events. To achieve this, a process will increase its own clock monotonically by setting the counter to the maximum of “receipt of the other process’s clock or its own local counter”. But what happens with concurrent events? Will hopefully learn soon
Events Quiz
Summary
C(a) < C(b) means one of two things. A happened before B in the same process. Or B is the recipient and chose the max between its local clock.
Logical Clock Conditions
Lamport’s logical clock conditions
Summary
Key Words: partial order, converse of condition
Lamport clocks give us a partial order of all the events in the distributed system. Key idea: Converse of condition 1 is not true. That is, just because timestamp of x is less than timestamp of y does not necessarily mean that x happened before y. Also, is partial order sufficient for us distributed system designers?
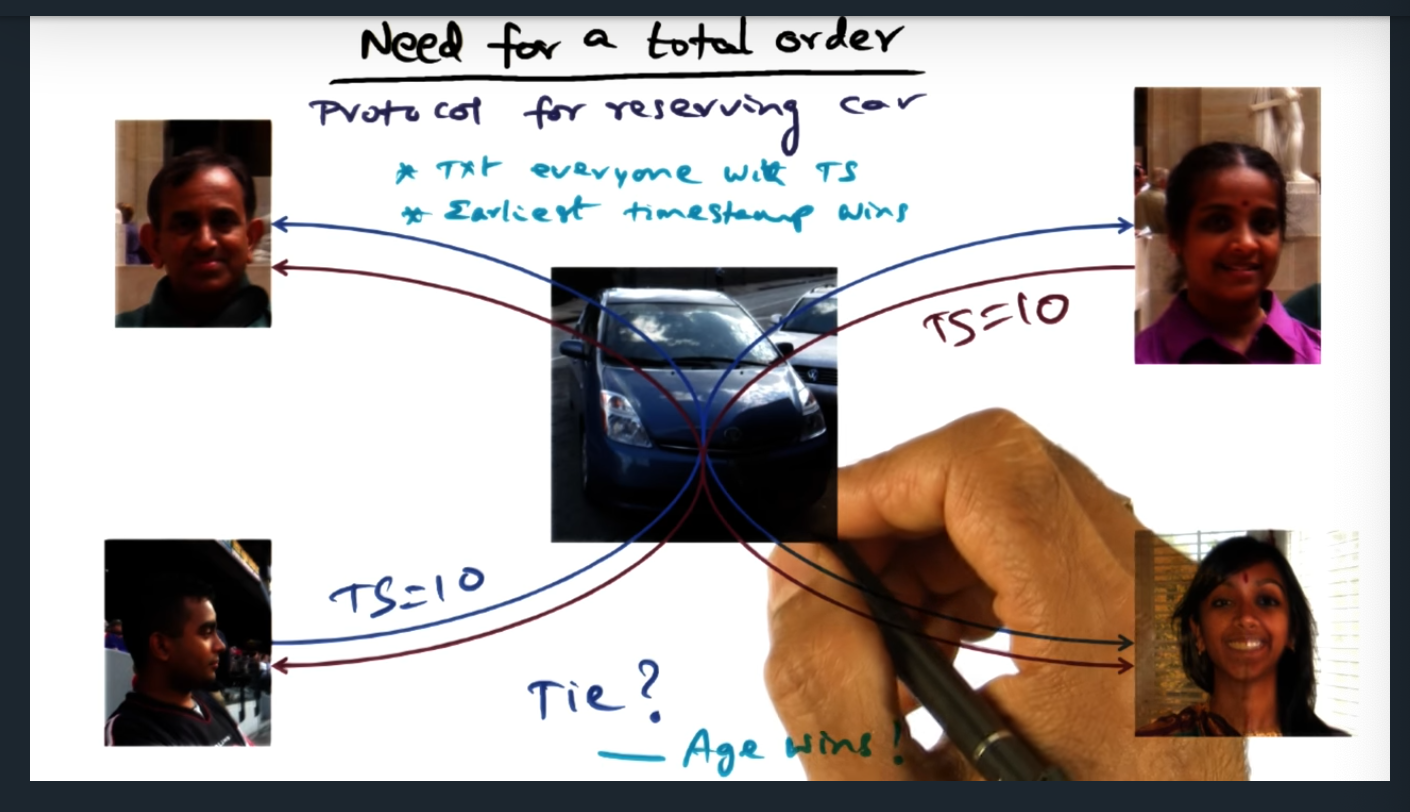
Need For A Total Order
Need for total order
Summary
Imagine a situation in which there’s a shared resource and individual people want access to that resource. They can send each other a text message (or any message) with a timestamp. The sender with the earliest timestamp wins. But what happens if two (or more) timestamps are the same. Then each individual person (or node) must make a local decision (in this case, oldest age of person wins)
Lamport’s Total Order
Lamport’s total order
Summary
Use timestamps to order events and break the time with some arbitrary function (e.g. oldest age wins).
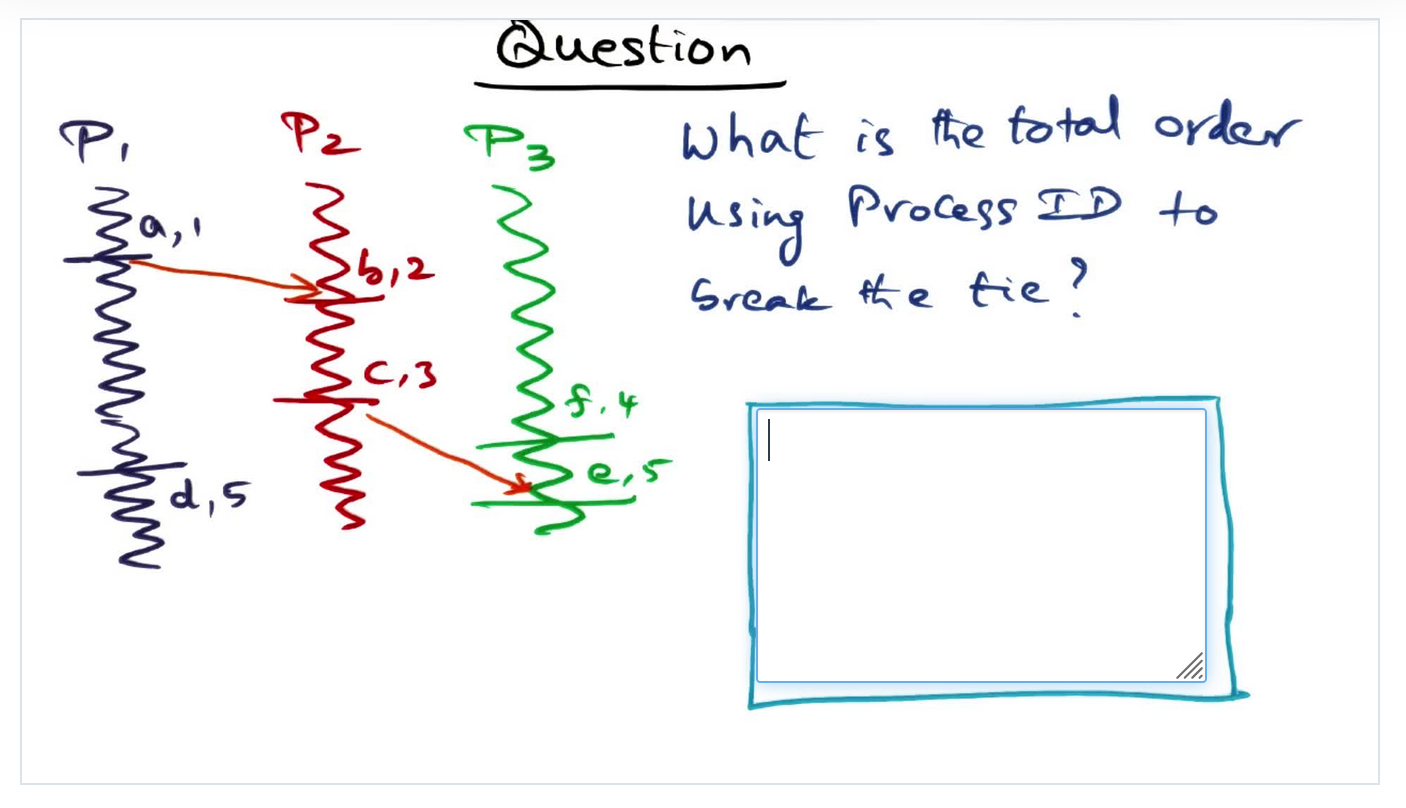
Total Order Quiz
Total order quiz
Summary
Identify the concurrency events and then figure out how to order those concurrent events to break the ties
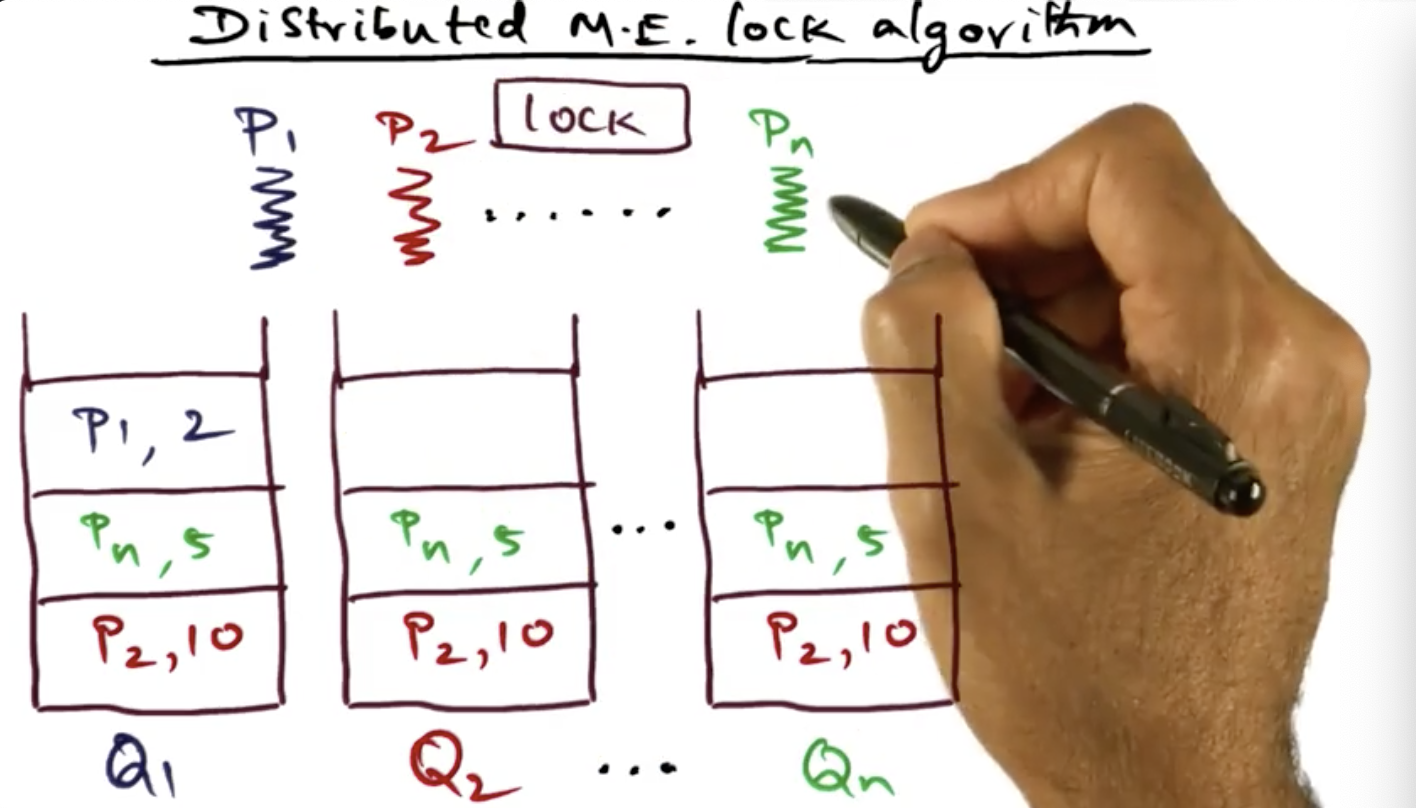
Distributed Mutual Exclusion Lock Algorithm
Distributed mutual exclusion lock
Summary
Essentially, this algorithm basically requires each process to send their lock requests via messages and these messages need to be confirmed by the other processes. Each request contains a timestamp and each host will make its own local decision, queueing (and sorting) the lock request in their local process and breaking ties by preferring lowest process ID. What’s interesting to me is that this algorithm makes a ton of assumptions like no broken network links or split brain or unidirectional communication: so many failure modes that haven’t been taken into consideration. Wondering if this will be discussed in next video lectures
Lots of assumptions of distributed mutual exclusion lock algorithm including 1) All messages are received in the order they are sent and 2) no messages are lost (this is definitely not robust enough for me at least)
Messages Quiz
Messages Quiz
Summary
With Lamport’s distributed mutual exclusion lock, we need to send 3(N-1) messages. First round that includes timestamp, second for acknowledge, third for release of lock.
Message Complexity
Message Complexity
Summary
A process can defer its acknowledgement by sending it during the unlock, reducing the message complexity from 3(N-1) to 2(N-1).
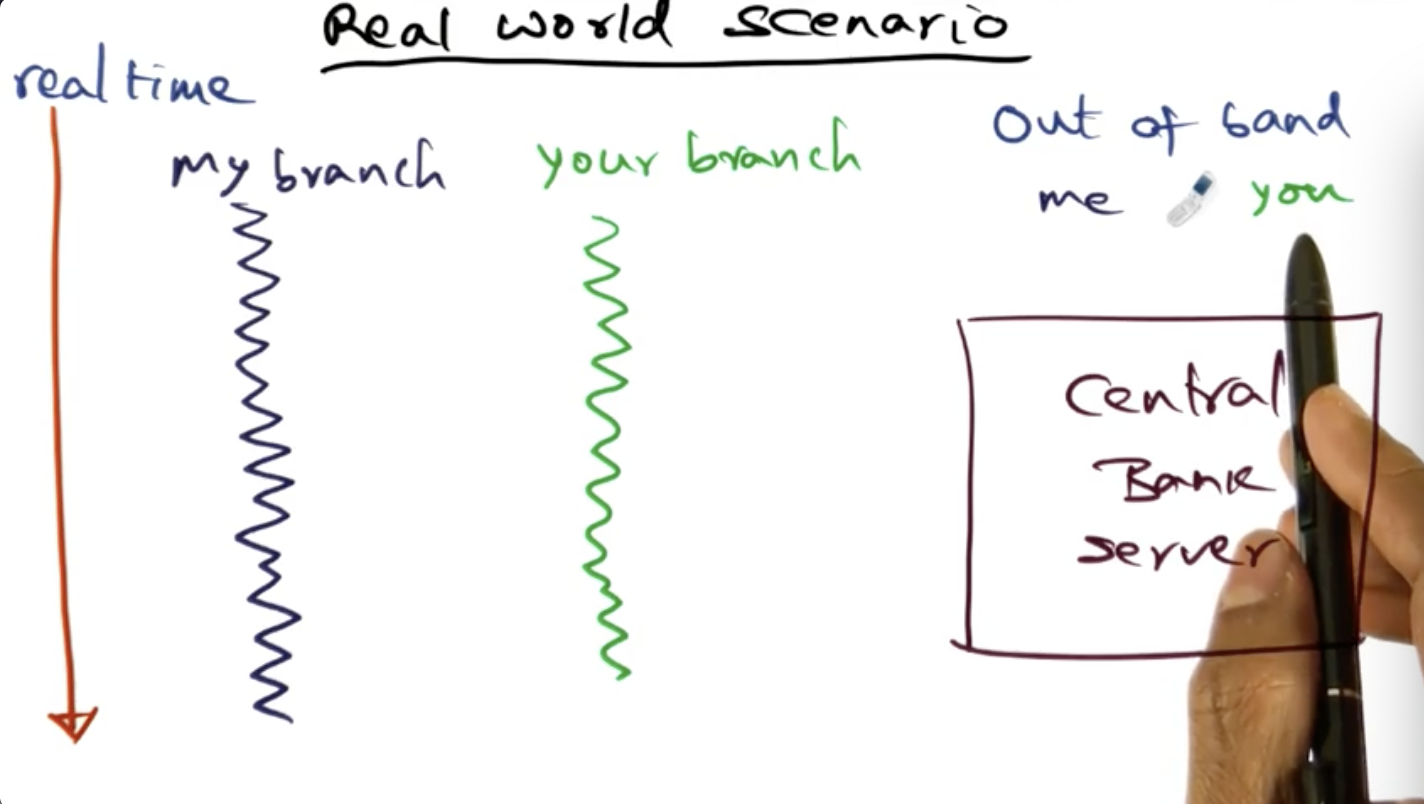
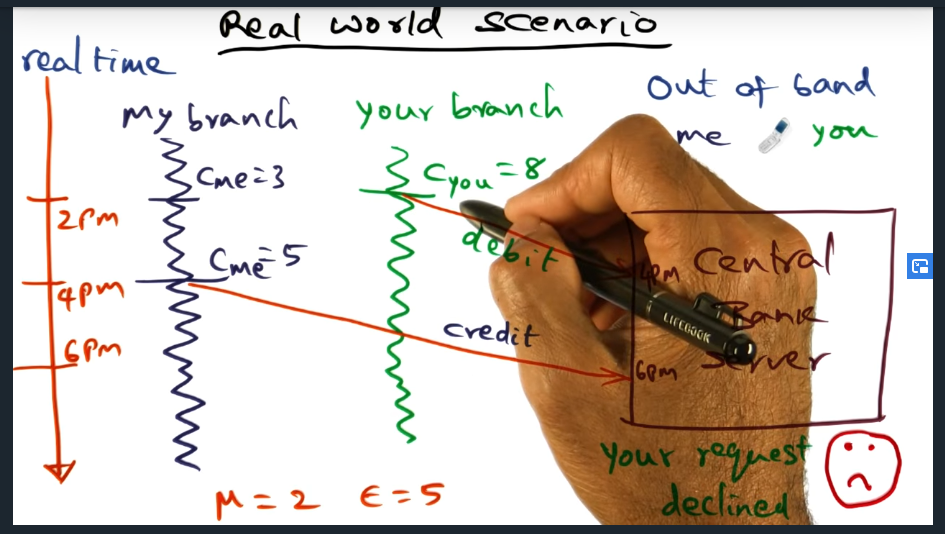
Real World Scenario
Real world scenario
Summary
Logical clocks may not good be enough in real world scenarios. What happens if a system clock (like the banks clock) drifts? What should we be doing instead?
Two conditions must be met in order to achieve Lamport’s physical clock. First is that the individual clock drift for any given node must be relatively small. Second, the mutual clock drift (i.e. between two nodes) must be negligible as well. We shall see soon but the clock drift must be negligible when compared to intercommunication process time
IPC time and clock drift
IPC and Clock Drift
Summary
Clock drift must be negligible when compared to the IPC time. Collectively, this is captured in the equation M >= Epsilon ( 1 – k) where E is the mutual clock drift and where K is individual clock drift.
Real World Example (continued)
Real world example
Summary
Mutual clock drift must be lower than IPC time. Or put differently, the IPC time must be greater than the clock drift. So the key take away is this: the IPC time (M) must be greater than the mutual clock drift (i.e. E), where k is the individual clock drift. So we want a individual clock drift to be low and to eliminate anomalies, we need IPC time to be greater than the mutual clock drift.
Conclusion
Summary
We can use Lamport’s clocks to stipulate conditions to ensure deterministic behavior and avoid anomalous behaviors